一种分布式智能邮件分析过滤方法、系统及存储介质与流程
本发明涉及邮件数据处理技术领域,特别是一种分布式智能邮件分析过滤方法、系统及存储介质。
背景技术:
邮件是局域网及互联网上的一种常用沟通交流方式,对大部分企业,特别是涉及进出口贸易的企业,更是一种必不可少的沟通方式。邮件承载着包括联系人、主题内容、收发时间、附件数据及地理位置在内的多种有效信息,对于取证分析人员来说,是非常有价值的数据。
目前取证分析人员有两种基本的方式进行分析,一是把邮件统一导入某个邮件客户端中,利用邮件客户端进行每封邮件的内容查看,并利用邮件客户端自带的搜索功能进行关键字搜索。二是通过单机取证软件解析出所有邮件,在取证软件中以列表的方式查看所有邮件。
但对于目前动辄上百gb、百万封数量级的涉案邮件,传统的分析方法及工具效率低下,邮件间的关联关系多为人工梳理,且只能单兵作战无法协作分析,显然这种方式已不再适用海关稽查走私、企业内部调查等海量邮件分析的场景。
可见,现有技术的主要缺陷在于:一是软件为单机版,分析速度受限于单台机器性能,且无法协同分析,无法应对日益庞大的海量邮件数据的快速处理。二是分析结果通常使用传统关系型数据库存储,当数据量增长时,搜索过滤的速度会明显下降,降低分析效率。三是对邮件内容的处理仅局限于邮件正文,对于附件中的文档、图片、压缩包等数据无法有效检索,并且没有对正文和附件做进一步的数据挖掘,仍然需要大量人工阅读工作来发掘其中的线索。四是邮箱地址之间的关系、邮件之间的关系多为人工梳理,无法展示。
技术实现要素:
本发明针对上述现有技术中的缺陷,提出了如下技术方案。
一种分布式智能邮件分析过滤方法,该方法包括:
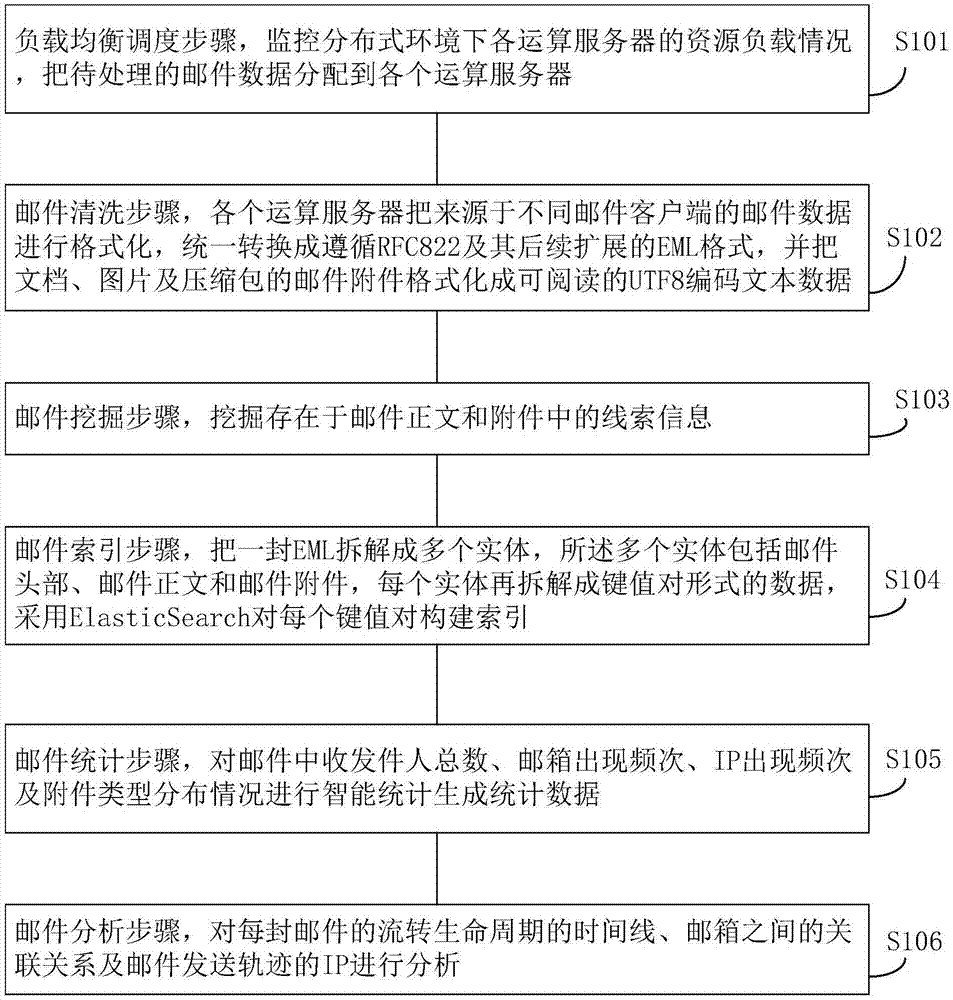
负载均衡调度步骤,监控分布式环境下各运算服务器的资源负载情况,把待处理的邮件数据分配到各个运算服务器;
邮件清洗步骤,各个运算服务器把来源于不同邮件客户端的邮件数据进行格式化,统一转换成遵循rfc822及其后续扩展的eml格式,并把文档、图片及压缩包的邮件附件格式化成可阅读的utf8编码文本数据;
邮件挖掘步骤,挖掘存在于邮件正文和附件中的线索信息;
邮件索引步骤,把一封eml拆解成多个实体,所述多个实体包括邮件头部、邮件正文和邮件附件,每个实体再拆解成键值对形式的数据,采用elasticsearch对每个键值对构建索引;
邮件统计步骤,对邮件中收发件人总数、邮箱出现频次、ip出现频次及附件类型分布情况进行智能统计生成统计数据;
邮件分析步骤,对每封邮件的流转生命周期的时间线、邮箱之间的关联关系及邮件发送轨迹的ip进行分析。
更进一步地,所述负载均衡调度步骤的操作为:将待处理的邮件数据上传至分布式存储上,并调用预处理器对邮件数据进行任务归类和拆分的预处理;预处理后的任务记录着任务类别、数据偏移及文件数量信息,将以json格式发送给调度中心进行统一调度;调度中心实时监测各个运算服务器的内存、cpu及磁盘io资源的负载情况,把部分任务平均分配给运算服务器,并对长期未响应的任务进行回收重新分配;运算服务器根据当前的资源使用情况,动态创建若干进程和若干线程进行任务的批量处理。
更进一步地,所述邮件清洗步骤的操作为:各个运算服务器解析各种邮件客户端的数据文件格式,提取每一封邮件的正文信息和附件信息,把提取到的正文信息格式化成遵循rfc822及其后续扩展的eml格式,并写入位于分布式存储上的结果报告目录下,通过文本提取模块将附件信息转换成类型为text/plain以utf-8编码的纯文本。
更进一步地,所述邮件挖掘步骤的操作为:将清洗出的纯文本利用正则表达式筛选出初步符合条件的手机号、身份证号、邮箱地址、快递单号、报关单号和集装箱号信息;如果筛选出的号码是符合内置正则表达式的,则对筛选出来的号码进行分割,提取区号、编码及校验位信息,对号码进行规则计算,若计算结果与校验位相同,则将该号码与身份标识库中已收集的编码规则进行比较,若匹配则同时入库编码对应的文本信息并记录号码对应的分类、来源及偏移信息并入库;如果筛选出的号码是符合用户自定义正则表达式的,则直接记录该号码对应的分类、来源及偏移信息并入库。
