一种基于浏览器的音频/视频直播方法及其系统与流程
本发明涉及流媒体技术领域,尤其涉及一种基于浏览器的音频/视频直播方法及其系统。
背景技术:
目前,网络直播是利用互联网及流媒体技术进行直播,主播用户客户端通过采集摄像头的数据,并将数据进行视频编码,将编码的视频推流送到直播平台的cdn服务器,其他观众则会从cdn服务器拉取视频流进行观看。
对于每一位主播用户,使用时均需要使用特定的客户端系统进行登录,相应的也需要用户设备具备一定的运算能力。
在实际中,往往存在多命令实现直播的繁琐过程,并且也需要主播用户进行诸多流程操作。
技术实现要素:
本发明的目的,是解决主播用户在更换设备等操作之后需要重新多步骤添加客户端的困扰。提供一种基于浏览器的音频/视频直播方法及其系统,技术方案如下:
一方面,提供了一种基于浏览器的音频/视频直播方法,其特征在于,包括以下步骤:
建立与用户设备上的浏览器之间的本地socket通信;
对用户设备所装载的实体摄像头和用户设备上所安装的虚拟摄像头按照浏览器传来的具体图像参数进行图像捕获,并将捕获到的图像根据图像帧加入到图像帧队列;
将捕捉到的图像统一转换成yuv420p格式;
按照浏览器传来的图像编码参数对yuv420p格式图像进行h264编码;
按照浏览器传来的音频捕获参数调用windowscoreapi对用户设备所装载的麦克风设备进行音频采集,对采集到的音频样本按预设要求进行重采样并转换为指定的采样率和通道数,进而加入到音频帧队列;
对音频帧队列中的音频帧里的音频数据进行声音特征分析;
按照浏览器传来的音频编码参数对音频进行aac编码或是mp3编码;
丢弃超时的音频帧,保证音频帧与图像帧同步,进而将同步后的音频帧与图像帧按rtmp协议进行打包和发送。
实时检测音频/视频直播方法过程中是否被意外终止;如果是,将其自动启动,并且添加开机自动启动功能。
优选地,图像捕获和音频采集同时进行;并将同步的音频帧于图像帧按照标准mp4文件格式保存mp4文件至用户设备上。
优选地,图像帧加入图像帧队列过程中,使用clsid_nullrenderer类型图像渲染过滤器以避免用户设备内没有相应的转码过滤器而造成的连接捕获源过滤器和图像渲染过滤器时失败;
优选地,利用directshow进行图像捕获时,isamplegrabber图像回调接口在调用setmediatype设置图像格式失败时,主动尝试更换为其他图像格式。
优选地,声音特征分析用以区分当前声音是说话模式还是唱歌模式;根据音频数据的波形与预设阈值的关系进行判断。
优选地,打包和发送过程中,当网络发生丢包,根据预设阈值划分网络环境状态,重新设定h264参数以适配不同网络环境。
另一方面,一种基于浏览器的音频/视频直播系统,其特征在于,包括:
通讯模块,用于建立与用户设备上的浏览器之间的本地socket通信;
图像采集模块,用于对用户设备所装载的实体摄像头和用户设备上所安装的虚拟摄像头按照浏览器传来的具体图像参数进行图像捕获,并将捕获到的图像根据图像帧加入到图像帧队列;
图像处理模块,用于将捕捉到的图像统一转换成yuv420p格式;
图像编码模块,用于按照浏览器传来的图像编码参数对yuv420p格式图像进行h264编码;
音频采集模块,用于按照浏览器传来的音频捕获参数调用windowscoreapi对用户设备所装载的麦克风设备进行音频采集,对采集到的音频样本按预设要求进行重采样并转换为指定的采样率和通道数,进而加入到音频帧队列;
音频处理模块,用于对音频帧队列中的音频帧里的音频数据进行声音特征分析;
音视编码模块,用于按照浏览器传来的音频编码参数对音频进行aac编码或是mp3编码;
