一种利用微表情调整音量的装置及方法与流程
本发明涉及一种利用微表情调整音量的装置以及利用微表情调整音量的方法。
背景技术
随着视频播放软件、视频网页、app的流行,用户使用手机、平板等设备观看视频的行为已经渐渐融入日常。
但是,这些视频播放软件在切换播放视频时可能会有音量的突然增大而引起用户的不适,其原因在于视频自身的音频由于各自处理过程的不同,导致在同等的设备音量下,每个音频输出的最终音量还是可能有所不同。
目前市面上的调整音量的设备大多都是外部设备,例如耳机、音箱,并且只是用于提高音频播放效果,并没有对由于音频自身原因导致音量突然增大的处理方案。
技术实现要素:
为解决上述问题,提供一种调整播放终端音量的装置及方法,本发明采用了如下技术方案:
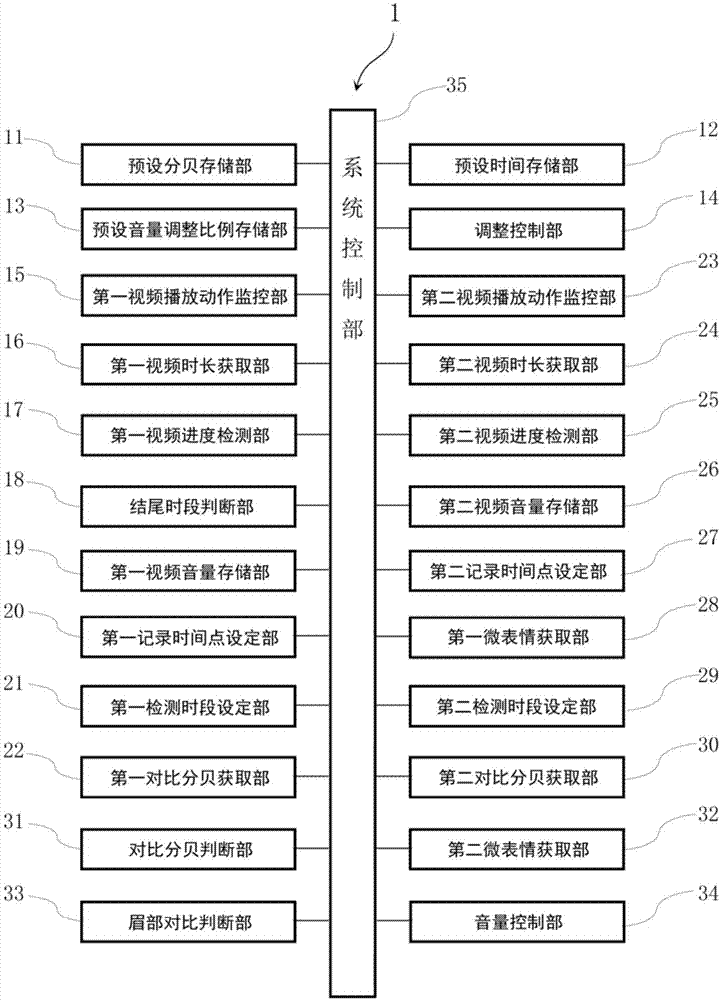
本发明提供了一种利用微表情调整音量的装置,设置在具有播放部以及摄像头的播放终端中,用于在播放终端播放的视频切换时对视频的外放音量进行调节,其特征在于,包括:预设分贝存储部、预设时间存储部、预设音量调整比例存储部、调整控制部、第一视频播放动作监控部、第一视频时长获取部、结尾时段判断部、第一视频进度检测部、第一视频音量存储部、第一记录时间点设定部、第一检测时段设定部、第一对比分贝获取部、第二视频播放动作监控部、第二视频时长获取部、第二视频进度检测部、第二视频音量存储部、第二记录时间点设定部、第一微表情获取部、第二检测时段设定部、第二对比分贝获取部、对比分贝判断部、第二微表情获取部、眉部对比判断部以及音量控制部,预设分贝存储部存储有预设的检测分贝值,预设时间存储部存储有第一预设时间长度以及第二预设时间长度,第一预设时间长度以及第二预设时间长度的取值范围在5~10秒之间,预设音量调整比例存储部存储有预设的音量调整比例,其中,第一视频播放动作监控部监控到播放部有正在播放的当前视频,调整控制部控制第一视频时长获取部对当前视频的播放进度进行检测获取第一视频总长度,并控制第一视频进度检测部检测当前视频的播放情况从而实时地获得当前播放进度,进一步控制结尾时段判断部根据第一视频总长度通过结尾判断比例计算获得与视频结束时间相差一定时间距离的预定检测时间点,第一视频音量存储部在当前播放进度到达预定检测时间点时开始按预定的视频采集时间点依次存储当前视频的多个播放音量作为结尾段分贝值,第一记录时间点设定部从结尾段分贝值中将开始小于等于检测分贝值的播放音量所对应的视频采集时间点设定为第一记录时间点,当上述当前播放进度到达当前视频结束时仍未满足上述判定条件,以当前视频结束的时间点作为第一记录时间点,第一检测时段设定部,将以第一记录时间点为终点的第一预设时间长度的时间区段设定为结尾检测时段,第一对比分贝获取部,在结尾检测时段内,获取最高的结尾段分贝值作为第一对比分贝,第二视频播放动作监控部监控到当前视频结束后有播放的第二视频,调整控制部控制第二视频时长获取部对第二视频的播放进度进行检测获取第二视频总长度,并控制第二视频进度检测部检测第二视频的播放情况从而实时地获得第二播放进度,第二视频音量存储部在播放部播放第二视频的开始按视频采集时间点依次存储当前视频的多个播放音量作为开头段分贝值,第二记录时间点设定部从开头段分贝值中将大于检测分贝值的播放音量对应的视频采集时间点设定为第二记录时间点,第一微表情获取部,在第二播放进度到达第二记录时间点时,通过摄像头获取用户的眉部的表情作为第一眉部微表情,第二检测时段设定部,将以第二记录时间点为起点的