一种基于动态模式分解的视频镜头检测方法与流程
本发明涉及视频镜头检测方法技术领域,具体涉及一种基于动态模式分解的视频镜头检测方法。
背景技术
大多数视频如电影和纪录片通常都是由幕、场景和镜头组成。一幕中存在多个场景,一个场景中又包含多个镜头。导演通常使用镜头转场来更平稳地切换镜头,使视频连接更加连贯。常见的镜头转场包括:硬切割,淡入淡出和溶解。其中,硬剪切是最常用的手法。淡入淡出中镜头转场十分缓慢。镜头中的场景和被摄对象几乎没有变化,只有亮度存在缓慢变化,因此难以检测。溶解则是后一个镜头的图像重叠在前一个镜头的图像上。在两个镜头边界上,由于前一个镜头与后一个镜头的视觉特性有所重叠,导致现有方法产生错误检测结果。
目前,镜头检测主要采用的方法:一是使用像素、像素块或颜色直方图比较来检测镜头边界。二是使用基于视频内容包括纹理、颜色和形状来进行镜头检测。除此之外,还有利用余弦相似度、加权边缘信息、机器学习等方法来检测镜头边界。当前方法存在的主要问题是:第一,在像素、像素块和直方图比较的镜头检测中,由于光照在非镜头边界上发生了剧烈的变化很容易导致产生错误结果。第二,当被拍摄物体(或摄像机)运动速度较快时,算法的正确率将大大降低。第三,由于溶解的镜头转场中前后镜头的图像存在重叠,因此基于纹理、颜色和形状等视频内容的镜头检测方法精度较低。此外,利用余弦相似度、加权边缘信息、机器学习等方法,处理溶解和淡入淡出这两种镜头转场的准确率和召回率都很低。
因此需要一种方法,在不存在镜头转场的视频中使用稳定的镜头边界特征权重抑制错误检测结果的出现,而在含有镜头转场的视频中得到显著变化且易于识别的特征权重,提取用户需要的镜头边界。
现有算法所存在的问题可以概括为两点:第一,在不存在镜头转场的视频中,由于光照变化剧烈,或者被拍摄物体(或照相机)移动得更快。现有算法可能存在错误检测,导致精确率低。第二,在存在镜头转场的视频中,不同场景中的色差太小,光线变化缓慢(淡入),或者前景对象重叠(溶解)。都会导致现有算法出现大量漏检导致召回率低。
技术实现要素:
本发明的目的在于克服上述背景技术存在的缺陷,提供一种基于动态模式分解的视频镜头检测方法,扩大背景(或前景)模式的时间特征权重,降低噪声(亮度,纹理等)对镜头检测的影响,有效减少漏检和误检,同时,本发明对镜头边界检测结果具有较高的正确率和召回率。
本发明的技术方案:
一种基于动态模式分解的视频镜头检测方法,包括如下步骤:
步骤一,从视频镜头获取图像数据建立时序矩阵
步骤二,通过动态模式分解对时序矩阵求解获得连续两帧的线性相关系数矩阵s;
步骤三,根据线性相关系数矩阵s求解视频中前景模式和背景模式;
步骤四,根据线性相关系数矩阵s分别求解前景模式和背景模式中振幅aamp(t);
步骤五,判断背景模式振幅是否超过预设阀值;如果背景模式振幅超出预设阀值,输出镜头边界,否则返回步骤一。
所述步骤二中线性相关系数矩阵s,
所述步骤三中背景模式,即
所述步骤三中背景模式,即
所述步骤四中振幅,即
