一种基于深度学习的网络告警定位方法与流程
本发明涉及计算机网络运维,特别涉及一种基于深度学习的网络告警定位方法。
背景技术:
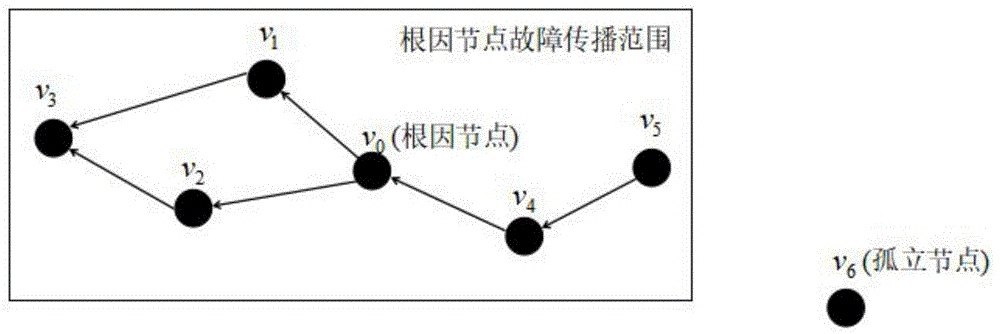
:故障管理是网络管理的一个重要组成部分,包括故障发现、故障诊断和故障修复,难点在于确定故障的根源,即故障根因节点。目前各种大型平台的内部涉及到了上百个系统间相互调用,其网络节点之间会产生大量的告警信息。而在网络中如果一个节点出现故障,调用该节点或者需要利用该节点资源的节点可能也会继而发生故障,从而产生大量的告警信息,而且可能比根因故障节点还早发出告警信息。这些问题的存在导致故障定位十分困难。每次网络出现告警时,需要有运维人员在最短时间内正确地判断出告警的关联关系,筛选出根因节点,然后采取相应的措施。如果有海量的告警信息发生,那么对于这些告警信息的人工处理将会占据大量人力资源,而且效率低下,甚至可能有重复告警信息。所以设计出网络告警信息根因定位自动化技术十分有必要。由于网络实在过于庞大,所以故障的发生在网络的运行中是不可能避免的。一般的做法是通过告警信息的告警关联方法,将告警之间的关系找出来,筛选掉不相关的告警信息,留下相关的告警信息。一般的告警关联方法有基于规则推理的方法、人工智能方法、因果图方法等。基于规则推理的方法需要设计一套告警信息出现的规则,实现起来十分困难,并且无法应对事先没有考虑到的情况,稳定性不足。而一般的人工智能方法,难以搜集到包含一堆关联的告警信息数据集,而且对告警信息数据的特征难以确定。而且根因告警信息样本数据一般比较少,所以还有数据不平衡的问题产生,导致模型过拟合,最终效果不佳。因果图方法也是对告警信息的连接关系进行规则推理得出根因节点。但是这些方法都不具备实时性,若产生了新的告警信息,无法实时匹配其中是否包含有成立的关联规则,难以满足告警关联分析实时性需求。技术实现要素:发明目的:本发明目的是提供一种提高网络运维的效率,降低网络故障所造成的损失的基于深度学习的网络告警定位方法。该方法在网络节点互相调用而产生大量告警数据的环境下,将非根因节点所发出的告警信息进行筛选,最终实时定位出根因节点。技术方案:本发明提供的一种基于深度学习的网络告警定位方法,包括如下步骤:步骤1:搜集到历史的一个具体的时间区间内的告警信息样本数据,对这些样本进行重复告警信息删除数据预处理;步骤2:去除重复告警信息以后,对孤立节点的样本也进行筛选。筛选完以后对所有样本中的节点的告警信息进行归类,然后对根因告警信息种类进行统计。构建根因节点告警信息类别知识库;步骤3:将样本的节点信息和告警信息组合后输入基于分布式假设的词表示模型,最终得到样本的特征表示。每个样本中都包含了特征表示和根因节点标记两个信息;步骤4:将样本数据集中的根因标记按1和0分为两个子集。针对根因标记为1的子集中的样本,利用样本扩充方法将其样本数扩充至和根因标记为0的子集样本数一致;步骤5:将扩充后的数据集的样本中的特征表示作为lstm模型的输入,扩充后数据集的样本中的根因标记为lstm模型的输出,对模型进行训练,并且将模型以及其参数保存下来。得到输入为特征表示,输出为将此样本预测为根因节点的概率值的一个模型;步骤6:取得实际中搜集到的新的一天内的告警信息样本数据集。样本中数据的存储内容包含了该样本的节点和该样本的告警信息。按步骤3的做法,将新数据集中每个样本的节点和告警信息组合后输入基于分布式假设的词表示模型中生成每个样本的特征表示,得到其对应的特征表示集合;步骤7:将所有样本的特征表示输入步骤5中存储的模型,得到每个样本被预测为疑似根因节点的概率集合。将所有概率大于阈值的样本节点存储起来作为疑似根因节点集合;步骤8:将疑似根因节点集合中的节点所发出的告警信息与步骤2中所建立的根因节点告警信息类别知识库中的告警信息种类进行比对,将不存在于知识库中的节点删除。若疑似根因节点集合中没有元素,则直这一天没有根因节点。否则利用节点之间的距离关系和知识库筛选出根因节点。