整数运动补偿的制作方法
相关申请的交叉引用
根据适用的《专利法》和/或《巴黎公约》的规定,本申请是为了及时要求2018年6月7日提交的在先美国临时专利申请no.62/682,150的权益,其全部公开以引用方式并入本公开,作为本申请的公开的一部分。
本文档涉及视频编码技术。
背景技术:
尽管视频压缩技术取得了进步,但数字视频仍在互联网和其他数字通信网络上占最大的带宽使用量。随着能够接收和显示视频的连接用户设备的数量增加,预计数字视频使用所需的带宽将继续增长。
技术实现要素:
公开了与视频编码中的解码器侧运动矢量推导(sidemotionvectorderivation,dmvd)相关的技术。该技术可以应用于现有的视频编码标准,如hevc、或最终确定的标准(多功能视频编码(versatilevideocoding,vvc))。该技术也可以应用于未来的视频编码标准或视频编解码器。
在一个示例方面,公开了一种解码包括视频的数字表示的比特流的方法。该方法包括:从比特流解码当前视频块的运动信息;生成一个或多个模板,其中一个或多个模板中的每个包含具有多个样本的视频块,基于一个或多个模板的模板来细化当前视频块的运动信息,以及对细化的运动信息执行运动补偿。
在另一示例方面,公开了一种装置,包括被配置为实施上述方法中的每一个的处理器。
在又一示例方面,这些方法可以以计算机可运行指令的形式体现并存储在计算机可读程序介质上。
在本文档中进一步描述了这些和其他方面。
附图说明
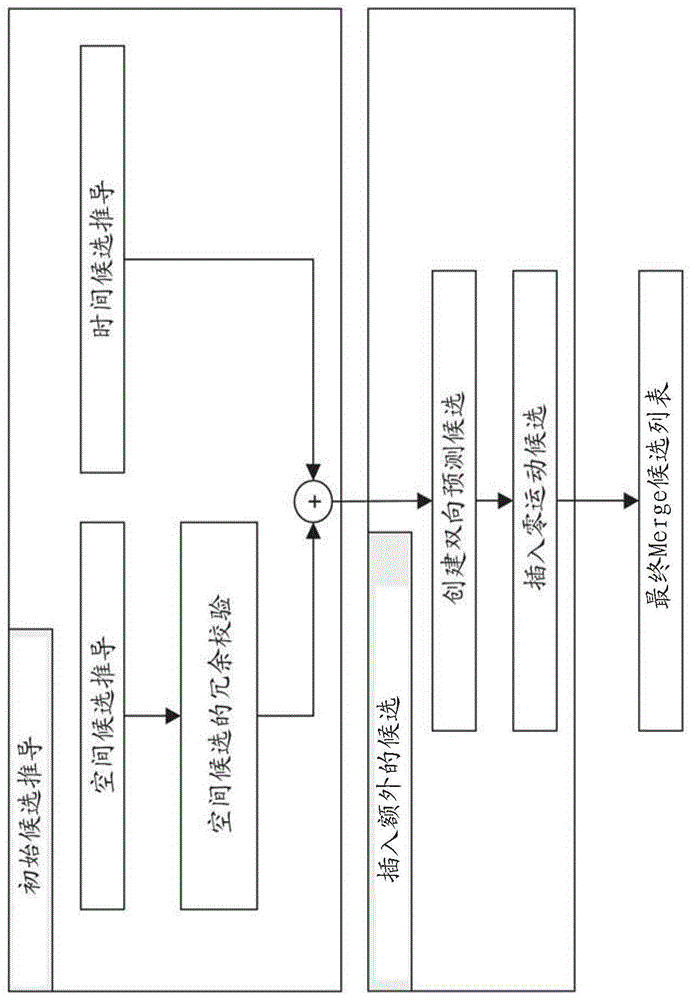
图1示出了用于merge(merge)候选列表建构的推导过程的示例。
图2示出了空间merge候选的示例位置。
图3示出了考虑空间merge候选的冗余校验的候选对的示例。
图4a和图4b示出了n×2n和2n×n个分区的第二pu的示例位置。
图5是用于时间merge候选的运动矢量缩放的示例说明。
图6示出了时间merge候选c0和c1的候选位置的示例。
图7示出了组合的双向预测merge候选的示例。
图8示出了运动矢量预测候选的示例推导过程。
图9示出了用于空间运动矢量候选的运动矢量缩放的示例说明。
图10示出了双边匹配的示例。
图11示出了模板匹配的示例。
图12示出了fruc中的单边me的示例。
图13示出了基于双边模板匹配的dmvr的示例。
图14示出了模板匹配中的简化模板的示例。
图15是视频解码的示例方法的流程图。
图16是视频解码装置的框图。
图17示出了视频编码器的示例实施方式。
具体实施方式
本文档提供了可由视频比特流的解码器使用的各种技术,以改善解压缩或解码的数字视频的质量。此外,视频编码器还可在编码处理期间实施这些技术,以便重建用于进一步编码的经解码的帧。
为了便于理解,在本文档中使用章节标题,并且不将实施例和技术限制于对应部分。这样,来自一个部分的实施例可以与来自其他部分的实施例组合。此外,虽然一些实施例详细描述了视频编码步骤,但是应该理解,将由解码器实施解码撤消(undo)编码的对应步骤。此外,术语视频处理包括视频编码或压缩、视频解码或解压缩以及视频转码,其中视频像素从一种压缩格式表示为另一压缩格式或以不同的压缩比特率表示。
1.技术框架
视频编码标准主要通过开发众所周知的itu-t和iso/iec标准而发展。itu-t产生了h.261和h.263,iso/iec产生了mpeg-1和mpeg-4visual,两个组织联合产生了h.262/mpeg-2视频和h.264/mpeg-4高级视频编码(advancedvideocoding,avc)和h.265/hevc标准[1]。从h.262开始,视频编码标准基于利用时间预测加变换编码的混合视频编码结构。为了探索hevc之外的未来视频编码技术,由vceg和mpeg于2015年联合成立了联合视频探索团队(jointvideoexplorationteam,jvet)。从那时起,许多新方法被jvet采用并被引入名为联合搜索模型(jointexplorationmodel,jem)的参考软件中[3][4]。在2018年4月,vceg(q6/16)和iso/iecjtc1sc29/wg11(mpeg)之间的联合视频专家组(jointvideoexpertteam,jvet)被创建用于vvc标准,目标是与hevc相比降低50%的比特率。
2.hevc/h.265中的帧间预测
每个帧间预测的预测单元(predictionunit,pu)具有用于一个或两个参考图片列表的运动参数。运动参数包括运动矢量和参考图片索引。也可以使用inter_pred_idc来信号通知两个参考图片列表中的一个的使用。可以将运动矢量明确地编码为相对于预测器的增量。
