基于编码损伤修复CNN的空域可分级视频编码方法与流程
本发明属于视频图像编码领域,涉及一种空域可分级视频编码方法,具体涉及一种基于编码损伤修复cnn的空域可分级视频编码方法,可用于视频压缩编码后视频图像编码损伤的修复。
背景技术:
视频图像的编码是一种在传输视频过程中降低视频冗余数据的有效手段。视频图像编码出现了很多标准的算法,最新一代高效视频编码标准hevc作为目前最新的视频压缩标准取得了不错的效果,但同时也大大增加了编码复杂度。进一步为了满足不同用户终端对不同分辨率和不同帧率的需求,以及解决已出现的一些异构网络和不可靠网络等问题,标准化组织提出可分级高效视频编码shvc。
shvc是为了适应ip网络的异构、波动和拥塞而采用的一种高效、强鲁棒性的可分级性视频编码技术。该技术将一个基本层和若干增强层看成一个多层视频系统,对单一视频序列产生若干层高低有序的压缩码流。基本层提供基本图像质量的码流,增强层提供可在基础上重构出更高图像质量所需的码流,一般为更高质量图像与低质量图像的差值。shvc可通过利用单层高效视频编码的编解码器构建实现,并添加层间参考图像处理模块。
可分级高效视频编码shvc主要分为质量可分级编码和空域可分级编码。实现空域可分级性,首先通过编码器对视频序列中的每帧图像进行不同空间分辨率的编码,得到分辨率不同的多个视频流,即基本层和增强层码流,且具有高分辨率的增强层码流以具有低分辨率的基本层码流为层间参考。仅对基本层码流信息进行解码得到的是低分辨率图像,增强层码流为高质量视频图像与低质量视频图像的差值码流,如同时加入增强层码流进行解码,得到的是高分辨率的图像。
但是该方法由于视频压缩编码的缘故,在解码端接收到的基本层重建图像与基本层被重建图像相比具有编码损伤,表征为图像失真,在视觉上表现为方块效应、振铃效应以及其他由于人为操作给图像引入噪声导致的图像效果视觉失真,会间接导致增强层图像失真,进而导致增强层编码码率增加,既不利于解码端得到高清晰度的图像,也会增加编码负担与传输负担。
作为深度学习网络中的一种,卷积神经网络由于具有卷积层等结构,能够很好地提取图像特征,在保留图像细节的前提下完成图像修复和图像超分等功能。
例如申请公布号为cn110087092a,名称为“基于图像重构卷积神经网络的低码率视频编解码方法”的专利申请,提出了一种基于图像重构卷积神经网络的低码率视频编解码方法,该方法对输入视频通过下采样操作后得到低分辨率的视频,再使用标准x.265编解码器对低分辨率视频进行视频编解码,得到解码后的低分辨率视频,将解码后的低分辨率视频输入到训练好的图像重构卷积神经网络,然后得到与输入视频相同分辨率的重构视频。该方法解决了传统空域可分级视频编码方法中存在的在低码率下视频编解码后视频有严重压缩失真的问题,更好地保留图像细节。但其只针对低码率下视频编码带来的严重压缩失真问题,不能兼顾较高清晰度的高码率视频编码压缩失真问题,也不能有效降低高清晰度视频的传输码流大小。
技术实现要素:
本发明的目的在于克服上述现有技术存在的缺陷,提出了一种基于编码损伤修复cnn的空域可分级视频编码方法,用于解决现有空域可分级视频编码方法中存在的因基本层重建图像与增强层图像基于编码损伤的图像失真较大导致的增强层编码码率的较高的技术问题,以减轻网络传输的负担。
