一种面向机器学习的分布式计算互连网络系统及通信方法与流程
本发明属于通信技术领域,更进一步涉及互连网络通信技术领域中的一种面向机器学习的分布式计算互连网络系统及通信方法,本发明利用光交换机、光电混合交换机和计算节点组成的互连网络系统,实现分布式计算互连网络系统中各个计算节点之间的高效通信。
背景技术:
随着计算技术的发展,许多新兴应用需要非常巨大的计算能力才能完成,尤其是以大数据和大模型为基础的机器学习应用。集中式计算完全依赖于一台大型的中心计算机的处理能力。与集中式计算相反,分布式计算中,多个通过网络互连的计算节点都具有较高的计算能力,它们之间相互传递数据,实现信息共享,共同协作完成一个处理任务。如果采用集中式计算,需要耗费相当长的时间来完成复杂的处理任务。分布式计算将该任务分解成许多小的部分,分配给多个计算节点进行处理。这样可以节约整体计算时间,大幅提高计算效率。
互连网络系统作为分布式计算中连接各个计算节点的重要组成部分,它的性能主要依赖于网络直径、可扩展性和可靠性等参数。另一方面,面对网络中复杂多变的流量环境,具备识别网络状态能力的通信方法可以根据网络中的流量变化做出及时的应对,避免网络拥塞导致的通信性能下降。在大规模分布式机器学习场景中,计算节点之间需要同步本地参数以更新训练模型,但是在网络规模扩大之后,参数同步的通信开销随之增大。具备较低网络直径和较小扩展复杂度的互连网络系统对于提升机器学习训练任务的执行效率有着重要的影响。同时,对于机器学习训练任务之间的差异性,具备一定自主调节能力的通信方法可以更好地平衡网络中的流量负载以应对复杂的网络环境。如何设计一个合理高效的分布式计算互连网络系统和通信方法对降低机器学习训练任务的执行时间至关重要。
现有的互连网络系统具有良好扩展性,互连网络的通信效率较高,但互连网络中流量负载的平衡能力较差,例如西安电子科技大学在其授权公告号为cn106789750b,名称为“一种高性能计算互连网络系统及通信方法”的发明中,公开了一种高性能计算互连网络系统及通信方法,该发明的互连网络系统包括电分组交换机组成的一级单元、光电混合交换机组成的二级单元和二级单元通过组内光交换机组成的三级单元,三级单元通过组间光交换机互连成整个系统;通信方法是利用电分组交换机制和光电混合的交换机制实现系统的多级通信,其中电分组交换机与光电混合交换机之间通过电分组交换机制实现一级单元与二级单元之间的通信,光电混合交换机与组间光交换机利用光电混合的交换机制实现三级单元之间的通信。该发明在网络下层通过多级单元组成模块化的结构,降低网络的扩展复杂度;网络上层的树形结构通过提供一定的设备冗余增强了网络的容错率,进而提高了系统的可靠性。但是其存在的不足之处在于:1、互连网络系统的网络直径较大,增加了机器学习任务的执行时间;2、通信方法仅能完成数据分组在通信节点对之间的传输,不具备自主调节的能力。
技术实现要素:
本发明的目的在于克服上述已有技术的不足,提出了一种面向机器学习的分布式计算互连网络系统及通信方法,旨在提高互连网络的通信效率,同时更好地平衡分布式计算互连网络中的流量负载。
为实现上述目的,本发明采取的技术方案为:
一种面向机器学习的分布式计算互连网络系统,包括光交换子系统和计算子系统。
所述光交换子系统包括编号为a0,a1,…,ai,…,a2n-1的2n台光交换机,每台光交换机包括n个交换端口,其中n≥1,ai表示第i台光交换机;