当用跳过模式对编码单元(codingunit,cu)进行编码时,一个pu与cu相关联,并且不存在显著的残差系数、没有编码的运动矢量增量或参考图片索引。指定merge模式,从而从相邻pu获得当前pu的运动参数,包括空间和时间候选。merge模式可以应用于任何帧间预测的pu,而不仅应用于跳过模式。merge模式的替代是运动参数的显式传输,其中,对于每个pu,明确地用信号通知运动矢量(更准确地说,与运动矢量预测器相比的运动矢量差)、每个参考图片列表的对应参考图片索引和参考图片列表使用[2]。在本文档中,这种模式被称为高级运动矢量预测(advancedmotionvectorprediction,amvp)。
当信令指示将使用两个参考图片列表中的一个时,从一个样本块产生pu。这被称为“单向预测(uni-prediction)”。单向预测可用于p条带和b条带两者。
当信令指示将使用两个参考图片列表时,从两个样本块产生pu。这被称为“双向预测(bi-prediction)”。双向预测仅适用于b条带。
以下文本提供了hevc中指定的帧间预测模式的详细信息。描述将从merge模式开始。
2.1.1merge模式
2.1.1.1merge模式的候选推导
当使用merge模式预测pu时,从比特流解析指向merge候选列表中的条目的索引并将其用于检索运动信息。该列表的建构(construction)在hevc标准中指定,并且可以根据以下步骤顺序进行总结:
●步骤1:初始候选推导
○步骤1.1:空间候选推导
○步骤1.2:空间候选的冗余校验
○步骤1.3:时间候选推导
●步骤2:插入额外的候选
○步骤2.1:创建双向预测候选
○步骤2.2:插入零运动候选
这些步骤也在图1中示意性地描绘。对于空间merge候选推导,在位于五个不同位置的候选当中选择最多四个merge候选。对于时间merge候选推导,在两个候选当中选择最多一个merge候选。由于在解码器处假设恒定数量的候选用于每个pu,因此当从步骤1获得的候选的数量未达到在条带报头中用信号通知的最大merge候选数量(maxnummergecand)时,生成额外的候选。由于候选的数量是恒定的,因此使用截断的一元二值化(truncatedunarybinarization,tu)来编码最佳merge候选的索引。如果cu的尺寸等于8,则当前cu的所有pu共享单个merge候选列表,其与2n×2n预测单元的merge候选列表相同。
在下文中,详细描述了与上述步骤相关的操作。
2.1.1.2空间候选推导
在空间merge候选的推导中,在位于图2描绘的位置的候选当中选择最多四个merge候选。推导的顺序是a1、b1、b0、a0和b2。仅当位置a1、b1、b0、a0的任何pu不可用(例如,因为它属于另一条带或区块)或者是帧内编码时,才考虑位置b2。在添加位置a1处的候选之后,对剩余候选的添加进行冗余校验,其确保具有相同运动信息的候选被排除在列表之外,使得编码效率提高。为了降低计算复杂度,在所提到的冗余校验中并未考虑所有可能的候选对。相反,仅考虑图3中用箭头连接的对,并且仅在用于冗余校验的对应候选具有不一样的运动信息时,才将候选添加到列表。重复运动信息的另一来源是与不同于2n×2n的分区相关联的“第二pu”。作为示例,图4a和图4b描绘了分别针对n×2n和2n×n的情况的第二pu。当当前pu被分区为n×2n时,位置a1处的候选不被考虑用于列表建构。实际上,通过添加该候选将导致具有相同运动信息的两个预测单元,这对于在编码单元中仅具有一个pu是多余的。类似地,当当前pu被分区为2n×n时,不考虑位置b1。
2.1.1.3时间候选推导
在该步骤中,只有一个候选被添加到列表中。具体地,在该时间merge候选的推导中,基于共同定位的pu来推导缩放的运动矢量,该共同定位的pu属于给定参考图片列表内与当前图片具有最小poc差的图片。在条带报头中明确地用信号通知要用于推导共同定位的pu的参考图片列表。如图5中的虚线所示获得用于时间merge候选的缩放的运动矢量,其是使用poc距离tb和td从共同定位的pu的运动矢量缩放的,其中tb被定义为当前图片的参考图片与当前图片之间的poc差,td被定义为是共同定位的图片的参考图片与共同定位的图片之间的poc差。时间merge候选的参考图片索引被设置为等于零。hevc规范[1]中描述了缩放过程的实际实现。对于b条带,获得两个运动矢量,一个用于参考图片列表0,另一用于参考图片列表1,并且结合该两个运动矢量以获得双向预测merge候选。
在属于参考帧的共同定位的pu(y)中,在候选c0和c1之间选择时间候选的位置,如图6所示。如果位置c0处的pu不可用、是帧内编码的、或者在当前ctu行之外,则使用位置c1。否则,位置c0用于时间merge候选的推导。
2.1.1.4插入额外的候选
除了空间和时间merge候选之外,还存在两种额外类型的merge候选:组合的双向预测merge候选和零merge候选。通过利用空间和时间merge候选来生成组合的双向预测merge候选。组合的双向预测merge候选仅用于b条带。通过将初始候选的第一参考图片列表运动参数与另一候选的第二参考图片列表运动参数组合来生成组合的双向预测候选。如果这两个元组提供不同的运动假设,它们将形成一个新的双向预测候选。作为示例,图7描绘了当原始列表(左侧)中具有mvl0和refidxl0或mvl1和refidxl1的两个候选被用于创建添加到最终列表(右侧)的组合的双向预测merge候选的情况。在hevc规范中定义了关于被认为生成这些额外的merge候选的组合的许多规则。
