一种端到端云服务延迟的计算方法与流程
本发明涉及一种端到端云服务延迟的计算方法,属于互联网技术领域。
背景技术:
大部分云服务提供者利用虚拟化技术实现物理资源共享,例如,amazonec2和gogrid利用xen虚拟化(文献[1])支持单物理服务器上多个虚拟机实例(文献[2-3])。虚拟技术的一个重要特征是通过物理资源(如处理器、i/o接口)虚拟化实现单个服务器被多个性能独立的平台,即虚拟机器(virtualmachine,vm)共享。研究人员通过大量研究指出虚拟化技术对云服务计算和通信性能产生严重影响。如文献[4]通过amazonec2与其它internet位置服务器进行通信,测量了虚拟化技术对s3(即simplestorageservice)服务的吞吐量和延迟等性能的影响,文献[5]在应用层比较了amazonec2和其它高性能计算集群在大规模科学计算方面的性能,研究结果显示amazonec2的性能比传统的科学计算集群(如ncsa[6])更差一些。基于经验值测量技术,文献[7]讨论了amazonec2实例端到端通信性能,并深入分析了大数据中心虚拟化技术对网络性能的影响。作者重点分析了由于终端主机虚拟化技术引起的延迟抖动异常偏大和tcp/udp吞吐量极不稳定等性能问题,这些发现有助于解释文献[8]所发现的异常现象。文献[7]研究指出:当前vm监视器的实现技术无法提供足够的性能隔离来确保运行在单个物理主机上的多个vm实例间资源共享的有效性,特别是当运行在相邻机器上vm的应用系统用于计算通信资源时,这种现象更为严重。近年来,markov过程和队列理论在云服务质量分析领域得到越来越多研究人员的重视,如文献[9]利用连续时间markov链(ctmc)分析了三个不同的虚拟机器随机结构,即负载均衡服务器结构(loadbalanceserverarchitecture,lbsa)、隔离组件服务器架构(isolatedcomponentserverarchitecture,icsa)和拜占庭容错服务器架构(byzantinefaulttolerantserverarchitecture,bftsa),并分析了其稳定状态分布和瞬时行为的特性。与本专利计算原理相似的工作有两个,即文献[10]和文献[11]。
文献[10]的应用场景是:所有服务请求都发送到云计算中心,云计算中心通过合适的计算节点(计算节点包括不同的计算资源,如web服务器、数据库服务器、目录服务器等等)提供相应的服务,服务完成后离开云计算中心。在文献[10]中,云计算数据中心通过m/g/m/m+r队列系统进行建模,模型假设服务请求到达服从泊松分布,作业服务时间为随机独立分布,即均值为μ的一般分布,服务器数为m,服务调度策略为先来先服务(fcfs:firstcomefirstservice),到达的服务请求大小为r,系统缓存大小为m+r。该技术主要用于分析服务响应时间的分布特性,其应用前提是假设服务请求到达时间间隔和服务时间均为指数分布。基于该假设,文献[10]研究了最大作业请求数目、最小服务时间和最高服务等级之间的函数关系。然而,由于无法得到响应时间的分布函数,以及m/g/m系统队列长度的精确求解仍然存在困难,因而,文献[10]中的模型只能得到合理的近似解。而且,文献[10]只考虑了单个类型作业到达的情形。
文献[11]是以加拿大哥伦比亚省的克洛纳综合医院(kgh:thekelownageneralhospital)急诊部门的紧急床位服务为应用背景:假设急诊部门提供三种类型紧急床位和两种等级的服务,病人到达速率是周期性随机变化的,紧急床位的服务时间为随机分布,讨论了如何使紧急床位的提供时间和服务质量(作者认为担架上等待服务的病人越少,服务质量越好)达到最优控制策略问题。文献[11]采用的技术是:通过m(t)/m/c/c队列对上述随机过程建模,病人到达速率为一个周期变化的m(t)函数,m表示每个作业的服务时间为指数分布,c表示病床数量。该技术定义了一个费用函数,费用函数主要包括三个部分:启动紧急病床时间、运行紧急病床时间和病人在担架上的时间。为此,需要求解队列方程的瞬态解,该技术采用四阶龙格-库塔法(thefourth-orderrunge–kutta)计算队列微分方程的瞬态解。该技术虽然是针对医院急诊部门紧急床位的随机过程建模,但对于任何一个符合上述假设的、到达速率和服务器变化的随机过程,该技术都是适用的,如internet服务等。该技术的主要缺陷在于,它是针对两种服务等级的随机模型,即根据到达的作业数数量提供两种不同服务质量的服务器,实际上,云计算服务环境都是多作业类型,且提供多服务器类型的应用场景。因此,对于多类型服务器的云计算中心是不适用的。
参考文献:
[1]abenil,faggiolid,anexperimentalanalysisofthexenandkvmlatencies,ieee22ndinternationalsymposiumonreal-timedistributedcomputing(isorc2019),pp.18-26,valencia,spain,2019.