音频/视频同步模块,用于丢弃超时的音频帧,保证音频帧与图像帧同步;
推流模块,用于将同步后的音频/视频按rtmp协议进行打包和发送。
监控模块,用于实时检测音频/视频直播系统工作过程中是否被意外终止;如果是,将其自动启动,并且添加开机自动启动功能。
优选地,图像采集模块和音频采集模块同时工作;并将同步的音频帧于图像帧按照标准mp4文件格式保存mp4文件至用户设备上。
优选地,图像帧加入图像帧队列过程中,使用clsid_nullrenderer类型图像渲染过滤器以避免用户设备内没有相应的转码过滤器而造成的连接捕获源过滤器和图像渲染过滤器时失败。
优选地,利用directshow进行图像捕获时,isamplegrabber图像回调接口在调用setmediatype设置图像格式失败时,主动尝试更换为其他图像格式。
优选地,声音特征分析用以区分当前声音是说话模式还是唱歌模式;根据音频数据的波形与预设阈值的关系进行判断。
优选地,打包和发送过程中,当网络发生丢包,根据预设阈值划分网络环境状态,重新设定h264参数以适配不同网络环境。
本发明的有益效果在于:区别于目前常规的音频/视频直播方法及其系统,采用了基于浏览器的插件策略。一键安装之后可以非常方便地在后台自启动并且会准备地相应来自浏览器的开始推流、停止推流、切换cdn、报告当前状态、断网重连指令,内部模块自动协同工作,真正做到一条命令实现直播的需要。
附图说明
图1为本发明实施例提供的一种基于浏览器的音频/视频直播方法流程示意图。
图2为本发明实施例提供的一种基于浏览器的音频/视频直播系统结构示意图。
图3为本发明实施例提供的一种音频处理方法的流程示意图。
具体实施方式
下面通过实施例,对本发明的技术方案做进一步的详细描述。
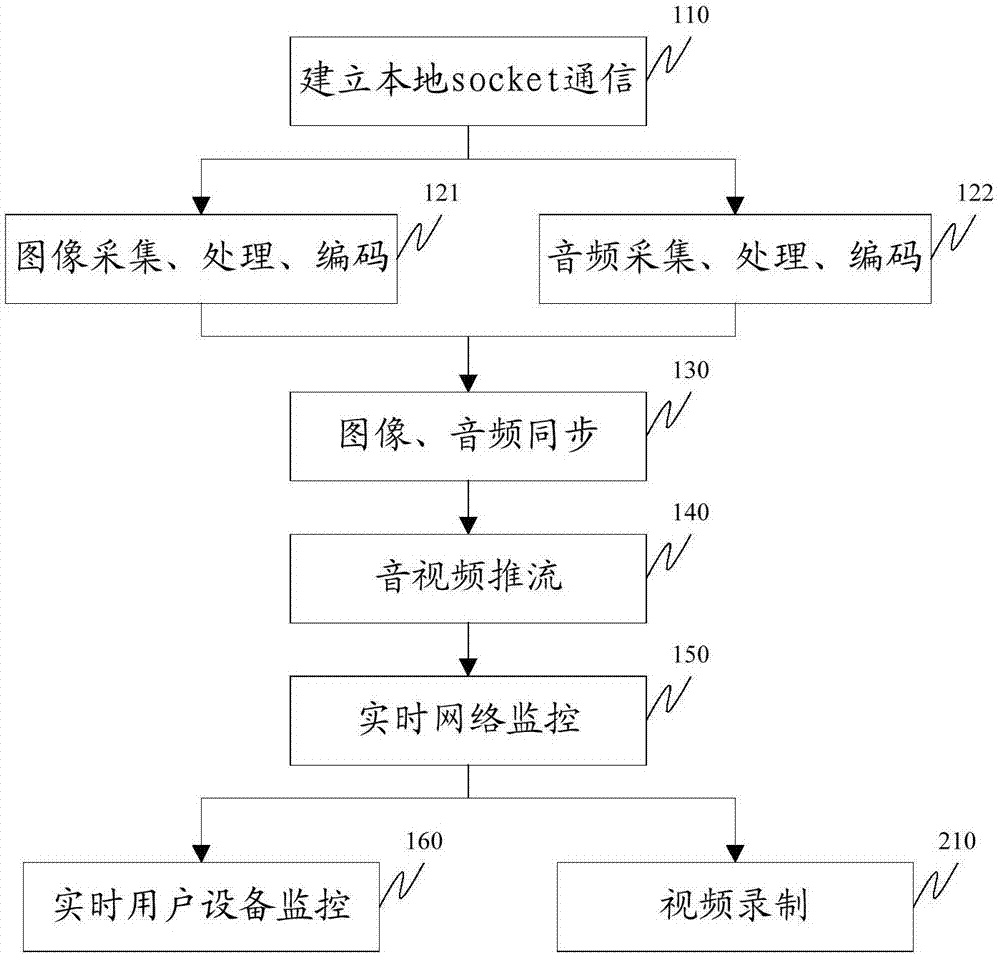
图1为基于浏览器的音频/视频直播方法流程图。如图1所示,该方法包括以下步骤:
步骤110,安装于用户设备上的软件,利用tcp方式建立与浏览器之间的本地socket通信;
步骤121,对用户设备所装载的实体摄像头和用户设备上所安装的虚拟摄像头按照浏览器传来的具体图像参数进行图像捕获,并将捕获到的图像根据图像帧加入到图像帧队列;图像帧加入图像帧队列过程中,使用图像渲染过滤器以避免用户设备内没有相应的转码过滤器而造成的连接捕获源过滤器和图像渲染过滤器时失败;图像帧加入图像帧队列过程中使用的图像渲染过滤器为clsid_nullrenderer类型的图像渲染过滤器;利用directshow进行图像捕获时,isamplegrabber图像回调接口在调用setmediatype设置图像格式失败时,主动尝试更换为其他图像格式;将捕捉到的图像统一转换成yuv420p格式;按照浏览器传来的图像编码参数对yuv420p格式图像进行h264编码。
图3为音频处理方法的流程图。如图3所示,该方法包括以下步骤:
步骤310,用adobeaudition软件打开音频文件,将时间粒度调节到预设时间范围,如5ms左右,观察波形特征。
步骤320,监测声音的音频文件波形,计算预设时间范围内的声音平均分贝值;
歌曲的音频文件波形是连续的,说话的音频文件波形是会出现波形隔断的,这意味着我们可以用20*log(valofinputaudiosample)计算一小段时间内(例如5ms)的声音平均分贝值去反映声音能量的大小,当声音能量小于预设声音平均分贝阈值(例如-50db)时,获得一个声音间隔;
当一段时间(例如5s)内统计的声音间隔次数超过一定次数(例如150次)时,确定声音为说话模式;
