基于AI视频理解的视频音乐适配方法与系统与流程
本发明涉及ai视频理解、音乐和互联网技术领域,特别涉及一种基于ai视频理解的视频音乐适配方法与系统。
背景技术:
音乐是视频内容的灵魂,可以增强影视作品、电子游戏、音乐或其它媒体艺术或其它内容的感染力和效果。
视频音乐创作,总体上讲是按照视频节目创作的意图和内容,将音乐与画面一起按照叙事的要求和手法去表达、呈现,以达到声画结合的综合效果。因此,要将综合表达的要求,也就是我们所说的视频语言的叙述表达要求,转换为音乐要求和元素,通过录音师的理解和经验,创作出符合要求的音乐作品。
由此来看,视频音乐适配是一个复杂的过程,涉及到对视频内容的理解、创作元素的准备,与画面的配合,同期录音中多种声音和效果的提取等。非专业人员和欠缺经验的视频拍摄者很难达到较高的水准和要求,从而影响了其作品的感染力和影响力。
技术实现要素:
本发明为有效地解决上述问题,提升非专业人员和一般视频创作者的视频适配音乐的水平,使其视频内容进一步增加感染力和效果,公开了一种基于ai视频理解的视频音乐适配方法与系统。
本发明所述基于ai视频理解的视频音乐适配方法与系统包括:ai视频理解模块、音视频时间线装置、音乐库和混音装置:
所述ai视频理解模块,用于理解所要处理的视频内容,通过ai对场景、人物、动作关系、情绪与气氛等视频理解,梳理和提炼出,视频适配音乐描述文件;
所述音乐库,用于存储各种音乐片段,按照所述音乐分类,便于检索和调用;
所述音视频时间线装置,用于根据视频画面参考时间线,安排音乐素材时间线;
所述混音装置,用于将为所述音视频时间线装置准备好的音乐素材等按照时间线进行混音,形成整体声音乐果。
本发明所述人工智能视频适配音乐方法包括如下步骤:
步骤1、视频理解:通过人工智能对视频内容理解,梳理出音乐场景,生成相应的音乐要求描述文件;
步骤2、准备匹配音乐片段:根据步骤1获得的音乐要求描述文件,从音乐库检索和调用相应的音乐片段(素材),如果所述音乐库中没有适配的音乐片段,需要专门制作;
步骤3、准备音视频时间线,将所准备好的视频和音乐片段根据画面参考时间线,分别安排在时间线上;
步骤4、混音处理,将同期声、音乐按照时间线进行混音处理,在混音处理过程中,录音师根据经验对所述音乐作进一步处理,使所有音乐达到统一效果。
根据本发明的一个方面,所述ai视频理解模块包括:ai视频场景理解模块、ai视频人物理解模块、ai视频复杂内容理解模块,分别从不同层次和角度理解所述视频内容。
根据本发明的另一方面,当所述音乐库没有满足所述音乐要求的音乐片段时,需要专门制作,并收入所述音乐库。
优选地,所述音乐的制作可以midi系统完成。
根据本发明的再一方面,所述音乐按照视频图像时间线排列,通过混音装置生成所述的整体声音乐果。
优选地,在所述混音装置上,录音师可以根据需要调整音乐,以便获得与其它音乐、声音和音乐之间的统一。
根据本发明的再一方面,所述音乐库中,音乐的分类与描述与所述场景梳理时输出的所述音乐描述文件的分类与描述格式一致,便于在所述音乐库中检索所述音乐片段,调用与所述描述文件匹配的素材。
