一种VANET中基于边缘计算的深度学习任务分配算法的制作方法
本发明涉及一种vanet中基于边缘计算的深度学习任务分配算法,属于车联网技术领域与通信领域。
背景技术:
随着车联网理论知识的完善,车与车之间,车与基站之间,车与行人之间将具备信息传输的能力,这就使得车联网内的所有通信单元能够共享它们的运动信息,而随着大数据时代下数据挖掘技术的发展,只要有了大量已知的数据集,并通过机器学习算法进行学习,计算机就能对未知的数据进行预测和分析。因此,通过车联网技术和机器学习技术可以有效地对即将发生的交通事故进行预测和分析,在预测到车辆很可能发生交通事故时,使车辆能够及时调整自身的行车状态,来避免交通事故的发生。
目前车联网中的边缘计算环境中采用的任务分配算法在对深度学习任务进行分配时产生的时延过高,且通常情况下,边缘服务器主要用来处理较低层的数据,而云服务器主要处理较高层的数据,然而,如何对深度神经网络的层数进行划分并没有统一的标准。将更多层部署到边缘服务器可以减少更多网络流量,但是,与云服务器相比,边缘服务器的服务器容量有限,在边缘服务器中处理无限任务是不可能的,同时深度学习网络中的每一层都会给服务器带来额外的计算开销,部署在边缘服务器中的神经网络层越多,计算开销就越大,边缘服务器所需处理的计算开销很可能超出自身的计算能力。反之,若部署在边缘服务器中的神经网络层越少,边缘服务器的计算就越小,但是上传到云端的数据就越多,所占用的带宽也就越多,延时也就越大。
技术实现要素:
本发明的主要目的在于解决在目前神经网络层没有统一划分标准的情况下,边缘计算环境中采用的任务分配算法在对深度学习任务进行分配时产生的时延过高,效率低下的问题,提出一种vanet中基于边缘计算的深度学习任务分配算法,具体技术方案如下:
一种vanet中基于边缘计算的深度学习任务分配算法,所述分配算法包括离线分配算法和在线分配算法,其特征在于:
所述离线分配算法主要针对事先已知一段时间内到来的深度学习任务序列的情况,所述在线分配算法主要针对事先不知道需要处理的深度学习任务序列的情况;
所述离线分配算法的流程如下所示:
步骤1,对于每个深度学习任务,遍历其所有的k,求得使lkj·rkj最大的k,rkj为第k层的神经网络的输入数据大小与初始输入数据的大小之比,lkj为在边缘服务器处理k层神经网络后产生的计算开销;
步骤2,遍历所有的边缘服务器,找到当前情况下边缘服务器的剩余服务能力和剩余带宽乘积最大的边缘服务器;
步骤3,将所有的深度学习任务先按照深度学习任务的输入数据大小进行升序排序;
步骤4,对排序后的每个深度学习任务,首先对序号为1的深度学习任务进行判断,若剩余服务能力和剩余带宽乘积最大的边缘服务器能够满足所提的约束条件,则在该边缘服务器上运行该任务,若该边缘服务器不满足约束条件,则改变k的值直到满足约束条件为止,若改变k后仍然不能满足条件,则不执行该任务;
步骤5,若序号为1的深度学习任务已经分配完成,则重新计算并找到当前情况下边缘服务器的剩余服务能力和剩余带宽乘积最大的边缘服务器,并按照排好的顺序对余下的深度学习任务进行分配,若某一个深度学习任务在遍历所有k后仍然不能分配到边缘服务器中,则说明当前所有的边缘服务器均已饱和,将该深度学习任务及其之后的所有深度学习任务暂缓,并在之前的任务处理完成后重复上述流程进行判断;
所述在线分配算法的流程如下所示:
步骤1,令bmax和bmin为任务tj在经过改变k层神经网络后所需的最大和最小带宽,对于任务tj,首先找出目前所有边缘服务器中具有最大剩余服务能力的服务器
步骤2,对该服务器的最大剩余服务能力进行判断,若满足处理条件,则认为该边缘服务器能够接受并立刻处理到来的深度学习任务;
步骤3,若该服务器的最大剩余服务能力不满足处理条件,则需要暂缓对该深度学习任务的处理,直至边缘服务器有足够的剩余服务能力进行处理。
进一步地,所述在线分配算法的步骤1中,服务器的剩余服务能力由函数
其中,
进一步地,所述在线分配算法的步骤2中,具体地,所述处理条件为:
若满足该条件,则认为该边缘服务器能够接受并立刻处理到来的深度学习任务,若不满足,则需要暂缓对该深度学习任务的处理,直至边缘服务器有足够的剩余服务能力进行处理。
