耳机及耳机组的制作方法
本发明是有关于一种语音处理装置,且特别是有关于一种耳机及耳机组。
背景技术:
随着科技的发展,使用耳机控制智能型装置的语音助理已然成为人们生活中最为常见的行为之一。然而,若仅透过耳机的麦克风接收使用者的语音,将可能因为环境噪音的干扰而影响语音辨识的结果。为了改善耳机的语音辨识表现,各家厂商无不致力于研发相关的技术。
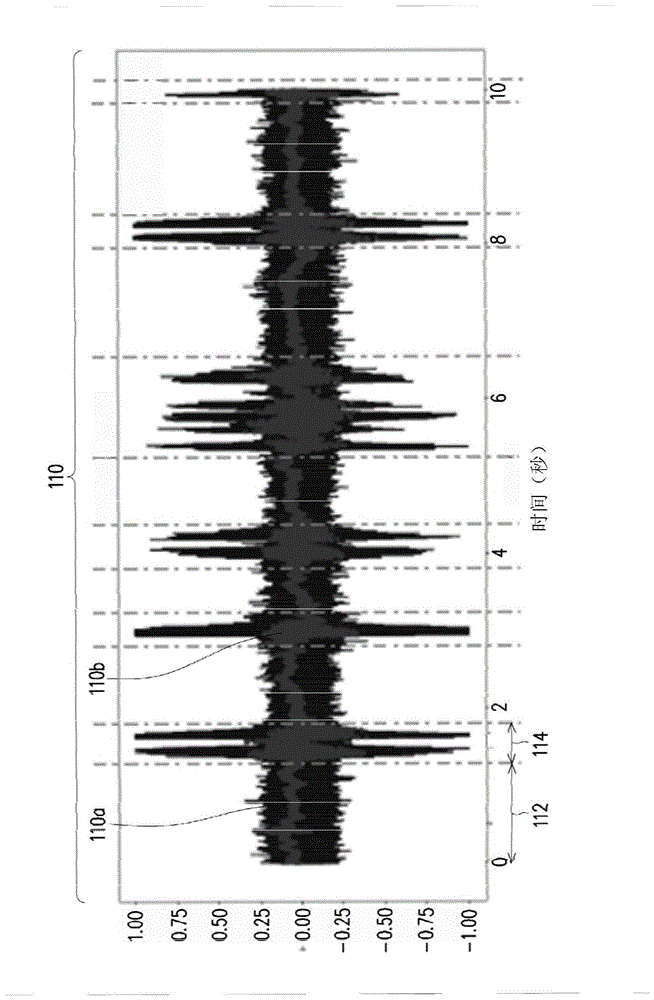
例如,习知一技术可利用加速规讯号辅助声音活动侦测(voiceactivitydetection,vad)技术以判定在麦克风的时域讯号中,语音讯号与噪声讯号的分界处,如图1所示。
在图1中,可看出在经由上述技术处理麦克风的时域讯号110(其包括语音成分110a及噪声成分110b)之后,可将时域讯号110区分为多段噪声讯号(例如噪声讯号112)与语音讯号(例如语音讯号114)。然而,由各语音讯号(例如语音讯号114)可看出,其个别仍包括噪声成分110b。换言之,此种作法并无法完全消除噪声成分。
此外,习知有另一技术利用加速规接收本质上不带有环境噪音的骨传导音讯号以隔绝外部噪声,再以此骨传导音讯号取代麦克风讯号的低频部分,借以滤除低频的噪声。然而,由于加速规讯号的采样频率较低,且骨传导音讯号本质上缺乏口腔与鼻腔中的共鸣,故相较于麦克风透过空气所接收到的讯号来的闷且模糊,因而可能导致所合成的语音讯号具有较差的音质。
因此,对于本领域技术人员而言,如何设计一种可提升语音讯号质量的技术方案实为一项重要议题。
技术实现要素:
有鉴于此,本发明提供一种耳机及耳机组,其可用于解决上述技术问题。
本发明提供一种耳机,其包括处理电路及滤波模块。处理电路从至少一麦克风取得一第一语音讯号,并对第一语音讯号执行一前处理操作以产生一第二语音讯号。滤波模块包括一高通滤波器、一低通滤波器及一带通滤波器,其中高通滤波器对第二语音讯号执行一高通滤波操作以产生一第一讯号,低通滤波器对第二语音讯号执行一低通滤波操作以产生一第二讯号,带通滤波器从至少一加速规接收对应于第一语音讯号的一骨传导音讯号,并对骨传导音讯号执行一带通滤波操作以产生一第三讯号。处理电路更经配置以:从高通滤波器、低通滤波器及带通滤波器分别接收第一讯号、第二讯号及第三讯号;对第二讯号及第三讯号执行一降噪操作,以产生一第四讯号;以及对第一讯号及第四讯号执行一讯号合成操作,以将第一讯号及第四讯号合成为一输出语音讯号。
本发明提供一种耳机组,包括第一耳机及第二耳机。第一耳机包括至少一第一麦克风。第二耳机包括至少一第二麦克风、处理电路及滤波模块。至少一第二麦克风与至少一第一麦克风形成一麦克风阵列。处理电路从麦克风阵列取得一第一语音讯号,并对第一语音讯号执行一前处理操作以产生一第二语音讯号。滤波模块包括一高通滤波器、一低通滤波器及一带通滤波器,其中高通滤波器对第二语音讯号执行一高通滤波操作以产生一第一讯号,低通滤波器对第二语音讯号执行一低通滤波操作以产生一第二讯号,带通滤波器从至少一加速规接收对应于第一语音讯号的一骨传导音讯号,并对骨传导音讯号执行一带通滤波操作以产生一第三讯号。处理电路更经配置以:从高通滤波器、低通滤波器及带通滤波器分别接收第一讯号、第二讯号及第三讯号;对第二讯号及第三讯号执行一降噪操作,以产生一第四讯号;以及对第一讯号及第四讯号执行一讯号合成操作,以将第一讯号及第四讯号合成为一输出语音讯号。
基于上述,本发明的耳机及耳机组可提供具更佳音质的输出语音讯号,从而有助于后续的语音辨识操作。
附图说明
图1是示例性技术中结合加速规讯号及vad技术以消除噪声的示意图。
图2为一实施例中的耳机示意图。
图3是依据图2绘示的耳机内硬件及软件模块的示意图。
图4为一实施例中的耳机组示意图。
其中:
110:时域讯号
110a:语音成分
110b:噪声成分
112:噪声讯号
114:语音讯号
202:滤波模块
202a:高通滤波器
202b:低通滤波器
202c:带通滤波器
204:处理电路
210,411,421:加速规
220,412,422:麦克风
301:前处理模块
301a:切换模块
310b:波束成形模块
302:降噪模块
302a:讯号分离模块
302b:子空间语音增强模块
