一种基于深度强化学习的上行NOMA资源分配方法与流程
一种基于深度强化学习的上行noma资源分配方法
技术领域
1.本发明涉及移动通信和强化学习邻域,具体涉及一种基于深度强化学习的上行noma无线资源分配方法。
背景技术:
2.第五代通信网络(5g)需要满足飞速上涨的无线数据流量需求,支持高密度的移动用户通信,并且提供各种无线网络服务。最近提出的非正交多址接入技术(non
‑
orthogonal multiple access,noma),被认为是一种可以有效提高网络容量,满足低延迟、大规模连接和高吞吐量的新兴技术。一方面,与传统的正交多址接入技术(orthogonal multiple access,oma)相比,noma在发射端利用叠加编码(superposition coding,sc)技术,用不同的功率等级把同一个子信道分配给多个用户同时传输,共享信道资源,然后在接收端利用串行干扰消除(successive interference cancellation,sic)技术消除干扰,使得频谱效率和系统容量大大提高,非常适合未来的移动通信。
3.另一方面,由于noma系统的性能增益与子信道和传输功率的分配方式密切相关,所以通过设计合理的资源分配方案,可以最大化整个noma系统的能量效率。从而实现利用较低的发送功率获得较高的传输速率,在充分利用noma技术优势的同时,减少不必要的资源浪费。目前已有的研究中提出了不同的方法来研究noma系统的最优资源分配方案。
4.通过对现有文献的检索发现。t.manglayev等人在《ieee international conference on application of information and communication technologies,oct.2016,pp.1
‑
4.(电气和电子工程师协会信息和通信技术应用国际会议,2016年10月,第1
‑
4页)》上发表了题为“optimum power allocation for non
‑
orthogonal multiple access(noma)(非正交多址(noma)的最佳功率分配)”一文。该文提出了一种结合公平性因子的最大化容量的功率分配算法,并且仿真证明了使用noma技术可以比原有oma技术获得更高的频谱效率。y.zhang等人在《ieee transactions on vehicular technology,mar.2017,vol.66,no.3,pp.2852
‑
2857.(电气和电子工程师协会车载技术期刊,2017年3月,第66卷,第3期,第2852
‑
2857页)》上发表了题为“energy
‑
efficient transmission design in non
‑
orthogonal multiple access(非正交多址的能量效率传输设计)”一文。该文提出了一种满足用户最小速率需求的最大化能量效率的功率分配策略。另检索发现,m.s.ali等人在《ieee transactions on communications,sep.2018,vol.66,no.9pp.3982
‑
3998.(电气和电子工程师协会通信期刊,2018年9月,第66卷,第9期,第3982
‑
3998页)》上发表了题为“downlink power allocation for comp
‑
noma in multi
‑
cell networks(多小区网络中协调多点noma的下行链路功率分配)”一文,该文研究了多小区的下行noma功率分配方案,并提出了一种分布式的功率优化算法来降低计计算复杂度,通过仿真分析了多小区noma系统的频谱效率和能量效率性能。以上三篇文献都仅注重于noma系统中的功率分配方案,然而,子信道分配方案的好坏对整个系统效率的提升也有很大的影响。
5.经检索还发现,c.l.wang等人在《ieee annual international symposium on personal,indoor and mobile radio communications,sep.2018,pp.1