为实现上述目的,本发明采取的技术方案包括如下步骤:
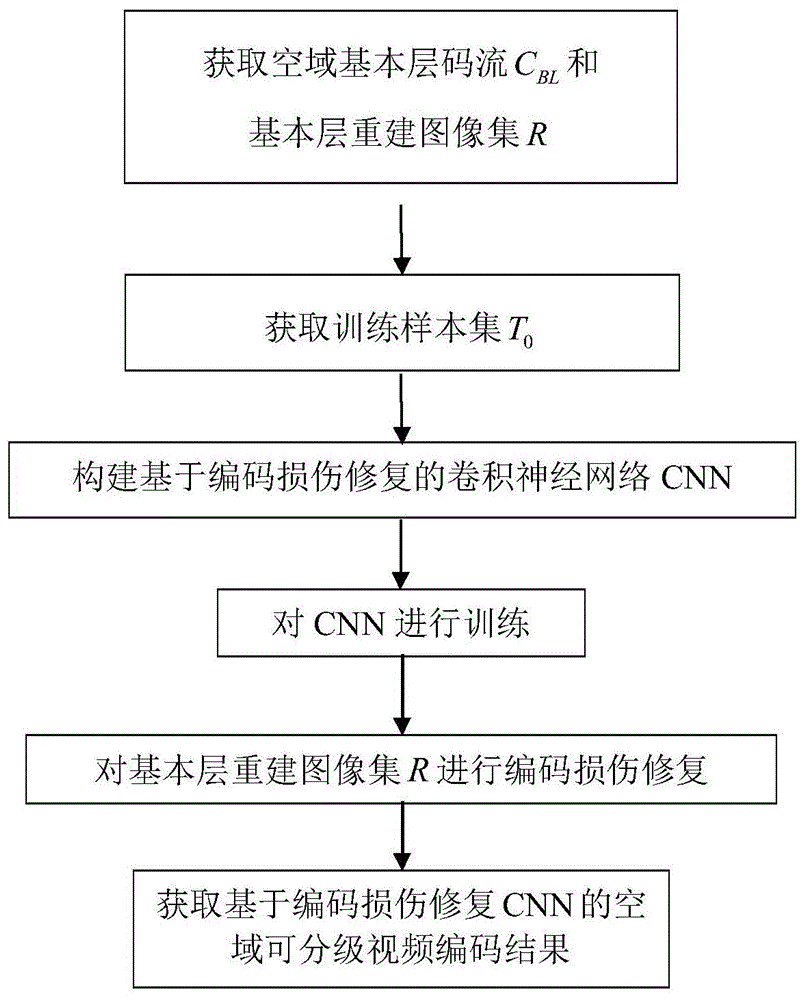
(1)获取空域基本层码流cbl和基本层重建图像集r:
(1a)随机选取的包括n帧图像的视频v,并对其中的每帧图像进行d倍下采样,得到包括n帧低分辨率图像的视频v',d>1;
(1b)对视频v'进行dct变换,并以q为量化参数qp对dct变换所获取的变换系数进行量化,得到量化后的变换系数n,1≤q≤51;
(1c)对变换系数n进行熵编码,得到空域基本层码流cbl,同时对变换系数n同时进行反量化,并对反量化的结果进行反dct变换,得到由n帧基本层重建图像组成的基本层重建图像集r;
(2)获取训练样本集t0:
(2a)选取像素大小为h×w的m幅自然图像,并将每幅图像裁剪为f个像素大小为l×l的大图像块,将所有大图像块作为标签图像数据sr_label,m≥400,h>l,w>l,
(2b)对每个大图像块进行d倍下采样,得到f个像素大小为l/d×l/d的小图像块,将所有小图像块作为标签图像数据lr_label;
(2c)获取重建图像数据input_lr:
(2c1)设量化参数qp的值为k,k的最小值为k0,最大值为km,并令k=k0,1≤k0≤q≤km≤51;
(2c2)对lr_label中的每个小图像块进行编码后再进行解码,得到f个重建图像,并判断k=km是否成立,若是,得到k个重建图像组input_lr,k=km-k0+1,并将lr_label、sr_label和input_lr作为训练样本集t0,否则,执行步骤(2c3);
(2c3)令k=k+1,并执行步骤(2c2);
(3)构建基于编码损伤修复的卷积神经网络cnn:
构建包括第一残差网络和第二残差网络的编码损伤修复的卷积神经网络cnn,其中:
第一残差网络包括第一主径结构、第一捷径结构和第二卷积层;第一主径结构包括依次层叠的第一卷积层、归一化层、relu激活层、多个block组合层;第一捷径结构包括第一直连通路;
第二残差网络包括并联的第二主径结构和第二捷径结构;第二主径结构包括多个block组合层和与其相连的第四卷积层;第二捷径结构包括依次层叠的第二反卷积层和第二直连通路;block组合层包括依次层叠的第三卷积层、归一化层和relu激活层;
第一主径结构包括两个连接,连接一连接第二主径结构,连接二连接第二卷积层;第一捷径结构连接第二捷径结构,第二卷积层连接第二捷径结构;第二主径结构连接输出端口,第二捷径结构连接输出接口;
(4)对cnn进行训练:
(4a)设迭代次数为t,最大迭代次数为t,t≥30,并令t=0;
(4b)首先对网络中所有卷积核的权值赋予初始值,将input_lr和lr_label作为第一残差网络的输入,将sr_label作为第二残差网络的输入,对cnn进行训练,并判断t=t是否成立,若是,得到cnn模型,否则,执行步骤(4c);
(4c)令t=t+1,并执行步骤(4b);
(5)对基本层重建图像集r进行编码损伤修复:
将基本层重建图像集r输入至cnn模型,对r中的n帧图像进行编码损伤修复,并将得到的n帧修复编码损伤后的图像组成增强层修复图像集r';
(6)获取基于编码损伤修复cnn的空域可分级视频编码结果:
(6a)将增强层修复图像集r'中的n帧图像与视频v中的n帧图像相减,得到由n个残差图像组成的残差图像集r'r;
