一种基于DNS解析的域名阴影检测方法和装置与流程
一种基于dns解析的域名阴影检测方法和装置
技术领域
[0001]
本发明涉及域名阴影检测技术领域,具体涉及一种基于dns解析的域名阴影检测方法和装置。
背景技术:
[0002]
臭名昭著的钓鱼工具包angler exploit kit使用了许多漏洞利用工具(含oday),以及一项名为“域名阴影(domain shadowing)”的新技术,将另一个知名恶意工具包blackhole exploit kit完全击败,成为当前市面上最“先进”的钓鱼攻击装备。攻击者通过钓鱼邮件或口令暴力破解方式盗取主域名拥有者的账户,并创建数以万计用于恶意用途的子域名。然后,利用子域名指向恶意网站,或者直接在这些域名绑定的服务器上挂恶意代码,进而通过域名阴影技术进行了大规模钓鱼攻击。这种恶意攻击手法非常有效,子域名非常多、生命周期短暂且域名随机分布。攻击者一般并没有明显的目的。这让遏止这种犯罪变得愈加困难,研究也变得十分不易。
[0003]
现有技术中,对域名阴影的检测时,通常采用人工对钓鱼工具包angler exploit kit进行分析,或者对大规模钓鱼事件进行分析,进而发现攻击者利用adobe flash和microsoft silverlight漏洞为基础,通过域名阴影技术进行了大规模钓鱼攻击。安全研究人员已经发现了约1万个这样的子域名,其中大部分为全球目前最大的域名提供商godaddy的帐户。此外,liu等人在论文中提出了woodpecker方法,通过对域名阴影的数据分析,发现两个维度的特性:
[0004]
(1)域名阴影和主域名下的合法子域名有较大的差异,例如ip、域名构成、服务器承载的业务、域名规模等;
[0005]
(2)不同主域名下的域名阴影可能来自同一非法组织。
[0006]
进而,liu等人从这两个维度提取了17个特征向量,并使用随机森林训练分类器对域名阴影进行建模。但是,由于作者提取的字段过于复杂,单个学习模型同时依赖在线和离线的数据,特别是作者为了平衡特征缺失的影响使用了随机森林分类器,导致检测性能和精度无法保证,并且算法缺少有效的检测框架,实际工程应用存在较大的问题。
[0007]
鉴于此,现有技术有待改进和提高。
技术实现要素:
[0008]
为了解决上述技术问题,本发明提供了一种基于dns解析的域名阴影检测方法和装置,解决了现有技术中对域名阴影检测时存在的性能、精度和工程化等问题。
[0009]
本发明是这样实现的,提供一种基于dns解析的域名阴影检测方法,包括如下步骤:
[0010]
1)获取域名解析的dns原始流量或pdns数据,解析域名请求的特征数据,对解析后的特征数据进行预处理,获取特征数据向量流;
[0011]
2)以预设的滑动时间窗口为检测周期对特征数据向量流进行检测统计,生成检测
特征向量流,所述的检测特征向量流提供两种分析能力,即分别对于同一域名的分析和同一ip的分析;
[0012]
3)利用多阶段异常检测模型组对检测特征向量进行处理,逐步判断子域名是否为疑似域名阴影;
[0013]
4)对疑似域名阴影进行汇聚,输出疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量,并写入数据库。
[0014]
优选地,所述步骤1)具体为:
[0015]
101)利用协议解析引擎对dns流量进行处理,按照标准pdns数据格式提取相应特征,构造实时pdns特征数据;
[0016]
102)利用爬虫根据时间获取来自pdns数据供应商的pdns数据;
[0017]
103)利用采集器获取来自实时dns流量的pdns特征数据和来自供应商的pdns特征数据,送到消息队列;
[0018]
104)利用dga域名识别算法、白域名生成算法、cdn服务器列表以及黑名单获取情报黑白名单列表,用于后续过滤使用;
[0019]
105)利用分布式数据流处理组件,从消息队列读取相应的pdns数据流,并使用情报黑白名单列表形成的过滤算法、在线数据扩充算法、离线数据扩充算法对pdns数据流进行数据特征扩充,补充相关特征向量;
[0020]
106)生成特征数据向量流,并写回消息队列的特征数据向量流topic。
[0021]
进一步优选,所述步骤2)具体为:
[0022]
201)利用分布式数据流处理组件,读取相应的特征数据向量流;
[0023]
202)利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以解析的主机ip为分析对象进行汇聚,若解析的主机ip承载了大量的、不重复的主域名,则判定为该服务器为cdn加速服务器,更新cdn服务器列表获取;
[0024]
203)利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以主域名为分析对象进行汇聚,若主域名包含的子域名具有子域名数量低于指定的阈值且子域名命名符合规范、子域名的活跃度大于指定的阈值等行为时,则过滤这部分特征数据向量流;
