一种基于大数据的网管数据互联系统的制作方法
本发明涉及一种数据互联系统,尤其涉及一种基于大数据的网管数据互联系统。
背景技术
省网络管理中心已初步形成了数据采集、共享、应用相互解耦的三层网管架构,涵盖了移动公司网络运行的主要数据,这些数据可以更加全面准确的描述业务运行状况,支撑业务运行发展。但目前各类网络数据源分散,如告警类数据在综合监控系统、资源数据在综合资源管理系统、故障工单/网络变更数据emos系统、投诉数据在客服ngcc系统、ps域信令数据在信令共享平台、2/3g语音数据在mvq系统、csfb/volte语音数据在语音信令监测平台。对外数据开放方式,也多是为满足特定专业的分析需求。
在现有技术架构下,网管数据有以下特点:1、数据分散在各网管系统,烟囱式单数据源对外共享;2、数据和接口格式不标准,数据使用方难以有效地关联分析;目前各网管系统仍以功能性场景服务为主,只能解决单一场景的问题,在数据的关联服务能力方面较弱,无法有效支撑面向用户的数据服务支撑能力。目前主要存在以下问题:1、在使用方层面,希望能将各类网管数据(告警,性能,资源,工单,工程,拓扑,拨测,投诉)进行集中管理、对地市共享,实现各类网管数据的集中互联、关联、清洗、共享,并希望实现网管数据和信令数据的关联,支持从网管数据到信令详情的追溯。2、从应用层面考虑,应用对于数据实时性要求越来越高,目前已有的系统无法满足应用的实时性要求;应用从多个系统获取数据成本较大,不利于上层应用敏捷开发,快速部署的诉求,与互联网新架构的发展趋势不相符。3、从数据层面考虑,多个系统形成数据孤岛,缺少统一的接入、清洗、建模的管理,需要统一的数据接入、统计的计算、统计的接口共享来打破数据孤岛;各自独立系统运维、管理面临很大难题,通过数据互联统一运维,提高资源利用率和处理效率;匹配互联网的发展趋势,数据统一互联形成大数据平台成为互联网主流选择。
本发明为解决以上缺点,运用大数据技术建设网管数据互联系统,对分散的网管数据进行互联、清洗、关联,并构建灵活统一的数据服务层,有效支撑上层应用,如智能研判、实时监控、地市共享、挖掘和关联分析等应用。
技术实现要素:
本发明要解决的技术问题是提供一种基于大数据的网管数据互联系统,解决当前专业业务系统无法数据分散和数据格式不统一的问题。
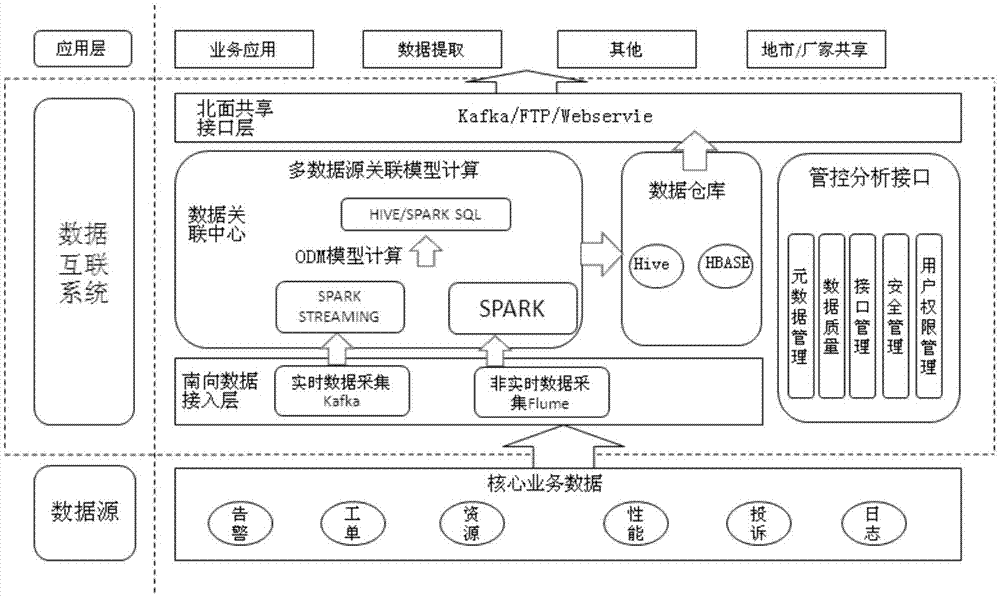
本发明为解决上述技术问题而采用的技术方案是提供一种基于大数据的网管数据互联系统,包括:南向数据接入层:用于接入各种实时性的网络数据和非实时性的网络数据;数据关联中心:用于对南向数据接入层接入的数据进行数据建模和模型输出,包括资源的oracle数据挖掘和多数据源关联;数据仓库:进行共享数据的统一存储;北向共享接口层:为分布式接口服务层,进行数据对外开放共享;管控分析接口:对互联系统进行可视化管理和控制。
进一步的,所述南向数据接入层对实时性要求高的网络数据通过kafka方式接入,对实时性无要求的网络数据通过flume方式接入。
进一步的,所述网络数据包括工单、网络变更、网络资源、网管性能、告警、拔测、用户投诉和其他网络数据。
进一步的,所述资源的oracle数据挖掘过程如下:加载资源数据后,采用sparkstreaming对南向接入的数据源以实时流的方式进行资源维度信息规范化处理,并回填资源信息,给多数据源关联提供统一标准的资源维度。
进一步的,所述多数据源关联,对资源的oracle数据挖掘后输出的各种数据源以资源维度为索引进行数据关联和汇聚,包括同最小维度关联、同网络类型关联、同数据量级关联和全字段关联。
进一步的,所述数据关联中心对资源信息的处理方式分为实时计算框架和离线计算框架,所述实时计算框架为sparksteaming,用于接入流式消息数据,并从消息队列kafka获取消息;所述离线计算框架为spark和hive,用于接入文件数据,并从hdfs获取输入数据。
