音频处理方法与音频均衡器与流程
本发明提供一种音频处理方法与音频均衡器,特别涉及一种对声音信号进行均衡(equalization)的音频处理方法与音频均衡器。
背景技术:
声音信号的均衡器(equalizer)早期是用来补偿数字模拟转换器(dac)、功率放大器(amp)或喇叭单体的不足。而近年来,多媒体产业经常用来美化声音,让声音听起来更丰富悦耳。一般均衡器设计采用串级(cascade)无限脉冲响应(infiniteimpulseresponse,iir)滤波器。
然而,在嵌入式系统中,采用串级iir滤波器的均衡器的运算量很大,因此必须以其他方式来设计均衡器。
技术实现要素:
本发明提供了一种音频处理方法与音频均衡器,其可以实现在嵌入式系统中,且不会造成过大的运算量。此外,本发明同时采用了一凯撒贝索衍生(kbd)视窗与一重叠与相加(ola)方法来消除声音信号在转换期间的信号失真。而音频处理方法与音频均衡器也可以提供使用者弹性设置均衡器中的滤波器的种类与数量,以符合使用者想要达到的音频效果。
本发明实施例提供一种音频处理方法,且适用于一音频均衡器。音频处理方法包括如下步骤:(a)读取一时域音频;(b)将时域音频窗化(windowing),以产生多个取样区块(block),其中每一个取样区块具有多个取样点(sample),且每一个相邻的取样区块具有一预定比例的重叠部分;(c)套用一凯撒贝索衍生(kbd)视窗到每一个取样区块,以在每一个取样区块中的每一个取样点对应产生一结果值;(d)通过一修改型离散余弦变换(mdct)方式将这些取样区块转换成一频率域的多个频段,其中每一个频段具有一频点且频点对应到一频率值;(e)均衡这些频段以产生多个调整后的频段,其中每一个调整后的频段的频点对应到一调整频率值;(f)通过一逆向mdct(imdct)方式将这些调整后的频段转换成一时间域的多个新取样区块,其中每一个新取样区块中的每一个取样点对应到一新结果值;(g)套用一kbd还原视窗到每一个新取样区块,以补偿每一个新取样区块中的每一个取样点对应到的新结果值;以及(h)根据重叠部分通过一重叠与相加(ola)方法混叠每一个取样区块,以产生一新时域音频。
本发明实施例提供一种音频均衡器,且包括一接收器与一处理器。接收器接收一声音信号,且将声音信号转换成一时域音频。处理器耦接接收器,且用以执行下列步骤:(a)读取时域音频;(b)将时域音频窗化(windowing),以产生多个取样区块(block),其中每一个取样区块具有多个取样点(sample),且每一个相邻的取样区块具有一预定比例的重叠部分;(c)套用一凯撒贝索衍生(kbd)视窗到每一个取样区块,以在每一个取样区块中的每一个取样点对应产生一结果值;(d)通过一修改型离散余弦变换(mdct)方式将这些取样区块转换成一频率域的多个频段,其中每一个频段具有一频点且频点对应到一频率值;(e)均衡这些频段以产生多个调整后的频段,其中每一个调整后的频段的频点对应到一调整频率值;(f)通过一逆向mdct(imdct)方式将这些调整后的频段转换成一时间域的多个新取样区块,其中每一个新取样区块中的每一个取样点对应到一新结果值;(g)套用一kbd还原视窗到每一个新取样区块,以补偿每一个新取样区块中的每一个取样点对应到的新结果值;以及(h)根据重叠部分通过一重叠与相加(ola)方法混叠每一个取样区块,以产生一新时域音频。
为使能更进一步了解本发明的特征及技术内容,请参阅以下有关本发明的详细说明与附图,但是这些说明与附图仅是用来说明本发明,而非对本发明的权利要求作任何的限制。
附图说明
图1是本发明一实施例的音频均衡器的示意图。
图2是本发明一实施例的音频处理方法的流程图。
图3是本发明一实施例的多个取样区块的示意图。
图4是本发明一实施例的套用kbd视窗到每一个取样区块的示意图。
图5是本发明一实施例的将多个取样区块转换成一频率域的多个频段的示意图。
图6a是本发明一实施例的均衡这些频段的细节流程图。
图6b是本发明一实施例的参考波形的示意图。
图6c是本发明一实施例的调整波形与合成波形的示意图。
图6d是本发明一实施例的调整后的频段的示意图。
图7是本发明一实施例的将多个调整后的频段转换成一时间域的多个新取样区块的示意图。