进一步地,所述步骤1的具体过程为:步骤11,将所有样本的节点告警信息、对应的节点和根因标记制作成包含节点、告警信息和根因标记的三元组格式存储,创建一个空的字典;步骤12,将一天内的告警信息放进队列;步骤13,判断队列是否为空,若为空,直接到步骤15,若不为空,则出队一个元素;步骤14,判断出队的元素是否存在于字典中,若存在则不做操作,若不存在则将其加入字典中。返回步骤13;步骤15,将字典中的所有元素存储起来,作为去除了重复告警信息的样本数据集。进一步地,所述步骤2的具体过程为:步骤21,根据每天的告警节点的连接关系制作成一个邻接矩阵,有连接关系的节点对应的矩阵位置的值置为1,没有连接关系的节点对应的矩阵位置的值置为0;步骤22,计算每个节点代表的行、列所有元素的和;步骤23,将行、列所有元素的和为0的节点去除;步骤24,剩下的样本中,将所有的样本的告警信息归类,存储进根因节点告警信息类别知识库中,并计算每个种类的出现频率。进一步地,所述步骤4的具体过程为:步骤41,设根因标记为1的子集为t1,根因标记为0的子集为t0。将t1内的所有样本之间的欧式距离计算出来,然后将每个样本最近距离的k个样本记录(本发明k取值优选为3)。得到了每个样本的k近邻(k=3);步骤42,创建一个空列表tnew;步骤43,若tnew与t1的样本数的和与t0样本数相同,直接跳到步骤46;步骤44,随机选取t1中的一个样本的节点和告警信息特征表示x,然后再将其k近邻的样本中随机抽取一个样本并取其节点和告警信息特征表示x′,利用以下公式计算出新样本的节点和告警信息特征表示xnew,其中rand(0,1)表示从0~1中随机取值;xnew=x+rand(0,1)|x-x|步骤45,将新构建出的xnew以及其根因标记构建成二元组,这里的根因标记值恒为1。加入tnew列表。作为新扩充的样本。返回步骤43;步骤46,将tnew的所有样本加入t1。进一步地,在步骤7的疑似根因节点集合生成以后,将疑似根因节点集合设为ss,所述步骤8的具体过程为:步骤81,新建一个空列表sc,将ss中所有节点的告警信息与步骤2中生成的根因节点告警信息类别知识库进行比对,保留ss中节点对应的告警信息种类存在于知识库中的节点;步骤82,若ss为空集,则说明这一天中没有根因节点,结束。若ss只有一个节点,则此节点为根因节点,结束;步骤83,将一天所有样本中的节点的连接关系制作成邻接矩阵,其中每条边的权值设置为1。根据连接关系,计算出ss与一天所有样本的节点的最短距离。并统计在根因节点故障传播范围(本发明设定为2跳以内)内的节点个数,然后形成包含节点和根因节点故障传播范围内节点数的二元组,并将其加入sc中;步骤84,取出sc中根因节点故障传播范围内节点数最大的元素,若元素唯一,则其元组对应的节点即为根因节点。否则则根据节点的告警信息种类在知识库中的出现频率的大小来选取根因节点,其中频率最大的告警信息种类对应的节点即为根因节点。有益效果:与现有技术相比,本发明具有如下优势:1、传统的告警信息根因节点定位技术一般采取告警关联的方法来实现,一般都需要有关联规则来实现,而不同的系统中可能有不同的告警信息规则,而本发明利用深度学习以及历史告警信息构成的知识库,不需要设计关联规则,只要是产生告警信息的系统都可以使用。2、网络告警信息中,根因样本数据一般远少于非根因样本数据。所以使用人工智能方法的时候,会产生样本类别不均衡问题,导致最后模型预测结果产生过拟合现象。本发明对训练集的根因告警信息样本进行扩充,将其扩充至与非根因告警信息样本数一致,解决样本类别不均衡问题。附图说明图1是节点连接关系示例图;图2是邻接矩阵示例图;图3是bert模型embedding层结构图;图4是bert模型网络结构图;图5是本发明实施方案前置准备流程图;图6是本发明实施方案流程图。具体实施方式本发明是在网络节点产生的大量的告警信息下,对无用以及重复告警信息进行筛选,准确定位发出根因告警信息的节点,提升网络运维的效率,降低网络故障产生的损失。利用深度学习辅助网络节点告警根因定位能够将大量非根因节点筛除,大大减少根因节点的定位时间。目前对于告警定位的方法比较稀缺,一般都是基于告警关联方法之后再进行根因筛选。常用的告警关联方法有基于案例或规则的推理专家系统、因果图、依赖图等方法。本发明将结合深度学习以及告警关联方法,通过深度学习方法将告警信息筛选出疑似根因节点集合,而后针对根因节点的特点在疑似根因节点集合中进行根因节点定位。