一种基于卷积自动编码算法的图像压缩硬件加速器装置的制作方法
本发明涉及计算机及电子信息技术领域,特别是涉及一种基于卷积自动编码算法的图像压缩硬件加速器装置。
背景技术:
图像作为人类感知世界的视觉基础,其压缩技术一直是数字信号处理的重要问题。图像压缩的目的是在保证准确性的前提下,通过对图像的压缩来减少表示数字图像需要的数据量。图像压缩的本质是在像素层面上以更少的编码比特率实现更高质量的图片重建任务。图像压缩按照压缩方式可分为有损压缩和无损压缩两大类技术。无损图像压缩技术因为在解压之后能够保证图像的完整性,故在对图像精度要求高的领域有着广泛的使用。有损图像压缩技术在保证图像重要信息完整性的前提下通过舍弃不必要信息实现图像压缩目标。有损压缩相对于无损压缩具有更高的压缩比例,而在一般对精度要求不高领域显然无损压缩更受欢迎,在日常生活中的使用也更加广泛。传统的有损图像压缩存在着如下缺点:1)压缩比例较低,无法满足部分严苛场景下的图像压缩需求以及传输、储存等应用目的;2)压缩方式单一,通常是依靠变换、量化和熵编码方法,无法将图像内容作为影响因素离列入压缩任务中,导致解压后图像重建质量无法达到最大程度的提高。
近年来,深度学习方法在图像处理领域大放异彩。在图像压缩方面,利用深度学习网络替代传统的变换、量化和熵编码过程,可以构建出端到端的压缩方案。自动编码算法作为处理高维数据的非监督深度学习算法,应用到图像压缩领域时能够将图片内容作为压缩过程中的影响因素,实现更高的压缩比和更好的解压重建效果。由于受到计算复杂度的影响,现阶段应用于图像压缩方法中的自动编码算法,特别是结合了卷积神经网络的自动编码算法,在推广和应用上面临着算力约束和资源约束等一系列挑战。
鉴于自编码算法应用于图像压缩的优点和缺点,本发明创作者通过研究解决算法的硬件实现中的资源耗用过多的问题,设计出了本发明的加速器装置。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种基于卷积自动编码算法的图像压缩硬件加速器装置。本发明针对图像压缩特别是高分辨图像压缩的卷积自动编码算法的硬件实现,提出了一种并行化处理和卷积拆分的周期性加速方案,将传统的依赖移位寄存器构建卷积窗口的方案转换为周期性执行的拆分卷积子窗口方案,能够降低内存资源的占用,同时迎合图片按行读取的数据特性。本发明的特点是并行度高、资源占用低,特别是相比采用移位寄存器卷积窗口方案能够最大程度地降低资源占用。同时由于摒弃了移位寄存器方案,在降低处理延时方面具有了一定的优势,并且针对不同的自动编码算法具有较好的通用性和可实施性。
本发明所采用的技术方案是:
1.独立的控制单元,主要包含存储单元控制模块和逻辑计算加速单元的控制模块;
2.逻辑计算加速单元,主要包含复用处理器、周期并行卷积计算单元和计算加速单元组成的卷积计算阵列。复用处理器,用以执行对输入像素神经元的接受和最终结果的打包输出,完成卷积结果的激活函数和池化操作等。周期性并行卷积单元和计算单元组成的卷积计算整列通过增加并行度和周期性的卷积拆分计算策略完成卷积操作和加法树操作等;