插入零运动候选以填充merge候选列表中的剩余条目,从而达到maxnummergecand容量。这些候选具有零空间位移和参考图片索引,该参考图片索引从零开始并且每当新的零运动候选被添加到列表时增加。这些候选使用的参考帧的数量是1和2,分别用于单向和双向预测。最后,不对这些候选执行冗余校验。
2.1.1.5用于并行处理的运动估计区域
为了加速编码处理,可以并行执行运动估计,从而同时推导给定区域内的所有预测单元的运动矢量。从空间邻域推导merge候选可能干扰并行处理,因为一个预测单元直到其相关联的运动估计完成时才能从相邻pu推导运动参数。为了减轻编码效率和处理等待时间之间的折衷,hevc定义运动估计区域(motionestimationregion,mer),其尺寸在图片参数集中使用hevc的语法元素“log2_parallel_merge_level_minus2”信号通知。当定义mer时,落入同一区域的merge候选被标记为不可用,因此在列表建构中不予考虑。
2.1.2amvp
amvp利用运动矢量与相邻pu的时空相关性,其用于运动参数的显式传输。对于每个参考图片列表,通过首先校验在时间上相邻的pu位置的上方,左侧的可用性,移除冗余候选并添加零矢量以使候选列表为恒定长度来建构运动矢量候选列表。然后,编码器可以从候选列表中选择最佳预测器,并发送指示所选候选的对应索引。与merge索引信令类似,使用截断的一元来编码最佳运动矢量候选的索引。在这种情况下要编码的最大值是2(参见图8)。在以下部分中,提供了关于运动矢量预测候选的推导过程的细节。
2.1.2.1amvp候选的推导
图8总结了运动矢量预测候选的推导过程。
在运动矢量预测中,考虑两种类型的运动矢量候选:空间运动矢量候选和时间运动矢量候选。对于空间运动矢量候选推导,最终基于位于图2所示的五个不同位置的每个pu的运动矢量推导两个运动矢量候选。
对于时间运动矢量候选推导,从两个候选中选择一个运动矢量候选,其是基于两个不同的共同定位的位置推导的。在产生时空候选的第一列表之后,移除列表中的重复的运动矢量候选。如果潜在候选的数量大于2,则从列表中移除相关联的参考图片列表内的其参考图片索引大于1的运动矢量候选。如果时空运动矢量候选的数量小于2,则将额外的零运动矢量候选添加到列表中。
2.1.2.2空间运动矢量候选
在空间运动矢量候选的推导中,在五个潜在候选当中考虑最多两个候选,其从位于如图2所示的位置的pu中推导,那些位置与运动merge的位置相同。将当前pu的左侧的推导顺序定义为a0、a1,以及缩放的a0、缩放的a1。将当前pu的上侧的推导顺序定义为b0、b1、b2,缩放的b0、缩放的b1、缩放的b2。因此,对于每一侧,存在可以用作运动矢量候选的四种情况,其中两种情况不需要使用空间缩放,两种情况使用空间缩放。四种不同的情况总结如下:
●没有空间缩放
-(1)相同的参考图片列表,以及相同的参考图片索引(相同的poc)
-(2)不同的参考图片列表,但相同的参考图片(相同的poc)
●空间缩放
-(3)相同的参考图片列表,但不同的参考图片(不同的poc)
-(4)不同的参考图片列表,以及不同的参考图片(不同的poc)
首先校验无空间缩放的情况,然后校验空间缩放。当poc在相邻pu的参考图片与当前pu的参考图片之间不同而不管参考图片列表时,考虑空间缩放。如果左候选的所有pu都不可用或者是帧内编码的,则允许对上述运动矢量进行缩放以帮助左和上mv候选的并行推导。否则,不允许对上述运动矢量进行空间缩放。
在空间缩放过程中,以与时间缩放类似的方式缩放相邻pu的运动矢量,如图9所示。主要区别是将参考图片列表和当前pu的索引作为输入给出;实际缩放过程与时间缩放过程相同。
2.1.2.3时间运动矢量候选
除了参考图片索引推导之外,用于推导时间merge候选的所有过程与用于推导空间运动矢量候选的过程相同(参见图6)。将参考图片索引用信号通知给解码器。
2.2jem中的新的帧间预测方法
2.2.1模式匹配的运动矢量推导
模式匹配的运动矢量推导(patternmatchedmotionvectorderivation,pmmvd)模式是基于帧速率上转换(frame-rateupconversion,fruc)技术的特殊merge模式。利用该模式,在解码器侧推导块的运动信息,而不是发信号通知块的运动信息。
当cu的merge标志为真时,向cu信号通知fruc标志。当fruc标志为假时,信号通知merge索引并使用常规merge模式。当fruc标志为真时,信号通知的额外的fruc模式标志以指示将使用哪种方法(双边匹配或模板匹配)来推导该块的运动信息。