进一步的,所述数据仓库存储的数据包括原始接入数据和关联后的融合模型数据,所述原始接入数据是指资源oracle数据挖掘后的原始接入数据,原始接入数据存储在hbase集群,关联后的融合模型数据存储在hive。
进一步的,所述北向共享接口层采用如下方式对外开放数据共享:实时获取hbase数据、异步获取hbase数据、异步获取即系查询数据、ftp定期获取数据或获取kafka实时数据。
进一步的,所述管控分析接口包括元数据管理、数据质量、接口管理、安全管理、用户权限管理。
本发明对比现有技术有如下的有益效果:本发明提供的基于大数据的网管数据互联系统,具有以下优点:区分不同的数据,采取不同的处理方法,不同数据源的相同数据可以进行互联,解决数据分散和数据格式不统一的问题;具有丰富的采集方式;提供统一的对外数据共享接口,使用时可以根据自身应用根据数据量大小、对数据时延要求和响应时延要求选择不同的数据接口。
附图说明
图1为本发明实施例中基于大数据的网管数据互联系统架构图;
图2为本发明实施例中基于大数据的网管数据互联系统实时数据流向图;
图3为本发明实施例中基于大数据的网管数据互联系统非实时数据流向图。
图中:
1数据采集2数据计算3数据存储
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图1为本发明实施例中基于大数据的网管数据互联系统架构图。
请参见图1,本发明提供的基于大数据的网管数据互联系统,包括南向数据接入层:各种网络数据的实时性接入和非实时性接入;数据关联中心:对南向数据接入层接入的数据进行数据建模和对数据模型化处理,包括资源信息的oracle数据挖掘化和多数据源关联;数据仓库:共享数据的统一存储;北向共享接口层:为分布式接口服务层,进行数据对外开放共享;管控分析门户:对互联系统进行可视化管理和控制。
南向数据接入层负责各种网络数据的接入,包括实时性接入和非实时性接入,实时性要求高的数据通过kafka方式接入,对实时性无要求的数据则通过flume方式接入。需接入的数据包括:工单:开通、故障、投诉;网络变更:工程割接、其他变更操作等;网络资源:2/3/4g基站信息、2/3/4g小区信息、bsc、rnc、sgsn、mme等网络资源信息;网管性能:从采集平台获取分支进行计算汇总,实时监控需求从采集平台直接送综合监控;告警:历史告警(补充了很多处理信息),实时告警(没有工单状态),综合监控目前没有实时的告警的对外共享接口,通过mq消息送到kafka总线,经过storm清洗后入hbase;拨测:基于探针拨测和仿真测试;用户投诉:批量投诉、广义投诉等;其他网络数据,如日志等,后续检视具体应用的数据需求再确定;无线专业的数据范围待后续结合地市需求和无优中心沟通后细化,比如投诉黑点、mr等。
数据关联中心是对南向接入数据进行数据建模、对数据模型化处理,主要分为资源信息的oracle数据挖掘和多数据源关联。所述资源的oracle数据挖掘过程如下:加载资源数据后,采用sparkstreaming对南向接入的数据源以实时流的方式进行资源维度信息规范化处理,并回填资源信息,给多数据源关联提供统一标准的资源维度。所述多数据源关联,所述多数据源关联,对资源的oracle数据挖掘后输出的各种数据源以资源维度为索引进行数据关联和汇聚,包括同最小维度关联、同网络类型关联、同数据量级关联和全字段关联;同最小维度关联,对最小维度级别相同的数据源进行关联;同网络类型关联,关联的数据源中只存在某种网络类型(2、3、4g)的,则根据网络类型维度分别关联输出模型;同数据量级关联,进行关联的数据源必须在同一数据量级,否则分开模型输出;全字段关联,关联的各数据源中维度外的字段全部输出到模型里。