与现有技术相比,本发明具有的优点:
本发明是将视频数据作为矩阵数据序列,直接从矩阵数据中提取时序特征,如图4所示。然后利用动态模式分解提取视频中的背景模式和一系列前景模式,每一帧的背景(或前景)可以通过使用与其对应的背景(或前景)模式和振幅来进行恢复;本发明可以很容易地扩展到其他类型的镜头转换。
第二,本发明是使用背景模式振幅来检测镜头边界,对于不存在镜头边界的视频数据,背景模式相对恒定,背景模式的振幅相对稳定。相反,当视频中存在镜头边界时,背景模式和对应的振幅会发生剧烈变化,如图5所示;提高对镜头视频采集的精准性。
第三,本发明是针对动态模式分解的颜色空间(如图6所示),减少了错误检测和漏检。
第四,本发明通过对150分钟的视频如图2、如图3所示,(包含硬剪切、溶解和淡入淡出)进行集中测试。验证了该方法的有效性,提高了镜头检测的召回率和精确率;并且对于任意复杂的电影序列,它具有恒定的检测质量,而无需调整参数。
附图说明
图1为本发明一种基于动态模式分解的视频镜头检测方法流程图。
图2为本发明中三种镜头转换方式:硬切割,淡入淡出和溶解。
图3为本发明中的视频镜头检测框架。
图4为本发明中动态模式算法将视频分解为模式矩阵、时间特征矩阵和权重矩阵。
图5为本发明分析若背景模式的振幅发生了剧烈变化,则视频尾帧是镜头边界。
图6为本发明中使用动态模式分解的颜色空间可以大大降低噪声对镜头检测的干扰。
图7为本发明中没有镜头边界但是光照变化剧烈的视频及其振幅检测结果。
图8为本发明中没有镜头边界但是前景物体快速移动的视频及其振幅检测结果。
图9为本发明中硬切割镜头转换方式及其振幅检测结果。
图10为本发明中淡入淡出镜头转换方式及其振幅检测结果。
图11为本发明中溶解镜头转换方式及其振幅检测结果。
图12为最佳实施方式第二步提出的通过比较背景模式振幅特征判断镜头边界。(a)显示存在硬剪切的视频数据。(b)通过动态模式分解方法从视频中提取振幅。红色线代表背景模式振幅,其他颜色线代表前景模式振幅。
图13为最佳实施方式第三步提出的利用不同的颜色空间增加时间特征权重。(a)显示不存在镜头边界的视频数据。(b)通过动态模式分解方法从视频中提取振幅线。红色线代表背景模式振幅,其他颜色线代表前景模式振幅。(c)通过dmd方法从视频中提取hsv颜色空间的振幅线。红色线代表背景模式振幅,其他颜色线代表前景模式振幅。
具体实施方式
下面通过具体实施例和附图对本发明作进一步的说明。本发明的实施例是为了更好地使本领域的技术人员更好地理解本发明,并不对本发明作任何的限制。
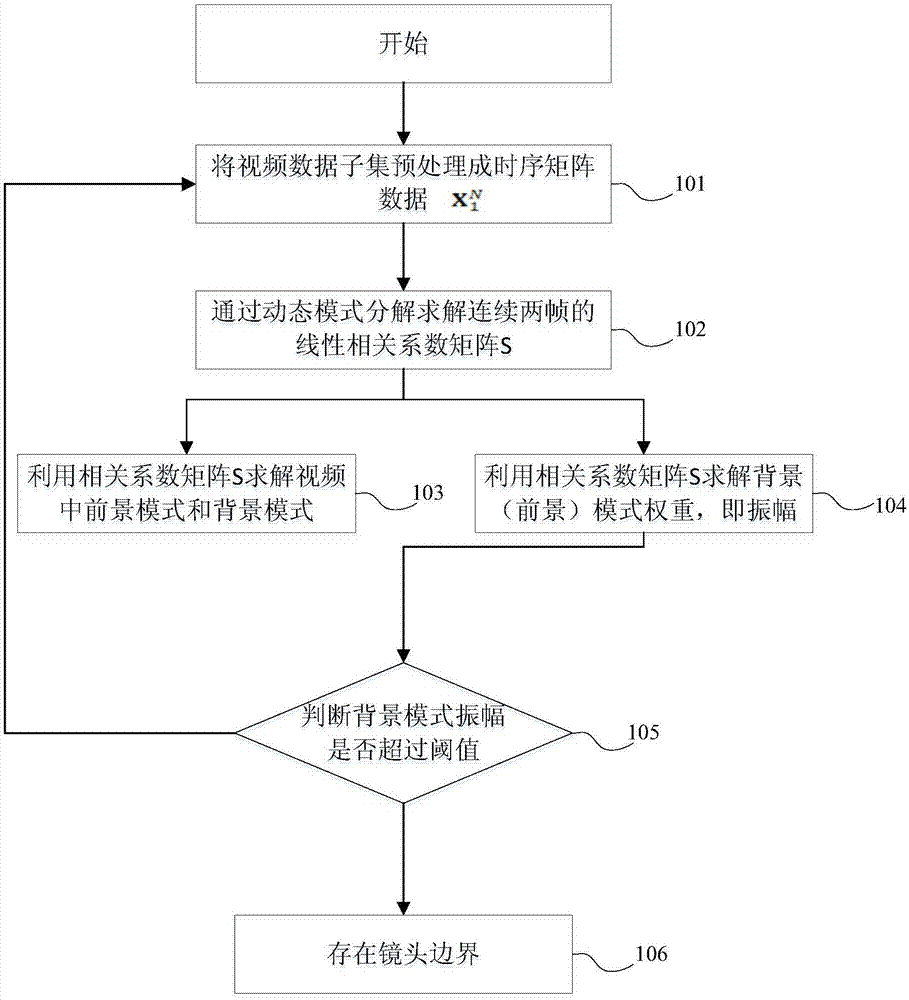
如图1所示,本发明提供一种基于动态模式分解的视频镜头检测方法,包括如下步骤:步骤一101,从视频镜头获取图像数据建立时序矩阵
视频是具有很强的时空相关性的数据。每个视频镜头都可以看作是一个潜在复杂的非线性动态快照。然而,动态模式分解是一种数学方法,它的重点是从具有时间动态特性的复杂系统中发现高维数据的相干时空模式。动态模式分解的能力是发现和利用复杂系统中的背景变化。这是解决镜头检测的关键。