[0025]
204)生成检测特征数据向量流,并写回消息队列的检测特征数据向量流topic。
[0026]
进一步优选,所述步骤3)具体为:
[0027]
301)利用分布式数据流处理组件,读取相应的检测特征数据向量流;
[0028]
302)利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以主域名为分析对象进行汇聚,提取汇聚结果的统计特征向量,包括子域名与主域名创建时间间隔f1、子域名组建立时间间隔f2、合法子域名的比例f3、子域名长度的多样性f4、ip的地理位置、阴影社区、k-l散度评估、web关联性;
[0029]
303)基于上述统计向量,利用阶段1异常检测模型进行域名阴影可信度评估,并根据可信度的阈值判断数据流是否进入下一阶段;
[0030]
304)利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为
检测周期对检测特征数据向量流进行检测统计,以解析的主机ip为分析对象进行汇聚,提取汇聚结果的统计特征向量,包括k-l散度评估、web关联性、主机ip承载的疑似域名阴影的数量;
[0031]
305)基于步骤304)输出的统计向量,利用阶段2异常检测模型进行域名阴影可信度评估,并根据可信度的阈值判断对子域名进行最终的可信度标注,更新检测特征数据向量流相关字段。
[0032]
进一步优选,所述步骤4)具体为:
[0033]
401)获取步骤3)得到的检测特征数据向量流;
[0034]
402)利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口对判定为可疑域名阴影的检测特征数据向量流根据主域名进行汇聚;
[0035]
403)提取疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量,生成域名阴影检测结果向量流;
[0036]
404)利用分布式数据流处理组件的数据库写入机制,将域名阴影检测结果向量流写入数据库。
[0037]
本发明还提供一种基于dns解析的域名阴影检测装置,包括:
[0038]
数据采集单元,用于获取pdns格式的请求解析日志数据,记为特征数据向量流,所述的pdns格式的请求解析日志数据主要包括:请求域名、应答ip、首次时间戳、最近一次时间戳、资源类型、ttl;
[0039]
数据预处理单元,用于对特征数据向量流进行特征清洗和扩充,将对统计没有影响的字段去掉,保留、修改和扩充影响异常检测结果的字段;
[0040]
数据预过滤和扩展单元,用于过滤与检测无关的特征数据向量流,提高后续异常检测方法的处理效率;
[0041]
异常检测单元,基于分布式数据流框架构造多阶段异常检测组件,利用统计分析模块对特定滑动时间窗口的特征数据向量流进行计算获得统计特征向量,多阶段异常检测组件对域名阴影进行可信度评估,并根据可信度的阈值判断对子域名是否为疑似域名阴影进行最终的可信度标注;
[0042]
入库单元,基于分布式数据流框架对可信度超过给定阈值的疑似域名阴影进行汇聚,输出模块将输出疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量,并写入数据库。
[0043]
优选地,所述数据采集单元通过架设dns协议解析服务器、爬虫服务器、镜像交换机以及光电转换设备,实现从现网流量和pdns数据供应商获取pdns格式的请求解析日志数据,并进行汇聚。
[0044]
进一步优选,所述数据预处理单元基于分布式数据流处理框架,使用dga域名识别模块、白域名生成模块、cdn服务器列表获取模块,以及情报黑白名单模块获取域名和ip黑白名单列表,并且封装域名和ip黑白名单列表为相应的黑白名单检测模块。
[0045]
进一步优选,所述数据预过滤和扩展单元基于分布式数据流处理框架,从消息队列读取相应的pdns数据流,并使用黑白名单过滤模块、在线数据扩充模块、离线数据扩充模块对pdns数据流进行数据过滤和特征扩充,降低后续处理流程数据流规模并补充相关特征向量,生成检测特征数据向量流,利用分布式数据流组件的消息队列写入模块,将检测特征
数据向量流写回消息队列的检测特征数据向量流topic。
[0046]
进一步优选,所述异常检测单元和入库单元,基于分布式数据流处理框架,利用分布式数据流组件的消息队列读取模块,从消息队列的检测特征数据向量流topic读取相应的数据流;利用聚合分析模块分别对主机ip和主域名进行聚合分析,多阶段异常检测模块分别对聚合结果进行分析,并且利用域名阴影可信度评估算法对其结果进行评估,并根据可信度的阈值判断对子域名进行最终的可信度标注,最后,提取疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量等,将域名阴影检测结果写入数据库。