每个主机节点之间有连接关系,这些连接关系错综复杂。如果其中一个节点发生了根本性的错误,那么与其相连的根因节点故障传播范围内的节点也往往可能发生错误。如图1所示,节点v0发生了故障,与其连接的根因节点故障传播范围内的节点v1、v2、v3、v4和v5也可能发生故障。搜集一个具体的历史时间区间内的告警信息日志,得到100组带有告警节点和告警信息的样本数据,每组中又包含若干条带有告警节点和告警信息的样本数据,并人工标记每条样本是否为根因节点,以此数据为训练集。同一个节点发生故障后可能持续发出告警信息,所以要将每组中相同节点且相同告警信息的样本去重,仅保留一条样本。然后将每组包含的节点的连接关系制作成一个邻接矩阵,以此观测出本组故障节点中是否存在孤立节点,将孤立节点的告警样本删除。经过去噪处理后,得到去噪后的训练集。将主机节点号与该节点的告警信息组合起来,同时通过基于分布式假设的词表示模型预训练后得到告警信息的词嵌入特征。由于根因节点一般而言只有一个或没有,而非根因节点却有许多个,这导致每组数据集中,根因节点和非根因节点的样本数很不均衡,所以需要使用数据扩充方法对根因节点样本进行数据扩充,将根因节点样本数量扩充至与非根因节点样本数一致。最终将扩充的样本和原样本合起来作为训练集。然后设计lstm模型,将训练集放入模型进行训练,得到一个可以筛选出一条样本信息是否为根因节点的模型。再找一组新的告警信息样本,在去噪和bert预训练步骤后,得到新的告警信息样本的词嵌入特征,将其输入训练好的模型中,得到预测结果,将预测结果为根因节点的样本中的节点做成疑似节点集合。根据训练集中根因告警信息的种类,制成一个(根因节点告警类型,出现频率)的知识库。将疑似节点集合中将疑似节点集合中所有节点的连接关系制成一个连接关系的邻接矩阵,每条边的权重视为1。使用dijkstra单源最短路径方法计算出疑似节点与本组所有节点之间最短距离小于2的节点个数。为了方便理解本发明的技术方案,下面定义一些概念:定义1重复告警信息一个节点出现故障后,会发出一种告警信息。但是节点故障如果没有被及时解决,间隔一段时间后,便会重复报告同一告警信息。所以同一天内,同一节点所发出的时间靠后的同一种告警信息的样本应当被去除。根据以上定义,将节点告警信息制成(节点,告警信息,根因标记)格式,创建一个一天内告警信息长度的字典。然后对一天内的(节点,告警信息,根因标记)存储进队列,然后对其进行遍历。具体实施步骤如下:①:若(节点,告警信息,根因标记)队列为空,则结束。否则队头元素出队。转至②。②:判断出队的(节点,告警信息,根因标记)是否存在于字典中,如果存在则回到①,否则将此(节点,告警信息,根因标记)加入字典中,回到①。定义2孤立节点一天发出告警信息的节点中,有的节点可能既没有被其他节点所连接,也没有连接其他节点,如图1所示,这种节点被称之为孤立节点。首先将一天内的所有发出告警信息节点的连接关系以邻接矩阵方式存储,然后对矩阵进行遍历,计算行和与列和,若有对应下标的行与列和均为0的节点,那么此节点必然没有连接其他节点,也没有被其他节点所连接,故而可以视为孤立节点。具体做法为,根据一天内的节点的连接关系形成连接关系的邻接矩阵,有连接关系的节点之间对应的矩阵值为1,没有连接关系的节点直接对应的矩阵值为0。如此一来,如图2邻接矩阵所示,若对应的节点的行和列和都为0,则可以视该节点为孤立节点。定义3去噪处理本发明的去噪处理为:将一天内的告警信息进行重复告警信息删除和孤立节点删除处理。定义4特征表示告警信息文本想要被计算机识别,就必须将文本的特征表示成能被计算机识别的格式。本发明面向的特征表示为利用基于分布式假设的词表示模型得到文本的特征表示。本发明以bert为例得到告警信息的词特征表示。bert方法是基于分布式假设的词表示,根据一定的方法将自然语言词语映射成词向量。分布式表示则是指特征向量中的每一个维度均不可被解释,而任何维度也不会对应到文本的具体特征。其每一个维度都是神经网络对文本的许多不同特征组合起来的新的特征。所以特征表示得到的词向量中的每一个向量都是文本的许多特征的组合。