一种基于改进的Park频域训练序列的定时频率同步方法与流程
本发明属于ofdm系统同步技术领域,具体涉及一种基于改进的park频域训练序列的定时频率同步方法。
背景技术:
作为4g的核心技术,正交频分复用(orthogonalfrequencydivisionmultiplexing,ofdm)是一种多载波传输技术,将整个频带划分为多个正交子载波来对抗频率选择性衰落,在提高频带利用率的同时,对定时和频偏极其敏感。一方面,多普勒效应或收发两端本地载波频率的差异引起的载波频偏,通常用载波同步来补偿;另一方面,由于收发两端fft窗起始位置的差异导致的定时偏移会引起载波相位的旋转,可用定时同步来确定每个符号的起止位置。上述两方面的影响都会破坏ofdm子载波间的正交性,并引起子载波间干扰(ici),降低系统抗衰落能力。因此,ofdm的同步技术(包括符号定时和偏移估计)对ofdm系统极为重要,是实现高质量、高速率的数据传输的重要前提。ofdm同步主要包括:定时同步、载波同步以及样值同步,目前的同步方法都是在假设样值同步完成的情况下进行的。
ofdm系统定时同步方法主要分为数据辅助法和非数据辅助法两大类。前者通过在传输符号中插入特殊训练符号进行辅助估计,增加的训练符号开销会降低源数据的传输速率,但同步精度高且计算复杂度低。p.moose提出利用连续传输的两个完全相同的ofdm符号的时域相关性进行载波频偏估计,但是该方法的应用前提是已知定时准确且频偏在半个子载波间隔内,一旦定时出现错误或者频偏较大,估计精度会急剧下降。
设计的sc方法采用一种[a,a,b]结构的训练符号,其中[a,a]为一个训练符号,[b]为另一个训练符号。该方法的频偏估计范围可达到整个符号带宽,但由于在循环前缀范围内,所有对应样点乘积和都一样,定时度量函数的曲线产生“峰值平台”,使得最终定时位置的估计误差较大。
针对sc方法定时度量函数曲线的平台问题,设计了[a,a,-a,-a]结构的训练符号,通过在训练符号中引入负号消除平台现象,但其定时估计曲线的主峰并不尖锐,且出现多个副峰,影响定时同步的精确度。
针对minn方法定时度量函数曲线主峰不够尖锐的问题,设计了一种共轭对称结构序列的park方法,并将定时度量函数计算规则由从左向右平移变为从中间向两边延伸,改进后的定时度量函数曲线更加尖锐,但并未从根本上消除副峰干扰问题。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于改进的park频域训练序列的定时频率同步方法,设计了一种新的训练序列,以此获得较理想的时域训练符号结构。然后基于该训练序列及其对应的时域训练符号分别进行整数倍和小数倍频偏,并进行定时同步估计,通过在频域各个子载波发送伪随机实数,在时域得到具有共轭对称结构的训练符号,有效地解决了park方法在主峰周围存在较大副峰的问题,且频偏估计范围达到-n/2~n/2。
本发明采用以下技术方案:
一种基于改进的park频域训练序列的定时频率同步方法,在ofdm数据符号发送之前先发送一个训练序列,该训练序列在频域所有子载波均发送伪随机实数,则相应的时域训练符号结构具有共轭对称性,fs-park同步方法首先用时域训练符号进行定时同步,然后在时域基于循环前缀做小数倍频偏估计,频域利用训练序列的互相关性做整数倍频偏估计,得到总的频偏为整数倍频偏与小数倍频偏的和,完成同步。
具体的,定时同步具体为,设计频域子载波均发送实数的新的训练序列,修改定时度量函数m(d),确定定时正确位置
进一步的,定时度量函数曲线在正确的符号定时处具有峰值,而在其他位置处的值几乎为零。定时正确位置
其中,n为子载波个数,d为长度为n的采样区间中第一个采样值对应的采样时间值。
更进一步的,定时度量函数m(d)如下:
其中,r为经过信道后的接收信号,k为左右移动的任意数。
具体的,频偏估计分为两步,在时域上利用符号的循环前缀与其重复部分之间的自相关特性做小数倍频偏估计,在频域上利用训练序列的互相关特性做整数倍频偏估计。
进一步的,小数倍频偏ε为
其中,
更进一步的,设发送信号为x(n),则多径条件下的接收信号可以表示为:
其中,l为信道多径数,w(n)为高斯噪声。
具体的,若|ε|>1,估计整数倍频偏,整数倍频偏的影响对频域数据进行循环移位。
进一步的,使用一个长为p的滑动窗,该滑动窗包含本地频域训练序列的p个有效载波数据,通过对接收的频域信号与滑动窗做循环相关运算,得到n个相关值,其中最大值所对应的s即为频域的一个ofdm符号有效载波起始位置的估计值,也即为整数倍频偏估计值。
更进一步的,假设接收端经过fft接收到的训练序列为yk,k=0,1,...,n-1,整数倍频偏估计εi为:
式中,p是滑动窗包含有效载波数据的长度,即滑动窗长,s是窗口移动值,s∈s,s=0,1,...,n-1。
与现有技术相比,本发明至少具有以下有益效果:
本发明提供的一种基于改进的park频域训练序列的定时频率同步方法,首先设计一个新的频域训练序列,其对应时域符合结构具有共轭对称结构。利用该时域符号结构进行定时可以有效消除经典park算法存在的副峰问题,从而使得定时更加精确。且本发明方法不仅涉及小数倍频偏估计,同时涉及整数倍频偏估计。
进一步的,符号定时同步是为了正确地确定ofdm符号的起始位置,若估计不准确,fft窗将不能和ofdm符号完全对齐,接收信号的幅度和相位值就会发生畸变,可能导致isi的产生,影响系统性能。本发明所得的定时度量函数不仅消除了sc算法的峰值平台,且解决了sc算法及minn算法同时存在的峰值不尖锐问题,更从根本上消除了经典park算法所存在的副峰问题。使定时更加精确。
进一步的,小数倍频偏会影响子载波正交性,从而导致ici。本发明在时域基于循环前缀做小数倍频偏估计。
进一步的,整数倍频偏只是使频域接收信号发生循环移位,不会影响子载波正交性,从而不产生ici。但整数倍频偏的存在,仍然会导致系统误码率增加。本发明在频域利用训练序列的互相关性做整数倍频偏估计。使得新算法的频偏估计范围达整个符号区间,而不是经典park算法的一个子载波间隔内。
综上所述,本发明设计了一种新的训练序列,以此获得较理想的时域训练符号结构。然后基于该训练序列及其对应的时域训练符号进行定时同步估计,并分别进行整数倍和小数倍频偏。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
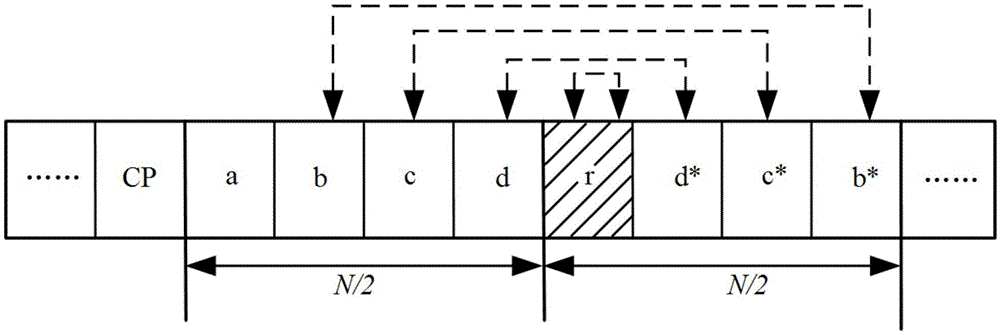
图1是本发明中的fs-park方法的时域训练符号结构图;
图2是本发明中的小数倍频偏计算过程图;
图3是本发明中的整数倍频偏计算过程图;
图4是本发明中的sc方法、minn方法、经典park方法以及新提出的fs-park方法定时度量函数曲线对比图,其中,(a)为sc方法与minn方法,(b)为经典park方法,(c)为提出的fs-park方法,横坐标为抽样点的位置,纵坐标为抽样点位置处信号的幅值。
图5是本发明中park方法与fs-park方法定时偏移均方误差对比图,其中横坐标为信噪比,纵坐标为平均误差值;
图6是本发明中park方法与fs-park方法频率偏移均方误差对比图,其中横坐标为信噪比,纵坐标为平均误差值。
具体实施方式
本发明提供了一种基于改进的park频域训练序列的定时频率同步方法,在ofdm数据符号发送之前先发送一个训练序列,该训练序列为在频域所有子载波均发送伪随机实数,则相应的时域训练符号结构具有共轭对称性。fs-park同步方法首先用时域训练符号进行定时同步,然后在时域基于循环前缀做小数倍频偏估计,频域利用训练序列的互相关性做整数倍频偏估计。