(6b)对r'r进行dct变换,并以q为量化参数qp对dct变换所获得的变换系数进行量化,得到量化后的变换系数n';
(6c)对变换系数n'进行熵编码,获取空域增强层码流cel,得到由cel与空域基本层码流cbl组成空域可分级视频编码的输出码流,作为空域可分级视频编码的结果。
本发明与现有技术相比,具有如下优点:通过在传统空域可分级编码方法中将预设定的插值滤波器用本发明中提出的基于编码损伤修复cnn取代,起到了对基本层重建图像编码损伤的修复和改善增强层图像质量的作用,与现有技术相比,解决了因基本层重建图像与增强层图像的图像质量较低而导致的增强层编码码率较高的技术问题,以减轻网络传输的负担。
附图说明
图1是本发明的实现示意图;
图2是本发明采用的基于编码损伤修复的卷积神经网络cnn的结构图;
图3(a)是一幅基本层重建图像;
图3(b)是利用卷积神经网络cnn模型处理图3(a)得到的增强层参考图像。
具体实施方式
以下结合附图和具体实施例,对本发明作进一步详细描述。
参照图1,本发明包括如下步骤:
步骤1)获取空域基本层码流cbl和基本层重建图像集r:
步骤1a)根据itu-t视频编码专家组提供的hevc测试序列,选取的包括48帧图像的视频basketballdrive_1920x1080,并对其中的每帧图像进行2倍下采样,得到包括48帧低分辨率图像的视频basketballdrive_960x540;
步骤1b)对视频basketballdrive_960x540进行dct变换,根据jctvc-q1009文档提供的测试qp值,选取22为量化参数qp对dct变换所获取的变换系数进行量化,得到量化后的变换系数n;
步骤1c)对变换系数n进行熵编码,得到空域基本层码流cbl,同时对变换系数n同时进行反量化,并对反量化的结果进行反dct变换,得到由48帧基本层重建图像组成的基本层重建图像集r;
步骤2)获取训练样本集t0:
步骤2a)选取bsd500数据集中的全部图像共500幅,该数据集涵盖自然图像纹理较丰富,且含数据量足够,能够训练卷积神经网络cnn学到足够的图像特征信息;将bsd500数据集中的每幅图像裁剪为共19200个像素大小为84×84的大图像块,将所有大图像块作为标签图像数据sr_label;由于小图像块的像素大小设置为42×42,比卷积神经网络的网络感受野像素大小41×41稍大,而小图像块将由大图像块进行2倍下采样得到,故将大图像块的像素大小设置为84×84;
步骤2b)与步骤1a)中的下采样操作保持一致,对每个大图像块进行2倍下采样,得到19200个像素大小为42×42的小图像块,将所有小图像块作为标签图像数据lr_label;
步骤2c)获取重建图像数据input_lr:
步骤2c1)设量化参数qp的值为k,为了将重建图像集r的qp值包含于训练数据的qp值范围内,选定k的最小值为19,最大值为23,并令k=19;
步骤2c2)对lr_label中的每个小图像块进行编码后再进行解码,得到19200个重建图像,并判断k=23是否成立,若是,得到5个重建图像组input_lr,并将lr_label、sr_label和input_lr作为训练样本集t0,否则,执行步骤(2c3);
步骤2c3)令k=k+1,并执行步骤(2c2);