[2]anjum,a,abdullah,t,tariq,mf,baltaci,y,antonopoulos,n,videostreamanalysisinclouds:anobjectdetectionandclassificationframeworkforhighperformancevideoanalytics,ieeetransactionsoncloudcomputingvol.7,issue4,pp.1152-1167,2019.
[3]zhangrr,xiaox,studyofdanger-theory-basedintrusiondetectiontechnologyinvirtualmachinesofcloudcomputingenvironment,journalofinformationprocessingsystems,vol.14,issue1,pp.239-251,2018.
[4]landonim,genonim,rivam,biancoa,corinaa,applicationofcloudcomputinginastrophysics:thecaseofamazonwebservices,proceedingsofspie-theinternationalsocietyforopticalengineering,softwareandcyberinfrastructureforastronomyv,vol.10707,2018.
[5]emerasj,varrettes,plugaruv,bouvryp,amazonelasticcomputecloud(ec2)versusin-househpcplatform:acostanalysis,ieeetransactionsoncloudcomputing,vol.7,no.2,p456-468,2019.
[6]minskerb,myersj,marikosm,wentlingt,downeys,liuy,bajcsyp,kooperr,marinil,contractorn,greenharoldd,futrellej,ncsaenvironmentalcyberinfrastructureforenvironmentalengineeringandhydrologicalsciencecommunities,proceedingsofthe2006acm/ieeeconferenceonsupercomputing,sc'06,tampa,fl,unitedstates,november11-17,2006.
[7]mehrotrap,djomehrij,heistands.etal.,performanceevaluationofamazonelasticcomputecloudfornasahigh-performancecomputingapplications,concurrencyandcomputation-practice&experience,vol.28,issue4,pp.1041-1055,2016.
[8]l.vaquero,l.rodero-merino,j.caceres,andm.lindner.abreakintheclouds:towardsaclouddefinition,acmsigcommcomputercommunicationreview,vol.39,no.1,pp.50-55,2009.
[9]t.atmaca,t.begin,a.brandwajn,andh.castel-taleb.performanceevaluationofcloudcomputingcenterswithgeneralarrivalsandservice,ieeetransactionsonparallelanddistributedsystems,vol.27,no.8,pp.2341-2348,august2016.
[10]zhoua,wangs.hsuc-h,etal.,networkfailure-awareredundantvirtualmachineplacementinaclouddatacenter,concurrencyandcomputation-practice&experience,vol.29,issue24,2017.
[11]optimalpoliciesofm(t)/m/c/cqueueswithtwodifferentlevelsofservers.europeanjournalofoperationalre-search,249(3),1124-1130,2016.