[0047]
本发明提供的一种基于dns解析的域名阴影检测方法和装置,使用了多个统计特征对域名阴影进行描述,多阶段域名阴影异常检测算法,并提出了一套基于分布式数据流的域名阴影检测框架,使得本发明具备以下优点:
[0048]
1)通过多重的流量过滤机制,极大的减少了后续异常检测流程处理的数据规模,提高了系统处理效率;
[0049]
2)通过使用分布式处理框架,可以大规模分析实时的dns请求流量,也可以分析离线的pdns数据,极大的提高了系统处理效率,降低了系统维护和升级的代价;
[0050]
3)通过提出的多阶段域名阴影异常检测算法,能够将复杂问题进行分解,将时间代价较大的异常检测算法放到后期处理流程,极大的提高了系统处理效率和工程化水平;
[0051]
4)通过使用分布式数据流处理框架、多阶段异常检测算法、多重数据流过滤和扩充机制以及新颖的统计向量特征,极大的提高了域名阴影的检测性能和准确率;
[0052]
5)本发明提供的一种基于dns解析的域名阴影检测方法和装置,通过解析dns数据,能够检测高可信的域名阴影,通过进一步分析可以确定受害人或组织以及确定恶意程序主机ip地址,及时提醒受害人利用域名管理权限删除非法添加的子域名,并更新和加固域名管理账号的凭证。
[0053]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0054]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0055]
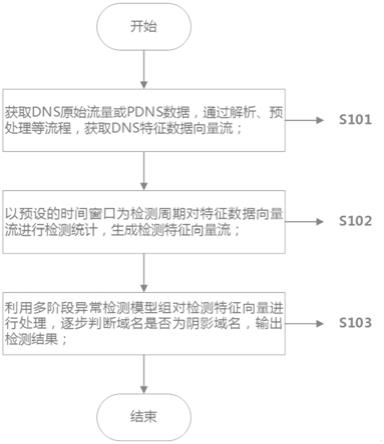
图1为本发明实施例提供的基于dns解析的域名阴影检测方法流程图;
[0056]
图2为本发明实施例提供的基于dns解析的域名阴影检测方法之生成特征数据向量过程流程图;
[0057]
图3为本发明实施例提供的基于dns解析的域名阴影检测方法之生成检测特征向量过程流程图;
[0058]
图4为本发明实施例提供的基于dns解析的域名阴影检测方法之异常检测过程流程图;
[0059]
图5为本发明实施例提供的基于dns解析的域名阴影检测装置结构图。
具体实施方式
[0060]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0061]
攻击者窃取了受害者(网站站长)的域名账户,创建了数以万计的子域名。这些子域名与众所周知的主域名相关联并且通常不遵循任何可识别的模式,难以检测。不仅如此,所涉及的攻击者不会影响父域或该域上托管的任何内容,从而使其操作更加隐蔽。攻击者使用这些欺诈性子域名进行恶意活动,包括分发恶意软件,注入漏洞利用工具包或将用户静默重定向到承载恶意元素的其他网站。
[0062]
本申请实施例中,获取域名解析的dns原始流量或pdns数据,解析域名请求的特征数据,对解析后的特征数据进行预处理,获取特征数据向量流;进一步,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,生成检测特征向量流。然后,利用多阶段异常检测模型组对检测特征向量进行处理,逐步判断子域名是否为疑似域名阴影。这样,如果确定待检测子域名为域名阴影,则及时通知主域名拥有者和域名服务提供商,从而清理一个主域名,可以阻断成千上万的域名阴影,进而在大规模钓鱼发起攻击的过程中阻断非法域名的解析服务,阻止域名阴影的危害。
[0063]
下面结合附图和具体实施例进一步说明本发明实施例的技术方案。
[0064]
图1是本发明实施例提供的基于dns解析的域名阴影检测方法流程图,包括以下步骤:
[0065]
s101:获取dns原始流量或pdns数据,通过解析、预处理等流程,获取pdns特征数据向量流,如图2所示;
[0066]
在具体实施过程中,包含以下步骤:
[0067]
步骤s101-1,利用协议解析引擎对dns流量进行处理,按照标准pdns数据格式提取相应特征,构造实时pdns特征数据;
[0068]
优选的是,pdns技术是由weimer等人在2005年提出的一种方案,用来解决dns系统ptr反向查询能力不足的问题。通过将现有dns业务的流量进行镜像或分光处理,解析出查询和响应的数据并存入数据库,然后建立正向和反向的查询索引。所述的pdns格式数据主要包括:请求域名[query]、主机ip(应答ip)[answer]、首次时间戳[first seen]、最近一次时间戳[last seen]、资源类型[rrtype]、查询类型[query type]、ttl、url等;
[0069]
优选的是,对于协议解析引擎,可以使用c语言、python语言根据dns协议规范进行开发,也可以使用开源的pdns数据提取工具代替;
[0070]
步骤s101-2,利用爬虫根据时间获取来自pdns数据供应商的pdns数据;
[0071]
