一种车联网中自适应联合计算卸载与资源分配方法与流程
本发明属于车联网计算领域,涉及一种车联网中自适应联合计算卸载与资源分配方法。
背景技术:
随着c-v2x中自动驾驶汽车数量的增加,各种计算密集型和对延迟敏感的应用兴起,例如图像辅助导航和增强现实驾驶,这些应用需要大量的计算资源用于实时处理和分析大量传感数据,这给计算资源有限的车辆带来了巨大挑战。
通过把计算任务卸载到其他计算节点,可以有效解决车辆计算资源有限问题。远端云服务器计算资源丰富,但是距离车辆较远,会产生巨大的传输时延和能耗。mec服务器将计算下沉到路边设备单元,更靠近车辆,使得时延和能耗更低,然而mec服务器的计算资源有限,如果当前rsu下车辆过多,也会导致时延增加。
现有研究中,多数只考虑单辆车任务卸载,很少研究多辆车计算任务的同时卸载;大部分只考虑了时延,而没有考虑能耗。卸载决策时也基本只考虑卸载到一个平台,而不是卸载到多个计算平台,也没有在卸载决策的同时进行资源分配。事实上,大多是多辆车并发卸载,对于计算资源有限的mec服务器是很难满足最大容忍时延,所以需要考虑多个计算平台的卸载,以及资源的合理分配,对于绿色车联网来说考虑能耗也是十分有必要的。
技术实现要素:
有鉴于此,本发明的目的在于提供一种车联网中自适应联合计算卸载与资源分配方法。
为达到上述目的,本发明提供如下技术方案:
在多个车辆并发卸载场景下,根据车辆的带宽、任务的大小、最大容忍时延、车辆发射功率,构建车辆的网络模型、任务模型、计算模型包括:
(1)车辆网络模型:车辆上传链路的信道是瑞利信道模型,车辆vi与bs之间的上传/下载的数据速率为
其中,h1,h2,b1,b2,
(2)任务模型:车辆vi需要卸载的计算任务si为可分型,定义
(3)本地车辆计算模型:si在本地车辆执行的计算任务量为
其中,pi表示车辆vi的设备功率。
(4)mec计算模型:si在mec执行的计算任务量为
其中,pmec是mec服务器的设备功率,
(5)远端云服务器计算模型:卸载到远端云服务器就需要先卸载到bs然后由光纤卸载到远端云服务器。定义在远端云服务器的执行时延为
其中,pcloud表示远端云服务器的设备功率,pbs表示基站的发射功率。
(6)空闲车辆计算模型:卸载到空闲车辆的执行时延为
其中,pidle表示空闲车辆的设备功率。
进一步的,将所有车辆的时延与能耗进行加权得到系统总成本,建立满足最大时延容忍的最小化系统总成本的约束优化问题与资源分配模型:
车辆的联合卸载的总时延t,总能耗e,定义联合卸载系统的成本为h。
h=γ·t+(1-γ)·e
其中,γ为时延权重系数,(1-γ)为能耗权重系数。
在满足任务si最大容忍时延
其中,d为卸载决策矩阵,f为mec服务器的计算资源分配向量,表示为
为了在做卸载决策的同时进行资源分配,获得每辆车卸载到各个计算平台的任务比例,以及mec分配给车辆的计算资源,提出粒子矩阵编码方式包括:
每辆车的优化参数有5个,分别是
为了解决上述模型的整数约束,提出的粒子修正算法包括:
将矩阵a的每一行取出,再还原成粒子的编码矩阵m,在把粒子编码矩阵的每一行取出,进行修正,即使得每辆车的任务满足
