帧内模式JVET编译的制作方法
优先权声明
本申请根据美国法典第35卷第119条(e)规定要求来自于2017年7月24日提交的较早提交的美国临时申请序列号62/536,072的优先权,其全部内容通过引用被合并在此。
本公开涉及视频编译(coding)领域,并且更具体地涉及有效帧内(intramode)模式编译。
背景技术:
演进的视频编译标准的技术改进说明增加编译效率以实现更高的比特率、更高的分辨率和更好的视频质量的趋势。联合视频探索小组正在开发一种称为jvet的新视频编译方案。与如同hevc(高效视频编译)的其他视频编译方案相似,jvet是基于块的混合空时预测编译方案。但是,相对于hevc,jvet包括用于生成解码图片的比特流结构、语法、约束和映射的许多修改。jvet已经在联合探索模型(jem)编码器(encoder)和解码器(decoder)中实现。
存在当前的jvet标准中描述的总共67种帧内预测模式,包括平面、dc模式和65个方向角帧内模式。为了有效地编译这67种模式,所有帧内模式都细分成三个集合,包括6种最可能模式(mpm)集、16种选择模式集和45种非选择模式集。
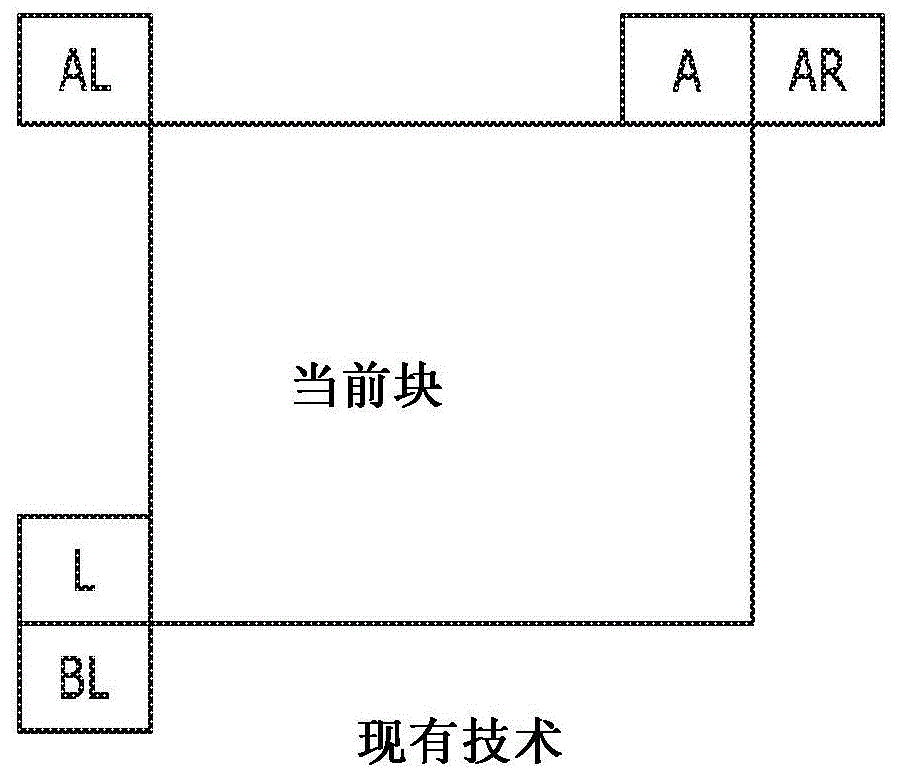
从可用邻近块的模式、导出的帧内模式和默认帧内模式导出6个mpm。在图1a中描绘当前块的5个邻近块的帧内模式。它们分别是左(l)、上(a)、左下(bl)、右上(ar)和左上(al),并且它们被用于形成当前块的mpm列表。通过将5个邻近帧内模式以及平面模式和dc模式插入mpm列表来形成初始mpm列表。修剪(pruning)过程被用于去除重复的模式,使得仅独特(unique)模式可以被包括在mpm列表中。包括初始模式的顺序为:左、上、平面、dc、左下、右上、并且然后左上。
如果mpm列表不完整,则添加导出的模式;通过将-1或+1添加到mpm列表中已包括的角度模式中,可以获得这些帧内模式。如果mpm列表仍不完整,则按以下顺序添加默认模式:垂直、水平、模式2和对角线模式。作为此过程的结果,生成6个mpm模式的独特列表。
对于6个mpm的熵编译,图1b中所示的截断的一元二值化当前被使用。mpm模式的前三个bin通过取决于与当前正在用信号发送的bin相关的mpm模式的上下文进行编译。mpm模式被分类成三个类别之一:(a)主要是水平的模式(即,mpm模式数小于或等于对角线方向的模式数),(b)主要是垂直的模式(即,mpm模式数大于对角线方向的模式数),以及(c)非角度(dc和平面)类。因此,基于此分类,使用三个上下文以用信号发送mpm索引。
用于选择剩余的61个非mpm的编译如下进行。首先将61个非mpm划分为两个集合:选定模式集和未选定模式集。选定模式集包含16种模式,并且其余(45种模式)被指配给未选定模式集。当前模式所属的模式集在比特流中通过标志指示。如果要指示的模式在选定模式集中,则以4比特固定长度码用信号发送选定模式,并且如果要指示的模式来自未选定集,则以截断的二进制码用信号发送选定模式。通过示例,通过对61种非mpm模式进行二次采样生成如下选定模式集:
选定模式集={0、4、8、12、16、20…60}
未选定模式集={1、2、3、5、6、7、9、10…59}
在下面的图1b中总结当前的jvet帧内模式编译。
如图1b中所示,mpm列表的最后两个条目需要六个bin,这与为16个选定模式指配的bin数目相同。对于mpm列表上的最后两种模式,这种设计在编译性能方面没有优势。而且,因为mpm模式的前三个bin利用基于上下文的熵编译来编译,所以编译mpm模式的六个bin的复杂度高于编译选定模式的六个bin的复杂度。
需要一种用于减少与帧内模式编译相关联的编译负担和带宽的系统和方法。
技术实现要素:
本公开提供一种用于jvet帧内预测的视频编译的方法,包括定义独特帧内预测编译模式的集合,在一些实施例中其可以是67种模式,并且在存储器中识别并实例化来自于所述独特帧内预测编译模式的集合的独特mpm帧内预测编译模式的子集,在一些实施例中,其可以是7种或更多种中的5种或更少。该方法还提供,在存储器中识别和实例化来自于除了所述独特mpm帧内预测编译模式的子集之外的所述独特帧内预测编译模式的集合的独特选定的帧内预测编译模式的子集,在一些实施例中,其可以包括16种编译模式,并且在存储器中识别和实例化来自于除了所述独特mpm帧内预测编译模式的子集之外和除了所述独特选定帧内预测编译模式的子集之外的所述独特帧内预测编译模式的集合的独特未选定帧内预测编译模式的子集,构成帧内预测模式的平衡。然后,使用截断的一元二值化对独特mpm帧内预测编译模式的所述子集进行编译。
本公开还提供一种用于jvet帧内预测的视频编译系统,在一些实施例中,该系统可以包括以下步骤:在存储器中实例化67种独特帧内预测编译模式的集合;在存储器中实例化来自于所述独特帧内预测编译模式的集合的独特mpm帧内预测编译模式的子集;在存储中实例化来自于除了所述独特mpm帧内预测编译模式的子集之外的所述独特帧内预测编译模式的集合的16种独特选定帧内预测模式的子集;在存储器中实例化来自于除了所述独特mpm帧内预测编译模式的子集之外和除了所述独特选定帧内预测编译模式的子集之外的所述独特帧内预测编译模式的集合的独特未选定帧内预测编译模式的子集;使用截断的一元二值化来对所述独特mpm帧内预测编译模式的子集进行编码;以及使用固定长度码的4个比特对所述16种独特选定帧内预测编译模式的子集进行编码。
附图说明
在附图的帮助下解释本发明的更多细节,其中:
图1a描绘当前编译块和相关联的邻近块。
图1b描绘用于帧内模式预测的当前jvet编译的表格。
图1c描绘将帧划分为多个编译树单元(ctu)。
图2描绘使用四叉树分割和对称二进制分割的方法将ctu分割成编译单元(cu)的示例性分割。
图3描绘图2的分割的四叉树加二叉树(qtbt)表示。
图4描绘将cu分割为两个较小cu的四种可能类型的非对称二进制分割。
图5描绘使用四叉树分割、对称二进制分割和非对称二进制分割将ctu分割成cu的示例性分割。
图6描绘图5的分割的qtbt表示。
图7描绘用于jvet编码器中的cu编译的简化框图。
图8描绘用于jvet中的亮度分量的67种可能的帧内预测模式。
图9描绘用于jvet编码器中的cu编译的简化框图。
图10描绘jvet编码器中的cu编译的方法的实施例。
图11描绘用于jvet编码器中的cu编译的简化框图。
图12描绘用于jvet解码器中的cu解码的简化框图。
图13描绘用于帧内模式预测的jvet编译的替代简化框图。
图14描绘用于帧内模式预测的替代jvet编译的表格。
图15描绘适合于和/或被配置成处理cu编译的方法的计算机系统的实施例。
图16描绘用于jvet编码器/解码器中的cu编译/解码的编码器/解码器系统的实施例。