优选的是,对于pdns数据供应商,主流的供应商包括farsight security、qihoo 360和virustotal;
[0072]
步骤s101-3,利用采集器获取来自实时dns流量的pdns特征数据和来自供应商的pdns特征数据,送到消息队列;
[0073]
优选的是,分布式消息队列kafka的选择是来自最佳实践,也可以选择其他消息队列;
[0074]
s101-4,利用dga域名识别算法、白域名生成算法、cdn服务器列表以及黑名单获取情报黑白名单列表,用于后续过滤使用;
[0075]
进一步地,优选的是,对于黑白名单列表的获取描述如下:
[0076]
dga域名识别算法,可以使用dga域名黑名单、异常域名检测、人工智能模型检测(机器学习、深度学习和集成学习)等技术,目的是识别pdns数据流中的dga域名,dga域名不可能是域名阴影,可以提前过滤,降低后续数据流的处理压力,提高处理效率;
[0077]
白域名列表生成算法,集合来自以下白域名样本数据来源,alex-1m、cisco-1m、majestic-1m、quantcast-1m和statvoo-1m,总计接近500万的白域名样本。然后,对样本源的更新频度进行权重分配(也可自定义权重),进而根据权重进行样本去重和排名,去重后样本规模为400万左右,可以根据算法需求获得前top-1k、top-10k、top-100k等白域名列表。通常情况下,权威域名的权限管理相对比较严格,难以被攻击者攻破而获取权限,故不可能是域名阴影,可以选择top-n作为权威域名,提前过滤,降低后续数据流的处理压力,提高处理效率;
[0078]
cdn服务器列表获取,该列表来自开放的cdn白名单,以及cdn服务器识别算法。对于cdn服务器识别算法,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口根据主机ip(应答ip)对pdns数据流进行汇聚,若主机ip上承载的不重复主域名的规模超过指定阈值,则判定为该主机ip为cdn服务器加速ip,用于加速用户访问速度。cdn服务器不可能承载域名阴影,可以利用cdn主机ip列表对pdns数据流进行提前过滤,降低后续数据流的处理压力,提高处理效率;
[0079]
黑白名单列表,该列表来自多个情报数据源,从情报源中剔除域名阴影ip及其相关域名情报。对于其他的ip和域名黑白名单情报,都可以用来进行pdns数据流提前过滤,降低后续数据流的处理压力,提高处理效率;
[0080]
步骤s101-5,利用分布式数据流处理组件,从消息队列读取相应的pdns数据流,并使用情报黑白名单列表形成的过滤算法、在线数据扩充算法、离线数据扩充算法对pdns数据流进行数据特征扩充,补充相关特征向量,例如web页面被主流搜索引擎索引特征集、域名whois特征集、域名的geoip信息等。
[0081]
最后,生成特征向量数据流;
[0082]
优选的是,从消息队列读取相应的pdns数据流,使用步骤101-4提出的各种过滤算法,对pdns数据流进行过滤,降低后续数据流的处理压力,提高处理效率;
[0083]
优选的是,利用分布式数据流处理组件,对于过滤之后的pdns数据流,使用在线数据扩充算法对其进行特征扩充,在线数据扩充算法包括whois数据扩充、web页面被主流搜索引擎索引数据扩充;
[0084]
whois数据,是指注册人向域名服务提供商提供的信息,可通过whois服务查询此类信息,这些信息包括以下数据元素:注册域名的主要域名服务器、次要域名服务器的名称、注册人的身份信息、注册的初始生成日期和到期日期、注册域名持有人的名称和邮政地址、注册域名技术、管理联系人的姓名、邮政地址、电子邮件地址、音频电话号码和(如适用)传真号码。whois数据能够为域名阴影提供注册时间、注册人身份信息及联系方式。其中,注
册时间是检测域名阴影的关键信息,域名阴影的注册时间往往晚于主域名的注册时间以及合法子域名的注册时间,且主域名和合法主域名的注册时间通常是根据需要进行注册的,而域名阴影的注册时间由于攻击需求存在聚集某一个时间段特性,即某一个时间段进行大规模注册;
[0085]
web页面被主流搜索引擎索引相关性,域名阴影通常与主域名、相关合法主域名及其兄弟域名提供的服务没有任何相关性,域名阴影存在的目的就是为攻击者提供便利和隐蔽的渠道。因此,域名阴影通常不会与其他合法站点的域名和子域名有链接关系,而合法站点的域名和子域名之间通常会存在链接关系。对于主流搜索引擎,其爬虫持续迭代获取数据的方式是以链接关系为基础的,即合法站点的域名和子域名的web页面数据是能够被主流搜索引擎爬取到且被索引,能够查询到相应的数据,而域名阴影不能通过主流搜索引擎搜索到相关的数据。使用主流的搜索引擎,包括但不局限于google、baidu、bing、internetarchive和commoncrawl对域名阴影进行搜索,判断是否存在相应的索引。若存在,该字段为1,不存在则为0;