技术实现要素:
本发明是为解决上述问题而提出的,其目的在于,
一种端到端云服务延迟的计算方法,包括如下步骤:
步骤一:端到端多作业请求转换为多队列系统;
每个用户请求随机到达云接纳控制系统,接受的作业进入rp&ddm等待虚拟资源分配,将用户请求到达过程视作一个多队列系统,qreq表示系统中所有用户请求队列;进入接纳控制系统的请求队列称为请求上行队列,而从rp&ddm出来的请求队列称为请求下行队列;
每个用户都有一个对应的请求上行队列和请求下行队列,并设
步骤二:多队列系统基于分层ctmc建模;
定义所有请求上行队列和请求下行队列的容量均为q,λ1=λ2=…=λm且μ1=μ2=…=μm,则
步骤三:端到端应用延迟计算;所述端到端延迟包括队列qreq等待延迟、资源部署延迟和执行时间。
优选的,该云服务系统包括接纳控制系统和全域资源提供与部署决策系统rp&ddm,定义该云服务系统中用户数为m,m>0,每个用户有n个不同类型的服务请求,即作业,n>0,每种类型请求都要求一个特定的虚拟机资源配置,即vm-配置,虚拟资源共享底层物理资源,每一个vm-配置表示一个虚拟资源组合;接纳控制系统判断能否满足用户作业的资源请求,云计算中心通过rp&ddm创建、分配和释放vm-配置;
云服务系统中服务器个数为l,每个服务器能提供n种类型vm-配置,类型k的用户请求表示为reqk,类型k的作业请求要求一个类型k的vm-配置(表示为vmk),
进一步的,所述
所述服务器状态的定义:给定一个服务器i,如果
对于rp&ddm状态的定义:设h是rp&ddm中l个服务器集合,如果在集合h中至少有一个服务器在给定的时隙间隔内对于reqk是active的,即
设s={active,passive}为rp&ddm的状态集合,在时刻t,rp&ddm可能处于在active状态或passive状态;处于active状态时,到达的请求可以立即处理;处于passive状态时,到达的请求只能在rp&ddm中pm重新部署后才能处理;在passive状态到达的请求,用户需要等待一个额外pm部署延迟,一旦进入active状态,所有排队的请求都将被处理;如果一个服务器有足够的vm-配置,队列头部的用户请求将立即得到满足;如果没有符合要求的vm-配置可用,则该请求将被拒绝;当正在运行的请求退出时,则立即释放该vm-配置使用的所有资源,并变为可用资源,提供给下一个用户请求;rp&ddm状态由rp&ddm中服务器的状态共同决定,而每个服务器根据两状态markov链以概率pxy转移,其中,x,y={0,1},状态1和0分别表示服务器是active状态或passive状态;
设
进一步的,所述步骤二中,状态空间λ建模的过程为:状态空间λ的状态可以表示为一个组合:(y(t),st),其中,y(t)={0,1,2,···,q},st={0,1};令
进一步的,所述步骤二中,状态空间
a、作业请求离开概率
两个连续请求到达的时间间隔内,表示为τ,每个服务器中每类型请求将有零个或多个离开,为不失一般性,设
其中,λik是k型请求的到达服务器i的速度,
其中,
其中,
b、计算
设p=[pij],其中,
c、计算稳态概率
设πik=(πik(0,s);πik(1,s);…;πik(q,s))是qik的稳态概率分布,即,
为了求得该平衡分布方程的解,需要解以下线性方程:
其中,p是转移概率矩阵。
进一步的,所述步骤b中pij的算法如下:
step1.当j>i+1,有pij=0;
step2.当i=0且j=0,即qik中没有请求等待,且没有请求到达,有:pij=0;
step3.当i=0且j=1,即qik中没有请求等待,因而,有:
step4.当i,j≥1且i-j≥1,即服务器在整个时间片内处于忙的状态,因而,有:
step5.当i≥1且j=0时,表示在时刻t所有的服务器都处于忙的状态,同时队列qik中有i-1个服务请求在等待,而在接下来的t+1时刻,qik没有请求等待,所有请求都离开服务器;此时,转移概率为:
进一步的,所述步骤三中,队列等待延迟的计算方法为:设tw表示在稳定状态下作业的等待时间,w(x)和w*(y)分别为tw和其lst的累积分布函数,即cdf;队列长度ql具有与在等待时间期间tw到达的请求数目相同的分布;设f(z)是ql的生成函数,即得到:
f(z)=w*(λ(1-z))(11)
设y=λ(1-z)即z=1-y/λ,得到:
(11)式的左边可以如下计算:
其中,l是rp&ddm中服务器的数目,根据(12)和(13)式,得到:
因而,根据式(14)得到:
进一步的,所述步骤三中,资源部署延迟的计算方法为:设td为资源部署的延迟,那么,e[td]可通过式(16)计算:
其中,