使用动态模式分解提取视频背景模式。首先,定义一个视频流从x1toxn是均匀采样数据在n帧,和时间间隔是δt。视频数据的时间表示为:
xi(i<<i<<n)是第i帧视频的图像。假设有一个线性映射的过程,可以利用库普曼算子a映射第j和第j+1时刻数据:
xi+1=axi
由于,
其中u是酉矩阵(u∈cm×l),σ对角矩阵(∑∈cl×l)和v是酉矩阵(v∈cn-1×l)。参数l是x最小的秩。
步骤二102,通过动态模式分解对时序矩阵求解获得连续两帧的线性相关系数矩阵s;
利用相似变换(v∑-1)可以得到s的变换矩阵,表示为:
动态模式分解算法的基本思路是:
s矩阵的特征值与库普曼算子a的特征值近似,类似于计算在arnoldi算法的ritz值。
步骤三103,根据线性相关系数矩阵s求解视频中前景模式和背景模式;
动态模式分解的模式
另外,将特征值转换为傅立叶模式,用以预测时间动态:
ωj=ln(μj)/δt
ωj实部对应的动态模式分解基函数的增长或衰减,ωj虚部对应的动态模式振荡。通过xdmd(t)=atx1可以重构视频
显然,会有一个相应的傅里叶模式ωj位于复杂的空间点原点附近,即||ωj||≈0,,如果视频不随时间推移而变化,或者变化很慢。因此,背景模式表示视频中相对静止的场景,而前景模式表示视频中相对运动中的多个对象或场景。可以得到背景模式和前景模式,即
步骤四104,根据线性相关系数矩阵s分别求解前景模式和背景模式中振幅aamp(t);
在上述aamp(t)公式中,λ通过计算时空特征矩阵的时间背景(前景)模式得到,它是在视频中的背景和前景的特征。权重矩阵表示图像中每帧不同模式的权重,其中包含背景模式权重和前景模式权重。总之,振幅随着时间变化。
步骤五105,判断背景模式振幅是否超过预设阀值;如果背景模式振幅超出预设阀值,输出镜头边界,否则返回步骤一。
步骤五106是通过比较背景模式振幅特征判断镜头边界。动态模式分解可以提取视频中的背景模式和前景模式。背景模式表示视频中相对静止的背景或场景。前景模式表示同一视频中的相对运动或改变的对象或场景。一般来说,视频可以提取到一个背景模式和几个前景模式。振幅是背景(或前景)模式的时间特征权重,它表示视频中背景(或前景)的变化程度。背景模式和振幅在有边界的视频数据中有剧烈变化。通过将背景模式与阈值进行比较,超过阈值则判断存在镜头边界,如果未超过阈值则说明视频中不存在镜头边界。该阈值是通过计算30组不存在镜头边界视频的背景模式的振幅得到的平均值。
图7显示了一组包含九帧图像的视频镜头。这九帧中并不存在镜头边界且只有部分光照变化。使用动态模式分解该视频,可以看出434帧到442帧的背景模式相对恒定。然而,使用像素块的结果却将第437帧和第440帧错识别为镜头边界。