或监测声音的音频文件波形,计算预设时间范围内的声音平均分贝值;
相邻时间段(例如5ms)唱歌时的声音波形是比较平滑的,在相邻时间段(例如5ms)说话时波形起伏是很大的,当一段时间(例如5s)内统计的时间相邻一小段时间声音能量的比值超过一个阈值(例如3)的次数(例如100)时,确定声音为说话模式。
步骤330,根据以上两点结合,说话模式的概率通过以下公式表示:p=w1p1+w2p2;
其中,p为说话模式概率,p1为时间间隔次数影响的说话模式概率,w1为p1所占权重(例如0.5),p2为声音能量比值超过阈值次数影响的说话模式概率,w2为p2所占权重(例如0.5)。
步骤340,预设p0为预设说话模式概率阈值(例如0.5),比较p与p0的关系,判断当前是说话模式,还是唱歌模式。
步骤122,按照浏览器传来的音频捕获参数调用windowscoreapi对用户设备所装载的麦克风设备进行音频采集,对采集到的音频样本按预设要求进行重采样并转换为指定的采样率和通道数,进而加入到音频帧队列;对音频帧队列中的音频帧里的音频数据进行声音特征分析;声音特征分析用以区分当前声音是说话模式还是唱歌模式;根据音频数据的波形与预设阈值的关系进行判断;按照浏览器传来的音频编码参数对音频进行aac编码或是mp3编码;
步骤121于步骤122同时进行;
步骤130,丢弃超时的音频帧,保证音频帧与图像帧同步;
步骤140,将同步后的音频帧与图像帧按rtmp协议进行打包和发送;
步骤150,打包和发送过程中,当网络发生丢包,根据预设阈值划分网络环境状态,重新设定h264参数以适配不同网络环境;
步骤160,实时检测音频/视频直播方法过程中是否被意外终止;如果是,将其自动启动,并且添加开机自动启动功能;
步骤210,并将同步的音频帧于图像帧按照标准mp4文件格式保存mp4文件至用户设备上。
本发明实施例采用了基于浏览器的插件策略。一键安装之后可以非常方便地在后台自启动并且会准备地相应来自浏览器的开始推流、停止推流、切换cdn、报告当前状态、断网重连指令,内部模块自动协同工作,真正做到一条命令实现直播的需要。
相应地,本发明实施例还提供了一种基于浏览器的音频/视频直播系统。图2为本发明实施例提供的一种基于浏览器的音频/视频直播系统结构示意图。如图2所示,该系统包括:
通讯模块10,利用tcp方式建立与用户设备上的浏览器之间的本地socket通信,接收浏览器开始推流、停止推流、切换cdn、报告当前状态、断网重连指令而启用相应功能模块;
图像采集模块21,利用directshow对用户设备所装载的实体摄像头和用户设备上所安装的虚拟摄像头按照浏览器传来的具体图像参数进行图像捕获,并将捕获到的图像根据图像帧加入到图像帧队列,其中在创建图表的过程中使用clsid_nullrenderer类型的图像渲染过滤器以避免用户设备内没有相应的转码过滤器而造成的连接捕获源过滤器和图像渲染过滤器时失败,isamplegrabber图像回调接口在调用setmediatype设置图像格式失败时,主动尝试更换为其他图像格式;
图像处理模块22,用于将图像采集模块20捕捉到的图像统一转换成yuv420p格式;
图像编码模块23,用于按照浏览器传来的图像编码参数对yuv420p格式图像进行h264编码;
音频采集模块31,用于按照浏览器传来的音频捕获参数调用windowscoreapi对用户设备所装载的麦克风设备进行音频采集,对采集到的音频样本按预设要求进行重采样并转换为指定的采样率和通道数,进而加入到音频帧队列;