3.存储单元,主要包括像素存储器、权值存储器、结果存储器和片外动态存储。像素存储器用以储存部分输入的待压缩图像和特征图像。权值存储器用以储存需要的卷积核的部分权值。结果存储器用于存储卷积计算的部分结果。片外动态存储用于储存全部的卷积核权值和需要处理的完整图像以及最终的计算结果,并在控制单元的控制下将所需部分图像和部分权值读入到片上存储,并且把计算结果从片上读出到片外动态存储。
与现有技术相比,本发明的有益效果是在对自动编码算法压缩图像实施硬件加速的同时,相比传统的使用移位寄存器构建卷积窗口,拆分卷积方法的周期性并行卷积计算单元,能够在使用更少的内存下实现更良好的加速效果。特别是针对高分辨的图片,例如4k图片(分辨率为3840*2160),过大的横向像素数导致使用传统的移位寄存器方法将导致耗费大量的片上内存来存储图像数据,影响资源利用和处理延迟,甚至导致设计方案不可行。采用周期性并行卷积计算单元,可以实现针对单行数据进行卷积操作。通过对卷积过程的拆分,降低了资源占用和处理延时。
附图说明
图1为本装置的顶层硬件架构图;
图2为控制单元的运行程序流程图;
图3为逻辑计算加速单元的架构图;
图4为周期性并行卷积单元的卷积窗口和卷积拆分的周期性工作原理示意图;
图5为存储单元的架构图。
具体实施方式
下面结合附图和对本发明的具体实施作更进一步说明。其中自始至终使用相同的名称表示相同或有类似功能的模块。下面通过参考附图描述的实施示例来具体地说明本装置。实施示例选取了分辨率为4k(3840*2160)的图像并且利用了本装置的周期性并行卷积加速能力处理压缩任务,旨在解释本发明,而不能理解为对本发明的限制。
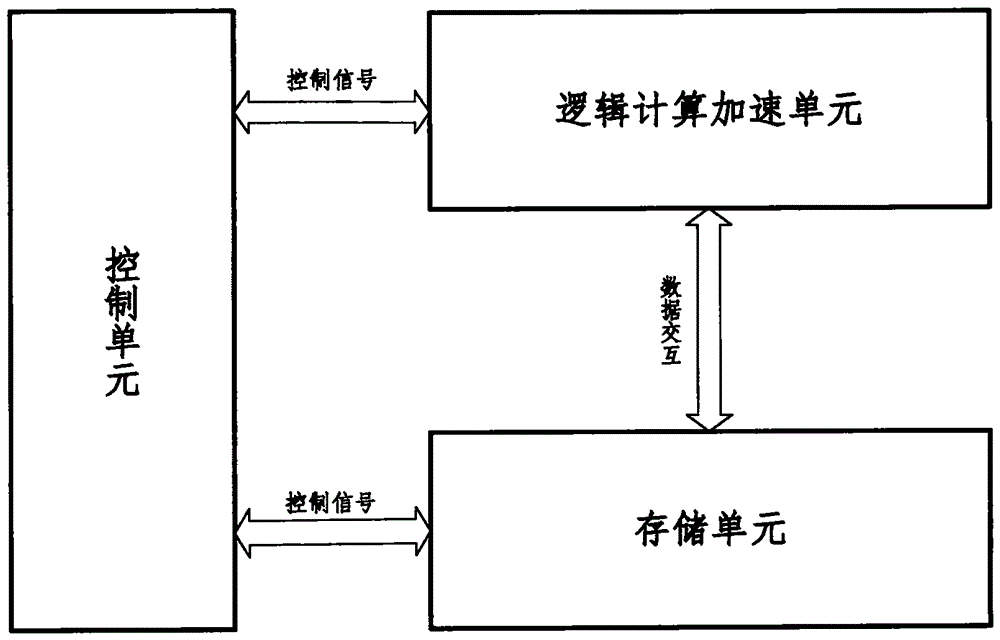
如图1所示为本发明装置的顶层硬件架构图。该种基于卷积自动编码算法的图像压缩硬件加速器装置包含了:
1.控制单元:负责针对存储和计算单元之间的数据交互进行控制;负责对计算单元计算过程进行控制;
2.逻辑计算加速单元:负责完成输入像素神经元的接受、完成卷积操作、加法树操作、激活操作和池化操作等;
3.存储单元:负责存储逻辑计算加速单元需要的部分待压缩的图片、特征图片以及部分权值;负责存储逻辑计算加速单元的部分结果;负责存储计算需要的全部卷积核权值和待处理的完整图像。
如图2所示是控制单元的运行程序流程图,完整的4k图像和卷积核权值存储在片外动态存储上,整个控制流程包括:
1.控制单元控制存储单元将部分图像和部分权值从片外动态存储读取到像素存储器和权值存储器;
2.逻辑计算加速单元的卷积计算加速阵列从像素存储器和权值存储器读取需要的图片数据和权值数据,其中图片数据读取的时候按照逐行读取的方式读入;
3.由于涉及到周期性计算和卷积拆分策略,逻辑计算加速单元需要判断读取的数据是否是原始图片上同一行像素的数据。若返回值为否,则需要执行第2步继续读取需要的图片数据和权值数据;若返回值为是,则计算阵列开始执行计算过程;
4.完成计算过程后,逻辑计算加速单元需要判断是否完成了对应卷积核的卷积窗口数据计算。若返回值为否,则返回第2步直至完成对应的卷积窗口;若返回值为是,则将对应卷积窗口的计算结果送至复用处理器进行激活函数操作和池化操作等;