[0086]
优选的是,利用分布式数据流处理组件,对于过滤之后的pdns数据流,使用离线数据扩充算法geoip映射对其进行特征扩充,补充以下特征:经纬度、国家、城市、isp、asn等。通常,geoip映射的数据库可以选用maxmind、纯真ip数据库;
[0087]
步骤s101-6,基于分布式数据流处理组件,将生成的特征数据向量流写回消息队列的特征数据向量流topic中;
[0088]
s102:以预设的滑动时间窗口为检测周期对检测特征数据向量流进行统计,生成检测特征向量流,如图3所示;
[0089]
在具体实施过程中,包含以下步骤:
[0090]
步骤s102-1,利用分布式数据流处理组件,从消息队列的特征数据向量流topic读取相应的特征数据向量流;
[0091]
步骤s102-2,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以解析的主机ip为分析对象进行汇聚,若解析的主机ip承载了大量的、不重复的主域名,则判定为该服务器为cdn加速服务器,更新cdn服务器列表获取;
[0092]
所述步骤s102-2进一步为,对于cdn服务器判定,与步骤s101-4的cdn判定过程存在两点差异:其一,由于步骤14的实时pdns数据流规模较大,flink开启的滑动时间窗口相对较小,而步骤22获取的是过滤后的特征数据向量流,flink开启的滑动时间窗口相对较大,可以进一步检测cdn服务器;其二,步骤22进一步使用了查询类型[query type]字段中的cname值,判断该值是否包含“cdn”、“cdn”等关键字;
[0093]
步骤s102-3,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以主域名为分析对象进行汇聚,若主域名包含的子域名具有以下特征时,即子域名数量低于指定的阈值且子域名命名符合规范、子域名的活跃度均大于指定的阈值,则过滤这部分特征数据向量流;
[0094]
所述步骤s102-3进一步为,该过程利用了域名阴影的以下特点:其一,在合法域名下创建恶意的子域名,它与一般所说恶意域名来比最大的不同在于主域名是合法的,且会创建大量的用于钓鱼的非法子域名;其二,非法子域名命名与主流的合法子域名的命名方
式差异较大,非法子域名多为随机生成,信息熵值较大。主流top-50合法子域名描述如下,www、mail、remote、blog、webmail、server、ns1、ns2、smtp、secure、vpn、m、shop、ftp、mail2、test、portal、ns、ww1、host、support、dev、web、bbs、ww42、mx、email、cloud、1、mail1、2、forum、owa、www2、gw、admin、store、mx1、cdn、api、exchange、app、gov、2tty、vps、govyty、hgfgdf、news、1rer、lkjkui;其三,域名阴影活跃度极低,通常不活跃,只有在发动钓鱼攻击任务时才会被使用。因此,可以通过passivedns数据中的可选字段“count”进行判定,表示该域名的查询次数;
[0095]
步骤s102-4,生成检测特征数据向量流,并写回消息队列的检测特征数据向量流topic;
[0096]
所述步骤s102-4进一步为,该过程利用分布式数据流处理组件的分布式消息队列读写接口,将生成检测特征数据向量流写入检测特征数据向量流topic。若存在检测特征数据向量流topic,则直接写入;若不存在检测特征数据向量流topic,则先建立该topic后写入;
[0097]
s103:利用多阶段异常检测模型组对检测特征向量进行处理,逐步判断子域名是否为疑似域名阴影,并输出检测结果,如图4所示;
[0098]
在具体实施过程中,包含以下步骤:
[0099]
步骤s103-1,利用分布式数据流处理组件,从消息队列的检测特征数据向量流topic读取相应的数据流;
[0100]
步骤s103-2,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以主域名为分析对象进行汇聚,提取汇聚结果的统计特征向量,包括子域名与主域名创建时间间隔f1、子域名组建立时间间隔f2、通用(合法)子域名的比例f3、子域名长度的多样性f4、ip的地理位置、阴影社区、k-l散度评估、web关联性;
[0101]
所述步骤s103-2进一步为,异常检测算法中涉及到的变量定义如下:
[0102]
a:表示主域名;
[0103]
s:表示子域名;
[0104]
s
a
:在确定的主域名下,不重复的子域名集合;
[0105]
i
a
:在确定的主域名下,承载子域名的不重复的ip集合;
[0106]
s(s):对于子域名s,与该子域名共享ip地址的子域名集合;
[0107]
