一种属性撤销方法与流程
本发明属于数据安全技术领域,具体涉及一种属性撤销方法。
背景技术:
属性撤销问题一直是属性加密机制中一个备受关注的研究点。当撤销用户或用户的属性时,需要保证该用户不再拥有该属性对应的权限,而其余用户的权限不受影响。
近年来,国内外的学者们提出了各种属性消减方案。attrapadung等人结合基于属性加密方案和多播加密技术,提出当前的属性撤销方案可以分为两类:直接撤销模式和间接撤销模式。
在直接撤销模式中,撤销列表由发送者嵌入到密文中,直接实现属性密钥的撤销。ostrovsky首先提出基于密文的属性加密的直接撤销思想,方案将用户标识作为属性,每当用户撤销时,将和密文相关联的用户标识写为”非”,从而实现了用户的撤销,但是这种方案导致密文和用户密钥长度过大。王鹏翩等针对属性的细粒度撤销,基于合数阶双线性群实现了属性的直接撤销,但该方案公钥参数与用户数量线性相关,容易造成公钥参数过长。lewko方案将已撤销权限的用户列表由发送者嵌入在密文中,当用户请求数据时,如果用户已在撤销列表中,那么将无法得到数据。而方案以lewko的方案为基础,提出了一种在密文和密钥长度方面都有所减少的属性直接撤销方案。综合起来,直接撤销模式的优势是所有未撤销用户无需更新密钥,减轻了授权机构的负担。缺点是撤销列表和用户密文相连,每当有新的用户被加入撤销列表,需要将用户更新到密文中,这会引入比较大的重复存储开销和计算开销。
在间接撤销模式研究早期,由授权机构周期性释放密钥的更新,只有权限未撤销的用户才可以更新密钥。hur提出一种kektree的方法,拥有某个属性的用户群被记录下来,拥有同一个属性的群体共享一个属性私钥。当由用户权限被取消时,生成新的属性私钥,并为所有依旧拥有权限的用户更新密钥。xie等对hur的方案进行了优化,缩小了密文和密钥的尺寸,并减轻了密钥更新阶段的计算量。yang提出属性版本号的方法,将版本号添加到用户密钥中,每当有用户权限变化,使用新的版本号更新其余用户的密钥,保证已撤销的用户无法访问到系统后添加的数据。可见,因属性撤销引入的开销主要包含两点:更新所有用户的密钥,更新所有使用该属性的密文的访问结构。
在间接撤销模式研究后期,jahid等通过引入可信第三方的手段提出了一个基于cp-abe的easier方案。但此方案只适用于相关用户规模很小的情况,当相关用户的规模比较大时,需要耗费大量的计算量更新代理密钥。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种属性撤销方法,在满足安全性和存储代价可接受的条件下,使得因用户权限撤销而影响到的其他用户尽可能的少。
本发明采用以下技术方案:
一种属性撤销方法,使用树形用户空间组织方式,定义用户身份识别码为由0\1字符组成的字符串,所有用户的身份识别码拥有相同的长度m,用户身份空间是所有可能出现的用户身份识别码组成的一个全域i,域的大小为2m,根据属性使用情况划分群,然后将用户随机划分到不相关的群中,引入最小覆盖机制,使用最小可覆盖群机制组织已消减用户群,在已撤销用户群中存放代表一个用户群体的群标识码,并引入合并机制,在没有用户进入被撤销权限的用户群时,将相邻的群合并为一个群,更新用户的代理密钥和已消减用户集的插值因子完成属性撤销。
具体的,包括以下步骤:
s1、系统初始化,设有三个乘法循环群
s2、用户从认证中心处获得解密数据使用的密钥sk,当认证中心收到用户发来的产生密钥的请求时,运行keygen(sp,smk,s)算法,算法输入属性集合s、系统参数sp和系统主密钥smk,输出访问密钥sk;
s3、数据拥有着运行encrypt(sp,k,τ)→ct算法将明文数据转换为密文数据,算法依据访问树t,使用系统参数sp对数据k进行加密;
