一种基于接收信号强度的层次分类室内定位方法与流程
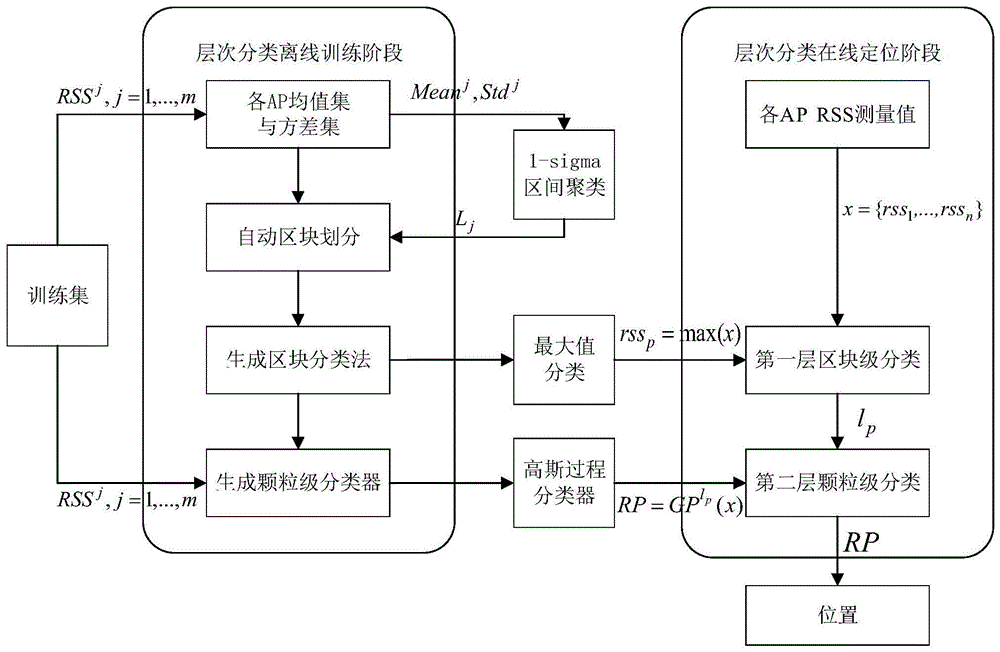
本发明涉及一种基于接收信号强度的层次分类室内定位方法,属于室内定位技术领域。
背景技术:
基于指纹的方法也是解决室内定位问题的主流策略(liz,liuj,niux,lil,wangz,chenr.abayesiandensitymodelbasedradiosignalfingerprintingpositioningmethodforenhancedusability.sensors2018,18(11):40-63.)。接收信号强度rss(recvedsignalstrength)指纹定位分为采集所有可能目标位置上rss数据建立rss指纹库的离线,与目标体的当前rss与指纹库匹配的在线阶段。该方法规避了回归定位中对wifi接入点ap数目和位置的限制,因此基于指纹的定位可以进一步降低室内定位的成本。指纹方法仅关注特征空间中各类别边界,使其鲁棒性较回归方法更具有优势。
本质上,指纹定位是一种基于rss数据的分类过程,使用rss数据库对可能的目标位置确定类别标签,建立分类机制,在线阶段利用该分类机制判别信号类别,确定信号位置。但是在稀疏节点条件下,信号源较少使得可用特征数难以实现简单分类,并且由于室内环境中因为存在多径效应(
指纹定位中,层次分类方法通过多个分类器结合寻找类别边界的方式提高了分类器的泛化能力,获得了研究人员的广泛关注,例如ahmad(ahmad,uzair.amodularclassificationmodelforreceivedsignalstrengthbasedlocationsystems.neurocomputing2008,71(13-15):2657-2669.)和noelia(noeliahernández,jmalonso,manuel
一般的聚类方法或者多数决定原则虽然解决了分区问题,但是一般聚类方法可能将不相邻的rp聚为一类,可视化时容易造成混淆;而多数决定原则是一种阈值判断方法,这种硬决策方法在rss波动频繁(比如常有人员走动的室内)的区域鲁棒性不佳。
现有的层次定位方法中,分区是一种硬决策行为,如果第一层分类不准确,将影响最终的定位精度。
技术实现要素:
为了解决上述至少一个问题,本发明提供了一种计算量小、运行时间短、准确率高,达到97.6%以上的稀疏节点下的基于接收信号强度的层次分类室内定位方法,可以解决稀疏节点情况下的低硬件成本,低数据率约束等定位问题。而且给出了适用于低计算性能的移动终端的房间级快速定位方法,使用已安装好的wifiap作为唯一信号源。
本发明的第一个目的是提供一种稀疏节点下的基于接收信号强度的层次分类室内定位方法,包括两个部分,第一部分是定位模型的建立,第二部分是利用模型对未知信号进行定位。
在一种实施方式中,所述的定位模型的建立包括以下步骤:
步骤1:采集所有参考点rp的信号;
步骤2:根据各个参考点rp计算1-sigma区间;
步骤3:根据1-sigma区间进行区块划分,得到区块级分类器;
步骤4:在各个区块内训练高斯过程分类器,即颗粒级分类器。
在一种实施方式中,所述的步骤1为:
使用手机或者平板电脑,根据wifiap的mac地址,确认采集信号来自哪个wifiap;然后确定参考点rp,在每个参考点上站立停留,使用手机或者平板电脑收集来自各个wifi的rss信号,每个位置采集50次以上,标注这些rss信号采集自哪个rp;当所有rp的rss信号均采集完毕,保存rss信号,作为rss数据库。
在一种实施方式中,所述的步骤2具体为:
采集各个参考点(rp)上各个wifi节点(ap)的接收信号强度(rss)值,构成均值集与方差集,记为
均值集
其中
h指代第几次采样,在连加里面变回从1加到k;
对于参考点rpj,wifi节点api的1-sigma的区间为:
在一种实施方式中,所述的步骤3为:
将整个环境中的n个wifiap划分成n份,每个ap对应一个类别;从第一个参考点rp开始,计算每个rp接收到n个ap的rss信号的n个1-sigma区间;对于任一rp的n个1-sigma区域,首先确定均值最大的1-sigma区间,然后到与这个其余(n-1)个1-sigma中与均值最大1-sigma区间相交的1-sigma区间,记录这些区间对应的ap,将该rp聚类至这些ap对应的类别;当所有rp聚类结束,则完成区域划分。
在一种实施方式中,所述的步骤3具体为:
拟使用每个ap信号的最强覆盖物理空间区域作为抽象的区块类别,因此区块类别数与ap数相同,定义区块的类别为l={li|i=1,2,...,n},其中n为ap个数,ap个数就是类别个数。1-sigma区间聚类方法各个参考点rp的上最强的ap作为特征,聚类至相应的区块l。
rpj的所有采样可以用以ap的rss形式表达,假设rssj={rssj1,...,rssjn}中,则
rpj中可能出现的一种情况是:aps(s=(1,2,...,s≠i)(s为ap标号)的rssjs的均值略小于最强api的均值,即
综上,基于1-sigma区间聚类思想,给定rpj进行区块聚类的流程如下:
输入:meanj,stdj,l;
输出:rpj的聚类类别lj;
step1
step2将li放入lj;
step3计算api的1-sigma区间下界
step4fors=(1,2,...,n),s≠i,计算aps的1-sigma区间上界
step5if
step6endfor;
step7退出。
在一种实施方式中,step4中的满足step5条件aps的个数可能大于1,表明rpj聚类至多个类别,因此lj中存在多个区块类别。如果有多个ap的1-sigma区间下界满足条件,输出类别应与ap一一对应。
在一种实施方式中,所述的步骤4具体为:
使用matlab中的gpml工具箱应用高斯过程机器学习算法实现分类,在使用过程中选择高斯核作为高斯过程的核函数,通过调整核函数的超参数拟合数据的分布情况,实现分类;使用时将rss信号出入该程序,自动计算出分类结果。
在一种实施方式中,所述利用模型对未知信号进行定位具体如下:
步骤(1)新接收了一个未知其位置的rss信号;
步骤(2)将其信号输入区块级分类器,确定该设备位于哪个区块;
步骤(3)将其信号输入对应的区块内的高斯过程分类器,得到确切位置。
在一种实施方式中,所述的步骤(2)为:
假设未知位置来自n个ap的单次测量rss为x=(rss1,rss2,...,rssn),首先找到最大的rss值rssp=max(x),则认为该移动设备位于区块lp;p为标号,指代x=(rss1,rss2,...,rssn)最大值的下标。
在一种实施方式中,所述的步骤(3)为:
颗粒级分类使用步骤(2)得到的lp内已训练好的高斯过程分类器进行分类。高斯过程分类器通过拟合隐函数并将隐函数的输出经由sigmoid函数压缩至[0,1]得到类别概率,概率高的一方为二分类结果;假设给定lp中有c(c泛指一个数字)个rp,则根据“一对一”方法训练的c(c-1)/2个二分类器结果中频数最高的分类结果为第二层分类的结果,从而得到目标位置。
在一种实施方式中,由于rss的波动性,可能出现同一位置不同时刻最大rss值来自不同ap的情况,应用1-sigma区间类别划分后无论将该数据分类至哪个ap对应的类别均不影响分类结果,仅依靠最大值即可完成第一层分类。
本发明的第二个目的是本发明所述的稀疏节点下的基于接收信号强度的层次分类室内定位方法在室内导航中的应用。
在一种实施方式中,本发明的方法可以实时给出设备所处位置,根据设备当前位置与目的地位置可以计算出路径,实现导航。
本发明的第三个目的是本发明所述的稀疏节点下的基于接收信号强度的层次分类室内定位方法在室内安防中的应用。
在一种实施方式中,本发明的方法可以实时监测设备位置,如果设备位置距离禁区过近,发起警报。
本发明的第四个目的是本发明所述的稀疏节点下的基于接收信号强度的层次分类室内定位方法在室内搜救中的应用。
在一种实施方式中,本发明的方法可以实时监测设备位置,例如在养老院中某个老人不在自己房间,但是没有离开养老院,通过设备定位可以确定老人位置,实现搜救。
本发明的有益效果:
(1)针对稀疏节点情况下的低硬件成本、低数据率约束等定位问题,本发明给出了适用于低计算性能的移动终端的房间级快速定位方法;使用已安装好的wifiap作为唯一信号源。