进一步的,所述步骤三中,执行时间的计算方法为:用户请求的平均执行时间te为:
因而,reqk平均端到端延迟te2e为:
te2e=e[tw]+e[td]+e[te](19)。
本发明的有益效果:
(1)本发明技术适合于多作业类型、多服务器类型的云服务场景,解决文献[10]和文献[11]所述技术没有解决的问题;
(2)本发明的端到端云服务延迟包括队列等待时间、计算资源配置与部署时间和执行时间三个部分,计算结果更加符合实际的云应用环境;
(3)本发明把云服务系统的状态空间分为系统整体状态空间和单个作业的状态空间两个层次,并通过分层ctmc描述其随机特性,对于端到端云服务的特征描述更加完整和精确;
(4)本发明延迟计算的理论基础成熟,易于实际系统的实现。
附图说明
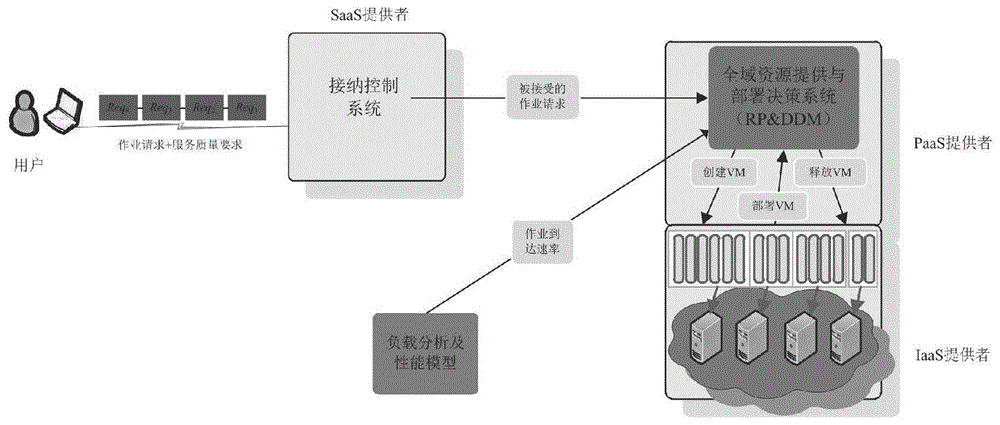
图1是本发明端到端云服务应用场景图。
图2是图1对应的简化模型。
图3是端到端服务对应的多队列系统。
图4是状态空间λ的ctmc模型。
图5是两个连续到达用户请求期间请求离开行为的简图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明技术方案用到的参考文献:
[12]k.s.trivedi,probabilityandstatisticswithreliability,queuingandcomputerscienceapplications,wiley,2ndedition,2001.
[13]rahulghosh,kishors.trivedi,vijayk.naiky,anddongseongkim.end-to-endperformabilityanalysisforinfrastructure-as-a-servicecloud:aninteractingstochasticmodelsapproach,2010pacificriminternationalsymposiumondependablecomputing,pp.125-132,2010.
[14]s.maguluri,r.srikant,l.ying,“stochasticmodelsofloadbalancingandschedulingincloudcomputingclusters”,inproc.ofieeeinfocom,pp.702-710,2012.
[15]h.takagi,“queueinganalysis”,vol.1:vacationandprioritysystems,amsterdam,thenetherlands:north-holland,1991.
[16]t.kimura,“diffusionapproximationforanm/g/mqueue”,operationsresearch,vol.31,pp.304-321,1983.
本发明一种端到端云服务延迟主要包括三部分:队列等待时间、rp&ddm资源配置与部署延迟和执行时间。下面从本技术方案的应用场景、计算模型和计算方法三个方面进行解释。
应用场景:本发明的应用场景如图1所示,设用户数为m(m>0),每个用户有n(n>0)个不同类型的服务请求(即作业),每种类型请求都要求一个特定的虚拟机资源配置(vm-配置),虚拟资源共享底层物理资源(如cpu、ram、虚拟接口等等),每一个vm-配置表示一个(cpu、ram、虚拟接口等)虚拟资源组合。接纳控制系统判断能否满足用户作业的资源请求,云计算中心通过全域资源提供与部署决策系统rp&ddm创建、分配和释放vm-配置。
每一个作业随机到达云服务系统,rp&ddm依据先来先服务(fcfs)的规则处理被接受的客户请求。因此,图1所示的系统可以简化为图2所示的模型。
rp&ddm(aglobalresourceprovisioninganddeployingdecisionmachine):全域资源提供与部署决策系统;
fcfs(firstcomefirstservice):先来先服务;
ctmc(continuoustimemarkovchain):连续时间马尔科夫链。
在上述云服务系统中,假设服务器个数为l,每个服务器能提供n种类型vm-配置,类型k的作业(表示为reqk)请求一个类型k的vm-配置(表示为vmk),
定义1(
定义2(服务器状态).给定一个服务器i,如果
定义3(rp&ddm状态).设h是rp&ddm中l个服务器集合,如果在集合h中至少有一个服务器在给定的时隙内对于reqk是active的,即