图8显示了一组包含了9帧图像的视频镜头。在该视频中,一直猫头鹰从镜头中迅速飞过但不存在镜头边界。使用动态模式分解该视频,发现背景模式的振幅相对稳定。而使用颜色块算法计算得到的结果却将第6730和第6732帧错误识别为镜头边界。原因是在这两帧图像中猫头鹰的图像特征发生了剧烈变化。
图9显示一组包含了9帧的视频镜头。这是一个包含了硬剪切的视频镜头转场效果。最后一帧1785帧是一个镜头边界。通过动态模式分解对视频进行处理,可以看出第1777帧到1784帧的背景模式的振幅十分稳定,而第1777帧到1785帧图像的背景模式振幅非常锐利。因此,确定第1785帧是镜头边界。
图10显示了一组包含9帧的淡入淡出视频镜头。随着时间变化,视频图像逐渐变黑。通过使用动态模式分解计算视频,可以看出从1921帧到1927帧视频的背景模式振幅随时间变化相对恒定。而第1921帧到1928帧的背景模式振幅则发生了非常锐利变化。因此可以证明第1928帧是一个镜头边界。
图11显示了一组溶解的视频镜头。通过计算第447帧到第454帧可以看出视频背景模式的振幅并没有发生剧烈变化,而当计算第447帧到第455帧的背景模式的振幅发现了一个明显的变化。因此,我们可以确定第455帧处存在镜头边界。
图12显示了一组包含十二帧图像的视频镜头。前十一帧中没有镜头边界,视频中描绘了海水冲刷海岸的过程。在该视频中,天空是背景,没有变化,因此镜头也不会切换。使用动态模式分解该视频,可以看到背景模式随时间的振幅是恒定的,对应于背景的图案,即天空。下一组前景模式是波浪,随着摄像机的移动也就是镜头中的前景元素。然而,在最后一帧中存在一个镜头边界。可以看出5162到5172帧的振幅非常平缓。然而,5162到5173帧的振幅非常锐利。因此,第5713帧是一个镜头边界。
图13所示,原始视频帧亮度变化不明显。然而,我们将rgb图像转换为灰度图。由于亮度的变化,由计算的背景模式的振幅发生剧烈的变化。因此,我们需要通过其他颜色空间来减少亮度变化的影响。选择hsv颜色空间,只使用色调通道和饱和通道来计算背景特征。这样可以减少镜头检测的噪声。在图12中,可以看到,当改变颜色空间到hsv时,没有镜头边界的视频中背景模式的振幅非常平缓。镜头边界处仍然满足背景模式振幅剧烈变化的检测条件。利用颜色空间消除噪声对镜头检测的干扰,提高了镜头检测的准确率和召回率。
本发明利用不同的颜色空间增加时间特征权重,从而减少亮度对镜头检测的影响。传统方法是比较相邻视频帧之间的亮度差异,确定镜头边界。但当光照变化剧烈时,算法的精度会大大降低。因此,当视频镜头转场相邻两帧亮度变化明显时,传统的镜头检测算法会产生噪声。使用动态模式分解方法求出镜头边界仍存在亮度噪声问题。通过将rgb颜色空间的原始视频图像转换为灰度图像,利用动态模式分解方法计算背景特征。当视频中不存在镜头转场但亮度稍有变化时,背景特征有时变化非常剧烈。
应当理解的是,这里所讨论的实施方案及实例只是为了说明,对本领域技术人员来说,可以加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!