智能音箱及播放控制方法与流程
本发明涉及到智能音箱领域,特别是涉及到一种智能音箱及播放控制方法。
背景技术:
智能音箱,是一个音箱升级的产物,是家庭消费者用语音进行上网的一个工具,比如点播歌曲、上网购物,或是了解天气预报,它也可以对智能家居设备进行控制,比如打开窗帘、设置冰箱温度、提前让热水器升温等。
以亚马逊echo为代表的智能音箱,实际上都属于智能语音技术。其操作都需要语音指令来控制。然而,现有的家居环境背景噪音较大,这种噪音会影响语音指令的正确识别,降低用户体验。因此,需要采用更多的方式,方便用户与智能音箱进行交互,提升用户体验。
技术实现要素:
本发明的主要目的为提供一种智能音箱及播放控制方法,增强使用智能音箱的用户体验。
本发明提供了一种播放控制方法,包括以下步骤:
智能音箱进行人体检测;
当检测到人体时,识别所述人体的手势动作;
根据所述手势动作调节所述智能音箱的播放状态。
优选地,所述识别所述人体的手势动作的步骤包括:
将检测到的人体的每帧手势图像的手势与背景进行分离,并找出每帧手势图像中的手势轮廓;
将所述手势轮廓逐帧与预设开始手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为开始手势轮廓;
将时序在所述开始手势轮廓之后的手势轮廓逐帧与预设结束手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为结束手势轮廓;
将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势动作确定为识别到的一组手势动作。
优选地,所述根据所述手势动作调节所述智能音箱的播放状态的步骤包括:
确定所述手势动作对应的控制指令;
根据所述控制指令调节所述智能音箱的播放状态。
优选地,所述确定所述手势动作对应的控制指令的步骤包括:
对所述手势动作进行特征提取,获得手势动作特征;
对所述手势动作特征进行编码,获得编码结果;
确定所述编码结果对应的控制指令。
优选地,所述方法还包括:
计算所述智能音箱与所述人体之间的物理距离;
根据所述物理距离调整所述智能音箱的音量。
优选地,所述智能音箱进行人体检测的步骤包括:
所述智能音箱基于梯度方向直方图进行人体检测。
优选地,所述智能音箱基于梯度方向直方图进行人体检测的步骤包括:
对检测窗口内的图像进行一阶梯度计算;
计算所述图像中各个单元格的梯度方向直方图;
对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图;
对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。
本发明的另一个方面,还提出了一种智能音箱,包括:
检测模块,用于进行人体检测;
识别模块,用于当检测到人体时,识别所述人体的手势动作;
调整模块,用于根据所述手势动作调节所述智能音箱的播放状态。
优选地,所述识别模块包括:
分离单元,用于将检测到的人体的每帧手势图像的手势与背景进行分离,并找出每帧手势图像中的手势轮廓;
开始手势单元,用于将所述手势轮廓逐帧与预设开始手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为开始手势轮廓;
结束手势单元,用于将时序在所述开始手势轮廓之后的手势轮廓逐帧与预设结束手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为结束手势轮廓;
手势动作单元,用于将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势动作确定为识别到的一组手势动作。
优选地,所述调整模块包括:
确定指令单元,用于确定所述手势动作对应的控制指令;
调整单元,用于根据所述控制指令调节所述智能音箱的播放状态。
优选地,所述确定指令单元包括:
获取特征子单元,用于特征对所述手势动作进行特征提取,获得手势动作特征;