设s={active,passive}为rp&ddm的状态集合,根据定义3,在时间t,rp&ddm可能处于在active状态或passive状态。处于active状态时,到达的请求可以立即处理;处于passive状态时,到达的请求只能在rp&ddm中pm重新部署后才能处理。在passive状态到达的请求,用户需要等待一个额外pm部署延迟,一旦进入active状态,所有排队的请求都将被处理。如果一个服务器有足够的vm-配置,队列头部的用户请求将立即得到满足。如果没有符合要求的vm-配置可用,则该请求将被拒绝。当正在运行的请求退出时,则立即释放该vm-配置使用的所有资源,并变为可用资源,提供给下一个用户请求。rp&ddm状态由rp&ddm中服务器的状态共同决定,而每个服务器根据两状态markov链以概率pxy转移,其中,x,y={0,1},状态1和0分别表示服务器是active状态或passive状态。
设
计算模型:上述应用场景中,服务器分服务时间通过指数分布描述,因而,可以采用连续时间马尔科夫链(ctmc:continuoustimemarkovchain)描述上述端到端云服务的特征,参考文献[12]和[13]。结合实际应用场景,本发明采用两层ctmc模型描述上述端到端服务的随机特性,其中,rp&ddm的整体特性是由第一层ctmc描述,而每个服务器上类型k请求队列的特征由第二层ctmc描述。随机建模过程如下:
第1步:端到端多作业请求转化为多队列系统
每个用户请求随机到达云接纳控制系统,接受的作业进入rp&ddm等待虚拟资源分配。因此,可以把用户请求到达过程视作一个多队列系统,如图3所示,图中qreq表示系统中所有用户请求队列,是为了描述方便而设计的虚拟队列(实际系统可以不需要)。
定义4(请求上行/下行队列).对于端到端云服务多队列系统而言,进入接纳控制系统的请求队列称为请求上行队列,而从rp&ddm出来的请求队列称为请求下行队列。
每个用户都有一个对应的请求上行队列和请求下行队列,并设
第2步:多排队系统基于分层ctmc建模
假设所有请求上行队列和请求下行队列的容量均为q、λ1=λ2=…=λm且μ1=μ2=…=μm,则
(1)状态空间λ建模。λ的状态可以表示为一个组合:(y(t),st),其中,y(t)={0,1,2,···,q},st={0,1}。假设每个服务器在开始时刻处于active状态和passive状态的概率分别为δ和1-δ,
因而,得到λ的ctmc模型如图4所示。
(2)状态空间
i.作业请求离开概率
两个连续请求到达的时间间隔(表示为τ)内,每个服务器中每类型请求有将有零个或多个离开。为不失一般性,设
两个连续请求的时间间隔内,请求
其中,λik是k型请求的到达服务器i的速度,
其中,
其中,
ii.计算
设p=[pij],其中,
step1.当j>i+1,有pij=0;
step2.当i=0且j=0,即qik中没有请求等待,且没有请求到达,有:pij=0;
step3.当i=0且j=1,即qik中没有请求等待,因而,有:
step4.当i,j≥1且i-j≥1,即服务器在整个时间片内处于忙的状态,因而,有:
说明:根据文献[15]的研究,中等负载情况下,单一服务器不会有多于一个请求离开。
step5.当i≥1且j=0时,表示在时刻t所有的服务器都处于忙的状态,同时队列qik中有i-1个服务请求在等待,而在接下来的t+1时刻,qik没有请求等待,所有请求都离开服务器。此时,转移概率为:
iii.计算稳态概率
设πik=(πik(0,s);πik(1,s);…;πik(q,s))是qik的稳态概率分布,即,
根据文献[15],为了求得该平衡分布方程的解,需要解以下线性方程:
其中,p是转移概率矩阵。
第3步:端到端应用延迟计算
本发明的端到端延迟包括三个部分:队列等待延迟、资源部署延迟和执行时间。
i.队列等待延迟;设tw表示在稳定状态下作业的等待时间,w(x)和w*(y)分别为tw和其lst的累积分布函数,即cdf。根据文献[16],队列长度ql具有与在等待时间期间tw到达的请求数目相同的分布。设f(z)是ql的生成函数,即得到:
f(z)=w*(λ(1-z))(11)
设y=λ(1-z)即z=1-y/λ,得到:
根据文献[16],(11)式的左边可以如下计算:
其中,l是rp&ddm中服务器的数目,根据(12)和(13)式,得到:
因而,根据式(14)得到:
ii.资源部署的延迟;设td为资源部署的延迟,那么,e[td]可通过式(16)计算:
其中,
iii.执行时间;根据本模型,得到用户请求的平均执行时间te为:
因而,reqk平均端到端延迟te2e为:
te2e=e[tw]+e[td]+e[te](19)
尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!