第二预设时间长度的时间区段设定为开头检测时段,第二对比分贝获取部,在开头检测时段内,获取最高的开头分贝值作为第二对比分贝,对比分贝判断部判断第一对比分贝与第二对比分贝是否具有显著增强特征,当对比分贝判断部的判断结果为否时,调整控制部中断各部的运行,控制第一视频时长获取部将第二视频总长度作为第一视频总长度以及重新开始之后依次运行的各部,当对比分贝判断部的判断结果为是时,第二微表情获取部在第二播放进度到达第二预设时间区间结束的时间点后的0.3~0.5秒时,通过摄像头获取用户的眉部的表情作为第二眉部微表情,眉部对比判断部判断第一眉部微表情与第二眉部微表情是否具有眉部收缩特征,音量控制部,若眉部对比判断部判断结果为是,则控制终端的音量按音量调整比例调小。
本发明提供的利用微表情调整音量的装置,还可以具有这样的技术特征,其中,所述结尾判断比例以视频时长大于10分钟时的最后1分钟或视频时长不大于10分钟时的最后10%作为视频结尾时长。
本发明提供的利用微表情调整音量的装置,还可以具有这样的技术特征,其中,所述显著增强特征为所述第二对比分贝较所述第一对比分贝增加了20db以上的分贝值。
本发明提供的利用微表情调整音量的装置,还可以具有这样的技术特征,其中,所述眉部收缩特征为所述第二眉部微表情较所述第一眉部微表情的眉部间距缩小了10%以上。
本发明提供的利用微表情调整音量的装置,还可以具有这样的技术特征,其中,所述视频采集时间点为每隔0.1秒对音量进行一次采集的各个时间点。
本发明还提供了一种利用微表情调整音量的方法,设置在具有播放部以及摄像头的播放终端中,用于在所述播放终端播放的视频切换时对所述视频的外放音量进行调节,其特征在于,包括如下步骤:步骤s1,监控到所述播放部有正在播放的当前视频;步骤s2,对所述当前视频的播放进度进行检测获取第一视频总长度,并检测所述当前视频的播放情况从而实时地获得当前播放进度,进一步根据所述第一视频总长度通过结尾判断比例计算获得与所述视频结束时间相差一定时间距离的预定检测时间点;步骤s3,在播放所述当前视频到达预定检测时间点时开始按预定的视频采集时间点依次存储所述当前视频的多个播放音量作为结尾段分贝值;步骤s4,从所述结尾段分贝值中将开始小于等于预设的检测分贝值的播放音量所对应的所述视频采集时间点设定为第一记录时间点,当所述当前播放进度到达当前视频结束时仍未满足上述判定条件,以所述当前视频结束的时间点作为所述第一记录时间点;步骤s5,以所述第一记录时间点为终点的第一预设时间长度的时间区段设定为结尾检测时段;步骤s6,在所述结尾检测时段内,获取最高的所述结尾段分贝值作为第一对比分贝;步骤s7,监控到所述当前视频结束后有播放的第二视频;步骤s8,对所述第二视频的播放进度进行检测获取第二视频总长度,并检测所述第二视频的播放情况从而实时地获得第二播放进度;步骤s9,在播放所述第二视频的开始按所述视频采集时间点依次存储所述当前视频的多个播放音量作为开头段分贝值;步骤s10,从所述开头段分贝值中将大于所述检测分贝值的播放音量对应的所述视频采集时间点设定为第二记录时间点;步骤s11,在所述第二播放进度到达第二记录时间点时,通过所述摄像头获取用户的眉部的表情作为第一眉部微表情;步骤s12,以所述第二记录时间点为起点的第二预设时间长度的时间区段设定为开头检测时段;步骤s13,在所述开头检测时段内,获取最高的所述开头分贝值作为第二对比分贝;步骤s14,判断所述第一对比分贝与所述第二对比分贝是否具有显著增强特征;步骤s15,当判断结果为否时,中断各步骤的运行,将第二视频总长度作为第一视频总长度并重新开始步骤s2以及之后依次运行的各步骤;步骤s16,当判断结果为是时,在所述第二播放进度到达所述第二预设时间区间结束的时间点后的0.3~0.5秒时,通过所述摄像头获取用户的眉部的表情作为第二眉部微表情;步骤s17,判断所述第一眉部微表情与所述第二眉部微表情是否具有眉部收缩特征,步骤s18,若判断结果为是,则控制所述终端的音量按预设的音量调整比例调小。
