极低信噪比环境下基于字典学习的频谱感知方法与流程
本发明涉及认知无线电中的频谱感知方法。
背景技术:
现有方法为了解决频谱利用的不平衡性提高频谱效率,认知无线电技术被提出。在认知无线电中,频谱感知是其最基础和最重要的一个环节,是认知无线环境分析的前提。目前的频谱感知方法主要包括能量感知方法、匹配滤波感知方法、循环平稳特征频谱感知方法以及特征值频谱感知方法等。但是这些方法在极低信噪比环境下的性能有待于提高。
学习字典理论的提出对于信号稀疏分解理论有着举足轻重的作用。它的优越性表现在对于一些现实信号的处理中能够取得一些最优结果。但学习字典不像分析字典那样,有着确定的内部结构和构成方法。目前字典学习算法主要包括最优方向法(mod算法),k-svd算法,递归最小二乘字典学习(rls-dla)以及在线字典学习(odl)等方法。目前使用最多的是mod算法和k-svd算法。
首先介绍mod算法:
mod算法最早是由engand等人提出的,并且是最早应用于训练信号稀疏表示学习字典的算法之一。假设信号xi属于空间ω,对于一组已知的训练信号
这里αi是矩阵γopt的每一列,||αi||0≤k是指稀疏分解中非零值的个数。求解的过程是一个类似于求解mp算法的np难问题。因为该问题是非凸的,最多能够得到一个局部问题解的最小值。与其他的字典训练方法相类似,mod算法是一种在字典更新和稀疏编码两个过程中间交替循环的迭代过程。稀疏编码就是对所有训练信号通过匹配追踪等稀疏表示算法进行编码。对于字典的更新过程,通过求解方程
mod算法的主要原理是将d看作一个矩阵来进行训练,其过程主要有两个步骤循环:训练信号的稀疏编码和学习字典的更新过程。
初始化时,任意产生一个字典矩阵(可以是随机矩阵,一般情况下采用dct字典),并将其按列归一化,即初始字典矩阵
(1)稀疏编码:
在这一阶段中,将字典dk-1不变,在保证信号稀疏度为k的情况下,求解信号集合xi,在该字典dk-1下的稀疏近似αi,即
其中,1≤i≤n为训练样本数量的标号,k为稀疏分解算法的循环次数,也即是训练信号的稀疏度。把所有稀疏表示向量并行排列,即可以得到稀疏表示矩阵γk。
(2)字典更新:
利用稀疏编码得到的稀疏表示矩阵γk作为已知条件,通过求解以下的目标函数来更新字典d,即
(3)停止迭代条件:
根据之前两步求解得到的稀疏表示矩阵γk和字典dk计算残差
或者循环次数满足预设的值,即k≥k0,则迭代停止,输出训练后的字典dopt;否则,继续之前两步的迭代。
下面介绍k-svd算法:
为了更加精确地训练一个可以用于稀疏信号表示的学习字典,研究人员在mod算法的基础上提出了k-svd算法。该训练算法的思路与mod算法类似。k-svd算法的主要创新之处在于算法的第二部分,它通过精确的奇异值分解的过程对字典的每个原子分别进行处理,而非采用对矩阵整体求逆整体更新的方法。因此,该算法是一种更稳定和高效的算法。
k-svd算法的名字取自于算法中对字典原子更新的主要步骤:根据字典中原子的个数n,重复n次奇异值分解过程。任意一个已知的字典的列,式(4)中的二次项可以写成:
其中,
通过之前的叙述可以看出,k-svd算法与mod算法的过程原理是类似的,都是分为稀疏表示和字典更新两个环节,不同之处在于k-svd算法的字典更新部分,不是采用mod算法中对字典取逆的方法,而是对字典中的所有原子通过奇异值分解算法依次更新。初始化时,任意产生一个字典矩阵(可以是随机矩阵,一般情况下采用dct字典),并将字典矩阵按列归一化,即初始字典矩阵