s4、代理密钥生成算法proxykey(sp,smk,rl)为已消减用户集rus和拥有权限的用户集aus中的用户生成子秘密,算法输入已消减用户列表rl,rl均匀分布于各个一级群中;
s5、先密文转换,然后解密数据;
s6、当属性撤销操作发生时,调用revocation(uid,sp,msk,rl,pxk)算法,输入用户的uid,系统参数sp,系统主密钥smk和已消减用户列表rus,代理密钥psk,更新用户的代理密钥和已消减用户集的插值因子。
进一步的,步骤s1具体为:
s101、由认证中心运行算法setup(1λ,m,n)为系统的正常运行生成基础的参数,从乘法群
选择两个随机指数
系统主密钥如下:
其中,系统主密钥参与到各个密钥生成的阶段,系统参数会参与到密钥生成、加解密、代理密钥生成和属性撤销等各个算法;
s102、当用户向认证中心发出携带自己身份描述信息info的请求时,认证中心运行userreg(sp,info)算法,验证请求用户的身份是否合法,如果用户的身份是合法的,则从用户身份空间中为请求用户分配一个全局唯一的用户身份识别码和用户公钥/私钥。
更进一步的,步骤s102中,生成upk/usk,算法选择随机指数
为用户生成身份识别码uid,算法userreg为用户分配身份识别码的过程就是从用户空间i中为用户随机选择一个未分配的字符串。
进一步的,步骤s2中,对于属性s∈s,认证中心根据使用属性s用户的数量将用户群划分为2l个一级群,每个一级群包含2m-l个用户,群标识码g的长度为l,记作gg;每个一级群gg由已消减用户集(revokedusers,rus)rusg、不拥有权限的用户集和拥有权限的用户集(authorizedusers,aus)ausg;
以每个已消减群为单位,使用秘密共享的机制将已消减用户群和拥有权限的用户联系起来,让他们共享一个密钥s,使用拉格朗日插值多项式的机制实现密钥共享;首先,计算得到已销减用户集rusg的大小t=|rugg|,算法为每个一级群gg生成阶为t+1的多项式,选择共享秘密
算法输出sk如下:
进一步的,步骤s3具体为:
自根节点r开始,以自顶向下的方式为t中每一个结点x选择一个多项式qx,对于每个多项式qx,设定度dx为比阈值kx小1,即dx=kx-1;选择一个随机指数
c=k·e(g1,g2)α·s
算法输出密文如下:
进一步的,步骤s4具体如下:
pg(gzr)
插值因子如下:
式中:zr=h1(id);计算得到,已消减用户集rus的代理密钥如下:
输出代理密钥(proxysecretkey,psk)如下:
进一步的,步骤s5中,根据用户的身份识别码,长度为l的前缀即是用户所在一级群的群识别码g=prx(uid,l),通过群识别码快速查找出用户所属群的已消减用户集的代理密钥pskg,计算将useruid映射到整数集
首先,查看在rusg中是否用有个元素是uid的前缀,如果是,则表示用户是rusg中的一个元素,不再拥有权限要求;否则,使用uid对pskg中的插值因子进行修正计算:
式中:gzr=h1(gid);
同时计算出useruid的插值因子:
式中:zr=h1(id);
输入密文组件c'y,计算出一个用于消除用户密钥的密文组件,
密文转化算法ct'输出:
更进一步的,采用数据解密算法decrypt(ct,ct',sk)验证用户的密钥是否满足密文中所定义的权限要求,验证过程包含如下:
第一层是验证用户密钥所隐含的属性集是否满足密文要求的属性集要求,通过验证用户密钥sk和密文ct实现;
第二层验证用户的密钥是否能代表用户的最新权限,通过验证使用嵌入用户密钥sk中的子秘密是否能够恢复共享秘密来实现;
