面向医联体的多用户大数据分析服务系统和方法与流程
本发明涉及大数据分析领域,具体地,涉及一种面向医联体的多用户大数据分析服务系统和方法。
背景技术:
大数据分析是指对规模巨大的数据进行分析。大数据可以概括为4个v,数据量大(volume)、速度快(velocity)、类型多(variety)、价值(value)。大数据作为时下最火热的it行业的词汇,随之而来的数据仓库、数据安全、数据分析、数据挖掘等等围绕大数据的商业价值的利用逐渐成为行业人士争相追捧的利润焦点。随着大数据时代的来临,大数据分析也应运而生。如何实现大数据分析服务集群的自动化、自服务化管理而无需关心底层资源申请、软件安装和配置等操作,满足用户,特别是多用户环境下对大数据集群的需求,已经成为使用大数据技术进行大数据分析亟待破解的难题。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种面向医联体的多用户大数据分析服务系统和方法。
根据本发明提供的一种面向医联体的多用户大数据分析服务系统,包括:
集群服务创建模块:接收来自控制台的由使用者以自助服务方式选择创建的大数据集群,接收使用者设置大数据集群规模后,由后台自动化部署配置大数据集群,完成大数据集群创建;
集群服务使用模块:通过控制台根据使用者的查看指令,提供大数据集群的访问信息,提供通过ssh客户端或vnc客户端访问大数据集群,使用大数据集群。
优选地,所述的面向医联体的多用户大数据分析服务系统,还包括集群服务删除模块:接收来自控制台的由使用者以自助服务方式选择删除的大数据集群,由后台自动化删除大数据集群。
优选地,所述大数据集群是构建在云上的大数据服务。
优选地,所述大数据集群的使用服务构建在x86和ibmpower服务器集群之上,采用定制化jvm。
优选地,所述大数据集群创建采用openstackheat进行集群创建。
优选地,所述分析任务的分析结果保存在hdfs、hive或集群文件系统中。
优选地,部署管理节点虚拟机和大数据集群,所述管理节点虚拟机包括nginx、大数据平台服务、heat管理、文件同步服务、对象存储,nginx实现对外接口映射,大数据平台服务处理web请求,大数据平台服务与文件同步服务、heat管理进行交互,文件同步服务完成对象存储和hdfs的同步。
优选地,所述使用大数据集群中,用户通过上传数据或程序提交分析任务,通过scp下载分析任务的分析结果。
优选地,所述使用大数据集群中,用户能够查看大数据集群的运行状态;
在创建大数据集群中,用户能够查看大数据集群的创建进度。
根据本发明提供的一种面向医联体的多用户大数据分析服务方法,包括:
集群服务创建步骤:接收来自控制台的由使用者以自助服务方式选择创建的大数据集群,接收使用者设置大数据集群规模后,由后台自动化部署配置大数据集群,完成大数据集群创建;
集群服务使用步骤:通过控制台根据使用者的查看指令,提供大数据集群的访问信息,提供通过ssh客户端或vnc客户端访问大数据集群,使用大数据集群;
集群服务删除步骤:接收来自控制台的由使用者以自助服务方式选择删除的大数据集群,由后台自动化删除大数据集群。
与现有技术相比,本发明具有如下的有益效果:
1、本发明的大数据服务构建在x86和ibmpower服务器集群之上,具有极其出色的计算能力,为了更好地适用于大数据业务,大数据服务采用了为power定制化的jvm,对于开发大数据业务的用户来说,底层集群应用了power还是x86对于编程没有任何影响,都可以用同样的代码运行。
2、本发明的大数据服务是一种构建在云上的大数据服务,能够处理任何数量的数据,按需将数据处理容量从数tb扩展至数pb级别。在大数据集群服务中,用户可以随时快速创建任意数量的节点。
3、本发明具有强大的编程扩展能力,支持java,python,scala等多种语言,还将支持r语言,用户可以使用自己习惯的编程语言进行hadoop/spark作业的编写、创建、配置、提交和监控。
4、本发明具有低廉的部署和维护方式,用户将无需花费大量时间进行部署安装配置,无需其它前期成本,大数据服务可以为用户自动完成这些工作,用户可在几分钟内启动一个集群。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为大数据集群创建服务流程图;
图2为大数据集群删除服务流程图;
图3为大数据分析服务子系统部署架构图;
