针对多视图视频信号生成合并候选列表的方法及解码装置与流程
本发明涉及用于对视频信号进行编码的方法和装置。
背景技术
近来在各种应用领域中对高分辨率、高质量视频例如高清晰度(hd)视频和超高清晰度(uhd)视频的需求已经提高。当视频数据具有更高分辨率和更高质量时,视频数据在量上大于传统视频数据。因而,如果在现有介质例如有线/无线宽带电路上传输视频数据或者在现有存储介质中存储视频数据,则传输成本和存储成本增大。为了避免高分辨率、高质量视频数据所遇到的这些问题,可以使用高效视频压缩技术。
存在各种视频压缩技术,包括:图片间预测,其中,根据当前图片之前的图片或者当前图片之后的图片来预测当前图片中包括的像素值;图片内预测,其中,使用当前图片内的像素信息来预测当前图片中包括的像素值;以及熵编码,其中,短代码被分配给较频繁的值并且长代码被分配给不太频繁的值。使用这样的视频压缩技术,可以高效地压缩视频数据并且对其进行传输或者存储。
伴随对高分辨率视频的增长的需求,对作为新的视频服务的三维(3d)视频内容的需求也增长。正在讨论用于高效地提供hd和uhd3d视频内容的视频压缩技术。
技术实现要素:
技术问题
本发明的目的是提供用于当对多视图视频信号进行编码/解码时使用视差向量来执行视图间预测的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时使用深度块的深度数据来得出纹理块的视差向量的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时根据当前块的相邻块来得出视差向量的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时使用视差向量来得出视图间合并候选的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时针对合并模式配置合并候选列表的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时考虑照明补偿来选择性地使用视图间运动候选的方法和装置。
本发明的另一目的是提供用于当对多视图视频信号进行编码/解码时考虑照明补偿来确定在合并候选列表中布置合并候选的顺序的方法和装置。
技术方案
根据本发明的一种用于对多视图视频信号进行解码的方法和装置的特征在于:生成针对当前块的合并候选列表;基于从比特流获得的当前块的合并索引来得出当前块的运动向量;使用所得出的运动向量来获得当前块的预测值;以及通过将当前块的所获得的预测值和残差值相加来重建当前块。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:合并候选列表包括至少一个合并候选,并且该至少一个合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:合并索引指定用于在合并模式下对当前块进行解码的合并候选。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:视图间运动候选(ivmc)具有由当前块的视差向量指定的参考块的时间运动向量,并且参考块属于当前块的参考视图。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:视图间运动候选(ivmc)根据是否对当前块执行照明补偿而被限制性地包括在合并候选列表中。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:如果不对当前块执行照明补偿,则视图间运动候选(ivmc)被包括在合并候选列表中,并且合并候选按照视图间运动候选(ivmc)、空间相邻块以及时间相邻块的优先级顺序被布置在合并候选列表中。
根据本发明的一种用于对多视图视频信号进行编码的方法和装置的特征在于:生成针对当前块的合并候选列表;基于当前块的合并索引来得出当前块的运动向量;使用所得出的运动向量来获得当前块的预测值;以及通过将当前块的所获得的预测值和残差值相加来重建当前块。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:合并候选列表包括至少一个合并候选,并且该至少一个合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:合并索引指定用于在合并模式下对当前块进行解码的合并候选。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:视图间运动候选(ivmc)具有由当前块的视差向量指定的参考块的时间运动向量,并且参考块属于当前块的参考视图。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:视图间运动候选(ivmc)根据是否对当前块执行照明补偿而被限制性地包括在合并候选列表中。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:如果不对当前块执行照明补偿,则视图间运动候选(ivmc)被包括在合并候选列表中,并且合并候选按照视图间运动候选(ivmc)、空间相邻块以及时间相邻块的优先级顺序被布置在合并候选列表中。