图8是本发明一实施例的套用kbd视窗到每一个新取样区块的示意图。
图9是本发明一实施例的新时域音频的示意图。
符号说明
100:音频均衡器
110:接收器
120:处理器
sa:声音信号
x(t):时域音频
y(t):新时域音频
s210、s220、s230、s240、s250、s260、s270、s280:步骤
blk1、blk2、blk3、blkn:取样区块
s0:数值
p50:取样点
s0’:结果值
fb1、fb2、fb3、fbn:频段
x(f1)、x(f2)、x(f3)、x(fn):频率值
fc1、fc2、fc3、fcn:频点
s610、s620、s630、s640:步骤
waver:参考波形
w1:调整波形
w2:调整波形
w3:调整波形
wad:叠加波形
wcom:合成波形
fb1’、fb2’、fb3’、fbn’:调整后的频段
x’(f1)、x’(f2)、x’(f3)、x’(fn):调整频率值
blk1’、blk2’、blk3’、blkn’:新取样区块
s1:数值
s1’:新结果值
具体实施方式
在下文中,将通过附图说明本发明的各种例示实施例来详细描述本发明。然而,本发明概念可能以许多不同形式来实现,且不应解释为限于本文中所阐述的例示性实施例。此外,附图中相同参考数字可用以表示类似的元件。
本发明实施例所提供的音频处理方法与音频均衡器,其可以实现在嵌入式系统中,且不会造成过大的运算量。更进一步来说,音频处理方法与音频均衡器利用一kbd视窗与一ola方法来消除时域音频在转换期间的信号失真,且使用者可以弹性设置滤波器的种类与数量,以符合使用者想要达到的音频效果。据此,本发明实施例所提供的音频处理方法与音频均衡器可以实现在运算量较小的嵌入式系统中,且可以根据使用者想要达到的音频效果来产生所需的滤波器。以下将进一步介绍本发明公开的音频处理方法与音频均衡器。
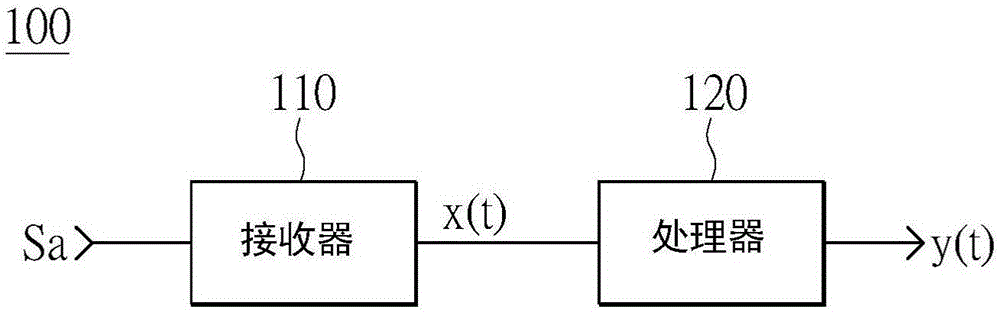
首先,请参考图1,其显示本发明一实施例的音频均衡器的示意图。如图1所示,音频均衡器100设置在嵌入式系统(未绘于附图)中且接收声音信号sa。使用者可以通过音频均衡器100来调整声音信号sa,并输出使用者想要的声音效果。在本实施例中,音频均衡器100是嵌入式系统中的某个元件(例如微处理器)或多个元件的组合(例如微处理器加上声音信号接收器),本发明对此不作限制。
音频均衡器100包括一接收器110与一处理器120。接收器110接收一声音信号sa,且将声音信号sa转换成一时域音频x(t)。在本实施例中,时域音频x(t)为声音信号sa在时间轴上的呈现。而有关声音信号sa转换成时域音频x(t)为所属领域技术人员所悉知,故在此不再赘述。
处理器120耦接接收器110,且用以执行下列步骤,以消除时域音频在转换期间的信号失真,且可提供使用者弹性设置滤波器所要达到的效果,但却不会造成过大的运算量。请同时参考图2,其显示本发明一实施例的音频处理方法的流程图。首先,处理器120读取时域音频x(t),以进一步对一时间域(timedomain)的时域音频x(t)进行处理(步骤s210)。在本实施例中,时域音频x(t)的取样频率为48000hz。
接着,处理器120将时域音频x(t)窗化(windowing),以产生多个取样区块(block)。每一个取样区块具有多个取样点(sample),且每一个相邻的取样区块具有一预定比例的重叠(overlap)部分(步骤s220)。如图3所示,处理器120窗化时域音频x(t),以产生多个取样区块blk1、blk2、blk3…blkn。在每一个取样区块blk1-blkn中具有多个取样点(未绘于附图中),且每一个相邻的取样区块blk1-blkn具有50%的重叠部分。在本实施例中,每一个取样区块blk1-blkn具有1024个取样点,且每个取样点对应到一个数值。举例来说,取样区块blk1的第50个取样点p50对应到数值s0。
而在接下来的步骤中,处理器120会进一步对信号由一时间域转换为一频率域,且信号会在转换过程中产生信号失真。因此,处理器120在下一个步骤s230中,将用来补偿信号失真的kbd视窗套用到每一个取样区块,以供信号在由频率域转换回时间域的时候,可以有个补偿依据将失真的信号补偿回来。
