一种管理Hadoop命名空间的高可用方法与流程
本发明属于计算机应用和大数据处理平台技术领域,具体涉及一种管理hadoop命名空间的高可用方法。
背景技术:
在hadoop2.0之前,namenode只有一个,存在单点问题,虽然hadoop1.0有secondarynamenode、checkpointnode,buckcupnode这些设置,但是单点问题依然存在。在hadoop2.0中引入了高可用(highavailable,ha)机制。hadoop2.0的官方资料介绍了2种实现ha机制的方式,一种是nfs(networkfilesystem)方式,另外一种是qjm(quorumjournalmanager)方式。
hadoop2.0的ha机制中有两个namenode,一个是activenamenode,状态是active;另外一个是standbynamenode,状态是standby。两者的状态是可以切换的,但是在同一时间只能有一个namenode处于active状态。只有处于active状态的namenode能够提供对外的服务,处于standby状态的namenode是不对外服务的。activenamenode和standbynamenode之间通过nfs或者jn(journalnode,qjm方式)来同步数据。
activenamenode会把最近的操作记录写到本地的一个edits文件中(editsfile),并传输到nfs或者jn中。standbynamenode定期地检查,从nfs或者jn把最近的edits文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage文件,合并完成之后会通知activenamenode获取这个新fsimage文件。activenamenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,就保持了activenamenode和standbynamenode的数据的实时同步,standbynamenode可以随时切换成activenamenode(譬如activenamenode挂了)。而且还实现了原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的ha机制之后,secondarynamenode,checkpointnode,buckcupnode这些设置就都不需要了。
activenamenode和standbynamenode可以随时切换。当activenamenode挂掉后,也可以把standbynamenode切换成active状态,成为activenamenode。可以人工切换和自动切换。人工切换是通过执行ha管理的命令来改变namenode的状态,从standby到active,或者从active到standby。自动切换则在activenamenode挂掉的时候,standbynamenode自动切换成active状态,取代原来的activenamenode成为新的activenamenode,hdfs继续正常工作。
要实现主备节点的自动切换,需要配置zookeeper。activenamenode和standbynamenode把他们的状态实时记录到zookeeper中,zookeeper监视他们的状态变化。当zookeeper发现activenamenode挂掉后,会自动把standbynamenode切换成activenamenode。
基于hadoop2.0官方资料介绍的2种实现ha机制的方式各有缺点。
1、nfs方式
nfs作为activenamenode和standbynamenode之间数据共享的存储。activenamenode会把最近的edits文件写到nfs,而standbynamenode从nfs中把数据读过来。这个方式的缺点是,如果activenamenode或者standbynamenode有一个和nfs之间的网络有问题,则会造成他们之间数据的同步出问题。
2、qjm方式
qjm方式可以解决上述nfs容错机制不足的问题。activenamenode和standbynamenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。activenamenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standbynamenode就可以从journalnode上读取了。可以看到,qjm方式有容错的机制,可以容忍n个journalnode的失败。但是这种方式的缺点是引入了存储开销,一份数据需要存储2n+1份,至少也要存储n+1份。
技术实现要素:
为了解决现有的hadoop2.0的ha两种实现方式存在的网络容错性差和存储开销大的问题,本发明提供一种管理hadoop命名空间的高可用方法,所述方法结合了hadoop官方推荐的nfs实现方式和qjm实现方式的优点,克服了各自的缺点,为hadoop系统增加了高可用性,同时也降低了存储开销。
为实现上述目标,本发明采用以下技术方案:
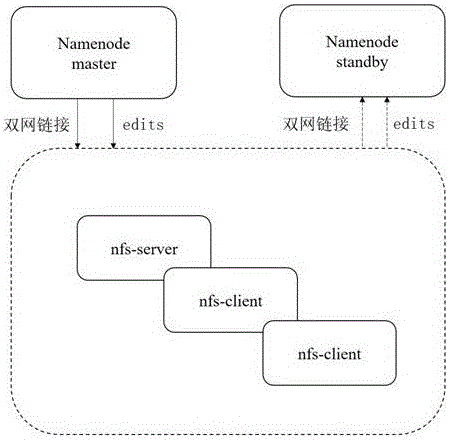
一种管理hadoop命名空间的高可用方法,所述方法采用nfs作为activenamenode(主名字节点)和standbynamenode(备用名字节点)之间的共享存储,在主、备用名字节点和nfs服务器之间设置多个网络连接,一方面均衡网络负载,另一方面增加网络容错能力;在nfs中对于主名字节点要存储的edits文件,进行适度的冗余存储,以增加数据的容错和抗毁能力。
优选的,在主、备用名字节点和nfs服务器之间设置双网络连接。
优选的,在nfs中对每个edits文件存储3份。
优选的,在nfs中存储的多份edits文件要适度隔离,可以是跨跨服务器隔离、跨机柜隔离和跨交换机隔离。
一种管理hadoop命名空间的高可用方法,所述方法包括以下步骤:
1)配置nfs集群;
2)在主节点与nfs集群之间设置多个网络连接;
3)在从节点与nfs集群之间设置多个网络连接;
4)设置nfs中对edits文件的存储份数;
5)设置nfs中对edits各份文件的隔离存储方案。
本发明的优点和有益效果为:所述方法结合了hadoop官方推荐的nfs实现方式和qjm实现方式的优点,克服了各自的缺点,为hadoop系统增加了高可用性,同时也降低了存储开销。
附图说明
图1为本发明所述的一种管理hadoop命名空间的高可用方法逻辑结构图。
具体实施方式
下面结合实施例对本发明作进一步说明。
实施例1
如图1所示,为本发明所述的一种管理hadoop命名空间的高可用方法逻辑结构图,采用nfs作为activenamenode(主名字节点)和standbynamenode(备用名字节点)之间的共享存储,在主、备用名字节点和nfs服务器之间设置两个网络连接;在nfs中对于主名字节点要存储的edits文件,进行冗余度为3的备份存储,以增加数据的容错和抗毁能力。
具体包括以下步骤:
1)配置nfs集群;
2)在主节点与nfs集群之间设置双网络连接;
3)在从节点与nfs集群之间设置双网络连接;
4)设置nfs中对edits文件的存储份数为3;
5)设置nfs中对edits各份文件的隔离存储方案为跨机柜隔离。
最后应说明的是:显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!