根据一个实施例,一种用于针对多视图视频信号生成合并候选列表的方法包括:从比特流获得照明补偿标记,照明补偿标记指示是否对当前块执行照明补偿;以及根据照明补偿标记来生成针对当前块的合并候选列表;其中,合并候选列表包括至少一个合并候选,至少一个合并候选包括空间相邻块、时间相邻块和视图间合并候选中的至少之一,其中,视图间合并候选包括纹理合并候选和视图间运动候选中的至少之一,并且其中,当照明补偿标记指示不对当前块执行照明补偿时,视图间运动候选被包括在合并候选列表中。
根据另一个实施例,一种用于对多视图视频信号进行解码的装置包括:帧间预测器,其被配置成:获得照明补偿标记,照明补偿标记指示是否对当前块执行照明补偿;以及根据照明补偿标记来生成针对当前块的合并候选列表,其中,合并候选列表包括至少一个合并候选,至少一个合并候选包括空间相邻块、时间相邻块和视图间合并候选中的至少之一,其中,视图间合并候选包括纹理合并候选和视图间运动候选中的至少之一,并且其中,当照明补偿标记指示不对当前块执行照明补偿时,视图间运动候选被包括在合并候选列表中;以及重建器,其被配置成根据合并候选列表来重建当前块。
有益效果
根据本发明,能够使用视差向量来高效地执行视图间预测。
根据本发明,能够根据当前深度块的深度数据或相邻纹理块的视差向量来高效地得出当前块的视差向量。
根据本发明,能够高效地配置合并候选列表的合并候选。
根据本发明,能够通过考虑照明补偿来选择性地使用视图间运动候选来提高编码/解码性能。
根据本发明,能够通过对合并候选列表中包括的多个合并候选区分优先级顺序来提高编码/解码性能。
附图说明
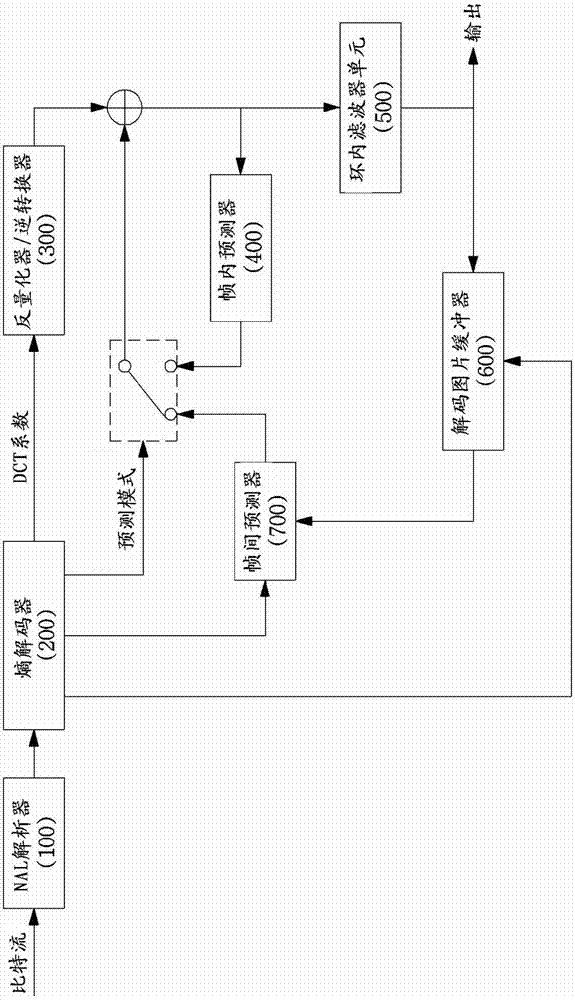
图1是根据本发明的实施方式的视频解码器的示意性框图;
图2是示出根据本发明的实施方式的用于在合并模式下对当前块进行解码的方法的流程图;
图3示出了根据本发明的实施方式的用于通过视图间预测来得出视图间运动候选的运动向量的方法;
图4是示出根据本发明的实施方式的基于当前块的视差向量来得出视图合成预测(vsp)候选的运动向量的方法的流程图;
图5是示出根据本发明的实施方式的使用深度图像的深度数据来得出当前块的视差向量的方法的流程图;
图6示出了根据本发明的实施方式的用于当前块的空间/时间相邻块的候选;
图7是示出根据本发明的实施方式的基于照明补偿标记ic_flag来自适应地使用视图间运动候选(ivmc)的方法的流程图;以及
图8示出了根据本发明的实施方式的基于照明补偿标记ic_flag的合并候选的优先级水平。
具体实施方式
根据本发明的一种用于对多视图视频信号进行解码的方法和装置的特征在于:生成针对当前块的合并候选列表;基于从比特流获得的当前块的合并索引来得出当前块的运动向量;使用所得出的运动向量来获得当前块的预测值;以及通过将当前块的所获得的预测值和残差值相加来重建当前块。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:合并候选列表包括至少一个合并候选,并且该至少一个合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:合并索引指定用于在合并模式下对当前块进行解码的合并候选。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:视图间运动候选(ivmc)具有由当前块的视差向量指定的参考块的时间运动向量,并且参考块属于当前块的参考视图。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:视图间运动候选(ivmc)根据是否对当前块执行照明补偿而被限制性地包括在合并候选列表中。
根据本发明的用于对多视图视频信号进行解码的方法和装置的特征在于:如果不对当前块执行照明补偿,则视图间运动候选(ivmc)被包括在合并候选列表中,并且合并候选按照视图间运动候选(ivmc)、空间相邻块以及时间相邻块的优先级顺序被布置在合并候选列表中。
根据本发明的一种用于对多视图视频信号进行编码的方法和装置的特征在于:生成针对当前块的合并候选列表;基于当前块的合并索引来得出当前块的运动向量;使用所得出的运动向量来获得当前块的预测值;以及通过将当前块的所获得的预测值和残差值相加来重建当前块。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:合并候选列表包括至少一个合并候选,并且该至少一个合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:合并索引指定用于在合并模式下对当前块进行解码的合并候选。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:视图间运动候选(ivmc)具有由当前块的视差向量指定的参考块的时间运动向量,并且参考块属于当前块的参考视图。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:视图间运动候选(ivmc)根据是否对当前块执行照明补偿而被限制性地包括在合并候选列表中。