算法输入密文ct,转换后的密钥ct'和用户密钥sk,如果用户拥有访问数据的权限,则输出明文,否则输出⊥,表示无法解密数据;首先定义算法decryptnode(ct,ct',sk,x),计算过程如下:
如果结点x是一个叶子结点,将密文转换后的结果cx″和λgid'引入数据解密的过程中,令i=att(x),进行如下计算:
如果i∈s
如果
decryptnode(ct,ct',sk,x)=⊥
如果结点x是访问树的一个内节点,对于结点x的所有孩子结点,调用数据解密算法,记录它们的计算结果作fz;令sx是由任意kx个满足条件fz≠⊥的孩子结点z构成的集合,如果满足要求的集合不存在,那么结点x不被满足,返回⊥;否则,计算如下:
解密算法从访问树t的根节点r出发,递归调用上述过程,如果用户的密钥满足访问树t,且对于每一个涉及到的属性,访问用户没有被添加到已消减用户群中,得到fr=e(g1,g2)r·s,进行如下计算得到最终明文:
其中,c为密文,d为解码密钥,fr为用户群的密钥,e为双线行映射关系,k为明文,g1,g2为乘法群的生成元,r、s、α、β为随机指数。
进一步的,步骤s6具体如下:
s601、根据用户的身份码将用户加入到他所在群的已消减用户集中,用户标识码的l位的前缀即使它所在一级群的识别码g=prx(uid,l),算法将用户useruid添加到群gg对应的已消减用户群rusg中;
将用户识别码uid添加到rusg中,然后调用递归合并算法merge,查看新添加的用户是否引起了合并操作;假设{g...00,g...010,g...101}∈rusg,新添加的用户为user...011,算法共调用了两次合并操作,第一次合并群g...010和群g...011为g...01,再次调用合并算法合并群g...00和群g...01为g...0;
s602、设定新的多项式p'g的阶t'=t+1,选择随机指数
p'g(x)=pg(x)+yt'+1·xt'+1=y0+y1·x+y2·x2+…+yt'+1·xt'+1
为群gg中的每个用户useruid更新代理密钥:
p'g(uzr)=pg(uzr)+yt'+1·uzrt'+1
为已消减用户集rusg中元素更新代理密钥,
p'g(gzr)=pg(gzr)+yt'+1·gzrt'+1
其中,uzr=h1(uid);gzr=h1(gid)。
与现有技术相比,本发明至少具有以下有益效果:
本发明一种属性撤销方法,使用树形结构组织用户的命名空间,引入已消减用户群组织已消减用户,在保证安全性的同时,降低了用户消减导致的密钥分配与重加密开销。
进一步的,系统初始化过程,定义半可信的认证机构,生成系统参数,为每个用户分配个人私钥与公钥,是加解密过程的基础。
进一步的,使用用户个人秘钥与已消减用户群信息生成用户个人的解密秘钥,包含了当前最新的相关群里的所有信息。
进一步的,使用对称秘钥与非对称秘钥相结合的二次加密方式,在保证安全性的同时,极大地降低了加解密的开销。
进一步的,每个已消减用户群维护一个代理密钥并公布,可以快速查找当前用户的权限信息,它代表了已消减用户群最新的权限信息,是进行相关密钥、密文更新的基础。
进一步的,用户消减后,更新已有的密钥和密文是必要的过程。在保证安全性的同时,使用了最小的计算开销,完成了密钥与密文的更新。
进一步的,密文的解密过程的安全性和性能是我们关注的重点,本文通过详细的过程和算式说明了整个解密过程的严谨性。
进一步的,合理的用户命名空间组织和已消减群命名空间组织,提升了加解密过程的效率。
综上所述,本发明可以抵御共谋攻击,保证了数据的机密性,数据的前向和后向安全性。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
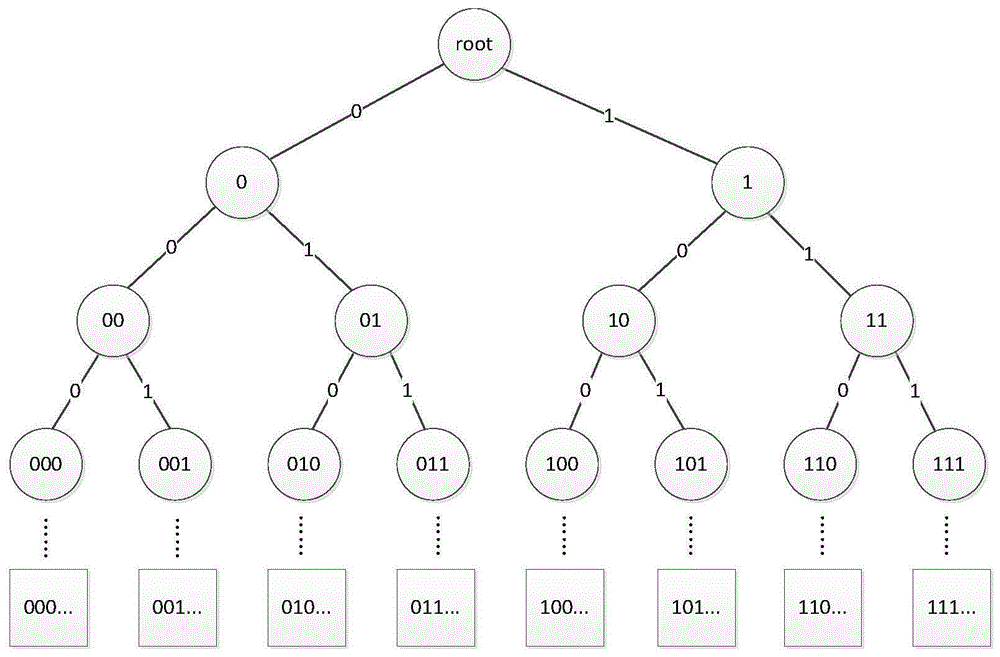
图1为用户空间树;
