一种基于深度强化学习的虚拟网络映射方法与流程
本发明涉及软件定义网络中虚拟网络的映射问题,特别涉及一种基于深度强化学习的虚拟网络映射方法。
背景技术:
随着云计算、移动互联网等技术的快速发展,多租户网络的需求越来越多和灵活,传统的以ip为核心的基础框架存在着扩展能力差和核心功能单一等问题,不能满足多租户网络的业务需求。
网络虚拟化技术是解决上述问题的有效方法,它能融合现有的通信和计算资源虚拟化技术,采用分层的技术手段解决此问题,是未来互联网应具备的关键特性之一。网络虚拟化技术使用解耦合和复用的方法使底层网络的物理资源被多个虚拟网络共享,为共享的异构上层网络提供差异化服务。可自组织、重构的上层虚拟网络能够动态的映射到底层物理网络之上,实现快速的异构网络部署。
但是在现有环境下实现网络虚拟化存在很大的局限性,于是一种新兴的网络体系架构—sdn应运而生。它将控制与转发分离,并且实现了可编程的集中控制,支持网络虚拟化,二者相辅相成,是两种具有高度相关性的技术的有效结合,可以很好的满足未来网络对组网的灵活性,网络的集中管理等需求。
虚拟网络映射或者虚拟网络嵌入是实现网络虚拟化的一项重要挑战,它能够实现将底层网络资源分配给虚拟网络,即在节点上分配cpu资源,在链路上分配带宽资源。vne是一个np难问题,即使所有的虚拟节点已被映射后,映射带有带宽资源约束的虚拟链路仍然是np难的。面向软件定义网络的虚拟网络映射是对底层网络设备的虚拟化,使其可以支持更多的可扩展应用,同一个物理基础设施可以运行多样的虚拟网络。
由于传统的深度强化学习无法解决q学习算法的固有缺点-过优估计,过优估计指的是估计的值函数比真实的值函数偏大,如果过优估计在所有状态都是均匀的,那么根据贪心策略,依然能够找到值函数的最大动作,但是往往过优估计在各个状态不是均匀的,因此过优估计会影响到策略决策,从而导致获取的不是最优策略。
技术实现要素:
本发明的目的在于针对软件定义网络中虚拟网络映射问题,提出一种基于深度强化学习的虚拟网络映射方法。
为了达到上述目的,本发明采用了以下技术方案:
一种基于深度强化学习的虚拟网络映射方法,包括以下步骤:
步骤1,将虚拟网络映射中节点映射问题建模为马尔可夫决策过程;
步骤2,在马尔可夫决策过程基础上,利用ddqn算法进行虚拟节点的映射;
步骤3,利用最短路径算法进行虚拟网络链路映射:
步骤4,更新物理网络资源,包括cpu资源和链路带宽资源。
本发明进一步的改进在于,步骤1的具体过程如下:
2.1定义状态集合st
假设在给定状态st中,代理选择一个物理节点
其中
2.2定义动作集合at
代理选择节点
其中ε表示能够到达终端状态的任意动作;当代理选择当前虚拟节点
2.3定义状态转移概率矩阵pr
当处于状态st时,代理选择节点
2.4定义回报函数r
其中,j表示第j个样本,γ为衰减因子,q为当前q网络,q′为目标q网络,a′为在当前q网络中最大q值对应的动作。
本发明进一步的改进在于,步骤2的具体过程如下:
3.1随机初始化所有状态和动作对应的价值q,随机初始化当前q网络的所有参数θ,初始化目标q网络的参数θ′=θ,清空经验回放集合d;
