一种提高无标度网络传输容量的局部信息动态路由算法的制作方法
本发明属于复杂网络中路由算法和拥塞控制领域,涉及一种不用预知整个网络的拓扑结构而只需要知道网络中局部信息的动态路由算法来提高网络的传输容量的路由算法。
背景技术:
复杂网络已经被证实大量存在于现实网络中,比如因特网,万维网,ip网络,道路交通网以及人际关系网等。其中基于复杂网络理论和方法研究网络的交通动力学特性也成为了这门学科的研究热点。针对复杂网络交通动力学的研究领域,网络资源的有效分配和拥塞现象如今越来越受到学者的关注,尤其是现在网络规模的不断扩大,人们对网络的传输要求越来越高。实际网络中,以互联网为例,由于网络的拓扑规模的不断壮大以及数据包的过载导致网络出现拥塞,降低了网络的传输能力。因此,针对如何有效控制网络的拥塞,保证信息在系统中处于自由畅通状态,提高网络的容量的研究具有重大的现实意义。
以最短路径路由算法为例文献[1-2],考虑到中心节点具有更大的可能连接到目的节点,因此最短路径的路由都会选择走这些中心节点,极易导致数据包在这些中心节点处越积越多,导致网络拥塞,严重降低了网络的传输容量。由于最短路径路由算法是基于全局信息的,现实生活中,尤其是规模庞大的互联网,随着互联网网络规模的不断扩大,基于全局信息的路由算法已经不能满足现在网络的需求,于是有学者提出了基于局部信息的路由策略。文献[3]wxwang,cyyin研究了基于局部信息的近邻搜索策略,目的是让数据包绕开度值大的节点而游走度值较小的节点,避免了数据包的过早拥塞。wxwang,cyyin等在文献[4]提出了一种结合局部静态和动态信息的路由策略,同时考虑了节点的度和数据包队列长度,但是搜索范围只局限在邻居节点处,且路由算法偏好游走度值较大的节点。
[1]tadicb,thurners,rodgersgj.trafficoncomplexnetworks:towardsunderstandingglobalstatisticalpropertiesfrommicroscopicdensityfluctuations.[j].physicalreviewestatisticalnonlinear&softmatterphysics,2004,69(3pt2):036102.
[2]mukherjeeg,mannass.phasetransitioninadirectedtrafficflownetwork[j].phys.rev.e,2005,71(2):066108.
[3]wangwx,wangbh,yincy,etal.trafficdynamicsbasedonlocalroutingprotocolonascale-freenetwork.[j].physicalreviewestatisticalnonlinear&softmatterphysics,2006,73(2):026111.
[4]wangwx,yincy,yang,etal.integratinglocalstaticanddynamicinformationforroutingtraffic[j].physicalreviewestatisticalnonlinear&softmatterphysics,2006,74(2):016101。
技术实现要素:
本发明的目的是针对现有技术不足提出的一种基于局部信息的动态路由算法来提高网络的吞吐量缓解网络的拥塞。
实现本发明目的的具体技术方案是:
一种提高无标度网络传输容量的局部信息动态路由算法,该方法包括以下具体步骤:
步骤1:具有无标度特性的网络模型的构建
(a).增长性:从一个具有m0个节点的全连通网络开始,其中全连通网络表示这m0个节点两两相连;初始网络为这m0个节点组成的全连通网络,每次添加一个新的节点并且该新加入的节点连接到m个已存在的节点上,这里m<=m0;
(b).优先连接:一个新加入的节点和网络已经存在的节点i相连接的概率pi与节点i的度值ki遵循如下优先连接性:
结果t步后,网络的规模为n=t+m0,网络的总边数m=mt+m0,其中m0表示网络的初始连边数,网络的节点度分布服从幂率分布,即p(k)~k-γ,其中p(k)为网络节点的度分布,γ为幂指数;因此这种网络也叫无标度网络,无标度网络的特征表现为网络的异质性,即网络中大多数节点只有少数几条连边,而少部分中心节点占据了大量的连边;