更进一步地,所述邮件索引步骤的操作为:各个计算服务器把一封eml邮件拆分成多个实体,所述多个实体包括邮件头、邮件正文和邮件附件,并生成一个随机的guid作为这封邮件的这几个实体之间的共同关联关系;将邮件头再拆分成key/value的形式作为邮件头部属性,key为属性名,value为属性值,并把value分别以text和keyword格式录入elasticsearch进行索引,text用于搜索,keyword用于过滤;对于收件人、抄送及暗送有多个value的属性,keyword存储为数组格式,对于时间类型属性,把value拆分为年月日yyyy、yyyymm、yyyymmdd三种形式进行索引;对邮件正文分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件正文属性;对邮件附件分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件附件属性;将guid、邮件头部属性和邮件正文属性拼接成一条邮件类型记录,将guid、邮件头部属性和邮件附件属性拼接成一条附件类型记录,创建邮件标志位表,以父子关系为所述邮件类型记录和附件类型记录分别创建一条子记录。
更进一步地,所述邮件统计步骤的操作为:根据用户选择的过滤条件,创建过滤集filterset,对过滤集filterset使用elasticsearch的term接口,对发件人地址from_address及收件人地址to_address属性的不重复值进行统计,统计出收发件人总数,对客户ip_client和服务器ip_server属性进行不重复值的统计,计算出ip出现频次,对附件类型file_type属性进行不重复值的统计,计算出附件类型的分布情况。
更进一步地,所述邮件分析步骤的操作为:以所选邮件的邮件idmessage-id作为查询条件,使用elasticsearch的query接口,对所有邮件的邮件idmessage-id和引用idreferences属性进行查询,对查询结果进行以发送时间sendtime进行排序,按时间顺序展示出邮件的流转生命周期,对所有邮件的发件人地址from_address及收件人地址to_address字段进行term过滤,筛选出所有的收发件人,根据收件人和发件人,绘制账号之间的关联关系。
本发明还提出了一种分布式智能邮件分析过滤系统,该系统包括:
负载均衡调度模块,用于监控分布式环境下各运算服务器的资源负载情况,把待处理的邮件数据分配到各个运算服务器;
邮件清洗模块,用于各个运算服务器把来源于不同邮件客户端的邮件数据进行格式化,统一转换成遵循rfc822及其后续扩展的eml格式,并把文档、图片及压缩包的邮件附件格式化成可阅读的utf8编码文本数据;
邮件挖掘模块,用于挖掘存在于邮件正文和附件中的线索信息;
邮件索引模块,用于把一封eml拆解成多个实体,所述多个实体包括邮件头部、邮件正文和邮件附件,每个实体再拆解成键值对形式的数据,采用elasticsearch对每个键值对构建索引;
邮件统计模块,用于对邮件中收发件人总数、邮箱出现频次、ip出现频次及附件类型分布情况进行智能统计生成统计数据;
邮件分析模块,用于对每封邮件的流转生命周期的时间线、邮箱之间的关联关系及邮件发送轨迹的ip进行分析。
更进一步地,所述负载均衡调度模块执行的操作为:将待处理的邮件数据上传至分布式存储上,并调用预处理器对邮件数据进行任务归类和拆分的预处理;预处理后的任务记录着任务类别、数据偏移及文件数量信息,将以json格式发送给调度中心进行统一调度;调度中心实时监测各个运算服务器的内存、cpu及磁盘io资源的负载情况,把部分任务平均分配给运算服务器,并对长期未响应的任务进行回收重新分配;运算服务器根据当前的资源使用情况,动态创建若干进程和若干线程进行任务的批量处理。