具体实施方式
图1描绘将帧划分成多个编译树单元(ctu)100。帧可以是视频序列中的图像。帧可以包括矩阵或矩阵的集合,具有表示图像中的强度度量的像素值。因此,这些矩阵的集合可以生成视频序列。像素值可以定义为表示全色视频编译中的颜色和亮度,其中像素被划分成三个通道。例如,在ycbcr色彩空间中,像素可以具有表示图像中灰度强度的亮度值y和表示色彩从灰色到蓝色和红色的差异程度的两个色度值,cb和cr。在其他实施例中,像素值可以用不同色彩空间或模型中的值表示。视频的分辨率可以确定帧中的像素的数目。较高的分辨率可能意味着更多的像素和更好的图像清晰度,但也可能导致更高的带宽、存储和传输要求。
可以使用jvet对视频序列的帧进行编码和解码。jvet是正在由联合视频探索小组开发的视频编译方案。jvet的版本已在jem(联合探索模型)编码器和解码器中实现。与如同hevc(高效视频编译)的其他视频编译方案类似,jvet是基于块的混合空时预测编译方案。在用jvet进行编译的期间,首先将帧划分成称为ctu100的正方形块,如图1中所示。例如,ctu100可以是128×128个像素的块。
图2描绘将ctu100分割成cu102的示例性分割。可以将帧中的每个ctu100分割成一个或多个cu(编译单元)102。cu102可以被用于如下所述的预测和变换。与hevc不同,在jvet中,cu102可以是矩形或正方形,并且可以被编译,而无需进一步分割成预测单元或变换单元。cu102可以与它们的根ctu100一样大,或者可以是与4×4个块一样小的根ctu100的更小的细分。
在jvet中,可以根据四叉树加二叉树(qtbt)方案将ctu100分割成cu102,其中可以根据四叉树将ctu100递归分离成正方形块,并且然后可以根据二叉树将这些正方形块递归地水平或垂直分离。可以设置参数,诸如ctu大小、用于四叉树和二叉树叶节点的最小大小、用于二叉树根节点的最大大小以及用于二叉树的最大深度,以根据qtbt控制分离。
在一些实施例中,jvet可以将qtbt的二进制树部分中的二进制分割限制为对称分割,其中可以沿着中线将块垂直或水平地划分为两半。
通过非限制性示例,图2示出通过指示四叉树分离的实线和指示对称二叉树分离的虚线被分割成cu102的ctu100。如图所示,二进制分离允许对称的水平分离和垂直分离以定义ctu的结构以及其细分成cu。
图3示出图2的分割的qtbt表示。四叉树根节点表示ctu100,四叉树部分中的每个子节点表示从父正方形块中分离出的四个正方形块之一。然后,可以使用二叉树将由四叉树叶节点表示的正方形块对称地划分零次或多次,其中四叉树叶节点是二叉树的根节点。在二叉树部分的每个级别处,可以对称、垂直或水平地划分块。设置为“0”的标志指示该块被水平对称地分离,而设置为“1”的标志指示该块被垂直对称地分离。
在其他实施例中,jvet可以在qtbt的二进制树部分中允许对称二进制分割或非对称二进制分割。在分割预测单元(pu)时,在hevc中的不同上下文中允许进行非对称运动分割(amp)。但是,对于根据qtbt结构在jvet中对cu102进行分割,当cu102的相关区域未被定位在穿过cu中心的中线的任意一侧时,相对于对称二进制分割,非对称二进制分割可以导致改进的分割。通过非限制性示例,当cu102描绘接近cu的中心的一个对象和在cu102的侧面处的另一个对象时,cu102可以被非对称地分割以将每个对象放置在不同大小的单独的较小的cu102中。
图4描绘四种可能类型的非对称二进制分割,其中,cu102沿着穿过cu102的长度或高度的线被分离成两个较小的cu102,使得较小的cu102之一是父cu102的大小的25%并且另一个是父cu102的大小的75%。图4中示出的四种类型的非对称二进制分割允许cu102沿着从cu102的左侧开始的路线的25%、从cpu102的右侧开始的路线的25%、从cpu102的顶部开始的路线的25%、或者从cpu102的底部开始的路线的25%的线被分离。在替代实施例中,在其处cu102被分离的不对称分割线可以被定位在任何其他位置处,这样cu102不会对称地划分成两半。
图5描绘使用允许qtbt的二进制树部分中的对称二进制分割和非对称二进制分割两者的方案被分割成cu102的ctu100的非限制性示例。在图5中,虚线示出不对称的二进制分割线,其中,使用图4中所示的一种分割类型来分离父cu102。
图6示出图5的分割的qtbt表示。在图6中,从节点延伸的两条实线指示在qtbt的二叉树部分中的对称分割,而从节点延伸的两条虚线指示在二叉树部分中的非对称分割。
可以在比特流中编译语法,其指示如何将ctu100分割成cu102。通过非限制性示例,可以在比特流中编译语法,其指示哪些节点通过四叉树分割被分离,哪些节点通过对称二进制分割被分离,并且哪些节点通过非对称二进制分割被分离。类似地,可以在用于通过非对称二进制分割分离的节点的比特流中编译语法,其指示使用哪种类型的非对称二进制分割,诸如图4中所示的四种类型之一。
在一些实施例中,非对称分割的使用可以限于在qtbt的四叉树部分的叶节点处分割cu102。在这些实施例中,在四叉树部分中使用四叉树分割从父节点分离的子节点处的cu102可以是最终cu102,或者可以使用四叉树分割、对称二进制分割或非对称二进制分割进一步分离它们。使用对称二进制分割分离的二叉树部分中的子节点可以是最终cu102,或者可以仅使用对称二进制分割将它们进一步递归分离一次或多次。在不允许进一步分离的情况下,使用非对称二进制分割从qt叶节点分离出的二进制树部分中的子节点可以是最终cu102。
在这些实施例中,将非对称分割的使用限制为分离四叉树叶节点可以降低搜索复杂度和/或限制开销比特。因为只有四叉树叶节点可以通过非对称分割进行分离,所以使用非对称分割可以直接指示qt部分分支的结束,而无需其他语法或进一步信令。类似地,因为不能进一步分离非对称分割的节点,所以在节点上使用非对称分割还可以直接指示其非对称分割的子节点是最终cu102,而无需其他语法或进一步信令。
在替代实施例中,诸如当限制搜索复杂度和/或限制开销比特的数量成为无关紧要时,非对称分割可以用于分离通过四叉树分割、对称二进制分割和/或非对称二进制分割生成的节点。
在使用上述任意qtbt结构进行四叉树分离和二叉树分离之后,由qtbt的叶节点表示的块表示要编译的最终cu102,诸如使用帧间预测(interprediction)或帧内预测(intraprediction)的编译。对于用帧间预测编译的片(slice)或全帧,可以将不同的分割结构用于亮度和色度分量。例如,对于帧间片,cu102可以具有用于不同颜色分量的编译块(cb),诸如一个亮度cb和两个色度cb。对于通过帧内预测编译的片或全帧,针对亮度和色度分量的分割结构可以相同。