所述计算子系统包括n个计算单元,每个计算单元包括n个子计算单元,每个子计算单元包括1台光电混合交换机和n个计算节点,每个光电混合交换机包括2个上行端口、n个下行端口和n-1个交换端口,每个计算节点包括1个上行端口;每个子计算单元所包含的光电混合交换机的n个下行端口分别与n个计算节点的上行端口连接,每个计算单元所包含的每一个光电混合交换机的n-1个交换端口分别与同一计算单元内的其他n-1个光电混合交换机的1个交换端口连接;
所述计算子系统所包含的n2个光电混合交换机的编号为m(0,0),m(0,1),…,m(0,n-1);m(1,0),m(1,1),…,m(1,n-1);…;m(x,y);…;m(n-1,0),m(n-1,1),…,m(n-1,n-1);其中m(x,y)表示第x个计算单元中第y台光电混合交换机,0≤x≤n-1,0≤y≤n-1;
所述光交换子系统中光交换机ai的每个交换端口与计算子系统中光电混合交换机m(x,y)的1个上行端口连接,其中i%n=y,%表示i对n取模。
上述一种面向机器学习的分布式计算互连网络系统中,所述计算节点,采用cpu或者gpu。
一种面向机器学习的分布式计算互连网络的通信方法,包括如下步骤:
(1)每个计算节点产生数据分组并发送:
每个计算节点sr根据自身的地址和与sr进行通信的每个计算节点sd的地址产生数据分组,并将所有数据分组发送至与计算节点sr相连的光电混合交换机rs;
(2)每个光电混合交换机rs对每个数据分组进行解析:
每个光电混合交换机rs对每个sr产生的数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址;
(3)每个光电混合交换机rs判断计算节点sr与sd是否在同一个计算单元内:
每个光电混合交换机rs通过解析得到的sr的地址和所有与sr进行通信的计算节点sd的地址,判断计算节点sr与sd是否在同一个计算单元内,若是,执行步骤(4),否则,执行步骤(7);
(4)每个光电混合交换机rs判断计算节点sr与sd是否在同一个子计算单元内:
每个光电混合交换机rs通过解析得到的sr的地址和所有与sr进行通信的计算节点sd的地址,判断计算节点sr与sd是否在同一个子计算单元内,若是,将sr产生的数据分组发送至与sr进行通信的计算节点sd;否则,执行步骤(5);
(5)每个光电混合交换机rs向光电混合交换机rd发送数据分组:
每个光电混合交换机rs将sr产生的数据分组发送至与计算节点sd相连的目的光电混合交换机rd;
(6)每个光电混合交换机rd对每个数据分组进行解析,并发送数据分组:
每个光电混合交换机rd对每个数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址,并向sd发送sr产生的数据分组;
(7)每个光电混合交换机rs判断自身与和计算节点sd相连的光电混合交换机rd之间是否存在光交换机:
每个光电混合交换机rs判断自身的编号m(x1,y1)与和计算节点sd相连的光电混合交换机rd的编号m(x2,y2)是否满足y1=y2,若是,执行步骤(8);否则,执行步骤(10);
(8)每个光电混合交换机rs发送数据分组至光交换机ro:
(8a)每个光电混合交换机rs检查所有与自身相连的光交换机需要发送的数据分组数目,并选择需要发送数据分组数目最小的光交换机ro;
(8b)每个光电混合交换机rs根据自身和光电混合交换机rd的设备编号计算通信波长w,并使用该通信波长将数据分组发送至相连的光交换机ro,其中:
w=(x1+x2)%n
其中,x1为与计算节点sr相连的光电混合交换机rs所在计算单元的编号,x2为与计算节点sd相连的光电混合交换机rd所在计算单元的编号;
(9)每个光交换机ro发送数据分组至光电混合交换机rd:
每个光交换机ro将sr产生的数据分组发送至与计算节点sd相连的光电混合交换机rd,并执行步骤(6);
(10)每个光电混合交换机rs发送数据分组至光电混合交换机rm:
每个光电混合交换机rs将sr产生的数据分组发送至与光电混合交换机rd在同一个计算单元内的光电混合交换机rm,rm的设备编号m(x3,y3)与光电混合交换机rd编号m(x2,y2)满足y2=y3;
(11)每个光电混合交换机rm解析数据分组并计算通信波长,然后发送数据分组:
每个光电混合交换机rm对每个sr产生的数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址,并检查所有与自身相连的光交换机需要发送的数据分组数目,选择需要发送数据分组数目最小的光交换机ro,然后根据自身的设备编号和光电混合交换机rd的设备编号计算通信波长w,最后使用w将数据分组发送至相连的光交换机ro,执行步骤(9)。
本发明与现有技术相比,具有以下优点:
第一,由于本发明的互连网络系统中仅仅包括光交换机组成的光交换子系统和光电混合交换机及计算节点组成的计算子系统,计算子系统中的计算单元通过光交换机和光电混合交换机连接,计算单元内的子计算单元之间同样通过光电混合交换机连接,光电混合交换机同时连接两个系统使得网络结构扁平化,降低了互连网络的网络直径,从而减少了计算节点对之间的通信时间,与现有技术相比,有效提高了互连网络的通信效率,进而提升了机器学习训练任务的执行效率。
第二,由于本发明的通信方法中在计算单元之间进行通信时光电混合交换机会根据光交换机需要发送的数据分组数目选择需要发送数据分组数目最小的光交换机,能够对互连网络的状态进行识别,提高了互连网络中流量负载的平衡能力,与现有技术相比,有效地提升了应对复杂网络环境的能力。
附图说明
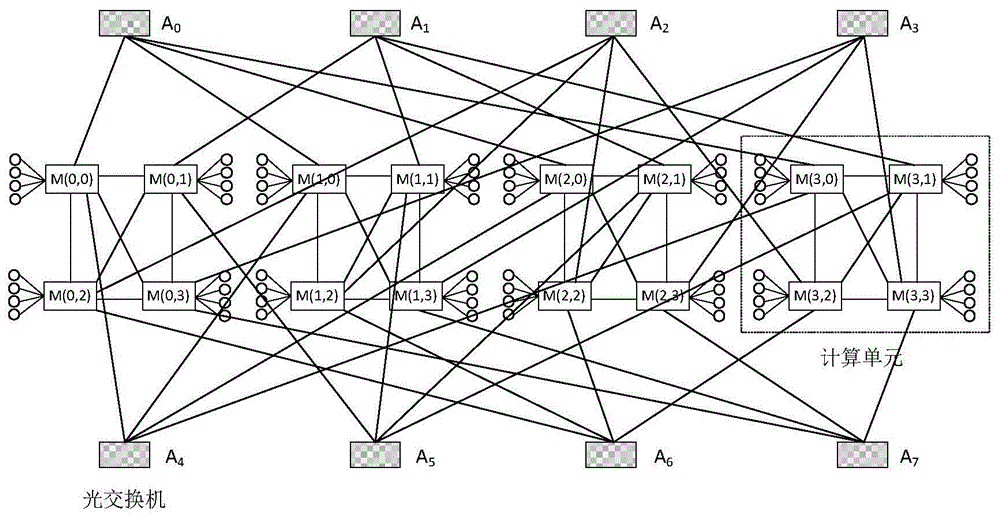
图1为本发明分布式计算互连网络系统具体实施例的结构示意图;
图2为本发明分布式计算互连网络系统中计算单元具体实施例的结构示意图;
图3为本发明分布式计算互连网络通信方法的实现流程图。
具体实施方式
下面结合附图和具体实施例,对本发明作进一步详细描述。
参照图1,一种面向机器学习的分布式计算互连网络系统,包括光交换子系统和计算子系统。
所述光交换子系统包括编号为a0,a1,…,ai,…,a2n-1的2n台光交换机,其中n≥1,ai表示第i台光交换机。为了便于观察和描述,本实施例n=4,则光交换子系统包含的光交换机的数量为8台,具体编号为a0,a1,…,a6,a7,每台光交换机包括n个交换端口,即每台光交换机包括4个交换端口。
所述计算子系统包括n个计算单元,则本实施例中计算子系统包含的计算单元数量为4个,计算单元的数目与每台光交换机的交换端口数量一致。
所述计算子系统所包含的n2个光电混合交换机的编号为m(0,0),m(0,1),…,m(0,n-1);m(1,0),m(1,1),…,m(1,n-1);…;m(x,y);…;m(n-1,0),m(n-1,1),…,m(n-1,n-1);其中m(x,y)表示第x个计算单元中第y台光电混合交换机,0≤x≤n-1,0≤y≤n-1。本实施例中计算单元0内4台光电混合交换机的编号分别为m(0,0),m(0,1),m(0,2),m(0,3);计算单元1内4台光电混合交换机的编号分别为m(1,0),m(1,1),m(1,2),m(1,3);计算单元2内4台光电混合交换机的编号分别为m(2,0),m(2,1),m(2,2),m(2,3);计算单元3内4台光电混合交换机的编号分别为m(3,0),m(3,1),m(3,2),m(3,3)。
