一种基于正交匹配追踪的水声信道时延估计方法与流程
本发明涉及一种水声信道时延估计方法,特别是一种基于正交匹配追踪的水声信道时延估计方法。
背景技术:
近年来,由于正交频分复用(ofdm)技术的高带宽利用率及其多径信道均衡的低复杂度使其广泛地应用于水声通信系统中,实际应用中大部分ofdm系统采用相干接收机,这使得信道估计的精度变得十分重要。作为具有较少计算量的贪婪算法,正交匹配追踪(omp)成为压缩感知(cs)分支中最受欢迎的算法之一。每次迭代中,基于omp算法的信道估计器先估计出信道的时延信息,接着通过求解最小二乘(ls)问题来最小化拟合误差。为了实现更精确的时延估计和信道估计,omp算法常常采用比基带采样间隔更精细的时延网格来构建字典矩阵。而omp的主要计算量集中在字典矩阵的转置与向量的乘法运算上,极大的字典矩阵原子个数导致omp算法需要极高的计算复杂度。由于水下传感器节点的成本以及布放操作较为昂贵,能量补充极其困难,这就导致了估计精度和计算复杂度的权衡问题,因此需要研究低复杂度的水声信道估计技术。目前国内外许多学者都对此进行了研究,但大部分技术的计算复杂度仍取决于时延网格精度,且每次迭代都需建立新的字典矩阵及计算对应的内积。
中国专利说明书cn102244624a中公开了一种基于正交匹配追踪的稀疏信道估计方法。该方法只是引用了经典的omp算法来进行信道估计,并没有明显降低计算复杂度,且没有应用到水声领域。中国专利说明书cn106027445a公开了一种水声块结构稀疏特性的信道估计方法。该方法从降低水声信道的稀疏度入手,通过降低omp所需的导频数量来降低估计所需的计算复杂度。而本文直接从omp算法的原理考虑,通过引入戈策尔(goertzel)算法来降低omp所需的计算复杂度。
技术实现要素:
针对上述现有技术,本发明要解决的技术问题是提供一种在降低计算复杂度的同时提高时延估计精度的基于正交匹配追踪的水声信道时延估计方法。
为解决上述技术问题,本发明一种基于正交匹配追踪的水声信道时延估计方法,包括以下步骤:
步骤1:初始化:残差
步骤2:输入:采样间隔δt,最大迭代次数q,迭代停止条件判断值χ1,χ2;
步骤3:迭代:q=q+1,当q>q时,执行步骤4,否则执行以下步骤:
(3-1):通过两步搜索模型找到精估时延
(3-2):将(3-1)所得采样点带入基于连续时域内积函数的时延估计模型,得到待估时延
(3-3):利用(3-2)所得待估时延
(3-4):利用最小二乘法计算当前路径q对应的幅度值
(3-5):更新变量:残差
(3-6):判断是否满足迭代停止条件,当‖rq+1-rq||2<χ1或者||rq+1||2<χ2时,停止迭代,执行步骤4,否则跳转至步骤3;
步骤4:输出信道估计结果
本发明还包括:
1.步骤(3-1)所述的两步搜索模型是基于戈策尔算法的两步搜索模型,构造步骤如下:
步骤1:先进行np次离散傅里叶逆变换运算(idft),np对应于基带采样间隔
步骤2:在粗估时延tcoa附近采用更小的采样间隔
2.步骤(3-2)所述的基于连续时域内积函数φ(t)的时延估计模型为:
其中np,dp分别为导频个数和导频间隔,t为一个ofdm符号块时长。
本发明的有益效果:1.本发明针对均匀导频ofdm系统由频域导频观测向量与字典矩阵原子的埃米尔特内积导出一种基于omp时延估计的闭式解,利用该解可显著提高时延估计精度。
2.本发明结合戈策尔算法提出一种两级搜索策略大大降低omp算法在搜索最佳估计样本时的计算复杂度。
3.本发明可在降低计算复杂度的同时提高时延估计精度,可用于实现高效高精度低复杂度的信道估计模型中,为水声通信装置或系统实现节省能源与高效运行上的双赢。
附图说明
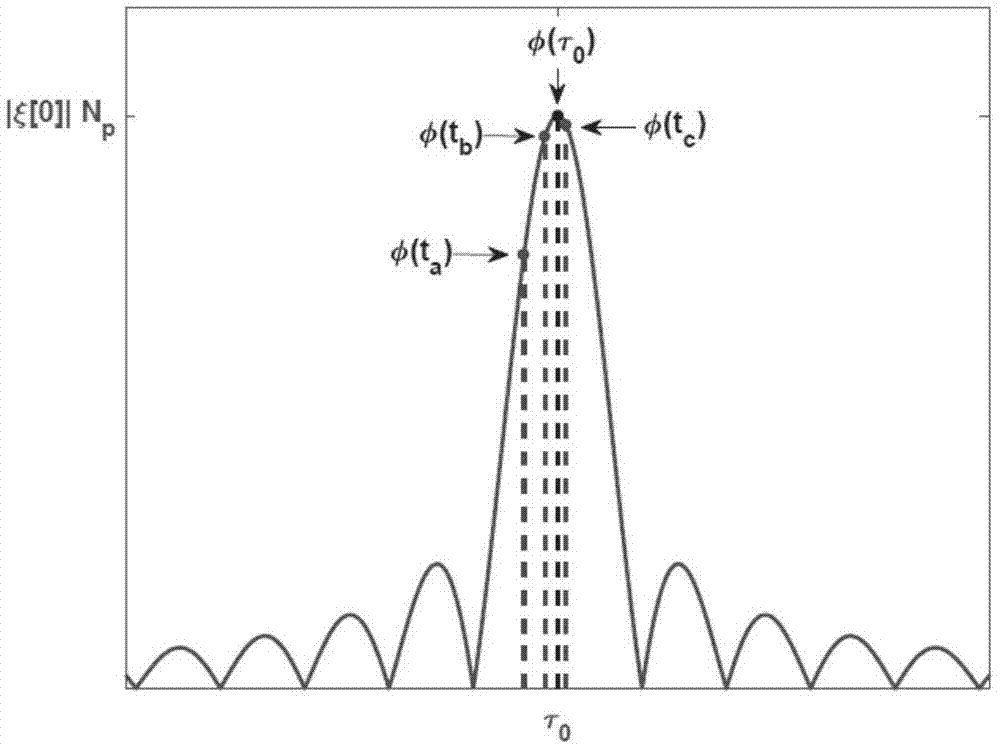
图1为单条路径的内积函数示意图;
图2为基于戈策尔算法的两步搜索策略流程图;