图4为大数据集群化服务流图;
图5为大数据分析服务子系统数据库设计图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
根据本发明提供的一种面向医联体的多用户大数据分析服务系统,包括:
集群服务创建模块:接收来自控制台的由使用者以自助服务方式选择创建的大数据集群,接收使用者设置大数据集群规模后,由后台自动化部署配置大数据集群,完成大数据集群创建;
集群服务使用模块:通过控制台根据使用者的查看指令,提供大数据集群的访问信息,提供通过ssh客户端或vnc客户端访问大数据集群,使用大数据集群。
具体地,所述的面向医联体的多用户大数据分析服务系统,还包括集群服务删除模块:接收来自控制台的由使用者以自助服务方式选择删除的大数据集群,由后台自动化删除大数据集群。
其中,大数据集群创建、使用大数据集群、删除大数据集群分别以服务的形式存在,分别对应大数据集群创建服务、大数据集群使用服务、大数据集群删除服务,且大数据集群创建服务必须优先于大数据集群使用服务和大数据集群删除服务。
所述大数据集群创建服务由用户以自服务的方式,在控制台选择创建大数据集群并确认集群规模(节点数量)后,由大数据集群创建服务后台自动化部署和配置大数据集群。用户可以通过控制台查看大数据集群创建进度,创建完成后即可登录使用。
所述大数据集群使用服务是在大数据集群创建完成后,用户可以通过控制台查看集群的访问信息(最重要的信息是集群master节点的ip地址)。之后,用户可以通过ssh或vnc方式直接访问master节点,通过上传分析数据、程序,向spark提交分析任务;分析完成后可以通过使用scp下载分析结果。在这个过程中,用户还可以通过控制台,点击集群中的spark监控和hadoop监控,对集群状态进行实时查看。
所述大数据集群删除服务也采用用户自服务的方式,由用户在控制台选择要删除大数据集群并确认,系统会在后台自动化的完成集群删除工作。集群一旦删除,无法恢复,在删除前用户需要手工完成数据备份。
具体地,所述大数据集群是构建在云上的大数据服务。能够处理任何数量的数据,按需将数据处理容量从数tb扩展至数pb级别。在大数据集群服务中,用户可以随时快速创建任意数量的节点。
具体地,所述大数据集群的使用服务构建在x86和ibmpower服务器集群之上,计算能力强,采用定制化jvm。对于开发大数据业务的用户来说,底层集群应用了power还是x86对于编程没有任何影响,都可以用同样的代码运行。所述大数据集群使用服务具有强大的编程扩展能力,支持java,python,scala等多种语言,还将支持r语言。用户可以使用自己习惯的编程语言进行hadoop/spark作业的编写、创建、配置、提交和监控。
具体地,所述大数据集群创建采用openstackheat进行集群创建。
具体地,所述分析任务的分析结果保存在hdfs、hive或集群文件系统中。
具体地,部署管理节点虚拟机和大数据集群,所述管理节点虚拟机包括nginx、大数据平台服务、heat管理、文件同步服务、对象存储,nginx实现对外接口映射,大数据平台服务处理web请求,大数据平台服务与文件同步服务、heat管理进行交互,文件同步服务完成对象存储和hdfs的同步。
具体地,所述使用大数据集群中,用户通过上传数据或程序提交分析任务,通过scp下载分析任务的分析结果。
具体地,所述使用大数据集群中,用户能够查看大数据集群的运行状态;在创建大数据集群中,用户能够查看大数据集群的创建进度。
根据本发明提供的一种面向医联体的多用户大数据分析服务方法,包括:
集群服务创建步骤:通过控制台根据使用者的查看指令,提供大数据集群的访问信息,提供设置大数据集群规模后,由后台自动化部署配置大数据集群,完成大数据集群创建;
集群服务使用步骤:通过控制台根据使用者的查看指令,提供大数据集群的访问信息,提供通过ssh客户端或vnc客户端访问大数据集群,使用大数据集群;
集群服务删除步骤:接收来自控制台的由使用者以自助服务方式选择删除的大数据集群,由后台自动化删除大数据集群。
本发明提供的面向医联体的多用户大数据分析服务系统,可以通过面向医联体的多用户大数据分析服务方法的步骤流程实现。本领域技术人员可以将面向医联体的多用户大数据分析服务方法理解为所述面向医联体的多用户大数据分析服务系统的优选例。
以下结合附图对本发明的优选例作进一步阐述。
