基于SVM分类模型的街道级地标获取方法与流程
本发明涉及街道地标获取领域,尤其涉及基于svm分类模型的街道地标获取方法。
背景技术:
高精度的ip定位在追踪网络攻击对象、定位隐蔽通信主体和减少p2p下载时间等方面具有很高的应用前景。街道级ip定位对街道级地标(ip和地理地址已知的网络实体)提出了高密度的要求。如何获取丰富的街道级地标,是街道级ip定位中极需解决的问题。当前,获取地标的主要方法有数据库查询,以及基于web的地标挖掘方法。
基于ip位置数据库查询的地标获取方法使用数据库api接口,从已有ip位置数据库中获取地标。当前,多数ip位置数据库(如baidu、ipip、ip.cn等)提供免费api接口,部分商业公司(如maxmind等)提供收费的api接口。使用数据库api接口能够在短时间内获得大量地标。但由于这些数据库提供的地标精度仅到城市级别,且数据库总的可靠性不高。因此,使用该方法难以获得大量可靠的街道级地标。
guoc等人提出的structon方法是一种基于web挖掘的地标获取方法。使用microsoftresearchasia的web搜索和挖掘小组抓取的74m个中文网页,在过滤url中包含“blog”,“bbs”,“forum”的页面后,使用正则表达式从网页中提取位置信息(地址、区域代码和邮政编码)。若从一个页面中提取出多个位置,则仅选择出现在网页中的最后一个地址;若地址、区域代码和邮政编码所属区域不一致,则根据同ip段中的其他ip的位置分别计算每个可能位置的位置权值,最大权值位置为ip的位置。该方法获在获取地标时从每个web页面中提取位置信息,需要大量的web页面源,且地标获取的时间开销大。
jiangh等人根据维基百科中高校列表获取美国大学信息,将大学主页的ip和大学位置信息关联,建立大学网站地标库;同时,利用美国38186个城市和城镇的地理位置及人口,将每个州人口最多的前60个城市和城镇的政府网站与政府位置关联,得到城市/城镇数据集。这种方法仅能获取特定行业的机构信息,所获取的街道级地标数量少。且对大量的网页进行爬取,时间开销较大。
从搜索引擎日志中提取用户搜索的地点名词,并将其与搜索时使用的ip相关联,通过ip聚合,并计算不同地点名词的权值,得到ip的城市级位置。该方法从数据分析的角度进行地标获取,能够获得大量的城市级地标,但该方法在实际使用过程中存在三个限制,一是数据集的获得需要与搜索引擎公司合作;二是从搜索引擎日志中识别提取细粒度地点名词难度较大;三是由于用户在使用搜索引擎的过程中往往不会输入细粒度的位置(如街道级位置),使用该方法很难获得大量的街道级地标。
wangy等人提出另外一种基于web的地标获取方法。该方法的主要思路是:许多公司、企业、政府部门等单位都拥有自己的web服务器,可以将这些web服务器与在线地图查询结合起来,实现web服务器与其地理位置的映射关系。该方法使用区域邮政编码,能够验证获取地标的区县级位置,但该方法仅能获取被在线地图收录的、网络发达地区的web服务器,地标挖掘的数量和范围有限。
朱光等人提出基于互联网论坛的城市级地标挖掘方法,该方法通过分析不同类型的论坛特点,给出适合作为候选地标挖掘对象的主题论坛,并基于论坛名称中的语义信息推测出论坛用户集中所处的地理位置。与从在线地图中获取地标的方法相比,挖掘的地标数量与范围都增大,但方法获取的地标为城市级地标,无法满足高精度定位对大量街道级地标的需求。
另外,还有其他一些地标获取途径,如基于目标协作方式获取地标。ip位置数据库中将ip与其所在地理位置关联起来,通过数据库查询手段,能够快速获得大量地标。这些ip位置数据库虽然在中国城市级别地区的可靠性较高,但在其他国家城市的可靠性较低,且数据库中的位置粒度仅到城市级,无法从中获得更高精度的地标数据。越来越多的移动联网设备(如智能手机、pda、平板电脑等)嵌入了gps模块,这些移动设备自定位后,将自己的经度、纬度等信息发送到控制端,实现目标设备ip到地理位置的映射。该类方法获取的地标精度高、可靠性高,但是需要目标端硬件的支持,且不易于大批量获取地标。
