一种远程声场实时虚拟重现的方法与装置与流程
本发明涉及3d虚拟声技术领域,具体涉及一种远程声场实时虚拟重现的方法与装置。
背景技术:
随着基于移动终端(例如手机、平板)的互联网时代的发展,远程实时3d直播成为大众喜爱的娱乐、学习以及交际的方式。视听信息的交互协调是远程实时3d直播的关键,是用户现场感和沉浸感的重要决定因素。目前,相比于视觉信息的远程实时传输,听觉信息远程实时传输的成熟度和效果都有待提升,主要体现在虚拟声的个性化重放和声场动态调整两个方面。
为了充分涵盖现场的所有声信息,目前主流采用传声器阵列实施多通路捡拾。由于移动用户端主要采用双通路耳机进行声重放,因此需要采用虚拟声技术将多通路捡拾声信号转变为双耳声信号。头相关传输函数(hrtf)是虚拟声技术的核心,它反映了人体的生理结构(例如耳廓、头部、肩部、躯干等)对入射声波的反射及衍射作用。不同用户的生理结构在细节形态和尺寸等方面存在差异,因此它们对声波的作用也存在个体差异。这意味着,hrtf因人而异,是一个具有个性化的参量。现有研究表明,相较于个性化hrtf,采用非个性化hrtf(如通用hrtf)进行虚拟声信号处理,将出现定位精度下降(特别是仰角方向)、前后混乱增多等现象,破坏用户的沉浸感。然而,无论是通过测量还是计算的途径获取个性化hrtf都需要特定的场所或设备,因此现有虚拟声产品中普遍使用通用hrtf进行虚拟声信号处理。
虚拟声技术采用头坐标系统,以听者的头中心为坐标原点。如果希望远程用户获得“身临其境”的现场声感受,就需要根据用户头部的位置实时动态地调整双耳虚拟声信号。然而,现有的主流系统主要还是采用静态重放,即假设在观看直播过程中用户的头保持不动。这主要是受限于两个方面:1)头部跟踪设备比较昂贵,尚未成为移动终端的标配;2)网络传输速度有限。动态虚拟重放的数据量远大于静态虚拟重放;如果强行实施动态重放,将出现声滞后以及视听不匹配等现象。
上述不足制约了远程声场实时虚拟重现技术的发展和相关产品性能的进一步提高。
技术实现要素:
基于移动终端、云处理技术(含神经网络)以及5g网络的发展,本发明为解决上述不足,提供了一种远程声场实时虚拟重现的方法与装置,涉及三维空间虚拟声的个性化定制方法和一种远程声场的动态自适应调整技术。本发明采用端对端的卷积神经网络,由用户耳部图像推知个性化的仰角定位因素,并以此为依据对通用hrtf实施进行个性化定制(即频移),进一步将定制的个性化hrtf应用于双耳虚拟声信号的合成;此外,利用移动终端的外设进行用户头部位置的实时检测,实现跟踪头部位置的动态双耳虚拟声信号的重放。上述hrtf个性化定制和实时动态的虚拟声处理方法可以增强用户的现场感和沉浸感。
本发明的目的通过以下技术方案实现。
一种远程声场实时虚拟重现的方法,其特征是,包括如下步骤:
步骤1、用户将自身的耳部图像上传至云服务器的神经网络模型,获取用户hrtf的特征谷曲线;
步骤2、以特征谷曲线为依据,对通用hrtf进行个性化定制,得到用户的个性化hrtf数据;
步骤3、对远程声场进行实时的多通路声捡拾并将捡拾信号上传至云服务器;
步骤4、将捡拾信号和用户个性化hrtf数据进行卷积和叠加运算,生成多个空间位置的双耳虚拟声信号;
步骤5、根据用户端实时检测并上传的用户头部空间位置,调取相应空间位置的双耳虚拟声信号,发送至用户端的耳机设备进行声重放。
步骤6、按照一定的时间采样间隔,重复步骤3到步骤5,直至远程声场直播结束。
进一步地,步骤1中所述的处于云服务器的神经网络模型已事先训练好,训练步骤包括:
步骤101、选取一个已知的完备hrtf数据库,它包含m名受试者的全空间hrtf数据和受试者的耳部图像;
步骤102:对于其中一个受试者m(m=1,2,…,m),采用头中心坐标系,选取受试者中垂面上沿仰角