编码子单元,用于对所述手势动作特征进行编码,获得编码结果;
确定指令子单元,用于确定所述编码结果对应的控制指令。
优选地,还包括:
距离计算模块,用于计算所述智能音箱与所述人体之间的物理距离;
调整音量模块,用于根据所述物理距离调整所述智能音箱的音量。
优选地,所述检测模块包括:
梯度检测单元,用于基于梯度方向直方图进行人体检测。
优选地,所述梯度检测单元包括:
一阶梯度计算子单元,用于对检测窗口内的图像进行一阶梯度计算;
单元格梯度子单元,用于计算所述图像中各个单元格的梯度方向直方图;
块梯度子单元,用于对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图;
生成特征向量子单元,用于对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。
本发明还提出了一种智能音箱,包括存储器、处理器和至少一个被存储在所述存储器中并被配置为由所述处理器执行的应用程序,所述应用程序被配置为用于执行上述的播放控制方法。
本发明提供了智能音箱及播放控制方法,其中的播放控制方法包括:智能音箱进行人体检测;当检测到人体时,识别所述人体的手势动作;根据所述手势动作调节所述智能音箱的播放状态。本发明提供的方法增加一种使用智能音箱的交互方式,使得用户可以通过手势对智能音箱进行控制,提高了用户体验。
附图说明
图1为本发明播放控制方法一实施例的流程示意图;
图2为本发明智能音箱一实施例的结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
参照图1,本发明实施例提出了一种播放控制方法,包括以下步骤:
s10、智能音箱进行人体检测;
s20、当检测到人体时,识别所述人体的手势动作;
s30、根据所述手势动作调节所述智能音箱的播放状态。
本实施例中,智能音箱上安装有深度传感器。深度传感器分为两类:被动式立体相机和主动式深度相机。被动式立体相机利用两个或更多个相机来观察场景,并且使用这些相机的多个视图中特征之间的差异(移位)来估计场景的深度。主动式深度相机向场景投射不可见的红外光,并且根据被反射的信息,估计场景的深度。在一应用场景中,用户甲站在与智能音箱一定位置,向智能音箱的深度传感器作出一些手势指令,如开启播放指令,智能音箱识别出用户甲手势指令的含义后,播放声音。
步骤s10中,智能音箱通过深度传感器进行人体检测。可以基于梯度方向直方图(histogramoforientedgradient,hog)、尺度不变特征转换(scale-invariantfeaturetransform,sift)、局部二值模式(localbinarypattern,lbp)、harr等图像特征进行人体检测。
步骤s20中,当智能音箱检测到人体时,识别该人体的手势动作。具体是通过深度传感器获取一组包含手势的视频数据。在此处深度传感器起到录影的作用。可按预设的规则来获取视频数据。如,当深度传感器监测到用户有较大的手势动作时,将该段视频数据确定为包含手势的视频数据。
将上述视频数据解析为多帧连续的图像,将图像中的背景与手势分离,并找出每帧图像中的手势轮廓。按预设的规则确定手势动作的起始帧和结束帧。将起始帧与结束帧之间的手势轮廓确定为手势动作。也就是说,手势动作包括多帧图像的手势轮廓。
步骤s30中,获得手势动作之后,对手势动作进行特征提取,获得手势动作特征,对手势动作特征进行识别,获得识别结果,最后根据识别结果生成控制指令。
智能音箱根据控制指令调节播放状态。如获得的控制指令为开始播放指令,则智能音箱开始播放声音;若获得的控制指令为停止播放指令,则智能音箱停止播放声音。
可选的,步骤s20包括:
将检测到的人体的每帧手势图像的手势与背景进行分离,并找出每帧手势图像中的手势轮廓;
将所述手势轮廓逐帧与预设开始手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为开始手势轮廓;
