一种基于后悔度的双连接基站选择方法与流程
本发明涉及基站选择算法领域,特别是涉及一种5g双连接场景中的基站选择算法。
背景技术:
在过去几年中,学术界和工业界一起参与并讨论了与下一代无线蜂窝网络相关的场景和要求,即第五代移动通信技术(5g)。这些讨论的协议现在开始成为第三代合作伙伴计划(3gpp:3rdgenerationpartnershipproject)的标准,预计到2020年将商业化。在此背景下,国际电信联盟将设想的用例分为以下几组:增强的移动宽带、超可靠和低延迟通信、大规模机器类型通信。
为了支持广泛的业务,5g空中接口(nr:newradio)有望在异构场景中与不同技术互通,其中用户设备(ue:userequipment)将具有双连接能力。基于r12标准化的lte双连接,与传统无线接入技术进行互通,已经作为5g运营要求在在3gpp中提出。
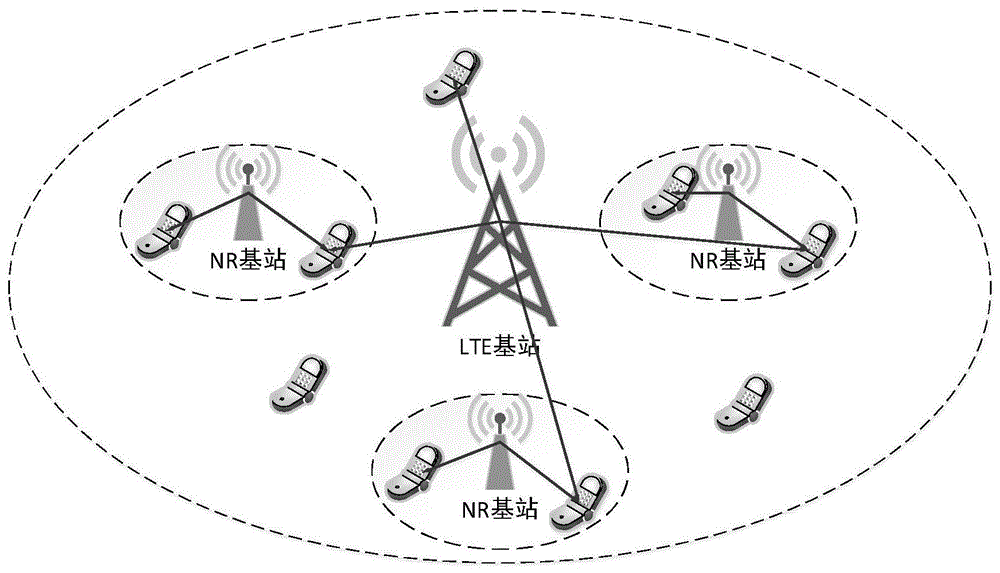
3gpp的r14中已经提出了一种5g双连接场景,如图1所示,即lte作为宏基站,nr基站作为小基站分布于lte小区内,用户可以同时连入两种基站,以实现双连接。
现有技术在基站选择问题上,仅是当前移动终端瞬时的接收信号的强度和已设定好阈值的比较下进行的基站选择。没有考虑历史的数据以及所选基站当前连入的用户数对性能的影响,这样可能导致的结果是用户的吞吐量的降低和频繁的切换。
技术实现要素:
发明目的:为了克服现有技术中存在的不足,本发明提供一种5g双连接场景中,用户端的基站选择策略,用于解决现有算法无法应用于5g双连接场景的问题的基于后悔度的双连接基站选择方法。
技术方案:为实现上述目的,本发明采用的技术方案为:
一种基于后悔度的双连接基站选择方法,本发明是终端基于强化学习思想,以后悔度为核心进行基站选择,完成强化学习对5g双连接场景下用户侧的基站选择算法的映射:环境映射为lte小区覆盖范围内所有终端的位置和连接基站的情况,行动映射为每个时刻使用本发明的用户的基站选择,回报映射为当前时刻使用本发明的用户所连入基站提供的吞吐量。以后悔度为核心,将后悔度定义为当前时刻用户所连入基站处得到的吞吐量与之前时刻从其他基站得到的吞吐量的差值,即用户如果选择了其他的基站,是否能产生更大的吞吐量,若是,则产生后悔;而当前时刻计算出的后悔度的大小会决定下一时刻用户选择每个基站的概率,且后悔度越大,则此基站下一时刻被选中的率就越大。
具体包括以下步骤:
步骤1:初始化用户本身的各种行动的概率;
步骤2:用户和其他用户在随机移动,导致了系统状态发生变化;
步骤3:在当前判决时刻,用户根据上一时刻学习到的概率选择基站;
步骤4:从基站处得到的吞吐量更新了本次基站选择的后悔度;
用户的后悔度为:
其中,
这种近似的遗憾表示分别执行动作
其中,
(2)(3)式中,平均吞吐量
其中,带有上标的吞吐量
其中,
(5)(6)式中每个时刻的吞吐量分别由(7)(8)式得到
其中,u=0表示用户没有连入lte,不为0则表示连入lte,此时吞吐量为用户a的瞬时速率ra,t,lte与当前lte基站的用户数nt,lte的比值;
其中,