图2为群识别码和用户识别码的关系;
图3为一个最小覆盖示例;
图4为easier和本发明中数据解密的计算时间;
图5为easier和本发明中rus用户数目对属性撤销时间的影响;
图6为不同一级群数目对属性撤销时间的影响;
图7为已消减用户集元素数目分析;
图8为属性撤销方案的时间开销。
具体实施方式
本发明提供了一种属性撤销方法,首先提出一种用户空间的合理组织方法,并将这些用户随机地划分到不相关的群中,用户权限的撤销只影响到本群内的其他用户。而受影响的用户数量就是群中活动用户的数目,所划分的群数目越多,分摊到每个群中的活动用户越少,受到影响的其他用户也会越少。但是,群的大小越小时,所需要的存储开销也会越大。所以,群的划分视属性使用的具体情况而定。
另一方面,随着属性使用时间的增加,已销减用户集中用户数目在它所属的群中所占的比例呈不断上升趋势。本发明引入最小覆盖机制,在已撤销用户群中存放的是能代表一个用户群体的群标识码而不是用户标识码,并引入合并机制,在每有用户进入被撤销权限的用户群时,将相邻的群合并为一个群。随着时间的增加,已撤销用户集的中的相邻的群不断进行合并操作,当群中所有的用户都属于已撤销用户集时,已撤销用户集只需存储群标识码即可。在将用户加入已消减用户集时,群的合并过程可能会造成一定的开销,但是,这种方法遏制了已撤销用户集的增长,计算开销整体来说是在不断降低的。
本发明一种属性撤销方法,构建于cp-abe方案上,方案基于素数阶的双线性循环群,应用于子群
s1、系统初始化
s101、系统建立
由认证中心运行算法setup(1λ,m,n)为系统的正常运行生成基础的参数。算法详情如下:从乘法群
选择两个随机指数
系统主密钥如下:
其中,系统主密钥参与到各个密钥生成的阶段,系统参数会参与到密钥生成、加解密、代理密钥生成和属性撤销等各个算法。
s102、用户注册
当用户向认证中心发出携带自己身份描述信息info的请求时,认证中心运行userreg(sp,info)算法,验证请求用户的身份是否合法,如果用户的身份是合法的,则从用户身份空间中为请求用户分配一个全局唯一的用户身份识别码(useridentification,uid)和用户公钥/私钥(userpublickey/usersecretkey,upk/usk)。
a)生成upk/usk
算法选择随机指数
b)为用户生成身份识别码uid
算法userreg为用户分配身份识别码的过程就是从用户空间i中为用户随机选择一个未分配的字符串。
s2、密钥生成
用户从认证中心处获得解密数据使用的密钥sk,当认证中心收到用户发来的产生密钥的请求时,运行keygen(sp,smk,s)算法。算法输入属性集合s、系统参数sp和系统主密钥smk,输出访问密钥sk。
对于属性s∈s,认证中心根据使用属性s用户的数量将用户群划分为2l个一级群,每个一级群包含2m-l个用户,群标识码g的长度为l,记作gg。每个一级群gg由已消减用户集(revokedusers,rus)rusg、不拥有权限的用户集和拥有权限的用户集(authorizedusers,aus)ausg等三部分组成。
算法以每个以及群为单位,使用秘密共享的机制将已消减用户群和拥有权限的用户联系起来,让他们共享一个密钥s。根据shamir秘密共享机制提出的秘密共享的原理,使用拉格朗日插值多项式的机制实现密钥共享。首先,计算得到已销减用户集rusg的大小t=|rugg|,算法为每个一级群gg生成阶为t+1(所有已销减用户集中的用户和任意一个拥有权限的用户可以重构共享密钥)的多项式,选择共享秘密
选择随机指数
算法输出
s3、数据加密
数据拥有着运行encrypt(sp,k,τ)→ct算法将明文数据转换为密文数据。算法依据访问树t,使用系统参数sp对数据k进行加密。以下是具体的过程。
