一种变分自编码器与生成对抗网络结合的视频生成方法与流程
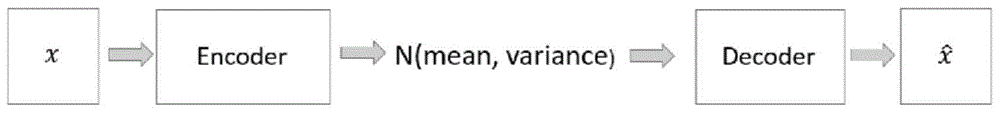
本发明属于视频生成技术领域,尤其涉及一种变分自编码器与生成对抗网络结合的视频生成方法。
背景技术:
近年来,随着人工智能技术在各行业的广泛应用,各行各业的生产力得到了很大提升,如在电视节目制作中,视频生成技术可以极大程度的减轻人力工作。业内,nvidia等公司提出了基于生成对抗网络的视频生成技术,以应对多种情形下的视频生成需求。然而,现有的视频生成方法在输入信息不足时往往出现生成的视频中帧与帧之间的时间连续性不足,图像变形等问题,从而降低了视频生成的质量。
diederikpkingma等于2013年提出变分自编码器,通过将样本映射到一个特定的正态分布,再从该正态分布中采样一个点以恢复样本的方法构建了一个隐空间连续性好的生成学习模型。iangoodfellow等于2014年提出生成对抗网络,以生成器生成样本,以判别器区分生成器生成的样本与真样本,二者以对抗的方式进行学习,构成动态的博弈,当最终达到纳什均衡时,判别器不能区分生成样本与真样本,此时生成样本也就被认为与真样本无差别了。
技术实现要素:
本发明的目的:提供一种变分自编码器与生成对抗网络结合的视频生成方法,利用变分自编码器对数据集中视频的每一帧进行学习,构建具有良好连续性的隐空间,隐空间中的每一点对应视频中的一帧。然后将噪声与文本输入生成对抗网络的生成器,生成器则生成潜变量空间中的多个相关联的点,然后将这些点通过变分自编码器的解码器生成多帧相关联连续图像,这些图像组成所要生成的视频。
为了实现上述目的,本发明的技术方案是:一种变分自编码器与生成对抗网络结合的视频生成方法,包括如下步骤:
(1)收集各种类的视频,并按照类别对每个视频做好文本描述;
(2)对步骤1收集的视频及文本描述做归一化处理,得到生成对抗网络训练过程中使用的“视频-文本”数据集;
(3)对步骤2归一化处理后的“视频-文本”数据集中的视频按帧分割,对分割得到的每一帧图像匹配其原所属视频的文本描述,得到变分自编码器训练过程中使用的“图像-文本”数据集;
(4)将步骤3得到的数据集中随机取出n个“图像-文本”样本输入变分自编码器进行训练。变分自编码器中编码器输出的隐空间维度为d,变分自编码器包括编码器encoder和解码器decoder,其中编码器encoder通过对输入的每一帧图像x计算均值meanx和方差variancex,将图像映射到专属于该图像的正态分布n(meanx,variancex),再从该分布随机中采样一个d维的隐变量,将该隐变量输入解码器decoder,decoder输出解码图像。同一类别的图像经过encoder编码后所对应的分布聚集在隐空间的同一均值meani附近,这个均值通过神经网络计算得到。
变分自编码器的损失函数:
其中,meanx、variancex分别是图像x经过编码器encoder得到的正态分布的均值和方差,meani是该图像所属类别均值,x为变分自编码器输出的重建图像。训练过程以最小化损失函数lvae为目标,设置每经过一定次数的迭代对decoder输出的解码图像进行人工检查,重复这一操作直到解码图像的质量达到要求,得到训练好的变分自编码器模型。
(5)从步骤2处理后的数据集中取出m个样本对,作为生成对抗网络训练中使用的真实样本对,取出所述m个样本对中的的描述文本,对这m个描述文本重新配上与描述不匹配的视频,得到m个不匹配样本对。再以这m个真实样本对中的描述文本作为输入描述文本,以步骤4训练好的变分自编码器模型与生成对抗网络结合,使用m个真实样本对,m个不匹配样本对及m个输入描述文本,输入生成对抗网络进行训练。
生成对抗网络包括生成器g和判别器d,生成的视频为l帧,其中生成器生成的是l个d维的变量delta1,delta2,...deltal,根据需要生成的视频类别加上对应类别的均值meani:
zk=meani+deltak,(k=1,2,...,l)
得到l个d维的变分自编码器的隐变量zk:z1,z2,...zl,将z1,z2,...zl输入到步骤4中已经训练好的变分自编码器的解码器decoder中得到长度为l帧的视频;
所述的生成器g的损失函数:
lg=-log(d(xgen,sgen))
其中,xreal是采样于真实视频数据分布的视频样本,sreal是对xreal的描述文本,(xreal,sreal)为所述真实样本对,(xmis,smis)为所述的真实样本对,sgen为输入生成器g的输入描述文本,xgen为生成器g生成的视频样本。