更进一步地,所述邮件清洗模块执行的操作为:各个运算服务器解析各种邮件客户端的数据文件格式,提取每一封邮件的正文信息和附件信息,把提取到的正文信息格式化成遵循rfc822及其后续扩展的eml格式,并写入位于分布式存储上的结果报告目录下,通过文本提取模块将附件信息转换成类型为text/plain以utf-8编码的纯文本。
更进一步地,所述邮件挖掘模块执行的操作为:将清洗出的纯文本利用正则表达式筛选出初步符合条件的手机号、身份证号、邮箱地址、快递单号、报关单号和集装箱号信息;如果筛选出的号码是符合内置正则表达式的,则对筛选出来的号码进行分割,提取区号、编码及校验位信息,对号码进行规则计算,若计算结果与校验位相同,则将该号码与身份标识库中已收集的编码规则进行比较,若匹配则同时入库编码对应的文本信息并记录号码对应的分类、来源及偏移信息并入库;如果筛选出的号码是符合用户自定义正则表达式的,则直接记录该号码对应的分类、来源及偏移信息并入库。
更进一步地,所述邮件索引模块执行的操作为:各个计算服务器把一封eml邮件拆分成多个实体,所述多个实体包括邮件头、邮件正文和邮件附件,并生成一个随机的guid作为这封邮件的这几个实体之间的共同关联关系;将邮件头再拆分成key/value的形式作为邮件头部属性,key为属性名,value为属性值,并把value分别以text和keyword格式录入elasticsearch进行索引,text用于搜索,keyword用于过滤;对于收件人、抄送及暗送有多个value的属性,keyword存储为数组格式,对于时间类型属性,把value拆分为年月日yyyy、yyyymm、yyyymmdd三种形式进行索引;对邮件正文分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件正文属性;对邮件附件分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件附件属性;将guid、邮件头部属性和邮件正文属性拼接成一条邮件类型记录,将guid、邮件头部属性和邮件附件属性拼接成一条附件类型记录,创建邮件标志位表,以父子关系为所述邮件类型记录和附件类型记录分别创建一条子记录。
更进一步地,所述邮件统计模块执行的操作为:根据用户选择的过滤条件,创建过滤集filterset,对过滤集filterset使用elasticsearch的term接口,对发件人地址from_address及收件人地址to_address属性的不重复值进行统计,统计出收发件人总数,对客户ip_client和服务器ip_server属性进行不重复值的统计,计算出ip出现频次,对附件类型file_type属性进行不重复值的统计,计算出附件类型的分布情况。
更进一步地,所述邮件分析模块执行的操作为:以所选邮件的邮件idmessage-id作为查询条件,使用elasticsearch的query接口,对所有邮件的邮件idmessage-id和引用idreferences属性进行查询,对查询结果进行以发送时间sendtime进行排序,按时间顺序展示出邮件的流转生命周期,对所有邮件的发件人地址from_address及收件人地址to_address字段进行term过滤,筛选出所有的收发件人,根据收件人和发件人,绘制账号之间的关联关系。
本发明还提出了一种计算机可读存储介质,所述存储介质上存储有计算机程序代码,当所述计算机程序代码被计算机执行时执行上述之任一的方法。
本发明的技术效果为:本发明通过将邮件分发到多台运算服务器上进行并发处理,抽取邮件元素,并对附件中的文档、图片及压缩包等文件进行文本提取及ocr字符识别,对提取出的信息再自动进行数据挖掘及分类,最终按一定规则入库到elasticsearch中,在elasticsearch中可以快速对海量邮件进行灵活过滤、智能统计、可视化关联分析及全文检索,帮助办案人员直观、快速找到线索,一举解决涉案邮件数据庞大、人工浏览单兵作战时间长、效率低的问题。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显。