与现有技术相比,本发明的有益效果是:本发明提出的深度学习任务分配算法最大化边缘服务器中运行的深度学习任务的数量,不仅减少了从车联网终端设备传输到云服务器的网络流量,也减少了因为信息的传输带来的传输时延。
附图说明
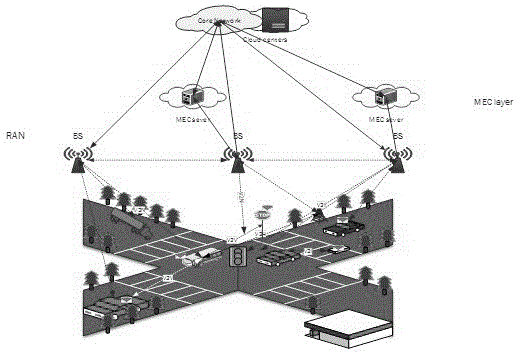
图1为vanet边缘深度学习框架。
图2为vanet边缘深度学习模型。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
一种vanet中基于边缘计算的深度学习任务分配算法,所述分配算法包括离线分配算法和在线分配算法。
参照图1,在深度神经网络的训练和部署方面,首先需要在云服务器中完成深度神经网络的训练。在训练完成之后,我们将深度神经网络分为两部分。第一部分为离输入数据较近的隐含层和输入层,第二部分为离输出数据较近的隐含层和输出层。本方案将第一部分安排在边缘服务器中,将第二部分部署到云服务器中进行处理。因此,边缘服务器主要用来处理较低层的数据,而云服务器主要处理较高层的数据。
然而,如何对深度神经网络的层数进行划分并没有统一的标准。通常,由较高层产生的中间数据的大小小于由较低层产生的中间数据的大小。将更多层部署到边缘服务器可以减少更多网络流量。但是,与云服务器相比,边缘服务器的服务器容量有限,在边缘服务器中处理无限任务是不可能的。深度学习网络中的每一层都会给服务器带来额外的计算开销,因此只能将部分深度学习网络部署到边缘服务器中。同时,由于不同的深度学习网络和任务具有不同大小的中间数据和计算开销,因此需要一种有效的分配算法分配深度学习网络在边缘服务器中运行的层数。
一种vanet中基于边缘计算的深度学习任务分配算法,所述分配算法包括离线分配算法和在线分配算法。所述离线分配算法主要针对事先已知一段时间内到来的深度学习任务序列的情况,所述在线分配算法主要针对事先不知道需要处理的深度学习任务序列的情况。其中,深度学习任务的具体分配方式如图2所示,深度神经网络的前面几层隐含层的处理将安排在边缘服务器中,而之后的隐藏层和输出层的处理将安排在云服务器中。因此,边缘服务器主要用来处理较低层的数据,而云服务器主要处理较高层的数据。
所述离线分配算法的流程如下所示:
步骤1,对于每个深度学习任务,遍历其所有的k,求得使lkj·rkj最大的k,rkj为第k层的神经网络的输入数据大小与初始输入数据的大小之比,lkj为在边缘服务器处理k层神经网络后产生的计算开销。
步骤2,遍历所有的边缘服务器,找到当前情况下边缘服务器的剩余服务能力和剩余带宽乘积最大的边缘服务器。服务器的剩余服务能力由函数
其中,
步骤3,将所有的深度学习任务先按照深度学习任务的输入数据大小进行升序排序。
步骤4,对排序后的每个深度学习任务,首先对序号为1的深度学习任务进行判断,若剩余服务能力和剩余带宽乘积最大的边缘服务器能够满足所提的约束条件,则在该边缘服务器上运行该任务,若该边缘服务器不满足约束条件,则改变k的值直到满足约束条件为止,若改变k后仍然不能满足条件,则不执行该任务。
步骤5,若序号为1的深度学习任务已经分配完成,则重新计算并找到当前情况下边缘服务器的剩余服务能力和剩余带宽乘积最大的边缘服务器,并按照排好的顺序对余下的深度学习任务进行分配,若某一个深度学习任务在遍历所有k后仍然不能分配到边缘服务器中,则说明当前所有的边缘服务器均已饱和,将该深度学习任务及其之后的所有深度学习任务暂缓,并在之前的任务处理完成后重复上述流程进行判断。
所述在线分配算法的流程如下所示:
步骤1,令bmax和bmin为任务tj在经过改变k层神经网络后所需的最大和最小带宽,对于任务tj,首先找出目前所有边缘服务器中具有最大剩余服务能力的服务器
步骤2,对该服务器的最大剩余服务能力进行判断,若满足处理条件,则认为该边缘服务器能够接受并立刻处理到来的深度学习任务。
步骤3,若该服务器的最大剩余服务能力不满足处理条件,则需要暂缓对该深度学习任务的处理,直至边缘服务器有足够的剩余服务能力进行处理。
所述在线分配算法的步骤2中,具体地,所述处理条件为:
若满足该条件,则认为该边缘服务器能够接受并立刻处理到来的深度学习任务,若不满足,则需要暂缓对该深度学习任务的处理,直至边缘服务器有足够的剩余服务能力进行处理。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!