为了解决系统的任务卸载和资源分配模型中的等式与不等式约束,利用压缩粒子群算法结合罚函数法处理约束包括:
惩罚函数为:
p(q)=θ(q)·qγ(q)
其中,q是相对约束惩罚函数,θ(q)是分段赋值函数,γ(q)是惩罚指数。适应度函数为目标函数加上惩罚函数:
本发明的有益效果在于:本发明综合考虑了每个车辆任务的大小、最大容忍时延、rsu下的计算资源,网络带宽。并且能够根据当前rsu的任务数自动调整卸载平台和最优卸载比例,在获得卸载比例的同时对mec的计算资源进行了分配。通过实验仿真,验证了本发明能有效降低系统总成本。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为本发明的系统模型;
图2为本发明的求解流程图;
图3为本发明的粒子编码矩阵示意图;
图4为本发明改进的粒子群算法流程图;
图5为不同算法下,系统总成本与每辆车计算任务量的曲线图;
图6为不同算法下,系统总成本与车辆数的曲线图;
图7为不同算法下,系统总成本与输出数据量系数的曲线图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
本发明提供一种车联网中自适应联合计算卸载与资源分配方法,包括:
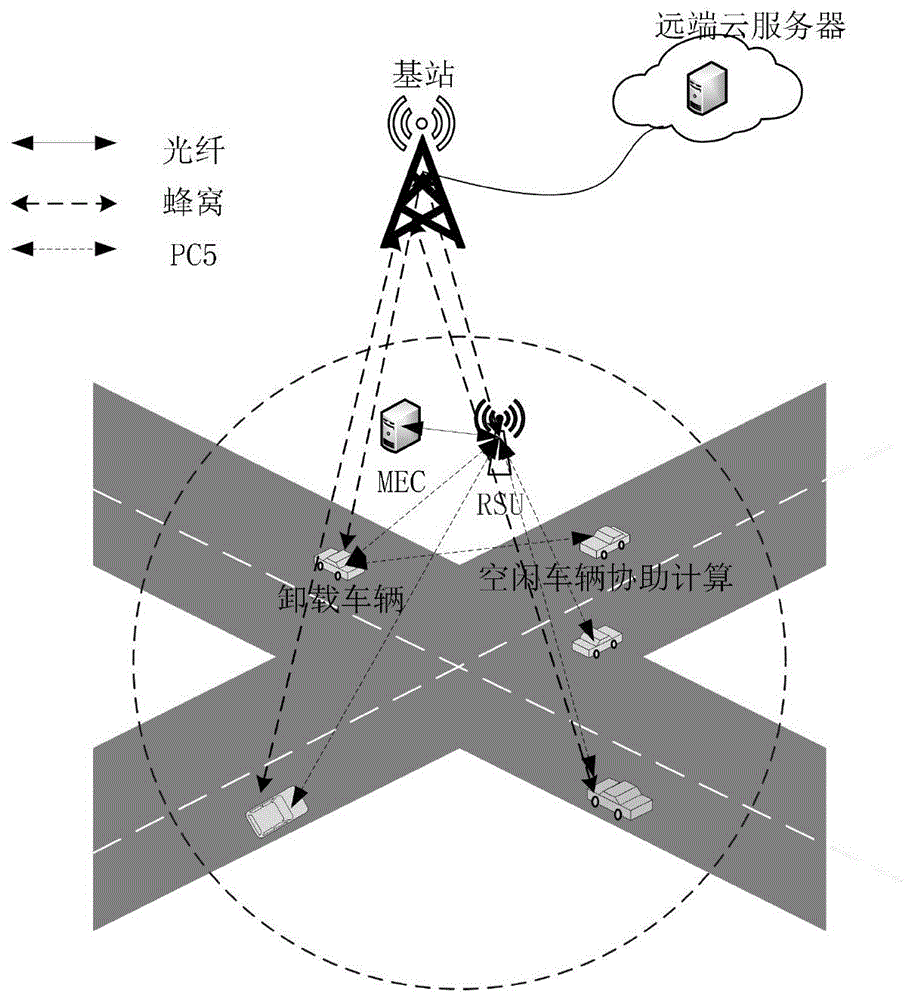
步骤1:如图1所示,卸载车辆的计算任务可以在本地计算,可以卸载到当前rsu下的空闲车辆vidle计算,可以卸载到配备有mec服务器的rsu上计算,也可以通过蜂窝网卸载到远端云服务器计算。图2为本发明的求解流程图;因此,构建车辆的网络模型如下:
多辆车同时卸载任务,定义当前rsu覆盖下有计算任务需要卸载的车辆集合为v={v1,v2,…,vn},每辆车都有一个计算任务需要卸载,对应的任务集合为s={s1,s2,…,sn},空闲车辆的集合为c={c1,c2,…,ck}。车辆上传链路的信道是瑞利信道模型,车辆vi与bs之间的上传/下载的数据速率为
其中,h1,h2,b1,b2,
步骤2:构建车辆的任务模型,如下:
车辆vi需要卸载的计算任务si为可分型,定义
由于任务可以在本地、mec服务器、远端云服务器、空闲车辆进行计算,所以需要对任务进行划分,并且确定卸载到哪些平台,以及卸载多少。定义卸载决策矩阵为:d=[d1,d2,…,dn],其中
步骤3:根据上述的网络模型,以及任务模型,建立四个计算平台的计算模型如下:
(1)本地车辆计算模型:si在本地车辆执行的计算任务量为
其中,pi表示车辆vi的设备功率。
(2)mec计算模型:si在mec执行的计算任务量为
其中,pmec是mec服务器的设备功率,
(3)远端云服务器计算模型:卸载到远端云服务器就需要先卸载到bs然后由光纤卸载到远端云服务器。定义在远端云服务器的执行时延为
其中,pcloud表示远端云服务器的设备功率,pbs表示基站的发射功率。
(4)空闲车辆计算模型:卸载到空闲车辆的执行时延为
其中,pidle表示空闲车辆的设备功率。