图1是根据本发明的实施例的一种分布式智能邮件分析过滤方法的流程图。
图2是根据本发明的实施例的负载均衡调度步骤的流程图。
图3是根据本发明的实施例的邮件清洗步骤的流程图。
图4是根据本发明的实施例的邮件挖掘步骤的流程图。
图5是根据本发明的实施例的邮件索引步骤的流程图。
图6是根据本发明的实施例的邮件统计步骤和邮件分析步骤的流程图。
图7是根据本发明的实施例的一种分布式智能邮件分析过滤系统的结构图。
具体实施方式
下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
图1示出了本发明的一种分布式智能邮件分析过滤方法,该方法包括:
负载均衡调度步骤s101,监控分布式环境下各运算服务器的资源负载情况,把待处理的邮件数据分配到各个运算服务器。
邮件清洗步骤s102,各个运算服务器把来源于不同邮件客户端的邮件数据进行格式化,统一转换成遵循rfc822及其后续扩展的eml格式,并把文档、图片及压缩包的邮件附件格式化成可阅读的utf8编码文本数据,对附件中的文档、及压缩包等的文档文件(如word、pdf等格式的文件)可以直接进行文本提取,但是对于图片中的文本需要进行ocr字符识别后进行文本提取。
邮件挖掘步骤s103,挖掘存在于邮件正文和附件中的线索信息。线索信息可以是通用类的手机号、身份证号、邮箱地址等信息,行业类信息,如海关类的快递单号、报关单号和集装箱号等信息。
邮件索引步骤s104,把一封eml拆解成多个实体,所述多个实体包括邮件头部、邮件正文和邮件附件,每个实体再拆解成键值对形式的数据,采用elasticsearch对每个键值对构建索引。
邮件统计步骤s105,对邮件中收发件人总数、邮箱出现频次、ip出现频次及附件类型分布情况进行智能统计生成统计数据。
邮件分析步骤s106,对每封邮件的流转生命周期的时间线、邮箱之间的关联关系及邮件发送轨迹的ip进行分析。
图2示出了负载均衡调度步骤s101的操作为:将待处理的邮件数据(如outlook的pst文件、foxmail的box文件、lotusnotes的nsf文件、thunderbird的mbox文件等)上传至分布式存储上,并调用预处理器对邮件数据进行任务归类和拆分的预处理;预处理后的任务记录着任务类别、数据偏移及文件数量信息,将以json格式发送给调度中心进行统一调度;调度中心实时监测各个运算服务器的内存、cpu及磁盘io资源的负载情况,把部分任务平均分配给运算服务器,并对长期未响应的任务进行回收重新分配;运算服务器根据当前的资源使用情况,动态创建若干进程和若干线程进行任务的批量处理。这样将海量的邮件数据进行分布式处理,提高了处理效率,该负载调度方式这是本发明的重要发明点之一。
图3示出了邮件清洗步骤s102的操作为:各个运算服务器解析各种邮件客户端的数据文件格式,提取每一封邮件的正文信息和附件信息,把提取到的正文信息格式化成遵循rfc822及其后续扩展的eml格式,并写入位于分布式存储上的结果报告目录下,通过文本提取模块将附件信息转换成类型为text/plain以utf-8编码的纯文本。邮件数据的统一格式化是海量的邮件数据进行分布式处理的前提,这是本发明的重要发明点之一
图4示出了所述邮件挖掘步骤s103,这也是本发明的一个重要发明点,其操作为:将清洗出的纯文本利用正则表达式筛选出初步符合条件的手机号、身份证号、邮箱地址、快递单号、报关单号和集装箱号信息;如果筛选出的号码是符合内置正则表达式的,则对筛选出来的号码进行分割,提取区号、编码及校验位信息,对号码进行规则计算,若计算结果与校验位相同,则将该号码与身份标识库中已收集的编码规则进行比较,若匹配则同时入库编码对应的文本信息并记录号码对应的分类、来源及偏移信息并入库;如果筛选出的号码是符合用户自定义正则表达式的,则直接记录该号码对应的分类、来源及偏移信息并入库。可见,在所述邮件挖掘中,除系统内置的规则外,还允许用户自定义线索规则进行数据挖掘,方便了用户的使用。