步骤103:拟合仰角
步骤104:对hrtf数据库中的每个受试者实施步骤102和步骤103,获得所有m名受试者hrtf特征谷曲线的集合
步骤105、构建一个端对端的卷积神经网络。将全体受试者的耳部图像作为网络输入,将hrtf特征谷曲线集合
步骤106、保存训练好的网络,即为神经网络模型。
进一步地,步骤101中所述的已知的完备hrtf数据库,可选取美国cipichrtf数据库或奥地利arihrtf数据库等;为了增大训练数据量,也可将不同的hrtf数据库联合使用;
进一步地,步骤1中云服务器的神经网络模型已通过训练建立了耳部图像和hrtf的特征谷曲线的映射关系,因此将用户的耳部图像输入神经网络模型,就可以获得其hrtf的特征谷曲线。
进一步地,步骤2中对通用hrtf进行个性化定制,可通过频移实现。假设通用hrtf在仰角方向
即可得到定制的用户个性化hrtf即hindividual。如果(f1-f0)为正,表明需要将通用hrtf向较f0高的频率方向移动;如果(f1-f0)为负,表明需要将通用hrtf向较f0高的频率方向移动。
进一步地,步骤1和步骤2都涉及双耳信息的处理,包括左耳图像、右耳图像、左耳中垂面hrtf和右耳中垂面hrtf。这里将双耳问题转化为单耳问题。具体的:以左耳为例,将右耳图像进行180°空间翻转即可获得一个新的左耳图像;左耳图像和左耳中垂面hrtf相对应,新的左耳图像和右耳中垂面hrtf相对应。
进一步地,步骤4中选取用户在收看远程直播过程中可能的头部空间区域,如水平方位角-10°≤θ≤10°,仰角
进一步地,步骤5中根据头动设备捕获的头部实时位置坐标
一种用于实现所述方法的装置,包括:
远程声场多通路捡拾模块,采用传声器阵列捡拾远程的现场声信号,阵列输出为多通路声信号;
云处理模块,包括基于神经网络的个性化hrtf的获取,并将获取的个性化hrtf应用于多个空间位置的双耳虚拟声信号的合成;根据用户实时的头位置信息,挑选合适的双耳虚拟声信号重放;
用户端模块,由拍摄装置、头部跟踪装置和耳机组成。拍摄装置用于拍摄用户的耳部图像,头部跟踪装置用于检测头部的实时位置,耳机用于播放双耳虚拟声信号。
5g通讯模块,采用5g通讯技术实施云处理模块和远程声场多通路捡拾模块、云处理模块和用户端模块之间的通讯。
进一步地,所述的云处理模块包括:
个性化hrtf定制模块,用于事前训练并建立反映耳部图像和hrtf特征谷曲线的映射关系的卷积神经网络;将用户的耳部图像输入神经网络,获取用户的hrtf的特征谷曲线;以用户hrtf的特征谷曲线为依据,对通用hrtf进行频移。
双耳虚拟声信号合成模块,用于将在远程声场实时捡拾的多通路声信号和用户个性化hrtf数据进行卷积和叠加运算,生成对应多个头部空间位置的双耳虚拟声信号
头部位置匹配模块,根据用户端上传的头部位置,匹配出空间最近邻的空间节点,读取相应方位的双耳虚拟声信号。
本发明的原理是:耳廓形态是最具有个性化的生理结构。当声源处于不同的仰角位置,其发出的声波和耳廓的相互作用形成了hrtf的特征谷;hrtf特征谷位置随仰角的变化(即hrtf特征谷曲线)是仰角定位的重要因素,也是个性化hrtf的重要特征。本发明从个性化hrtf的形成入手,借助端对端卷积神经网络强大的非线性拟合能力,建立耳部图像和hrtf特征谷曲线之间的关联,获取了用户个性化的hrtf特征谷曲线,并据此对通用hrtf进行频移,实现个性化hrtf的定制。这里,个性化hrtf特征谷曲线的预测需要借助端对端卷积神经网络,它是一种复杂的神经网络,需要占用较大的计算资源。随着云计算技术的发展,神经网络的训练、存储和预测都可以在云服务器上实施。