步骤2:基于次近邻节点信息的动态路由算法
网络生成后,数据包流量将会在给定的网络上生成,数据包在网络传输的具体流量模型如下:
(i).每个时间步,网络随机生成r个数据包,这r个数据包的源节点和目的节点随机生成,数据包在节点处遵循fifo原则,每个节点的功能具有转发和接受数据包的能力;
(ii).每个时间步,节点至多投递c个数据包,称c为节点处理能力;
(iii).当前节点遍历与它直接相连的所有邻居节点,如果邻居节点中有目的节点,则直接将数据包传递给目的节点,同时删除该数据包,数据包投递成功;如果邻居节点中找不到目的节点,则执行第(iv)步;
(iv).将搜索范围扩大,遍历该节点的所有邻居节点的邻居节点,这些节点的集合称为该节点的次近邻节点,若该节点没有次近邻节点,则依据路由转发概率公式(2)将数据包传递到该节点的邻居节点处;若该节点有邻居节点,则执行第(v)步;
其中,ki为节点i的度值,ni为节点i的队列长度,α和β为两个可调参量;
(v).若目的节点在该节点的次近邻节点中,则数据包传递到与目的地相连的邻居节点,否则,执行第(vi)步;
(vi).目的节点不在该节点的次近邻节点中,依据路由转发概率公式(2)将数据包传递到该节点的邻居节点处;
步骤3:计算网络的传输容量
网络的传输容量计算用序参量计算,其计算公式如下:
其中,△w=w(t+△t)-w(t)表示从t+△t时刻网络增加的数据包数目,<△w>是对其取平均;r为网络中数据包的产生率;当η=0时,网络处于自由态,对应于r<rc,其中rc是网络的临界数据包产生率;当η>0时,网络处于拥塞态,r>rc,且η值越大,拥塞越显著;当η=1时,网络处于完全拥塞状态,数据包全部没有传输成功,rc为网络的传输容量。由此可见网络由自由态向拥塞态转变发生在r=rc处,因此rc为网络的传输容量。rc越大说明网络处理节点的能力越好,网络越不容易发生拥塞;而由于无标度网络的异质性,度值越大的节点流量负载越大,这些节点也越容易发生拥塞。
本发明的有益效果:
1.采用公式(2)的好处是不仅考虑了节点的度值信息,也考虑了节点的队列长度信息,这样数据包在传递的过程中综合考虑了这两种节点信息,数据包不仅绕开了负载繁重的hub节点,而且保证了那些数据包缓存队列长度较小的节点作为路由选址的下一跳,有效地均衡了网络的流量负载,提高网络的传输容量。
2.相对于文献[2],[3]提出来的局部信息的路由算法,基于节点次近邻信息的路由算法不仅可以获得该节点的邻居节点信息,还可以知道该节点的次近邻节点的信息,将搜索范围扩大,有效地避免了当数据包偏离目的节点而导致路由时间变长或者数据包丢失的情况。
附图说明
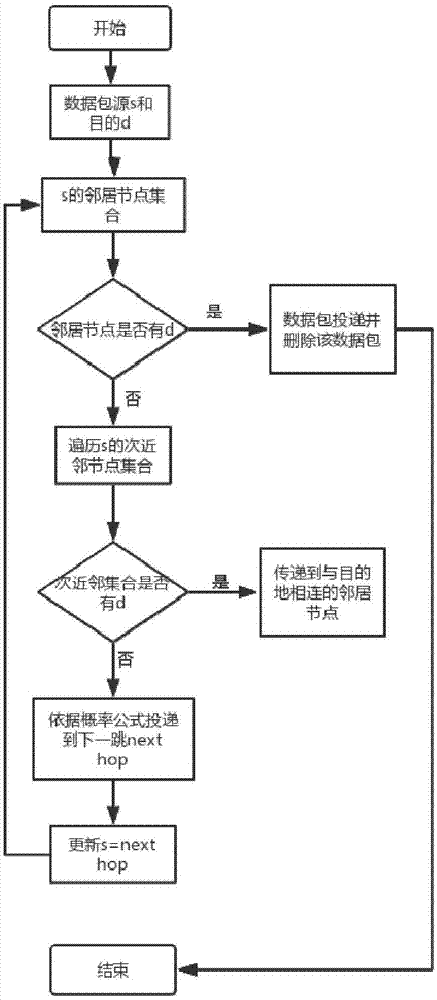
图1为本发明中步骤2数据包在网路传输的流程图;
图2为网络的近邻与次近邻关系示意图;
图3为在不同α与β参数下,有序参量η和数据包生产率r之间的关系图;
图4为不同α,β参数组合下传输容量的分布图;
图5为网络中的数据包数目w(t)随时间t的变化图;
图6为平均传输时间<t>随数据包生成率r的变化情况图;
图7为度值k与平均队列长度<len>的关系图;
图8为三种不同的局部路由算法序参量η的比较图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及发明优点更加清楚明白,以下结合
附图及实施例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅
用以解释本发明,并不用于限定本发明。
1.网络的表现形式