图5示出了所述邮件索引步骤s104,这是邮件后续分析统计的基础,是本发明的重要发明点,其操作为:各个计算服务器把一封eml邮件拆分成多个实体,所述多个实体包括邮件头、邮件正文和邮件附件,并生成一个随机的guid作为这封邮件的这几个实体之间的共同关联关系;将邮件头再拆分成key/value的形式作为邮件头部属性,key为属性名,value为属性值,并把value分别以text和keyword格式录入elasticsearch进行索引,text用于搜索,keyword用于过滤;对于收件人、抄送及暗送有多个value的属性,keyword存储为数组格式,对于时间类型属性,把value拆分为年月日yyyy、yyyymm、yyyymmdd三种形式进行索引;对邮件正文分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件正文属性;对邮件附件分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件附件属性;将guid、邮件头部属性和邮件正文属性拼接成一条邮件类型记录,将guid、邮件头部属性和邮件附件属性拼接成一条附件类型记录,创建邮件标志位表,以父子关系为所述邮件类型记录和附件类型记录分别创建一条子记录。本发明采用一元分词和语义分词两种分词器对正文及附件信息进行索引,以满足精确搜索和语义搜索两种不同的需求;且在构建索引时,除邮件分析表外,还额外创建一张标志位表作为邮件分析表的子表,把后续对邮件的打标签、排除等操作以独立的表格进行处理,子表的更新不影响父表的数据,即可满足快速过滤的需求,提高了处理性能,这是本发明的另一个重要发明点。
本发明设计的索引表把邮件正文记录和附件记录以相同的表结构存储,根据所需操作为每个字段存储多种类型格式,同时每种类型记录只存储必要的字段,即节省空间,又可方便进行统计、过滤、搜索、分析等操作。在一个实施例中,本发明的表结构设计摘要如下:
该表格是本发明的一个示例性表格,本领域技术人员可以设计其他的表格实现数据项的存储。
图6示出了所述邮件统计步骤s105和邮件分析步骤s106的操作,邮件统计步骤s105为:根据用户选择的过滤条件,创建过滤集filterset,对过滤集filterset使用elasticsearch的term接口,对发件人地址from_address及收件人地址to_address属性的不重复值进行统计,统计出收发件人总数,对客户ip_client和服务器ip_server属性进行不重复值的统计,计算出ip出现频次,对附件类型file_type属性进行不重复值的统计,计算出附件类型的分布情况。所述邮件分析步骤s106的操作为:以所选邮件的邮件idmessage-id作为查询条件,使用elasticsearch的query接口,对所有邮件的邮件idmessage-id和引用idreferences属性进行查询,对查询结果进行以发送时间sendtime进行排序,按时间顺序展示出邮件的流转生命周期,对所有邮件的发件人地址from_address及收件人地址to_address字段进行term过滤,筛选出所有的收发件人,根据收件人和发件人,绘制账号之间的关联关系。从而实现了可以快速对海量邮件进行过滤、智能统计、可视化关联分析及全文检索。这也是本发明的另一个重要发明点。
进一步参考图7,作为对上述图1所示方法的实现,本申请提供了一种分布式智能邮件分析过滤系统的一个实施例,该系统实施例与图1所示的方法实施例相对应,该系统具体可以包含于各种电子设备中。
图7示出了本发明的一种分布式智能邮件分析过滤系统,该系统包括:
负载均衡调度模块701,用于监控分布式环境下各运算服务器的资源负载情况,把待处理的邮件数据分配到各个运算服务器。