本发明一种基于改进的park频域训练序列的定时频率同步方法,包括以下步骤:
s1、fs-park定时同步
设计一种频域子载波均发送实数的新的训练序列,由fft性质可知,对应的时域训练符号结构如图1所示。
基于上述分析,将定时度量函数修改为:
其中,
如图1结构所示,只有定时在正确的位置r处时,p(d)有
s2、小数倍频偏估计
进行频偏估计时分为两步,在时域上利用符号的循环前缀与其重复部分之间的自相关特性做小数倍频偏估计,在频域上利用训练序列的互相关特性做整数倍频偏估计。
根据ofdm系统可知,循环前缀为ofdm符号后ng段的复制,在没有频偏的理想情况下,两部分在接收端的数值应完全一致。若系统存在小于一个子载波间隔的小数倍频偏εf,如图2所示,设发送信号为x(n),则多径条件下的接收信号可以表示为:
其中,l为信道多径数,w(n)为高斯噪声。
则由上式可得循环前缀和ofdm符号中的重复部分的相位差为:
φ=2πεf(10)
则相位估计值为
计算得到小数倍频偏为
s3、整数倍频偏估计
若|ε|>1,还需要估计整数倍频偏,由fft的性质可知,整数倍频偏的影响只是对频域数据进行了循环移位。
如图3所示,整数倍频偏估计就是使用一个长为p的滑动窗,该滑动窗包含本地频域训练序列的p个有效载波数据,通过对接收的频域信号与滑动窗做循环相关运算,得到n个相关值,其中最大值所对应的s即为频域的一个ofdm符号有效载波起始位置的估计值,即为整数倍频偏估计值。
假设接收端经过fft接收到的训练序列为yk,k=0,1,...,n-1,整数倍频偏估计为:
式中,p是滑动窗包含有效载波数据的长度,即滑动窗长。s是窗口移动值,s∈s,s=0,1,...,n-1。总的频偏即为ε=εf+εi。
表1park理想算法、实际算法以及fs-park算法对比
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明中采用的是qpsk调制,系统子载波n=256,循环前缀长度cp=32的ofdm系统框架,系统循环次数为1000次。首先在发送数据符号之前发送训练序列,该训练序列为在频域所有子载波均发送伪随机实数,则其对应的时域训练符号结构如图1所示。在接收端利用频域训练序列以及其对应的时域训练符号分别进行整数倍和小数倍频偏,以及定时同步估计。
图4分别仿真了sc方法、minn方法、经典park方法以及fs-park方法的定时度量曲线,可以看出,sc方法的定时度量曲线存在一个宽度为cp的平台区,而minn方法虽然消除了平台区问题,但存在主峰不尖锐且存在诸多副峰等问题。park方法尽管解决了主峰不尖锐的问题,但它未完全消除副峰。fs-park方法不仅具有类脉冲的定时度量函数曲线,而且彻底消除了副峰,从而实现了更精确的频偏估计。
图5分别仿真了经典park方法好fs-park方法的定时偏移均方误差曲线,可以看出,fs-park方法具有更小的定时偏移误差,这正是由于该方法不但具有类脉冲性的定时度量曲线,且不会受到副峰的干扰。
图6分别仿真了相对频偏ε为0.2、1和1.5时,park方法和fs-park方法的频率偏移均方误差曲线,可以看出,当频偏为0.2时,fs-park方法的性能要略优于park方法。
当频偏为1或者1.5时,相比于经典park算法,fs-park算法误差可降低104个数量级,这是因为当频偏超出一个子载波间隔后,park方法的估计性能就会严重下降,而fs-park方法不受此约束。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!