303:讯号合成模块
400:耳机组
200,410,420:耳机
bt:骨传导音讯号
ns:噪声讯号
os:输出语音讯号
s1:第一讯号
s2:第二讯号
s3:第三讯号
s4:第四讯号
ss1:第一特定讯号
ss2:第二特定讯号
vo1:第一语音讯号
vo2:第二语音讯号
具体实施方式
请参照图2,其是一实施例中的耳机示意图。如图2所示,耳机200例如是一入耳式耳机,并可包括滤波模块202及处理电路204,其中滤波模块202可接收来自加速规210的骨传导音讯号bt,而滤波模块202及处理电路204可接收来自于麦克风220的第一语音讯号vo1。
在图2中,加速规210及麦克风220可设置于耳机200之外。例如,加速规210及麦克风220可设置于与耳机200属于同一有线/无线耳机组的另一耳机中。在此情况下,上述另一耳机可透过相关的有线/无线通讯协定将骨传导音讯号bt、第一语音讯号vo1及其他的讯号发送至耳机200,但可不限于此。
此外,在一些实施例中,加速规210及麦克风220亦可设置于耳机200中,并如图2所示方式耦接于滤波模块202及处理电路204。另外,在不同的实施例中,麦克风220可包括单一个麦克风,或是由多个麦克风单元形成的麦克风阵列。
在本发明的实施例中,第一语音讯号vo1可对应于骨传导音讯号bt。具体而言,在一实施例中,假设佩戴有上述耳机或耳机组的使用者借由说话等方式而发出/产生人声讯号,而麦克风220可在接收上述人声讯号后相应地将人声讯号转换为第一语音讯号vo1。于此同时,加速规210可撷取使用者在发出上述人声讯号的过程中,因说话所产生的振动以产生骨传导音讯号bt。
基于骨传导音讯号bt及第一语音讯号vo1,本发明耳机200中的滤波模块202及处理电路204可协同进行本发明提出的技术方案,从而提供具较佳音质的输出语音讯号,其相关细节将在之后详述。
在本发明的实施例中,耦接于滤波模块202的处理电路204例如是一般用途处理器、特殊用途处理器、传统的处理器、数位讯号处理器、多个微处理器(microprocessor)、一个或多个结合数位讯号处理器核心的微处理器、控制器、微控制器、特殊应用集成电路(applicationspecificintegratedcircuit,asic)、现场可程序闸阵列电路(fieldprogrammablegatearray,fpga)、任何其他种类的集成电路、状态机、基于进阶精简指令集机器(advancedriscmachine,arm)的处理器以及类似品。
请参照图3,其是依据图2绘示的耳机内硬件及软件模块的示意图。在本发明的实施例中,滤波模块202可包括高通滤波器202a、低通滤波器202b及带通滤波器202c。此外,处理电路204可存取所需的软件模块、程序码来实现本发明提出的技术方案。为使本案技术更易于理解,以下将假设处理电路204所存取的软件模块包括如图3所示的前处理模块301、降噪模块302及讯号合成模块303。应了解的是,图3所示内容并非上述各软件模块与滤波模块202之间的实际耦接关系,而仅是用于便于说明本发明中的讯号传递/处理机制而作如此呈现。
在图3中,处理电路204可从麦克风220取得第一语音讯号vo1,并执行前处理模块301以对第一语音讯号vo1执行前处理操作以产生第二语音讯号vo2。
在本发明的实施例中,用于执行上述前处理操作的前处理模块301可包括切换模块301a及波束成形模块301b,其中切换模块301a可用于判断麦克风220是否仅包括单一麦克风。若是,则切换模块301a可将第一语音讯号vo1作为第二语音讯号vo2而输出至高通滤波器202a及低通滤波器202b。
在另一实施例中,若切换模块301a判定麦克风220未仅包括单一麦克风(即,麦克风220包括一麦克风阵列),则处理电路204可执行波束成形模块301b以对第一语音讯号vo1执行波束成形操作,以产生噪声讯号ns及第一特定讯号ss1,其中第一特定讯号包括第一音讯成分及第一噪声成分。
在一实施例中,第一特定讯号ss1例如是在第一语音讯号vo1中对应于发出第一语音讯号vo1的声源方向的一部分讯号,而噪声讯号ns例如是未对应于上述声源方向的其他部分讯号。从另一观点而言,上述波束成形操作可理解为一种在物理空间上的消噪方式,但可不限于此。之后,波束成形模块301b可将第一特定讯号ss1作为第二语音讯号vo2输出至高通滤波器202a及低通滤波器202b。