如图3所示,[cls]标志为对应最后隐藏状态下包含了后面所有词信息的一个标记。[sep]标志记录分句位置信息,但是本发明针对的告警信息中都是一句话,所以只会有一个尾部的[sep]标记。为第i个样本中告警信息的第j个字。将告警信息分别通过三个embedding层,ea为词向量embedding层(tokenembedding),eb为分句embedding层(segmentembedding),ec为位置embedding层(positionembedding)。ea负责将字映射成字向量,eb负责记录这是第几个句子,ec负责记录字的位置信息向量。然后将三个embedding层结果加起来,形成每个字的最终embedding。再将最终的embedding送入如图4所示的transformer结构中,最终得到样本的特征表示。定义5疑似根因节点利用lstm模型对输入的样本进行计算,得到该样本为根因节点的概率。设置一个阈值(本发明设为0.9),只要是预测出该样本为根因节点的概率大于这个阈值的,就被列为疑似根因节点。由一天内的所有疑似根因节点组成的集合为疑似根因节点集合。定义6根因节点告警信息类别知识库将训练集中足够多的根因告警信息进行统计,将同样类别的告警信息归类,统计出现的次数。由此形成如表1所示的根因告警信息类别知识库。表1根因告警信息类别知识库样本示例表告警信息类别告警信息内容告警信息出现频率0端口80通信异常0.248url:http://{节点号:端口号}//访问失败0.121ping丢包率100%服务器宕机0.08………利用深度学习方法找到了一天内的疑似根因节点集合后,对所有疑似根因节点发出的告警信息与知识库进行对比,如若不存在于知识库中,则直接筛除。定义7告警信息类别频率告警信息类别知识库构建以后,将每类告警信息的出现次数统计,并且利用公式(1)计算出告警信息某类的频率其中fi表示i种类的告警信息频率,ni为i种类告警信息出现的次数,n为总的根因告警个数。定义8根因节点故障传播范围网络拓扑中一个节点出现故障,往往会导致与其相连的其他节点也发生异常,进而产生大量告警,由于网络节点的合理设计,根因节点故障所导致的异常不会大范围传播,通常会有一个根因节点故障传播范围,在这个范围内的节点,可能会因为根因节点发生故障继而发生故障,也可能不发生故障。定义9根因节点标记该样本是否为根因节点的标记信息,若值为1,则说明该样本的告警信息为根因节点产生。若值为0,则说明该样本的告警信息不是由根因节点产生。本发明中使用的故障传播范围设定为根因节点前后两跳之内的节点。如图1所示,根因节点v0前后两跳内的节点v1、v2、v3、v4和v5为根因节点故障传播范围。通过本发明的方法,可以用深度学习的方法求得疑似根因节点。为了在疑似根因节点中进一步确定唯一的根因节点,本发明还将使用根因节点告警信息知识库以及节点的距离关系对疑似根因节点集合进行筛选。并且考虑到了根因节点在根因节点故障传播范围内的节点可能造成影响。本发明以某电商平台告警信息样本为例,确定新出现的某天内的根因节点告警信息定位。本发明的实施方案前置准备流程图如图5所示。其具体操作步骤如下:步骤1:搜集到历史的一个具体的时间区间内的告警信息样本数据,对这些样本进行重复告警信息删除数据预处理。具体对某一天的数据的重复告警信息预处理描述如下:①将节点告警信息制作成(节点,告警信息,根因标记)格式存储。创建一个空的字典。②将一天内的告警信息放进队列。③判断队列是否为空,若为空,转⑤,若不为空,则出队一个元素。④判断出队的(节点,告警信息,根因标记)是否存在于字典中,若存在则不做操作,若不存在则将其加入字典中。转③。⑤将字典中的所有元素存储起来,作为去除了重复告警信息的样本数据集。步骤2:去除重复告警信息以后,开始对孤立节点进行删除,将每天的告警信息中的节点的连接关系制作成一个连接关系的邻接矩阵。有连接关系的节点对应的矩阵位置为1,没有连接关系的节点对应的矩阵位置为0。如此一来,只需要找每个节点的行与列的和是否为0即可知道是否为孤立节点。若某个节点的行和列之和为0,则说明这是一个孤立节点。将孤立节点的样本数据删除。得到去除了重复告警信息和包含了孤立节点的样本数据集strain。