根据本发明的用于对多视图视频信号进行编码的方法和装置的特征在于:如果不对当前块执行照明补偿,则视图间运动候选(ivmc)被包括在合并候选列表中,并且合并候选按照视图间运动候选(ivmc)、空间相邻块以及时间相邻块的优先级顺序被布置在合并候选列表中。
实现本发明的方式
用于对多视图视频信号进行编码或解码的技术考虑空间冗余、时间冗余和视图间冗余。在多视图视频的情况下,在两个或更多个视点处拍摄的多视图纹理图像可以被编码以实现三维图像。当需要时,可以对与多视图纹理图像对应的深度数据进行进一步编码。不用说,可以考虑空间冗余、时间冗余或视图间冗余来对深度数据进行编码。深度数据是表示关于摄像机与相应像素之间的距离的信息。在本公开内容中,深度数据可以被灵活地解释为与深度有关的数据,例如深度值、深度信息、深度图像、深度图片、深度序列或深度比特流。另外,在本公开内容中,编解码(coding)可以涵盖编码(encoding)与解码(decoding)二者的概念,并且可以在本发明的范围和精神内被灵活地解释。
图1是根据本发明的实施方式的视频解码器的示意性框图。
参照图1,视频解码器可以包括网络抽象层(nal)解析器100、熵解码器200、反量化器/逆转换器300、帧内预测期400、环内滤波器单元500、解码图片缓冲器单元600和帧间预测器700。
nal解析器700可以接收包括多视图纹理数据的比特流。如果需要深度数据来对纹理数据进行编码,则可以还接收包括编码深度数据的比特流。可以在一个比特流或单独的比特流中发送输入纹理数据和输入深度数据。nal解析器100可以基于nal对接收的比特流进行解析以对比特流进行解码。如果接收的比特流是与多视图有关的数据(例如,三维视频),则比特流还可以包括摄像机参数。摄像机参数可以被分类成内在摄像机参数和外在摄像机参数。内在摄像机参数可以包括焦距、长宽比、主点等,而外在摄像机参数可以包括关于摄像机在全局坐标系中的位置的信息。
熵解码器200可以通过熵解码来提取量化转换系数、用于预测纹理图片的编解码信息等。
反量化器/逆转换器300可以通过将量化参数应用于量化转换系数来获得转化系数,并且通过对转换系数进行逆转换来对纹理数据或深度数据进行解码。经解码的纹理数据或深度数据可以指代由预测产生的残差数据。另外,可以考虑纹理数据的复杂度来设置深度块的量化参数。例如,如果与深度块对应的纹理块是具有高复杂度的区域,则可以设置低的量化参数,并且如果与深度块对应的纹理块是具有低复杂度的区域,则可以设置高的量化参数。可以通过等式1基于重建纹理图片中的相邻像素之间的差值来确定纹理块的复杂度。
等式1
在等式1中,e可以表示纹理数据的复杂度,c可以表示重建纹理数据,并且n可以表示要计算其复杂度的纹理数据区域中的像素的数目。参考等式1,可以使用位置(x,y)处的纹理数据与位置(x-1,y)处的纹理数据之间的差值以及位置(x,y)处的纹理数据与位置(x+1,y)处的纹理数据之间的差值来计算纹理数据的复杂度。而且,可以针对纹理图片和纹理块中的每个来计算复杂度,并且可以使用通过等式2所计算的复杂度来得出量化参数。
等式2
参照等式2,可以基于纹理图片的复杂度与纹理块的复杂度之比来确定深度块的量化参数。α和β可以为通过解码器得出的可变整数或者在解码器中确定的整数。
帧内预测器400可以使用当前纹理图片的重建纹理数据来执行图片内预测。可以以与针对纹理图片的方式相同的方式对深度图片执行图片内预测。例如,用于纹理图片的图片内预测的相同编解码信息可以用于纹理图片。用于图片内预测的编码信息可以包括关于帧内预测模式的信息和帧内预测分割信息。
环内滤波器单元500可以对每个编解码块应用环内滤波器以降低块失真。滤波器可以通过使块的边缘平滑来提高解码图片的视频质量。经滤波的纹理图片或深度图片可以被输出或存储在解码图片缓冲器单元600中以用作参考图片。同时,如果使用相同的环内滤波器对纹理数据和深度数据进行编码,则编码效率可能降低,这是因为纹理数据在特性方面与深度数据不同。因此,可以单独地针对深度数据来定义环内滤波器。作为用于高效地对深度数据进行编码的环内滤波方法,下面将描述基于区域的自适应环滤波器和三边环滤波器。
在基于区域的自适应环滤波器的情况下,可以基于深度块的变化(variance)来确定是否应用基于区域的自适应环滤波器。深度块的变化可以被定义为深度块中的最大像素值与最小像素值之间的差值。可以通过将深度块的变化与预定阈值进行比较来确定是否应用该滤波器。例如,如果深度块的变化等于或大于预定阈值,则意味着深度块的最大像素值与最小像素值之间的差较宽。因而,可以确定应用基于区域的自适应环滤波器。相反地,如果深度变化小于该阈值,则可以确定不应用基于区域的自适应环滤波器。如果根据比较结果来使用滤波器,则可以通过将预定权值应用于相邻像素值来得出经滤波的深度块的像素值。可以基于当前经滤波的像素与其相邻像素之间的位置差和/或当前经滤波的像素的值与其相邻像素的值之间的差值来确定该预定权值。相邻像素值可以为深度块中包括的除当前经滤波的像素值之外的像素值之一。