邮件清洗模块702,用于各个运算服务器把来源于不同邮件客户端的邮件数据进行格式化,统一转换成遵循rfc822及其后续扩展的eml格式,并把文档、图片及压缩包的邮件附件格式化成可阅读的utf8编码文本数据,对附件中的文档、及压缩包等的文档文件(如word、pdf等格式的文件)可以直接进行文本提取,但是对于图片中的文本需要进行ocr字符识别后进行文本提取。
邮件挖掘模块703,用于挖掘存在于邮件正文和附件中的线索信息。线索信息可以是通用类的手机号、身份证号、邮箱地址等信息,行业类信息,如海关类的快递单号、报关单号和集装箱号等信息。
邮件索引模块704,用于把一封eml拆解成多个实体,所述多个实体包括邮件头部、邮件正文和邮件附件,每个实体再拆解成键值对形式的数据,采用elasticsearch对每个键值对构建索引。
邮件统计模块705,用于对邮件中收发件人总数、邮箱出现频次、ip出现频次及附件类型分布情况进行智能统计生成统计数据。
邮件分析模块706,用于对每封邮件的流转生命周期的时间线、邮箱之间的关联关系及邮件发送轨迹的ip进行分析。
图2示出了负载均衡调度模块701执行的操作为:将待处理的邮件数据(如outlook的pst文件、foxmail的box文件、lotusnotes的nsf文件、thunderbird的mbox文件等)上传至分布式存储上,并调用预处理器对邮件数据进行任务归类和拆分的预处理;预处理后的任务记录着任务类别、数据偏移及文件数量信息,将以json格式发送给调度中心进行统一调度;调度中心实时监测各个运算服务器的内存、cpu及磁盘io资源的负载情况,把部分任务平均分配给运算服务器,并对长期未响应的任务进行回收重新分配;运算服务器根据当前的资源使用情况,动态创建若干进程和若干线程进行任务的批量处理。这样将海量的邮件数据进行分布式处理,提高了处理效率,该负载调度方式这是本发明的重要发明点之一。
图3示出了邮件清洗模块702执行的操作为:各个运算服务器解析各种邮件客户端的数据文件格式,提取每一封邮件的正文信息和附件信息,把提取到的正文信息格式化成遵循rfc822及其后续扩展的eml格式,并写入位于分布式存储上的结果报告目录下,通过文本提取模块将附件信息转换成类型为text/plain以utf-8编码的纯文本。邮件数据的统一格式化是海量的邮件数据进行分布式处理的前提,这是本发明的重要发明点之一
图4示出了所述邮件挖掘模块703执行的操作,这也是本发明的一个重要发明点,其操作为:将清洗出的纯文本利用正则表达式筛选出初步符合条件的手机号、身份证号、邮箱地址、快递单号、报关单号和集装箱号信息;如果筛选出的号码是符合内置正则表达式的,则对筛选出来的号码进行分割,提取区号、编码及校验位信息,对号码进行规则计算,若计算结果与校验位相同,则将该号码与身份标识库中已收集的编码规则进行比较,若匹配则同时入库编码对应的文本信息并记录号码对应的分类、来源及偏移信息并入库;如果筛选出的号码是符合用户自定义正则表达式的,则直接记录该号码对应的分类、来源及偏移信息并入库。可见,在所述邮件挖掘中,除系统内置的规则外,还允许用户自定义线索规则进行数据挖掘,方便了用户的使用。
图5示出了所述邮件索引模块704执行的操作,这是邮件后续分析统计的基础,是本发明的重要发明点,其操作为:各个计算服务器把一封eml邮件拆分成多个实体,所述多个实体包括邮件头、邮件正文和邮件附件,并生成一个随机的guid作为这封邮件的这几个实体之间的共同关联关系;将邮件头再拆分成key/value的形式作为邮件头部属性,key为属性名,value为属性值,并把value分别以text和keyword格式录入elasticsearch进行索引,text用于搜索,keyword用于过滤;对于收件人、抄送及暗送有多个value的属性,keyword存储为数组格式,对于时间类型属性,把value拆分为年月日yyyy、yyyymm、yyyymmdd三种形式进行索引;对邮件正文分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入eontent字段及content.cn字段作为邮件正文属性;对邮件附件分别以一元分词和中文语义分词两种分词器进行分词处理,并分别存入content字段及content.cn字段作为邮件附件属性;将guid、邮件头部属性和邮件正文属性拼接成一条邮件类型记录,将guid、邮件头部属性和邮件附件属性拼接成一条附件类型记录,创建邮件标志位表,以父子关系为所述邮件类型记录和附件类型记录分别创建一条子记录。