算法自根节点r开始,以自顶向下的方式为t中每一个结点x选择一个多项式qx。对于每个多项式qx,设定它的度dx为比阈值kx小1,即dx=kx-1。选择一个随机指数
设y是访问树t的叶子结点组成的集合,计算:
算法输出密文
s4、生成代理密钥
代理密钥生成算法proxykey(sp,smk,rl)用于为已消减用户集rus和拥有权限的用户集aus中的用户生成子秘密。算法输入已消减用户列表rl,rl均匀分布于各个一级群中。
pg(gzr)
插值因子:
式中:zr=h1(id)。
计算得到,已消减用户集rus的代理密钥:
输出代理密钥(proxysecretkey,psk):
s5、数据解密
s501、密文转换
密文转换算法convert(psk,ct)在代理端运行。算法输入代理密钥psk和密文ct,首先,由于只有t+1个参与方才可以通过得到共享密钥,而已取消用户集rus中元素个数为t,所以,当且仅当被授权的用户aus中的用户才可以得到共享密钥。
根据用户的身份识别码,它的长度为l的前缀即是用户所在一级群的群识别码g=prx(uid,l),可以通过群识别码快速查找出用户所属群的已消减用户集的代理密钥pskg。计算将useruid映射到整数集
首先,查看在rusg中是否用有个元素是uid的前缀,如果是,则表示用户是rusg中的一个元素,不再拥有权限要求。否则,使用uid对pskg中的插值因子进行修正计算:
式中:gzr=h1(gid)。
同时计算出useruid的插值因子:
式中:zr=h1(id)
输入密文组件c'y,计算出一个用于消除用户密钥的密文组件,
密文转化算法输出:
s502、解密数据
数据解密算法decrypt(ct,ct',sk)用于验证用户的密钥是否满足密文中所定义的权限要求。验证过程包含两层含义:
第一层是验证用户密钥所隐含的属性集是否满足密文要求的属性集要求,通过验证用户密钥sk和密文ct实现;
第二层验证用户的密钥是否能代表用户的最新权限,通过验证使用嵌入用户密钥sk中的子秘密是否能够恢复共享秘密来实现。
算法输入密文ct,转换后的密钥ct'和用户密钥sk,如果用户拥有访问数据的权限,则输出明文,否则输出⊥,表示无法解密数据。
数据解密是一个递归计算的过程。首先定义一个算法decryptnode(ct,ct',sk,x),计算过程如下:如果结点x是一个叶子结点,将密文转换后的结果cx″和λgid'引入数据解密的过程中,令i=att(x),进行如下计算:
如果i∈s
如果
如果结点x是访问树的一个内节点,对于结点x的所有孩子结点,调用decryptnode(ct,ct',sk,x)算法,记录它们的计算结果作fz。令sx是由任意kx个满足条件fz≠⊥的孩子结点z构成的集合,如果满足要求的集合不存在,那么结点x不被满足,返回⊥。
否则,计算如下:
解密算法从访问树t的根节点r出发,递归调用上述过程,如果用户的密钥满足访问树t,且对于每一个涉及到的属性,访问用户没有被添加到已消减用户群中,那么可以得到fr=e(g1,g2)r·s,算法进行如下计算得到最终明文:
s6、属性撤销
当属性撤销操作发生时,revocation(uid,sp,msk,rl,pxk)算法被调用。算法输入用户的uid,系统参数sp,系统主密钥smk和已消减用户列表rus,代理密钥psk等。算法主要包含两项工作:更新用户的代理密钥和已消减用户集的插值因子。
s601、更新已消减用户集
此过程是根据用户的身份码将用户加入到他所在群的已消减用户集中。用户标识码的l位的前缀即使它所在一级群的识别码g=prx(uid,l),算法将用户useruid添加到群gg对应的已消减用户群rusg中。