(1)稀疏编码:
在这一阶段中,将字典dk-1固定,在保证信号稀疏度为k的情况下,求解信号集合xi,在字典dk-1下的稀疏近似为xi,即:
其中,1≤i≤n为训练样本数量的标号,k为信号稀疏度,也即是训练信号的稀疏度;||αi||0≤k是指稀疏分解中非零值的个数;把所有稀疏表示向量并行排列,即可以得到稀疏表示矩阵γk;
(2)字典更新:
设dm是要更新的字典中的第m个原子,也即是字典dk-1中的第m列向量,此时字典对训练样本的表示误差为:
其中,
令
为了通过svd更新dm和
其中:ωm为中间变量,
利用svd对
其中:u、δ、v为矩阵;
用矩阵u的第一列u1更新dm,δ(1,1)·v1更新
其中:δ(1,1)为矩阵δ里第一个元素,v1为矩阵v里第一列,u1为矩阵u里第一列;
依次更新完字典中的所有原子。
(3)停止迭代条件:
根据上两步求解得到的字典dk和稀疏表示矩阵γk计算残差
或者循环次数满足预设的值,即k≥k0,则迭代停止,输出训练后的字典dopt;否则,继续之前两步的迭代;ε为阈值。
技术实现要素:
本发明的目的是为了解决现有方法在极低信噪比环境下频谱感知准确率低的问题,而提出极低信噪比环境下基于字典学习的频谱感知方法。
极低信噪比环境下基于字典学习的频谱感知方法具体过程为:
步骤一、建立频谱感知二元假设模型;
步骤二、采集n组频谱感知信号组成字典学习的训练集
步骤三、利用k-svd字典学习算法和稀疏度1约束条件训练字典dopt;
步骤四、计算频谱感知信号与训练后的字典dopt每一列的內积g[i],并找出内积中最大值的位置,即
步骤五、更新索引集γ={k}及原子集合dγ={dk},利用最小二乘法求得最大分量
其中,x是感知用户接收到的频谱感知信号向量,dk为字典中的第k个原子;
步骤六、对得到的最大分量α1平方计算得到最大分量对应的能量;
步骤七、设定需要的虚警概率,根据虚警概率公式计算感知门限λ;
步骤八、把步骤六得到的最大分量对应的能量和步骤七计算的门限进行对比,判断信号是否存在,如果能量大于门限则信号存在,否则信号不存在。
本发明的有益效果为:
本发明公开了一种极低信噪比情况下的频谱感知方法,具体公开一种基于字典学习和稀疏分解的频谱感知方法。首先,采集训练信号利用字典学习的k-svd方法训练字典,在训练字典的时候,为了使更多的信号集中在一个信号稀疏分解分量上,增加了稀疏度为1的约束。然后,利用频谱感知信号和训练好的字典对频谱感知信号进行分解,分解采用omp算法的第一次迭代即可。利用稀疏分解得到的分量的平方作为频谱感知的检验统计量。最后利用纽曼皮尔逊准则,固定虚警概率获得频谱感知门限,和检验统计量进行比较得到频谱感知结果。本发明公开的采用稀疏度为1约束下的字典学习方法进行信号稀疏分解,把更多的信号能量集中在一个信号稀疏分解分量上,实现了极低信噪比环境下的频谱感知。仿真结果表明,本发明提出的方法能够在信噪比为-26db的极低信噪比情况下实现准确的频谱感知,提高了极低信噪比环境下频谱感知准确率,提出方法的检测概率和roc性能在不同信噪比的情况下均具有优良的表现。
附图说明
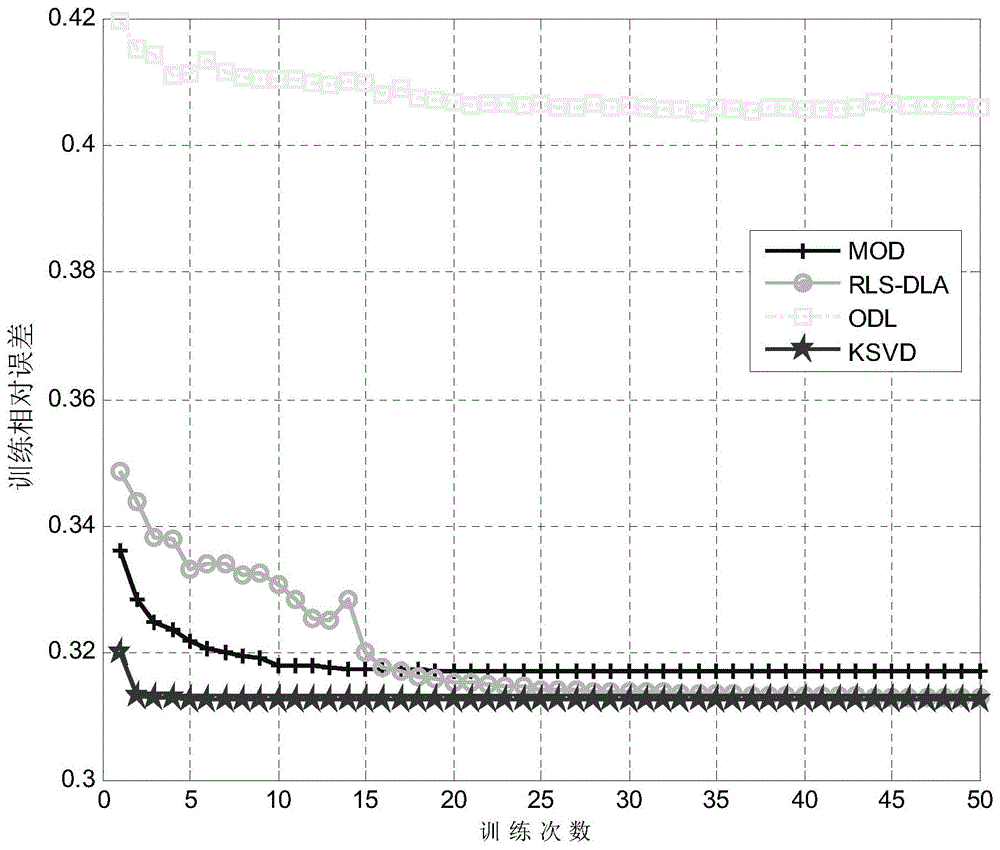
图1是采用不同字典学习方法得到的信号稀疏分解误差图,可以看出k-svd方法的性能是最好的,因此,本发明采用k-svd作为字典学习算法;
