随机数均匀化处理方法及射频识减少碰撞时隙数量的方法和应用与流程
本发明属于通信信道处理领域,具体涉及随机数均匀化处理方法及射频识减少碰撞时隙数量的方法和应用。
背景技术:
射频识别(radiofrequencyidentification,rfid)是一种非接触式自动识别技术,标签和阅读器之间通过无线射频信号进行通信,可工作于复杂的恶劣环境中,其真正实现了完全的自动识别,被广泛应用于室内定位、物流管理、供应链管理、工业自动化等领域。rfid识别过程中,若有多个标签在同一时间响应阅读器,则标签和阅读器之间的信息传输将会产生干扰,即发生标签碰撞,将会导致阅读器读取信息失败。因此,标签碰撞已成为影响rfid系统性能的瓶颈问题之一。
目前,常用的标签防碰撞算法分为aloha类算法和树类算法两类。aloha类算法属于随机性识别方案,主要包括纯aloah算法、时隙aloha算法(sa)、帧时隙alioha算法(frame-slottedaloah,fsa)和动态帧时隙aloah算法(dynamicframe-slottedaloha,dfsa)等。其中,dfsa算法从理论上分析了帧长与标签数的关系,得出理论上的最优识别率,但在识别过程中,会出现大量碰撞与空闲时隙;针对上述问题,vazquez-gallegof等人提出一种基于哈希函数进行时隙选择算法,解决了碰撞时隙过多的问题,但进行时隙选择时会出现大量中间空闲时隙,从而造成时隙的浪费;基于此,郭志涛和chenwt.等人对标签选择时隙进行了改进,但标签识别量较大时,仍会出现大量碰撞时隙。该类算法设计简单,阅读器与标签不需要执行复杂的运算,识别时间较短,但是由于标签随机响应阅读器来实现信息交换,时隙选择的随机性会出现碰撞时隙,导致标签识别容易出现“饥饿”问题。树类算法属于确定性识别方案,主要包括二进制搜索树算法(binarysearch,bst)、动态二进制搜索树算法(dynamicbinarysearch,dbst)、跳跃式动态树算法(jumpingdynamicsearch,jds)、查询树算法(querytree,qt)、二进制分裂树算法(basictreesplitting,bts)、自适应多叉树算法(adaptivemulti-treesearch,ams)等。上述树类算法不存在标签“饥饿”问题,可实现标签的100%识别,但存在空闲时隙和碰撞时隙过多问题。苏健等人提出了一种二进制分裂(idleslotseliminationbasedbinarysplitting,ise-bs)算法,彻底消除了空闲时隙,但碰撞时隙仍然存在;刘子龙等人提出了一种基于连续碰撞位探测(continuouscollisionbitdetection,ccbd)防碰撞算法,检测到碰撞标签的序列号连续时,可以一次性识别,但在非连续碰撞位时,这种方法无能为力。此外,基于树的方法由于算法较复杂,识别时间较长,因而不适合密集标签环境下的识别。针对上述问题,张小红等人提出了一种动态帧时隙二进制树混合(dynamicframedbinarytree,dfbt)算法,充分利用aloha和树类算法的的优点,减少碰撞时隙数,降低识别延时,从而提高标签识别率,但是两类算法基于不同的协议框架,结合较为困难。
技术实现要素:
为了解决减少碰撞时隙的数量,实现标签的全部识别的问题,本发明提出了一种基于混沌映射的射频识别防碰撞算法,技术方案如下:
一种随机数均匀化处理方法,其特征在于,包括如下步骤:
logistic混沌映射描述:
初始表达式为:
xn+1=α×xn×(1-xn)
其中,xn∈(0,1),a是系统控制参数,n为迭代次数,xn表示系统在给定初值之后迭代了n-1次的状态值;
logistic混沌映射概率密度函数描述如下:
由logistic混沌映射密度函数,对logistic混沌映射产生的伪随机数均匀化处理:
logistic混沌映射均匀化系统描述为:
本发明还涉及一种射频识减少碰撞时隙数量的方法,包括如下步骤:
logistic混沌映射产生一组伪随机数,对其进行均匀化处理,标签随机选择伪随机数区间中的一个伪随机数作为通信时隙,进行标签时隙选择;
均匀化的伪随机数序列作为扩频通信的扩频码,并用其对标签身份进行标识,阅读器通过识别不同扩频码序列信息来识别标签。
进一步的,logistic混沌映射生成的伪随机数,在[0,0.1]与[0.9,1]区间出现次数较多,而中间部分的[0.1,0.9]相对较少,随机数分布覆盖整个迭代区间,但分布不均匀。
进一步的,对其进行均匀化处理的步骤如下:logistic混沌映射描述:
初始表达式为:
xn+1=α×xn×(1-xn)
其中,xn∈(0,1),a是系统控制参数,n为迭代次数,xn表示系统在给定初值之后迭代了n-1次的状态值;
logistic混沌映射概率密度函数描述如下:
由logistic混沌映射密度函数,对logistic混沌映射产生的伪随机数均匀化处理:
logistic混沌映射均匀化系统描述为:
进一步的,实施该方法的仿真方法:从总时隙数、碰撞时隙数、吞吐率三个方面,利用matlab仿真软件对其进行了仿真实验,实验中标签样本数量最大为2000,以50为间隔,每个样本数量取30次仿真结果平均值。
本发明还涉及一种logistic混沌映射在减少碰撞时隙数量的应用。
有益效果:对混沌映射产生伪随机数进行均匀化处理,使标签时隙选择时更加均匀,从而减少碰撞时隙的数量;然后把混沌映射理论用于扩频通信,将均匀化的伪随机数序列用作扩频通信的扩频码,解决碰撞时隙问题,实现标签的全部识别。最后,通过仿真实验对改进算法在不同标签样本量,尤其是密集标签样本量下的识别性能进行验证。
附图说明
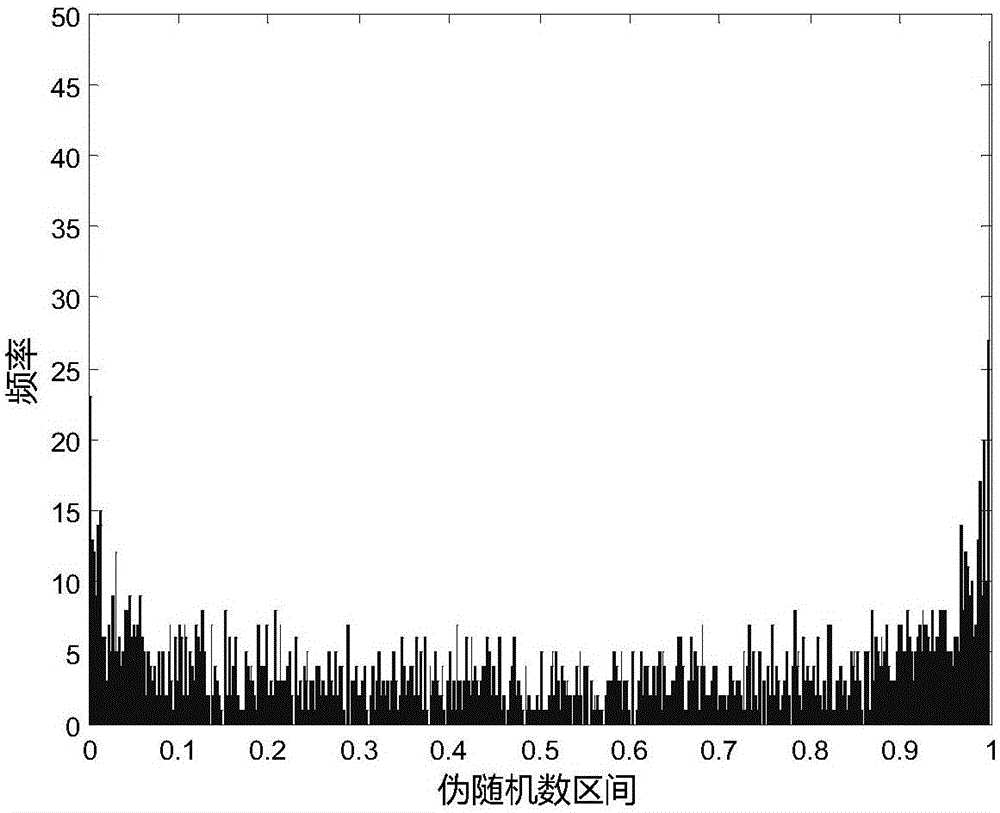
图1为logistic混沌映射生成随机数均匀化前频率分布图;
图2为logistic混沌映射生成随机数均匀化后频率分布图;
图3为单个识别周期本发明算法与传统算法碰撞时隙数量对比图;
图4扩频通信技术原理图;
图5为本发明实现的流程图;
图6为本发明算法与其余三种主流算法在总时隙数量上的对比图;
图7为本发明算法与其余三种主流算法在总碰撞时隙数量上的对比图;
图8为本发明算法与其余三种主流算法在吞吐率上的对比图。
具体实施方式
以下结合附图及本发明的目的、推导和方案、仿真对本发明进行详细说明。
1发明目的
本发明提出一种基于logistic混沌映射理论的rfid防碰撞算法(logisticchaosmappingslotaloha,lcmsa)。首先,对混沌映射产生伪随机数进行均匀化处理,使标签时隙选择时更加均匀,从而减少碰撞时隙的数量;其次,混沌映射理论与扩频通信结合,将均匀化的伪随机数序列用作扩频通信的扩频码,解决碰撞时隙问题,实现标签的全部识别。最后,通过仿真实验对改进算法在不同标签样本量,尤其是密集标签样本量下的识别性能进行验证。
2伪随机数的生成及均匀化
2.1伪随机数生成
目前,常用的伪随机数生成方法有:线性反馈移位寄存器法、线性同余法、线性乘同余法、扩大周期法等,其中,线性同余法已被破译,安全性较低,而其他几种方法较为复杂,且存在着周期性、分布不均匀等问题。混沌理论伪随机数生成方式简单、快速且易于实现,已被广泛应用于各个领域。
混沌(chaos)不需附加任何随机因素亦可出现类似随机行为,即具有内在随机性。常用的混沌映射有:logistic映射、tent映射、henon映射、chebyshev映射、组合混沌映射等。