将时序在所述开始手势轮廓之后的手势轮廓逐帧与预设结束手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为结束手势轮廓;
将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势动作确定为识别到的一组手势动作。
本实施例中,智能音箱存储有不同控制指令对应的预设开始手势轮廓和预设结束手势轮廓。视频数据的各个手势轮廓先逐帧与预设开始手势轮廓进行匹配,将匹配的第一帧手势轮廓确定为开始手势轮廓。在第一帧以后的手势轮廓,逐帧与预设结束手势轮廓进行匹配,将匹配的第一帧手势轮廓确定为结束手势轮廓。然后,将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势轮廓序列确定为手势动作。获得的手势动作可用来识别手势包含的含义,进而生成相应的控制指令。
可选的,步骤s30包括:
确定所述手势动作对应的控制指令;
根据所述控制指令调节所述智能音箱的播放状态。
本实施例中,智能音箱上存储芯片预存了多组不同手势动作对应的控制指令。例如可以规定,手势动作“往上一挥”对应“提升音量”指令,手势动作“往下一挥”对应“降低音量”指令,手势动作“摆手”对应“停止播放”指令,手势动作“双手轻拍”对应“开始播放”指令。当智能音箱确定用户做出的手势动作对应的开始播放指令,则智能音箱会按照开始播放指令进行播放。播放的内容可以是音乐,也可以是新闻。同样的,当智能音箱确定用户做出的手势动作对应的结束播放指令,则智能音箱会按照结束播放指令停止播放声音内容。用户可以免受停止播放前的声音内容的干扰。
可选的,所述确定所述手势动作对应的控制指令的步骤包括:
对所述手势动作进行特征提取,获得手势动作特征;
对所述手势动作特征进行编码,获得编码结果;
确定所述编码结果对应的控制指令。
本实施例中,手势动作特征是每帧图像轮廓特征的序列集合。为了获得手势动作特征,需要计算每帧图像的每个轮廓的特征值。具体而言,将提取得到的手势轮廓,计算该手势轮廓中每个轮廓的轮廓特征值。每个轮廓的轮廓特征值包括每个轮廓的区域直方图、矩和地球移动距离。
然后,要对提取的手势动作特征采用8个基准方向向量进行编码,计算编码结果。8个基准方向指的是360度平分的八个方向。
可以使用dtw算法来计算编码结果。在dtw算法中,已存入模板库的各个手势成为样本模板,一个样本模板表示为{t(1),t(2),...,t{m},...,t{m}}。所要识别的一个输入手势为测试模板,表示为{s(1),s(2),...s(n),...,s(n)}。将测试模板的各帧号m=1-m在纵轴上标出,通过这些表示帧号的坐标画出纵线即可形成一个个网格,网格中的每一个交叉点(n,m)表示测试模板中某一帧与训练模式中某一帧的交汇点。
dtw算法可以归结为寻找一条通过此网格中若干格点的路径.为了描述这条路径,假设路径通过的所有格点依次为(n1,m1),...,(ni,mi),..,(nn=mn),其中(n1,m1)=(1,1),(nn,mn)=(n,m).路径可以用函数mi=f(ni),其中ni=i,i=1,2,...,n,f(1)=1,f(n)=m。为了使路径不至于过分倾斜,可将倾斜约束在0-2范围内,如果路径通过格点(ni,mi),那么其前一个节点只可能是下列三种情况之一:(ni-1,mi),(ni-1,mi-1)或(ni-1,mi-2)。路径的累积距离d[(ni,mi)]=d[s(ni),t(mi)+d((ni-1,mi-1))],其中(ni-1,mi-1)由下式决定:
d[(ni-1,mi-1)]=min{d[ni-1,mi],d[(ni-1,mi-1)],d[(ni-1,mi-2)]}。
最后,确定编码结果对应的控制指令。获得的编码结果与预设编码数据比较,输出最接近的预设编码数据对应的控制指令。为了减少错误检测率,还可以设置接近度阈值,若获得的编码结果与预设编码数据的匹配度太低,则不输出控制指令。