发明作用与效果
根据本发明的利用微表情调整音量的装置,安装在具有摄像头和播放部的播放终端中,在装置启用时,对播放终端正在播放的视频及切换的下一个视频的音量进行采集,通过将两个视频的音量大小对比,判断前后的音量是否有明显的增强,若有则对用户的微表情进行采集,通过处理微表情的图像以此分析出用户潜意识的感觉,最后完成调低音量的动作。从而避免了视频切换导致音量突增引起用户不适的情况,也可以起到一定的保护用户耳朵的效果。
附图说明
图1是本发明的利用微表情调整音量的装置的结构框图;以及
图2是本发明的利用微表情调整音量的方法的流程图。
具体实施方式
以下结合附图来说明本发明的具体实施方式。
<实施例>
本实施例的利用微表情调整音量的装置基于利用微表情调整音量的方法,设置在具有摄像头和播放部的播放终端中,用于对播放部切换视频导致的音量突增进行调整处理。
如图1所示,本实施例的利用微表情调整音量的装置1包括:
预设分贝存储部11、预设时间存储部12、预设音量调整比例存储部13、调整控制部14、第一视频播放动作监控部15、第一视频时长获取部16、第一视频进度检测部17、结尾时段判断部18、第一视频音量存储部19、第一记录时间点设定部20、第一检测时段设定部21、第一对比分贝获取部22、第二视频播放动作监控部23、第二视频时长获取部24、第二视频进度检测部25、第二视频音量存储部26、第二记录时间点设定部27、第一微表情获取部28、第二检测时段设定部29、第二对比分贝获取部30、对比分贝判断部31、第二微表情获取部32、眉部对比判断部33、音量控制部34以及控制上述各部运行的系统控制部35。
预设分贝存储部11存储有预设的检测分贝值,该检测分贝值用于检测终端中播放的视频是否不再产生音量,该检测分贝值一般在35db以下就能取得应有的效果。
预设时间存储部12存储有第一预设时间长度以及第二预设时间长度,第一预设时间长度以及第二预设时间长度的取值范围在5~10秒之间,预设时间长度用于框定视频音量的分贝值的判定区间。
预设音量调整比例存储部13存储有预设的音量调整比例,该音量调整比例可由用户预先设置,用于调节每次音量调整的幅度大小。
第一视频播放动作监控部14监控是否有正在播放的当前视频。
在监控到有视频播放后,调整控制部15就会控制第一视频时长获取部16对当前视频的播放进度进行检测获取第一视频总长度,并控制第一视频进度检测部17检测当前视频的播放情况从而实时地获得当前播放进度,进一步控制结尾时段判断部18根据第一视频总长度通过结尾判断比例计算获得与视频结束时间相差一定时间距离的预定检测时间点。
第一视频音量存储部19在当前播放进度到达预定检测时间点时,开始按预定的视频采集时间点依次存储当前视频的多个播放音量作为结尾段分贝值,该视频采集时间点为每隔0.1秒对视频进行一次采集的各个时间点。