虽然本发明的三边环滤波器与基于区域的自适应环滤波器类似,但是前者与后者不同指出在于:在前者中另外地考虑了纹理数据。具体地,三边环滤波器可以提取满足以下三个条件的相邻像素的深度数据。
条件1.|p-q|≤σ1
条件2.|d(p)-d(q)|≤02
条件3.|v(p)-v(q)|≤σ3
对于条件1,将深度块中的当前像素p与相邻像素q之间的位置差与预定参数σ1进行比较。对于条件2,将当前像素p的深度数据与相邻像素q的深度数据之间的差值与预定参数σ2进行比较。对于条件3,将当前像素p的纹理数据与相邻像素q的纹理数据之间的差值与预定参数σ3进行比较。
可以提取满足以上三个条件的相邻像素,并且可以通过滤波将当前像素p的值设置成相邻像素的深度数据的均值或平均值。
解码图片缓冲器单元600用于存储或打开先前所编解码的纹理图片或深度图片,以用于图片间预测。可以在解码图片缓冲器单元600中使用帧号frame_num和图片的图片顺序数(poc)来存储或打开先前所编解码的纹理图片或深度图片中的每个。另外,由于存在来自先前所编解码的图片中的当前深度图片的不同视图的深度图片,所以在深度编解码期间可以使用指示这些深度图片的视图的视图标识信息将深度图片用作参考图片。解码图片缓冲器单元600可以通过自适应存储器管理控制操作方法、滑动窗口方法等来管理参考图片,以更灵活地进行图片间预测。执行该操作以将用于参考图片的存储器和用于非参考图片的存储器包含在单个存储器中并且利用小的存储容量来有效地管理存储器。在深度编解码中,深度图片可以被标记有单独的指示以与解码图片缓冲器单元中的纹理图片区分,并且在标记期间可以使用标识每个深度图片的信息。
帧间预测器700可以使用运动信息和存储在解码图片缓冲器单元600中的参考图片对当前块执行运动补偿。在本公开内容中,可以理解,运动信息在广义上包括运动向量、参考索引等。帧间预测器700可以执行时间帧间预测以执行运动补偿。时间帧间预测可以指代基于在与当前纹理块相同的视图处并且在与当前纹理块不同的时区中的参考图片以及当前纹理块的运动信息的帧间预测。在通过多个摄像机捕获的多视图视频的情况下,可以执行视图间预测以及时间帧间预测。用于视图间预测的运动信息可以包括视差向量或视图间运动向量。下面将参照图2来描述使用视差向量来执行视图间预测的方法。
图2是示出根据本发明的实施方式的用于在合并模式下对当前块进行解码的方法。
参照图2,可以生成用于当前块的合并候选列表(s200)。
本发明的合并候选列表可以包括可用于在合并模式下对当前块进行解码的至少一个合并候选。例如,当前块的空间/时间相邻块可以为合并候选。空间相邻块可以为左相邻块、上相邻块、右上相邻块、左下相邻块和左上相邻块中的至少之一。时间相邻块可以被定义为在具有与当前块不同的时间顺序的col图片(并置图片)中的位于与当前块相同的位置处的块。
而且,基于视图间关联或纹理-深度关联的合并候选(下文中称为视图间合并候选)可以被包括在合并候选列表中。视图间合并候选可以包括纹理合并候选、视图间运动候选、视图间视差候选、视图合成预测(vsp)候选等。后面将参照图3至图6来描述用于得出每个视图间合并候选的运动向量的方法和用于配置合并候选列表中的合并候选的方法。
参照图2,可以基于合并索引merge_idx和在步骤s200中生成的合并候选列表来得出当前块的运动向量(s210)。
具体地,可以从合并候选列表中选择与当前块的合并索引对应的合并候选。合并索引是指定合并候选列表中包括的多个合并候选之一的语法,其可以从比特流中提取。也就是说,合并索引是指定用于得出当前块的运动向量的合并候选的信息。
分配给所选的合并候选的运动向量可以被设置为当前块的运动向量。
可以使用在步骤s210中得出运动向量来获得当前块的预测值(s200)。
具体地,如果当前块的参考图片和当前块属于同一视图,则可以使用运动向量对当前块执行时间帧间预测。相反地,如果当前块的参考图片与当前块属于不同视图,则可以使用运动向量对当前块执行视图间帧间预测。
可以通过指定参考图片列表中的参考图片、使用当前块的参考索引并且将指定的参考图片的视图索引与当前块的视图索引进行比较来确定当前块的参考图片与当前块是否属于同一视图。
参照图2,可以通过将在步骤220中获得的当前块的预测值和当前块的残差值相加来重建当前块(s230)。
残差值指代当前块的重建值与当前块的预测值之间的差值。可以通过对从比特流中提取的转换系数进行反量化和/或逆转换来获得残差值。
现在,将对之前已经参照图2提及的用于得出视图间合并候选的运动向量的方法和用于配置合并候选列表中的合并候选的方法进行描述。
i.用于得出视图间合并候选的运动向量的方法
1.纹理合并候选(t)
由于视频的纹理数据和深度数据描述了同一时间和同一视图的图像,因此纹理数据和深度数据是高度相关的。因而,如果使用对纹理数据进行编码/解码的相同运动向量对深度数据进行编码/解码,则可以提高视频的编码/解码性能。