在编码器侧,关于是否对cu使用frucmerge模式的决定是基于对正常merge候选所做的rd成本选择。即,通过使用rd成本选择来校验cu的两种匹配模式(双边匹配和模板匹配)两者。引起最小成本的匹配模式与其他cu模式进一步比较。如果fruc匹配模式是最有效的模式,则对于cu将fruc标志设置为真,并且使用相关的匹配模式。
frucmerge模式中的运动推导过程具有两个步骤:首先执行cu级运动搜索,然后进行子cu级运动细化。在cu级,基于双边匹配或模板匹配,推导整个cu的初始运动矢量。首先,生成mv候选列表,并且选择引起最小匹配成本的候选作为进一步cu级细化的起点。然后,在起点附近执行基于的双边匹配或模板匹配的局部搜索,并且将最小匹配成本的mv结果作为整个cu的mv。随后,以推导的cu运动矢量作为起点,进一步在子cu级细化运动信息。
例如,对于w×hcu运动信息推导执行以下推导过程。在第一阶段,推导整个w×hcu的mv。在第二阶段,该cu进一步被划分成m×m个子cu。m的值的计算方法如(1)所示,d是预定义的划分深度,在jem中默认设置为3。然后推导每个子cu的mv。
如图10所示,通过在两个不同参考图片中沿当前cu的运动轨迹找到两个块之间的最接近匹配,使用双边匹配来推导当前cu的运动信息。在连续运动轨迹的假设下,指向两个参考块的运动矢量mv0和mv1应当与当前图片和两个参考图片之间的时间距离(即td0和td1)成比例。作为特殊情况,当当前图片在时间上在两个参考图片之间并且从当前图片到两个参考图片的时间距离相同时,双边匹配成为基于镜像的双向mv。
如图11所示,模板匹配用于通过找到当前图片中的模板(当前cu的顶部和/或左侧相邻块)与参考图片中的块(与模板的尺寸相同)之间的最接近匹配来推导当前cu的运动信息。除了上述frucmerge模式之外,模板匹配也应用于amvp模式。在jem中,正如在hevc中所做的那样,amvp有两个候选。通过模板匹配方法,新的候选被推导出。如果由模板匹配新推导的候选与第一现有amvp候选不同,则将其插入amvp候选列表的最开始处,然后将列表尺寸设置为2(意味着移除第二现有amvp候选)。当应用于amvp模式时,仅应用cu级搜索。
2.2.2cu级mv候选集
在cu级处设置的mv候选包括:
(i)如果当前cu处于amvp模式,则为原始amvp候选
(ii)所有merge候选,
(iii)在2.2.4节中介绍的插值mv场中的几个mv。
(iv)顶部和左侧相邻运动矢量
当使用双边匹配时,将merge候选的每个有效mv用作输入,以生成假设双边匹配的情况下的mv对。例如,在参考列表a中,merge候选的一个有效mv是(mva,refa)。然后,在其他参考列表b中找到其配对的双边mv的参考图片refb,使得refa和refb在时间上位于当前图片的不同侧。如果这样的refb在参考列表b中不可用,则refb被确定为与refa不同的参考,并且其到当前图片的时间距离是列表b中的最小值。在确定refb之后,通过基于当前图片refa和refb之间的时间距离来缩放mva来推导mvb。
来自插值mv场的四个mv也被添加到cu级候选列表。更具体地,添加当前cu的位置(0,0)、(w/2,0)、(0,h/2)和(w/2,h/2)处的插值mv。
当fruc应用于amvp模式时,原始amvp候选也被添加到cu级mv候选集。
在cu级,对于amvpcu,最多将15个mv添加到候选列表,对于mergecu,最多将13个mv添加到候选列表。
2.2.3子cu级mv候选集
在子cu级处设置的mv候选包括:
(i)从cu级搜索确定的mv,
(ii)顶部、左侧、左上角和右上角的相邻mv,
(iii)来自参考图片的并置mv的缩放版本,
(iv)最多4个atmvp候选,
(v)最多4个stmvp候选
来自参考图片的缩放mv如下推导。遍历两个列表中的所有参考图片。参考图片中的子cu的并置位置处的mv被缩放到起始cu级mv的参考。
atmvp和stmvp候选仅限于前四个。
在子cu级,最多将17个mv添加到候选列表中。
2.2.4插值mv场的生成
在对帧进行编码之前,基于单边me为整个图片生成插值运动场。然后,运动场可以稍后用作cu级或子cu级mv候选。
首先,两个参考列表中的每个参考图片的运动场以4×4块级遍历。对于每个4×4块,如果与块相关联的运动通过当前图片中的4×4块(如图12所示)并且块未被分配任何插值运动,则参考块的运动根据时间距离td0和td1(以与hevc中的tmvp的mv缩放的方式相同的方式)被缩放到当前图片,并且将缩放的运动分配给当前帧中的块。如果没有缩放的mv被分配给4×4块,则在插值运动场中将块的运动标记为不可用。
2.2.5插值和匹配成本
当运动矢量指向分数样本位置时,需要运动补偿插值。为了降低复杂度,替代常规8抽头hevc插值,将双线性插值用于双边匹配和模板匹配。
匹配成本的计算在不同步骤处有点不同。当从cu级的候选集中选择候选时,匹配成本是双边匹配或模板匹配的绝对和差(absolutesumdifference,sad)。在确定起始mv之后,子cu级搜索的双边匹配的匹配成本计算如下:
其中w是根据经验设置为4的加权因子,mv和mvs分别指示当前mv和起始mv。sad仍用作子cu级搜索的模板匹配的匹配成本。
在fruc模式中,仅通过使用亮度样本来推导mv。推导的运动将用于mc帧间预测的亮度和色度两者。在确定mv之后,使用用于亮度的8抽头插值滤波器和用于色度的4抽头插值滤波器来执行最终mc。
2.2.6mv细化
mv细化是基于模式的mv搜索,以双边匹配成本或模板匹配成本为标准。在jem中,支持两种搜索模式—无限制中心偏置菱形搜索(unrestrictedcenter-biaseddiamondsearch,ucbds)和自适应交叉搜索,分别在cu级和子cu级进行mv细化。对于cu和子cu级mv细化两者,以四分之一亮度样本mv精度直接搜索mv,并且接着是八分之一亮度样本mv细化。将用于cu和子cu步骤的mv细化的搜索范围设置为等于8个亮度样本。
2.2.7模板匹配frucmerge模式中预测方向的选择
在双边匹配merge模式中,始终应用双向预测,因为cu的运动信息是基于在两个不同的参考图片中沿当前cu的运动轨迹的两个块之间的最近匹配推导的。对于模板匹配merge模式没有这样的限制。在模板匹配merge模式中,编码器可以从列表0中的单向预测、列表1中的单向预测或双向预测当中为cu选择。选择基于如下的模板匹配成本:
如果costbi<=factor*min(cost0,cost1)
则使用双向预测;
否则,如果cost0<=cost1
则使用列表0中的单向预测;
否则,
使用列表1中的单向预测;
其中cost0是列表0模板匹配的sad,cost1是列表1模板匹配的sad,costbi是双向预测模板匹配的sad。factor的值等于1.25,这意味着选择过程偏向于双向预测。
帧间预测方向选择仅应用于cu级模板匹配过程。
2.2.8解码器侧运动矢量细化
在双向预测操作中,对于一个块区域的预测,将分别使用list0的运动矢量(mv)和list1的mv形成的两个预测块进行组合以形成单个预测信号。在解码器侧运动矢量细化(decoder-sidemotionvectorrefinement,dmvr)方法中,通过双边模板匹配过程进一步细化双向预测的两个运动矢量。双边模板匹配应用在解码器中,以在双边模板和参考图片中的重建样本之间执行基于失真的搜索,以便获得细化的mv而无需传输附加的运动信息。
在dmvr中,分别从列表0的初始mv0和列表1的mv1,将双边模板生成为两个预测块的加权组合(即平均),如图13所示。模板匹配操作包括计算所生成的模板与参考图片中的(在初始预测块周围的)样本区域之间的成本度量。对于两个参考图片中的每个,将产生最小模板成本的mv考虑为该列表的更新mv以替换原始mv。在jem中,对每个列表搜索九个mv候选。该九个mv候选包括原始mv和8个与原始mv在水平或垂直方向上或两个方向上具有一个亮度样本偏移的环绕的mv。最后,将两个新的mv,即如图13中所示的mv0'和mv1',用于生成最终的双向预测结果。将绝对差之和(sad)用作成本度量。请注意,当计算由一个环绕的mv生成的预测块的成本时,实际上使用取整的mv(到整数像素)而不是真实mv来获得预测块。
将dmvr应用于双向预测的merge模式,其中一个mv来自过去的参考图片,另一mv来自未来的参考图片,而无需传输额外的语法元素。在jem中,当对cu启用lic、仿射运动、fruc或子cumerge候选时,不应用dmvr。
2.2.9问题的示例
如dmvr和fruc的dmvd方法执行运动估计以推导或细化运动信息,这对于解码器来说非常复杂。在运动估计期间,它们有一个共同的问题:对于块中的所有像素计算模板和候选块之间的差(绝对差、平方差等)并将其相加,然后用于选择最佳匹配块。这不是必需的,因为部分像素的差可能足以选择最佳候选块或mv。同时,通常在运动矢量的推导或细化中仅使用亮度分量,而不考虑色度分量。
对于dmvr,它有另一复杂度问题:它执行两次运动补偿,一次用于生成模板,以及另一次用于生成最终预测块。结果,对于每个参考图片列表(即,预测方向),它执行两次水平插值和垂直插值两者,以防初始mv和细化的mv仅具有分数分量。这极大地增加了最坏情况的复杂度。同时,dmvr仅在merge模式下工作,而不能在amvp模式下工作。在mv细化中,它将信号通知的mv(从merge候选推导的mv)作为起始mv,并校验其环绕的mv。然而,没有考虑信号通知的mv的mv精度。在amvr中,可能选择低精度mv。例如,假设最高允许的mv精度是1/4像素,在amvr中,可以使用4像素或1像素mv。在这种情况下,dmvr可用于细化mv精度。与可以在子块级应用的fruc不同,除了atmvp和stmvp情况之外,dmvr在块级执行,这可能导致编码性能损失。
对于furc,当执行双边匹配时,考虑起始mv和候选mv之间的mv差以抑制不可靠的运动矢量,如等式2。将mv差乘以固定的加权因子,这可能不合理。对于较大的块,sad起主导作用并且mv差是可忽略的,并且对于较小的块,mv差可能太大。
2.2.10示例实施例