本发明选取logistic映射生成伪随机数,因为与其他几种混沌映射相比,它具有较好遍历性、自相关和互相关性。logistic混沌映射,表达式描述为:
xn+1=α×xn×(1-xn)(1)
其中,xn∈(0,1),a是系统控制参数,当α∈[3.57,4]时,系统为混沌状态。α=4时,称为满映射(函数曲线取满了值域空间)迭代形式。n为迭代次数,xn表示系统在给定初值之后迭代了n-1次的状态值。为映射整个迭代空间,本发明选取满映射混沌状态,即α=4。logistic混沌映射具有如下性质:
(1)序列概率密度为:
ρ(x)与初始值x0无关,所以该系统具有普遍性。
(2)序列均值:
(3)自相关函数:
(4)互相关函数,其中,初值分别为x10,x20:
图1为logistic混沌映射产生2000个伪随机数,分为500个区间的伪随机数频率分布图。
由图1可知,logistic混沌映射生成的伪随机数,在[0,0.1]与[0.9,1]区间出现次数较多,而中间部分[0.1,0.9]相对较少,随机数分布虽然可以覆盖整个迭代区间,但分布不均匀。
2.2伪随机数的均匀化
logistic混沌映射产生的伪随机数分布不均匀,用于标签时隙选择和扩频通信时,导致碰撞时隙数量过多和碰撞时隙处理失败等问题。所以,需对logistic混沌映射产生的伪随机数进行均匀化处理。
假设有两个概率密度函数f(x)和g(y),分别在(a,b)和(c,d)区间内可积,则存在(a,b)和(c,d)内的x、y,有:
若随机变量的概率密度函数为f(x),其在区间(0,1)上服从均匀分布,则式(6)可以进一步表示为:
式(2)给出了满映射,即α=4时的logistic混沌映射概率密度函数,根据式(7),本发明对其进行均匀化处理,即:
于是,logistic混沌映射均匀化系统表述为:
均匀化后的映射频率如图2所示。
由图2可看出,均匀化后的伪随机数序列覆盖整个迭代区间,且分布均匀,避免了图1中伪随机数分布两边多中减少的情况。
3改进aloha算法描述
本发明融合tdm和cdm技术对传统的时隙aloha算法进行改进。首先利用logistic混沌映射产生一组伪随机数,然后对其进行均匀化处理;其次,利用均匀化的伪随机数进行标签时隙选择,同时作为扩频通信的扩频码,达到减少碰撞时隙数量和解决碰撞时隙问题。
3.1均匀时隙选择
由于标签选择时隙的随机性,使得碰撞发生概率随标签数量的增加而增大。理想状态下:大部分标签能被分配到唯一时隙上,从而减少碰撞发生概率,缩短系统识别时间,提高识别效率。
标签时隙选择是以等概率分配到每一个时隙区间,然后选择自己的通信时隙,如果时隙数量分布不均匀,时隙选择时碰撞的概率将增大。对logistic混沌映射产生的伪随机数进行均匀化处理,处理后的伪随机数可覆盖整个迭代空间,且分布均匀。均匀化后的伪随机数区间中的伪随机数数量基本相等,标签随机选择伪随机数区间中的一个伪随机数作为通信时隙,可减少碰撞时隙发生的概率。
图3所示为logistic混沌映射均匀化伪随机数与线性同余法产生的伪随机数用于时隙选择时,单个识别周期出现的碰撞时隙数量对比。由图3可看出,随着标签数量增加,均匀化伪随机数用于时隙选择时的优势越来越明显,当标签数量达到2000时,单个识别周期碰撞时隙数量减少33%。
3.2碰撞时隙处理
由公式(4)和(5)可知,logistic混沌映射序列具有良好自相关和互相关特性,而扩频通信技术所要求扩频码是具有正交特性的随机数序列,因此将混沌映射与扩频通信结合,解决碰撞时隙问题。本发明用伪随机数序列作为扩频通信的扩频码序列,并用其对标签身份进行标识,阅读器通过识别不同扩频码序列信息来识别标签,从而在碰撞时隙中实现了多个标签的有效识别,大大减少了标签与阅读器间通信次数与通信量,提高识别碰撞标签的成功率。
图4所示为结合扩频通信技术的碰撞时隙处理示意图。