具体地,如果当前块是深度块(dpethflag=1),则可以将与深度块对应的纹理块的运动向量分配给纹理合并候选。纹理块可以被确定成与深度块相同的位置处的块。
2.视图间运动候选(ivmc)
可以通过视图间运动预测来得出视图间运动候选的运动向量,将参照图3来对此进行描述。
参照图3,可以使用视差向量对当前视图(视图0)的当前块来指定参考视图(视图1)的参考块。例如,在从与当前块的位置对应的参考视图的块位置移动视差向量的位置处的块可以被指定为参考块。如果参考块具有时间运动向量(即,如果通过时间帧间预测对参考块进行编码),参考块的时间运动向量可以被分配给视图间运动候选。
而且,可以基于子块对当前块执行视图间运动预测。在该情况下,可以将当前块分成多个子块(例如,8×8个子块),可以基于子块来获得参考块的时间运动向量并且将其分配给视图间运动候选。
同时,可以根据与当前块对应的深度图像来得出当前块的视差向量,将参照图5来对其详细描述。也可以根据与当前块空间相邻的块或者位于与当前块不同的时区中的时间相邻块来得出视差向量。将参照图6来描述用于根据当前块的空间/时间相邻块得出当前块的视差向量的方法。
3.视图间运动移位候选(ivmcshift)
可以将前述的视图间运动移位候选的视差向量移位预定值,并且可以使用移位的视差向量来指定参考视图(视图0)的参考块。具体地,可以通过在考虑当前块的宽度(npbw)/高度(npbh)的情况下对视图间运动移位候选(ivmc)的视差向量进行移位来得出移位的视差向量。例如,可以通过将视图间运动候选(ivmc)的视差向量移位(npbw*2,npbh*2)来得出移位的视差向量。
如果参考块具有时间运动向量,可以将参考块的时间运动向量分配给视图间运动移位候选。
4.视图间视差候选(ivdc)
如上所述,可以根据与当前块对应的深度图像或当前块的空间/时间相邻块来得出当前块的视差向量。可以将通过将所得出的视差向量的垂直分量(y分量)设置为0而获得的向量分配给视图间视差候选。例如,如果所得出的当前块的视差向量为(mvdisp[0],mvdisp[1]),则可以将向量(mvdisp[0],0)分配给视图间视差候选。
5.视图间视差移位候选(ivdcshift)
同样,可以根据与当前块对应的深度图或当前块的空间/时间相邻块像来得出当前块的视差向量。可以将通过将所得出的视差向量的水平分量(x分量)移位预定值而获得的向量分配给视图间视差移位候选。例如,如果视图间视差候选的运动向量为(mvdisp[0],mvdisp[1]),则可以将通过将水平分量mvdisp[0]移位4而获得的向量,即(mvdisp[0]+4,mvdisp[1])分配给视图间视差移位候选。
或者可以将通过将所得出的视差向量的水平分量(x分量)移位预定值并且将所得出的视差向量的垂直分量(y分量)设置为0而得出的向量分配给视图间视差移位候选。例如,如果视图间视差候选的运动向量为(mvdisp[0],mvdisp[1]),则可以将通过将水平分量mvdisp[0]移位4并且将垂直分量mvdisp[1]设置为0而获得的向量,即向量(mvdisp[0]+4,0)分配给视图间视差移位候选。
6.vsp候选
也可以基于前述的当前块的视差向量来得出vsp候选的运动向量,将参照图4来对此进行描述。
参照图4,可以根据当前块的深度图像或空间/时间相邻块来得出视差向量(第一视差向量)。随后将参照图5和图6来描述用于得出视差向量的方法。
可以使用在步骤s400中得出的视差向量来指定参考视图的深度块。在本文中,深度块可以被包括在参考深度图像中。参考深度图片和参考纹理图片可以属于同一接入单元,并且参考纹理图片可以与当前块的视图间参考图片对应。
可以使用在步骤s410中指定的深度块中的预定义位置处的至少一个样本来得出修改的视差向量(第二视差向量)(s420)。例如,可以使用深度块的四个角处的深度样本。可以根据四个角处的深度样本的值的最大值、四个角处的深度样本的值的平均值或者四个角处的深度样本之一来得出第二视差向量。
图5是示出根据本发明的实施方式的使用深度图片的深度数据来得出当前块的视差向量的方法的流程图。
参照图5,可以基于关于当前块的位置的信息来获得关于深度图片中的与当前块对应的深度块的位置的信息(s500)。
可以考虑深度图片和当前图片的空间分辨率来确定深度块的位置。
例如,如果已经以相同的空间分辨率对深度图片和当前图片进行编码,则深度块的位置可以被确定成与当前图片中的当前块的位置相同。同时,可以以不同空间分辨率对当前图片和深度图片进行编码。这是因为考虑到表示关于摄像机与对象之间的距离的信息的深度信息的性质,即使以降低的空间分辨率对深度信息进行编码,也不会很大地降低编解码效率。因而,如果已经以比当前图片低的空间分辨率对深度图片进行编码,则解码器可以在获得关于深度块的位置的信息之前对深度图片进行上采样。而且,如果经上采样的深度图片的长宽比不与当前图片的长宽比准确地匹配,则在获得关于在经上采样的深度图片中的当前深度块的位置的信息时可以另外地考虑偏移信息。偏移信息可以包括上偏移信息、左偏移信息、右偏移信息和下偏移信息中至少之一。上偏移信息可以指示经上采样的深度图片的上端处的至少一个像素与当前图片的上端处的至少一个像素之间的位置差。也可以以相同的方式来定义左偏移信息、右偏移信息和下偏移信息。