我们提议了几个方面来降低dmvd方法的复杂度并提高编码性能。所公开的方法可以应用于现有的dmvd方法,但也可以应用于解码器侧的运动/模式推导的未来方法。
第一,仅针对解码器侧运动估计中的部分像素,即,在运动信息推导或细化过程中,计算模板和候选块之间的成本(例如,考虑失真和mv的差、失真或成本)。第二,对于dmvr,插值次数减少。第三,使用所公开的技术的一些实施例将dmvr应用于amvp模式。第四,对于不同的块尺寸,mv差的权重因子可以不同。
以下列举的示例提供了一些方式,通过这些方式,可以将所公开的技术体现到视频解码过程中。
将prec表示为运动矢量精度,当prec等于n时,它意味着运动矢量具有1/2^n像素精度。n可以是正整数、零或负整数。
1.仅针对运动信息推导或细化过程中的部分所选择的行计算模板和候选块之间的成本(例如,差)。
a.在一个示例中,所选择的行定义为所有每n行的第i行,其中n>1并且1<=i<=n。例如,n等于2并且i等于1。
b.在一个示例中,对于具有n行的每个组,组内的某些行用作所选择的行。例如,利用每4行的第一行和第二行。
c.在一个示例中,针对块的任意所选择的行计算成本,例如,第一行和最后一行,或者前两行和后两行。
d.选择部分行时,可以对所有块尺寸应用相同的规则。可替代地,可以对不同的块尺寸和/或块形状(例如,正方形或矩形或块宽度和块高度之间的比率)应用不同的规则。
i.在一个示例中,在成本计算期间,对于更大的块尺寸,跳过更多行,反之亦然。例如,当块尺寸小于16×16(即,宽度*高度<16*16)时,针对每2行的第一行计算差,但是对于其他块尺寸针对每4行的第一行计算差。
ii.在一个示例中,在成本计算期间,对于具有较大高度的块形状,跳过更多行,反之亦然。例如,当块的高度小于16时,针对每2行的第一行计算成本,但是对于其他块尺寸,针对每4行的第一行计算成本。
iii.在一个示例中,这种简化仅应用于一个或几个最小块尺寸(即,最小宽度*高度)以抑制最坏情况的复杂度。例如,简化仅应用于面积小于8×8的块。
iv.在一个示例中,这种简化仅应用于一个或几个最大块尺寸。例如,简化仅应用于面积大于32×32的块。
v.在一个示例中,这种简化仅应用于具有最大块高度或宽度的一个或几个块形状。
vi.在一个示例中,这种简化仅应用于一些所选择的块形状。
2.对于块的每一行或块的每个所选择的行,计算所有列或仅部分列的成本。
a.在一个示例中,计算每个t列的m个连续列(可以在任何有效列y处开始)的成本,其中t>0,1<=m<=t,1<=y<=t-m+1。例如,t=8,m=4并且y=1。
b.在一个示例中,计算每t列的m个所选择的列的成本。
c.在一个示例中,计算行的m个任意所选择的列(例如,前k列和后l列)的成本。
d.选择部分列时,可以将相同的规则应用于所有块尺寸。或者,可以将不同的规则应用于不同的块尺寸和/或块形状(例如,正方形或矩形或块宽度和块高度之间的比率)。
i.在一个示例中,在成本计算期间,对于更大的块尺寸跳过更多列,反之亦然。例如,当块尺寸小于16×16时,计算每8列的前4列的差,但是针对其他块尺寸计算每16列的前4列的差。当列小于8或16时,仅使用前4列计算差。
ii.在一个示例中,在成本计算期间,对于具有较大宽度的块形状跳过更多列,反之亦然。例如,当块的宽度小于16时,计算每8列的前4列的成本,但是针对其他块尺寸计算每16列的前4列的成本。
iii.在一个示例中,这种简化仅应用于一个或几个最小块尺寸以抑制最坏情况的复杂度。
iv.在一个示例中,这种简化仅应用于一个或几个最大块尺寸。
v.在一个示例中,这种简化仅应用于具有最大块宽度的一个或几个块形状。
vi.在一个示例中,这种简化仅应用于一些所选择的块形状。
3.在dmvr中,当生成模板时,使用具有整数水平分量或垂直分量的mv或整数mv来执行运动补偿,而不是如在jem中那样使用真实mv。
a.在一个示例中,对于两个预测方向,mv(水平分量和垂直分量两者)取整为整数精度。
b.在一个示例中,一个预测方向的mv被取整为整数精度,而其他预测方向的mv不改变。
c.在一个示例中,对于每个预测方向,仅将一个mv分量(水平分量或垂直分量)取整为整数精度。
d.在一个示例中,一个预测方向的mv被取整为整数精度,并且另一预测方向的仅一个mv分量被取整为整数精度。
e.在一个示例中,不改变一个预测方向的mv,并且将其他预测方向的仅一个mv分量取整为整数精度。
f.将fmv表示为分数mv,并将imv表示为取整的整数精度mv。将sign(x)表示为x的sign,并且
i.imv=(fmv+(1<<(prec-1)))>>prec
ii.可替代地,imv=fmv>>prec
iii.可替代地,imv=(fmv+sign(fmv)*(1<<(prec-1)))>>prec
g.这种简化可以应用于所有块尺寸或仅应用于一个或几个块尺寸和/或某些块形状。
i.在一个示例中,将其应用于一个或几个最小块尺寸,如jem或bms(基准集)中的4×4、或hevc中的4×8和8×4。