3.3碰撞算法设计
算法流程图如图5所示,具体步骤如下:
1)阅读器根据标签数量n,由logistic映射系统产生n个随机数并对其进行均匀化,然后以广播方式发送给识别范围内的标签;
2)识别范围内的标签收到广播信息后,随机选择一个随机数作为自己的时隙号;
3)标签根据选择的时隙号,依次与阅读器进行通信。若时隙中仅有一个标签,则为成功时隙,标签成功识别,并结束;若时隙中没有标签选择,则为空闲时隙;若时隙中有2个或2个以上标签,则为碰撞标签,等待进一步处理,即继续执行步骤(4);
4)碰撞时隙中标签选择上述步骤(1)中产生的均匀化随机数,作为自己的扩频码序列;
5)标签根据碰撞时隙号,响应阅读器。若碰撞时隙中的标签选择不同的随机数,则碰撞时隙可成功识别;若碰撞时隙中有2个或2个以上的标签选择同一个随机数,则碰撞时隙未解决,等待进一步处理,继续执行步骤(6);
6)清除标签中选择的作为扩频码的随机数,重复上述(4)到(5),直至所有标签识别完毕。
4仿真与算法性能分析
为验证算法的有效性与实用性,本发明从总时隙数、碰撞时隙数、吞吐率三个方面,利用matlab仿真软件对dfsa#6#、ise-bs、dfbt算法以及改进时隙aloha算法(lcmsa)进行了仿真实验,实验中标签样本数量最大为2000,以50为间隔,每个样本数量取30次仿真结果平均值。
4.1总时隙数
图6为标签数与识别标签所需总时隙数仿真结果。标签识别时,会产生成功时隙、空闲时隙和碰撞时隙,总时隙数为成功识别标签所用三种时隙数总和。由图6知,随着标签数量增加,dfbt和lcmsa算法总时隙数明显小于dfsa算法和ise-bs算法,相比dfsa和ise-bs算法分别减少64%和50%。且lcmsa算法的总时隙数与标签数基本呈现线性关系,表明所提算法在识别全部标签所需总时隙上具有良好稳定性。
4.2碰撞时隙数
图7所示为标签数与识别标签产生碰撞时隙数仿真结果。由于标签选择时隙的随机性,标签识别时,一定会出现碰撞时隙。由图7,lcmsa算法由于对碰撞时隙进行直接处理,总碰撞时隙数比其他几种算法具有明显的优势。相比dfsa和ise-bs算法采用轮询方法处理碰撞时隙,所提算法碰撞时隙数分别减少了90%和83%。虽然dfbt也是对碰撞时隙数进行直接处理,但由于其在时隙选择时采用传统方法,因此相比于本发明所提lcmsa算法,总碰撞时隙数还是要高出33%。
4.3吞吐率
图8所示为标签数与算法吞吐率仿真结果。由图8可知,传统dfsa算法识别效率较低,且随着标签数量增加,识别效率明显下降。ise-bs算法没有因标签数量变化而出现较大幅度波动,但算法识别效率较低,仅为0.42。dfbt算法和lcmsa算法由于对碰撞时隙进行直接处理,具有较高识别效率。本发明所提lcmsa算法吞吐率可达到0.8,且比较稳定,因而在标签识别时具有较大优势。
综上,通过对标签识别时总时隙数、碰撞时隙数和吞吐率的分析,本发明算法皆具有显著优势,这是由于lcmsa算法对logistic混沌映射产生的伪随机数进行的均匀化处理,不仅在标签时隙选择时,减少碰撞时隙数量,而且通过logistic混沌映射与扩频技术相结合,解决了碰撞时隙问题,最终提高标签识别效率。
5有益效果
本发明提出基于混沌映射的aloha标签防碰撞算法,首先对logistic混沌映射产生的伪随机数进行均匀化处理,然后将其应用到标签时隙选择和碰撞时隙处理中。均匀化的伪随机序列应用于标签时隙选择,较大幅度减少碰撞时隙数量,其次将其应与扩频通信技术结合,用于扩频通信的扩频码,从而实现一个时隙多个标签的识别,解决碰撞时隙问题,最终提高算法识别效率。仿真结果表明,当标签数达到2000时,本发明算法的吞吐率仍然能够稳定在80%,且总时隙数与碰撞时隙数并没有因为标签数量的增加,而有较大幅度的变化。因此,本发明所提算法提高了rfid系统识别性能,适合较大数量标签环境的应用。