因此,处理器120在取得多个取样区块(即步骤s220)后,处理器120将套用一kbd视窗到每一个取样区块,以在每一个取样区块中的每一个取样点对应产生一结果值(步骤s230)。承接上述实施例,如图4所示,处理器120将kbd视窗的范围设定为0-1023,且将kbd视窗中的第0-1023个数值分别乘上每一个取样区块blk1-blkn中的1024个取样点,以在每一个取样区块blk1-blkn中的每一个取样点对应产生一结果值。举例来说,取样区块blk1的第50个取样点p50对应到数值s0。而处理器120将kbd视窗中的第50个数值乘上取样区块blk1的第50个取样点p50,以产生取样点p50的结果值s0’。
接下来,处理器120通过一mdct方式将这些取样区块转换成一频率域的多个频段(步骤s240)。每一个频段具有一频点,且每一个频点对应到一频率值。承接上述实施例,如图5所示,处理器120通过mdct方式将多个取样区块blk1-blkn转换成一频率域的多个频段fb1、fb2、fb3…fbn。频段fb1、fb2、fb3…fbn分别具有频点fc1、fc2、fc3…fcn,且频点fc1、fc2、fc3…fcn分别对应到频率值x(f1)、x(f2)、x(f3)…x(fn)。
而由于时域音频x(t)的取样频率为48000hz,相邻的取样区块blk1-blkn有50%的重叠部分,且每一个取样区块blk1-blkn具有1024个取样点。因此,频段fb1-fbn的频点fc1、fc2、fc3…fcn将设定为0(hz)、46.875(hz)、93.75(hz)…23953(hz)。而有关处理器120通过mdct方式将一时间域的多个取样区块blk1-blkn转换成一频率域的多个频段fb1、fb2、fb3…fbn的过程为所属领域技术人员所悉知,故在此不再赘述。此外,处理器120通过mdct方式来产生多个频段fb1-fbn,其不需要复杂的运算,使得音频均衡器100可以在嵌入式系统中实现而不会造成过大的运算量。
接着,处理器120将均衡这些频段,以产生多个调整后的频段(步骤s250)。而处理器120可根据使用者需求来均衡这些频段,使得调整后的频段符合使用者想要的声音效果。更进一步来说,如图6a所示,在处理器120均衡这些频段的过程中,首先将产生一参考波形(步骤s610)。举例来说,处理器120产生正弦波形(sinewave)来当作调整频段的模型,以形成参考波形。如图6b所示,处理器120将正弦波形的0-2π对应到频宽0-2000,且将正弦波形数值0-1对应到增益值0-1,以借此形成参考波形waver。而上述参考波形亦可以用锯齿波形、或其他合适的波形,本发明对此不作限制。
再来,处理器120将套用至少一个参数组到参考波形,以产生具有参数组的数量的至少一调整波形(步骤s620)。每一个参数组具有一预设频点、一预设频带与一预设增益值,以供处理器120根据这些参数组中的资料数据分别产生相对应的调整波形。承接上述例子,如图6c所示,参数组共有三组,其分别代表一低通滤波的第一参数组pf1、代表一带通滤波的第二参数组pf2、代表另一带通滤波的第三参数组pf3。
第一参数组pf1的预设频点fc=50hz且预设增益值gain=6db。第二参数组pf2的预设频点fc=1000hz、预设频带bw=1000hz且预设增益值gain=6db。第三参数组pf3的预设频点fc=3000hz、预设频带bw=3000hz且预设增益值gain=6db。因此,处理器120将根据上述第一参数组pf1、第二参数组pf2与第三参数组pf3分别产生调整波形w1、w2与w3。而有关参数组的数量可以依照使用者想要产生的调整波形的数量与效果来做设计,本发明对此不作限制。
再来,处理器120将叠加这些调整波形以产生一叠加波形,且根据一预设最大增益值限制叠加波形的增益值以产生一合成波形(步骤s630)。承接上述例子,同样如图6c所示,处理器120将叠加这三个调整波形w1、w2与w3以产生一叠加波形wad,并根据一预设最大增益值限制叠加波形wad的增益值,以产生合成波形wcom(如图6c中的实线部分)。承接上述例子,预设最大增益值例如为6db,以避免处理器120输出爆音。因此,处理器120将限制叠加波形wad的最大增益值为6db而产生合成波形wcom。而若处理器120不会有输出爆音的问题,则叠加波形wad可以直接作为合成波形wcom,本发明对此不作限制。