基于ai视频理解的视频音乐适配方法与系统,提供了基于人工智能给视频内容适配音乐的方法与系统,通过人工智理解视频,整理出所述音乐描述文件;根据所述描述文件,可以自动检索和调用所述音乐库的素材,并按照所述的音视频时间线,经混音得到统一的音乐结果。采用本发明所述的方法和系统给所述视频适配音乐,可以大大地节约素材准备时间,使音乐处理更具多样化,有更多地选择和效果,帮助那些非专业人员和经验不足的音视频创作人员提高工作效率,提高制作水平。
附图说明
图1为本发明优先实施例提供的所述系统结构图;
图2为本发明优先实施例提供的所述视频音乐适配流程图;
图3是本发明优先实施例的时间线混音处理示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
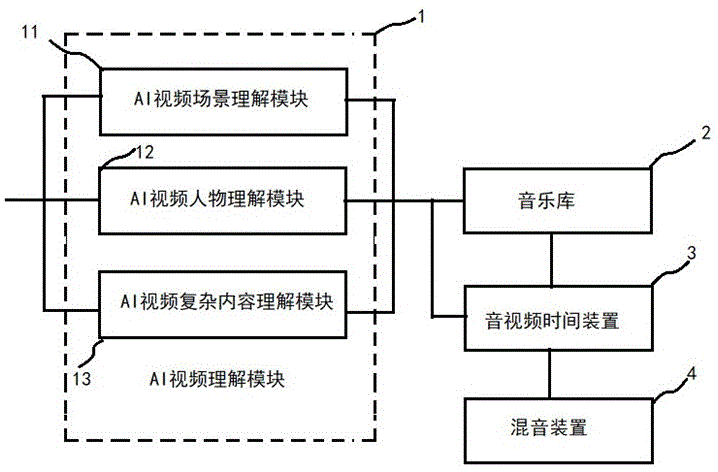
图1为本发明优先实施例提供的所述系统结构图。参考图1,所述系统包括:ai视频理解模组1、音乐库2、音视频时间线装置3、混音装置4:
所述ai视频理解模块1,用于通过人工智能理解所述视频,通过ai将其场景、人物、复杂视频关系、情绪与气氛等进行梳理,生成所述音乐描述文件;为了能够更准确地理解视频内容,所述1又包括:ai视频场景理解模块11、ai视频人物理解模块12、ai视频复杂内容理解模块13,分别从不同层次和角度理解所述视频内容;
所述音乐库2,用于存储各种类型音乐,按照所述音乐描述文件分类要求分类,便于按照所述音乐文件检索和调用;
所述音视频时间线装置3,用于根据视频画面参考时间线,安排音乐时间线和声音时间线等;
所述混音装置4,用于将所述音视频时间线装置准备好的素材,例如,声音和音乐等按照时间线进行混音,形成整体声音乐果。
图2为本发明优先实施例提供的所述视频音乐适配流程图。参考图2,所述流程包括如下步骤:
步骤s11:人工智能视频理解,将所述视频分别送给三个不同的ai视频理解模块,通过ai处理,从不同层次和角度获得所述视频较精准的描述,例如,场景、人物,人物关系、事件关系、情绪等等。梳理出相应的音乐描述文件;
步骤s12:匹配音乐片段。根据步骤1获得的所述音乐描述文件匹配相应的音乐和时长;从音乐库检索和调用相应的音乐片段,如果所述音乐库中没有适配的音乐片段,需要专门制作;
步骤s13:准备音视频时间线。将所准备好的视频和音乐片段、配音等,根据画面参考时间线,分别将音乐安排在音乐时间线上,语言声音也安排在相应的时间线上;
步骤s14:混音处理。将同期声、音乐按照时间线进行混音处理,在混音处理过程中,录音师根据自己对环境、场景、情节、情感的理解,对音乐作进一步处理,使所有音乐达到统一效果。
图3是本发明优先实施例的时间线混音处理示意图。如图3所示,根据步骤s11,将所述视频s31送入ai视频场景理解模块11、ai视频人物理解12、ai视频复杂事件理解13,通过分析所述视频,得到所述音乐描述文件;根据所述描述文件,从音乐库2中调出音乐片段s33、s34、s35;在本发明一个实施例中,s33是在所述视频时间
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!