基于卷积神经网络的视频插帧方法与流程
本发明属于计算机图像处理技术领域,尤其涉及一种非均匀的视频插帧方法。
背景技术:
视频帧率转换技术是利用视频中相邻两帧之间的相关信息并应用插值的方法将中间帧重建出来的一种技术。由于该技术能在编码中去除冗余信息并降低视频传输过程中的帧率,减少视频网络传输的数据量,因此可应用于视频压缩或增强视频连续性。
传统的视频插帧方法主要包括两个步骤,即光流估计和像素合成。在该方法中视频插帧技术的效果往往取决于光流估计的质量,而光流估计的过程容易受到遮挡、模糊的影响出现明显的错误。随着深度学习的发展,基于深度学习的视频插帧技术也有了新的突破,利用卷积神经网络尝试进行视频插帧取得了一定的成功。
视频插帧技术是指利用视频中相邻前后帧之间的相关信息,应用插值的方法获得中间帧。视频插帧的目的是在视频中合成新的中间帧,提高视频的帧率。
根据新的插值帧的数量与输入视频帧的数量关系,视频插帧可分为均匀插帧与非均匀插帧。均匀插帧是指新的插值帧与输入的视频帧序列按照1:1的比例合成最后新的视频序列,非均匀插帧一般是指新的插值帧与输入的视频序列按照一定的比例合成新的视频序列。
传统的视频插帧技术主要是找出视频前后两帧图像的像素间明显的对应关系,最常见的方法就是获取视频前后两帧之间的光流信息。将光流场的信息作为视频前后两帧图像间的对应关系,并利用光流场信息合成中间帧图像。这种传统的方法,插帧质量的好坏很大程度上依赖于光流场信息的质量。
在视频插帧技术中,运动估计占有重要的地位,除了直接寻找相邻两帧图像间的运动关系外,一些可代替直接估计相邻帧运动信息的方法也在不断产生,这些方法都是基于相位方法的改编,主要思想大多是对相邻视频帧图像间的相位差中的运动部分进行编码。
技术实现要素:
为避免相邻两帧间运动估计过程对插帧质量的影响,本发明目的是提供一种基于卷积神经网络的视频插帧方法,该方法训练一个深度卷积神经网络,将视频中相邻的两帧作为神经网络的输入,并直接输出中间帧。
本发明的技术解决方案是:
一种基于卷积神经网络的视频插帧方法,包括以下步骤:
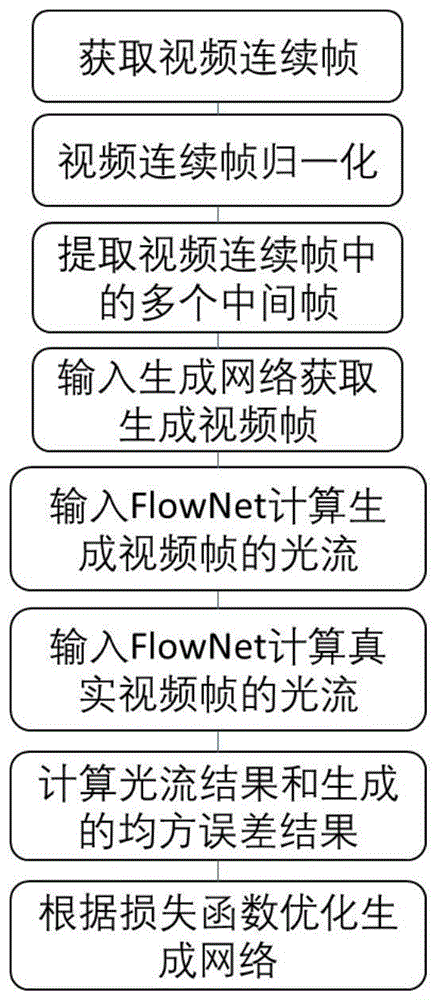
1)获取视频连续帧:
从真实视频帧中选取相关联的前后帧,并进行归一化,然后输入到卷积神经网络中;
2)提取视频运动信息并恢复视频空间:
卷积神经网络前半部分编码模块对归一化处理后的前后帧进行降采样处理,提取前后帧视频间运动信息;然后卷积神经网络后半部分解码模块对降采样处理后的视频间运动信息进行上采样处理,恢复视频空间维度并补偿细节;同时,卷积神经网络中间部分,采取skip-connection的方式将网络底层的信息传输到深层网络中,进行视频插帧特征的提取和输出;
3)输出多个中间帧:
将步骤2中进行上采样处理后的信息以及视频插帧特征,输入双向lstm卷积层,循环输出至少一个中间视频帧;
4)计算光流的均方误差:
通过预训练的flownet分别计算步骤3中的中间视频帧光流和真实视频帧光流;然后计算中间视频帧光流与真实视频帧光流之间的均方误差;
5)优化插帧:
将步骤4中的均方误差作为视频非均匀插帧计算的优化目标函数,使flownet参与网络优化中梯度后向传播过程,实现视频插帧的优化。
上述步骤2中,卷积神经网络前半部分编码模块对归一化处理后的前后帧最好进行两次降采样处理;卷积神经网络后半部分解码模块对降采样处理后的视频间运动信息相应进行两次上采样处理。
上述卷积神经网络优选编解码u-net模块,且编码模块为3层卷积模块。
在进行上采样和降采样之前,还可分别使用稠密连接网络进行卷积特征提取。
上述上采样采用sub-pixel算法;上述降采样采用conv-lstm算法。
上述步骤2中,卷积神经网络中间部分,通过skip-connection连接,将网络底层的信息传输到深层网络中。
上述步骤2还包括使用带有stride的卷积算法将采样从视频空间扩大网络视野场。
