基于照片视频的时空体积捕捉系统的制作方法
基于照片视频的时空体积捕捉系统
1.相关申请的交叉引用
2.本技术依据35u.s.c.
§
119(e)要求2018年12月20日提交的题为“time efficient video
‑
based face and body capture system for albedo
‑
ready virtual human digitization,3d cg modeling and natural reenactment”的序列号为62/782,862的美国临时专利申请的优先权,将其整个内容通过引用结合在本文中。
技术领域
3.本发明涉及用于娱乐产业的三维计算机视觉和图形。更具体地,本发明涉及获取和处理用于电影、电视、音乐和游戏内容创建的三维计算机视觉和图形。
背景技术:
4.在电影/电视产业中,真人演员是生产成本的主要部分。此外,当使用实物演员时,由于伤害/事故有生产延迟的风险,并且有用于旅行的复杂的后勤和协调的需求。最近的趋势示出,用于虚拟制作的数字化的人类演员的使用越来越多。数字演员可以使人类不可能的超级英雄动作成为可能,而无需将真实的演员置于危险的特技动作中。然而,这种视觉特效(vfx)是高成本且费时的,其只有高预算的续集电影或电视节目才能负担得起。
5.在游戏产业中,对逼真的玩游戏的用户体验的追求在继续。在过去的10年中,游戏制作成本已经增加了10倍。在2020年,平均的aaa游戏的制作成本估计将达到2.5亿美元,与电影预算相似。逼真的玩游戏的用户体验的最大挑战是去在合理的时间/成本预算内创建逼真的游戏角色。虚拟人类创建是高度手动的,并且费时且昂贵。例如,每个角色的成本为8
‑
15万美元,并且对于多个角色,成本加起来容易达到数百万美元。
6.最近的趋势是通过多视点相机3d/4d扫描仪高效地创建逼真的数字人类模型,而不是从头开始手工制作cg艺术品。世界各地都有各种3d扫描仪工作室(3lateral、avatta、ten24、pixel light effect、eisko)和4d扫描仪工作室(4dviews、microsoft、8i、dgene)用于基于相机捕获的人类数字化。
7.基于照片的3d扫描仪工作室由高分辨率摄影相机(photography camera)的多阵列组成。通常需要手动cg用于动画,因为其无法捕获自然表面动力学。基于视频的4d扫描仪(4d=3d+时间)工作室由高帧率机器视觉相机的多阵列组成。它捕捉自然表面动力学,但是由于摄像机(video camera)的分辨率,其保真度有限。
技术实现要素:
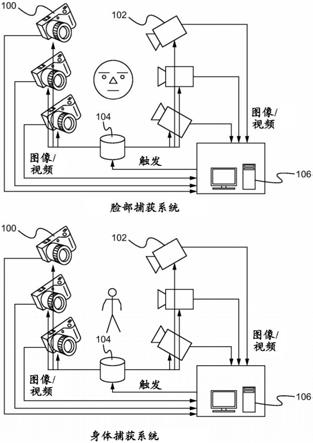
8.基于照片视频的时空体积捕获系统通过从时域稀疏的一组高分辨率3d扫描关键帧对4d扫描视频数据的分辨率时域上采样而不是在初始化时的单个静态模板模型(例如,a或t姿势),更高效地产生高帧率和高分辨率4d动态人类视频,而无需2个单独的3d和4d扫描仪系统,并且减少对于手动cg工作的需求,所述3d扫描关键帧以较低的帧率来捕获人类动力学。另外,通过利用触发,视频获取被优化以致通常以高帧率捕获低分辨率多视点视频,
但是以较低的帧率同时捕获高分辨率多视点摄影相机与视频。关键帧定义为使用以较低的帧率同时触发的摄影相机和摄像机两者重构的高分辨率3d扫描模型。
9.在一方面,方法包含使用一个或多个摄影相机和一个或多个摄像机捕获内容,用设备触发一个或多个摄影相机和一个或多个摄像机以获取一个或多个关键帧,并使用该设备基于捕获的内容和一个或多个关键帧生成一个或多个模型。捕获内容包括捕获脸部表情和/或身体动作。触发包括利用触发定时以同时生成针对一个或多个摄影相机和一个或多个摄像机的触发。一个或多个摄影相机的触发定时包括周期性触发。一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部和/或身体表情。一个或多个摄影相机的触发定时包括由设备、一个或多个摄影相机和/或一个或多个摄像机自动检测特定的脸部或身体表情。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,高分辨率3d扫描模板通过一个或多个摄影相机和一个或多个摄像机两者来捕获。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率,4d扫描体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置(collocated)在高和低分辨率uv纹理对之间。方法还包含使用包括脸部表情和身体动作的内容和一个或多个模型来生成计算机图形,其中生成计算机图形包括利用内容的关键帧和用于在关键帧之间过渡的内容的非关键帧。