ip(s):对于子域名s,被解析的ip地址;
[0108]
2ld(s):对于子域名s,其主域名定义为2ld(s);
[0109]
r:表示主流(通用)合法子域名的正则表达式集合,能够覆盖几乎所有的合法子域名;
[0110]
t(a):主域名建立时间,以天为单位;
[0111]
t(s):子域名建立时间,以天为单位;
[0112]
g(i,∈):对于ip i∈i
a
,该函数表示满足以下条件的子域名集合,在时间窗口∈范围内(以s为单位),至少存在两个或两个以上的子域名;
[0113]
l
i
:对于ip i∈i
a
,该函数表示子域名长度列表;
[0114]
h(l
i
):对于子域名长度列表,该函数表示该列表的香农指数;
[0115]
a
i
:对于ip i∈i
a
,表示该ip地址承载的主域名集合,即被解析到该ip地址的主域名集合;
[0116]
s
i
:对于ip i∈i
a
,表示该ip地址承载的子域名集合,即被解析到该ip地址的子域名集合;
[0117]
g(i):对于ip i∈i
a
,表示该ip地址社区规模的大小,即包含不重复的主域名规模;
[0118]
index(s):对于子域名s,表示与子域名s相关的页面能够被爬虫获取并且被搜索引擎索引;
[0119]
对于主域名a,在主域名a下,承载子域名不重复的ip集合定义为i
a
,被定义为子域名ip地址i与所有其他子域名的ip地址之间距离的均值。ip地址之间的距离定义如下,即4维空间中的曼哈顿距离。
[0120]
所述步骤s103-2进一步为,以主域名为分析对象进行汇聚,提取汇聚结果的统计特征向量,即阶段1异常检测算法中涉及到的统计特征。其中,对于子域名与主域名创建时间间隔f1,该统计特征主要是描述主域名的创建时间通常与域名阴影涉及到的子域名创建时间是不同,并且之间间隔时间较长,故该特征可以用来区分域名阴影和主域名。形式化定义如下:
[0121]
其中,对于子域名组建立时间间隔f2,该统计特征主要是描述合法子域名的创建时间通常与域名阴影涉及到的子域名创建时间是不同,并且之间间隔时间较长,故该特征可以用来区分域名阴影和合法子域名。形式化定义如下:
[0122]
其中,对于通用(合法)子域名的比例f3,该统计特征主要是描述与主域名相关的子域名集合中,通用(合法)子域名的占比。通用(合法)子域名通常是指与主域名创建时间接近,且子域名在主流top-50合法子域名集合中或满足其正则匹配。因此,该特征可以用来区分域名阴影和合法子域名。形式化定义如下:
[0123]
其中,对于子域名长度的多样性f4,该统计特征主要是描述域名阴影的算法生成特性,而主域名和合法子域名的命名是基于词法、语法和语义知识的,且与具体业务相关,多样性较好。对于算法生成的域名,通常具有较少的多样性。形式化定义如下:
[0124]
其中,对于ip的地理位置f5,该统计特征主要是描述承载域名阴影的ip地址与承载主域名以及合法子域名的ip地址通常是不同的,具体表现在ip地址的地理位置、isp和asn存在较大差异。ip的地理位置f5用来表示ip之间的距离,形式化定义如下:
[0125]
其中,对于k-l散度评估,该统计特征是为了评估不同阴影子域名的特征一致性,转化每个特征成为频度直方图并且与所有子域名共享相同的值直方图进行对比,然后使用k-l散度评估差异。即,对于一个数值集合v,首先计算每个值的频率权重
然后,若w
i
具备最大频度则通过设定<w
i
,1>获得一个新的集合w
′
,否则设定<w
i
,0>。最后,利用w和w
′
计算k-l散度,基于k-l散度评估,对域名阴影的特征进行建模,衍生出以下统计特征f6、f7和f8。对于一个子域名s,计算与该子域名共享ip地址的子域名集合s(s),并获取子域名集合s(s)的首次捕获时间列表,利用k-l散度求取捕获域名的时间分布f6。对于特征f7,表示域名解析次数分布。对于域名阴影,其访问模式较为单一,即按照一定的时间间隔轮询一次。而合法域名的访问模式更多样化,对于类似www的合法子域名能够获得持续的更多的访问。因此,利用k-l散度对域名解析次数进行建模,求取捕获域名的解析次数分布f7。对于特征f8,表示域名活跃的天数分布。若合法子域名很少被访问,特征f7可能引发异常。而特征f8是f7的辅助方法,计算子域名的活跃天数,该特征能够较好的描述攻击者频繁更换主机ip地址。而与之相反,承载合法域名的ip地址更加稳定,导致具有更长的活跃天数。因此,利用k-l散度对域名活跃天数进行建模,求取域名的活跃天数分布f8。
[0126]
其中,对于web关联性,该统计特征主要描述域名阴影提供的服务通常与主域名、兄弟域名和主机服务器提供的服务是无关的,也不会存在与主域名或其他合法子域名主页面的超链接。但是,合法主域名和子域名之间通常是存在超链接关系的。因此,域名阴影是很难被web爬虫访问到,通常是进行了伪装。为了描述域名阴影的web关联性,定义特征f9、f
10
和f
11