(2)本发明提出一种基于层次分类的室内定位方法,首先给出了1-sigma区间判别机制,将整个平面楼层空间划分成若干存在交叉数学的区块域;进一步以高斯过程分类,实现以房间为颗粒元素的室内定位,可以解决人员流通造成的信号强度不稳定,从而导致定位不准确的问题。本发明所提方法在浙江某医疗养护中心进行实地测试,通过与支持向量机(svm)、决策树、k近邻(knearestneighbor,knn)方法相比所提方法在准确率、平均误差和标准误差等方面表现更佳,平均误差达到80.8以下,标准误差达到81.1以下,误差方差达到7.7以下,准确率达到97.6%以上,稳定性仅低于svm(误差方差为4.6)。
附图说明
图1为基于接收信号强度的层次分类室内定位模型图。
图2为实验场景平面图及信号采集位置图。
图3为实验场景各房间1-sigma区间示意图。
图4为rp4处重叠信号rss分布图。
图5为rp6处重叠信号rss分布图。
图6为rp9处重叠信号rss分布图。
具体实施方式
以下对本发明的优选实施例进行说明,应当理解实施例是为了更好地解释本发明,不用于限制本发明。
实施例1
一种稀疏节点下的基于接收信号强度的层次分类室内定位方法,包括以下步骤:
第一部分:定位模型的建立,具体包括以下步骤:
步骤1:使用手机或者平板电脑,根据wifiap的mac地址,确认采集信号来自哪个wifiap;然后确定参考点rp,在每个参考点上站立停留,使用手机或者平板电脑收集来自各个wifi的rss信号,每个位置采集50次以上,标注这些rss信号采集自哪个rp;当所有rp的rss信号均采集完毕,保存rss信号,作为rss数据库。
步骤2:采集各个参考点(rp)上各个wifi节点(ap)的接收信号强度(rss)值,构成均值集与方差集,记为均值集
h指代第几次采样,在连加里面变回从1加到k;
对于参考点rpj,wifi节点api的1-sigma的区间为:
步骤3:拟使用每个ap信号的最强覆盖物理空间区域作为抽象的区块类别,因此区块类别数与ap数相同,定义区块的类别为l={li|i=1,2,...,n},其中n为ap个数,ap个数就是类别个数。1-sigma区间聚类方法各个参考点rp的上最强的ap作为特征,聚类至相应的区块l。
rpj的所有采样可以用以ap的rss形式表达,假设rssj={rssj1,...,rssjn}中,则
rpj中可能出现的一种情况是:aps(s=(1,2,...,n),s≠i)(s为ap标号)的rssjs的均值略小于最强api的均值,即
综上,基于1-sigma区间聚类思想,给定rpj进行区块聚类的流程如下:
输入:meanj,stdj,l;
输出:rpj的聚类类别lj;
step1
step2将li放入lj;
step3计算api的1-sigma区间下界
step4fors=(1,2,...,n),s≠i,计算aps的1-sigma区间上界
step5if
step6endfor;
step7退出。
其中,step4中的满足step5条件aps的个数可能大于1,表明rpj聚类至多个类别,因此lj中存在多个区块类别。如果有多个ap的1-sigma区间下界满足条件,输出类别应与ap一一对应。
步骤4:使用matlab中的gpml工具箱应用高斯过程机器学习算法实现分类,在使用过程中选择高斯核作为高斯过程的核函数,通过调整核函数的超参数拟合数据的分布情况,实现分类;使用时将rss信号出入该程序,自动计算出分类结果。
第二部分:利用模型对未知信号进行定位,具体包括以下步骤:
步骤(1):新接收了一个未知其位置的rss信号;
步骤(2):假设未知位置来自n个ap的单次测量rss为x=(rss1,rss2,...,rssn),首先找到最大的rss值rssp=max(x),则认为该移动设备位于区块lp;p为标号,指代x=(rss1,rss2,...,rssn)最大值的下标。
步骤(3):颗粒级分类使用步骤(2)得到的lp内已训练好的高斯过程分类器进行分类。高斯过程分类器通过拟合隐函数并将隐函数的输出经由sigmoid函数压缩至[0,1]得到类别概率,概率高的一方为二分类结果;假设给定lp中有c(c泛指一个数字)个rp,则根据“一对一”方法训练的c(c-1)/2个二分类器结果中频数最高的分类结果为第二层分类的结果,从而得到目标位置。
