一种适用于深度学习的通信数据编码方法与流程
本发明涉及网络通信检测及深度学习技术领域,具体为一种适用于深度学习的通信数据编码方法。
背景技术:
深度学习方法被认为具有高度的认知能力和数据抽取能力,被广泛应用于计算机视觉、图像处理、语音识别等领域。与此同时,近年来深度学习也被大量应用于网络通信行为检测方面。然而,深度学习算法对数据的输入具有严格的要求,网络通信分析领域与图像分析领域的数据特点具有一定的差异。在现有的网络通信检测领域的研究中,根据深度学习算法输入类型的不同,可以将这些工作分为基于特征的研究方法和基于原始数据的研究方法。
(1)基于特征的研究方法
基于特征的研究方法直接利用已有的、预定义的通信特征作为输入,而深度学习算法只是作为分类器的角色存在。一些方法采用著名的kdd-99数据集或nsl-kdd数据集来训练检测模型,这些数据集提供了预定义的41个特征,因此这类研究方法将数据集提供的41维特征直接作为深度学习算法的输入,用来训练检测而模型。此外,还有其他研究将基于专家知识设计的特征作为深度学习算法的输入,如不同属性(如数据包、字节数、会话数等)的统计数据(如sum、max、min、均值、方差、偏差、信息熵等)。
(2)基于原始数据的研究方法
基于原始数据的研究方法主要采用深度学习算法从原始网络流量数据中自动学习通信特征表示,从而避免了特征工程。一些方法从大量未标记的原始网络流量数据中自动地学习有效的特征表示,在这类方法中,网络会话中的头部信息和部分有效负载的原始数据被作为深度学习算法的输入数据,用来提取网络通信特征。另一些方法将网络流量的前n个字节的原始数据表示为图像,然后基于cnn、autoencoder、dbn等方法进行特征表示学习。
现有研究主要关注预先提取好的特征或网络流量的payload数据,而较少关注netflow、netstream、ipfix等通信数据。基于特征的研究方法直接使用基于专家知识构造的通信特征作为输入,而未充分利用深度学习的特征自动提取能力和优势。基于原始数据的研究方法通常关注于流量负载,而不是异构的通信数据。对于负载长度不一致问题,这类方法主要采取简单的截断方法(只保留了前n个字节)。然而,在大规模网络流量应用场景下的网络异常检测、网络应用识别、网络行为分析等领域,网络流量数据通常以获取及存储成本较低、扩展性较好的netflow、netstream、ipfix等格式表示。然而,异构通信数据具有不同尺度、不同规模等特性,无法直接应用于深度学习场景,具体表现在以下两个方面:1)原始的通信数据具有尺度差异性,在图像识别领域,作为深度学习算法输入的像素数据具有相同量纲,而一条netflow记录由不同尺度的属性构成,如发包数、字节数、持续时间等属性,它们的量纲各不相同,甚至数据类型也有差异;2)原始的结构化通信数据具有规模差异性,在图像识别领域,作为深度学习训练样本的图像数据具有相同的尺寸,而不同通信节点间的netflow序列,在时间和空间上都表现为不同的规模,如不同通信节点间netflow序列的长度不同,即使netflow序列长度相同,总的通信持续时长也未必相同。因此,原始的结构化通信数据无法直接作为深度学习算法的输入进行应用。
技术实现要素:
针对上述问题,本发明的目的在于提供一种适用于深度学习的通行数据编码方法,在尽量保留通信时空特性的基础上,实现对异构通信数据的编码。该方法能够很好地解决深度学习在流量数据上的特征自动提取问题,同时也能为网络行为分析、网络应用识别等其他相关通信行为分析领域带来深刻的借鉴作用。技术方案如下:
一种适用于深度学习的通信数据编码方法,包括以下步骤:
步骤1:将各种格式的流级通信数据进行预处理,规范化成特定的flow格式,保留信息抽取和编码需要的特定字段;