第一记录时间点设定部20从结尾段分贝值中将开始小于等于检测分贝值的播放音量所对应的视频采集时间点设定为第一记录时间点,当播放进度到达当前视频结束时仍未满足上述判定条件,以当前视频结束的时间点作为所述第一记录时间点。第一记录时间点的设定用于检测当前视频的播放音量是否开始静默,规避视频结尾可能产生的消声期或衰声期。
第一检测时段设定部21,将以第一记录时间点为终点的第一预设时间长度的时间区段设定为结尾检测时段。
第一对比分贝获取部22,在结尾检测时段内,获取最高的结尾段分贝值作为第一对比分贝。
第二视频播放动作监控部23监控到当前视频结束后有播放的第二视频,若是没有的话本实施例的系统会进入待机状态并启动第一视频播放动作监控部14。
调整控制部14控制第二视频时长获取部24对第二视频的播放进度进行检测获取第二视频总长度,并控制第二视频进度检测部25检测第二视频的播放情况从而实时地获得第二播放进度。
第二视频音量存储部26在播放部播放第二视频的开始按视频采集时间点依次存储当前视频的多个播放音量作为开头段分贝值。
第二记录时间点设定部27从开头段分贝值中将大于检测分贝值的播放音量对应的视频采集时间点设定为第二记录时间点。第二记录时间点的设定用于规避开头没有音量输出的视频。
第一微表情获取部28,在第二播放进度到达第二记录时间点时,获取用户的眉部的表情作为第一眉部微表情。
第二检测时段设定部29,将以第二记录时间点为起点的第二预设时间长度的时间区段设定为开头检测时段。
第二对比分贝获取部30,在开头检测时段内,获取最高的开头分贝值作为第二对比分贝。
对比分贝判断部31判断第一对比分贝与第二对比分贝是否具有显著增强特征。该显著增强特征为第一对比分贝较第一对比分贝增加了20db以上的分贝值。
当对比分贝判断部31的判断结果为否时,调整控制部14中断各部的运行,控制第一视频时长获取部16将第二视频总长度作为第一视频总长度以及重新开始之后依次运行的各部。
当对比分贝判断部31的判断结果为是时,第二微表情获取部32在第二播放进度到达第二预设时间区间结束的时间点后的0.3~0.5秒时,获取用户的眉部的表情作为第二眉部微表情。
眉部对比判断部判断33第一眉部微表情与第二眉部微表情是否具有眉部收缩特征。具体通过采集到的图像并将其进行二值化处理、canny算法提取边界、根据眉部两眉毛的边界的距离来计算第二眉部微表情中两个眉头的眉头间距相对于其在第一眉部微表情中的缩紧程度。
音量控制部34,若眉部对比判断部判断结果为是,则控制终端的音量按音量调整比例调小。
系统控制部35用于对上述各部的运行进行控制。
图2是本发明的利用微表情调整音量的方法的流程图。
如图2所示,本实施例的利用微表情调整音量的方法100包括如下步骤:
步骤101,当监控到播放终端有正在播放的视频时,开始运行本次方法。
步骤102,检测结束音量峰值,具体为:
对当前视频的播放进度进行检测获取第一视频总长度,并检测当前视频的播放情况从而实时地获得当前播放进度,进一步根据第一视频总长度通过结尾判断比例计算获得与视频结束时间相差一定时间距离的预定检测时间点;
在播放当前视频到达预定检测时间点时开始按预定的视频采集时间点依次存储当前视频的多个播放音量作为结尾段分贝值;
从结尾段分贝值中将开始小于等于预设的检测分贝值的播放音量所对应的视频采集时间点设定为第一记录时间点,当当前播放进度到达当前视频结束时仍未满足上述判定条件,以当前视频结束的时间点作为第一记录时间点;
以第一记录时间点为终点的第一预设时间长度的时间区段设定为结尾检测时段;
在结尾检测时段内,获取最高的结尾段分贝值作为第一对比分贝,该第一对比分贝即结束音量峰值。