图2是提出的方法在不同信噪比下的检测概率和虚警概率图,可以看出本发明的方法相比于传统的方法有明显的优势,在信噪比为-26db的情况下,检测性能仍然满足fcc的要求,pd-sr1withdl和pf-sr1withdl是本发明,其他是现有技术;
图3是本发明方法和传统频谱感知在不同信噪比下的roc曲线图,可以看出本发明的方法性能明显优于传统的方法,sr1withdl(-35db)和sr1withdl(-15db)是本发明,其他是现有技术。
具体实施方式
具体实施方式一:本实施方式极低信噪比环境下基于字典学习的频谱感知方法具体过程为:
频谱感知低于-15db的信噪比为极低信噪比;
本发明涉及认知无线电中的频谱感知方法,具体为利用稀疏表示中的字典学习方法对信号稀疏表示的字典进行学习,根据学习到的字典对信号进行稀疏分解得到稀疏分解的最大分量,利用最大分量的平方作为检验统计量进行频谱感知。
本发明提出的方法利用字典学习方法和稀疏度约束为1的条件得到信号稀疏表示的训练字典,以此使信号的能量集中在一个稀疏表示分量上,最大限度地提高稀疏表示分量的信噪比。与此同时,选择信号稀疏表示分量的平方作为检验统计量,提高极低信噪比下的频谱感知性能。
假设信号的训练集为
其中,
根据上述信号稀疏分解原理可知,在选取一定的稀疏分解算法基础上,信号稀疏分解性能取决于在于字典的选择。在一般情况下,可以通过以下两类方式获取字典:一类是一些常见的正交基以及其演变得到的分析字典,比如fft基,dct字典等;另外一类是基于一系列已知信号通过字典学习算法得到的学习字典,也称之为训练字典。因此,具有字典学习功能的信号稀疏分解可以表示为
步骤一、建立频谱感知二元假设模型;
步骤二、采集n组频谱感知信号组成字典学习的训练集
步骤三、利用k-svd字典学习算法(公式(9)-(15))和稀疏度1约束条件训练字典dopt;
步骤四、计算频谱感知信号与训练后的字典dopt每一列的內积g[i],并找出内积中最大值的位置,即
步骤五、更新索引集γ={k}及原子集合dγ={dk},利用最小二乘法求得最大分量
其中,x是感知用户接收到的频谱感知信号向量,dk为字典中的第k个原子;
由于在原有的信号稀疏分解中稀疏度k是实现固定的,但是原来信号稀疏分解的目的是为了恢复信号,而频谱感知的目的是检测信号是否存在,并不关心信号的具体波形。因此,在提出的频谱感知方法中,把稀疏度k也看成可以优化的参数,目的是提高检验统计量的信噪比使得频谱感知的性能最优。
现在以一个信号为例证明稀疏度对信噪比的影响。首先把根据公式(17)得到的信号和噪声稀疏表示分量按照降序排列为α=[α1,α2,…,αi,…,αn]和β=[β1,β2,…,βi,…,βn],其中α1和β1分别为信号和噪声的最大稀疏表示分量;
定义稀疏表示后信号的信噪比为
现在分析噪声稀疏表示各个分量的关系,由于噪声符合均值为零的高斯分布,所以噪声稀疏表示的第i个分量
其中,n为加性高斯白噪声,di为字典中的第i个原子,nl为加性高斯白噪声中第l个元素,dli为字典第l个元素中的第i个原子,l为加性高斯白噪声中元素,m为加性高斯白噪声中元素个数;
βi的均值和方差分别为
观察公式(21)和(22)发现,噪声稀疏表示后的各个分量的均值为零,方差都为σ2;根据随机信号理论,对于均值为零的噪声,方差就是功率;
因此可以把公式(21)和(22)代入公式(19)可得
分析公式(24),发现接收信号稀疏表示后总的信噪比为各个稀疏表示分量信噪比