在替代实施例中,jvet可以使用两级编译块结构作为上述qtbt分割的替代或扩展。在两级编译块结构中,首先可以在高级别处将ctu100分割成基本单元(bu)。然后可以在较低级别处将bu分割成多个操作单元(ou)。
在采用两级编译块结构的实施例中,在高级别处,可以根据上述qtbt结构之一或根据诸如在其中块能够被仅分离成四个大小相等的子块的hevc中使用的四叉树(qt)结构的四叉树(qt)结构将ctu100分割成bu。通过非限制性示例,可以根据以上关于图5-图6描述的qtbt结构将ctu102分割成bu,使得可以使用四叉树分割、对称二进制分割或非对称二进制分割来分离四叉树部分中的叶节点。在此示例中,qtbt的最终叶节点可以是bu而不是cu。
在两级编译块结构中的较低级别处,从ctu100分割的每个bu可以进一步被分割成一个或多个ou。在一些实施例中,当bu为正方形时,可以使用四叉树分割或二进制分割,诸如对称或非对称二进制分割,将其分离成ou。但是,当bu不是正方形时,只能使用二进制分割将其分离为ou。限制能够被用于非正方形bu的分割类型可以限制用于用信号发送用于生成bu的分割类型的比特数。
尽管下面的讨论描述编译cu102,但是在使用两级编译块结构的实施例中可以对bu和ou而不是cu102进行编译。通过非限制性示例,bu可以被用于诸如帧内预测或帧间预测的较高级别的编译操作,而较小的ou可以被用于诸如变换和生成变换系数的较低级别的编译操作。因此,指示是通过帧内预测还是帧间预测进行编译的用于bu的用于被编译的语法,或者识别特定帧内预测模式或运动矢量的信息用于编码bu。类似地,ou的语法可以识别用于对ou进行编译的特定变换操作或量化的变换系数。
图7描绘用于jvet编码器中的cu编译的简化框图。视频编译的主要阶段包括分割以识别如上所述的cu102、随后在704或706处使用预测对cu102进行编码、在708处生成残余cu710、在712处进行变换、在716进行量化、以及在720进行熵编译。图7中所图示的编码器和编码过程还包括解码过程,下面将对其进行更详细的描述。
考虑到当前cu102,编码器可以在704处在空间上使用帧内预测或在706处在时间上使用帧间预测来获得预测cu702。预测编译的基本思想是发送原始信号和原始信号的预测之间的差分或残差信号。在接收器侧,可以通过将残差和预测相加来重构原始信号,如下面将会描述的。因为差分信号具有比原始信号低的相关性,所以对于其传输需要更少的比特。
完全用帧内预测的cu102编译的片,诸如整个图片或图片的一部分,可以是i片,其可以不参考其他片而被解码,并且正因如此,其可以是解码可以开始的可能点。用至少一些帧间预测的cu编译的片可以是可以基于一个或多个参考图片解码的预测(p)或双向预测(b)片。p片可以与先前编译的片一起使用帧内预测和帧间预测。例如,通过使用帧间预测,与i片相比可以进一步压缩p片,但是需要对先前编译的片进行编译以对它们进行编译。b片可以使用应用来自两个不同帧的插值预测的帧内预测或帧间预测,使用来自先前和/或后续片的数据进行编码,从而增加运动估计过程的准确性。在一些情况下,还可以使用帧内块复制对p片和b片编码或替换地编码,其中使用来自同一片的其他部分的数据。
如以下将讨论的,可以基于来自先前编译的cu102(诸如,邻近cu102或参考图片中的cu102)的重构的cu734来执行帧内预测或帧间预测。
当在704处使用帧内预测对cu102进行空间编译时,可以发现帧内预测模式,其基于来自图片中的邻近cu102的样本来最佳地预测cu102的像素值。
当对cu的亮度分量进行编译时,编码器可以生成候选帧内预测模式的列表。尽管hevc具有针对亮度分量的35个可能的帧内预测模式,但是在jvet中,存在用于亮度分量的67个可能的帧内预测模式。这些包括使用从邻近像素生成的值的三维平面的平面模式、使用从邻近像素平均的值的dc模式以及使用沿着指示的方向从邻近像素复制的值的在图8中示出的65个方向模式。
当生成用于cu的亮度分量的候选帧内预测模式的列表时,该列表上的候选模式的数量可以取决于cu的大小。候选列表可以包括:hevc的35种模式的子集,其具有最低satd(绝对变换差之和)成本;为邻接从hevc模式中找到的候选的jvet添加的新的定向模式;以及基于用于先前编译的邻近块的帧内预测模式以及默认模式列表来识别的用于cu102的六个最可能模式(mpm)的集合当中的模式。
当编译cu的色度分量时,还可以生成候选帧内预测模式的列表。候选模式列表可以包括利用来自亮度样本的跨分量线性模型投影生成的模式、针对在色度块中特定共置位置中的亮度cb找到的帧内预测模式、以及先前为邻近块找到的色度预测模式。编码器可以在列表中找到具有最低速率失真成本的候选模式,并且在对cu的亮度和色度分量进行编译时使用这些帧内预测模式。可以在指示用于对每个cu102进行编译的帧内预测模式的比特流中对语法进行编译。
在已经选择用于cu102的最佳帧内预测模式之后,编码器可以使用那些模式来生成预测cu402。当选定模式为定向模式时,可以使用4抽头滤波器来改进定向精度。可以使用边界预测滤波器,诸如2抽头或3抽头滤波器来调整预测块顶部或左侧处的列或行。
可以利用位置相关帧内预测组合(pdpc)过程进一步平滑预测cu702,该位置相关帧内预测组合(pdpc)过程使用邻近块的未滤波的样本来调整基于邻近块的已滤波的样本而生成的预测cu702,或者是使用3抽头或5抽头低通滤波器的自适应参考样本平滑以处理参考样本。
当在706处通过帧间预测对cu102进行时间编译时,可以找到运动矢量(mv)的集合,其指向最佳预测cu102的像素值的参考图片中的样本。帧间预测通过表示片中像素块的位移来利用片之间的时间冗余。通过称为运动补偿的过程,根据前面或后面片中的像素值确定位移。指示像素相对于特定参考图片的位移的运动矢量和相关联的参考索引可以与原始像素和运动补偿像素之间的残差一起在比特流中被提供给解码器。解码器可以使用残差和用信号发送运动矢量以及参考索引来重构重构片中的像素块。
在jvet中,可以以1/16像素存储运动矢量精度,并且可以用四分之一像素分辨率或整数像素分辨率对运动矢量和cu的预测运动矢量之间的差进行编译。
在jvet中,可以使用诸如高级时间运动矢量预测(atmvp)、空时运动矢量预测(stmvp)、仿射运动补偿预测、模式匹配运动矢量推导(pmmvd)和/或双向光流(bio)的技术为cu102内的多个子cu找到运动矢量。
使用atmvp,编码器可以找到cu102的时间矢量,其指向参考图片中的对应块。可以基于为先前编译的邻接cu102找到的运动矢量和参考图片来找到时间矢量。使用要通过用于整个cu102的时间矢量指向的参考块,可以为在整个cu102内的每个子cu找到运动矢量。