3.2初始化状态集合s为当前状态的第一个状态,得到状态集合s的特征向量,并用
3.3在当前q网络中使用状态集合s的特征向量
3.4在状态s执行当前动作a,得到新状态s′、特征向量
3.5将
3.6令初始状态s=s′;
3.7从经验回放集合d中采集m个样本
3.8使用均方差损失函数
3.9重复步骤3.1-步骤3.8多次,如果重复次数达到目标网络的更新频率c,则更新目标网络参数θ′=θ;如果重复次数没有达到目标网络的更新频率c,则继续重复步骤3.1-步骤3.8;
3.10判断终止状态标志is_end是否为终止状态;如果终止状态标志is_end是终止状态,则进行步骤4,否则转到步骤3.2。
本发明进一步的改进在于,步骤3.3中,使用ε-贪婪法在当前q值输出中选择对应的动作a。
本发明进一步的改进在于,步骤3.8中,通过神经网络的梯度反向传播更新当前q网络的所有参数θ。
本发明进一步的改进在于,步骤3的具体过程如下:
4.1对于虚拟链路luw,首先排除reqbwl(luw)>bwl(lmn)的物理链路;其中,reqbwl(luw)为虚拟链路luw请求的带宽,bwl(lmn)为物理链路lmmn的剩余可用带宽;
4.2初始化计数变量count=0;
4.3对于连接两个终端节点uv,wv的虚拟链路luw,首先找到虚拟链路luw终端映射的物理节点ms,ns,然后寻找ms,ns间的最短路径ps;
4.4若ms,ns间的最短路径ps存在,则技术变量count++,继续执行步骤4.1-步骤4.3,直到技术变量count等于虚拟链路总数时执行步骤5,否则输出虚拟网络映射失败。
本发明进一步的改进在于,步骤4.3中,使用floyd算法寻找ms,ns间的最短路径ps。
与现有技术相比,本发明具有的有益效果:本发明通过马尔可夫决策过程(mdp模型)获取当前的vne环境,在每次映射开始时,第一个映射的节点被随机传送到某个物理节点,然后基于ddqn算法获得奖励值r,更新网络参数,然后移动到下一个状态st+1。本发明中使用的ddqn算法,它是一种将doubleq-learning引入到dqn,即将action的选择和评估解耦开的算法。ddqn中存在两个结构完全相同但是参数却不同的网络,用当前q网络中q值选择
附图说明
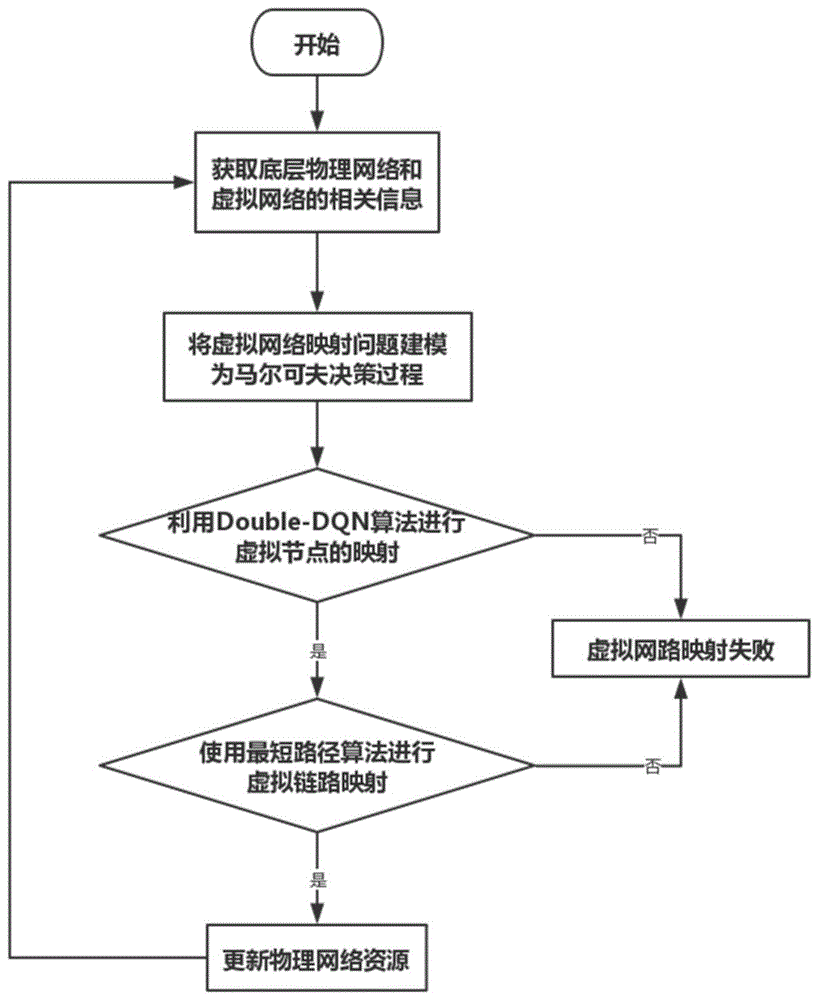
图1为本发明中所用ddqn算法的流程图。
具体实施方式
下面结合附图1和具体实施方式对本发明进行详细的描述。
本发明提出的一种sdn场景下基于深度强化学习的虚拟网络映射方法,具体包括以下步骤:
步骤1,获取底层物理网络和虚拟网络的相关信息:
衬底网络拓扑使用无向图表示:
虚拟网络同样使用加权无向图表示:
vne问题可描述为:m(gv):
步骤2,将虚拟网络映射中节点映射问题建模为马尔可夫决策过程:
2.1定义状态集合st
假设在给定状态st中,代理选择一个物理节点
其中
2.2定义动作集合at
代理选择节点
其中ε表示可以到达终端状态的任意动作。当代理选择当前虚拟节点
