基于粗粒度可重构架构的SM3算法轮迭代系统及迭代方法与流程
本发明属于嵌入式可重构系统领域,特别涉及一种应用于通信、加密等领域的基于大规模粗粒度嵌入式可重构系统及其处理方法。
背景技术:
通用处理器与专用集成电路(asic)是传统的计算机系统结构领域的两大主流方法。然而,随着应用领域对系统的性能、能耗、上市时间等指标需求的不断提高,这两种传统计算模式的弊端就暴露出来。
通用处理器方法适用范围广,但是计算效率低,专用集成电路虽然可以提高计算速度和计算效率,满足性能需求,但是asic器件的灵活性很差。
为了在灵活性和计算效率之间实现很好的权衡,可重构计算(reconfigurablecomputing)技术应运而生。可重构计算是当前计算机系统结构领域的发展趋势之一,它的架构介于通用处理器和asic之间,并且综合了二者长处。它通过对可重构设备进行配置,可以使之由一个通用的计算平台转化为一个专用的硬件系统,以完成具体的计算任务,相当于计算任务同时在时间和空间上展开,显示出了应用的灵活性和很高的计算性能。此外,可重构计算技术还具有系统能耗低、可靠性高、上市时间短等优势。这些优势使得可重构计算技术在各个应用领域尤其是嵌入式应用领域有着广阔的应用前景。很多在嵌入式领域中的主流应用,例如多媒体应用、加/解密应用以及通信应用等都非常适合利用可重构计算技术实现。当前的可重构计算技术主要还是用于尖端技术领域中的计算平台,但随着可重构逻辑器件成本逐渐降低,运行时可重构计算技术不断完善,我们有理由相信可重构计算技术具备的种种优势会使其在更多的领域里大有作为。
目前国内外已研究有多重可重构系统,如remap,asap,drp等。但是,这些阵列的互联方式较为简单,在sm3算法轮迭代运算中需要大量的比特移位以及较多的轮数,因此运算的效率和速度较低。传统的可重构计算系统在sm3的运算效率与运算周期方面存在较大问题。
技术实现要素:
本发明的目的,在于提供一种基于粗粒度可重构架构的sm3算法轮迭代系统及迭代方法,利用可重构技术的并行性处理、运算模块独立可配置等优点,在支持一定的灵活性的同时,通过提高对des算法的并行度以及优化流水线等方法实现sm3算法的高效运算。
为了达成上述目的,本发明的解决方案是:
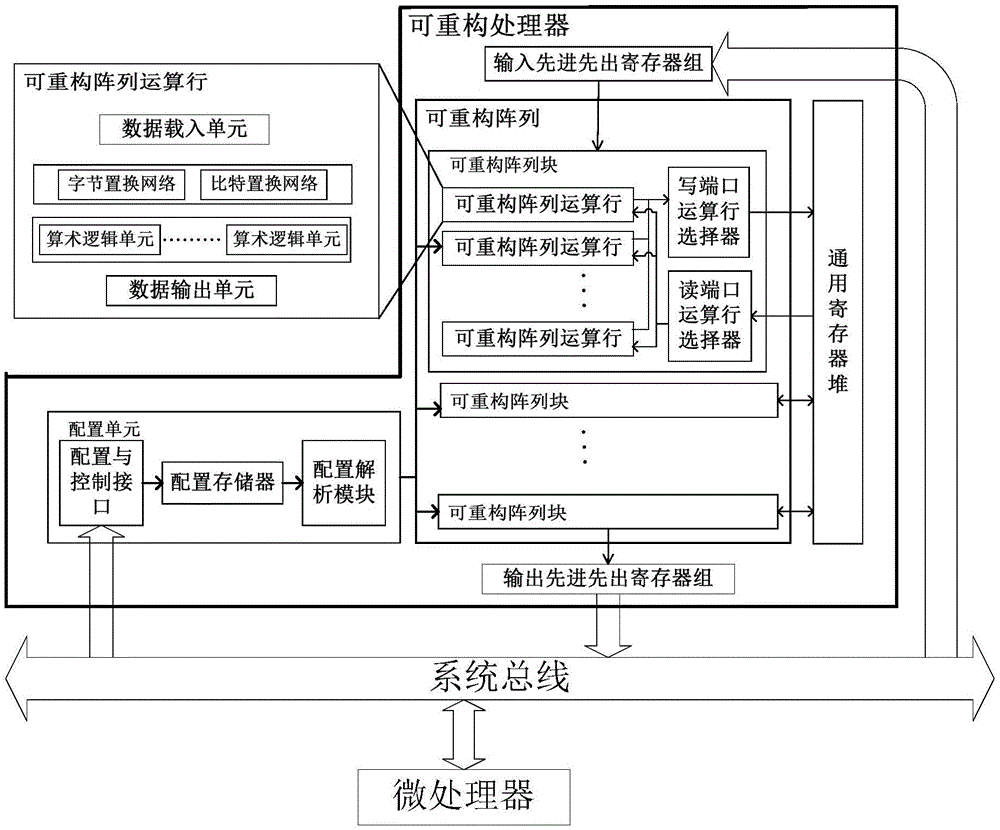
一种基于粗粒度可重构架构的sm3算法轮迭代系统,包括系统总线、可重构处理器和微处理器,其中,所述可重构处理器包括配置单元、输入先进先出寄存器组、输出先进先出寄存器组、通用寄存器堆和4个可重构阵列块,所述配置单元的进线口通过系统总线与微处理器连接,且配置单元的出线口分别与各个可重构阵列块连接;而所述输入先进先出寄存器组通过系统总线与微处理器连接;4个可重构阵列块分别与输入先进先出寄存器组连接,同时又分别与输出先进先出寄存器组连接,且这4个可重构阵列块均与通用寄存器堆连接;4个可重构阵列块之间通过通用寄存器堆互相进行数据的储存、读取和传递;所述输出先进先出寄存器组通过系统总线与微处理器连接;
所述sm3算法轮迭代系统包含5m+1张配置流程图,微处理器通过分析sm3的特征来确定轮迭代的运算流程,将多轮的轮迭代运算的配置流程图展开成一幅数据流图映射到可重构处理器中形成配置信息发送给配置单元;微处理器通过系统总线发送明文数据给可重构处理器,明文数据将存入输入先进先出寄存器组,微处理器并将初始数据、生成的密钥和计算的中间数据存入通用寄存器堆中用于下一张图的轮迭代;所述配置单元用于存储配置信息,并将配置信息发送给各个可重构阵列块。