按照上面的结论可以选择利用字典学习算法得到的dopt对信号进行稀疏分解得到稀疏分解γopt的最大值作为检验统计量。收到上述思想的启发,可以设想,若稀疏度为1,则信号稀疏分解为一个分量,则信号的能量会更多的集中在一个信号分量上,此时应用于频谱感知的信号稀疏分解表示为
通过上述操作,虽然信号稀疏分解后的误差增大,但更多的信号能量集中在一个稀疏分解分量上,对于提升频谱感知的性能是有很大好处的。
步骤六、对得到的最大分量α1平方计算得到最大分量对应的能量;
步骤七、设定需要的虚警概率,根据虚警概率公式(29)计算感知门限λ;
步骤八、把步骤六得到的最大分量对应的能量和步骤七计算的门限进行对比,判断信号是否存在,如果能量大于门限则信号存在,否则信号不存在。
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤一中建立频谱感知二元假设模型;具体过程为:
本发明采用频谱感知的二元假设模型,在频谱感知的二元假设模型下每个感知用户接收频谱感知信号形式为
其中,x是感知用户接收到的频谱感知信号向量,n是加性高斯白噪声,符合均值为0,方差为σn2的正太分布n(0,σn2);h0代表主用户未占用所检测的频带资源的情况,h1代表主用户正占用所检测的频带资源的情况;s代表没有噪声的信号(纯信号);
按照稀疏分解理论,频谱感知的二元假设模型表示为
其中,d为稀疏分解字典,α和β分别为信号和噪声在字典d下的稀疏分解系数向量;rs和rn分别为信号和噪声稀疏分解的余量,当字典为正交字典时,rs和rn等于零。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤二中采集n组频谱感知信号组成字典学习的训练集
假设用户接收到频谱感知信号的个数为n个,n个频谱感知信号组成字典学习的训练集
其中,xn为感知用户接收到的第n个频谱感知信号向量;
找到一个训练后的字典dopt和一个训练信号在该字典dopt上的稀疏表示矩阵
其中,αi是矩阵γopt的每一列,为系数向量;||αi||0为系数向量
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述步骤七中设定需要的虚警概率,根据虚警概率公式(29)计算感知门限λ;具体过程为:
下面分析提出频谱感知方法的性能,主要包括检测概率和虚警概率。由于字典dopt中的原子已经进行了归一化处理,所以得到最大分量和其对应的时域能量是相等的。
h1情况下频谱感知的二元假设模型表示为
x=dα+dβ+r=x′+r=du+r(25)
其中,r为x的剩余分量,x′为中间变量(dα+dβ);d为稀疏分解字典,u为中间变量(α+β);
由于在实际操作中得到的是x′=du,x′包含了信号和噪声;噪声可以表示为
nu=x′-s(26)
其中,s代表没有噪声的信号(纯信号);
为了方便,进一步假设信号功率和噪声功率分别为ps和pu,对信号和噪声利用噪声的标准差
其中,γ为中间变量,
给定一个门限λ,提出频谱感知方法的检测概率和虚警概率可以表示为
其中,qm(·)为q函数;γ(·)表示伽马函数。
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述qm(·)和γ(·)分别被定义为
其中,a,b,t均为变量(函数)。
其它步骤及参数与具体实施方式一至四之一相同。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!