参照图5,可以获得与关于深度块的位置的信息对应的深度数据(s510)。
如果深度块中存在多个像素,则可以使用与深度块的角像素对应的深度数据。或者可以使用与深度块的中心像素对应的深度数据。或者可以选择性地使用与多个像素对应的多个深度数据的最大值、最小值和最频繁值之一,或者可以使用多个深度数据的平均值。
参照图5,可以使用在步骤s510中获得的深度数据来得出当前块的视差向量(s520)。
例如,可以通过等式3来得出当前块的视差向量。
等式3
dv=(a*v+f)>>n
参照等式3,v表示深度数据,a表示缩放因子,并且f表示用于得出视差向量的偏移。可以在视频参数集或片头部(sliceheader)中发送缩放因子a和偏移f,或者可以在解码器中预配置缩放因子a和偏移f。在本文中,n是指示比特移位值的变量,其可以根据视差向量的准确度来可变地确定。
图6示出了根据本发明的实施方式的当前块的空间/时间相邻块的候选。
参照图6(a),空间相邻块可以为当前块的左相邻块a1、上相邻块b1、左下相邻块a0、右上相邻块b0或左上相邻块b2中的至少之一。
参照图6(b),时间相邻块可以指代与当前块相同的位置处的块。具体地,时间相邻块是属于与当前块不同的时区中的图片的块。时间相邻块可以为与当前块的右下像素对应的块br、与当前块的中心像素对应的块ct或者与当前块的左上像素对应的块tl中的至少之一。
可以根据以上空间/时间相邻块中的视差补偿预测(dcp)块得出当前块的视差向量。dcp块可以指代通过使用视差向量的视图间纹理预测而编码的块。换言之,可以使用通过视差向量指定的参考块的纹理数据对dcp块执行视图间预测。在该情况下,可以使用用于dcp块的视图间纹理预测的视差向量来预测或重建当前块的视差向量。
或者可以根据空间相邻块中的基于视差向量的运动补偿预测(dv-mcp)块来得出当前块的视差向量。dv-mcp块可以指代通过使用视差向量的视图间运动预测而编码的块。换言之,可以使用视差向量所指定的参考块的时间运动向量对dv-mcp块执行时间帧间预测。在该情况下,可以使用用于获得dc-mcp块的参考块的时间运动向量的视差向量来预测或重建当前块的视差向量。
对于当前块,可以根据其预定优先级水平来确定空间/时间相邻块是否为dcp块,并且可以根据第一个检测到的dcp块来得出当前块的视差向量。例如,可以按照空间相邻块->时间相邻块的顺序初步地对相邻块划分优先级顺序,并且可以按照a1->b1->b0->a0->b2的优先级顺序来确定空间相邻块是否为dcp块。然而,优先级顺序仅是实施方式,并且显然可以在对于本领域技术人员而明显的范围内以不同方式对相邻块划分优先级顺序。
如果空间/时间相邻块均不是dcp块,则可以另外检查空间相邻块是否是dv-dcp块。同样地,可以根据第一个检测到的dv-mcp块来得出视差向量。
ii.用于配置合并候选列表的方法
可以可变地确定合并候选列表中的合并候选的最大数目maxnummergecand。然而,可以限制性地在预定范围(例如,1至6)内确定合并候选的最大数目maxnummergecand。可以通过基于片来自适应地控制合并候选的最大数目maxnummergecand来提高编码性能。
例如,可以通过等式4来得出合并候选的最大数目maxnummergecand。
maxnummergecand=5–five_minus_max_num_merge_cand+numextramergecand(等式4)
在等式4中,five_minus_max_num_merge_cand是片段(slicesegment)水平下的语法,其可以指示除视图间合并候选以外的合并候选的最大数目(例如,5)与除视图间合并候选的数目以外的每个片的合并候选的最大数目之间的差。可以通过等式5来得出变量numextramergecand。
numextramergecand=iv_mv_pred_flag[nuh_layer_id]∥mpi_flag[nuh_layer_id]∥viewsynthesispredflag
(等式5)
在等式5中,可以基于iv_mv_pred_flag[nuh_layer_id]、mpi_flag[nuh_layer_id]或者viewsynthesispredflag来得出变量numextramergecand。
在本文中,iv_mv_pred_flag是指示是否在当前视图处执行视图间运动预测的语法。例如,如果iv_mv_pred_flag=1,则执行视图间运动预测,否则,不执行视图间运动预测。相应地,如果iv_mv_pred_flag=1,则可以使用基于视图间运动预测的视图间运动候选(ivmc),并且可以将变量numextramergecand设置为1。