步骤3)如图2所示结构构建基于编码损伤修复的卷积神经网络cnn,其中1为第一残差网络,11为第一卷积层,12为归一化层,13为relu激活层,14为block组合层,15为第二卷积层,16为第二直连通路,17为求和运算,2为第二残差网络,21为第一反卷积层,22为第二反卷积层,23为第四卷积层,24为block组合层,25为第二直连通路,26为求和运算;
由于残差网络结构在图像去噪方面效果显著,故为了解决视频编码给视频图像引入的噪声,降低图像失真,构建该卷积神经网络cnn的结构时采用了残差网络结构,即构建包括第一残差网络和第二残差网络的编码损伤修复的卷积神经网络cnn,用以修复编码损伤,其中:
第一残差网络主要起对图像编码损伤的修复功能,包括第一主径结构、第一捷径结构和第二卷积层;归一化实质是一种线性变换,对数据分布不会造成实质性的改变,反而能提高数据的表现,故设计第一主径结构包括依次层叠的第一卷积层、归一化层、relu激活层、多个block组合层;第一捷径结构包括第一直连通路;
第二残差网络主要对修复编码损伤后的图像进行图像超分,其结构包括并联的第二主径结构和第二捷径结构;第二主径结构包括多个block组合层和与其相连的第四卷积层;第二捷径结构包括依次层叠的第二反卷积层和第二直连通路;block组合层包括依次层叠的第三卷积层、归一化层和relu激活层;
第一主径结构包括两个连接,连接一连接第二主径结构,连接二连接第二卷积层;第一捷径结构连接第二捷径结构,第二卷积层连接第二捷径结构,且第一捷径结构与第二卷积层在接入第二捷径结构前进行求和运算;第二主径结构连接输出端口,第二捷径结构连接输出接口,且第二主径结构与第二捷径结构在接入输出前进行求和运算;
步骤4)yuv颜色编码将亮度信息y与色度信息u和v分离,利用人眼对亮度的敏感超过色度的特征,将图像特征集中在y分量,对cnn进行训练时仅对视频图像的y分量进行训练:
步骤4a)设迭代次数为t,最大迭代次数为t,在本实例下,t=30的时候网络收敛,故取t=30,并令t=0;
步骤4b)首先对网络中所有卷积核的权值赋予初始值,将input_lr和lr_label作为第一残差网络的输入,将sr_label作为第二残差网络的输入,对cnn进行训练,并判断t=t是否成立,若是,得到cnn模型,否则,执行步骤(4c);
步骤4c)令t=t+1,并执行步骤(4b);
步骤5)对基本层重建图像集r进行编码损伤修复:
将基本层重建图像集r输入至cnn模型,对r中的48帧图像进行编码损伤修复,并将得到的48帧修复编码损伤后的图像组成增强层修复图像集r';
步骤6)获取基于编码损伤修复cnn的空域可分级视频编码结果:
步骤6a)由于增强层码流一般为高质量图像编码码流与低质量图像编码码流的差值,故将增强层修复图像集r'中的48帧图像与视频basketballdrive中的48帧图像相减,得到由48个残差图像组成的残差图像集r'r;
步骤6b)对r'r进行dct变换,并以22为量化参数qp对dct变换所获得的变换系数进行量化,得到量化后的变换系数n';
步骤6c)对变换系数n'进行熵编码,获取空域增强层码流cel,得到由cel与空域基本层码流cbl组成空域可分级视频编码的输出码流,作为基于编码损伤修复cnn的空域可分级视频编码的结果。