所述光交换子系统中光交换机ai的每个交换端口与计算子系统中光电混合交换机m(x,y)的1个上行端口连接,每个光电混合交换机包括2个上行端口,其中i%n=y,%表示i对n取模。本实施例中,由于0%4=0,光交换机a0的4个交换端口分别连接m(0,0)、m(1,0)、m(2,0)和m(3,0)的一个上行端口;由于1%4=1,光交换机a1的4个交换端口分别连接m(0,1)、m(1,1)、m(2,1)和m(3,1)的一个上行端口;由于2%4=2,光交换机a2的4个交换端口分别连接m(0,2)、m(1,2)、m(2,2)和m(3,2)的一个上行端口;由于3%4=3,光交换机a3的4个交换端口分别连接m(0,3)、m(1,3)、m(2,3)和m(3,3)的一个上行端口;由于4%4=0,光交换机a4的4个交换端口分别连接m(0,0)、m(1,0)、m(2,0)和m(3,0)的另一个上行端口;由于5%4=1,光交换机a5的4个交换端口分别连接m(0,1)、m(1,1)、m(2,1)和m(3,1)的另一个上行端口;由于6%4=2,光交换机a6的4个交换端口分别连接m(0,2)、m(1,2)、m(2,2)和m(3,2)的另一个上行端口;由于7%4=3,光交换机a7的4个交换端口分别连接m(0,3)、m(1,3)、m(2,3)和m(3,3)的另一个上行端口。
参照图2,一种面向机器学习的分布式计算互连网络系统中的计算单元,采用采用cpu或者gpu,由于gpu作为目前最常用来加速机器学习的设备,本实施例分布式计算互连网络系统中的计算单元采用gpu。
所述的每个计算单元包括n个子计算单元,即每个计算单元包含的子计算单元数量为4个,每个计算单元中子计算单元的数量与互连网络系统中计算单元的数量相同;每个子计算单元包括1台光电混合交换机和n个计算节点,即每个子计算单元中光电混合交换机和计算节点的数量分别为1台和4个,每个子计算单元中计算节点的数量与计算单元的数量相同。每个光电混合交换机包括2个上行端口、n个下行端口和n-1个交换端口,则每个光电混合交换机包含的上行端口、下行端口和交换端口的数量分别为2个、4个和3个;每个计算节点包括1个上行端口;每个子计算单元所包含的光电混合交换机的n个下行端口分别与n个计算节点的上行端口连接,即每个光电混合交换机的4个下行端口分别与4个计算节点的上行端口连接;每个计算单元所包含的每一个光电混合交换机的n-1个交换端口分别与同一计算单元内的其他n-1个光电混合交换机的1个交换端口连接,则每个计算单元中每个光电混合交换机的3个交换端口分别与同一计算单元内的其他3个光电混合交换机的1个交换端口连接。光电混合交换机同时连接光交换子系统和计算子系统使得网络结构扁平化,降低了互连网络的网络直径,从而减少了计算节点对之间的通信时间,有效提高了互连网络的通信效率,进而提升了机器学习训练任务的执行效率。
上述互连网络系统中共有n2个子计算单元、n2台光电混合交换机和n3个计算节点,本实施例中则有16个子计算单元、16台光电混合交换机和64个计算节点,光交换机、计算单元、子计算单元、光电混合交换机和计算节点的数量之间的对应关系使网络中计算节点的数量可以随着网络规模的扩展以三次方的数量级增加,有效提升了网络的扩展性。
参照图3,一种面向机器学习的分布式计算互连网络的通信方法,包括如下步骤:
步骤1)每个计算节点产生数据分组并发送。