将一个具体网络抽象为一个有顶点集合v(vertextset)和边集合e(edgeset)构成网络g=(v,e),在计算机程序中,使用邻接矩阵(adjacencymatrix)表示一个网络;网络的邻接矩阵为行数和列数相同的方阵,具体地表现形式为:a=(aij)n×n,其中网络的规模即网络的顶点数为n,矩阵中的元素aij的值表示网络中节点i与节点j的连边状态,aij=0则表示节点i与j之间没有连边,反之则有连边;若aij>=1则表示为有权重的网络,边的权重值为具体的aij值;若aij=1则表示该网络为无权重的网络,即所有连边的权重都为1;若aij=aji,说明节点i与节点j之间没有方向性,这种网络称为无向网络;aij≠aji说明节点i到节点j的值不等于节点j到节点i的值,称这种网络为有向网;这里所使用网络为无向无权网络,邻接矩阵的元素值aij=aji且若节点i与j之间有连边则aij=1。邻接矩阵能反映网络的拓扑信息,本发明所说的网络都用邻接矩阵表示。
2.得到一个具有无标度特性的网络后,数据包流量将会在给定的网络上进行生成。数据包在网络中具体的流程结合图1由如下给出:
(i).每个时间步,网络随机生成r个数据包,这r个数据包的源节点和目的节点随机生成,数据包在节点处遵循fifo原则,每个节点的功能具有转发和接受数据包的能力;
(ii).每个时间步,节点至多投递c个数据包,称c为节点处理能力;
(iii).当前节点遍历与它直接相连的所有邻居节点,如果邻居节点中有目的节点,则直接将数据包传递给目的节点,同时删除该数据包,数据包投递成功;如果邻居节点中找不到目的节点,则执行第(iv)步;
(iv).将搜索范围扩大,遍历该节点的所有邻居节点的邻居节点,这些节点的集合称为该节点的次近邻节点,若该节点没有次近邻节点,则依据路由转发概率公式(2)将数据包传递到该节点的邻居节点处;若该节点有邻居节点,则执行第(v)步;
其中,ki为节点i的度值,ni为节点i的队列长度,α和β为两个可调参量;
(v).若目的节点在该节点的次近邻节点中,则数据包传递到与目的地相连的邻居节点,否则,执行第(vi)步;
(vi).目的节点不在该节点的次近邻节点中,依据路由转发概率公式(2)将数据包传递到该节点的邻居节点处。
3.为了得到网络的传输容量,使用序参量公式(3)来计算网络的传输容量;其计算公式如下:
其中,△w=w(t+△t)-w(t)表示从t+△t时刻网络增加的数据包数目,<△w>是对其取平均;r为网络中数据包的产生率;当η=0时,网络处于自由态,对应于r<rc,其中rc是网络的临界数据包产生率;当η>0时,网络处于拥塞态,r>rc,且η值越大,拥塞越显著;当η=1时,网络处于完全拥塞状态,数据包全部没有传输成功,rc为网络的传输容量。
4.二种评价该动态路由算法的性能指标及其计算方法
4.1数据包的平均传输时间是衡量一个路由算法效率的重要指标。
平均传输时间越长,表示数据包在网络中游历的时间越长。平均传输时间<t>的计算公式为:
其中n为指定时间内到达目的节点的数据包个数,ti表示数据包i在网络中生存的总时间,ti包含数据包i的游历时间和在缓存队列的等待时间。
4.2平均队列长度的分布情况。
平均队列长度的分布情况直观地反映了数据包避开度值大且队列长度长的节点,从而极大地提高网络的传输容量。
实施例
本发明是在无标度网上提出的一种基于次近邻节点信息的动态路由算法,简称drnnn算法,为了对该算法的运行结果进行测试,通过仿真分析了其重要的评价指标,也和两种传统的局部路由算法做对比,最后在真实网络数据中进行验证。
本实施例所有结果均是在8核,64位windows10操作系统,matlab2015b实验环境下获得的。网络的规模n为1000,程序运行一次总共1000步时间步,每个时间步内同时生成r个数据包(r也叫数据包生成率),每个数据包随机分配源节点和目的节点,在每个时间步每个节点处理能力c=10。
图2描绘了网络中的近邻与次近邻示意图,以node2为当前节点,则该节点的邻居节点为node1、node3、node4、node5,次近邻节点node6、node7、node8。
为了验证drnnn算法是否可行,图3仿真了在α与β不同取值情况下系统有序参量的变化情况。由图3可知当α与β参数其中只要有一个为正,网络的容量rc要远远低于α与β同时为负的情况。在α>0的情况下,度值大的节点往往是数据包路由的hub节点,根据路由转发概率可知,数据包会优先选择度值大的节点,这会使得数据包在这些节点处越积越多,导致网络进入拥塞状态;在β>0的情况下,数据包会优先选择那些队列长度较大的路由节点,从而使这些节点的队列长度越积越多,最终导致拥塞。且β对系统容量的影响程度要大于α对系统容量的影响;当α与β同时为负时,这是由于依据路由转发概率,数据包会优先选择度值较小且数据包队列长度也较小的节点作为转发下一跳,网络负载得到了均衡,系统容量也会显著性地提高。