所述的判别器d的损失函数:
ld=-log(d(zreal,sreal))-log(1-d(zmis,smis)-log(1-d(zfake,sgen))
zreal,zmis,zfake分别是xreal,xmis,xgen经过变分自编码器的编码器encoder后得到的正态分布中随机采样出的隐变量。
生成对抗网络的训练过程分为生成器g的训练和判别器d的训练,生成器g的训练以最小化lg为目标,判别器d的训练以最小化ld为目标。训练过程中先训练判别器d,再训练生成器g,重复训练过程,对生成器生成的视频样本质量进行人工检查,直到生成的视频样本质量达到要求。
(6)将步骤5训练得到的网络中输入描述文本,生成视频。
进一步地,所述变分自编码器的编码器encoder由多层卷积神经网络构成,解码器decoder由多层反卷积神经网络构成。
进一步地,所述生成器g为生成变分自编码器隐变量的隐变量生成器。
进一步地,所述生成器g为循环神经网络:lstm(longshort-termmemory)。
进一步地,所述判别器d对变分自编码器隐变量进行判别。
本发明的有益效果在于:该发明的视频生成方法能够根据输入描述文本生成视频,克服生成视频中帧间连续性差的问题,相比于单独使用生成对抗网络,变分自编码器与生成对抗网络结合的视频生成方法提高了视频生成的帧间连续性,将训练步骤分为训练变分自编码器和以训练好的变分自编码器为基础训练生成对抗网络两个部分,使训练更容易以及更稳定。
附图说明
图1是所述变分自编码器结构示意图;
图2是本发明所述一种变分自编码器与生成对抗网络结合的视频生成方法结构示意图。
具体实施方式
以下结合附图1和附图2进一步说明本发明的实施例。
一种变分自编码器与生成对抗网络结合的视频生成方法,包括如下步骤:
(1)收集各种类的视频,并按照类别对每个视频做好文本描述;
(2)对步骤1收集的视频及文本描述做归一化处理,得到生成对抗网络训练过程中使用的“视频-文本”数据集;
(3)对步骤2预处理后的“视频-文本”数据集中的视频按帧分割,对分割得到的每一帧图像匹配其原所属视频的文本描述,得到变分自编码器训练过程中使用的“图像-文本”数据集;
(4)将步骤3得到的数据集中随机取出n个“图像-文本”样本输入变分自编码器进行训练。变分自编码器中编码器输出的隐空间维度为d,变分自编码器包括编码器encoder和解码器decoder,所述变分自编码器的编码器encoder由多层卷积神经网络构成,解码器decoder由多层反卷积神经网络构成。其中编码器encoder通过对输入的每一帧图像x计算均值meanx和方差variancex,将图像映射到专属于该图像的正态分布n(meanx,variancex),再从该分布随机中采样一个d维的隐变量,将该隐变量输入解码器decoder,decoder输出解码图像。同一类别i的图像经过encoder编码后所对应的分布聚集在隐空间的同一均值meani附近,这个均值通过神经网络计算得到,通过这个操作,在后续步骤中生成视频时,对于每一帧,如果该帧属于类别j,则可以在隐空间中meani的附近寻找该帧对应的隐变量。
变分自编码器的损失函数:
其中,meanx、variancex分别是图像x经过编码器encoder得到的正态分布的均值和方差,meani是该图像所属类别均值,x为变分自编码器输出的重建图像。训练过程以最小化lvae为目标,设置每经过一定次数的迭代对decoder输出的解码图像进行人工检查,重复这一操作直到解码图像的质量达到要求,得到训练好的变分自编码器模型。
(5)从步骤2处理后的数据集中取出m个样本对,作为生成对抗网络训练中使用的真实样本对,取出所述m个样本对中的的描述文本,对这m个描述文本重新配上与描述不匹配的视频,得到m个不匹配样本对。再以这m个真实样本对中的描述文本作为输入描述文本,以步骤4训练好的变分自编码器与生成对抗网络结合,使用m个真实样本对,m个不匹配样本对及m个输入描述文本,输入生成对抗网络进行训练。
生成对抗网络包括生成器g和判别器d,生成的视频为l帧,所述生成器g为生成变分自编码器隐变量的隐变量生成器,该生成器g为循环神经网络:lstm(longshort-termmemory)。所述判别器d对变分自编码器隐变量进行判别,首先,输入描述文本sgen通过lstm组成的生成器生成的是l个相关联的d维的变量delta1,delta2,...deltal,根据需要生成的视频类别加上对应类别的均值meani:
zk=meani+deltak,(k=1,2,...,l)