每个计算节点sr根据自身的地址和与sr进行通信的每个计算节点sd的地址产生数据分组,并将所有数据分组发送至与计算节点sr相连的光电混合交换机rs,其中每个计算节点sr既可以作为通信的源节点也可以作为通信的目的节点;
步骤2)每个光电混合交换机rs对每个数据分组进行解析。
每个光电混合交换机rs对每个sr产生的数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址。
步骤3)每个光电混合交换机rs判断计算节点sr与sd是否在同一个计算单元内。
每个光电混合交换机rs通过解析得到的sr的地址和所有与sr进行通信的计算节点sd的地址,判断计算节点sr与sd是否在同一个计算单元内,若是,执行步骤4,否则,执行步骤7。
步骤4)每个光电混合交换机rs判断计算节点sr与sd是否在同一个子计算单元内。
每个光电混合交换机rs通过解析得到的sr的地址和所有与sr进行通信的计算节点sd的地址,判断计算节点sr与sd是否在同一个子计算单元内,若是,将sr产生的数据分组发送至与sr进行通信的计算节点sd;否则,执行步骤5。
步骤5)每个光电混合交换机rs向光电混合交换机rd发送数据分组。
每个光电混合交换机rs将sr产生的数据分组发送至与计算节点sd相连的目的光电混合交换机rd。
步骤6)每个光电混合交换机rd对每个数据分组进行解析,并发送数据分组。
每个光电混合交换机rd对每个数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址,并向sd发送sr产生的数据分组。
步骤7)每个光电混合交换机rs判断自身与和计算节点sd相连的光电混合交换机rd之间是否存在光交换机。
每个光电混合交换机rs判断自身的编号m(x1,y1)与和计算节点sd相连的光电混合交换机rd的编号m(x2,y2)是否满足y1=y2,若是,执行步骤8;否则,执行步骤10。
步骤8)每个光电混合交换机rs发送数据分组至光交换机ro。
步骤8a)每个光电混合交换机rs检查所有与自身相连的光交换机需要发送的数据分组数目,并选择需要发送数据分组数目最小的光交换机ro。该步骤能够对互连网络的状态进行识别,提高了互连网络中流量负载的平衡能力,有效地提升了应对复杂网络环境的能力。
步骤8b)每个光电混合交换机rs根据自身和光电混合交换机rd的设备编号计算通信波长w,并使用该通信波长将数据分组发送至相连的光交换机ro,其中:
w=(x1+x2)%4
其中,x1为与计算节点sr相连的光电混合交换机rs所在计算单元的编号,x2为与计算节点sd相连的光电混合交换机rd所在计算单元的编号。
步骤9)每个光交换机ro发送数据分组至光电混合交换机rd。
每个光交换机ro将sr产生的数据分组发送至与计算节点sd相连的光电混合交换机rd,并执行步骤6。
步骤10)每个光电混合交换机rs发送数据分组至光电混合交换机rm。
每个光电混合交换机rs将sr产生的数据分组发送至与光电混合交换机rd在同一个计算单元内的光电混合交换机rm,rm的设备编号m(x3,y3)与光电混合交换机rd编号m(x2,y2)满足y2=y3。
步骤11)每个光电混合交换机rm解析数据分组并计算通信波长,然后发送数据分组。
每个光电混合交换机rm对每个sr产生的数据分组进行解析,得到sr的地址和所有与sr进行通信的计算节点sd的地址,并检查所有与自身相连的光交换机需要发送的数据分组数目,选择需要发送数据分组数目最小的光交换机ro,然后根据自身的设备编号和光电混合交换机rd的设备编号计算通信波长w,最后使用w将数据分组发送至相连的光交换机ro,执行步骤9。
- 还没有人留言评论。精彩留言会获得点赞!