简言之,若麦克风220仅包括单一麦克风,则前处理模块301即直接将第一语音讯号vo1输出至高通滤波器202a及低通滤波器202b。另一方面,若麦克风220为麦克风阵列,则处理电路204可将经波束成形操作所取得的第一特定讯号ss1输出至高通滤波器202a及低通滤波器202b。
之后,在取得第二语音讯号vo2之后,高通滤波器202a可对第二语音讯号vo2执行高通滤波操作以产生第一讯号s1,而低通滤波器202b可对第二语音讯号vo2执行低通滤波操作以产生第二讯号s2。在一实施例中,高通滤波器202a与低通滤波器202b的分频点可介于1khz及2khz之间。例如,若分频点经设定为1500hz,则第一讯号s1例如是第二语音讯号vo2中高于1500hz的讯号成分,而第二讯号例如是第二语音讯号vo2中低于1500hz的讯号成分。
此外,在从加速规210取得骨传导音讯号bt之后,带通滤波器202c可对骨传导音讯号bt执行带通滤波操作以产生第三讯号s3。在一实施例中,带通滤波器202c的通带可介于20hz至1000hz之间,即一般人声讯号的频率范围。
之后,处理电路204可从高通滤波器202a、低通滤波器202b及带通滤波器202c分别接收第一讯号s1、第二讯号s2及第三讯号s3。并且,处理电路204可执行降噪模块302以对第二讯号s2及第三讯号s3执行降噪操作,以产生第四讯号s4。
在一实施例中,降噪模块302可基于第二讯号s2及第三讯号s3产生第二特定讯号ss2,其中第二特定讯号ss2可包括彼此分离的第二音讯成分及第二噪声成分。之后,降噪模块302可再依据噪声讯号ns从第二特定讯号ss2中获取第二音讯成分以作为第四讯号s4。
在图3中,降噪模块302可包括讯号分离模块302a及子空间语音增强模块302b,其中讯号分离模块302a可执行讯号分离操作以基于第二讯号s2及第三讯号s3产生第二特定讯号ss2,而子空间语音增强模块302b可执行子空间语音增强操作以依据噪声讯号ns从第二特定讯号ss2中获取第二音讯成分以作为第四讯号s4。
在一实施例中,讯号分离模块302a可基于独立成分分析(independentcomponentsanalysis,ica)的盲讯号分离算法产生第二特定讯号ss2,或是基于主成分分析(principalcomponentsanalysis,pca)算法产生第二特定讯号ss2,但可不限于此。上述ica的相关细节可参照「alaatharwat,independentcomponentanalysis:anintroduction,appliedcomputingandinformatics,2018.」的内容,而pca的相关细节可参照「reneveyr.vetter,n.viragandj.vesin,“singlechannelspeechenhancementusingprincipalcomponentanalysisandmdlsubspaceselection,”inproceedingsofthe6theuropeanconferenceonspeechcommunicationandtechnology(eurospeech’99),1999,vol.5,pp.2411–2414」的内容,于此不另赘述。
详细而言,由于讯号分离模块302a系基于第二讯号s2(其可理解为第二语音讯号vo2中低于分频点的低频成分)及第三讯号s3(其例如是骨传导音讯号bt中介于20hz至1000hz之间的低频成分)进行上述讯号分离操作,因此相较于仅使用第二讯号s2进行讯号分离操作的方式可达到更佳的讯号分离效能。从另一观点而言,若仅有第三讯号s3亦无法执行上述讯号分离操作。因此,本案可理解为透过在执行讯号分离操作时同时考虑第二讯号s2及第三讯号s3的方式来改善讯号分离效能。从另一观点而言,上述讯号分离操作可理解为一种统计方法上的消噪方式。