stmvp可以通过缩放和平均为利用帧间预测先前编译的邻近块找到的运动矢量以及时间矢量来找到子cu的运动矢量。
仿射运动补偿预测可以被用于基于为块的顶角找到的两个控制运动向量来预测块中的每个子cu的运动向量的场。例如,可以基于为cu102内的每个4x4块找到的顶角运动矢量来导出子cu的运动矢量。
pmmvd可以使用双向匹配或模板匹配来找到当前cu102的初始运动矢量。双向匹配可以沿着运动轨迹查看当前cu102和两个不同参考图片中的参考块,而模板匹配可以查看当前cu102中的相应块以及由模板标识的参考图片。然后,可以针对每个子cu分别修正为cu102找到的初始运动矢量。
当基于更早和更晚的参考图片以双向预测执行帧间预测时可以使用bio,并且允许基于两个参考图片之间的差异的梯度来为子cu找到运动矢量。
在某些情况下,可以基于邻接当前cu102的样本和邻接由候选运动向量标识的参考块的相应样本在cu级别处使用局部亮度补偿(lic)来找到用于缩放因子参数和偏移参数的值。在jvet中,lic参数可以更改并在cu级别处用信号发送。
对于上述方法中的一些,可以以cu级别将为cu的每个子cu找到的运动矢量用信号发送解码器。对于诸如pmmvd和bio的其他方法,不会在比特流中用信号发送运动信息以节省开销,并且解码器可以通过相同的过程导出运动矢量。
在已经找到用于cu102的运动矢量之后,编码器可以使用那些运动矢量来生成预测cu702。在某些情况下,当已经为单个子cu找到运动矢量时,当通过将那些运动矢量与先前为一个或多个邻近的子cu找到的运动矢量进行组合生成预测cu702时可以使用重叠块运动补偿(obmc)。
当使用双向预测时,jvet可以使用解码器侧运动矢量修正(dmvr)来找到运动矢量。dmvr允许使用双向模板匹配过程基于为双向预测而找到的两个运动矢量来找到运动矢量。在dmvr中,可以找到用两个运动矢量中的每个运动矢量生成的预测cu702的加权组合,并且可以通过用最佳指向组合的预测cu702的新运动矢量替换它们来修正两个运动矢量。两个修正的运动向量可以被用于生成最终预测cu702。
在708处,如上所述,一旦通过在704处的帧内预测或在706处的帧间预测找到预测cu702,编码器就可以从当前cu102减去预测cu702以找到残余cu710。
编码器可以在712处使用一个或多个变换操作以将残余cu710转换成在变换域中表达残余cu710的变换系数714,诸如使用离散余弦块变换(dct变换)以将数据变换到变换域。与hevc相比,jvet允许进行更多类型的变换操作,包括dct-ii、dst-vii、dst-vii、dct-viii、dst-i和dct-v操作。可以将允许的变换操作分组为子集,并且可以由编码器用信号发送使用哪些子集以及那些子集中的哪些特定操作的指示。在一些情况下,大块大小的变换可以被用于将大于特定大小的cu102中的高频变换系数归零,使得仅为那些cu102保持低频变换系数。
在一些情况下,在前向核变换之后,可以将模式相关的不可分离的二次变换(mdnsst)应用于低频变换系数714。mdnsst操作可以基于旋转数据使用hypercube-givens变换(hygt)。当使用时,编码器可以用信号发送标识特定mdnsst操作的索引值。
在716处,编码器可以将变换系数714量化为量化的变换系数716。可以通过将系数的值除以量化步长来计算每个系数的量化,从量化参数(qp)导出该量化步长。在一些实施例中,qstep被定义为2(qp-4)/6。因为可以将高精度变换系数714转换为具有有限数量的可能值的量化变换系数716,所以量化可以协助数据压缩。因此,变换系数的量化可以限制由变换过程生成和发送的比特量。然而,尽管量化是有损操作,并且不能恢复量化损耗,但是量化过程呈现在重构序列的质量和表示该序列所需的信息量之间的权衡。例如,较低的qp值可以导致更好质量的解码视频,尽管可能需要更高的数据量来用于表示和传输。相反,高qp值会导致质量较低的重构视频序列,但数据和带宽需求较低。
jvet可以利用基于方差的自适应量化技术,其允许每个cu102对其编译或过程使用不同的量化参数(而不是在帧的每个cu102的编译中使用相同的帧qp)。基于方差的自适应量化技术可以自适应地降低某些块的量化参数,而在其他块中增加量化参数。为了为cu102选择特定的qp,计算cu的方差。简而言之,如果cu的方差高于帧的平均方差,则可以为cu102设置比帧的qp高的qp。如果cu102呈现出比帧的平均方差低的方差,则可以指配较低的qp。
在720处,编码器可以通过对量化的变换系数718进行熵编译来找到最终压缩比特722。熵编译旨在去除要发送的信息的统计冗余。在jvet中,可以使用cabac(上下文自适应二进制算术编码)来对量化的变换系数718进行编译,其使用概率度量来去除统计冗余。对于具有非零的量化变换系数718的cu102,可以将量化的变换系数718转换为二进制。然后可以使用上下文模型对二进制表示的每个比特(“bin”)进行编码。cu102可以被分解成三个区域,每个区域具有其自己的上下文模型集合以用于该区域内的像素。
可以执行多次扫描操作以对bin进行编码。在对前三个bin(bin0、bin1和bin2)进行编码的操作中,可以通过在由模板标识的多达五个先前编译的邻近的量化变换系统中找到bin位置的总和来找到指示要用于该bin的上下文模型的索引值。
上下文模型可以基于bin的值为“0”或“1”的概率。在对值进行编译时,可以基于遇到的“0”和“1”值的实际数目来更新上下文模型中的概率。虽然hevc使用固定表以为每个新图片重新初始化上下文模型,但是在jvet中,可以基于为先前编译的帧间预测的图片开发的上下文模型来初始化新帧间预测的图片的上下文模型的概率。
编码器可以产生比特流,该比特流包含残余cu710的熵编码的比特722、诸如选择的帧内预测模式或运动矢量的预测信息、如何根据qtbt结构从ctu100分割cu102的指示符、和/或其他有关编码视频的信息。比特流可以由解码器解码,如下所述。
除了使用量化的变换系数718来找到最终的压缩比特722之外,编码器还可以通过遵循与解码器将用于生成重构的cu734相同的解码过程,来使用量化的变换系数718来生成重构的cu734。因此,一旦编码器计算并量化变换系数,量化的变换系数718可以被发送到编码器中的解码环路(loop)。在对cu的变换系数进行量化之后,解码环路允许编码器生成与解码器在解码过程中生成的cu734相同的重构cu734。因此,编码器可以使用当解码器在执行针对新的cu102的帧内预测或帧间预测时将用于邻近cu102或参考图片的相同的重构cu734。重构cu102、重构片或完全重构帧可以用作进一步的预测阶段的参考。