10.在另一方面,设备包含用于存储应用的非暂时性存储器,该应用用于:实现触发以获取一个或多个关键帧,其中触发信号被发送到一个或多个摄影相机和一个或多个摄像机,以及基于一个或多个关键帧和从一个或多个摄影相机和一个或多个摄像机捕获的内容生成一个或多个模型,以及耦合到存储器的处理器,该处理器被配置用于处理应用。触发包括利用触发定时来同时生成针对一个或多个摄影相机和一个或多个摄像机的触发。一个或多个摄影相机的触发定时包括周期性触发。一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部和/或身体表情。一个或多个摄影相机的触发定时包括由设备、一个或多个摄影相机和/或一个或多个摄像机自动检测特定的脸部或身体表情。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,高分辨率3d扫描模板通过一个或多个摄影相机和一个或多个摄像机两者来捕获。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的3d体积序列上的基于机器学习的时域纹理超分辨率,基于视频的3d体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置在高分辨率和低分辨率uv纹理对之间。应用还被配置为使用包括脸部表情和身体动作的内容和一个或多个模型来生成计算机图形,其中生成计算机图形包括利用内容的关键帧和用于在关键帧之间过渡的内容的非关键帧。
11.在另一方面,系统包含:第一组设备,其被配置为捕获对象的图像内容;第二组设备,其被配置为捕获对象的视频内容;以及计算设备,被配置为:实现触发以获取基于图像内容和视频内容的一个或多个关键帧,并基于图像内容和视频内容以及一个或多个关键帧生成一个或多个模型。捕获内容包括捕获脸部表情和/或身体动作。触发包括利用触发定时来同时生成针对一个或多个摄影相机和一个或多个摄像机的触发。一个或多个摄影相机的触发定时包括周期性触发。一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部和/或身体表情。一个或多个摄影相机的触发定时包括通过计算设备、第一组设备和/或第二组设备自动地检测特定的脸部或身体表情。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,高分辨率3d扫描模板通过一个或多个摄影相机和一个或多个摄像机两者来捕获。使用一个或多个模型来实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率,4d扫描体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置在高和低分辨率uv纹理对之间。计算设备还被配置为用于使用包括脸部表情和身体动作的图像内容和视频内容和一个或多个模型来生成计算机图形,其中生成计算机图形包括利用内容的关键帧和用于在关键帧之间过渡的内容的非关键帧。
附图说明
12.图1图示了根据一些实施例的脸部捕捉系统和身体捕捉系统的图。
13.图2图示了根据一些实施例的触发机制的图。
14.图3图示了根据一些实施例的网格跟踪的图。
15.图4图示了根据一些实施例的基于网格跟踪的时域形状超分辨率的图。
16.图5图示了根据一些实施例的基于机器学习的纹理超分辨率的图。
17.图6图示了根据一些实施例的实现时间高效的基于视频的帧率捕获系统的方法的流程图。
18.图7图示了根据一些实施例的示例性计算设备的框图,该示例性计算设备被配置为实现基于照片视频的时空体积捕获系统。
具体实施方式