技术实现要素:
本发明的目的在于提供基于svm分类模型的街道地标获取方法,针对当前已有地标获取方法无法快速获取大量街道级地标的不足,从而得到街道级地标,并使用街道级地标评估方法对获得的候选地标进行评估。
为了实现上述目的,本发明采用以下技术方案:
基于svm分类模型的街道地标获取方法,包括以下步骤:
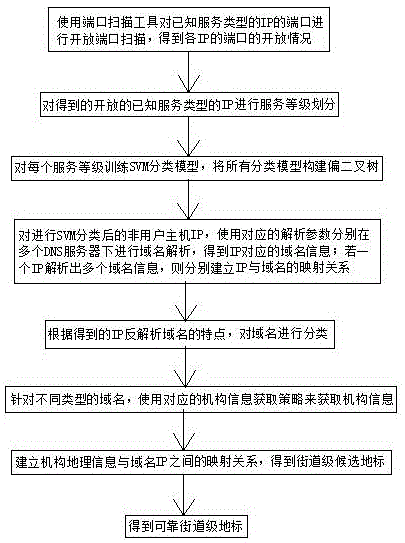
步骤1:使用端口扫描工具对已知服务类型的ip的端口进行开放端口扫描,得到各ip的端口的开放情况;
步骤2:根据步骤1得到的已知服务类型的ip的开放端口进行服务等级划分;
步骤3:根据步骤2得到的ip服务等级间的偏序关系,构建服务等级间的全序关系。同时,针对每个服务等级训练svm分类模型,依据全序关系,将所有svm分类模型构建偏二叉树;
步骤4:使用步骤3中的偏二叉树对未知服务类型的ip进行分类,对所有的非用户主机ip,分别在多个dns服务器下进行域名解析,得到ip对应的域名信息;若一个ip解析出多个域名信息,则分别建立ip与域名的映射关系;同时,基于投票策略得出未知服务类型ip所属于城市,并基于社会工程学方法构建该城市的机构信息库;
步骤5:根据步骤4中得到的域名的特点,对域名进行分类;
步骤6:对步骤5中得到的每类域名,依据其特点,利用在线地图、数据库查询、机构信息库匹配方法中的一种或多种,来获得域名对应的机构名;
步骤7:依据步骤6中得到的机构名获取地理位置信息,从而建立地理信息与域名ip之间的映射关系,得到街道级候选地标;
步骤8:对步骤7得到的街道级候选地标,使用街道级地标评估方法进行评估,从而得到可靠街道级地标。
所述步骤2包括以下步骤:
步骤2.1:依据ip的服务端口和运维端口,为ip建立服务等级间的偏序关系;具体采用以下方法:
对任意两类服务类型的ip,分别记为se(serv1)和se(serv2),对其服务端口集合sport()和运维端口集合oport(),若满足
则serv1的等级比serv2高,即:
若满足
则serv1的等级与serv2相同,即:
步骤2.2:构建偏序关系转换全序关系的规则,依据步骤2.1得到的偏序关系为ip建立所有服务等级间的全序关系;具体采用以下方法:
若两个服务等级间偏序关系的最大元相同,而最小元不同,则两个服务等级间转换全序关系时,最大元作为全序关系的最大元,任意选择两个服务等级中的其中一个偏序关系的最小元作为全序关系的最小元;若两个服务等级间偏序关系的最小元相同,而最大元不同,则两个服务等级间转换全序关系时,最小元为全序关系的最小元,任意选择两个服务等级中的其中一个偏序关系的最大元作为全序关系的最大元;若其中某类服务等级与其他服务等级均不构成偏序关系,则转换全序关系时,该类服务等级作为全序关系的最大元;
步骤2.3:依据步骤2.2得到的所有服务等级间的全序关系,对ip的各类服务类型的服务等级进行赋值,服务等级值为正整数;
所述步骤3包括以下步骤:
步骤3.1:对每个参与svm分类模型训练的服务器ip向量化,具体采用以下方法:
根据参与svm分类模型训练的服务器ip的端口扫描结果,确定向量维数m,
其中,n为服务类型的种类,port(featuree(service))=sport(se(service))∪oport(se(service))。对每个类型的服务器,依据在
步骤3.2:分类器训练:
在训练svm分类器时,训练集由两类或两类以上网络实体的端口向量组成,训练第i(1≤i≤n)个分类器时,训练集ci={vp(ek)|gradek≥i},其正样本ti={vp(ek)|gradek=i},gradek为网络实体ek的服务等级;构建用于分类的偏二叉树,偏二叉树上的第i层为训练的第i个分类器(根节点视为第1层);
步骤3.3:分类器分类:
使用分类器进行分类时,测试集为s={vp(ek)|gradek=0},从偏二叉树的根节点开始,对训练集进行分类;用vp(ek)→svmi表示使用svmi对ek进行分类,|vp(ek)→svmi|为ek在svmi中的分类结果;