在获取重构图像的像素值的编码器的解码环路(对于解码器中的相同操作,请参见下面的内容)处,可以执行去量化过程。为了对帧进行去量化,例如,将帧的每个像素的量化值乘以量化步长,例如,上述的(qstep),以获得重构的去量化变换系数726。例如,在编码器中的图7中所示的解码过程中,可以在724处对残余cu710的量化变换系数718进行去量化以找到去量化的变换系数726。如果在编码期间执行mdnsst操作,则该操作可以在去量化之后反转。
在728处,可以对去量化的变换系数726进行逆变换,以找到重构的残余cu730,诸如通过将dct应用于这些值以获得重构的图像。在732处,可以将重构的残余cu730添加到在704处通过帧内预测或在706处通过帧间预测而找到的对应预测cu702,以便于找到重构的cu734。
在736处,可以在图片级或cu级处,在解码过程期间(在编码器中,或如下所述,在解码器中)将一个或多个滤波器应用于重构数据。例如,编码器可以应用去块滤波器,样本自适应偏移(sao)滤波器和/或自适应环路滤波器(alf)。编码器的解码过程可能会实现滤波器,以估算可解决重构图像中潜在伪影的最佳滤波器参数并将其发送到解码器。这样的改进增加重构视频的客观和主观质量。在去块滤波中,可以修改子cu边界附近的像素,而在sao中,可以使用边缘偏移或带偏移分类来修改ctu100中的像素。jvet的alf可以针对每个2x2块使用具有圆形对称形状的滤波器。可以用信号发送用于每个2x2块的滤波器的大小和标识的指示。
如果重构图片是参考图片,则可以将它们存储在参考缓冲区738中,以在706处对未来cu102进行帧间预测。
在以上步骤期间,jvet允许使用内容自适应裁剪操作来调整颜色值以适合上下裁剪界限。裁剪界限可以针对每个片而改变,并且可以在比特流中用信号发送标识界限的参数。
图9描绘用于jvet解码器中的cu编译的简化框图。jvet解码器可以接收包含关于编码的cu102的信息的比特流。该比特流可以指示如何根据qtbt结构从ctu100分割图片的cu102。作为非限制性示例,比特流可以使用四叉树分割、对称二进制分割和/或非对称二进制分割来识别如何在qtbt中从每个ctu100分割cu102。比特流还可以指示用于cu102的预测信息,诸如帧内预测模式或运动矢量,以及表示熵编码的残余cu的比特902。
在904处,解码器可以使用由编码器在比特流中用信号发送的cabac上下文模型来解码熵编码的比特902。解码器可以以在编码过程中进行更新的相同方式使用由编码器用信号发送的参数来更新上下文模型的概率。
在904处将熵编码反转以找到量化的变换系数906之后,解码器可以在908处对其进行去量化以找到经去量化的变换系数910。如果在编码期间执行mdnsst操作,则该操作可以在去量化之后被解码器反转。
在912处,可对经去量化的变换系数910进行逆变换以找到重构的残余cu914。在916处,可以将重构的残余cu914添加到在922处利用帧内预测或在924处利用帧间预测而找到的对应预测cu926以便于找到重构的cu918。
在920处,可以以图片级别或cu级别将一个或多个滤波器应用于重构数据。例如,解码器可以应用去块滤波器、样本自适应偏移(sao)滤波器和/或自适应环路滤波器(alf)。如上所述,位于编码器的解码环路中的环路内滤波器可以用于估计最优滤波器参数以增加帧的客观和主观质量。这些参数被发送到解码器以在920处对重构帧进行滤波以匹配编码器中的滤波后的重构帧。
在通过找到重构的cu918并应用用信号通知的滤波器已经生成重构的图片之后,解码器可以将重构的图片作为输出视频928输出。如果将重构的图片用作参考图片,则可以将其存储在参考缓冲区930中,以在924处对未来cu102进行帧间预测。
图10描绘在jvet解码器中的cu编译1000的方法的实施例。在图10中所示的实施例中,在步骤1002中,可以接收编码的比特流902,然后在步骤1004中,可以确定与编码的比特流902相关联的cabac上下文模型,并且然后可以在步骤1006中使用确定的cabac上下文模型来对编码的比特流902进行解码。
在步骤1008中,可以确定与编码的比特流902相关联的量化变换系数906,并且然后可以在步骤1010中从量化变换系数906确定去量化变换系数910。
在步骤1012中,可以确定在编码期间是否执行mdnsst操作和/或比特流902是否包含比特流902应用mdnsst操作的指示。如果确定编码过程期间执行mdnsst操作或比特流902包含将mdnsst操作应用于比特流902的指示,则在步骤1016中对比特流902执行逆变换操作912之前可以实现逆mdnsst操作1014。可替选地,可以在步骤1016中对比特流902执行操作912,而不在步骤1014中应用逆mdnsst操作。步骤1016中的逆变换操作912可以确定和/或构造重构的残余cu914。
在步骤1018中,可以将来自步骤1016的重构残余cu914与预测cu918组合。预测cu918可以是在步骤1020中确定的帧内预测cu922和在步骤1022确定的帧间预测单元924之一。
在步骤1024中,可以将任何一个或多个滤波器920应用于重构的cu914并在步骤1026中输出。在一些实施例中,可以在步骤1024中不应用滤波器920。
在一些实施例中,在步骤1028中。可以将重构的cu918存储在参考缓冲区930中。
图11描绘用于jvet编码器中的cu编译的简化框图1100。在步骤1102中,jvet编译树单元可以被表示为四叉树加二叉树(qtbt)结构中的根节点。在一些实施例中,qtbt可以具有从根节点分支的四叉树和/或从一个或多个四叉树的叶节点分支的二叉树。来自步骤1102的表示可以进行到步骤1104、1106或1108。
在步骤1104中,可以采用非对称二进制分割将表示的四叉树节点分离为两个大小不等的块。在一些实施例中,可以在从作为能够表示最终编译单元的叶节点的四叉树节点分支的二叉树中表示分离的块。在一些实施例中,在从作为表示最终编译单元的叶节点的四叉树节点分支的二叉树中不允许进一步分离。在一些实施例中,非对称分割可以将编译单元分离成大小不等的块,第一块表示四叉树节点的25%,并且第二块表示四叉树节点的75%。
在步骤1106中,可以采用四叉树分割以将表示的四叉树节点分割成四个大小相等的正方形块。在一些实施例中,分离的块可以被表示为表示最终编译单元的四叉树节点,或者可以被表示为可以通过四叉树分割、对称二进制分割或非对称二进制分割再次分割的子节点。
在步骤1108中,可以采用四叉树分割将表示的四叉树节点分离成相等大小的两个块。在一些实施例中,分离的块可以被表示为表示最终编译单元的四叉树节点,或者可以被表示为可以通过四叉树分割、对称二进制分割或非对称二进制分割再次分割的子节点。
在步骤1110中,可以将来自步骤1106或步骤1108的子节点表示为配置成被编码的子节点。在一些实施例中,子节点可以利用jvet由二叉树的叶节点表示。