19.需要时间高效但如照片般真实的3d脸部和身体捕捉系统。如前所述,一个问题是费时的基于照片图像的3d捕获系统以及由此导致的建模和动画管线(pipeline)。对于每个脸部表情(或身体姿势),对象通常在以下各种条件下的扫掠中保持静止:例如,跨相机、跨各种光方向以及迫使对象的脸部/身体表情不自然。对象针对各种脸部表情或身体姿势重复此操作(例如,>10)。现有技术的脸部捕捉光阶段通常需要每个脸部表情约20分钟的捕捉时间。一旦捕获所有数据,则cg动画制作者清理,重新网格化每个表情的静态模型,并创建基于facs(脸部动作编码系统)的动态可动画模型用于动画。由于表情之间的过渡不被3d扫
描仪捕获,cg动画制作者通常手动地手工制作细节表面动力学,并且这个工作流程常常需要数月的时间。4d扫描仪经常用作用于动画制作者的参考,但由于基于机器视觉视频的4d扫描仪的有限分辨率,通常无法在facs建模管线中使用。
20.图1图示了根据一些实施例的脸部捕捉系统和身体捕捉系统的图。一个或多个摄影相机100获取图像。一个或多个摄影相机100能够是多视点、高分辨率(例如,4200万像素)摄影相机(例如,dslr相机),但是帧率通常有限(例如,2fps)。一个或多个摄像机120获取视频信息。一个或多个摄像机能够是多视点高帧率机器视觉摄像机(例如,60fps),但是分辨率是有限的(例如,8百万像素)。例如,一个或多个摄影相机100和一个或多个摄像机102获取人的图像和视频,其中该视频包括各种脸部表情和身体移动。
21.触发机制104被实现为同时产生针对摄影相机和视频(机器视觉)相机的触发。触发机制104能够以任何方式来实现,例如实现为存储在一个或多个摄影相机100、一个或多个摄像机102和/或一个或多个计算设备106中的应用。在一些实施例中,在触发机制104由一个或多个计算设备106控制的情况下,触发机制104同时将触发发送到多视点摄影相机100和摄像机102,而摄像机则保持更高的触发率(例如,对于摄影相机2fps,对于摄像机60fps)。
22.在一些实施例中,关键帧被定义为当同时触发摄影相机和摄像机两者时的帧,并且因此,高分辨率3d模板模型被重构。其他帧被定义为当仅触发较低分辨率的摄像机时的非关键帧,并且因此,使用较高分辨率的3d模板关键帧对重构的4d模型上采样。
23.摄影相机的触发定时包括3个用例:1)周期性(例如,2fps):对在较高分辨率3d扫描关键帧之间的基于视频的较低分辨率4d扫描体积序列(例如,60fps)上采样,2)半自动:当人类观察者检测到某些脸部或身体表情时,3)自动:当由计算设备、一个或多个摄影相机和/或一个或多个摄像机(例如,使用模板匹配或任何其他检测表情的机制)检测到特定脸部或身体表情时。
24.一个或多个计算设备106初始化捕获过程并从一个或多个摄影相机100和一个或多个摄像机102中获取一系列图像/视频。图像/视频信息在一个或多个计算设备106处被接收和/或被发射到一个或多个计算设备106,其中处理视频信息。例如,一个或多个计算设备106处理视频信息并生成cg内容(例如,执行建模)。
25.使用多个高分辨率3d扫描模板关键帧模型,该系统能够实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率(上采样),以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d模板来细化,高分辨率3d模板通过摄影相机100和摄像机102两者来捕获。该系统还能够实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率(上采样),4d扫描体积序列通过训练在多个关键帧处同时触发和捕获的高分辨率和低分辨率uv纹理对(高分辨率纹理来自多视点摄影相机100并且低分辨率纹理来自多视点摄像机102)来细化。
26.图2图示了根据一些实施例的触发机制的图。如上所述,关键帧200是当同时触发摄影相机和摄像机时,并且因此,重构高分辨率3d模板模型。非关键帧202是当仅触发较低分辨率的摄像机时,并且因此,对重构的4d模型上采样用于细化。非关键帧包括较低分辨率的体积序列,旨在通过应用以下方法来使用关键帧被时域上采样:1)基于网格跟踪的时域
形状超分辨率,以及2)基于机器学习的时域纹理超分辨率。
27.在关键帧处重构高分辨率3d模板模型。使用多视点摄影相机和机器视觉相机,较高分辨率形状重构是可能的。高分辨率和低分辨率uv纹理对被用作用于基于机器学习的纹理超分辨率的训练数据集。