‑
6.(美国电气电子工程师学会个人室内和移动无线电通信年度国际研讨会,2018年9月,第1
‑
6页)》上发表了题为“low
‑
complexity resource allocation for downlink multicarrier noma systems(下行链路多载波noma系统的低复杂度资源分配)”一文,该文在一般功率分配研究的基础上,提出了一种在noma系统中低复杂度的联合子信道和功率分配的方法。在该方法下,最优功率分配因子由闭式解得到,而最优子载波则基于低复杂度信道增益准则得到,并能取得比传统的正交频分多址方案更好的系统容量。虽然该方法的计算复杂度较低,但并不能保证找到最优的资源分配方案。
6.经检索专利发现,南京邮电大学朱晓荣等人发明了“一种下行mimo
‑
noma网络下的资源分配方法”(公开号:109922487a)。该发明技术公开了一种下行noma系统中的资源分配方法。通过获取用户的信道状态信息,对用户进行分簇,然后利用迫零波束成型理论为分簇的用户分配波束向。再分别使用匈牙利算法和子梯度算法在确定功率分配和信道分配的前提下得到最优信道分配和功率分配方案,交替迭代直到用户容量收敛,从而得到最优的资源分配方案。此外,检索还发现华南理工大学唐杰等人发明了“一种基于深度学习的携能noma系统的资源分配方法”(公开号:108924935a)。该项发明公开了一种在满足用户服务质量(quality of service;qos)的前提下,最小化发射功率的基于深度学习的联合资源分配方法。改方法首先构建携能noma系统中基于发射功率最小化的联合资源分配的数学优化问题,包括优化变量、优化目标函数及约束条件。然后采用遗传算法得到大量样本数据,训练深度置信网络来获取数据样本输入和输出之间的潜在信息。最后在运行阶段,利用训练好的网络直接输出最优的载波和功率分配策略。该方法在网络训练完成的情况下能够高效地得到资源分配方案,实现了低功耗的资源分配,更加符合低时延的要求。
7.虽然已存在的这些资源分配方案都在一定程度上提高了整个noma系统的能量效率或是其他指标,但这些方案都存在一定的局限性。例如对于传统的基于模型的资源分配方案来说,优化过程的计算复杂度较高,迭代算法所花费的时间较长。而基于深度学习的优化算法虽然降低了计算复杂度,但依然需要大量时间构造足够的样本数据训练网络才能达到良好的性能。
技术实现要素:
8.本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于深度强化学习(deep reinforcement learning,drl)的上行noma多用户场景下的联合子信道分配和功率分配方法,在保证用户最小速率需求的同时,最大化整个系统的能量效率。作为机器学习的一大分支,drl结合了传统的强化学习和深度学习里的神经网络,通过不断地互动来收集系统的反馈信息,动态地调整参数以更好地决策,从而最大化系统的性能。因此,drl不再需要系统的数学模型或是先验知识,更加适合解决未知系统的动态资源分配问题。本方法利用drl中的深度q网络(deep q network,dqn),根据用户的信道增益信息,先选择合适的子信道分配策略,再选择合适的功率分配策略,最后依照系统的反馈更新分配策略的参数,从而实现最优的子信道分配和功率分配,提高系统的能量效率。
9.本发明是通过以下技术方案实现的:
10.本发明是一种基于drl的上行noma系统的子信道分配和功率分配方法,用于解决多用户noma无线通信系统上行链路的资源分配问题,包括以下步骤:
11.s1、状态获取:在时刻t,基站获取小区内所有用户在不同子信道上的信道增益信息作为当前状态s
t
。
12.s2、子信道分配:基站处的子信道分配网络遵循ε
‑
greedy策略选择最优的子信道分配方案
13.s3、功率分配:得到子信道分配方案之后,激活基站处的功率分配网络,遵循ε
‑
greedy策略选择最优的功率分配方案
14.s4、反馈获取:所有用户按照两个网络输出的资源分配方案在给定的子信道上以给定的功率传输数据到基站。基站返回相应的反馈到资源分配网络。