在步骤1112中,可以使用jvet对来自步骤1104或1110的编译单元进行编码。
图12描绘用于在jvet解码器中的cu解码的简化框图1200。在图12中描绘的实施例中,在步骤1202中,可以接收指示如何根据qtbt结构将编译树单元分割成编译单元的比特流。比特流可以指示如何通过四叉树分割、对称二进制分割或非对称二进制分割中的至少一个来分离四叉树节点。
在步骤1204中,可以识别由qtbt结构的叶节点表示的编译单元。在一些实施例中,编译单元可以指示节点是否使用非对称二进制分割从四叉树分离叶节点。在一些实施例中,编译单元可以指示节点表示要解码的最终编译单元。
在步骤1206中,可以使用jvet对识别的编译单元进行解码。
图13描绘用于帧内模式预测1300的jvet编译的替代简化框图。在图13中描绘的实施例中,步骤1302中,可以在存储器中标识并且实例化mpm的集合,然后在步骤1304中,可以在存储器中标识并实例化16种选定模式的集合,并且在步骤1304中,可以在存储其中定义和实例化67种模式的平衡。在一些实施例中,可以从6个mpm的标准集合减少mpm的集合。在一些实施例中,mpm的集合可以包括5个独特模式,选定模式可以包括16个独特模式,并且未选定模式集合可以包括剩余的46个未选定独特模式。然而,在替代实施例中,mpm的集合可以包括更少的独特模式,选定模式可以保持固定为16个独特模式,并且可以相应地调整未选定的独特模式集的大小以容纳总共67种模式。
通过非限制性示例,在一些实施例中,其中mpm的集合包括5种独特模式而不是六个mpm,因此,如果使用截断的一元二值化并且可以利用用于5个mpm的新二值化,则为mpm模式指配的bin的数量因此可以等于或小于五个bin。因此,在一些实施例中,可以通过对这些62种帧内模式进行均匀地二次采样来生成62种剩余帧内模式当中的16种选定模式,并且通过4比特的固定长度码来编译每种模式。通过非限制性示例,如果假设剩余的62种模式被索引为{0,1,2,…,61},则16种选定模式={0,4,8,12,16,20,24,28,32,36,40,44,48,52,56,60}。剩余46种未选定模式={1,2,3,5,6,7,9,10…59,61},其中可以用截断的二进制码对这46种未选定模式进行编译。
图14描绘根据图13的用于帧内模式预测的替代jvet编译的表1400。在图14所描绘的实施例中,帧内预测模式1402被示为包括5个mpm、16个选定模式和46个未选定模式,其中可以使用截短的一元二值化来编码用于mpm的二进制串1404,可以使用4比特的固定长度码来对16个选定模式进行编译,并且可以使用截断二进制编译对46种未选定模式进行编译。
在图13的替代实施例中,可以利用6个mpm,但是如图14中所示,仅将mpm列表上的前五个mpm二值化,并使用当前jvet中描述的基于当前上下文的方法进行编译。现在将mpm列表上的第六个mpm视为16种选定模式之一,并且与其他15种选定模式一起用4比特的固定长度码进行编译。
作为非限制性示例,如果将剩余的61种模式索引为{0,1,2,…,60},则可以通过对剩余的61种帧内模式进行均匀地二次采样来获得如下15种选定模式:选定模式集可以是{0,5,10,14,18,22,26,30,34,38,42,46,50,55,60},其中将通过4比特的固定长度码对15种选定模式加上第六个mpm进行编译,如在以下集合中:{第六mpm,0,5,10,14,18,22,26,30,34,38,42,46,50,55,60},并且在下面的集合示出46种未选定模式的平衡,并通过截断的二进制码将其编译为未选定模式集合={1,2,3,4,6,7,8,9,11,12…49,51,52,53,54,56,57,58,59}。
在图13的又一替代实施例中,仅mpm列表上的前五个mpm可以被二值化,如图14中所示,并使用当前jvet标准中描述的基于当前上下文的方法进行编译。在这样的实施例中,mpm列表上的第六mpm可以被认为是16种选定模式之一,并且与其他15种选择模式一起利用4比特的固定长度码进行编译。因此,可以使用任何已知的方便和/或期望的选择过程来建立其他15种选定模式的选择。通过非限制性示例,可以围绕mpm模式,或者围绕(基于内容的)统计流行模式,或者围绕受训的或历史流行模式,或使用其他方法或过程来选择它们。
再次,选择5个mpm仅仅是非限制性示例,并且在替代实施例中,可以将mpm的集合进一步减少到4或3个mpm或扩展到6个以上,其中仍然存在16种选定模式,并且67个(或其他已知的、方便的和/或期望的总数)帧内编译模式的平衡被包括在未选定的帧内编译模式的集合中。也就是说,可以设想帧内编译模式的总数大于或小于67的实施例是下述实施例,其中mpm集合可以包含任何已知的方便的或期望数量的mpm,并且选定模式的数量可以是任何已知的方便和/或期望的数量。
实践实施例所需的指令序列的执行可以由如图15中所示的计算机系统1500执行。在实施例中,指令序列的执行由单个计算机系统1500执行。根据其他实施例,通过通信链路1515耦合的两个或更多个计算机系统1500可以相互协调地执行指令序列。尽管下面将仅描述一个计算机系统1500,但是应当理解,可以采用任何数量的计算机系统1500来实践实施例。
现在将参考图15描述根据实施例的计算机系统1500,图15是计算机系统1500的功能组件的框图。如本文所使用的,术语计算机系统1500被广泛地用于描述任何计算设备,其可以存储并独立运行一个或多个程序。
每个计算机系统1500可以包括耦合到总线1506的通信接口1514。通信接口1514提供计算机系统1500之间的双向通信。各自的计算机系统1500的通信接口1514发送和接收电、电磁或光信号,其包括表示各种类型的信号信息,例如,指令、消息和数据的数据流。通信链路1515将一个计算机系统1500与另一计算机系统1500相链接。例如,通信链路1515可以是lan,在这样的情况下通信接口1514可以是lan卡,或者通信链路1515可以是pstn,在这样的情况下通信接口1514可以是综合业务数字网(isdn)卡或调制解调器,或者通信链路1515可以是因特网,在这种情况下通信接口1514可以是拨号、电缆或无线调制解调器。
计算机系统1500可以通过其各自的通信链路1515和通信接口1514发送和接收消息、数据和指令,包括程序,即,应用程序、代码。当其被接收时,所接收的程序代码可以由各自的处理器1507执行,并且/或者存储在存储设备1510或其他关联的非易失性介质中,以供以后执行。