可选的,播放控制方法还包括:
计算所述智能音箱与所述人体之间的物理距离;
根据所述物理距离调整所述智能音箱的音量。
本实施例中,可以通过主动式深度相机直接计算出智能音箱与用户之间的距离,然后根据用户与智能音箱的距离调节音量,以使调节后的音量达到预设值。例如,用户离智能音箱5米时,听到的音量为50分贝,离智能音箱10米时,为了使用户听到的音量等于50分贝,需提高智能音箱的音量。由于在室内,距离与音量成一定的对应关系,可以根据对应关系调节智能音箱的音量,使得用户在不同地点听到的音量是一样的。此处的预设值可以是5米处用户听到的音量,也可以是厂商预设的一个物理距离的音量。
可选的,步骤s10包括:
所述智能音箱基于梯度方向直方图进行人体检测。
本实施例中,智能音箱可以基于梯度方向直方图(histogramoforientedgradient,hog)进行人体检测。
梯度方向直方图是类似于尺度不变特征转换的一种局域描述符,它通过计算局部区域上的梯度方向直方图来构成人体特征。与尺度不变特征转换不同的是,尺度不变特征转换是基于关键点的特征提取,是一种稀疏描述方法,而梯度方向直方图是密集的描述方法。
梯度方向直方图描述方法具有以下优点:梯度方向直方图表示的是边缘(梯度)的结构特征,因此可以描述局部的形状信息;位置和方向空间的量化,在一定程度上可以抑制平移和旋转带来的影响;同时采取在局部区域的归一化,可以部分抵消光照带来的影响。故本发明实施例优选基于梯度方向直方图进行人体检测。
可选的,所述智能音箱基于梯度方向直方图进行人体检测的步骤包括:
对检测窗口内的图像进行一阶梯度计算;
计算所述图像中各个单元格的梯度方向直方图;
对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图;
对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。
本实施例中,首先对检测窗口内的图像进行一阶梯度计算,具体为:将规范化大小(如64x128)的检测窗口(detectionwindow)作为输入,通过一阶(一维)sobel算子[-1,0,1]计算检测窗口内的图像水平和垂直方向上的梯度。
采用单一窗口作为分类器输入的好处是分类器对目标的位置与尺度具有不变性。对于一个待检测的输入图像来说,需要沿着水平和垂直方向移动检测窗口,同时要以多尺度对图像进行缩放以检测不同尺度下的人体。
然后,计算所述图像中各个单元格的梯度方向直方图,具体为:梯度方向直方图是在被称为单元格(cell)和块(block)的网格内进行密集计算得到的。将图像分成若干单元格,每个单元格由多个像素构成,而块则是由若干相邻的单元格组成。
在此实施例中,先计算图像内每个像素的梯度,再统计出图像内每个单元格中所有像素的梯度方向直方图,即该单元格的梯度方向直方图。在统计各个单元格的梯度方向直方图时,首先针对每个单元格将[0~π]划分为多个区间,然后根据该单元格内各像素的梯度方向进行加权投票计算,得到该单元格中所有像素的梯度方向直方图。
在进行加权投票计算时,每个像素的权重为优选为该像素的梯度幅度。为了消除混淆,优选采用三线性差值(trilinearinterpolationi)进行加权投票计算。
遍历图像中的每个单元格,得到图像中各个单元格的梯度方向直方图。
对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图。在块内,对该块内的单元格的梯度方向直方图进行归一化处理,以消除光照的影响,从而得到该块的梯度方向直方图。遍历图像中的每个块,得到图像中每个块的梯度方向直方图。
对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。由各块归一化后得到的检测窗口的梯度方向直方图,构成人体特征向量,从而实现人体检测。