一种基于粗粒度可重构架构的sm3算法迭代系统的迭代方法,包括以下步骤;
步骤1,归纳出sm3方法迭代的数据流图;
步骤2,制定sm3的数据输入方式;
步骤3,根据步骤2确定的数据输入方式以及步骤1确定的数据流图,配置可重构处理器,并生成配置信息;
步骤4,通过微处理器将配置信息以及可重构处理器初始数据存入相应的存储器中;
步骤5,微处理器启动可重构处理器,并将配置信息及待处理数据发送给可重构处理器;
步骤6,可重构处理器根据配置信息及待处理数据进行数据处理,当可重构处理器完成当前任务后,发送中断信号;并将处理好的数据通过系统总线发送给微处理器。
采用上述方案后,本发明针对sm3算法迭代,通过4个可重构阵列块包含多个运算单元,借助通用寄存器堆提高sm3算法的运算并行度,将多轮迭代在可重构处理器中并行移位替换的方式进行优化和加速,在具有一定灵活性的同时,提高sm3方法的运算效率,尽可能地减少运算周期。
附图说明
图1是本发明的基于大规模粗粒度嵌入式可重构系统处理器框图;
图2至图7是本发明sm3算法迭代配置流程图;
图8是消息扩展规则示意图;
图9是压缩函数规则示意图;
图10是sm3算法轮迭代整体流图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
如图1所示,本发明提供一种基于粗粒度可重构架构的sm3算法轮迭代系统,包括系统总线、可重构处理器和微处理器,下面分别介绍。
所述可重构处理器包括配置单元、输入先进先出寄存器组、输出先进先出寄存器组、通用寄存器堆、4个可重构阵列块、查找表,所述配置单元的进线口通过系统总线与微处理器连接,且配置单元的出线口分别与各个可重构阵列块连接;而所述输入先进先出寄存器组通过系统总线与微处理器连接;这4个可重构阵列块分别为第1个可重构阵列块、第2个可重构阵列块、第3个可重构阵列块和第4个可重构阵列块;所述每个可重构阵列块与输入先进先出寄存器组连接,同时又与输出先进先出寄存器组连接,且这4个可重构阵列块均与通用寄存器堆连接;这4个可重构阵列块之间通过通用寄存器堆互相进行数据的储存、读取和传递;所述输出先进先出寄存器组通过系统总线与微处理器连接;所述sm3算法轮迭代系统包含5m+1张配置流程图,其中:
微处理器通过分析sm3的特征来确定轮迭代的运算流程,将多轮的轮迭代运算的配置流程图展开成一幅数据流图映射到可重构处理器中形成配置信息发送给配置单元。微处理器通过系统总线发送明文数据给可重构处理器,明文数据将存入输入先进先出寄存器组。微处理器并将初始数据、生成的密钥和计算的中间数据存入通用寄存器堆中用于下一张图的轮迭代。
所述配置单元用于存储配置信息,并将配置信息发送给各个可重构阵列块。
对于第5p-4个配置流程图,1≤p≤m;第(5p-4)个配置流程图用于获取输入先进先出寄存器组的消息数据和读取其对应的配置单元的配置信息;第(5p-4)个配置流程图根据配置信息对读取的初始消息数据存入通用寄存器堆;根据配置信息将初始消息数据载入下一个配置流程图中,用于下一个配置流程图的运算;
对于第5p-3个配置流程图,1≤p≤m;第(5p-3)个配置流程图用于获取第(5p-4)个配置流程图的存入通用寄存器堆的初始消息数据、读取其对应的配置单元的配置信息,完成消息扩展迭代;通过第1个读端口运算行选择器读取通用寄存器堆中消息扩展字数据;所述第(5p-3)个配置流程图根据配置信息完成sm3算法中消息扩展第一阶段迭代;