在实施例中,计算机系统1500与数据存储系统1531,例如,包含数据库1532的数据存储系统1531一起操作,该数据库1532可由计算机系统1500容易地访问。计算机系统1500通过数据接口1533与数据存储系统1531通信。耦合到总线1506的数据接口1533发送和接收电、电磁或光信号,其中包括表示各种类型的信号信息,例如,指令、消息和数据的数据流。在实施例中,数据接口1533的功能可以由通信接口1514执行。
计算机系统1500包括:总线1506或其他通信机制,用于传送指令、消息和数据,统一地,信息;以及一个或多个处理器1507,其与总线1506耦合以处理信息。计算机系统1500还包括主存储器1508,诸如随机存取存储器(ram)或其他动态存储设备,被耦合到总线1506,用于存储动态数据和要由处理器1507执行的指令。主存储器1508还可用于在处理器1507执行指令期间存储临时数据,即,变量或其他中间信息。
计算机系统1500可以进一步包括只读存储器(rom)1509或耦合到总线1506的其他静态存储设备,用于存储用于处理器1507的静态数据和指令。也可以提供诸如磁盘或光盘的存储设备1510并将其耦合到总线1506,用于存储用于处理器1507的数据和指令。
计算机系统1500可以经由总线1506耦合到显示设备1511,例如但不限于阴极射线管(crt)或液晶显示器(lcd)监视器,用于向用户显示信息。输入设备1512,例如,字母数字键和其他键,被耦合到总线1506,用于将信息和命令选择传送到处理器1507。
根据一个实施例,单个计算机系统1500通过它们各自的处理器1507执行包含在主存储器1508中的一个或多个指令的一个或多个序列来执行特定操作。这样的指令可以从诸如rom1509或存储设备1510的另一计算机可用介质读入到主存储器1508中。主存储器1508中包含的指令序列的执行使处理器1507执行本文所述的过程。在替代实施例中,可以使用硬连线电路代替软件指令或与软件指令结合使用。因此,实施例不限于硬件电路和/或软件的任何特定组合。
如本文所用,术语“计算机可用介质”是指提供信息或可由处理器1507使用的任何介质。这种介质可以采取许多形式,包括但不限于非易失性、易失性和传输媒介。非易失性介质,即,在没有电力的情况下可以保留信息的介质,包括rom1509、cdrom、磁带和磁盘。易失性介质,即,在没有电力的情况下不能保留信息的介质,包括主存储器1508。传输介质包括同轴电缆、铜线和光纤,包括构成总线1506的导线。传输介质也可以采用载波的形式;即,可以按频率、振幅或相位进行调制的电磁波,以发送信息信号。另外,传输介质可以采用声波或光波的形式,诸如在无线电波和红外数据通信期间生成的那些。
在前述说明书中,已经参考实施例的具体元素描述实施例。然而,显而易见的是,在不脱离实施例的更广泛精神和范围的情况下,可以对其进行各种修改和改变。例如,读者要理解,在此描述的过程流程图中示出的过程动作的特定顺序和组合仅仅是说明性的,并且可以使用不同的或附加的过程动作,或者可以使用过程动作的不同组合或顺序以实施实施例。因此,说明书和附图应被认为是说明性而非限制性的。
还应当注意,本发明可以在各种计算机系统中实现。本文描述的各种技术可以以硬件或软件或两者的组合来实现。优选地,该技术在可编程计算机上执行的计算机程序中实现,该可编程计算机均包括处理器、处理器可读的存储介质(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备以及至少一个输出设备。程序代码被应用于使用输入设备输入的数据,以执行上述功能并生成输出信息。输出信息被应用于一个或者多个输出设备。每个程序优选地以高级过程或面向对象的编程语言来实现以与计算机系统通信。但是,如果需要,可以用汇编语言或机器语言来实现程序。在任何情况下,该语言都可以是编译语言或解释语言。每个这样的计算机程序优选地存储在通过通用或专用可编程计算机可读的存储介质或设备(例如,rom或磁盘)上,用于当通过计算机读取存储介质或者设备以执行上述过程时配置和操作计算机。该系统也可以被认为实现为配置有计算机程序的计算机可读存储介质,其中,如此配置的存储介质使计算机以特定且预定的方式操作。此外,示例性计算应用的存储元件可以是能够以各种组合和配置存储数据的关系或顺序(平面文件)类型的计算数据库。
图16是可以合并本文描述的系统和设备的特征的源设备1612和目的地设备1610的高级视图。如图16中所示,示例视频编译系统1610包括源设备1612和目的地设备1616,其中,在此示例中,源设备1612生成编码的视频数据。因此,源设备1612可以被称为视频编码设备。目的地设备1616可以对由源设备1612生成的编码的视频数据进行解码。因此,目的地设备1616可以被称为视频解码设备。源设备1612和目的地设备1616可以是视频编译设备的示例。
目的地设备1616可以经由信道1616从源设备1612接收编码的视频数据。信道1616可以包括能够将编码的视频数据从源设备1612移动到目的地设备1616的一种类型的介质或设备。在一个示例中,信道1616可以包括通信介质,该通信介质使源设备1612能够将编码的视频数据直接实时地直接发送到目的地设备1616。
在此示例中,源设备1612可以根据诸如无线通信协议的通信标准来调制编码的视频数据,并且可以将调制的视频数据发送到目的地设备1616。通信介质可以包括无线或有线的通信介质,诸如射频(rf)频谱或一条或多条物理传输线。通信介质可以形成诸如局域网、广域网或诸如因特网的全球网络的基于分组的网络的一部分。通信介质可以包括路由器、交换机、基站或有助于从源设备1612到目的地设备1616的通信的其他设备。在另一个示例中,信道1616可以对应于存储由源设备1612生成的编码的视频数据的存储介质。
在图16的示例中,源设备1612包括视频源1618、视频编码器1620和输出接口1622。在一些情况下,输出接口1628可以包括调制器/解调器(调制解调器)和/或发射器。在源设备1612中,视频源1618可以包括源,诸如视频捕获设备,例如,摄像机、包含先前捕获的视频数据的视频存档、用于从视频内容提供商接收视频数据的视频馈送接口和/或用于生成视频数据的计算机图形系统、或此类源的组合。
视频编码器1620可以对捕获的、预捕获的或计算机生成的视频数据进行编码。输入图像可以由视频编码器1620接收并存储在输入帧存储器1621中。通用处理器1623可以从此处加载信息并执行编码。用于驱动通用处理器的程序可以从诸如图16中所描绘的示例存储模块的存储设备加载。通用处理器可以使用处理存储器1622来执行编码,并且通用处理器的编码信息的输出可以被存储在诸如输出缓冲区1626的缓冲区中。
视频编码器1620可以包括重采样模块1625,该重采样模块1625可以被配置成以定义至少一个基本层和至少一个增强层的可伸缩视频编译方案来编译(例如,编码)视频数据。作为编码过程的一部分,重采样模块1625可以对至少一些视频数据进行重采样,其中可以使用重采样滤波器以自适应方式执行重采样。