当存在svmi+1时,
若|vp(ek)→svmi|=true,则gradek=i;
若|vp(ek)→svmi|=false,则vp(ek)→svmi+1;
当svmi+1不存在时,
若|vp(ek)→svmi|=true,则gradek=i;
若|vp(ek)→svmi|=false,则gradek=0。
本发明的有益效果:
本发明针对当前已有地标获取方法无法快速获取大量街道级地标的不足,提出基于svm分类模型的街道地标获取方法,利用开放端口识别该ip上所承载的服务,并对ip进行域名反解析,同时使用社会工程学手段构建特定地区的机构信息库,并基于该机构信息库,结合数据库查询和在线地图的方法得到候选街道级地标;本发明所述的基于svm分类模型的街道地标获取方法能够在更短的时间内获得更多的街道级可靠地标。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的方法流程图;
图2所示为将偏序关系转换为全序关系的策略图a;
图3所示为将偏序关系转换为全序关系的策略图b;
图4所示为将偏序关系转换为全序关系的策略图c。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示:本发明所述的基于svm分类模型的街道地标获取方法,包括以下步骤:
步骤1:使用端口扫描工具对已知服务类型的ip的端口进行开放端口扫描,得到各ip的端口的开放情况;
步骤2:根据步骤1得到的已知服务类型的ip的开放端口进行服务等级划分,主要采用以下方法:
步骤2.1:依据ip的服务端口和运维端口,为ip建立服务等级间的偏序关系;具体采用以下方法:
对任意两类服务类型(如serv1、serv2)的ip,分别记为se(serv1)和se(serv2),对其服务端口集合sport()(根据rfc6335中的服务类型与端口号之间的关系得到的集合)和运维端口集合oport()(se()集合的所有网络实体中,超过20%的网络实体开放的除sport()外的其他端口的集合),若满足
则serv1的等级比serv2高,即:
若满足
则serv1的等级与serv2相同,即:
其中,网络实体e={ip,lng,lat,grade},进一步的,0<gradei=gradejip,lng,lat,grade分别表示网络实体e的ip、经度、纬度以及服务等级值;若网络实体e上开放多项服务,则服务等级值取最高服务的服务等级值;若网络实体上开放的服务未知,则该网络实体的服务等级值为0;
port(ei)为开放端口集合,即网络实体ei开放的所有端口的集合;
se(service)为所有开放service类型服务的网络实体e所构成的集合,
eport(se(service))为同服务实体开放端口集合,即所有开放service服务的网络实体e所开放的所有端口的集合;其中:
sport(se(service))为服务端口集合,即从iana指定的系统端口中,根据常见服务的端口号列表得到的端口集合;
oport(se(service))为运维端口集合,即se(service)中不少于20%的网络实体开放的运维端口的集合;其中:
其中fun(x)为判断函数,当x为真时,fun(x)=1;反之,fun(x)=0;
featuree(service)为特征网络实体集合,即最能代表开放service服务的网络实体e的特征的网络实体集合;该网络实体是构造的,不一定在se(service)中出现,其开放端口port(featuree(service))=sport(se(service))∪oport(se(service));
步骤2.2:构建偏序关系转换全序关系的规则,依据步骤2.1得到的偏序关系为ip建立所有服务等级间的全序关系;具体采用以下方法:
如图2、图3和图4所示为将偏序关系转换为全序关系的策略图;偏序关系转换全序关系的规则为:若两个服务等级间偏序关系的最大元相同,而最小元不同,则两个服务等级间转换全序关系时,最大元作为全序关系的最大元,任意选择两个服务等级中的其中一个偏序关系的最小元作为全序关系的最小元;若两个服务等级间偏序关系的最小元相同,而最大元不同,则两个服务等级间转换全序关系时,最小元为全序关系的最小元,任意选择两个服务等级中的其中一个偏序关系的最大元作为全序关系的最大元;若其中某类服务等级与其他服务等级均不构成偏序关系,则转换全序关系时,该类服务等级作为全序关系的最大元;
步骤2.3:依据步骤2.2得到的所有服务等级间的全序关系,对ip的各类服务类型的服务等级进行赋值,服务等级值为正整数;具体采用以下方法:
服务等级取值为1,2,…,n,全序关系中最大元的服务等级值为1,最小元的服务等级值为n,主机类型网络实体的服务等级为n+1;
其中,服务等级值越大,该服务类型对应ip的服务等级越低。
使用等级划分依据两类服务的sport()和oport()间的关系,等级划分后,能够避免由于高等级服务的oport()与低等级服务的sport()有交集,而对分类带来的准确率降低的影响。
步骤3:根据步骤2.1得到的ip服务等级间的偏序关系,对每个服务等级训练svm分类模型,将所有分类模型构建偏二叉树;具体采用以下方法:
步骤3.1:对每个参与svm分类模型训练的服务器ip向量化,具体采用以下方法:
根据参与svm分类模型训练的服务器ip的端口扫描结果,确定向量维数m,
其中,n为服务类型的种类,port(featuree(service))=sport(se(service))∪oport(se(service))。对每个类型的服务器,依据在
步骤3.2:分类器训练:
在训练svm分类器时,训练集由两类或两类以上网络实体的端口向量组成,训练第i(1≤i≤n)个分类器时,训练集ci={vp(ek)|gradek≥i},其正样本ti={vp(ek)|gradek=i},gradek为网络实体ek的服务等级;构建用于分类的偏二叉树,偏二叉树上的第i层为训练的第i个分类器(根节点视为第1层);
步骤3.3:分类器分类:
使用分类器进行分类时,测试集为s={vp(ek)|gradek=0},从偏二叉树的根节点开始,对训练集进行分类;用vp(ek)→svmi表示使用svmi对ek进行分类,|vp(ek)→svmi|为ek在svmi中的分类结果;
当存在svmi+1时,
若|vp(ek)→svmi|=true,则gradek=i;
若|vp(ek)→svmi|=false,则vp(ek)→svmi+1;
当svmi+1不存在时,
若|vp(ek)→svmi|=true,则gradek=i;
若|vp(ek)→svmi|=false,则gradek=0;
步骤4:ip反解析域名,具体采用以下方法:
使用步骤3中的偏二叉树对未知服务类型的ip进行分类,对所有的非用户主机ip,分别在多个dns服务器下进行域名解析,得到ip对应的域名信息;若一个ip解析出多个域名信息,则分别建立ip与域名的映射关系;同时,基于投票策略得出未知服务类型ip所属于城市,并基于社会工程学方法构建该城市的机构信息库;
步骤5:根据步骤4得到的ip反解析域名的特点,对域名进行分类,具体采用以下方法:
icann定义了代表各个国家的顶级域名(国家的顶级域名通常由两个英文字母组成),同时还定义了.top、.com、.edu、.gov、.org等顶级类别域名;顶级域名之下的二级域名,通常也是按类别进行分类的,如教育科研类二级域名.edu、.ca、.com等;为快速获得域名中的机构信息字段,需要对域名进行分类处理;
本文将域名主要分为三类,类别1为.top、.com、.edu、.gov、.org等顶级域名;类别2为.com、.edu、.ca、.gov、.org等二级域名;类别3为其他域名;
根据icann的定义,.top表示商业机构(个人也可注册),.com表示商业机构,.edu表示教育机构,.gov表示政府机构,.org表示非营利性组织;国家域名下,表示类别的二级域名通常通常含义与icann中的含义相同,即国家域名下的.com域名表示商业机构、.edu表示教育机构(一些国家也用.ca表示科研教育机构)、.org表示非营利性组织、.gov表示政府部门。这些域名下的子域名通常机构信息(如哈佛大学的域名为harvard.edu),能够从机构信息中进行机构名推断。