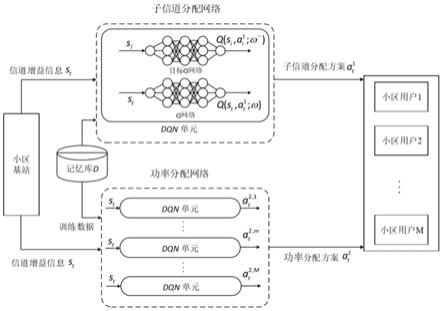
15.s5、参数更新:根据得到的反馈,基于经验重放和固定q值两个策略训练子信道分配网络和功率分配网络内的所有dqn单元的神经网络,更新网络的参数,从而更好地选择资源分配方案。
16.所述s1)的具体步骤为:
17.t时刻,基站获取所有用户的信道增益信息,则当前时刻下的状态s
t
表示为当前时刻所有用户在不同子信道上的信道增益。用g
k,m
(t)表示用户m在子信道k上的信道增益信息,那么s
t
表示如下:
18.s
t
={g
1,1
(t),g
2,1
(t),...,g
k,m
(t),..,g
k,m
(t)}
19.其中k和m分别表示小区内的子信道个数和用户个数,g
k,m
(t)包括大尺度衰落效应和小尺度衰落效。大尺度衰落效应指用户端与基站通信的信道路径上由于固定障碍物的阴影导致的衰落,包含平均路径损耗和阴影衰落;小尺度衰落则由多径效应引起,假设该效应对用户端的影响服从瑞利分布。
20.所述s2)的具体步骤为:
21.得到当前状态s
t
之后,s
t
被传送到基站处的子信道分配网络。该网络由一个子信道分配dqn单元组成。该单元包含两个神经网络,即q网络q(s,s;w)和目标q网络q(s,a;w
‑
),w和w
‑
分别表示这两个神经网络的参数。
22.子信道分配dqn单元中的q网络根据得到的状态s
t
,利用网络参数w估计出所有子信道分配方案的q值,即:其中a1表示所有可能的子信道分配方案组成的集合。
23.之后,子信道分配dqn单元遵循ε
‑
greedy策略从所有子信道分配方案中选择一个作为当前的最佳分配方案。其中,ε
‑
greedy策略指:以概率1
‑
ε从a1中随机选择一个子信道分配方案做为t时刻的最优子信道分配方案输出;或者以概率ε选择那个拥有最大q值的方案,即选择:
[0024][0025]
其中0<ε<1。之后,子信道分配网络输出t时刻的子信道分配方案
[0026]
所述s3)的具体步骤为:
[0027]
在得到子信道分配方案之后,激活基站处的功率分配网络。该网络由m个功率分配dqn单元组成。每个功率分配dqn单元都包含与子信道分配单元相同的两个神经网络,但这些网络的参数都不一样。
[0028]
使用相同的状态s
t
作为输入,第m个功率分配dqn单元的q网络使用s2中相同的方法遵循ε
‑
greedy策略从所有功率分配方案的集合a2中选择一个,作为第m个传输功率输出。
[0029]
然后,所有m个功率分配dqn单元的输出由功率分配网络合并为t时刻的功率分配方案即:
[0030][0031]
所述s4)的具体步骤为:
[0032]
所有用户按照两个网络输出的资源分配方案在给定的子信道上以给定的功率传输数据到基站。若每个用户的传输速率都能满足最小速率需求,那么基站计算出所有用户的能量效率之和作为当前时刻t下的反馈r
t
到子信道分配网络和功率分配网络。若不能满足,则这两个资源分配网络获得的反馈为0,即
[0033][0034]
其中r
t
表示t时刻的反馈,r
min
表示最小速率需求,e
k,m
和r
k,m
分别表示用户m在子信道k上的能量效率和传输速率。之后,由于用户的移动,基站获取新的信道增益信息作为新的状态s
t+1
。
[0035]
所述s5)的具体步骤为:
[0036]
根据得到的系统反馈r
t
,基于经验重放和固定q值两个策略训练子信道分配网络和功率分配网络内所有dqn单元的神经网络,更新网络的参数,以更好地选择资源分配方案。具体参数更新的s包括:
[0037]
(1)将每个时刻的(s
t
,a
t
,r
t
,s
t+1
)存入记忆库d中作为神经网络的训练样本;
[0038]
(2)从d中随机选取n组样本(s
i
,a
i
,r
i
,s
i+1
)训练神经网络;
[0039]
(3)对于子信道分配网络,通过随机梯度下降的方法最小化损失函数来更新子信道分配dqn单元中的q网络的参数w。其中的损失函数表示如下:
[0040][0041][0042]
