一种基于数据挖掘算法的Snort改进方法与流程
本发明属于信息安全技术领域,涉及一种基于数据挖掘算法的snort改进方法。
背景技术:
随着网络的迅速发展,“互联网+”模式得到了广泛应用。与此同时,网络入侵技术也在发展,互联网和信息通信网络的安全形势更加严峻,产生的蓄意攻击和破坏造成的影响更加广泛。面对复杂多样的攻击手段,传统的数据库安全机制显得有些乏力。而入侵检测是新一代的安全防卫技术,idssnort是一种网络入侵检测系统(networkintrusiondetectionsystem.nids),在业内具有很重要的地位,特别是在国内安全行业,其所用的规则语法更是被作为业界标准;snort是一个易于扩展的开源nids,使用灵活,占用资源少,但是在入侵检测方面功能很强大,它能够实时的进行网络数据流量的分析,并且通过其检测引擎模块检测各种入侵或攻击;snort不仅支持多种硬件平台,而且能够在windows、linux等多种操作系统上安装运行;此外,snort自身已经定义了一些动态加载的检测规则,并且用户可自行移除或添加规则而无须更改核心程序。综合这些优点,snort成为了目前主流的且最受欢迎的ids,在入侵检测技术竞争中占据优势。但是snort在入侵检测技术方面采用的是传统的规则匹配模式,在当前的大数据环境下,此模式匹配效率限制了snort的检测能力。而聚类算法的出现很好的解决了对大量信息有效管理困难的问题,本文引入最常用的聚类算法——kmeans算法对snort的核心模块——检测引擎模块进行改进。但kmeans算法由于其初始聚类中心k的随机性,导致其聚类结果不准确,一直被人们所诟病。故针对kmeans算法核心问题进行改进,使其更好的提高idssnort的检测效率。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于数据挖掘算法的snort改进方法,在该方法中,针对包含一个将改进的kmeans算法与入侵检测技术相结合后对snort进行改进的方法,实现snort在检测效率和准确率上有明显提高,使入侵检测技术更进一步,信息安全更加可靠。
为达到上述目的,本发明提供如下技术方案:
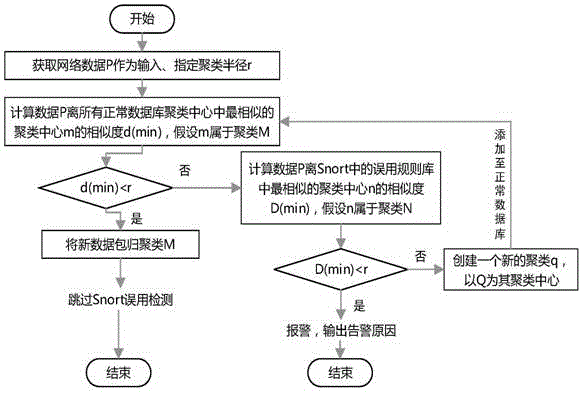
一种基于数据挖掘算法的snort改进方法,该方法为:针对snort系统的入侵检测模式,经过各个模块的聚类结果,分析数据是否正常,获得高效率,高准确率的snort,该方法具体步骤为:
步骤一:snort系统获取网络上的数据p并指定聚类半径r;
步骤二:利用改进k-means算法将p与正常行为数据库进行相似性聚类,判断聚类结果;
步骤三:根据聚类结果判断是否跳过snort误用检测;
步骤四:进入snort误用检测的检测的数据利用改进k-means算法将数据与规则库进行相似性聚类,判断聚类结果;
步骤五:根据结果输出异常报警,或正常数据添加至正常行为数据库后更新数据库聚类结果。
进一步的,步骤一中所述snort系统获取网络上的数据p并指定聚类半径r。利用snort网络嗅探器在网络上获取数据的同时,将正常数据库中的数据利用改进的k-means算法根据聚类半径r进行聚类。
进一步的,所述的改进k-means算法。利用k近邻非参概率密度算法与传统kmeans聚类算法相结合,同时去除离群点,得出聚类准确率高的改进的k-means算法,具体步骤如下:
(1)对于空间数据集x={x1,...xi,...xn}内的任一点,通过k近邻非参概率密度估计样本的密度,得出点的概率密度估计值,所需公式如下(4),(5)所示:
其中di是k近邻距离,xt为xi邻近的t个点的集合;
(2)将概率密度估计值进行从大到小排序,取n*0.9点的值作为阈值,低于阈值的点作为离群点,则x内密度最大的点c1即为首个聚类中心;
(3)计算每个样本与首个聚类中心c1的距离,用d1(x)表示;接着利用下列公式计算每个样本(离群点除外)被选为下一个聚类中心的概率qi;最后,用轮盘法思想选择出第二个聚类中心;
(4)重复进行(3)步骤,即计算每个样本到被选出的聚类中心的最短距离d(x),再计算qi,一个一个选择聚类中心,直到得到k个聚类中心;
(5):计算样本xi到各聚类中心c的欧式距离,将每个样本聚类至与其最近的聚类中心cj,形成k个聚类;