如图1所示,在一个实施例中,当用户需要使用大数据集群时,通过控制台创建集群,用户在控制台上选择创建大数据集群。在弹出页面中选择希望创建集群的节点数。后台系统根据用户选择的节点数,通过是用openstackheat完成集群的创建。在创建过程中,用户可以通过控制台看到集群的状态。当集群创建完成后,集群即进入可用状态,用户可以通过ssh客户端登录到集群的主节点(sparkmaster),使用集群;或通过web控制台对hadoop集群和spark集群进行监控。
在一个实施例中,用户通过scp向集群上传待分析数据,并根据需要,导入hdfs或hive中。通过scp上传spark程序,在程序中,可以读取hdfs或hive中的数据;通过sparksubmit提交程序任务,进行分析运算;分析结果可以保持在hdfs、hive或集群的文件系统中。将hive或hdfs中的文件导出到本地文件系统;将集群文件系统中的数据通过scp下载到客户端。
如图2所示,在一个实施例中,用户登录集群或通过scp下载集群中需要保留的数据。由于集群删除为不可恢复操作,且不保留任何数据。因此,在用户删除集群之前,需要手工下载需要保留的数据。用户通过控制台点击删除集群。后台系统通过heat完成集群删除的操作。
如图3所示,在一个实施例中,主要包括部署在管理控制节点(x86-01~x86-03)上的管理节点虚拟机以及运行在docker计算节点上、有管理节点动态管理生命周期的大数据集群组成。大数据分析服务管理节点虚拟机中包含了nginx,大数据平台服务,heat管理,文件同步和对象存储等组件,nginx负责对外的接口映射,大数据平台服务器负责处理web请求,并且与文件同步服务和heat管理服务相连,当用户进行大数据服务创建时,大数据平台处理服务器会根据用户输入调用对应的heat模板,完成大数据创建任务。同时,如果用户要对文件操作,可以调用web中的文件管理,大数据平台服务器会处理这个请求,调用文件同步服务,完成对象存储和hdfs之间的同步。值得注意的是,可以采用多个大数据平台服务器进行高可靠的保证。
如图4所示,大数据集群根据用户请求动态创建,即当用户在控制台中申请新的大数据集群时,由管理节点发出集群创建指令,完成集群创建。首先,用户的创建信息会通过大数据分析子系统控制台(dashboard)传给heat模块(openstack中的编排服务),更新heat模板中的相关配置;heat通过glance(openstack中的镜像服务)取得包含大数据服务节点的软件包和相关环境配置的docker镜像,并通过nova(openstack中的计算服务)创建相应的容器实例;最后在docker中启动每个大数据的节点(namenode,datanode,master,worker,driver,executor),完成搭建用户所需的大数据集群环境。
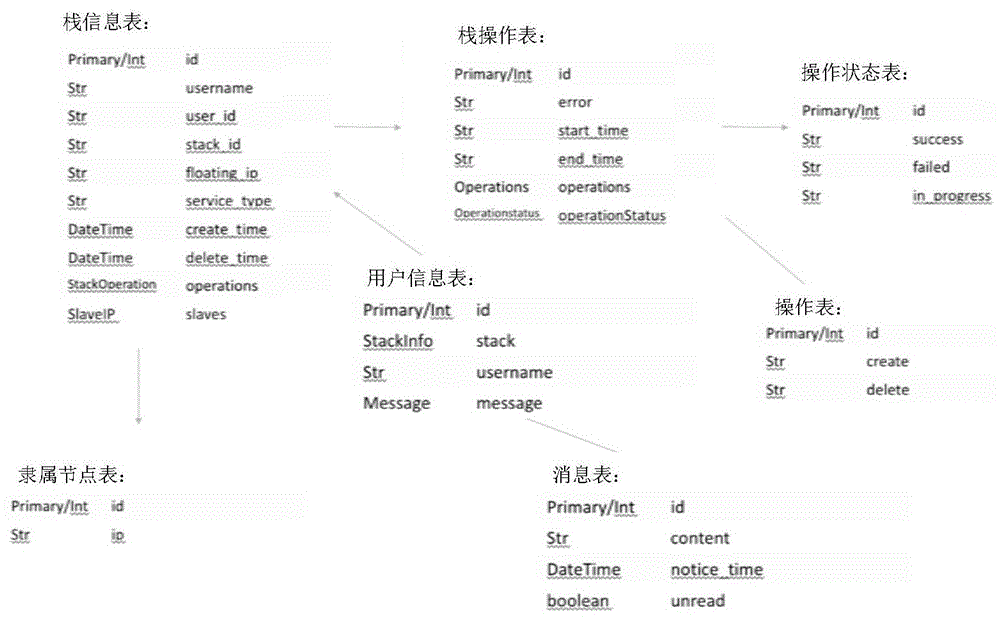
如图5所示,在大数据服务数据库的设计中,本实施例采用了7张表,其中包括,栈信息表,用户信息表,操作表,栈操作表,操作状态表,隶属节点表和消息表。所述用户信息表用于存储用户名称和消息信息。消息信息是一些通知信息,帮助用户了解大数据集群的更多信息。所述栈信息表用于存储用户的heat操作栈信息。所述栈操作表用于存储用户对大数据集群的所有操作行为,包括操作的开始和结束时间,操作内容,成功与否,错误消息。所述隶属节点表存储大数据slave节点的ip地址信息。所述操作状态表用于存储大数据服务操作状态。所述消息表用于存储消息信息,包括消息内容,通知时间和用户是否阅读的状态。
本发明使用openstack的容器服务(novadocker)作为运行支撑环境,即为用户创建的集群运行在openstack的docker计算节点中。利用了openstack的资源管理能力,无需在大数据分析服务子系统中另外实现物理资源管理功能;可与其它服务共享物理资源,提高资源利用率、减少物理资源浪费。在系统高可用方面,本发明提供的大数据集群本身为集群架构,且均为spark集群。spark集群中,如worker节点发生故障,整个集群仍处于可用状态,仅会因可用资源减少(节点数减少)而导致性能下降,如master节点发生故障,将会导致整个集群的不可用。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
- 还没有人留言评论。精彩留言会获得点赞!