数据关联中心对资源信息的处理方式分为实时计算框架和离线计算框架,所述实时计算框架为sparksteaming,用于接入流式消息数据,并从消息队列kafka获取消息;所述离线计算框架为spark和hive,用于接入文件数据,并从hdfs获取输入数据。
数据仓库负责共享数据的统一存储,包括资源信息的oracle数据挖掘化后的原始的接入数据和关联后的融合模型数据。资源信息的oracle数据挖掘化后的原始接入数据因其数据量大,存储在hbase集群以提供高速的海量数据查询响应。关联后的融合模型数据是对多数据源关联汇聚后的统计数据,存储在hive以提供灵活组合的高效查询。
北向共享接口层是一种分布式接口服务层,负责数据对外开放共享。外部系统可以通过以下方式获取数据。实时获取hbase数据:以restapi方式,对外发布get(url)接口,将查询条件封装在url?para1=xxx¶2=xxx,以json的格式返回查询数据;此方式主要用于查询结果集较小、实时性要求高的场景。异步获取hbase数据:以kafka+ftp方式,查询结果较大时使用此方式,将结果写入到文件中,然后上传到ftp服务器上,通过kafka返回如何获取文件的信息;此方式主要用于查询结果集较大、实时性要求低的场景。异步获取即系查询数据:以kafka+ftp方式,查询结果较大时使用此方式,将结果写入到文件中,然后上传到ftp服务器上,通过kafka返回如何获取文件的信息;此方式主要用于查询结果集较大、实时性要求低的场景。与异步获取hbase数据的差别是,异步获取hbase数据查询的是hbase数据,而异步获取即系查询数据查询的是hive数据。ftp定期获取数据:数据互联中心把使用方需要的数据(hbase、hive数据)上传至ftp,使用方定期扫描ftp服务器、发现有新文件则获取下来;考虑到多用户频繁扫描ftp服务器会增加服务器压力、目前未使用该方式。获取kafka实时数据。通过kafka接口,实时传输数据,使用方订阅相应topic即可获取所需数据;此方式主要用于对数据实时性要求极高的场景。
管控分析接口用于对互联系统进行可视化管理和控制,分以下子模块:元数据管理、数据质量、接口管理、安全管理和用户权限管理。元数据管理:对南向接入数据进行可视化管理;对资源数据的管理和对数据源的资源关联规则配置,包括了资源列表和资源关联规则两部分;提供在资源信息的oracle数据挖掘化和数据源关联以后以及最终共享给外部系统的模型数据视图;提供接入数据的数据流向图。数据质量:对互联中心的接入数据的完整性进行统计、给出缺失的文件;统计各模型的资源关联率、关联率低的模型及时告警。接口管理:管理南向数据接入的种类、接入方式、采集频率等信息;管理北向共享数据的种类、共享方式、时间粒度等信息。安全管理:对用户行为进行监控、对敏感数据进行脱敏等。用户权限管理:对每个访问互联中心的账号进行权限管理、按要求进行授权。
基于大数据的网管数据互联系统,数据流总体上分两类:实时数据流和非实时数据流。参见图2和图3可看出实时数据和非实时数据流向的区别。
综上所述,本发明提供的基于大数据的网管数据互联系统,解决数据分散和数据格式不统一的问题;具有丰富的采集方式,适配目前已有的各类数据采集方式,对实时性要求高的数据通过kafka方式接入,对实时性无要求的数据则通过flume方式接入;各类数据进行标准化处理,不同数据源的相同数据可以进行互联;提供统一的对外数据共享接口,具有实时流的kafka接口、精准查询hbase接口、数据分析hive接口和离线文件ftp接口,使用方可以根据自身应用根据数据量大小、对数据时延要求和响应时延要求选择不同的数据接口。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!