由于梯度方向直方图是一种密集计算方式,因此计算量较大。为了减小计算量,提高检测速度,可以考虑选择在有较明显的人体轮廓的重点区域计算梯度方向直方图,从而达到降低维数的目的。
本发明提供了一种播放控制方法,包括:智能音箱进行人体检测;当检测到人体时,识别所述人体的手势动作;根据所述手势动作调节所述智能音箱的播放状态。本发明提供的方法增加一种使用智能音箱的交互方式,使得用户可以通过手势对智能音箱进行控制,提高了用户体验。
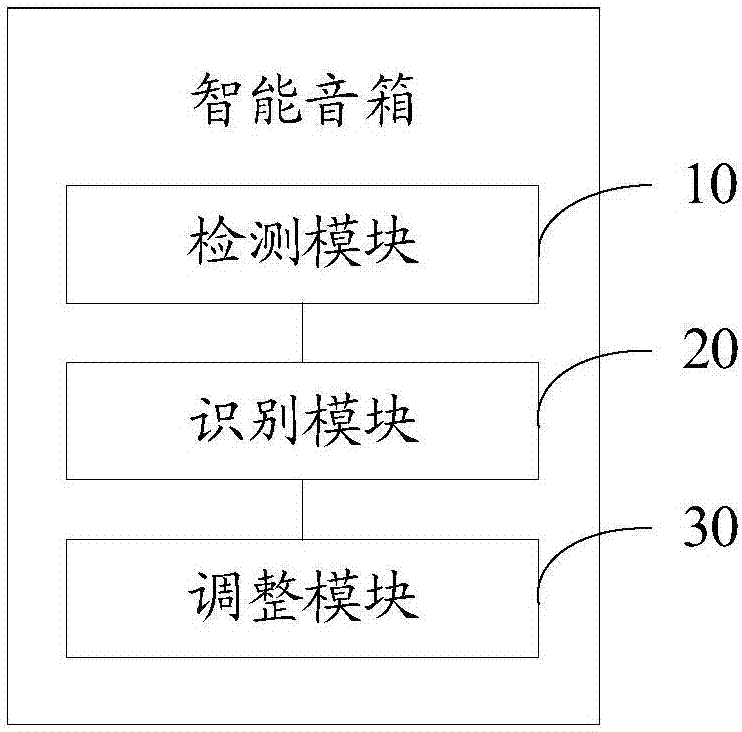
参照图2,本发明实施例还提出了一种智能音箱,包括:
检测模块10,用于进行人体检测;
识别模块20,用于当检测到人体时,识别所述人体的手势动作;
调整模块30,用于根据所述手势动作调节所述智能音箱的播放状态。
本实施例中,智能音箱上安装有深度传感器。深度传感器分为两类:被动式立体相机和主动式深度相机。被动式立体相机利用两个或更多个相机来观察场景,并且使用这些相机的多个视图中特征之间的差异(移位)来估计场景的深度。主动式深度相机向场景投射不可见的红外光,并且根据被反射的信息,估计场景的深度。在一应用场景中,用户甲站在与智能音箱一定位置,向智能音箱的深度传感器作出一些手势指令,如开启播放指令,智能音箱识别出用户甲手势指令的含义后,播放声音。
检测模块10中,智能音箱通过深度传感器进行人体检测。可以基于梯度方向直方图(histogramoforientedgradient,hog)、尺度不变特征转换(scale-invariantfeaturetransform,sift)、局部二值模式(localbinarypattern,lbp)、harr等图像特征进行人体检测。
识别模块20中,当智能音箱检测到人体时,识别该人体的手势动作。具体是通过深度传感器获取一组包含手势的视频数据。在此处深度传感器起到录影的作用。可按预设的规则来获取视频数据。如,当深度传感器监测到用户有较大的手势动作时,将该段视频数据确定为包含手势的视频数据。
将上述视频数据解析为多帧连续的图像,将图像中的背景与手势分离,并找出每帧图像中的手势轮廓。按预设的规则确定手势动作的起始帧和结束帧。将起始帧与结束帧之间的手势轮廓确定为手势动作。也就是说,手势动作包括多帧图像的手势轮廓。
调整模块30中,获得手势动作之后,对手势动作进行特征提取,获得手势动作特征,对手势动作特征进行识别,获得识别结果,最后根据识别结果生成控制指令。
智能音箱根据控制指令调节播放状态。如获得的控制指令为开始播放指令,则智能音箱开始播放声音;若获得的控制指令为停止播放指令,则智能音箱停止播放声音。
可选的,识别模块20包括:
分离单元,用于将检测到的人体的每帧手势图像的手势与背景进行分离,并找出每帧手势图像中的手势轮廓;
开始手势单元,用于将所述手势轮廓逐帧与预设开始手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为开始手势轮廓;
结束手势单元,用于将时序在所述开始手势轮廓之后的手势轮廓逐帧与预设结束手势轮廓进行匹配,将匹配到的第一个手势轮廓确定为结束手势轮廓;
手势动作单元,用于将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势动作确定为识别到的一组手势动作。
本实施例中,智能音箱存储有不同控制指令对应的预设开始手势轮廓和预设结束手势轮廓。视频数据的各个手势轮廓先逐帧与预设开始手势轮廓进行匹配,将匹配的第一帧手势轮廓确定为开始手势轮廓。在第一帧以后的手势轮廓,逐帧与预设结束手势轮廓进行匹配,将匹配的第一帧手势轮廓确定为结束手势轮廓。然后,将以所述开始手势轮廓为起始,所述结束手势轮廓为结尾的手势轮廓序列确定为手势动作。获得的手势动作可用来识别手势包含的含义,进而生成相应的控制指令。
可选的,调整模块30包括:
确定指令单元,用于确定所述手势动作对应的控制指令;