作为另一种实施例:
一种基于混沌映射的射频识别防碰撞算法,包括如下步骤:
1)阅读器根据标签数量n,由logistic映射系统产生n个随机数并对其进行均匀化,然后以广播方式发送给识别范围内的标签;
2)识别范围内的标签收到广播信息后,随机选择一个随机数作为自己的时隙号;
3)标签根据选择的时隙号,依次与阅读器进行通信;
若时隙中仅有一个标签,则为成功时隙,标签成功识别,并结束;若时隙中没有标签选择,则为空闲时隙;若时隙中有2个以上标签,则为碰撞标签,等待进一步处理,继续执行步骤4);
4)碰撞时隙中标签选择上述步骤(1)中产生的均匀化随机数,作为自己的扩频码序列;
5)标签根据碰撞时隙号,响应阅读器;
若碰撞时隙中的标签选择不同的随机数,则碰撞时隙可成功识别;若碰撞时隙中有2个以上的标签选择同一个随机数,则碰撞时隙未解决,等待进一步处理,继续执行步骤6);
6)清除标签中选择的作为扩频码的随机数,重复上述步骤4)到步骤5),直至所有标签识别完毕。
进一步的,所述由logistic映射系统产生n个随机数并对其进行均匀化的步骤如下:
logistic混沌映射描述:
初始表达式为:
xn+1=α×xn×(1-xn)
其中,xn∈(0,1),a是系统控制参数,n为迭代次数,xn表示系统在给定初值之后迭代了n-1次的状态值;
logistic混沌映射概率密度函数描述如下:
由logistic混沌映射密度函数,对logistic混沌映射产生的伪随机数均匀化处理:
logistic混沌映射均匀化系统描述为:
本发明还涉及一种基于混沌映射的射频识别防碰撞系统,存储有多条指令,所述指令适于由处理器加载并执行:
1)阅读器根据标签数量n,由logistic映射系统产生n个随机数并对其进行均匀化,然后以广播方式发送给识别范围内的标签;
2)识别范围内的标签收到广播信息后,随机选择一个随机数作为自己的时隙号;
3)标签根据选择的时隙号,依次与阅读器进行通信;
若时隙中仅有一个标签,则为成功时隙,标签成功识别,并结束;若时隙中没有标签选择,则为空闲时隙;若时隙中有2个以上标签,则为碰撞标签,等待进一步处理,继续执行步骤4);
4)碰撞时隙中标签选择上述步骤(1)中产生的均匀化随机数,作为自己的扩频码序列;
5)标签根据碰撞时隙号,响应阅读器;
若碰撞时隙中的标签选择不同的随机数,则碰撞时隙可成功识别;若碰撞时隙中有2个以上的标签选择同一个随机数,则碰撞时隙未解决,等待进一步处理,继续执行步骤6);
6)清除标签中选择的作为扩频码的随机数,重复上述步骤4)到步骤5),直至所有标签识别完毕。
进一步的,所述由logistic映射系统产生n个随机数并对其进行均匀化的步骤如下:
logistic混沌映射描述:
初始表达式为:
xn+1=α×xn×(1-xn)
其中,xn∈(0,1),a是系统控制参数,n为迭代次数,xn表示系统在给定初值之后迭代了n-1次的状态值;
logistic混沌映射概率密度函数描述如下:
由logistic混沌映射密度函数,对logistic混沌映射产生的伪随机数均匀化处理:
logistic混沌映射均匀化系统描述为:
以上所述,仅为本发明创造较佳的具体实施方式,但本发明创造的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明创造披露的技术范围内,根据本发明创造的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明创造的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!