卷积神经网络cnn结构:
第一残差网络的第一主径结构为:第一层卷积层→归一化层→relu层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层
第一残差网络的第一捷径结构为:第一直连通路;
第二残差网络的第二主径结构为:第一反卷积层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→block组合层→第四反卷积层;
第二残差网络的第二捷径结构为:第二反卷积层→第二直连通路;
考虑到在不影响网络感受野的情况下降低网络参数数量,cnn结构中的参数设置为:
第一卷积层的卷积核大小设置为3,输入通道数为1,输出通道数为64,采用填充补零;
第二卷积层的卷积核大小设置为3,输入通道数为64,输出通道数为1;
第三卷积层的卷积核大小设置为3,输入通道数为64,输出通道数为64;
第四卷积层的卷积核大小设置为3,输入通道数为64,输出通道数为1;
第一反卷积层的卷积核大小设置为3,输入通道数为64,输出通道数为64;
第二反卷积层的卷积核大小设置为3,输入通道数为1,输出通道数为1;
第一直连通路:连接第一残差网络的输入和第二卷基层的输出;
第二直连通路:连接第二反卷积层的输出与第三卷积层的输出。
以下结合测试,对本发明的效果作进一步的描述。
1.测试条件:
本发明的测试是在主频3.60ghz的inteli7-7280cpu、nvidiageforce2080tigpu的硬件环境和shvc软件测试平台shm12.0的软件环境下进行的。在本发明中,采用的测试序列为itu-t视频编码专家组提供的hevc测试序列中b类的basketballdrive,根据jctvc-q1009文档提供的测试内容,qp值取22,测试条件为randomaccess和allintra两种,增强层与基本层的qp值差为0,上采样率为2x,其余配置参数均取默认值。
2.测试内容及结果分析:
采用本设计和现有的空域可分级视频编码方法对视频编码的效果和码率进行测试,其图像处理结果如图3所示,图3(a)表示进行重建操作后的basketballdrive_960x540视频中提取的第2帧图像,即像素大小为960×540的基本层低清重建图像,该图像经过卷积神经网络cnn处理,得到图3(b)表示的与图3(a)相对应的像素大小1920×1080的增强层高清图像,图3(b)块效应等图像失真明显减弱,部分图像纹理得到恢复,且图像纹理较为平滑。
视频编码图像目前通常采用psnr值作为客观评价指标,本实例中psnr值包括第一残差网络输出的图像与未重建图像的峰值信噪比,和输入的重建图像与未重建图像的峰值信噪比。psnr值越高说明图像质量越相近,解码后图像的质量越高。经测量,psnr值均有一定程度的提升,表征了客观上图像质量的提升,同时测得码率均有一定程度的下降。
测试结果表明:本发明的方法较传统空域可分级编码,显著地改善了编码损伤导致的图片失真,主观和客观上均提升了图像质量,进一步降低了输出码流,说明相比于现有编码方法中人工设置的上采样插值滤波器,改进后的方法在实现相同功能的情况下在主观及客观评价指标上均改善了视频图像质量,进一步可降低传输码流以节省传输开支。
- 还没有人留言评论。精彩留言会获得点赞!