ii.在一个示例中,将其应用于一个或几个最大块尺寸。
iii.在一个示例中,将其应用于某些所选择的块尺寸。
4.可替代地,在dmvr中,当生成模板时,在运动补偿中使用较短抽头的插值滤波器(诸如双线性滤波器)。
5.提议dmvr以子块级执行。块可以以不同方式划分成子块。
a.在一个示例中,所有块被划分成固定的m×n子块尺寸,例如,4×4、或4×8或8×4或8×8或8×16或16×8或16×16等。当块宽度/高度是子块宽度/高度的整数倍时,它被划分成子块;否则,它不会被划分为子块。
b.在一个示例中,块被划分为具有相等尺寸的k个子块,其中k>=2。例如,m×n块被划分为4个(m/2)×(n/2)个子块、或者2个(m/2)×n个子块、或2个m×(n/2)个块。
c.在一个示例中,划分方法取决于块尺寸或块形状或其他编码信息。例如,8×32块被划分成4×8个子块,32×8块被划分成8×4个子块。
d.在一个示例中,当生成子块的模板时,可以利用整个块的推导的运动信息,如在当前块级dmvr中。
i.可替代地,可以利用具有或不具有整个块的推导的运动信息的相邻(多个)子块的细化运动信息来形成模板。
e.在一个示例中,子块的搜索点还可以考虑来自其他(多个)子块的细化的运动信息。
6.在一个示例中,(在pmmvd中)模板匹配使用的模板仅包括当前块上方的像素,而不包括当前块左侧的像素,如图14所示。
7.在现有的dmvd方法中,仅考虑亮度分量来推导或细化运动矢量。提议还考虑色度分量。用ci表示给定运动矢量的三个颜色分量的成本(其中i指示颜色分量索引)。
a.最终成本被定义为wi*ci,其中wi指示第i个颜色分量的权重。
b.可替代地,最终成本被定义为(w0*c0+w1*(c1+c2))。在一些示例中,w0或w1等于1。
c.在一个示例中,当将dmvr应用于色度分量时,可以应用运动矢量的取整,使得可以利用整数运动矢量,而不需要对色度分量应用插值。
d.在一个示例中,当将dmvr应用于色度分量时,如果需要插值,则可以应用较短抽头的插值滤波器(诸如双线性滤波器)。
8.上述方法可以应用于某些颜色分量或所有颜色分量。
a.可以将不同的规则应用于不同的颜色分量,或者亮度和色度分量可以利用不同的规则。
b.可替代地,可以在序列参数集、图片参数集、条带报头等中进一步信号通知如何以及是否应用上述方法。
图15是视频解码的示例方法1500的流程图。方法1500包括从比特流解码(1502)当前视频块的运动信息;从比特流解码当前视频块的运动信息,生成(1504)一个或多个模板,其中一个或多个模板中的每个包含具有多个样本的视频块,基于一个或多个模板的模板来细化(1506)当前视频块的运动信息,以及对细化的运动信息执行(1508)运动补偿。
2.2.10节提供了可以通过方法1500实施的额外的示例实施例和变型。例如,在一些实施例中,一个或多个模板的生成包括使用双线性插值滤波器、仅整数运动矢量值、仅整数水平运动矢量值和仅整数垂直运动矢量值中的一个或多个。在一些实施例中,仅整数水平运动矢量值和仅整数垂直运动矢量值用于第一预测方向和第二预测方向。在一些实施例中,仅整数运动矢量值仅用于第一预测方向。
在一些实施例中,条件包括一个或多个模板的尺寸。在一些实施例中,一个或多个模板的尺寸对应于最小可能的块尺寸。在一些实施例中,一个或多个模板的尺寸对应于最大可能块尺寸。
在一些实施例中,条件包括一个或多个模板的形状。
如在2.2.10节中进一步讨论的,在一些实施例中,仅整数水平运动矢量值和仅整数垂直运动矢量值之一用于第一预测方向,并且仅整数水平运动矢量值和仅整数垂直运动矢量值之一用于第二预测方向。可替代地,仅整数运动矢量值用于第一预测方向,并且仅整数水平运动矢量值和仅整数垂直运动矢量值之一用于第二预测方向。
图16示出了可用以实施本发明所公开的技术的各个部分的硬件设备1600的示例实施例的框图。硬件设备1600可以是笔记本电脑、智能手机、平板电脑、摄像机或能够处理视频的其他类型的设备。设备1600包括处理数据的处理器或控制器1602,以及与处理器1602通信、存储和/或缓冲数据的存储器1604。例如,处理器1602可以包括中央处理单元(centralprocessingunit,cpu)或微控制器单元(microcontrollerunit,mcu)。在一些实施方式中,处理器1602可包含现场可编程门阵列(field-programmablegate-array,fpga)。在一些实施方式中,设备1600包括或与图形处理单元(graphicsprocessingunit,gpu)、视频处理单元(videoprocessingunit,vpu)和/或无线通信单元通信,以实现智能手机设备的各种视觉和/或通信数据处理功能。例如,存储器1604可以包括并存储处理器可运行代码,该代码在由处理器1602运行时,将设备1600配置为执行各种操作,例如诸如接收信息、命令和/或数据,处理信息和数据,以及将处理过的信息/数据发送或提供给另一设备,诸如执行器或外部显示器。为了支持设备1600的各种功能,存储器1604可以存储信息和数据,诸如指令、软件、值、图像以及处理器1602处理或引用的其他数据。例如,可以使用各种类型的随机存取存储器(randomaccessmemory,ram)设备、只读存储器(readonlymemory,rom)设备、闪存设备和其他合适的存储介质来实施存储器1604的存储功能。设备1600还可以包括专用视频处理电路1606,用于执行重复计算功能,诸如变换和解码。