调整单元,用于根据所述控制指令调节所述智能音箱的播放状态。
本实施例中,智能音箱上存储芯片预存了多组不同手势动作对应的控制指令。例如可以规定,手势动作“往上一挥”对应“提升音量”指令,手势动作“往下一挥”对应“降低音量”指令,手势动作“摆手”对应“停止播放”指令,手势动作“双手轻拍”对应“开始播放”指令。当智能音箱确定用户做出的手势动作对应的开始播放指令,则智能音箱会按照开始播放指令进行播放。播放的内容可以是音乐,也可以是新闻。同样的,当智能音箱确定用户做出的手势动作对应的结束播放指令,则智能音箱会按照结束播放指令停止播放声音内容。用户可以免受停止播放前的声音内容的干扰。
可选的,所述确定指令单元包括:
获取特征子单元,用于特征对所述手势动作进行特征提取,获得手势动作特征;
编码子单元,用于对所述手势动作特征进行编码,获得编码结果;
确定指令子单元,用于确定所述编码结果对应的控制指令。
本实施例中,手势动作特征是每帧图像轮廓特征的序列集合。为了获得手势动作特征,需要计算每帧图像的每个轮廓的特征值。具体而言,将提取得到的手势轮廓,计算该手势轮廓中每个轮廓的轮廓特征值。每个轮廓的轮廓特征值包括每个轮廓的区域直方图、矩和地球移动距离。
然后,要对提取的手势动作特征采用8个基准方向向量进行编码,计算编码结果。8个基准方向指的是360度平分的八个方向。
可以使用dtw算法来计算编码结果。在dtw算法中,已存入模板库的各个手势成为样本模板,一个样本模板表示为{t(1),t(2),...,t{m},...,t{m}}。所要识别的一个输入手势为测试模板,表示为{s(1),s(2),...s(n),...,s(n)}。将测试模板的各帧号m=1-m在纵轴上标出,通过这些表示帧号的坐标画出纵线即可形成一个个网格,网格中的每一个交叉点(n,m)表示测试模板中某一帧与训练模式中某一帧的交汇点。
dtw算法可以归结为寻找一条通过此网格中若干格点的路径.为了描述这条路径,假设路径通过的所有格点依次为(n1,m1),...,(ni,mi),..,(nn=mn),其中(n1,m1)=(1,1),(nn,mn)=(n,m).路径可以用函数mi=f(ni),其中ni=i,i=1,2,...,n,f(1)=1,f(n)=m。为了使路径不至于过分倾斜,可将倾斜约束在0-2范围内,如果路径通过格点(ni,mi),那么其前一个节点只可能是下列三种情况之一:(ni-1,mi),(ni-1,mi-1)或(ni-1,mi-2)。路径的累积距离d[(ni,mi)]=d[s(ni),t(mi)+d((ni-1,mi-1))],其中(ni-1,mi-1)由下式决定:
d[(ni-1,mi-1)]=min{d[ni-1,mi],d[(ni-1,mi-1)],d[(ni-1,mi-2)]}。
最后,确定编码结果对应的控制指令。获得的编码结果与预设编码数据比较,输出最接近的预设编码数据对应的控制指令。为了减少错误检测率,还可以设置接近度阈值,若获得的编码结果与预设编码数据的匹配度太低,则不输出控制指令。
可选的,智能音箱还包括:
距离计算模块,用于计算所述智能音箱与所述人体之间的物理距离;
调整音量模块,用于根据所述物理距离调整所述智能音箱的音量。
本实施例中,可以通过主动式深度相机直接计算出智能音箱与用户之间的距离,然后根据用户与智能音箱的距离调节音量。例如,用户离智能音箱5米时,听到的音量为50分贝,离智能音箱10米时,为了使用户听到的音量等于50分贝,需提高智能音箱的音量。由于在室内,距离与音量成一定的对应关系,可以根据对应关系调节智能音箱的音量,使得用户在不同地点听到的音量是一样的。此处的预设值可以是5米处用户听到的音量,也可以是厂商预设的一个物理距离的音量。
可选的,所述检测模块10包括:
梯度检测单元,用于基于梯度方向直方图进行人体检测。
本实施例中,智能音箱可以基于梯度方向直方图(histogramoforientedgradient,hog)进行人体检测。