28.摄影相机的触发定时包括以下3个用例:
29.周期性(例如,2fps):用于对关键帧之间的基于视频的低分辨率体积序列(例如,60fps)上采样;
30.半自动:当人类观察者检测到某些脸部或身体表情时;
31.自动:当检测到特定的脸部或身体表情时。
32.图3图示了根据一些实施例的网格跟踪的图。网格跟踪涉及及时一致地注册网格拓扑。
33.图4图示了根据一些实施例的基于网格跟踪的时域形状超分辨率的图。
34.图4的左侧示出了基于单个模板的表现捕获。没有细节表面动力学的鲁棒上采样。有3d和4d扫描的两个单独的阶段。
35.图4的右侧示出了基于多关键帧的形状超分辨率,其鲁棒地适应细节表面动力学。在序列中4d扫描仪与多个3d模板结合在一起。
36.图5图示了根据一些实施例的基于机器学习的纹理超分辨率的图。
37.图5的左侧示出了基于单个模板的表现捕获。有来自基于跟踪网格的单个模板的恒定的纹理。
38.图5的右侧示出了基于机器学习的纹理超分辨率,其适应纹理变化,并在序列中使用多个关键帧纹理训练数据集。
39.图6图示了根据一些实施例的实现基于照片视频的时空体积捕获系统的方法的流程图。在步骤600中,使用一个或多个摄像机和一个或多个摄影相机捕获包括脸部表情和身体动作的内容(例如,图像/视频内容)。在步骤602中,实现触发以获取一个或多个关键帧。触发包括同时生成针对摄影相机和摄像机的触发。摄影相机的触发定时包括3个用例:1)周期性(例如,2fps):使用较高分辨率3d模板模型对关键帧之间的较低分辨率的基于视频的4d扫描体积序列(例如60fps)上采样,2)半自动:当人类观察者检测到某些脸部或身体表情时,3)自动:当由计算设备检测到特定的脸部或身体表情时(例如,使用模板匹配、机器学习和/或用于检测表情的任何其他机制)。在步骤604,使用所获取的视频来生成内容。例如,使用所获取的内容,cg化身能够被部署在电影或其他视频中。生成内容能够包括生成多个高分辨率模板模型。使用多个高分辨率模板模型,系统能够实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率(上采样),以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列在多个关键帧处通过使用高分辨率模板来细化,高分辨率模板通过摄影相机和摄像机两者来捕获。该系统还能够实现:在基于低分辨率但高帧率的视频的体积序列上的基于机器学习的时域纹理超分辨率(上采样),体积序列通过训练在多个关键帧处同时触发和捕获的高分辨率和低分辨率uv纹理对来细化(高分辨率纹理来自多视点摄影相机并且低分辨率纹理来自多视点摄像机)。在一些实施例中,实现更少或额外的步骤。在一些实施例中,步骤的顺序被修改。
40.图7图示了根据一些实施例的示例性计算设备的框图,该示例性计算设备被配置
为实现基于照片视频的时空体积捕获系统。计算设备700能够用于获取、存储、计算、处理、通信和/或显示诸如包括3d内容的图像和视频的信息。计算设备700能够实现任何时间高效的基于视频的帧率捕获系统方面。一般而言,适合于实现计算设备700的硬件结构包括网络接口702、存储器704、处理器706、i/o设备708、总线710和存储设备712。处理器的选择不是至关重要的,只要选择具有足够的速度的合适的处理器。存储器704能够是本领域中已知的任何传统计算机存储器。存储设备712能够包括硬盘驱动器、cdrom、cdrw、dvd、dvdrw、高清光盘/驱动器、超hd驱动器、闪存卡或任何其他存储设备。计算设备700能够包括一个或多个网络接口702。网络接口的示例包括连接至以太网或其他类型的lan的网卡。(一个或多个)i/o设备708能够包括以下一个或多个:键盘、鼠标、监视器、屏幕、打印机、调制解调器、触摸屏、按钮接口和其他设备。用于实现基于照片视频的时空体积捕获系统的(一个或多个)基于照片视频的时空体积捕获应用730可能存储在存储设备712和存储器704中,并且如应用通常被处理那样被处理。图7中示出的更多或更少的组件能够被包括在计算设备700中。在一些实施例中,包括基于照片视频的时空体积捕获硬件720。尽管图7中的计算设备700包括用于基于照片视频的时空体积捕获系统的应用730和硬件720,但是基于照片视频的时空体积捕获系统能够以硬件、固件、软件或其任何组合在计算设备上实现。例如,在一些实施例中,基于照片视频的时空体积捕获应用730在存储器中被编程并且使用处理器来执行。在另一个示例中,在一些实施例中,基于照片视频的时空体积捕获硬件720是被编程的硬件逻辑,包括专门设计以实现基于照片视频的时空体积捕获系统的门。