由于已消减用户群中的存储的用户采用的是最小覆盖原则,要保证存储规则不被破坏,可能需要经过一系列的合并操作,但是总次数不会超过n-l次(此时群gg中所有的用户都已经被消减,合并操作完成后rusg中只有一个元素)。算法首先将用户识别码uid添加到rusg中,然后调用递归合并算法merge,查看新添加的用户是否引起了合并操作。
在图4中,假设{g...00,g...010,g...101}∈rusg,新添加的用户为user...011,算法共调用了两次合并操作,第一次合并群g...010和群g...011为g...01,再次调用合并算法合并群g...00和群g...01为g...0。
s602、更新代理密钥
由于已消减用户群大小的改变,原来和群相关的多项式pg已经不再满足秘密共享的要求了。设定新的多项式p'g的阶t'=t+1,选择随机指数
p'g(uzr)=pg(uzr)+yt'+1·uzrt'+1
为已消减用户集rusg中元素更新代理密钥,
p'g(gzr)=pg(gzr)+yt'+1·gzrt'+1
式中:uzr=h1(uid);gzr=h1(gid)。
本发明和基于密文策略的属性加密方案比起来,加入了两个额外开销:已消减用户群更新引起的重新计算代理密钥和在加密的时候引入的密钥转换操作。
每次属性撤销操作中,将用户添加到已消减用户集中,旧的插值公式必须根据需要进行扩展,所以,用户原来的子密钥必须重新计算。虽然嵌入进用户密钥中的共享密钥并没有改变,但是代理密钥和子密钥对用户都是保密的,用户使用旧密钥进行共谋攻击也无法恢复共享密钥pg(0),即无法跳过验证权限是否已被撤销的过程。所以,本发明可以抵御共谋攻击。
属性撤销算法被触发后,会为被授权的用户更新子密钥,为已消减用户集中的元素更新代理密钥。权限过期的用户子密钥无法和已销减用户集的代理密钥联合恢复共享密钥,故无法通过恢复e(g,g)α·s解密密文。因此,未授权的用户无法解密得到明文,方案保证了数据的机密性。
当有用户新加入时,认证机构pg(0)会为用户随机选取身份标识码uid,并依据uid找到用户所在的群gg,按照shamir秘密共享机制,输入zid=h1(uid)生成子密钥pg(zid),将共享密钥pg(0)和子密钥pg(zid)嵌入到用户的密钥中
当有用户的权限被撤销时,认证机构定位出他所在的群gg,并将用户加入进已消减用户集rug,并会为群gg中所有权限未被撤销的用户更新子密钥,为rug更新代理密钥。被消减的用户使用旧的子密钥在解密的过程中无法消去密钥中的共享密钥pg(0),也就无法通过恢复e(g,g)α·s解密密文,保证了数据的后向安全性。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
1)使用树形的用户空间组织方式
定义用户身份识别码为由0\1字符组成的字符串,所有用户的身份识别码拥有相同的长度m。而用户身份空间是所有可能出现的用户身份识别码组成的一个全域i,域的大小为2m。为了实现用户空间的随机划分和快速查找,将用户空间组织为如图1所示的树形结构。
以下是用户空间树的构建过程:从根节点root出发,根据字符串的第1个字符是0还是1,可以将用户空间划分为身份识别码以“0”开始和以“1”开始的两个部分:“0…”和“1…”。按照相同的划分规则,根据字符串的第i个字符的值对群进行递归划分。划分过程中总共有m层递归,最后一层是字符串根据最后一位的划分后的结果,是一个m位的确定字符串,这个字符串可以被随机选作用户的身份识别码。可以看出,用户空间树的第i层有2m-i个节点,所有用户的身份识别码都选自叶子节点,共2m种可能的值。