步骤4:通过上述步骤,进一步的将所有车辆的时延与能耗进行加权得到系统总成本,建立满足最大时延容忍的最小化系统总成本的约束优化问题与资源分配模型:
车辆的联合卸载的总时延t,总能耗e,定义联合卸载系统的成本为h。
h=γ·t+(1-γ)·e
其中,γ为时延权重系数,(1-γ)为能耗权重系数。
在满足任务si最大容忍时延
其中,d为卸载决策矩阵,f为mec服务器的计算资源分配向量,表示为
c1表示车辆vi确定把任务si要卸载到本地,mec服务器,远端云服务器,空闲车辆的任务比例相加为整个任务;c2表示完成每辆车的任务的时间不应超过最大容忍时延;c3表示能卸载到空闲车辆的最大数目;c4表示为每个车辆分配的计算资源不能超过mec服务器的总资源;c5表示为车辆任务分配的计算资源总和不能超过mec服务器的总资源。
步骤5:为了在做卸载决策的同时进行资源分配,获得每辆车卸载到各个计算平台的任务比例,以及mec分配给车辆的计算资源,提出粒子矩阵编码方式如下:
每辆车的优化参数有5个,分别是
步骤6:为了解决步骤4中建立的系统的任务卸载和资源分配模型中的整数约束,提出的粒子修正算法如下:
(1)将矩阵a的每一行取出,再还原成粒子的编码矩阵m。
(2)从m矩阵中逐次取出每一行,如果
(3)从m的第四列中选出idealcar个最大的数,其余赋值为0。
(4)从取出的这一行中依次取出每辆车的5个参数
(5)
(6)把矩阵m的第2列相加得到所有卸载到mec服务器的任务量sum。
(7)每辆车从mec服务器获得的计算资源
(8)再把矩阵m转化为1行,放入矩阵a中的相应行。
其中,idealcar空闲车辆数。
步骤7:为了解决系统的任务卸载和资源分配模型中的等式与不等式约束,利用压缩粒子群算法结合罚函数法处理约束如下:
惩罚函数为:
p(q)=θ(q)·qγ(q)
其中,q是相对约束惩罚函数,θ(q)是分段赋值函数,γ(q)是惩罚指数。适应度函数为目标函数加上惩罚函数:
最后的得到改进的粒子群算法流程图,如图4所示。
从图5可以看出,随着计算任务量的增加,五种算法的系统总成本也随着增加。但是,本发明所提算法的增加的幅度最小,并且系统总成本明显低于其他四种算法。约是全部本地卸载算法的22.09%,全部mec卸载算法的38.66%,随机卸载算法的27.8%,传统联合卸载算法的68.80%。
从图6可以看出,随着车辆数的增加,五种算法的系统总成本都呈现上升趋势。本发明所提算法相比其他算法,具有最小的系统总成本。其中全部mec卸载算法在车辆数为20时出现突增,是因为当车辆数超过一定值时,导致mec分配给每辆车的计算资源还没有本地高,所以会出现比本地计算的系统总成本还高。
从图7可以看出,随着输出数据量的增加,除了全部本地卸载算法外,其他所有算法的系统总成本都增加。因为本地计算不存在计算结果的返回时延,所以全部本地卸载算法的系统总成本保持不变。而其他算法的影响也较小,是因为只有卸载到mec,远端云服务器,空闲车辆才有结果返回时延,而计算结果的返回量相对较小,所以对系统成本影响不大。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!