音频处理模块32,用于对音频帧队列中的音频帧里的音频数据进行声音特征分析,声音特征分析用以区分当前声音是说话模式还是唱歌模式;根据音频数据的波形与预设阈值的关系进行判断;
具体地,用adobeaudition软件打开音频文件,将时间粒度调节到预设时间范围,如5ms左右,观察波形。监测声音的音频文件波形,计算预设时间范围内的声音平均分贝值;歌曲的音频文件波形是连续的,说话的音频文件波形是会出现波形隔断的,这意味着我们可以用20*log(valofinputaudiosample)计算一小段时间内(例如5ms)的声音平均分贝值去反映声音能量的大小,当声音能量小于预设声音平均分贝阈值(例如-50db)时,获得一个声音间隔;当一段时间(例如5s)内统计的声音间隔次数超过一定次数(例如150次)时,确定声音为说话模式;或监测声音的音频文件波形,计算预设时间范围内的声音平均分贝值;相邻时间段(例如5ms)唱歌时的声音波形是比较平滑的,在相邻时间段(例如5ms)说话时波形起伏是很大的,当一段时间(例如5s)内统计的时间相邻一小段时间声音能量的比值超过一个阈值(例如3)的次数(例如100)时,确定声音为说话模式。根据以上两点结合,说话模式的概率通过以下公式表示:p=w1p1+w2p2;其中,p为说话模式概率,p1为时间间隔次数影响的说话模式概率,w1为p1所占权重(例如0.5),p2为声音能量比值超过阈值次数影响的说话模式概率,w2为p2所占权重(例如0.5)。预设p0为预设说话模式概率阈值(例如0.5),比较p与p0的关系,判断当前是说话模式,还是唱歌模式。
音视编码模块33,用于按照浏览器传来的音频编码参数对音频进行aac编码或是mp3编码;
音频/视频同步模块40,用于丢弃超时的音频帧,保证音频帧与图像帧同步;
推流模块50,用于将同步后的音频/视频按rtmp协议进行打包和发送。
监控模块60,用于实时检测所述音频/视频直播系统工作过程中是否被意外终止;如果是,将其自动启动,并且添加开机自动启动功能。
网络监控模块70,打包和发送过程中,当网络发生丢包,根据预设阈值划分网络环境状态,重新设定h264参数以适配不同网络环境;
在rtmp发送数据包循环线程中从待发送的音视频数据队列中判断队列头与队列尾时间戳的差值,该值可反应待发送数据包的积压情况,当该值超过一个阈值(例如500ms)时可以从队列中丢弃与队列尾时间差超过该阈值的数据包,同时计下丢弃数据包的个数,当一段时间内(例如20s)丢包数≤n1时认为网络状况极好,当n1<丢包数≤n2时认为网络状况一般,当n2≤丢包数时认为网络状况很差,根据不同网络状况重新设置x264_param_t.rc.i_rc_method,当网络良好由好到差时可以分别设置为x264_rc_cqp、x264_rc_crf、x264_rc_abr;x264_param_t.rc.i_bitrate、x264_param_t.rc.i_vbv_max_bitrate、x264_param_t.rc.i_vbv_buffer_size也可依次降低;x264_param_t.rc.i_keyint_max可以依次增大。
视频保存模块80,并将同步的音频帧于图像帧按照标准mp4文件格式保存mp4文件至用户设备上。
本发明实施例采用了基于浏览器的插件策略。一键安装之后可以非常方便地在后台自启动并且会准备地相应来自浏览器的开始推流、停止推流、切换cdn、报告当前状态、断网重连指令,内部模块自动协同工作,真正做到一条命令实现直播的需要。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!