图4是为了研究α为负时,β的变化对传输容量rc的影响。取α∈[-3,-2,-1],从图4中可以看出在给定的α下,传输容量rc随着β的变化而变化。无论α取何值,rc在β为-1.6的时候取得最大,且当α=-2下,rc要略大于其余两种情况。这里最佳参数组合取值为α=-2,β=-1.6。
图5是验证不同的数据包生产率r下(在最佳参数α=-2,β=-1.6的情况下),网络中数据包个数w(t)随t的变化情况,直线表示r<rc的变化情况,虚线表示r=rc的情况,点线表示r>rc的情况。从图中可以得到在r<=rc的情况下,网络中新产生的数据包个数与网络中被处理的数据包个数相等,网络中的数据包个数几乎不随时间的变化而变化,呈现一条水平线,系统处于自由态。而当r>rc的情况下,网络中前一个时刻产生的数据包还没来得及全部被处理掉,新产生的数据包又加入到网络中,这样使得网络中的数据包随着时间步的推移越积越多,w(t)随t呈线性增长,系统处于拥塞态,随着时间的增加,网络的拥塞状况越来越严重。
平均传输时间是定量刻画路由效率的一个重要指标。一个数据包在网络中的传输时间包含两部分:在队列的等待时间和在网络中的游历时间。为了说明本发明的路由效率,图6是数据包的平均传输时间<t>随r的变化情况。其中,平均传输时间<t>的计算依据公式(4)。由图可以看出,随着数据包生成率r的增加,数据包的平均传输时间<t>在自由态的时候是一条水平直线,且不超过10,数据包能很快地传输到目的节点,在拥塞态后<t>随着r呈现缓慢上升。这是由于数据包在路由选择的时候不会优先选择度值大的节点作为路由路径,这就缓解了中心节点的传输负载,通过选择那些度值较小且数据包队列长度较小的节点作为路由路径,这样数据包花在排队等待的时间也就降低了,路由算法的效率得到了提高。
为了验证数据包在网络中的分布情况,图7给出了在α=-2,β=-1.6的情况下平均队列长度<len>随节点度值k的变化图。从图中可以直观地看出节点度值较小处集中了大部分的数据包,而度值大的节点处,平均数据包队列长度较小。进一步说明了数据包在选取路由路径的时候优先考虑了队列长度较小并且度值也较小的节点,路由算法均衡了那些度值大的节点的负载。在r<=rc的情况下,即使网络中度值最大的节点,其平均队列长度较低,但是当r>rc的时候,网络中最大的度值节点的平均队列长度<len>超过了1000,这些度值大的节点的拥堵十分严重,说明在拥塞状态下,网络发生拥塞现象主要表现在这些度值大的中心节点处,随着网络中新的数据包不断地生成,这些中心节点的数据包也会越积越多,导致中心节点的平均队列长度十分巨大。
为了和文献[3],[4]提出的局部路由算法做比较,分别在模拟数据和实际数据做了对比实验。这里把文献[3]的路由算法叫为传统局部路由算法(traditionallocalrouting)记为tlr算法;文献[4]为局部动态路由算法(localdynamicrouting),简记为ldr算法。图8是本发明提出的drnnn路由算法与上述两种局部路由算法比较,其中文献[3]取最佳参数α=-1,文献[4]取最佳参数β=-3。图8(a)是在平均度<k>=4的ba网络上进行仿真实验,由仿真结果可知,本发明提出的drnnn路由算法,其网络的传输容量有所提高,rc达到55,较tlr算法提高了近2倍,较ldr算法提高了3倍。为了验证实际数据的传输容量,这里选取autonomoussystems(fromthebgp)的实际数据,其中包含2107个节点,4489条连边,网络平均度<k>≈3.7。其网络数据包生产率r与有序参量η的关系如图8(b)所示,从图中可以看出运用本章提出的drnnn算法,也能很好地应用在实际网络中。
本发明方案所公开的技术手段不仅限于上述实施方案所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!