。对于特征f9,表示域名相关的页面能够被爬虫获取并且被搜索引擎索引,f9=index(s),被索引则f9被赋值为1,否则为0。此外,对于特征f
10
,表示在同一主域名情况下,子域名列表被索引的概率,对于特征f
11
,表示在同一主机ip情况下,子域名列表被索引的概率,
[0127]
步骤s103-3,基于上述统计向量,利用阶段1异常检测模型进行域名阴影可信度评估,并根据可信度的阈值判断数据流是否进入下一阶段;
[0128]
所述步骤s103-3进一步为,阶段1异常检测算法将会整合f1到f
11
特征值,整合算法其中,对于重要性权重w
i
,阐述如下;
[0129]
对每一维特征“打分”,即给每一维特征赋予权重,这样权重就代表该维特征的重要性,然后依据权重排序。即,按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或待选择阈值的个数,选择合适特征。特征选择算法,使用卡方检验chi-squared test,检验某个特征分布和输出值分布之间的相关性,在sklearn的代码中可以使用chi2这个类来做卡方检验得到所有特征的卡方值与显著性水平p临界值,给定卡方值阈值,选择卡方值较大的部分特征;
[0130]
对于阶段1异常检测算法总体可信度评分score
p1
,若score
p1
≥q1,则判定为该时间窗口存在域名阴影。若score
p1
<q1,则将该时间窗口数据流送往阶段2异常检测模型;
[0131]
步骤s103-4,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口为检测周期对检测特征数据向量流进行检测统计,以解析的主机ip为分析对象进行汇聚,提取汇聚结果的统计特征向量,包括k-l散度评估、web关联性、主机ip承载的疑似域名阴影的数量;
[0132]
所述步骤s103-4进一步为,以解析的主机ip为分析对象进行汇聚,提取汇聚结果的统计特征向量,即阶段2异常检测算法中涉及到的统计特征。其中,对于特征f
12
和f
13
,描述了子域名的算法生成特性,这与dga域名生成类似,但随机生成字符(熵值较高)组成的域名阴影较为少见,通常都是有语义的词。因此,可以通过对同主机的子域名进行相似性建模,进而描述子域名的特征。对于特征f
12
,描述域名层次的多样性分布。攻击者在一次攻击过程中使用的域名阴影通常会使用统一的模板生成,故域名层级是相同的,而在同一主机的合法域名并不一定具有一致的域名层级。因此,可以利用k-l散度对域名层级进行建模,求取域名层级分布f
12
。对于特征f
13
,描述子域名长度的多样性分布。首先利用子串正则匹配方法移除主域名,并且比较遗留域名的长度。当判定同组的子域名存在不同长度时,利用空字符串补位以确保字符串长度相同。假设子域名的前缀n={<n
i
>
i=1...m
},其中,n
i
表示第i层级。最后,利用k-l散度对子域名长度进行建模,求取子域名长度分布f
13
。对于特征f
13
和特征f4,都是用来描述子域名长度的多样性,但异常检测的阶段、处理的数据和使用的描述算法不同,使得这两个特征在各自的异常检测阶段中特征有效性差异较大;
[0133]
其中,对于web关联性,特征f
14
表示在同一主机ip情况下,子域名列表被索引的概率,
[0134]
其中,特征f
15
表示主机ip承载的疑似域名阴影的数量。为了提高隐匿成功率,攻击者通常会使用多个受控的主域名进行域名阴影操作。对于一个存在域名阴影的主域名a,若另一个主域名b的域名阴影也解析到与主域名a相同的ip地址,则主域名a和b的域名阴影解析到同一个主机ip上,形式化定义如下,
[0135]
步骤s103-5,基于步骤s103-4输出的统计向量f
12
到f
15
,利用阶段2异常检测模型进行域名阴影可信度评估,并根据可信度的阈值判断对子域名进行最终的可信度标注,更新检测特征数据向量流相关字段;
[0136]
所述步骤s103-5进一步为,阶段2异常检测算法将会整合f
12
到f
15
特征值,整合算法其中,对于重要性权重w
i
,阐述如下;
[0137]
对每一维特征“打分”,即给每一维特征赋予权重,这样权重就代表该维特征的重要性,然后依据权重排序。即,按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或待选择阈值的个数,选择合适特征。特征选择算法,使用卡方检验chi-squared test,检验某个特征分布和输出值分布之间的相关性,使用sklearn的chi2类来做卡方检验得到所有特征的卡方值与显著性水平p临界值,给定卡方值阈值,选择卡方值较大的部分特征;
[0138]
对于阶段2异常检测算法总体可信度评分score
p2
,若score
p2
≥q2,则判定为该时间窗口存在域名阴影;
[0139]