(6)重新计算k个聚类的平均聚类中心,以新的平均聚类中心替换原来的聚类中心;
(7)反复进行(5)(6)步骤,直到聚类中心c基本无变化或达到指定迭代次数后结束。
进一步的,步骤二中所述利用改进k-means算法将p与正常行为数据库进行相似性聚类,判断聚类结果。利用改进的k-means算法将网络数据p与正常数据库各类进行相似性聚类,当与任一聚类中心m的聚类相似度d(min)小于等于指定的聚类半径r时,即
进一步的,步骤三中所述根据聚类结果判断是否跳过snort误用检测。当
进一步的,步骤四中所述进入snort误用检测的数据利用改进k-means算法将数据与规则库进行相似性聚类,判断聚类结果。当
进一步的,步骤五中所述根据结果输出异常报警,或正常数据添加至正常行为数据库后更新数据库聚类结果。当
进一步的,所述将数据p添加至正常行为数据库后更新数据库聚类结果。当
本发明的优点及有益效果如下:
1、本发明通过在入侵检测系统snort内加入聚类算法,通过多次使用聚类算法来提高snort的检测效率即检测准确率,能够保证在当前大数据且网络环境复杂的情况下,即减少丢包率的同时又提高了准确率。
2、本发明改进的k-means算法,根据最优聚类中心的特性,把点的密度当作挑选依据很具有说服力;其次,避免了初选k个聚类中心选定的不稳定性;最后,排除了密度最小的10%个离群点作为聚类中心的可能,保证算法结果与理想聚类中心相近,大大的提高了聚类的准确性。
3、本发明的全程步骤都使用了聚类算法的改进,特别是在与正常数据库及异常数据库的相似性对比方面,正常数据库的对比可以是snort的误用引擎减少绝大多数正常数据的检测,提高了检测效率,与异常数据库的对比,在聚类算法的作用下降低误报率和漏报率。最终提高了入侵检测系统的性能。
附图说明
图1是本发明提供优选实施例流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
在本实施例中,一种基于数据挖掘算法的snort改进方法是按如下步骤进行的。
步骤一:snort系统获取网络上的数据p并指定聚类半径r
利用snort网络嗅探器在网络上获取数据的同时,将正常数据库中的数据利用改进的k-means算法根据聚类半径r进行聚类。
其中改进k-means算法。利用k近邻非参概率密度算法与传统kmeans聚类算法相结合,同时去除离群点,得出聚类准确率高的改进的k-means算法,具体步骤如下:
(1)对于空间数据集x={x1,...xi,...xn}内的任一点,通过k近邻非参概率密度估计样本的密度,得出点的概率密度估计值,所需公式如下(7),(8)所示:
其中di是k近邻距离,xt为xi邻近的t个点的集合;
(2)将概率密度估计值进行从大到小排序,取n*0.9点的值作为阈值,低于阈值的点作为离群点,则x内密度最大的点c1即为首个聚类中心;
(3)计算每个样本与首个聚类中心c1的距离,用d1(x)表示;接着利用下列公式计算每个样本(离群点除外)被选为下一个聚类中心的概率qi;最后,用轮盘法思想选择出第二个聚类中心;
(4)重复进行(3)步骤,即计算每个样本到被选出的聚类中心的最短距离d(x),再计算qi,一个一个选择聚类中心,直到得到k个聚类中心;
(5):计算样本xi到各聚类中心c的欧式距离,将每个样本聚类至与其最近的聚类中心cj,形成k个聚类;
(6)重新计算k个聚类的平均聚类中心,以新的平均聚类中心替换原来的聚类中心;
(7)反复进行(5)(6)步骤,直到聚类中心c基本无变化或达到指定迭代次数后结束。
步骤二:利用改进k-means算法将p与正常行为数据库进行相似性聚类,判断聚类结果
利用改进的k-means算法将网络数据p与正常数据库各类进行相似性聚类,当与任一聚类中心m的聚类相似度d(min)小于等于指定的聚类半径r时,即
步骤三:根据聚类结果判断是否跳过snort误用检测
当
步骤四:进入snort误用检测的数据利用改进k-means算法将数据与规则库进行相似性聚类,判断聚类结果
当
步骤五:根据结果输出异常报警,或正常数据添加至正常行为数据库后更新数据库聚类结果
当
当
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!