mpi_flag是指示是否执行运动参数继承的语法。例如,在对深度块的解码期间使用与深度块对应的纹理块的运动向量或者根据相邻视图的参考块的纹理块的运动向量的得出被称为运动参数继承。因而,如果根据mpi_flag执行运动参数继承,则可以将前述的纹理合并候选或视图间运动候选(ivmc)用作当前块的合并候选,并且可以将变量numextramergecand设置为1。
viewsynthesispredflag是指示是否使用vsp候选的标记。因而,如果viewsynthesispredflag被设置成1,则可以将vsp候选添加至当前块的合并候选列表,并且可以将变量numextramergecand设置成1。
可以将前述合并候选,即当前块的空间/时间相邻块和视图间合并候选包括在当前块的合并候选列表中。值得注意的是,与合并候选的最大数目maxnummergecand一样多的合并候选可以包括在合并候选列表中。
出于该目的,需要定义被添加至合并候选列表的合并候选的优先级水平(或布置顺序)。
例如,可以按照视图间运动候选(ivmc)、左相邻块a1、上相邻块b1、右上相邻块b0、视图间视差候选(ivdc)、vsp候选、左下相邻块a0、左上相邻块b2、视图间运动移位候选(ivmcshift)以及视图间视差移位候选(ivdcshift)的顺序来划分合并候选的优先级顺序。
或者可以按照视图间运动候选(ivmc)、左相邻块a1、上相邻块b1、vsp候选、右上相邻块b0、视图间视差候选(ivdc)、左下相邻块a0、左上相邻块b2、视图间运动移位候选(ivmcshift)以及视图间视差移位候选(ivdcshift)的顺序来划分合并候选的优先级顺序。显然,可以在对于本领域技术人员而明显的范围内改变这些优先级水平。
图7是示出根据本发明的实施方式的用于基于照明补偿标记ic_flag来自适应地使用视图间运动候选(ivmc)的方法的流程图。
参照图7,可以从比特流获得照明补偿标记(s700)。
照明补偿标记可以指代指示是否对当前块(例如,编解码块或预测单元)执行照明补偿的信息。根据本发明,照明补偿意指针对视图间的照明差的补偿。如果视图之间存在照明差,则与视图间运动候选(ivmc)相比,使用视图间视差候选(ivdc)可以更为高效。因而,可以规定基于照明补偿标记来选择性地使用视图间运动候选(ivmc)。
参照图7,可以确定在步骤s700中获得的照明补偿标记的值是否为1(s710)。
如果照明补偿标记的值不为1(即,ic_flag=0),则可以得出视图间运动候选(ivmc)(s720)。
可以生成在步骤s720中获得的包括视图间运动候选(ivmc)的合并候选列表(s740)。也就是说,可以根据前述优先级顺序将视图间运动候选(ivmc)添加至合并候选列表。
相反地,如果照明补偿标记的值为1,则可以跳过视图间运动候选(ivmc)的得出。
在该情况下,也可以从合并候选列表中排除与视图间运动候选(ivmc)有关的视图间运动移位候选(ivmcshift)。可以根据前述优先级顺序将除视图间运动候选(ivmc)和视图间运动移位候选(ivmcshift)以外的合并候选添加至合并候选列表。例如,可以按照左相邻块a1、上相邻块b1、视图间视差候选(ivdc)、右上相邻块b0、vsp候选、左下相邻块a0、左上相邻块b2以及视图间视差移位候选(ivdcshift)的优先级顺序将合并候选的最大数目maxnummergecand以内的合并候选添加至合并候选列表。
或者可以按照左相邻块a1、上相邻块b1、视图间视差候选(ivdc)、右上相邻块b0、vsp候选、视图间视差移位候选(ivdcshift)、左下相邻块a0和左上相邻块b2的优先级顺序将合并候选添加至合并候选列表。
或者可以按照左相邻块a1、上相邻块b1、右上相邻块b0、视图间视差候选(ivdc)、vsp候选、左下相邻块a0、左上相邻块b2和视图间视差移位候选(ivdcshift)的优先级顺序将合并候选添加至合并候选列表。
图8示出了根据本发明的实施方式的基于照明补偿标记ic_flag的合并候选的优先级水平。
如之前参照图7所述,当视图之间存在照明差时,与视图间运动候选(ivmc)相比,使用视图间视差候选(ivdc)可以更为高效。因而,通过改变合并候选的优先级水平使得视图间视差候选(ivdc)可以具有高于视图间运动候选(ivmc)的优先级顺序,可以提高编解码性能。而且,可以改变合并候选的优先级水平使得视图间视差移位候选(ivdcshift)可以具有高于视图间运动移位候选(ivmcshift)的优先级顺序。
参照图8,如果照明补偿标记的值为1,则可以按照视图间视差候选(ivdc)、左相邻块a1、上相邻块b1、视图间运动候选(ivmc)、右上相邻块b0、vsp候选、视图间视差移位候选(ivdcshift)、视图间运动移位候选(ivmcshift)、左下相邻块a0以及左上相邻块b2的优先级顺序将合并候选添加至合并候选列表。在图8中,当合并候选具有较低优先级值时,合并候选具有较高的优先级水平,并且当合并候选具有较高优先级值时,合并候选具有较低的优先级水平。