另一方面,由于器件的微型化,现在的移动终端集成了越来越多的外设和功能,可以方便地获取用户头部的实时位置。考虑到根据头部实时位置计算双耳虚拟声信号需要消耗较长时间,本发明在云服务器上进行头部可能变化空间的多节点的双耳虚拟声信号计算,然后根据实时的头位置进行调取。这样,在不增加移动终端计算量的同时实现了声重放的低延迟。同时,5g通讯技术的发展,极大提升了网络传输速度(5g的下载速度可达到1gbps以上),可以实现一个云服务器下的多用户并发。
本发明与现有技术相比,具有如下优点和有益效果:
(1)利用神经网络预测个性化仰角定位信息,并采用频移的方式实现通用hrtf的个性化定制。本发明可提升用户在仰角方位的感知准确性。
(2)基于用户端头动检测设备所实现的双耳虚拟重放信号的动态调整,可更好的实现用户端和现场的同步,提高用户的现场感和沉浸感。
(3)融合云计算技术和5g网络通讯技术,实现远程声场虚拟重现的多用户并发。
附图说明
图1是本发明实施例的原理图;
图2是本发明实施例的端对端卷积神经网络的训练流程图;
图3是本发明实施例的模块连接示意图。
具体实施方式
下面结合附图对本发明作进一步的说明,但本发明要求保护范围并不局限于实施例表示的范围。
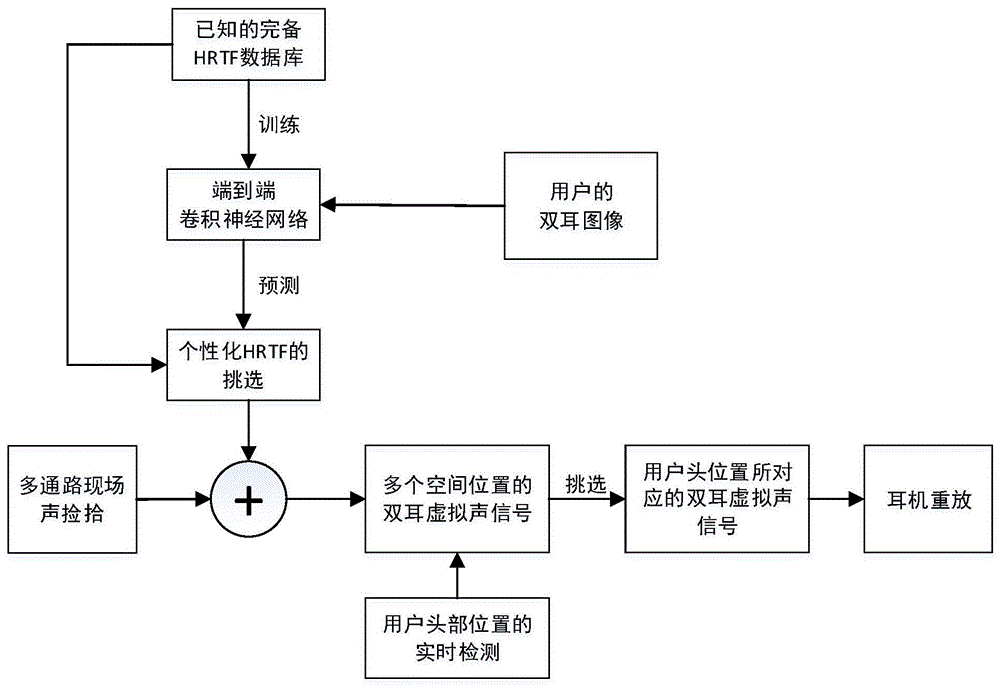
图1是本发明的一种远程声场实时虚拟重现的方法的原理方框图。该方法(1)采用端对端的卷积神经网络,由用户耳部图像推知个性化的仰角定位因素,并以此为依据对通用头相关传输函数(hrtf)进行个性化定制,进一步将定制的个性化hrtf应用于双耳虚拟声信号的合成;(2)基于用户头部位置的实时检测,实现跟踪头部位置的动态双耳虚拟声信号的重放。上述个性化定制和实时动态的虚拟声信号处理方法可以增强用户的现场感和沉浸感。
一种远程声场实时虚拟重现的方法,其特征是,包括如下步骤:
步骤1、用户将自身的耳部图像上传至云服务器的神经网络模型,获取用户hrtf的特征谷曲线;
这里,需要指出的是,可以利用现有的移动终端(例如手机)的拍摄功能获取耳部图像。
步骤2、以特征谷曲线为依据,对通用hrtf进行个性化定制,得到用户的个性化hrtf数据;
步骤3、对远程声场进行实时的多通路声捡拾并将捡拾信号上传至云服务器;
步骤4、将捡拾信号和用户个性化hrtf数据进行卷积和叠加运算,生成多个空间位置的双耳虚拟声信号;
步骤5、根据用户端实时检测并上传的用户头部空间位置,调取相应空间位置的双耳虚拟声信号,发送至用户端的耳机设备进行声重放。
这里,需要指出的是,根据生产厂家发布的信息,目前已有两款手机(亚马逊firephone,三星galaxys5)和一款耳机(ossicx)具备用户头部检测功能,可以用作本实施例的头部跟踪装置。
步骤6、按照一定的时间采样间隔,重复步骤3到步骤5,直至远程声场直播结束。
具体而言,步骤1中所述的处于云服务器的神经网络模型已事先训练好,训练步骤包括:
步骤101、选取一个已知的完备hrtf数据库,它包含m名受试者的全空间hrtf数据和受试者的耳部图像;
步骤102:对于其中一个受试者m(m=1,2,…,m),采用头中心坐标系,选取受试者中垂面上沿仰角
这里,需要指出的是,hrtf可能包括多个特征谷,这里只需要提取第一个特征谷。大量人群的数据表明,当声源的仰角
例如,选取cipichrtf数据库中受试者中垂面仰角
步骤103:拟合仰角
步骤104:对hrtf数据库中的每个受试者实施步骤102和步骤103,获得所有m名受试者hrtf特征谷曲线的集合
步骤105、构建一个端对端的卷积神经网络。将全体受试者的耳部图像作为网络输入,将hrtf特征谷曲线集合
步骤106、保存训练好的网络,即为神经网络模型。
具体而言,步骤101中所述的已知的完备hrtf数据库,可选取美国cipichrtf数据库或奥地利arihrtf数据库等;为了增大训练数据量,也可将不同的hrtf数据库联合使用。