使用随机梯度下降法,则参数w的更新方式表示为:
[0043][0044]
其中y
i
表示由该dqn单元内的目标q网络q(s,α;w
‑
)产生的目标q值,α表示学习速率。
[0045]
(4)对于功率分配网络,使用与(3)相同的随机梯度下降法最小化m个功率分配dqn单元的损失函数,更新神经网络参数。对第m个功率分配单元来说,其损失函数表示如下:
[0046][0047][0048]
其中m={1,2,...,m}。然后使用随机梯度下降法更新对应的网络参数。
[0049]
(5)对于所有资源分配dqn单元内的m+1个目标q网络,每个一段固定的时间w就把对应的q网络的参数w赋值给自己的参数w
‑
,实现目标q网络参数的更新。
[0050]
与现有技术相比,本发明的有益效果在于:1)本发明是一种基于drl的、无模型的联合子信道分配和功率分配方法,计算复杂度低,可以高效地得到最优资源分配方案,提高上行noma系统的能量效率。并且在不同的发送功率限制的条件下都能取得良好性能。2)为了将dqn应用于功率分配任务,本发明在传统dqn的基础上进行了改进,提出了一种离散化的、分布式的dqn网络,降低了网络的输出维度,进而提高了整个功率分配网络的性能。
附图说明
[0051]
图1是本发明所述的上行多用户noma系统示意图;
[0052]
图2是本发明所述的基于drl的联合子信道和功率分配方法框架示意图;
[0053]
图3是本发明所述的方法在不同学习速率下损失函数随时间变化的示意图;
[0054]
图4是本发明所述的基于drl的联合子信道和功率分配方法与其他方法的平均总能量效率对比示意图;
[0055]
图5是本发明所述的基于drl的联合子信道和功率分配方法与其他方法在不同传输功率限制下的平均总能量效率示意图。
具体实施方式
[0056]
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护权限不限于下述的实施例。基于本发明的任何实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施例,都属于本发明所保护的范围。
[0057]
本发明是一种基于drl的上行noma系统的联合子信道分配和功率分配方法。如图1所示,该noma无线通信系统中的基站位于小区中央,本发明的子信道分配网络和功率分配网络均位于基站处的drl控制器内。m个用户随机分布在小区内,并在每个时隙之间进行随机移动。基站的总带宽被平均分成k个相互正交的子信道。每个子信道可以同时服务多个用户。每个用户终端的最大传输功率为p
max
。用b
k,m
(t)和p
k,m
(t)分别表示t时刻下,用户m在子信道k上的子信道分配标记和分配的功率。其中,b
k,m
(t)=1表示t时刻用户m被分配到子信道k上,否则b
k,m
(t)=0。
[0058]
本实施例通过以下步骤实现:
[0059]
s1)状态获取:基站获取时刻t小区内所有用户在不同子信道上的信道增益信息作为当前状态s
t
。
[0060]
用g
k,m
(t)表示t时刻下,用户m在子信道k上的信道增益信息。该信息由两部分组
成,分别是t时刻下的大尺度衰落β
k,m
(t)和小尺度衰落h
k,m
(t)。其中,大尺度衰落指用户端与基站通信的信道路径上由于固定障碍物的阴影导致的衰落,包含平均路径损耗和阴影衰落;小尺度衰落则由多径效应引起,假设该效应对用户端的影响服从瑞利分布。那么g
k,m
(t)可以表示为:
[0061][0062]
则当前时刻t下的状态s
t
表示如下:
[0063]
s
t
={g
1,1
(t),g
2,1
(t),...,g
k,m
(t),...,g
k,m
(t)}
[0064]
s2)子信道分配:根据得到的s
t
,基站处的drl控制器内的子信道分配网络遵循ε
‑
greedy策略选择最优的子信道分配方案
[0065]
子信道分配方案可由子信道分配标记b
k,m
(t)表示为:
[0066][0067]
其中b
k,m
(t)的取值可以为0或1。所有可能的分配方案组成了子信道分配方案集合a1。