步骤2:将具有相同源ip和目的ip的flow数据f聚合在一个集合中,形成通信对:nf(x→y)=<f1,f2,…,fn>,一个通信对内的所有flow数据表示通信节点x和y之间的所有通信记录;
步骤3:将通信对内的flow数据记录按流的开始时间进行排序,根据前后两条流的开始时间之差计算时间间隔,新增时间间隔字段,形成新的通信对nf′(x→y);
步骤4:根据每条flow数据中包含的字段,将nf′(x→y)内的flow序列拆解成对应的属性值序列,每个字段对应一个属性值序列avs;
步骤5:利用空间金字塔池化方法,对每个属性值序列avs进行编码,将其编码成定长数据;
步骤6:在对每个属性值序列avs编码后,将其拼接,形成原始特征向量fv;
步骤7:将原始特征向量fv进行归一化,生成统一的原始特征向量fv′,作为对任何长度的流记录序列的编码数据。
进一步的,所述步骤5中基于空间金字塔池化方法进行数据编码的计算过程为:
步骤51:将各属性值序列avs依次平均分割成1、2、4、8、……、2l-1块,l表示金字塔的层数;
步骤52:分别计算每块数据的平均数、总数和众数,从每块数据中抽取出3个值;
步骤53:将这些值进行拼接,每个属性值序列avs将产生3*(2l-1)个值。
更进一步的,所述步骤2之后还包括:过滤掉flow记录数小于2l-1的通信对。
更进一步的,对通信对内长度不定的flow数据进行编码时,同时保留通信节点间通信行为的空间特性和时间特性;对于对应的属性值的统计情况和分布情况的字段进行了进一步的选择,将源端口、目的端口、字节数、包数字段加入到待编码字段中;
对于与通信时间相关以及各类字段对应的属性值随时间变化的趋势的字段进行进一步处理:将通信对内的flow记录按time字段从小到大进行排序,根据前后两条流的time之差计算时间间隔,同时将时间间隔和持续时间字段加入到待编码字段中。
更进一步的,所述步骤7中将原始特征向量fv进行归一化采用z-score标准化方法,计算函数为:
式中,x为原始特征向量初始值,x*为原始特征向量标准值;μ为均值,σ为标准差。
本发明的有益效果是:本发明能够自动将任何长度的flow序列编码成定长的原始特征向量,使这类不规则的异构通信数据能够应用于深度学习的场景中;在不需要专家知识介入的情况下,能够充分保留通信行为在时间和空间方面的特性,从而使编码后的数据能够充分代表节点之间的通信特征,从而应用到各类通信行为分析任务中。
附图说明
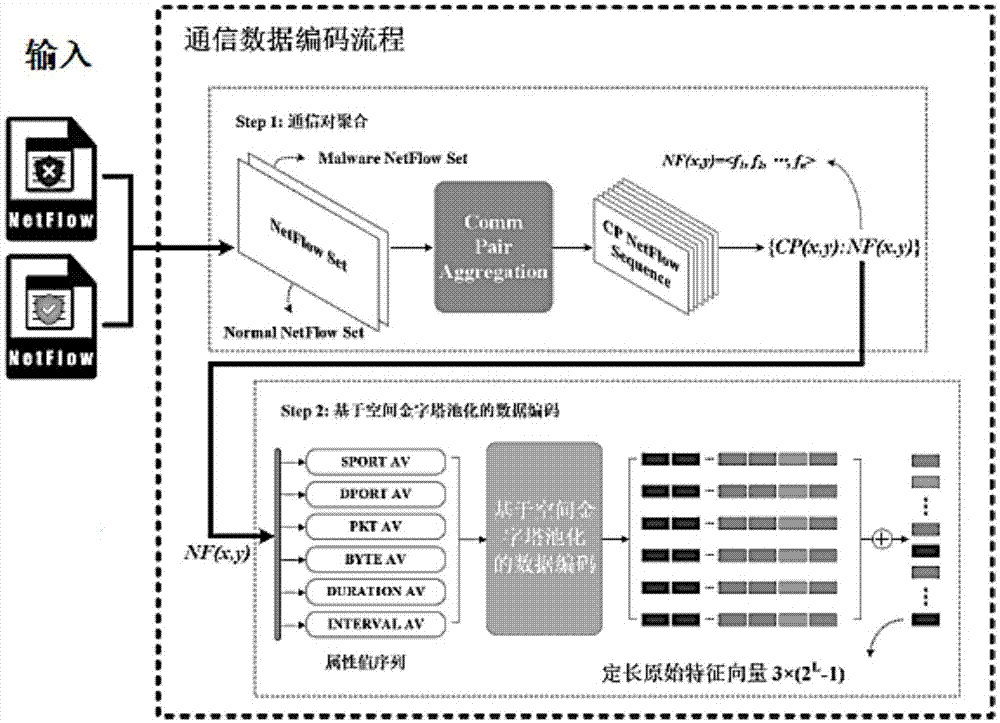
图1为本发明中通信数据编码流程图。
图2为本发明中基于金字塔池化思想的数据编码方法示意图。
图3为本发明中基于cnn的特征提取流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细说明。本发明方法在具体实施时的流程如图1所示,主要包括以下步骤:
a.对流级通信数据进行预处理,聚合成ip通信对;
b.对ip通信对内的flow记录进行排序,并抽取出需要编码的字段及对应的属性值序列;
c.基于金字塔池化方法对各属性值序列进行编码,拼接成原始的特征向量;
d.对形成的原始特征向量进行归一化处理,并应用到深度神经网络中进行验证。