得到l个d维的变分自编码器的隐变量zk:z1,z2,...zl,将z1,z2,...zl输入到步骤4中已经训练好的变分自编码器的解码器decoder中得到长度为l帧的视频;
所述的生成器g的损失函数:
lg=-log(d(xgen,sgen))
其中,xreal是采样于真实视频数据分布的视频样本,sreal是对xreal的描述文本,(xreal,sreal)为所述真实样本对,(xmis,smis)为所述的真实样本对,sgen为输入生成器g的输入描述文本,xgen为生成器g生成的视频样本。
所述的判别器d的损失函数:
ld=-log(d(zreal,sreal))-log(1-d(zmis,smis)-log(1-d(zfake,sgen))
如图2所示,zreal,zmis,zfake分别是xreal,xmis,xgen经过变分自编码器的编码器encoder后得到的正态分布中随机采样出的隐变量。
生成对抗网络的训练过程分为生成器g的训练和判别器d的训练,生成器g的训练以最小化lg为目标,判别器d的训练以最小化ld为目标。训练过程中先训练判别器d,再训练生成器g,为一次迭代。训练过程中变分自编码器的编码器encoder和解码器decoder的参数不更新,只更新判别器d和生成器g的参数。设置每进行一定次数迭代,对生成器生成的视频样本质量进行人工检查,重复训练过程,直到生成的视频样本质量达到要求。
(6)将步骤5训练得到的网络中输入描述文本,生成视频。
实施例
步骤1,从mnist数据集中取出手写数字图片,取出的手写数字图片种类如果是“0,1,4,6,9”则对该数字形成一个16帧的48×48像素的视频,该数字在第一帧中以任意位置作为起点,在16帧中进行上下移动;取出的手写数字图片种类如果是“2,3,5,7,8”则对该数字形成一个16帧的48×48像素的视频,该数字在第一帧中以任意位置作为起点,在16帧中进行左右移动;对每个手写数字的移动视频做文本描述,如“thedigit0ismovingupanddown”、“thedigit2ismovingleftandright”,这样,得到10个类别的手写数字移动视频,每个类别的视频有相应的文本描述;
步骤2,对步骤1中得到的视频数据集及其文本描述进行预处理,得到生成对抗网络训练使用的“视频-文本”数据集;
步骤3,对步骤2中预处理后的视频数据集按帧分割,对分割得到的每一帧图像匹配一个其原所属视频的文本描述,共10个类别的手写数字图像,每个类别的手写数字图像有相应的文本描述,得到变分自编码器训练中使用的“图像-文本”数据集;
步骤4,从步骤3中得到的数据集中随机取出n个样本对输入图1所示的变分自编码器进行训练,变分自编码器中编码器输出的隐空间维度为d,根据需求,重复操作多次;
步骤5,从步骤2中处理后的数据集中取出m个“视频-文本”样本对,作为生成对抗网络训练中使用的真实样本对,取出这m个真实样本对中的的视频,对这m个视频重新配上与内容不匹配的描述文本,得到m个不匹配样本对,以这m个真实样本对中的描述文本作为输入描述文本。以生成对抗网络与步骤4训练后得到的变分自编码器结合,使用m个真实样本对,m个不匹配样本对及m个输入描述文本输入生成对抗网络进行训练。生成对抗网络与变分自编码器的结合方式如图2,其中,textgen是输入描述文本,latentvariablegenerator是隐变量生成器,textgen与从正态分布中随机采样的一个噪声noise一同输入隐变量生成器,encoder、decoder分别是是在步骤4中已训练好的变分自编码器中的编码器和解码器,
步骤6,对步骤5中训练得到的网络输入描述文本,得到生成视频。
结果表明,在24000个16帧48×48像素的手写数字移动视频数据集上设定batchsize大小为64,经500epoch的训练,网络能够针对输入文本生成接近训练数据集中的手写数字移动视频。
由上述实施例可知,该发明的视频生成方法能够根据输入描述文本生成视频,克服生成视频中帧间连续性差的问题,相比于单独使用生成对抗网络,变分自编码器与生成对抗网络结合的视频生成方法提高了视频生成的帧间连续性,将训练步骤分为训练变分自编码器和以训练好的变分自编码器为基础训练生成对抗网络两个部分,使训练更容易以及更稳定。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书内容所作的等效结构变换,或直接或间接运用附属在其他相关产品的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!