在空间树中,每个内部节点都可以代表以它为根节点的整个子树的所有叶子节点组成的集合。如,节点“001”可以代表所有身份码以“001”为前缀的用户,称结点“001”这样可以代表一个用户集合的结点为群结点,而字符串“001”称为群识别码(groupidentification,gid),群识别码在整个空间树中具有唯一性。从图1可以看出,一个群可以是很多其他的群的集合。群识别码和用户识别码的关系如图2所示。
图2可以看出,用户身份识别码uid是由0/1组成的长度为m的字符串,群识别码gid的作为用户身份呢识别码的前缀,长度在1~m内变化。一个用户可能同时属于m个群,在用户空间树中,它们都是uid的祖先节点。长度为i的群标识码包含的用户数量为2n-i。
2)使用最小可覆盖群机制组织已消减用户群
已消减用户集用于记录那些权限被取消的用户。因为某些覆盖范围广的临时性属性会给代理密钥的更新带来很大的开销。随着属性使用时间的增长,已消减用户群中用户的数量也是在不断地积累,已消减用户群大小的的递增会引入大量的计算开销。为了减小rusg中元素数量,本发明使用在rusg中存储已消减用户的最小覆盖代替用户识别码。
请参阅图3,为某一个群的一部分,其中包含的已消减用户有{g…000,g….001,g…010,g…011,g…110,g…111},它的最小覆盖为{g…0,g…01,g…11}。
性能分析
(1)属性撤销
近年来,研究者们提出了各种属性撤销的方案,表1列举出来几种具有代表性的研究成果。
表1各方案中访问控制的比较
从表1可以看出,与lewko、hur和yang方案相比较,由于采用了最小可信代理机制,本发明和easie方案不需要更改相关密文组件,这将大大降低属性撤销的开销。
接下来的小节讨论本发明较easier方案在性能上的提升。
(2)方案对比
本小节从存储开销、通信开销和计算开销等三方面出发,分析本属性撤销方案相对于方案easier在性能方面的提升。
a)存储开销
在数据外包环境下,存储开销是衡量访问控制结构的一个非常重要的指标。本发明和easier方案的建立类似,都基于cp-abe算法的主体密钥结构。将
本发明和easier方案之间各组件的存储大小如表2所示。可以看出,与easier方案相比较,本发明的系统参数sp,系统主密钥smk、用户密钥sk、密文ct和代理密钥psk的大小并未增大。对于拉格朗日插值多项式p,本发明较easier方案,p的数目增长速度与属性被划分后的一级群的数目2l相等,但是由于一级群标识码的长度l是一个比较小的值,取值范围为0~m(m是用户标识码的长度),故多项式p的存储代价还处于可接受的范围之内。
表2组件大小对比
b)通信开销
和easier方案相比较,本发明在访问控制的基本结构方面并未增加额外的通信开销,本小节仅仅讨论因为属性撤销机制而引入的通信开销。此处假设已消减用户集中用户的总数目为,被授权的用户数目为2m,本属性的用户被分为2l个群。每次属性撤销操作会为被授权的用户更新子密钥,为已消减用户集中的用户更新代理密钥。从表3可见看出,本属性撤销方案将属性撤销会波及到的用户2u数目降低到了2l倍,具有较低的通信开销。
表3属性撤销算法引入的通信开销对比
c)计算开销
由于本发明并不会改变加密和解密等操作,在此主要比较在本发明和easier方案中单一属性撤销操作引入的计算开销。如表4所示,此处假设已消减用户群中用户的总数目为,被授权的用户数目为2m,本属性的用户被分为2l个群,tm表示一次乘法运算需要的时间,te表示一次幂运算需要的时间。
表4属性撤2u销算法引入的计算开销对比
从表4可以看出,属性撤销算法引入的计算开销主要包含更新子密钥和更新插值因子两项,由于本发明使用群策略组织用户,已消减用户集中元素的数目随着已消减用户数的增多而呈现如图7所示的变化趋势,大体在之间变化。所以,与easier方案相比较,本发明具有较低的计算开销。
综上所述,本发明在付出了部分存储开销的代价下,降低了属性撤销算法会引入的通信开销和计算开销。