梯度方向直方图是类似于尺度不变特征转换的一种局域描述符,它通过计算局部区域上的梯度方向直方图来构成人体特征。与尺度不变特征转换不同的是,尺度不变特征转换是基于关键点的特征提取,是一种稀疏描述方法,而梯度方向直方图是密集的描述方法。
梯度方向直方图描述方法具有以下优点:梯度方向直方图表示的是边缘(梯度)的结构特征,因此可以描述局部的形状信息;位置和方向空间的量化,在一定程度上可以抑制平移和旋转带来的影响;同时采取在局部区域的归一化,可以部分抵消光照带来的影响。故本发明实施例优选基于梯度方向直方图进行人体检测。
可选的,所述梯度检测单元包括:
一阶梯度计算子单元,用于对检测窗口内的图像进行一阶梯度计算;
单元格梯度子单元,用于计算所述图像中各个单元格的梯度方向直方图;
块梯度子单元,用于对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图;
生成特征向量子单元,用于对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。
本实施例中,首先对检测窗口内的图像进行一阶梯度计算,具体为:将规范化大小(如64x128)的检测窗口(detectionwindow)作为输入,通过一阶(一维)sobel算子[-1,0,1]计算检测窗口内的图像水平和垂直方向上的梯度。
采用单一窗口作为分类器输入的好处是分类器对目标的位置与尺度具有不变性。对于一个待检测的输入图像来说,需要沿着水平和垂直方向移动检测窗口,同时要以多尺度对图像进行缩放以检测不同尺度下的人体。
然后,计算所述图像中各个单元格的梯度方向直方图,具体为:梯度方向直方图是在被称为单元格(cell)和块(block)的网格内进行密集计算得到的。将图像分成若干单元格,每个单元格由多个像素构成,而块则是由若干相邻的单元格组成。
在此实施例中,先计算图像内每个像素的梯度,再统计出图像内每个单元格中所有像素的梯度方向直方图,即该单元格的梯度方向直方图。在统计各个单元格的梯度方向直方图时,首先针对每个单元格将[0~π]划分为多个区间,然后根据该单元格内各像素的梯度方向进行加权投票计算,得到该单元格中所有像素的梯度方向直方图。
在进行加权投票计算时,每个像素的权重为优选为该像素的梯度幅度。为了消除混淆,优选采用三线性差值(trilinearinterpolationi)进行加权投票计算。
遍历图像中的每个单元格,得到图像中各个单元格的梯度方向直方图。
对所述图像中每个块内的所有单元格进行归一化处理,得到所述块的梯度方向直方图。在块内,对该块内的单元格的梯度方向直方图进行归一化处理,以消除光照的影响,从而得到该块的梯度方向直方图。遍历图像中的每个块,得到图像中每个块的梯度方向直方图。
对所述图像内的所有块进行归一化处理,得到所述检测窗口的梯度方向直方图,并将所述检测窗口的梯度方向直方图作为人体特征向量。由各块归一化后得到的检测窗口的梯度方向直方图,构成人体特征向量,从而实现人体检测。
由于梯度方向直方图是一种密集计算方式,因此计算量较大。为了减小计算量,提高检测速度,可以考虑选择在有较明显的人体轮廓的重点区域计算梯度方向直方图,从而达到降低维数的目的。
本发明提供了一种智能音箱,智能音箱进行人体检测;当检测到人体时,识别所述人体的手势动作;根据所述手势动作调节所述智能音箱的播放状态。本发明提供的智能音箱增加一种使用智能音箱的交互方式,使得用户可以通过手势对智能音箱进行控制,提高了用户体验。
本发明还提出了一种智能音箱,包括存储器、处理器和至少一个被存储在所述存储器中并被配置为由所述处理器执行的应用程序,所述应用程序被配置为用于执行上述的播放控制方法。
在本发明实施例中,该智能音箱所包括的处理器还具有以下功能:
进行人体检测;
当检测到人体时,识别所述人体的手势动作;
根据所述手势动作调节所述智能音箱的播放状态。以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!