图17是示出视频编码器的示例实施方式的框图。视频编码器对使用诸如变换、运动估计和残差误差编码的编码工具编码的视频图片进行操作。在编码器处对编码的视频帧进行重构(运动补偿),并将其用作用于其他视频图片的帧间编码的参考图片。本文档中描述的技术可以由视频编码器或视频解码器使用诸如关于图16所描述的硬件平台来实施。
从前述内容可以理解,本文已经出于说明的目的描述了当前所公开的技术的具体实施例,但是在不脱离本发明的范围的情况下可以做出各种修改。因此,除了所附权利要求之外,当前所公开的技术不受限制。
本文档中描述的公开的和其他实施例、模块和功能性操作可以在数字电子电路中实施,或者在计算机软件、固件或硬件中实施,包括本文档中公开的结构及其结构等同物,或者以他们的一个或多个的组合实施。所公开的和其他实施例可以被实施为一个或多个计算机程序产品,即,在计算机可读介质上编码的一个或多个计算机程序指令模块,用于由数据处理装置运行或控制数据处理装置的操作。计算机可读介质可以是机器可读存储设备、机器可读存储基板、存储器设备、影响机器可读传播信号的物质的合成、或者它们中的一个或多个的组合。术语“数据处理装置”包括用于处理数据的所有装置、设备和机器,包括例如可编程处理器、计算机或者多个处理器或计算机。除了硬件之外,装置可以包括为所讨论的计算机程序创建运行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统及其一个或多个的组合的代码。传播信号是人工生成的信号,例如机器生成的电信号、光信号或电磁信号,其被生成以对信息进行编码以便传输到合适的接收器装置。
计算机程序(也称为程序、软件、软件应用、脚本或代码)可以用任何形式的编程语言(包括编译语言或解释语言)编写,并且可以以任何形式部署,包括作为独立程序或作为模块、组件、子程序或其他适合在计算环境中使用的单元。计算机程序不一定与文件系统中的文件相对应。程序可以存储在保存其他程序或数据的文件的部分中(例如,存储在标记语言文档中的一个或多个脚本)、专用于所讨论的程序的单个文件中、或多个协调文件(例如,存储一个或多个模块、子程序或部分代码的文件)中。计算机程序可以部署在一台或多台计算机上来执行,这些计算机位于一个站点或分布在多个站点并通过通信网络互连。
本文档中描述的处理和逻辑流可以由一个或多个可编程处理器执行,该一个或多个处理器运行一个或多个计算机程序,通过对输入数据进行操作并生成输出来执行功能。处理和逻辑流也可以由专用逻辑电路来执行,并且装置也可以实施为专用逻辑电路,例如,fpga(现场可编程门阵列)或asic(专用集成电路)。
例如,适用于运行计算机程序的处理器包括通用和专用微处理器、以及任何类型的数字计算机的任何一个或多个处理器。通常,处理器将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是执行指令的处理器和存储指令和数据的一个或多个存储设备。通常,计算机还将包括一个或多个用于存储数据的大容量存储设备,例如,磁盘、磁光盘或光盘,或可操作地耦合到一个或多个大容量存储设备,以从其接收数据或向其传送数据,或两者兼有。然而,计算机不一定需要具有这样的设备。适用于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如eprom、eeprom和闪存设备;磁盘,例如内部硬盘或可移动磁盘;磁光盘;以及cdrom和dvd-rom光盘。处理器和存储器可以由专用逻辑电路来补充,或合并到专用逻辑电路中。
虽然本专利文档包含许多细节,但不应将其解释为对任何发明或要求保护的范围的限制,而应解释为特定于特定发明的特定实施例的特征的描述。本专利文档在分离的实施例的上下文描述的某些特征也可以在单个实施例中组合实施。相反,在单个实施例的上下文中描述的各种功能也可以在多个实施例中单独地实施,或在任何合适的子组合中实施。此外,虽然特征可以被描述为在某些组合中起作用,甚至最初这样要求保护,但在某些情况下,可以从要求保护的组合中删除组合中的一个或多个特征,并且要求保护的组合可以指向子组合或子组合的变体。
同样,尽管在附图中以特定顺序描述了操作,但这不应理解为要获得期望的结果必须按照所示的特定顺序或次序顺序来执行这些操作,或执行所有示出的操作。此外,本专利文档所述实施例中的各种系统组件的分离不应理解为在所有实施例中都需要这样的分离。
仅描述了一些实施方式和示例,其他实施方式、增强和变体可以基于本专利文档中描述和说明的内容做出。
- 还没有人留言评论。精彩留言会获得点赞!