所述步骤a中的各种格式的流级通信数据包括nstflow、netstream、ipfix等xflow类型,这类数据提供了节点之间数据通信的流级视图,包括了一段通信时间内的数据包统计信息。每种xflow类型都提供了自定义的格式和协议,为了对这类流级通信数据进行统一处理,本发明针对通信行为分析中关注的属性,以及这类协议共同包含的字段,提取出统一的flow格式。所述flow格式的字段类型包括源ip(sip)、目的ip(dip)、源端口(sport)、目的端口(dport)、协议(prot)、字节数(bytes)、包数(pkts)、持续时间(duration)、流开始时间(time)、时间间隔(interval)等。为了对节点之间的通信行为进行分析,本发明以源ip和目的ip为key,对flow数据进行聚合,具有相同源ip和目的ip的flow将被聚在一个集合中,作为一个通信对进行处理。本发明的主要目标就是对一个通信对内的flow数据(长度不定)进行编码,使其适用于深度学习算法。在步骤a操作过程中需要注意的是,为了能够在步骤c中对属性值序列进行分块处理,在步骤a中需要过滤部分flow记录数未达到要求的通信对,如为了能够对属性值序列均分成8份,那么就要求通信对内的flow记录数必须大于或等于8,因此,flow记录数小于8的那些通信对将被过滤。
在所述步骤b中,为了对一个通信对内的flow数据(长度不定)进行编码,同时保留通信节点间通信行为的时空统计特性,本发明对通信对内的flow序列进行了针对性的操作。操作内容主要包括以下两个方面:
1)保留通信行为的空间特性:通信行为的空间特性主要体现在各种字段对应的属性值的统计情况和分布情况,本专利针对这类关注的字段进行了进一步的选择,包括源端口(sport)、目的端口(dport)、字节数(bytes)、包数(pkts)等,将这些字段加入到待编码字段;
2)保留通信行为的时间特性:通信行为的时间特性主要体现在与通信时间相关的一些特性以及上述各类字段对应的属性值随时间变化的趋势,因此本专利将通信对内的flow记录按time字段从小到大进行排序,根据前后两条流的time之差计算时间间隔,新增了时间间隔字段(interval),第一条流的interval属性值根据第二条流的interval属性值进行设置。同时将时间间隔(interval)和持续时间(duration)字段加入到待编码字段中。
基于以上操作确定了编码字段后,则将flow序列拆解成相应的属性值序列,包括源端口(sport)、目的端口(dport)、字节数(bytes)、包数(pkts)、时间间隔(interval)和持续时间(duration)等属性值序列,令a为待编码的字段集合,则|a|表示待编码的字段数,这将影响最后编码得到的原始特征向量的长度。
在所述步骤c中,根据金字塔层数l,每个属性值序列将被分别均分成1、2、4、8、……、2l-1块,然后进行不同尺度的数据抽取,抽取过程为计算每个数据块的统计特性,抽取的原理如图2所示。为了保留属性值序列的各类统计特性和变化趋势,本发明从平均特性、总量特性及集中特性三个方面对数据块内的统计信息进行抽取,分别计算每块数据的平均数、总数和众数,从而从每块数据中抽取出3个值。然后,将这些值进行拼接,那么一个属性值序列avs将产生3*(1+2+4+……)=3*(2l-1)个原始特征,一个通信对将产生3*|a|*(2l-1)个原始特征。
在所述步骤d中,我们对编码得到的长度为3*|a|*(2l-1)的原始特征向量进行归一化,常用的归一化方法包括min-max标准化、z-score标准化等方法。鉴于实际网络环境下的通信数据复杂多样,各通信对的差别较大,本发明采用z-score标准化方法。这类方法基于均值μ和标准差σ对数据进行归一化,计算函数为:
基于步骤a~d编码得到的原始特征向量,能够直接应用到深度学习算法中进行应用。当应用于深度神经网络(dnn)时,拼接得到的一维原始特征向量可直接作为input输入到神经网络中;当应用于卷积神经网络(cnn)时,则需要将一维原始特征向量转换成二维形式,如公式2所示:
w×h=3×|a|×(2l-1)(2)
其中w和h分别表示二维特征向量的宽和高,初始特征向量应用到卷积神经网络的示意图如图3所示。
- 还没有人留言评论。精彩留言会获得点赞!