之后,在第一实施例中,若麦克风220包括麦克风阵列,则波束成形模块301b可相应地提供噪声讯号ns至子空间语音增强模块302b。在此情况下,子空间语音增强模块302b可执行子空间语音增强(subspacespeechenhancer)算法以依据噪声讯号ns从第二特定讯号ss2中获取第二音讯成分。
从另一观点而言,上述子空间语音增强操作可理解为一种矢量空间上的消噪方式。具体而言,子空间语音增强模块302b可依据噪声讯号ns而将第二特定讯号ss2中含有噪声的子空间消除,借以达到消除环境噪音并保留第二音讯成分的效果。上述子空间语音增强算法的细节可参照「krishermus,patrickwambacq,hugovanhamme,areviewofsignalsubspacespeechenhancementanditsapplicationtonoiserobustspeech,eurasipjournalonadvancesinsignalprocessing,2006」的内容,于此不另赘述。
此外,在第二实施例中,若麦克风210仅包括单一麦克风,则波束成形模块301b可能无法提供噪声讯号ns至子空间语音增强模块302b。在此情况下,子空间语音增强模块302b仍可执行子空间语音增强算法而直接从第二特定讯号ss2中获取第二音讯成分以作为第四讯号s4。
之后,处理电路204可执行讯号合成模块303以对第一讯号s1及第四讯号s4执行讯号合成操作,以将第一讯号s1及第四讯号s4合成为输出语音讯号os。在一实施例中,上述讯号合成操作对应的截止频率可介于1khz及2khz之间。藉此,可避免上述讯号合成操作对普遍低于1khz的人声讯号造成衰减。
进一步而言,由于讯号分离模块302a系基于第二讯号s2及第三讯号s3进行上述讯号分离操作,而第二讯号s2及第三讯号s3可理解为对应于使用者所发出的人声讯号中的低频成分,因此讯号分离模块302a及子空间语音增强模块302b所执行的操作可对人声讯号中的低频讯号达到更佳的噪声消除效果。
因此,在将子空间语音增强模块302b提供的第四讯号s4与高通滤波器202a提供的第一讯号s1(其对应于使用者所发出的人声讯号中高于分频点的高频讯号)进行上述讯号合成操作之后,可让输出语音讯号os的低频讯号具有较低的噪声讯号,又由于高频噪声指向性高,可以透过波束成形模块301b大幅滤除,不需要透过降噪模块302执行降噪,因此降噪模块302仅需要执行低频讯号中的降噪运算,可以有效提升运算的速度,进而有助于进行后续的语音辨识操作。
请参照图4,其是一实施例中的耳机组示意图。在图4中,耳机组400可包括耳机410及420,其中耳机410可包括加速规411、麦克风412、滤波模块202及处理电路204,而耳机420可包括加速规421及麦克风422。应了解的是,为便于理解,图4耳机410中的滤波模块202及处理电路204系以图3所绘示的方式呈现。
在本实施例中,麦克风412及422可耦接于处理电路204。由于麦克风412及422可形成一麦克风阵列,故在处理电路202从此麦克风阵列接收第一语音讯号vo1之后,处理电路204可执行切换模块301a以将来自此麦克风阵列的第一语音讯号vo1提供予波束成形模块301b进行先前实施例中教示的波束成形操作。此外,在带通滤波器202c接收来自加速规411及421的骨传导音讯号bt之后,可依先前实施例教示的内容进行带通滤波操作。之后,滤波模块202及处理电路204可依据先前实施例的教示进行相关的讯号处理,进而产生具较佳音质的输出语音讯号os,其细节于此不另赘述。
应了解的是,即便麦克风412及422个别仅包括单一个麦克风,麦克风411及421仍可被视为一麦克风阵列,故波束成形模块301b仍可基于第一语音讯号vo1进行波束成形操作。
综上所述,有别于示例性技术中直接以骨传导音讯号取代低频讯号的作法,本发明的耳机系将骨传导音讯号作为执行讯号分离操作时的参考,借以提升讯号分离的效能,并进而改善降噪的效果。借此,本发明可提供具更佳音质的输出语音讯号,从而有助于后续的语音辨识操作。
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视后附的申请专利范围所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!