步骤s103-6,对可信度超过指定阈值的域名阴影进行汇聚,输出疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量;
[0140]
所述步骤s103-6进一步为,利用分布式数据流处理组件的滑动时间窗口机制,以预设的滑动时间窗口对判定为可疑域名阴影的检测特征数据向量流根据主域名进行汇聚。然后,提取疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量,生成域名阴影检
测结果向量流。其中,所述的证据向量,即当前时间窗口的特征数据向量流。最后,利用分布式数据流处理组件的数据库写入机制,将域名阴影检测结果向量流写入数据库。
[0141]
此外,与本发明方法实施例相对应,参考图5所示,还提供了一种基于dns解析的域名阴影检测装置,包括:
[0142]
s501:数据采集单元,用于获取pdns格式的请求解析日志数据,记为特征数据向量流;所述的pdns格式数据主要包括:请求域名、应答ip、首次时间戳、最近一次时间戳、资源类型、ttl等;数据预处理单元,用于对特征数据向量流进行特征清洗和扩充,将对统计没有影响的字段去掉,保留、修改和扩充影响异常检测结果的字段;
[0143]
所述步骤s501进一步为,通过架设dns协议解析服务器、爬虫服务器、镜像交换机以及光电转换等设备,实现从现网流量和pdns数据供应商获取pdns格式的请求解析日志数据,并进行汇聚;
[0144]
s502:数据预处理单元,用于过滤与检测无关的特征数据向量流,提高后续异常检测方法的处理效率;
[0145]
所述步骤s502进一步为,基于分布式数据流处理框架,使用dga域名识别模块、白域名生成模块、cdn服务器列表获取模块,以及情报黑白名单模块等获取域名和ip黑白名单列表,并且封装域名和ip黑白名单列表为相应的黑白名单检测模块;
[0146]
s503:数据预过滤和扩展单元,用于过滤与检测无关的特征数据向量流,提高后续异常检测方法的处理效率;
[0147]
所述步骤s503进一步为,基于分布式数据流处理框架,从消息队列读取相应的pdns数据流,并使用黑白名单过滤模块、在线数据扩充模块、离线数据扩充模块对pdns数据流进行数据过滤和特征扩充,降低后续处理流程数据流规模并补充相关特征向量,生成特征数据向量流。利用分布式数据流组件的消息队列写入模块,将特征数据向量流写回消息队列的特征数据向量流topic;
[0148]
s504:异常检测单元,基于分布式数据流框架构造多阶段异常检测组件,利用统计分析模块对特定滑动时间窗口的特征数据向量流进行计算获得统计特征向量,多阶段异常检测组件对域名阴影进行可信度评估,并根据可信度的阈值判断对子域名是否为疑似域名阴影进行最终的可信度标注;
[0149]
s505:入库单元,基于分布式数据流框架对可信度超过给定阈值的疑似域名阴影进行汇聚,输出模块将输出疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量,并写入数据库;
[0150]
所述步骤s504和s505进一步为,基于分布式数据流处理框架,利用分布式数据流组件的消息队列读取模块,从消息队列的检测特征数据向量流topic读取相应的数据流;利用聚合分析模块分别对主机ip和主域名进行聚合分析,多阶段异常检测模块分别对聚合结果进行分析,并且利用域名阴影可信度评估算法对其结果进行评估,并根据可信度的阈值判断对子域名进行最终的可信度标注。最后,提取疑似域名阴影的主域名、主机ip、受害人或组织以及证据向量等,将域名阴影检测结果写入数据库。
[0151]
综上所述,本发明涉及一种基于dns解析的域名阴影检测方法,本方法的核心是利用域名阴影的独特性,特别是其恶意使用行为,即异常行为,与合法主域名和子域名差异较大。攻击者通过钓鱼邮件或口令暴力猜解方式盗取主域名拥有者的账户,并创建数以万计
用于恶意用途的子域名。然后,利用子域名指向恶意网站,或者直接在这些域名绑定的服务器上挂恶意代码,进而通过域名阴影技术进行了大规模钓鱼攻击。这种恶意攻击行为具有子域名非常多、生命周期短暂、域名随机分布、解析的ip多样性等特点。本发明基于分布式数据流处理框架,可以大规模分析实时的pdns数据,通过多阶段异常检测模型组挖掘出潜在的域名阴影,极大的提高了分析效率。本发明在一定程度上解决了传统域名阴影检测技术遇到的检测性能慢、准确性低、检测模型同时依赖实时和离线数据、难以根据流量横向扩展、工程化困难等问题。同时,本发明通过进一步分析可以确定受害人或组织以及确定恶意程序主机ip地址,及时提醒受害人利用域名管理权限删除非法添加的子域名,并更新和加固域名管理账号的凭证。
[0152]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的保护范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1