本发明的有益效果:
1、本发明基于视频运动估计的视频非均匀插帧算法,利用空间几何关系和时域运动关系进行视频插帧,通过深度学习用于运动估计和补偿预测,可用于视频帧率的提升,增加时间分辨率。
2、本发明方法,基于视频运动估计进行视频非均匀插帧,在编码中去除冗余信息并降低视频传输过程中的帧率,减少视频网络传输的数据量,因此可应用于视频压缩或增强视频连续性。
3、本发明方法,基于视频运动估计进行视频非均匀插帧,从而提升视频时间分辨率,提升视频流畅度,补偿缺失的运动信息。
4、本发明方法通过降采样提取视频运动信息,从而减少空间维度,并使用带有stride的卷积算法将采样从视频空间扩大网络视野场,扩大网络的感受野,并以此增强网络的运动估计能力。
5、本发明方法通过上采样过程中使用sub-pixel算法进行卷积特征的上采样恢复视频空间维度,并补偿细节。
6、本发明方法使用skip-connection算法将卷积神经网络的底层信息传输到网络的深层,用以视频插帧的特征提取和输出,提升卷积神经网络的特征的提取能力,并且可以避免网络优化时出现梯度爆炸。
7、本发明方法通过conv-lstm算法,学习视频时间序列上运动信息,并且基于conv-lstm具有在时间维度上可以输出多个卷积结果的特点,用以实现基于视频运动估计的视频多帧插帧。
附图说明
图1为本发明方法的流程图。
图2为本发明方法所用的神经网络结构图。
图3和图4为本发明的运动估计模块,其中,图3为卷积神经网络的前半部分即运动估计的降采样过程,图4为卷积神经网络的后半部分即运动估计的上采样过程。
图5和图6是本发明实施例的两个相关联的真实视频帧1和真实视频帧2。
图7至图9是本发明实施例中生成的三个插入帧,即中间插帧1、中间插帧2、中间插帧3。
具体实施方式
参见图1,本发明基于卷积神经网络的视频插帧方法,包括以下步骤:
1)从输入视频中选取相关联的前后帧,并进行归一化,然后输入到卷积神经网络中;
2)参见图2,使用稠密连接网络对归一化处理后的前后帧进行卷积特征提取;再使用带有stride的卷积算法将采样从视频空间扩大网络视野场,然后卷积神经网络前半部分对归一化处理后的前后帧进行降采样处理(参见图3),提取前后帧视频间运动信息;再次使用稠密连接网络对降采样处理后的前后帧进行卷积特征提取,然后卷积神经网络后半部分编码模块对降采样处理后的前后帧视频间运动信息进行上采样处理(参见图4),恢复视频空间维度并补偿细节;同时,卷积神经网络中间部分,通过skip-connection连接,将网络底层的信息传输到深层网络中;其中,网络的整体结构为编解码u-net模块,编码模块为3层卷积模块,降采样优选conv-lstm算法,上采样优选sub-pixel算法;
3)将步骤2中进行上采样处理后的信息,输入双向lstm卷积层,循环输出多个中间视频帧;
4)通过预训练的flownet分别计算步骤3中的中间视频帧光流和真实视频帧光流;然后计算中间视频帧光流与真实视频帧光流之间的均方误差;
5)将步骤4中的均方误差作为视频非均匀插帧计算的优化目标函数,使flownet参与网络优化中梯度后向传播过程,实现视频插帧的优化。
以中间插帧三帧为例,将视频中相连的两帧,即真实视频帧1(图5)和真实视频帧2(图6),输入到卷积神经网络,分别经由稠密连接网络对归一化处理后的前后帧进行卷积特征提取,通过两次降采样运动估计模块处理后,提取得到前后帧视频间运动信息;输入卷积神经网络后半部分编码模块,通过两次上采样运动估计模块的处理后,还原至与输入视频一致的空间尺寸,并通过conv-lstm算法输出中间插帧结果,即中间插帧1(图7)、中间插帧2(图8)、中间插帧3(图9)。可以看出,中间插帧相对于真实视频帧1,激光刀在逐渐向左方移动,并逐渐靠近真实视频帧2中激光刀的位置,而对于视频帧中相对稳定的肿瘤部分,视频插帧结果与真实视频帧1和真实视频帧2一样保持稳定。
- 还没有人留言评论。精彩留言会获得点赞!