strain里每个样本都是(节点,告警信息,根因标记)格式。然后根据strain中的根因节点的告警信息种类进行统计,形成一个根因节点告警信息类别知识库v。步骤3:将strain输入基于分布式假设的词表示模型。本发明以bert为例,将strain输入bert预训练好的模型,具体做法为将每一个样本的节点和告警信息组合后分别通过三个embedding层,ea为词向量embedding层(tokenembedding),eb为分句embedding层(segmentembedding),ec为位置embedding层(positionembedding)。ea负责将字映射成字向量,eb负责记录这是第几个句子,ec负责记录字的位置信息向量。然后将三个embedding层结果加起来,形成每个字的最终embedding。再将最终的embedding送入如图4所示的transformer结构中,最终得到样本的特征表示。其中,bert预训练的模型的参数是google团队所设定好的,只需要直接将节点以及告警信息输入便可以得到最终的特征表示集ttrain。ttrain里每个样本都是(节点与告警信息组合后的特征表示,根因标记)格式。步骤4:将ttrain按其根因标记将样本数据集分为t1和t0,其中t1为根因标记为1的样本,t0为根因标记为0的样本。接下来要对少量的根因节点告警样本集t1进行数据扩充,直到将t1数据集的样本数扩充至与t0样本数一致为止。具体做法为:①将t1中的所有样本之间的欧式距离计算出来,然后将每个样本最近距离的k个样本记录(本发明k取值为3)。得到了每个样本的k近邻(k=3)。②创建一个空列表tnew。③若tnew与t1的样本数的和与t0样本数相同,转⑥。④随机选取t1中的一个样本的节点和告警信息特征表示x,然后再将其k近邻的样本中随机抽取一个样本并取其节点和告警信息特征表示x′,利用公式(2)计算出新样本的节点和告警信息特征表示xnew,其中rand(0,1)表示从0~1中随机取值。xnew=x+rand(0,1)|x-x|(2)⑤将新构建出的xnew构建成(xnew,根因标记),加入tnew列表。作为新扩充的样本。转③。⑥将tnew的所有样本加入t1。步骤5:将t1与t0合并成tnew_train,将tnew_train作为训练集,输入lstm神经网络模型,进行训练,得到输入为节点与告警信息特征表示,输出为预测为根因节点的概率值的一个模型的参数,将模型以及其参数保存为m。到此,本发明的实施方案前置准备已经完成。本发明的实施方案流程图如图6所示。其具体操作步骤如下:步骤6:取得实际中搜集到的新的一天内的告警信息样本数据集stest。stest中数据的存储格式为(节点,告警信息)。按步骤3的做法,将stest中每个样本的节点和告警信息组合后输入基于分布式假设的词表示模型中生成每个样本的特征表示,得到stest对应的特征表示集合ttest。步骤7:新创建一个空列表ss,将ttest的所有样本输入进步骤5中得到的模型m,得到所有样本被预测为根因节点的概率。设置一个阈值(本发明设置为0.9),将预测结果大于阈值的样本节点存入ss。得到疑似根因节点集合ss。步骤8:新创建一个空列表sc。将ss中所有节点的告警信息与v中的告警信息进行比对,去除掉不存在于v中告警信息种类节点。再判断若ss为空集,则说明这天没有根因节点,否则若ss只有一个元素,则那个节点即为根因节点。若ss中不止一个元素,则将stest中所有节点的连接关系制作成邻接矩阵。每条边的权值设置为1。为了得到节点之间的距离,利用dijkstra方法计算ss中的节点与stest中的节点之间的距离,并统计距离小于根因节点故障传播范围(本发明设定为2跳以内)的节点个数。最终形成(节点,根因节点故障传播范围内节点数)元组,并将元组加入列表sc。取出sc中根因节点故障传播范围内节点数最多的元素集合vmax,若vmax中元素唯一,则那个节点则为根因节点。若元素不唯一,则根据v中告警信息出现频率的大小选取根因节点,选取出现频率最大的那个告警信息种类对应的节点即为根因节点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1