2.3定义状态转移概率矩阵pr
当处于状态st时,代理选择节点
2.4定义回报函数r
其中,j表示第j个样本,γ为衰减因子,q为当前q网络,q′为目标q网络,a′为在当前q网络中最大q值对应的动作。
步骤3,利用ddqn算法进行虚拟节点的映射;参见图1,具体如下:
3.1随机初始化所有状态和动作对应的价值q,随机初始化当前q网络(mainnet)的所有参数θ,初始化目标q网络(targetnet)的参数θ′=θ,清空经验回放集合d。
3.2初始化状态集合s为当前状态的第一个状态,得到状态集合s的特征向量,并用
3.3在mainnet中使用状态集合s的特征向量
3.4在状态s执行当前动作a,得到新状态s′,特征向量
3.5将
3.6令初始状态s=s′;
3.7从经验回放集合d中采集m个样本
3.8使用均方差损失函数
3.9重复步骤3.1-步骤3.8多次,如果重复次数达到目标网络的更新频率c,则更新目标网络参数θ′=θ。如果重复次数没有达到目标网络的更新频率c,则继续重复步骤3.1-步骤3.8。
3.10判断终止状态标志is_end是否为终止状态;如果终止状态标志is_end是终止状态,则进行步骤4,否则转到步骤3.2。
步骤4,利用最短路径算法进行虚拟网络链路映射:
4.1对于虚拟链路luw,首先排除reqbwl(luw)>bwl(lmn)的物理链路;其中,reqbwl(luw)为虚拟链路luw请求的带宽,bwl(lmn)为物理链路lmn的剩余可用带宽;
4.2初始化计数变量count=0;
4.3对于连接两个终端节点uv,wv的虚拟链路luw,首先找到虚拟链路luw终端映射的物理节点ms,ns,然后使用floyd算法寻找ms,ns间的最短路径ps。
4.4若ms,ns间的最短路径ps存在,则count++,继续执行步骤4.1-步骤4.3,直到count等于虚拟链路总数时执行步骤5,否则输出虚拟网络映射失败。
步骤5,更新物理网络资源,包括cpu资源和链路带宽资源。
本发明通过马尔可夫决策过程(mdp模型)获取当前的vne环境,例如物理网络的资源情况、链路连接状态以及虚拟网络的请求量。在每次映射开始时,第一个映射的节点被随机传送到某个物理节点,然后基于ddqn算法获得奖励值r,更新网络参数,然后移动到下一个状态st+1。
本发明中使用的ddqn算法,它是一种将doubleq-learning引入到dqn,即将action的选择和评估解耦开的算法。ddqn中存在两个结构完全相同但是参数却不同的网络,用当前q网络中q值选择
因为ddqn算法的核心思想是将目标动作的选择和目标动作的评估分别使用不同的值函数来实现,所以可以有效地解决过优估计问题。通过这种自适应学习方案,可以通过节约能耗和提高vnr接收率来获得全局最优的映射方法,比传统方法相比,有更好的灵活性。
该方法首先将将虚拟节点映射问题建模为马尔可夫决策过程,使用ddqn算法进行虚拟节点映射,最后使用最短路径算法完成虚拟链路的映射。实验表明,该方法能够降低能耗,提高请求接受率并提高长期平均收益。
- 还没有人留言评论。精彩留言会获得点赞!