具体而言,步骤1中云服务器的神经网络模型已通过训练建立了耳部图像和hrtf的特征谷曲线的映射关系,因此将用户的耳部图像输入神经网络模型,就可以获得其hrtf的特征谷曲线。
具体而言,步骤2中对通用hrtf进行个性化定制,可通过频移实现。假设通用hrtf在仰角方向
即可得到定制的用户个性化hrtf即hindividual。如果(f1-f0)为正,表明需要将通用hrtf向较f0高的频率方向移动;如果(f1-f0)为负,表明需要将通用hrtf向较f0低的频率方向移动。
这里,需要指出的是,原则上公式(1)的频移对左耳和右耳hrtf同时实施。在实际应用中,当声源相对于正前方的偏离角大于±45°时,考虑到声源异侧耳(即远离声源的耳)对定位的贡献较小,可以只对声源同侧耳(即靠近声源的耳)进行上述个性化定制。
具体而言,上述步骤1和步骤2都涉及双耳信息的处理,包括左耳图像、右耳图像、左耳中垂面hrtf和右耳中垂面hrtf。这里将双耳问题转化为单耳问题。具体的:以左耳为例,将右耳图像进行180°空间翻转即可获得一个新的左耳图像;左耳图像和左耳中垂面hrtf相对应,新的左耳图像和右耳中垂面hrtf相对应。
具体而言,步骤4中选取用户在收看远程直播过程中可能的头部空间区域,如水平方位角-10°≤θ≤10°,仰角
具体而言,步骤5中根据头动设备捕获的头部实时位置坐标
其中,步骤1中所述的处于云服务器的神经网络模型的训练步骤如图2所示,其中卷积层和池化层的数目i可以取2。可以通过(1)公开hrtf完备数据库(包括hrtf数据和受试者耳部图像)的联合使用和(2)耳图像翻转的途径扩大数据量,提高网络的预测精度。整个训练过程可以在googlecolab上实施。
如图3所示,一种用于实现所述方法的装置,包括:
远程声场多通路捡拾模块,采用传声器阵列捡拾远程的现场声信号,阵列输出为多通路声信号;
例如,传声器阵列可采用由四个心形指向性传声器根据irt-cross布置方法构成的正方形阵列,传声器的主轴分别指向左前、右前、左后和右后方向,传声器之间的距离为0.25m。通过上述传声器阵列可以得到四通路声信号。
云处理模块,包括基于神经网络的个性化hrtf的获取,并将其应用于多个空间位置的双耳虚拟声信号的合成;根据用户实时的头位置信息,挑选合适的双耳虚拟声信号重放;
用户端模块,由拍摄装置、头部跟踪装置和耳机组成。拍摄装置用于拍摄用户的耳部图像,头部跟踪装置用于检测头部的实时位置,耳机用于播放双耳虚拟声信号。
这里,需要指出的是,由于采用5g高速传输网络进行模块之间的通讯,可以实现多用户并发。图3中以用户1为例,详细的描述了用户端借助5g网络和云处理模块之间的信息交换。类似的情况可以推广到用户2,…,用户n。为了图例的简约表述,图中仅画出用户2,…,用户n和通讯模块的连接。
5g通讯模块,采用5g通讯技术实施云处理模块和远程声场多通路捡拾模块、云处理模块和用户端模块之间的通讯。
10.根据权利要求9所述的装置,其特征在于,所述的云处理模块包括:
个性化hrtf定制模块,用于事前训练并建立反映耳部图像和hrtf特征谷曲线的映射关系的卷积神经网络;将用户的耳部图像输入神经网络,获取用户的hrtf的特征谷曲线;以用户hrtf的特征谷曲线为依据,对通用hrtf进行频移。
双耳虚拟声信号合成模块,用于将在远程声场实时捡拾的多通路声信号和用户个性化hrtf数据进行卷积和叠加运算,生成对应多个头部空间位置的双耳虚拟声信号
头部位置匹配模块,根据用户端上传的头部位置,匹配出空间最近邻的空间节点,读取相应方位的双耳虚拟声信号。
本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!