[0068]
基站获得的状态s
t
被传输到drl控制器内的子信道分配网络,该网络由一个子信道分配dqn单元组成。该单元包括两个神经网络,分别为q网络q(s,a;w),和目标q网络q(s,a;w
‑
),w和w
‑
分别表示这两个网络的网络参数。其中,q网络用于估计所选动作的q值,而目标q网络则用于产生目标q值以训练网络参数。
[0069]
用获得的s
t
作为输入,子信道分配dqn单元中的q网络利用参数w输出所有子信道分配方案的估计q值,即:在得到所有的估计q值之后,子信道分配dqn单元遵循ε
‑
greedy策略从a1中选择一个方案作为当前时刻t下的最优子信道分配方案
[0070]
其中,ε
‑
greedy策略是指:以概率1
‑
ε从a1中随机选择一个子方案或者以概率ε选择那个拥有最大估计q值的方案,即
[0071][0072]
其中ε的取值范围为0<ε<1。ε越小,基站就越倾向于尝试选择其他的分配方案,ε越大,基站就越倾向于选择q值最大的那个分配方案。
[0073]
之后,子信道分配网络输出t时刻下的最优子信道分配方案
[0074]
s3)功率分配:在得到子信道分配方案之后,激活基站处drl控制器内的功率分配网络,遵循ε
‑
greedy策略选择最优的功率分配方案
[0075]
功率分配方案可由每个用户在不同子信道上分配的功率p
k,m
(t)表示为:
[0076][0077]
其中0≤p
k,m
(t)≤p
max
。由于只需要决定分配给用户m的子信道上的传输功率,而用户m在其他子信道上的功率可以无需考虑,所以令:
[0078][0079]
这样能够减少dqn单元输出的维度以提高性能。
[0080]
此外,由于可供分配的功率区间是一个连续值,所以必须离散化功率以适配dqn的输入输出。但是,功率离散化会带来输出维度的指数式上涨,因此本方案使用一种分布式的构架以解决此问题。
[0081]
本方案中drl控制器内的功率分配网络包含m个功率分配dqn单元,每个单元负责一个用户的功率分配任务,则功率分配方案的表达形式转化为:
[0082][0083]
其中表示第m个功率分配dqn单元在t时刻做出的功率分配方案。设功率被离散化成了l个等级,则有l种可选的功率,表示为:
[0084][0085]
在s2中得到子信道分配方案之后,激活功率分配网络内的m个功率分配dqn单元。每个功率分配dqn单元都包含与上述子信道分配dqn单元相同的两个神经网络,但是这些神经网络的参数都不一样。使用相同的状态s
t
作为输入,第m个功率分配单元的q网络输出估计的q值,并遵循ε
‑
greedy策略从所有的功率分配方案中选择一个,作为第m个用户的传输功率输出。这m个输出的功率合并为功率分配方案作为t时刻下的最优子信道分配方案输出。
[0086]
s4)反馈获取:所有用户按照子信道分配网络和功率分配网络输出的资源分配方案在给定的子信道上以给定的功率传输数据到基站。基站返回所有用户的能量效率之和作为反馈。
[0087]
已知子信道分配方案和功率分配方案之后,所有b
k,m
(t)和p
k,m
(t)的取值便已知。根据上行noma传输原则,用户m在子信道k上的信号与干扰加噪声比表示如下:
[0088][0089]
其中表示高斯白噪声的方差。使用归一化的带宽,那么相应的传输速率表示为:
[0090]
r
k,m
(t)=log(1+γ
k,m
(t))
[0091]
则用户m在子信道k上的上行能量效率为:
[0092][0093]
其中p
m
表示由于用户设备自身运行所消耗的一部分能量。
[0094]
t时刻的反馈定义为当前时刻所有用户在所有子信道上的能量效率之和。若每个用户的传输速率r
k,m
(t)都能满足最小速率需求r
min
,那么基站计算出所有用户的能量效率
之和作为当前时刻t下的反馈r
t
到子信道分配单元和所有功率分配单元。若不能满足,则所有资源分配单元获得的反馈r
t
=0,即
[0095][0096]
之后,由于用户的移动,所有用户的信道增益信息发生改变,基站再次获取所有用户的信道增益信息作为新的状态s
t+1
。
[0097]