实施例2:实施例1的方法在养老院中的应用
图1为基于接收信号强度的层次分类室内定位模型图,以养老院为例进行定位:
在浙江省某个典型的稀疏节点室内环境中进行实验,定位精度为房间级。如图2,实验场景呈36m×26.8m矩形,其中已安装4个wifiap,以a、b、c、d编号区分;病房即为rp,以编号1~10区分。实验中,使用平板电脑采集wifirss信号,单个房间内选择人员活动频繁的床位和中间走道位置作为采样点,总共设置55个采样点,每个rp内设置5至6个采样点,3号房间与10号客厅位置考虑其面积与结构因素仅设置3个采样点,总共采集5500个数据,由于楼层中间部分为电梯井与应急通道,基于墙体固件以及项目需求原因,不进行采样分配。平板电脑的wi-fi信号检测范围是[-1dbm,-95dbm],对于ap未覆盖采样点的缺失信号以-100dbm插入。
图3中使用误差棒图画出每个rp位置各个ap的1-sigma区间,误差棒的中点为各aprss均值,长度为1-sigma区间,分别使用不同的符号代表apa、apb、apc和apd的1-sigma区间。
从图4可以看出:深灰色是rp4位置接收到apa的信号强度频数,白色是rp4位置接收到apb的信号强度频数,浅灰色代表rp4位置apa与apb的接收信号强度重叠部分。
从图5可以看出:深灰色是rp6位置接收到apb的信号强度频数,白色是rp6位置接收到apc的信号强度频数,浅灰色代表rp6位置apb与apc的接收信号强度重叠部分。
从图6可以看出:深灰色是rp9位置接收到apc的信号强度频数,白色是rp9位置接收到apd的信号强度频数,浅灰色代表rp9位置apc与apd的接收信号强度重叠部分。
如图4、5和6所示:rp4、rp6与rp9的最大均值ap1-sigma区间与其他ap1-sigma相交,根据本发明的方法将它们被聚类至多个类别:rp4同时属于la和lb,rp6同时属于lb和lc,rp9同时属于lc和ld。
图4-6使用直方图画出rp4、rp6、rp9的两个最强覆盖aprss重叠情况,这些最强覆盖ap的rss测量值分布高度重合,难以区分。因此,根据1-sigma区间聚类将整个楼层划分成为4个区块,其中la={rp2,rp3,rp4},lb={rp4,rp5,rp6},lc={rp6,rp7,rp8,rp9},ld={rp1,rp9,rp10}。
由于一个房间内存在多个采样点,为了防止数据不平衡造成过拟合,实验中随机从所有采样点中选取40%的数据作为训练集,剩下的60%数据作为测试集验证提出方法。作为对比也使用svm、knn和决策树直接进行分类实现定位。
svm,knn与决策树都是机器学习分类算法,常用于室内定位中。实验中我们在matlab的分类工具箱上应用这些分类算法,通过调整svm算法的核函数与超参数选择,knn算法的k参数,决策树算法的树最大深度参数得到最优的分类结果,给出定位结果,并将结果与本发明进行对比。
为了排除偶然情况,实验重复10次,每次选择不同的数据作为训练集和测试集。从表1中可以看到:实施例2的方法平均误差和标准误差比其他方法降低了25%至50%,方差略高于svm,准确率高于其他比较方法。实施例2的方法使用层次分类的方法提高了分类器的学习能力与泛化能力,因此平均误差与标准误差较其他方法有所降低,从而也提高了定位的准确率。而在误差方差方面,svm进行分类时仅考虑支持向量的最大间隔,因此受训练集变化的影响较小,分类结果更稳定。综合来看,实施例2的方法在保证定位准确率的同时保持了一定的定位稳定性。svm更适合对定位稳定性要求高的场景,knn与决策树则因为操作简单更适合计算复杂度要求高的场景。
表1四种算法性能比较
虽然本发明已以较佳实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可做各种的改动与修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!