最后,处理器120将套用合成波形到步骤s240所产生的频率域的多个频段,以据此产生调整后的频段(步骤s640)。承接上述例子,处理器120将套用合成波形wcom到图5所示的多个频段fb1-fbn,以据此产生调整后的频段fb1’、fb2’、fb3’…fbn’。而调整后的频段fb1’、fb2’、fb3’…fbn’分别具有频点fc1-fcn,且频点fc1-fcn分别对应到一调整频率值x’(f1)、x’(f2)、x’(f3)…x’(fn)。
在处理器120均衡这些频段以取得调整后的频段(即步骤s250)后,代表处理器120已将这些频段调整为使用者想要的声音效果。此时,处理器120接着将通过一逆向mdct(imdct)方式将这些调整后的频段转换成一时间域的多个新取样区块(步骤s260)。而每一个新取样区块中的每一个取样点会对应到一新结果值。承接上述例子,如图7所示,处理器120通过imdct方式将调整后的频段fb1’-fbn’转换成一时间域的多个新取样区块blk1’、blk2’、blk3’…blkn’。每一个新取样区块blk1’、blk2’、blk3’…blkn’中具有多个取样点(未绘于附图中),且每一个取样点会对应到一个新结果值(未绘于附图中)。举例来说,每一个新取样区块blk1’-blkn’中具有1024个取样点,新取样区块blk1’的第50个取样点p50对应到数值s1。
在此步骤s260中,处理器120将均衡后的频段转换回时间域的信号,并在接下来的步骤中还原成关联于时域音频x(t)的信号。
因此,在步骤s270中,处理器120将套用一kbd还原视窗到每一个新取样区块,以补偿每一个新取样区块中的每一个取样点对应到的新结果值(步骤s270)。承接上述例子,如图8所示,处理器120将kbd还原视窗的范围设定为0-1023,且将kbd还原视窗中的第0-1023个数值分别乘上每一个新取样区块blk1’-blkn’中的1024个取样点,以在每一个新取样区块blk1’-blkn’中的每一个取样点对应产生一新结果值。举例来说,请同时参考图7-图8,新取样区块blk1’的第50个取样点p50对应到数值s1。而处理器120将kbd还原视窗中的第50个数值乘上新取样区块blk1’的第50个取样点p50,以对应产生取样点p50的新结果值s1’。在本实施例中,kbd还原视窗与步骤s230中的kbd视窗相同,使得处理器120可以在相同的条件下补偿每一个新取样区块中的每一个取样点对应到的新结果值。当然,kbd还原视窗与步骤s230中的kbd视窗亦可依照实际状况设计为不相同,本发明对此不作限制。
此时,新取样区块blk1’-blkn’代表经过均衡时域音频x(t)后的区域信号,且每一个新取样区块blk1’-blkn’具有一预定比例(在本实施例为50%)的重叠部分。
因此,处理器120将根据重叠部分通过一重叠与相加(ola)方法混叠每一个新取样区块,以产生一新时域音频(步骤s280)。承接上述例子,如图9所示,处理器120将根据步骤s220所述的重叠部分(在本例子为50%的重叠部分)通过ola方法混叠每一个新取样区块blk1’-blkn’,以产生一新时域音频y(t)。此时的新时域音频y(t)代表处理器120均衡时域音频x(t)后所产生的时间地域的音频。而处理器120将可传送新时域音频y(t)至下一级的放音元件(例如喇叭)输出或者至其他电子元件作后续处理。
综上所述,本发明实施例所提供的一种音频处理方法与音频均衡器,其可以实现在嵌入式系统中,且不会造成过大的运算量。更进一步来说,音频处理方法与音频均衡器利用一kbd视窗与一ola方法来消除时域音频在转换期间的信号失真,且使用者可以弹性设置滤波器的种类与数量,以符合使用者想要达到的音频效果。据此,本发明实施例所提供的音频处理方法与音频均衡器可以实现在运算量较小的嵌入式系统中,且可以根据使用者想要达到的音频效果来产生所需的滤波器。
以上所述仅为本发明的实施例,其并非用以局限本发明的权利要求。
- 还没有人留言评论。精彩留言会获得点赞!