另一方面,如果照明补偿标记的值为0,则可以按照视图间运动候选(ivmc)、左相邻块a1、上相邻块b1、视图间视差候选(ivmc)、左相邻块a1、上相邻块b1、视图间视差候选(ivdc)、右上相邻块b0、vsp候选、视图间运动移位候选(ivmcshift)、视图间视差移位候选(ivdcshift)、左下相邻块a0以及左上相邻块b2的优先级顺序将合并候选添加至合并候选列表。
工业实用性
本发明适用于多视图视频编解码。
本发明实施例还包括:
(1)一种用于对多视图视频信号进行解码的方法,所述方法包括:
针对当前块生成合并候选列表,所述合并候选列表包括至少一个合并候选,并且所述合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一;
基于从比特流获得的所述当前块的合并索引来得出所述当前块的运动向量,所述合并索引指定要用于在合并模式下对所述当前块进行解码的合并候选;
使用所得出的运动向量来获得所述当前块的预测值;以及
通过将所述当前块的所获得的预测值和所述当前块的残差值相加来重建所述当前块。
(2)根据(1)所述的方法,其中,所述视图间运动候选(ivmc)具有所述当前块的视差向量所指定的参考块的时间运动向量,并且所述参考块属于所述当前块的参考视图。
(3)根据(2)所述的方法,其中,所述视图间运动候选(ivmc)根据是否对所述当前块执行照明补偿而被限制性地包括在所述合并候选列表中。
(4)根据(3)所述的方法,其中,当不对所述当前块执行所述照明补偿时,所述视图间运动候选(ivmc)被包括在所述合并候选列表中,并且
其中,合并候选被按照所述视图间运动候选(ivmc)、所述空间相邻块以及所述时间相邻块的优先级顺序布置在所述合并候选列表中。
(5)一种用于对多视图视频信号进行解码的装置,所述装置包括:
帧间预测器,其用于:针对当前块生成合并候选列表;基于从比特流获得的所述当前块的合并索引来得出所述当前块的运动向量;以及使用所得出的运动向量来获得所述当前块的预测值;以及
重建器,用于通过将所述当前块的所获得的预测值和所述当前块的残差值相加来重建所述当前块,
其中,所述合并候选列表包括至少一个合并候选,所述合并候选包括空间相邻块、时间相邻块或视图间运动候选(ivmc)中的至少之一,并且所述合并索引指定要用于在合并模式下对所述当前块进行解码的合并候选。
(6)根据(5)所述的装置,其中,所述视图间运动候选(ivmc)具有所述当前块的视差向量所指定的参考块的时间运动向量,并且所述参考块属于所述当前块的参考视图。
(7)根据(6)所述的装置,其中,所述视图间运动候选(ivmc)根据是否对所述当前块执行照明补偿而被限制性地包括在所述合并候选列表中。
(8)根据(7)所述的装置,其中,当不对所述当前块执行所述照明补偿时,所述视图间运动候选(ivmc)被包括在所述合并候选列表中,并且
其中,合并候选被按照所述视图间运动候选(ivmc)、所述空间相邻块以及所述时间相邻块的优先级顺序布置在所述合并候选列表中。
(9)一种用于对多视图视频信号进行编码的方法,所述方法包括:
针对当前块生成合并候选列表,所述合并候选列表包括至少一个合并候选,并且所述合并候选包括空间相邻块、时间相邻块或者视图间运动候选(ivmc)中的至少之一;
基于所述当前块的合并索引来得出所述当前块的运动向量,所述合并索引指定要用于在合并模式下对所述当前块进行编码的合并候选;
使用所得出的运动向量来获得所述当前块的预测值;以及
通过将所述当前块的所获得的预测值和所述当前块的残差值相加来重建所述当前块。
(10)根据(9)所述的方法,其中,所述视图间运动候选(ivmc)具有所述当前块的视差向量所指定的参考块的时间运动向量,并且所述参考块属于所述当前块的参考视图。
(11)根据(10)所述的方法,其中,所述视图间运动候选(ivmc)根据是否对所述当前块执行照明补偿而被限制性地包括在所述合并候选列表中。
(12)根据(11)所述的方法,其中,当不对所述当前块执行所述照明补偿时,所述视图间运动候选(ivmc)被包括在所述合并候选列表中,并且合并候选被按照所述视图间运动候选(ivmc)、所述空间相邻块以及所述时间相邻块的优先级顺序布置在所述合并候选列表中。
(13)一种用于对多视图视频信号进行编码的装置,所述装置包括:
帧间预测器,其用于:针对当前块生成合并候选;基于所述当前块的合并索引来得出所述当前块的运动向量;以及使用所得出的运动向量来获得所述当前块的预测值;以及
重建器,用于通过将所述当前块的所获得的预测值和所述当前块的残差值相加来重建所述当前块,
其中,所述合并候选列表包括至少一个合并候选,所述合并候选包括空间相邻块、时间相邻块或视图间运动候选(ivmc)中的至少之一,并且所述合并索引指定要用于在合并模式下对所述当前块进行编码的合并候选。
(14)据(13)所述的装置,其中,所述视图间运动候选(ivmc)具有所述当前块的视差向量所指定的参考块的时间运动向量,并且所述参考块属于所述当前块的参考视图。
(15)根据(14)所述的装置,其中,所述视图间运动候选(ivmc)根据是否对所述当前块执行照明补偿而被限制性地包括在所述合并候选列表中。
- 还没有人留言评论。精彩留言会获得点赞!