步骤103,捕捉第一眉部微表情,具体为:
监控到当前视频结束后有播放的第二视频;
对第二视频的播放进度进行检测获取第二视频总长度,并检测第二视频的播放情况从而实时地获得第二播放进度;
在播放第二视频的开始按视频采集时间点依次存储当前视频的多个播放音量作为开头段分贝值;
从开头段分贝值中将大于检测分贝值的播放音量对应的视频采集时间点设定为第二记录时间点;
在第二播放进度到达第二记录时间点时,通过摄像头获取用户的眉部的表情作为第一眉部微表情。
步骤104,检测开始音量峰值,具体为:
以第二记录时间点为起点的第二预设时间长度的时间区段设定为开头检测时段;
在开头检测时段内,获取最高的开头分贝值作为第二对比分贝,该第二对比分贝即开始音量峰值。
步骤105,判断音量是否具有显著增加的特征,具体为判断第一对比分贝与第二对比分贝是否具有显著增强特征。
步骤106,当步骤105的判断结果为否时,不做调整,并结束本次方法中各步骤的运行,将第二视频总长度作为第一视频总长度并重新开始步骤102以及之后依次运行的各步骤。
步骤107,当步骤105的判断结果为是时,捕捉第二眉部微表情,具体为:
在第二播放进度到达第二预设时间区间结束的时间点后的0.3~0.5秒时,通过摄像头获取用户的眉部的表情作为第二眉部微表情。
步骤108,判断眉部微表情是否存在收缩特征,具体为判断第一眉部微表情与第二眉部微表情是否具有眉部收缩特征。
步骤109,当步骤108的判断结果为否时,不做调整,并结束本次方法中各步骤的运行,将第二视频总长度作为第一视频总长度并重新开始步骤102以及之后依次运行的各步骤。
步骤110,当步骤108的判断结果为是时,按照用户预设比例调小音量。
步骤111,本次方法运行结束,将第二视频总长度作为第一视频总长度并重新开始步骤102以及之后依次运行的各步骤。
实施例作用与效果
根据本实施例提供的利用微表情调整音量的装置,设置在具有摄像头和播放部的播放终端中,在装置启用时,对播放终端正在播放的视频及切换的下一个视频的音量进行采集,通过将两个视频的音量大小对比,判断前后的音量是否有明显的增强,若有则对用户的微表情进行采集,通过处理微表情的图像以此分析出用户潜意识的感觉,最后完成调低音量的动作。从而避免了视频切换导致音量突增引起用户不适的情况,也可以起到一定的保护用户耳朵的效果。
根据本实施例的结尾判断比例设定,为视频时长大于10分钟时的最后1分钟或视频时长不大于10分钟时的最后10%,由于视频很少在结束留白一分钟以上,以视频结束前一分钟作为音量监测的区间可以满足系统对音量检测的需求。
根据本实施例的显著增强特征设定,为第二对比分贝较第一对比分贝增加20db以上的分贝值,对于一般适耳强度的播放音量,20db的分贝增量将引起用户的些许不适。
根据本实施例的眉部收缩特征设定,为第二眉部微表情较第一眉部微表情的眉部间距缩小10%以上,眉头间距缩紧的比例大于10%在一般情况下能较为准确的判断出用户存在皱眉的情况。
根据本实施例的视频采集时间点设定,为每隔0.1秒对音量进行一次采集的各个时间点,可以有效地避免系统对音量样本的过多采集从而占用播放终端的运作。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
例如,实施例中,利用微表情调整音量的装置的设置主体播放终端为具有摄像头以及播放部的播放设备。但在本发明中,不具有摄像头的播放设备也可以通过外置连接的摄像装置运行本实施例的装置。
- 还没有人留言评论。精彩留言会获得点赞!