5.判断是否完成了全部的图像处理任务。若返回值为否,则返回第1步继续执行计算加速任务;若返回值为是,则完成了所有的计算加速任务,整个计算过程结束。
如图3所示是逻辑计算加速单元的架构图,是本加速器装置的计算核心,其工作流程包括:
1.输入待处理的像素数据和权值数据到卷积计算阵列;
2.卷积计算阵列对输入的像素和权值进行周期性的高并行度的计算,其中通过部署多个周期并行卷积计算单元(图中的pe)来提高并行度;通过卷积拆分的方式实现周期性卷积,具体细节在图4中做出详细的解释;
3.卷积计算加速阵列完成计算后将卷积结果输出到复用处理器;
4.复用处理器接受卷积结果并通过内部的激活函数模块和池化模块完成激活操作和池化操作;
5.复用处理器完成计算任务后将最终结果输出。
如图4所示是逻辑计算加速单元中的周期性并行卷积方法中的一个计算单元对应的卷积过程(以8*8维度的卷积核为例),其具体过程包括:
1.将待压缩的图像数据按照逐行形式读入,如图中所示的步骤0至7是分别对应8行像素数据;
2.以步骤0为例,将8*8维度的二维卷积核拆分为8个8*1的子卷积核,每个子卷积核的计算对象对应着待处理图像中的一整行像素;
3.执行步骤0时,首先读取子卷积核0和步骤0对应的行像素数据,在对应位置执行卷积操作,并将卷积过程的结果作为中间结果进行缓存。针对原始图像的3840个像素,在non-overlap的模式下,随着像素数据沿着位移方向移动,对应8*1维度的子卷积核计算会产生480个中间结果,记作中间结果0;
4.完成步骤0之后,继续执行步骤1。首先读取步骤1像素行数据和对应的子卷积1,然后经过卷积计算产生480个中间结果,记作中间结果1;
5.完成步骤1之后需要将中间结果0和1相加记作缓存结果;
6.继续重复上述过程执行步骤2到步骤7,逐步骤缓存中间结果2到7,并与上一步中的缓存结果执行相加操作直到加和完中间结果7,此时获得卷积窗口对应8行数据计算的最终结果,表示一个计算周期结束,获得了3840*8个像素针对8*8卷积核的480个卷积计算结果;
7.继续读取下一个周期需要的数据完成下一个执行周期,重复执行周期性卷积计算过程,直到完成所有的计算任务,获得480*270个卷积计算结果。这就是周期性执行计算加速的计算策略。
如图5所示,为存储单元的架构图,其结构和工作流程包括:
1.所有的待压缩的图像数据和权值数据都存储在片外动态存储上;
2.片外动态存储通过动态存储通信接口与片上存储相连接;
3.片上存储包括权值存储器、图像存储器和结果存储器,分别对应存储待处理的部分权值数据、部分图像数据和经过逻辑计算加速单元计算所得结果;
4.逻辑计算加速单元通过计算权值存储器所输入的权值数据和图像存储器所输入的图像数据,将最终的计算结果输出到结果存储器。
以上所述内容仅为本发明装置的较佳实施例,对本发明而言仅仅是说明性的。本专业技术人员理解,在本发明权利要求所限定的范围内可对其进行诸多变化、修改乃至等效,但都应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!