通过域名分类,将大概率包含机构信息的域名分成一类,在使用社会工程学策略进行机构信息推断时,能够提高推断效率。
步骤6:针对不同类型的域名,使用对应的机构信息获取策略来获取机构信息,具体采用以下方法:
机构信息获取策略主要有数据库查询、在线地图以及社会工程学三种策略;数据库查询指通过域名备案网站(如中国工信部的域名备案系统),查询域名对应的机构信息;在线地图方式则是使用在线地图服务查询域名,得到域名所对应的机构信息;社会工程学策略则是根据域名中的信息字段对机构信息进行推断;下面详细对社会工程学策略进行介绍。
社会工程学策略主要分为构建机构信息库和机构名匹配两个步骤:
一、构建机构信息库:从当前公开的数据集中获取特定地区的poi数据,并从poi数据中分析选择出可能具有服务器的机构名及类别,并在此基础上进行数据规模的扩充;由于当前域名主要由字母组成,因此,将机构名转换为字母组合表示,一个域名可能转换得到多个字母组合,如机构名“武汉大学”,其类别为“大学”,则转换得到的字母组合为“wuhandaxue”、“whdx”、”wuda”、”wuhanuniversity”、“whu”;将机构名与其字母组合相关联,构建机构信息库。
二、机构名匹配:提取域名中类别域名下的子域名字段,该字段通常为字母组合字段,对非英语国家中的ip所对应的域名,利用该字段从构建的机构信息库中匹配机构名;对英语国家中的ip所对应的域名,直接将该字段作为机构名;将域名对应的ip关联匹配到的机构名,得到地标,若匹配到多个机构名,则构建多个地标。
步骤7:建立机构地理信息与域名ip之间的映射关系,得到街道级候选地标;
步骤8:对步骤7得到的街道级候选地标,使用街道级地标评估方法进行评估,从而得到可靠街道级地标。
为了便于本领域技术人员进一步理解本发明的技术方案,下面将以具体实施例对本发明所述的技术方案做进一步说明:
步骤1:根据[iana(2018)],dns、email和web服务的服务端口如下表1所示。并分别对380个dns服务器(280个用于训练,100上用于测试)、1100个email服务器(1000个用于训练,100上用于测试)、1000个web服务器ip(900个用于训练,100上用于测试)和1200个主机ip(1200个用于训练),使用nmap探测工具对0到49151端口的开放情况进行探测。
表1为dns服务、email服务、和web服务的服务端口;
步骤2:对步骤1得到的dns服务器、email服务器、web服务器ip和主机ip的端口开放情况进行服务等级划分,主要采用以下方法:
步骤2.1:依据步骤1统计的dns服务器、email服务器、web服务器ip和主机ip的端口开放情况得到运维端口oport(),为dns服务器、email服务器、web服务器ip和主机ip建立服务等级间的偏序关系;,构建的服务等级间偏序关系为web<dns、web<email;
步骤2.2:依据步骤2.1得到的偏序关系为ip建立所有服务等级间的全序关系;最终得到全序关系为web<email<dns;
步骤2.3:依据步骤2.2得到的所有服务等级间的全序关系,对ip的各类服务类型的服务等级进行赋值,服务等级值为正整数;
步骤3:根据步骤2.1得到的ip服务等级间的偏序关系,对每个服务等级训练svm分类模型,将所有分类模型构建偏二叉树;具体采用以下方法:
步骤3.1:对每个参与svm分类模型训练的服务器ip向量化,具体采用以下方法:
根据featuree(dns)、featuree(email)、featuree(web)和featuree(host)(认为
步骤3.2:分类器训练:
当核函数分别为linear、rbf和sigmoid时,分别取惩罚因子c为2.0、1.0、0.5、0.2进行dns服务器、email服务器、web服务器的svm分类器训练(分别命名为svm11、svm12、svm13);其中,训练svm11时,训练集c1={vp(ea)|ea∈se(dns)}∪{vp(eb)|eb∈se(email)}∪{vp(ec)|ec∈se(web)}∪{vp(ed)|ed∈se(hosts)},
其中1≤a,b,c,d≤200,正样本t1={vp(ek)|ek∈se(dns),1≤k≤200};训练svm12时,训练集c2={vp(ea)|ea∈se(email)}∪{vp(eb)|eb∈se(web)}∪{vp(ec)|ec∈se(hosts)},其中1≤a,b,c≤200,正样本t2={vp(ek)|ek∈se(email),1≤k≤200};训练svm13时,训练集c3={vp(ea)|ea∈se(web)}∪{vp(eb)|eb∈se(hosts)},其中1≤a,b≤200,正样本t3={vp(ek)|ek∈se(web),1≤k≤200};使用训练得到的模型分别对另外100个已知类型的服务器进行分类,统计真正例(truepositive,tp)、假正例(falsepositive,fp)、真负例(truenegative,tn)、假负例(falsenegative,fn)的值,并根据
计算不同核函数和惩罚因子下模型的准确率和召回率从准确率和召回率来看,核函数linear对dns、email和web服务器分类比其他核函数好;同时,在核函数为linear时,惩罚因子c对准确率和召回率影响较小;依次依据
本文中训练svm分类模型的核函数为linear,惩罚因子c=0.2;
选择380个dns服务器、1100个email服务器、1000个web服务器ip和1200个主机ip的端口探测结果,根据featuree(dns)、featuree(email)、featuree(web)和featuree(host)的交集,得到训练和分类的向量维度m=317,并将端口扫描结果进行向量化处理,训练得到dns服务器分类器svm21、email服务器分类器svm22、web服务器分类器svm23;根据全序关系web<email<dns,构建偏二叉树,根节点为svm21,叶子节点为svm23。
步骤3.3:分类器分类:
使用步骤3.2构建的偏二叉树分类器对ip进行分类;
步骤4:基于投票策略从baidu、ipip、ip.cn三个位置数据库中选择出广州和武汉的ip,ip数量分别为7028366和4772821,其中在线ip数量分别为3341747和2000357,使用nslookup工具基于不同参数反查ip所对应的域名信息;
步骤5:使用域名分类策略将域名进行分类处理;
步骤6:从公开数据库中获取广州和武汉地区的poi数据库,从中分析选择出可能具有服务器的机构名及类别,并结合在线地图和实地采集数据构建广州和武汉地区的机构信息库。
对所有域名依次使用数据库查询和在线地图方式尝试获取机构信息,对无法获取机构信息的第一类和第二类域名,提取类别域名后的子域名字段,在机构信息库中匹配机构信息;如下表2所示:
表2为各阶段保留的ip\地表数量;
从表2中可以看出,数据库中的ip段,其中有超过一半的ip处于不经常在线的状态。经过分类器分类后,ip数量出现了大幅度的减少,这是由于排除了主机ip和路由器ip;
步骤7:建立机构地理信息与域名ip之间的映射关系,得到地标;
步骤8:对步骤7得到的街道级候选地标,使用街道级地标评估方法进行评估,从而得到可靠街道级地标。
本发明针对当前已有地标获取方法无法快速获取大量街道级地标的不足,提出基于svm分类模型的街道地标获取方法,利用开放端口识别该ip上所承载的服务,并对ip进行域名反解析,同时使用社会工程学手段构建特定地区的机构信息库,并基于该机构信息库,结合数据库查询和在线地图的方法得到候选街道级地标,最后使用街道级地标评估方法对候选街道级地标进行评估;本发明所述的基于svm分类模型的街道地标获取方法能够在更短的时间内获得更多的街道级可靠地标。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!