对于第5p-2个配置流程图,1≤p≤m;第(5p-2)个配置流程图用于获取第(5p-3)个配置流程图的存入通用寄存器堆的初始消息数据、读取其对应的配置单元的配置信息,完成消息扩展迭代;通过第1个读端口运算行选择器读取通用寄存器堆中消息扩展字数据;所述第(5p-2)个配置流程图根据配置信息完成sm3算法中消息扩展第二阶段迭代;
对于第5p-1个配置流程图,1≤p≤m;对于第5p-1个配置流程图块用于获取第(5p-2)个配置流程图产生的消息扩展字、读取存储在通用寄存器堆的哈希值、其对应的配置单元的配置信息;通过第1个读端口运算行选择器读取通用寄存器堆中存储的哈希值;所述第5p-1个配置流程图根据配置信息对第(5p-2)个可重构阵列块的消息扩展字、初始哈希值进行压缩函数第0到第15次迭代,得到本次块迭代的中间信息;
对于第5p个配置流程图,1≤p≤m;对于第5p个配置流程图块用于获取第(5p-1)个配置流程图产生的消息扩展字、读取存储在通用寄存器堆的哈希值、其对应的配置单元的配置信息;通过第1个读端口运算行选择器读取通用寄存器堆中存储的哈希值;所述第5p个配置流程图根据配置信息对第(5p-2)个可重构阵列块的消息扩展字、初始哈希值进行压缩函数第16到第63次迭代,得到本次块迭代的中间信息;
对于第(5m+1)个可重构阵列块获取第5m个配置流程图的中间信息和读取其对应的配置单元的配置信息;第(5m+1)个配置流程图根据配置信息对第5m个可重构阵列块的中间信息与初始哈希值异或获取杂凑值。
优选的,所述配置单元包括依次连接在一起的配置与控制接口、配置存储器和配置解析模块,且所述配置与控制接口和系统总线连接;微处理器依次通过系统总线和配置与控制接口将所需要的配置信息发送给配置存储器,所述配置存储器存储发送过来的配置信息,而配置解析模块用于解析配置存储器的配置信息,且将解析的配置信息发送给可重构阵列块,实现对可重构阵列块的配置、启动以及切换操作。
优选的,所述可重构阵列块包括读端口运算行选择器、写端口运算行选择器以及n行可重构阵列运算行,且这n行可重构阵列运算行共享读端口运算行选择器和写端口运算行选择器;其中,第m个配置流程图中的读端口运算行选择器记为第m个读端口运算行选择器,第m个配置流程图中的写端口运算行选择器记为第m个写端口运算行选择器,第m个配置流程图中的第n行可重构阵列运算行记为第
在轮迭代中配置流程图运算得到的中间数据通过写端口运算行选择器存在通用寄存器堆中,而在轮迭代中配置流程图运算需要得到的中间数据通过读端口运算行选择器读取通用寄存器堆中存储的信息;
第
在第(5p-4)个配置流程图中,1≤p≤m;第
对于第(5p-3)个配置流程图,1≤p≤m;第(5p-3)个配置流程图中的第
对于第(5p-2)个配置流程图,1≤p≤m;第(5p-2)个配置流程图中的第
对于第(5p-1)个配置流程图,1≤p≤m;第(5p-1)个配置流程图中的第
对于第5p个配置流程图,1≤p≤m;第5p个配置流程图中的第
对于第5m+1个配置流程图,第5m+1个配置流程图中的第
优选的,每行可重构阵列运算行均包括x1个数据载入单元、x2个数据输出单元、x3个32位运算单元;每个运算单元使用对应的读端口运算行选择器选择任意三个上行或本行其它运算单元输出作为其输入;第m个配置流程图第n行可重构阵列运算行的第k1个数据载入单元记为第