图3为基于正交匹配追踪的信道估计模型流程图;
图4为传统omp算法与本发明的复杂度比较图;
具体实施方式
本发明涉及的是一种基于正交匹配追踪的水声信道时延估计方法。下面将结合附图对本发明进行详细说明。
a.cp-ofdm系统与水声多径信道模型
本发明所涉及的ofdm系统采用循环前缀模式。假定一个ofdm符号块包含k个子载波,每个子载波上的发送符号为s[k]。一个ofdm符号块时长为t,循环前缀的时长为tcp,载波频率为fc。因此,待发送的ofdm符号时域表达式如下,
假设信道在一个符号持续时间内保持不变,本文的信道模型为具有l条路径的多径信道,每条径的幅度与时延分别为al和τl(l=0,1,...,l-1),并假设信道中有多普勒偏移fd。接收端经下变频和滤波处理后的信号为
其中
其中
其中ε=fdt表示归一化多普勒因子。
为了不失一般性,假设一组均匀分布的导频子载波索引为{-k/2,-k/2+dp,-k/2+2dp,…},共有
通常,经多普勒补偿之后,残余的多普勒频移也会被限制,因此(4)式中的矩阵cε可近似为主对角线附近为非零项的带状矩阵。进一步假设,导频间隔dp足够大,载波间干扰可被忽略。综上,可得到(3)式中导频项的频域输入输出关系式:
其中
对导频位置的频域观测量进行补偿,得到如下表达式:
v[m]=(id[mdp]+w[mdp])/sp[mdp]
其中m=0,1,...,np-1。通过上述表达式可将(5)式表示为
这里
b.基于连续时域内积函数的时延估计模型
将omp估计中的过采样时延网格表示为
其中
现选取一条时延为τ0,等效幅度为ξ[0]的路径为说明对象,忽略噪声的影响,导频补偿频域观测量与字典矩阵对应于时延t的列向量之间的内积函数可表示为如下形式:
利用(8)式的内积函数,如图1所示,选取三个采样点φ(ta),φ(tb),φ(tc)。在内积函数φ(t)中,选择的采样点离函数峰值点越近,估计结果受噪声和其他路径的影响越小。因此,选择的采样点tb离峰值点越近,选择的采样间隔δt越小,估计结果越准确。上述采样点之间的关系如下:tb-ta=tc-tb=δt
如图1所示,内积函数φ(t)的主瓣宽度为
(9)式左右两端乘上|ξ[0]|,另
其闭式表达形式为:
c.基于戈策尔算法的两步搜索模型
为了选出最优的三个样本值{tb-δt,tb,tb+δt},本发明提出一种能够降低计算复杂度的两步搜索策略,流程如图2所示。
在均匀导频ofdm系统中,利用正交匹配追踪估计信道时,需要计算导频观测向量与字典矩阵原子之间的内积,内积计算通常利用离散傅里叶逆变换(idft)实现,因此omp每次迭代中搜索最优解都需要λnp次idft运算。为了降低idft的运算次数,本发明在每次迭代过程中采用两步搜索策略,详细实施步骤为:步骤1)先进行np次(对应于基带采样间隔
d.基于正交匹配追踪的信道估计模型
构建流程如图3所示,具体步骤如下:
步骤1:初始化:残差
步骤2:输入:采样间隔δt,最大迭代次数q,迭代停止条件χ1,χ2;
步骤3:迭代:q=q+1,当q>q时,执行步骤4,否则执行以下步骤:
(3-1)通过两步搜索模型找到精估时延
(3-2)将(3-1)所得采样点带入基于连续时域内积函数的时延估计模型,得到待估时延
(3-3)利用(3-2)所得待估时延
(3-4)利用最小二乘法计算当前路径q对应的幅度值
(3-5)更新变量:残差
(3-6)判断是否满足迭代停止条件,当||rq+1-rq||2<χ1或者||rq+1||2<χ2时,停止迭代,执行步骤4,否则跳转至步骤3;
步骤4:输出信道估计结果
以上步骤流程仅为说明本发明的技术思想,并不用以限制本发明,凡是在本发明提出的技术方案、技术思想、引进方法上所做的任何改动、改进等,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!