本发明采用一元分词和语义分词两种分词器对正文及附件信息进行索引,以满足精确搜索和语义搜索两种不同的需求;且在构建索引时,除邮件分析表外,还额外创建一张标志位表作为邮件分析表的子表,把后续对邮件的打标签、排除等操作以独立的表格进行处理,子表的更新不影响父表的数据,即可满足快速过滤的需求,提高了处理性能,这是本发明的另一个重要发明点。
本发明设计的索引表把邮件正文记录和附件记录以相同的表结构存储,根据所需操作为每个字段存储多种类型格式,同时每种类型记录只存储必要的字段,即节省空间,又可方便进行统计、过滤、搜索、分析等操作。在一个实施例中,本发明的表结构设计摘要如下:
该表格是本发明的一个示例性表格,本领域技术人员可以设计其他的表格实现数据项的存储。
图6示出了所述邮件统计模块705和邮件分析模块706执行的操作,邮件统计模块705执行的操作为:根据用户选择的过滤条件,创建过滤集filterset,对过滤集filterset使用elasticsearch的term接口,对发件人地址from_address及收件人地址to_address属性的不重复值进行统计,统计出收发件人总数,对客户ip_client和服务器ip_server属性进行不重复值的统计,计算出ip出现频次,对附件类型file_type属性进行不重复值的统计,计算出附件类型的分布情况。所述邮件分析模块706执行的操作为:以所选邮件的邮件idmessage-id作为查询条件,使用elasticsearch的query接口,对所有邮件的邮件idmessage-id和引用idreferences属性进行查询,对查询结果进行以发送时间sendtime进行排序,按时间顺序展示出邮件的流转生命周期,对所有邮件的发件人地址from_address及收件人地址to_address字段进行term过滤,筛选出所有的收发件人,根据收件人和发件人,绘制账号之间的关联关系。从而实现了可以快速对海量邮件进行过滤、智能统计、可视化关联分析及全文检索。这也是本发明的另一个重要发明点。
本发明的技术效果为:通过将邮件分发到多台运算服务器上进行并发处理,抽取邮件元素,并对附件中的文档、图片及压缩包等文件进行文本提取及ocr字符识别,对提取出的信息再自动进行数据挖掘及分类,最终按一定规则入库到elasticsearch中,在elasticsearch中可以快速对海量邮件进行灵活过滤、智能统计、可视化关联分析及全文检索,帮助办案人员直观、快速找到线索,一举解决涉案邮件数据庞大、人工浏览单兵作战时间长、效率低的问题。
为了描述的方便,描述以上系统时以功能分为各种单元分别描述。当然,在实施本申请时可以把各单元的功能在同一个或多个软件和/或硬件中实现。
通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到本申请可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本申请各个实施例或者实施例的某些部分所述的方法。
最后所应说明的是:以上实施例仅以说明而非限制本发明的技术方案,尽管参照上述实施例对本发明进行了详细说明,本领域的普通技术人员应当理解:依然可以对本发明进行修改或者等同替换,而不脱离本发明的精神和范围的任何修改或局部替换,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!