3)模拟实验
在模拟实验中,使用了3.10ghzintel(r)core(tm)i5-2400处理器,8gb内存和windows10专业版,在vmware工作站12.0.1版本的虚拟机上运行unbuntu12.04.3,并为其分配1gb内存。
测试程序使用javapairing-basedcryptographylibrary(jpbc-2.0.0)提供的方法模拟访问控制模型。本发明使用的椭圆曲线类型为typea,提供两个输入参数:
在此设定用户的身份识别码为32bit。在本小节中,就数据解密、属性消减和rus中元素变化情况等三方面对算法性能进行了详细的模拟分析。
(1)数据解密
数据解密操作的计算开销会很直观地反映到用户体验上,让用户等待过长的时间会降低用户的体验度,所以,应该尽力降低用户从申请获取数据到得到数据这个过程中的时间。数据解密过程包括密文转换和解密数据两个过程,而此处计算开销的差异主要来自于密文转换。图3中分别显示了在已消减用户集的大小分别为(26,27,28,29,210,211,212,213)时,easier方案解密数据的时间和本发明在划分一级群为24份时解密数据的时间开销。
请参阅图4,为easier和本发明中数据解密的计算时间,从图4中可以看出,easier方案受rus中用户数量的影响较严重,这是因为在用户在获取数据之前,密文转换过程会影响到大量的相关用户。而本发明在当前已消减用户集的规模下,解密速度大体稳定,这是因为将用户划分到不同的群中,有效地控制了秘密共享机制中恢复共享秘密的参与方的数量。
综上所述,与easier方案相比较,本发明有效地降低了数据解密的计算开销。
(2)属性撤销
讨论easier方案和本发明之间关于属性撤销操作的性能差异如下。图5为在已消减用户集的大小分别为(26,27,28,29,210,211,212,213)时,easier方案和本发明在划分一级群为24份时属性撤销算法的运行时间。
从图5可以看出,与easier方案相比较,在rus中用户数目增大时,本发明中属性撤销算法的计算开销得到了有效的抑制。
为了更有效的突显出一级群的划分对属性消减算法的影响,本发明分析一级群的数目分别为(24,25,26,27)时,每次属性撤销操作所需要的计算时间进行对比,实验的具体情况如图6所示。
从图6中可以看出,随着一级群数目2l的上升,每次属性消减操作所需要的时间也会越来越小,在已消减用户集rus中数目较大的情况时更为明显,所以,本发明可以更适用于大规模的已消减用户集。
(3)rus中最小覆盖群的合并效果分析
测试本发明对覆盖面广且撤销频繁的属性的适用情况。在方案中,已消减用户集rus会以用户最小覆盖群的形式组织起来,每次有一个用户的权限被撤销后,会将其加入rus中,并验证他是否会引起相邻群的合并。
如图7所示,设定在一个大小为212的一级群中,随着拥有权限的用户相继被撤销权限,直到群中所有用户都不再拥有权限为止,rus中包含的群数量的变化趋势。从图7中可以看出,通过群合并操作,可以有效地抑制住rus中元素数目的上升趋势。
图8所示为图7群中有计算开销。随着被授权的用户的权限一个个被撤销后,直到群中所有用户都被撤销的过程中,每个消减用户权限属性撤销操作的所需要的时间开销。
在用户的消减过程中,虽然每次子群合并操作都会引入最多对数级别的计算开销(从大小分别为1有子群合并到大小为211的子群的合并),但是每次子群合并操作都会使得群中元素减少。而群中元素有降低必定会引起属性撤销算法的计算开销的不断地降低。
综上所述,本发明有效地抑制了覆盖面广且易撤销的属性对算法的影响。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!