第
第
优选的,所述运算单元中包括模加运算、异或运算、与运算、与非运算、移位运算、直通输出运算操作;同时每个运算单元有最多3个输入和最多2个输出,其中运算单元执行上述运算操作的同时,支持任选一个输入作为输出。
优选的,所述可重构阵列块的个数为4个,各个可重构阵列块之间首尾依次连接在一起,通用寄存器堆的个数为1个,输入先进先出寄存器组的个数为4个,输出先进先出寄存器组的个数为4个。
优选的,每个可重构阵列块包括4行可重构阵列运算行、4个读端口运算行选择器和4个写端口运算行选择器;每行可重构阵列运算行包括4个数据载入单元、4个数据输入单元、8个32位算术运算单元。
优选的,所述m为消息数据按512bit分块的块数。
本发明还提供一种基于粗粒度可重构架构的sm3算法迭代系统的迭代方法,包括以下步骤;
步骤1,分析sm3方法迭代的计算特点,并归纳出数据流图;
步骤2,根据数据流图中的运算流程,制定sm3的数据输入方式;
步骤3,根据步骤2确定的数据输入方式以及步骤1确定的数据流图针对可重构处理器的特点配置可重构处理器,并生成配置信息;
步骤4,通过微处理器将配置信息以及可重构处理器初始数据存入相应的存储器中;
步骤5,微处理器启动可重构处理器,并将配置信息及待处理数据发送给可重构处理器;
步骤6,可重构处理器根据配置信息及待处理数据进行数据处理,当可重构处理器完成当前任务后,发送中断信号;并将处理好的数据通过系统总线发送给微处理器。
优选的,步骤6中可重构处理器根据配置信息及待处理数据进行数据处理的具体过程是:
步骤61:第
步骤62:对于第(5p-3)个配置流程图,1≤p≤m;通过第(5p-3)个读端口运算行选择器读取配置单元的配置信息,第(5p-3)个配置流程图读取通用寄存器堆中消息数据wj-3,wj-5,wj-6,wj-8,wj-9,wj-11,wj-12,wj-13,wj-16,0≤j<68且j为偶数,第
第
步骤63:对于第(5p-2)个配置流程图,1≤p≤m;通过第(5p-2)个读端口运算行选择器读取配置单元的配置信息,第(5p-3)个可重构阵列块第读取通用寄存器堆中消息数据wk-12,wk-11,wk-15,wk-16,0≤k<64且k为偶数。第
第
步骤64:对于第(5p-1)个配置流程图,1≤p≤m;第(5p-3)和第(5p-2)个可重构阵列块写入到通用寄存器堆中消息扩展字组;第(5p-1)个可重构阵列块中的第
第
第
第
步骤65:对于第5p个配置流程图,1≤p≤m;第(5p-3)和第(5p-2)个可重构阵列块写入到通用寄存器堆中消息扩展字组;第5p个可重构阵列块中的第
第
第
第
步骤66:对于第5m+1个配置流程图,第5m+1个配置流程图读取第5m个配置流程图以及第5m-5配置流程图写入到通用寄存器堆中哈希值第5m+1个可重构阵列块中的第
第
优选的,所述步骤62、63、64和65中的p0,p1置换的规则如下:
p0(x)=x⊕(x<<<9)⊕(x<<<17)
p1(x)=x⊕(x<<<15)⊕(x<<<23)式中x为字。
所述步骤62、63、64和65中的布尔函数ffi和ggi规则如下:
式中xyz为字。
所述步骤64中的常量如下:
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!