s5)参数更新:根据s4中得到的系统反馈r
t
,基于经验重放和固定q值两个策略训练子信道分配网络和功率分配网络内所有dqn单元的神经网络,更新网络的参数,以更好地选择资源分配方案。具体参数更新的s包括:
[0098]
(1)将每个时刻的(s
t
,a
t
,r
t
,s
t+1
)存入记忆库d中作为神经网络的训练样本;
[0099]
(2)从d中随机选取n组样本(s
i
,a
i
,r
i
,s
i+1
)训练神经网络;
[0100]
(3)对于子信道分配网络,通过随机梯度下降的方法最小化损失函数来更新子信道分配dqn单元的q网络的参数w。子信道分配dqn单元的损失函数表示如下:
[0101][0102][0103]
使用随机梯度下降法,则参数w的更新方式表示为:
[0104][0105]
其中y
i
表示由该dqn单元内的目标q网络q(s,a;w
‑
)产生的目标q值,α表示学习速率。
[0106]
(4)对于功率分配网络,使用与s(3)中相同的随机梯度下降法最小化m个功率分配dqn单元的损失函数,更新神经网络参数。对第m个功率分配单元来说,它的损失函数表示如下:
[0107][0108][0109]
使用随机梯度下降法,第m个功率分配单元的参数更新方式表示为:
[0110][0111]
其中m={1,2,...,m}。
[0112]
(5)对于所有资源分配dqn单元内的m+1个目标q网络,每个一段固定的时间w就把对应的q网络的参数w赋值给自己的参数w
‑
,实现目标q网络参数的更新。
[0113]
图2是本发明所述的基于drl的联合子信道和功率分配方法框架示意图。
[0114]
本实例考虑多用户上行noma场景,对所有用户进行联合子信道和功率分配的优
化,本实例仿真场景的主要参数如表1所示。
[0115]
表1仿真场景主要参数
[0116][0117][0118]
图3是本发明所述的方法在不同学习速率下损失函数随时间变化的示意图。该图从上往下分别是本发明方法中的学习速率α被设置成0.001、0.005和0.01的情况。仿真结果显示,本发明的算法具有很好的收敛性。由图3所示,三种学习速率情况下的损失函数一开始都很大,并随着时隙数增加迅速下降,且都在20步以内收敛。特别地,当α=0.01时,只需要几步就能使损失函数达到最小值,并且之后都趋于稳定。因此,使用这种学习速率可以提供更快的收敛速率,以最小化损失函数,从而使得q值的预测变得更准确,进而使网络的性能更好。
[0119]
图4是本发明所述的基于drl的联合子信道和功率分配方法与其他方法的平均能量效率对比示意图。该图从上往下分别是本发明提出的基于drl的资源分配方法(dqn)、使用穷举搜索和随机传输功率的方法(optrp)、使用穷举搜索和最大传输功率的方法(optmp)以及使用随机子信道和最大传输功率(rcmp)的方法。其中穷举搜索是指遍历所有子信道方案,然后选择使得能量效率最高的子信道分配方案的方法。需要注意的是,为了更好地显示仿真结果,总能量效率每100步取滑动平均。由图可以看出应用本发明的资源分配方案的noma系统的能量效率性能远远高于其他方法的性能。因为本发明方法可以根据用户的实时信道信息,动态地选择发送功率,自适应地调整资源分配方案。在满足最低速率需求的基础上,减少不必要的发送功率,从而能够提供更多的能量效率。通过对比还能发现,使用穷举
搜索得到的能量效率远远超过使用随机子信道的能量效率。这也说明子信道的分配对整个noma系统的性能增益有着很大的影响。
[0120]
图5是本发明所述的基于drl的联合子信道和功率分配方法与其他方法在不同传输功率限制下的平均能量效率示意图。该图显示了在不同最大传输功率的限制下,各个方案在所有时隙上的平均能量效率。由图可见,随着最大传输功率的增加,本方法的平均能量效率也增加并趋于一最大值,而其余三种方法的平均能量效率都在增加后有不同程度的下降。此外,由图可以看出本发明方法在大多数最大传输功率条件下都优于其他方法。
[0121]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1