步骤5:本次行动的后悔度更新了下一判决时刻基站选择的概率;
用户在下个时刻用户选择每个行动的概率为:
其中,m表示终端所在lte宏小区内,所有nr基站的数目,而(2m+1)表示所有可能行动的总数,max(|bt|)表示所有行动的后悔度的绝对值的最大值,用来归一化分子
步骤6:等待用户的下一个判决周期,继续从步骤2开始执行。
步骤1中每个行动的选择概率初始化为:
其中,行动
优选的:终端单独连入lte基站或者任一nr基站,或者同时连入lte基站和任一nr基站。
优选的:用户a从lte基站处得到的速率ra,t,lte定义为:
优选的:用户a从第v个nr基站处得到的速率ra,t,nr,v定义为:
优选的:步骤1中的初始概率为平均概率,即所有行动的概率一样。
优选的:步骤2中的回报更新会结合历史的回报,而不是当前的瞬时回报。
优选的:可以应用于具有快速时变性的场景,具体为在每个判决时刻进行基站的选择,此选择是依据概率的,用户会根据当前的回报改变下一时刻的基站选择概率。
本发明相比现有技术,具有以下有益效果:
本发明在5g双连接异构网络场景下,提出一种以用户为中心的基于强化学习思想的后悔度最小算法。强化学习算法作为机器学习算法的一个分支,对历史性的数据有很好的处理能力,在本发明中可以得到较优的基站选择算法,以提升用户所得到的吞吐量。本发明采用基于强化学习算法,将其应用于5g多连接网络中,相比典型算法,我们的算法具有更高的用户吞吐量和更少的切换次数;在5g双连接场景中,由于复杂而时变的系统状态,大多数强化学习的算法的收敛都是缓慢且任意的,而本发明可以在动态的小区环境中,在保证吞吐量的同时,保持较低的切换次数。
附图说明
图1为5g双连接场景图;
图2为算法流程图;
图3为不同算法的用户吞吐量对比图;
图4为不同算法的用户切换次数图;
图5为选择因子变化下的用户吞吐量对比图;
图6为选择因子变化下的切换次数对比图。
具体实施方式
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
一种基于后悔度的双连接基站选择方法,在未来的5g场景中,为了满足日益增长的数据业务需求,大量的5g小型基站将会被密集部署。由于5g演变的渐进性,将会出现5g和4g基站共存的场景,此时终端可以同时接入5g基站和4g基站,从而产生5g双连接场景,而当前主流的基站选择算法不能较好地运用于此场景,如图1所示,本发明的应用场景为5g双连接场景,用户可以同时连入lte基站和nr基站。以用户为中心的基于强化学习思想的基站选择算法,该算法以后悔度为核心,将后悔度定义为当前时刻用户所连入基站处得到的吞吐量与之前时刻从其他基站得到的吞吐量的差值,即用户如果选择了其他的基站,是否能产生更大的吞吐量,若是,则产生后悔;而当前时刻计算出的后悔度的大小会决定下一时刻用户选择每个基站的概率,且后悔度越大,则此基站下一时刻被选中的率就越大。如图2所示,包括以下步骤:
步骤1:初始化用户本身的各种行动的概率。
每个行动的选择概率初始化为:
其中,行动
步骤2:使用本发明算法的用户和其他用户在随机移动,导致了系统状态发生变化。
步骤3:在当前判决时刻,用户根据上一时刻学习到的概率选择基站。