编码的视频数据,例如,编译的比特流,可以经由源设备1612的输出接口1628直接发送到目的地设备1616。在图16的示例中,目的地设备1616包括输入接口1638、视频解码器1630和显示设备1632。在一些情况下,输入接口1628可以包括接收机和/或调制解调器。目的地设备1616的输入接口1638通过信道1616接收编码的视频数据。编码的视频数据可以包括由视频编码器1620生成的表示视频数据的各种语法元素。这样的语法元素可以与在通信介质上发送、存储在存储介质上或存储在文件服务器中的编码视频数据一起包括。
还可以将编码的视频数据存储到存储介质或文件服务器上,以供以后由目的设备1616访问以进行解码和/或回放。例如,可以将编译的比特流临时存储在输入缓冲区1631中,然后加载到通用处理器1633中。可以从存储设备或存储器加载用于驱动通用处理器的程序。通用处理器可以使用处理存储器1632来执行解码。视频解码器1630还可以包括与视频编码器1620中采用的重采样模块1625相似的重采样模块1635。
图16描绘与通用处理器1633分离的重采样模块1635,但是本领域的技术人员将理解,重采样功能可以由通用处理器执行的程序来执行,并且视频编码器中的处理可以使用一个或多个处理器来完成。解码的图像可以被存储在输出帧缓冲区1636中,并且然后被发送到输入接口1638。
显示设备1638可以与目的地设备1616集成在一起或者可以在其外面。在一些示例中,目的地设备1616可以包括集成的显示设备,并且还可以被配置成与外部显示设备接口。在其他示例中,目的地设备1616可以是显示设备。通常,显示设备1638将解码后的视频数据显示给用户。
视频编码器1620和视频解码器1630可以根据视频压缩标准来操作。itu-tvceg(q6/16)和iso/iecmpeg(jtc1/sc29/wg11)正在研究对具有显著超过当前的高效视频编译hevc标准(包括其当前扩展和对于屏幕内容编译和高动态范围编译的近期扩展)的压缩能力的未来视频编译技术进行标准化的潜在需求。小组正在联合协作下共同开展这项探索活动,该联合协作称为联合视频探索小组(jvet),以评估该领域的他们的专家提出的压缩技术设计。jvet开发的最新成果在由j.chen、e.alshina、g.sullivan、j.ohm、j.boyce撰写的jvet-e1001-v2的“联合探索测试模型5(jem5)的算法描述”中描述。
另外地或可替选地,视频编码器1620和视频解码器1630可以根据以所公开的jvet特征起作用的其他专有或工业标准来操作。因此,诸如itu-th.264标准的其他标准,可替选地称为mpeg-4,第10部分,高级视频编译(avc),或者这些标准的扩展。因此,尽管是为jvet做新的开发,但是本公开的技术不限于任何特定的编译标准或技术。视频压缩标准和技术的其他示例包括mpeg-2、itu-th.263和专有或开源压缩格式以及相关格式。
视频编码器1620和视频解码器1630可以以硬件、软件、固件或其任何组合来实现。例如,视频编码器1620和解码器1630可以采用一个或多个处理器、数字信号处理器(dsp)、专用集成电路(asic)、现场可编程门阵列(fpga)、分立逻辑或其任意组合。当视频编码器1620和解码器1630部分地以软件实现时,设备可以将用于该软件的指令存储在合适的非暂时性计算机可读存储介质中,并且可以使用一个或多个处理器以硬件来执行指令以执行本公开的技术。视频编码器1620和视频解码器1630中的每一个可以被包括在一个或多个编码器或解码器中,其任意一个可以被集成为各自的设备中的组合编码器/解码器(codec)的一部分。
本文描述的主题的各方面可以在由诸如上述通用处理器1623和1633的计算机执行的诸如程序模块的计算机可执行指令的一般上下文中描述。通常,程序模块包括例程、程序、对象、组件、数据结构等,其执行特定的任务或实现特定的抽象数据类型。本文描述的主题的各方面也可以在分布式计算环境中实践,在分布式计算环境中,任务由通过通信网络链接的远程处理设备执行。在分布式计算环境中,程序模块可以位于包括内存存储设备的本地和远程计算机存储介质中。
存储器的示例包括随机存取存储器(ram)、只读存储器(rom)或两者。存储器可以存储用于执行上述技术的指令,诸如源代码或二进制代码。存储器还可以用于在执行将由诸如处理器1623和1633的处理器执行的指令期间存储变量或其他中间信息。
存储设备还可以存储用于执行上述技术的指令,诸如源代码或二进制代码。存储设备可以另外存储由计算机处理器使用和操纵的数据。例如,视频编码器1620或视频解码器1630中的存储设备可以是由计算机系统1623或1633访问的数据库。存储设备的其他示例包括随机存取存储器(ram)、只读存储器(rom)、硬盘驱动器、磁盘、光盘、cd-rom、dvd、闪存、usb存储卡或计算机可以读取的任何其他介质。
存储器或存储设备可以是供视频编码器和/或解码器使用或与视频编码器和/或解码器结合使用的非暂时性计算机可读存储介质的示例。非暂时性计算机可读存储介质包含用于控制计算机系统的指令,该计算机系统被配置成执行由特定实施例描述的功能。当由一个或多个计算机处理器执行时,指令可以被配置成执行在特定实施例中描述的功能。
此外,应注意,一些实施例已经被描述为可以被描绘为流程图或框图的过程。尽管每个都可以将操作描述为顺序过程,但是许多操作可以并行或同时执行。另外,可以重新排列操作的顺序。过程可能具有附图中未包括的其他步骤。
特定实施例可以在非暂时性计算机可读存储介质中实现,以供指令执行系统、装置、系统或机器使用或与其结合使用。该计算机可读存储介质包含用于控制计算机系统执行由特定实施例描述的方法的指令。该计算机系统可以包括一个或多个计算设备。当由一个或多个计算机处理器执行时,指令可以被配置成执行在特定实施例中描述的方法。
如本文的说明书和随后的整个权利要求书中所使用的,除非上下文另外明确指出,否则“一个(a)”、“一个(an)”和“该”包括复数引用。而且,如本文的说明书和随后的权利要求书中所使用的,除非上下文另外明确指出,否则“在...中”的含义包括“在...中”和“在...上”。
尽管已经以上述结构特征和/或方法动作特定的语言详细描述本发明的示例性实施例,但是要理解,本领域的技术人员将容易理解,在实质上不脱离本发明的新颖教导和优点的情况下,在示例性实施例中可以进行许多附加的修改。此外,要理解,所附权利要求书中定义的主题不必限于上述特定特征或动作。因此,这些以及所有这样的修改旨在被包括在根据所附权利要求的广度和范围上解释的本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!