41.在一些实施例中,(一个或多个)基于照片视频的时空体积捕获应用730包括多个应用和/或模块。在一些实施例中,模块也包括一个或多个子模块。在一些实施例中,能够包括更少或额外的模块。
42.在一些实施例中,基于照片视频的时空体积捕获硬件720包括相机部件,例如镜头、图像传感器和/或任何其他相机部件。
43.合适的计算设备的例子包括个人计算机、膝上型计算机、计算机工作站、服务器、主机计算机、手持计算机、个人数字助理、蜂窝/移动电话、智能电器、游戏控制台、数码相机、数码摄录组合相机、照相电话、智能电话、便携式音乐播放器、平板电脑、移动设备、视频播放器、视频光盘刻录机/播放器(例如,dvd刻录机/播放机、高清光盘刻录机/播放器、超高清光盘刻录机/播放器)、电视、家庭娱乐系统、增强现实设备、虚拟现实设备、智能珠宝(例如,智能手表)、车辆(例如,无人驾驶车辆)或任何其他合适的计算设备。
44.为了利用本文描述的基于照片视频的时空体积捕获系统,设备使用针对捕获图像和视频内容的触发来获取视频内容。基于照片视频的时空体积捕获系统能够在用户协助下实现,或者自动实现而无需用户参与。能够利用任何数量的相机来实现基于照片视频的时空体积系统。
45.在操作中,基于照片视频的时空体积捕获系统通过同时获取摄影图像和视频以及通过从使用摄影相机和摄像机两者重构的较高分辨率3d扫描关键帧模板模型对较低分辨率4d扫描视频上采样,来创建高帧率以及高分辨率4d扫描人类动态体积视频。基于照片视频的时空体积捕获系统在序列内生成多个高分辨率模板模型,以用于离线形状和纹理超分辨率。使用多个关键帧高分辨率模板模型,该系统允许:基于网格跟踪的时域形状超分辨率,用以恢复在长动作序列内的高分辨率表面动力学。典型的表现捕获系统具有从单个模
板(例如,a姿势)恢复表面动力学(例如,衣服(outfit))的有限能力。本文所述的系统能够提供用于训练的高分辨率和低分辨率uv纹理对的多个关键帧数据集。
46.用于动态4d人类脸部和身体数字化的基于照片视频的时空体积捕获系统的一些实施例
47.1.一种方法,包括:
48.使用一个或多个摄影相机和一个或多个摄像机捕获内容;
49.用设备触发所述一个或多个摄影相机和所述一个或多个摄像机以获取一个或多个关键帧;和
50.用所述设备基于所捕获的内容和所述一个或多个关键帧生成一个或多个模型。
51.2.根据条款1所述的方法,其中捕获内容包括捕获脸部表情和/或身体动作。
52.3.根据条款1所述的方法,其中,触发包括利用触发定时来同时生成针对所述一个或多个摄影相机和所述一个或多个摄像机的触发。
53.4.根据条款3所述的方法,其中所述一个或多个摄影相机的触发定时包括周期性触发。
54.5.根据条款3所述的方法,其中所述一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部表情和/或身体表情。
55.6.根据条款3所述的方法,其中所述一个或多个摄影相机的触发定时包括由所述设备、所述一个或多个摄影相机和/或所述一个或多个摄像机自动地检测特定脸部表情或身体表情。
56.7.根据条款1所述的方法,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,3d扫描高分辨率模板通过所述一个或多个摄影相机和所述一个或多个摄像机两者来捕获。
57.8.根据条款1所述的方法,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率,4d扫描体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置在高分辨率和低分辨率uv纹理对之间。
58.9.根据条款1所述的方法,还包括:使用包括所述脸部表情和身体动作的所述内容和所述一个或多个模型来生成计算机图形,其中生成所述计算机图形包括利用所述内容的关键帧和用于在所述关键帧之间过渡的所述内容的非关键帧。
59.10.一种装置,包含:
60.非暂时性存储器,用于存储应用,所述应用用于:
61.实现获取一个或多个关键帧的触发,其中触发信号被发送到一个或多个摄影相机和一个或多个摄像机;和
62.基于所述一个或多个关键帧和从所述一个或多个摄影相机和所述一个或多个摄像机捕获的内容来生成一个或多个模型;和
63.耦合到所述存储器的处理器,所述处理器被配置用于处理所述应用。
64.11.根据条款10所述的装置,其中触发包括利用触发定时来同时生成针对所述一个或多个摄影相机和所述一个或多个摄像机的触发。
65.12.根据条款11所述的装置,其中所述一个或多个摄影相机的触发定时包括周期性触发。
66.13.根据条款11所述的装置,其中所述一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部表情和/或身体表情。
67.14.根据条款11所述的装置,其中所述一个或多个摄影相机的触发定时包括由所述装置、所述一个或多个摄影相机和/或所述一个或多个摄像机自动检测特定的脸部表情或身体表情。
68.15.根据条款10所述的装置,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,高分辨率3d扫描模板通过所述一个或多个摄影相机和所述一个或多个摄像机两者来捕获。
69.16.根据条款10所述的装置,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率,4d扫描体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置在高分辨率和低分辨率uv纹理对之间。
70.17.根据条款10所述的装置,其中所述应用进一步被配置为用于使用包括所述脸部表情和身体动作的所述内容和所述一个或多个模型来生成计算机图形,其中生成所述计算机图形包括利用所述内容的关键帧和用于在所述关键帧之间过渡的所述内容的非关键帧。
71.18.一种系统,包括:
72.第一组设备,其被配置为捕获对象的图像内容;
73.第二组设备,其被配置为捕获所述对象的视频内容;和
74.计算设备,其被配置为:
75.实现用于基于所述图像内容和所述视频内容获取一个或多个关键帧的触发;和
76.基于所述图像内容和所述视频内容以及所述一个或多个关键帧生成一个或多个模型。
77.19.根据条款18所述的系统,其中捕获内容包括捕获脸部表情和/或身体动作。
78.20.根据条款18所述的系统,其中触发包括利用触发定时来同时生成针对一个或多个摄影相机和一个或多个摄像机的触发。
79.21.根据条款20所述的系统,其中所述一个或多个摄影相机的触发定时包括周期性触发。
80.22.根据条款20所述的系统,其中所述一个或多个摄影相机的触发定时包括利用人类观察者来检测特定的脸部表情和/或身体表情。
81.23.根据条款20所述的系统,其中所述一个或多个摄影相机的触发定时包括由所述计算设备、所述第一组设备和/或所述第二组设备自动地检测特定的脸部表情或身体表情。
82.24.根据条款18所述的系统,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于网格跟踪的时域形状超分辨率,以用于恢复在长动作序列内的高分辨率表面动力学,4d扫描体积序列通过在多个关键帧处使用高分辨率3d扫描模板来细化,高分辨率3d扫描模板通过所述一个或多个摄影相机和所述一个或多个摄像机两者来捕获。
83.25.根据条款18所述的系统,其中所述一个或多个模型用于实现:在基于低分辨率但高帧率的视频的4d扫描体积序列上的基于机器学习的时域纹理超分辨率,4d扫描体积序列通过训练在多个关键帧处的高分辨率和低分辨率uv纹理对来细化,在每个关键帧处,使用摄影相机的图像数据来生成高分辨率uv纹理映射图,而使用摄像机的图像数据来生成低分辨率uv纹理映射图,并且为了更高的训练效率使用相同的网格拓扑以致纹理并置在高分辨率和低分辨率uv纹理对之间。
84.26.根据条款18所述的系统,其中所述计算设备还被配置为使用包括脸部表情和身体动作的所述图像内容和所述视频内容以及所述一个或多个模型来生成计算机图形,其中生成计算机图形包括利用所述内容的关键帧和用于在所述关键帧之间过渡的所述内容的非关键帧。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1