步骤3中的概率结合了强化学习的思想,在“探索”和“采纳”之间找到一种平衡,使终端能自主学习到下一时刻的行动概率。
步骤4:从基站处得到的吞吐量更新了本次基站选择的后悔度。
用户的后悔度为:
其中,1τ表示在时刻其他用户的行动;
这种近似的遗憾表示分别执行动作
(2)(3)式中,吞吐量u的具体定义为:
其中,带有上标的吞吐量
其中,num_lte_t表示截止到t时刻为止,用户a连入lte的次数;num_nr_v_t示截止到t时刻为止,用户a连入第v个nr基站的次数,若某一判决时刻没有切换基站,当前用户a连入基站的累计次数仍加一;此处的平均吞吐量代替了某一时刻的回报,可以有效的减少切换次数,并提升决策的回报;
(5)(6)式中每个时刻的吞吐量分别由(7)(8)式得到
其中u=0表示用户没有连入lte,不为0则表示连入lte,此时吞吐量为用户a的瞬时速率ra,t,lte与当前lte基站的用户数nt,lte的比值;(1)式中用户a从lte基站处得到的速率定义为:
其中,所有连入到同nr基站的用户在此nr基站处得到相同的吞吐量;用户a从第v个nr基站处得到的速率定义为:
步骤5:本次行动的后悔度更新了下一判决时刻基站选择的概率。
用户在下个时刻用户选择每个行动的概率为
其中,δt=δ/tγ,0<δ<1,
步骤6:等待用户的下一个判决周期,继续从步骤2开始执行。
实例:
假设宏基站位于坐标(0,0)处,在其小区范围内,均匀分布了4个nr基站,其坐标分别为(-200,-200)、(-200,200)、(200,-200)、(200,200)。使用本发明算法的用户和其他用户在lte小区内服从泊松分布,其他用户在其自身所在小区内,随机连入lte与nr基站。在每个判决周期,用户以1-5m/s的速度向任意方向移动,当用户移出lte小区范围时,假设在(0.0)处有另一用户出现,继续移动并选择基站。
如图3和图4所示,在选择因子取值为8时,本发明与其他算法在用户接收到的吞吐量和切换次数方面的比较。仿真表明,与传统rss算法以及其他基准算法相比,本发明算法具有更高的用户吞吐量和更低的切换次数。具体为:在吞吐量方面,本发明算法基于历史的数据,会促使终端选择吞吐量较大的基站,在一段时间内,使用本发明算法的用户的总吞吐量大于使用主流rss算法的用户的总吞吐量;在切换次数方面,随着时间的推移和系统状态的变化,传统的rss算法的切换次数满足线性的增长,而本发明算法的切换次数的增加会愈发缓慢,这是由于本发明算法获得的数据越多,则基站选择越趋于稳定。
如图5和图6所示,在选择因子factor取不同值时,本发明会得到不一样的结果,具体为当选择因子变大时,用户更倾向于切换基站;当选择因子变小时,用户更倾向于继续保持当前连接。
仿真结果表明,与传统rss算法以及其他基准算法相比,本发明算法具有更高的用户吞吐量和更低的切换次数,且选择因子f的取值会对算法的性能造成影响,具体由环境和系统而定。因此本发明可以减少用户的切换次数并提升用户得到的吞吐量。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!