一种基于模型驱动深度学习的多用户MIMO接收方法与流程
本发明涉及一种无线通信技术领域的信号接收方法,具体是一种基于模型驱动深度学习的多输入多输出(mimo)无线信号的联合信道估计和信号检测方法。
背景技术:
随着5g网络时代到来,高数据率和高质量的通信系统成为移动通信的研究目标。mimo通过对信道资源的一种复用,实现信息的高速率传输。该技术在不增加频谱资源和天线发射功率的前提下,可以成倍的提高系统信道容量。因此mimo已经成为下一代无线通信的关键技术之一。而mimo接收算法的性能直接影响到mimo系统的信号质量。如何提高mimo接收机性能一直都是研究的热门课题。
近年来,人工智能技术深入到了生活工作的各个领域。近年来随着深度学习的理论的完善和gpu的数据处理能力的飞速提高,深度学习作为人工智能的一个关键技术,已经广泛的运用在计算机视觉、自然语言处理和语音识别等领域,并且取得的显著的成果。与此同时,在无线通信的领域中,人们也逐渐开始关注深度学习这一新技术。在现有文献中,已经有利用深度学习技术解决波束赋形,信道估计以及信号检测等问题。目前来看,基于深度学习的无线通信方法分为数据驱动和模型驱动两个主流方法。数据驱动深度学习方法将通信的某个模块看作黑盒子,利用深度学习网络替代这个模块,其中此方法利用的深度学习网络包括全连接网络(dnn)、卷积神经网络(cnn)以及循环神经网络(rnn)等。例如haoye等人在《ieeewirelesscommunicationslettersfeb.2018,pp.114-117.(电气电子工程师协会无线通信快报,2018年2月,第114-117页)》上发表了题为“powerofdeeplearningforchannelestimationandsignaldetectioninofdmsystems(正交频分复用系统中信道估计和信号检测的深度学习能力)”一文,该文章采用数据驱动的方法,通过大量的训练数据来训练该深度网络模型,最终实现了对ofdm系统精准的信道估计和信号检测,然而数据驱动的缺点在于训练参数多,难度大,时间久,不适于应对多变的环境。模型驱动则是将根据已知的通信领域的知识和机制构建网络。经检索,neevsamuel等人在《2017ieee18thinternationalworkshoponsignalprocessingadvancesinwirelesscommunications(spawc)2017,pp.1-5.(2017年ieee第18届无线通信信号处理进展国际研讨会(spawc),2017年,第1-5页)》上发表了题为“deepmimodetection(深度多输入多输出检测)”一文。该文采用模型驱动深度学习的方式,通过展开投影梯度迭代算法,并且加入了可训练参数,通过训练之后获得了可用于mimo信号检测的方案,获得了更好的检测性能以及更快的收敛速度。
经检索发现,东南大学金石等人发明了“一种数据模型双驱动的mimo接收机”(公开号:cn109391315a)。该发明公开了一种数据模型双驱动的mimo接收机,由t层相同结构的网络串联而成,其中每层网络均包括最小均方误差去噪器和线性估计器;将信道状态信息和接收信号作为每层网络的输入,其中第t层网络结合第(t-1)层网络的输出计算得到错误方差向量;第t层网络根据输入的待训练参数、错误方差估计向量和线性估计器计算得到外信息,并根据外信息采用最小均方误差去噪器计算得到后验概率均值,同时输出并传递至下一层网络;由第t层网络输出发送符号的估计值。该发明可以大幅提升网络性能,实现动态更新,网络自适应,可提升接收机性能,在传统迭代接收机的基础上获得显著的性能增益。此外,检索还发现东南大学黄永明等人发明了“一种基于低复杂度接收机的上行大规模mimo系统的功率控制方法”(公开号:cn105744613a)。该发明公开了一种基于低复杂度接收机的上行大规模mimo系统的功率控制方法,在上行大规模mimo系统,采用截断多项式(tpe)接收机,以截断多项式作为最小均方误差(mmse)接收机中的求逆矩阵;基站获取统计信道状态信息,采用迭代算法联合优化tpe接收机的多项式系数和用户的上行发送功率。该发明有效避免mmse接收机的大维矩阵求逆运算,降低了复杂度,同时性能可以逼近mmse接收机。
但是目前基于深度学习的mimo接收方法都是基于信道信息完全已知的情况下的,并没有将信道估计所产生的误差考虑在内,并且训练的参数过多,训练时间长,因此无法适应于环境多变的情况。
技术实现要素:
:
本发明的目的在于针对现有技术的不足,提供一种模型驱动深度学习的mimo接收方法,这种方法没有完全依赖于大量的数据驱动,而是通过与mimo信号处理接收知识结合进一步提升接收性能和降低训练时间,同时完成信道估计和信号检测。
本发明是通过以下技术方案实现的:
一种模型驱动深度学习的mimo接收方法,包括以下步骤:
s1、将接收的导频信号yp输入至最小二乘(ls)信道估计器进行初始化信道估计,然后将最小二乘估计器得到的估计结果,送到一个全连接的神经网络来获得更精确的信道信息
s2、将接收的数据信号yd和s1获得的信道信息
s3、通过对信道估计和信号检测内神经网络的训练,来获得最佳的网络参数。
进一步的,s1具体包括:
s11、接收信号由导频信号和数据信号组成,即y=(yp,yd),其中yp是接收的导频信号,yd是接收的数据信号。将接收导频信号yp和本地导频信号xp输入到最小二乘估计(ls)器进行初始化结果
s12、将最小二乘估计器得到的初始化结果
o=net1(i)=f0(w0fl(wlfl-1(...f1(w1i+b1)...)+bl)+b0)
其中,i和o分别为深度神经网络的输入和输出数据,wi、bi和fi(i=0,1,...,l)分别为第i层神经网络的权重、偏差和激活函数,其中l为隐含层的层数。因此经过net1得到信道信息
进一步的,s2具体包括:
s21、将接收的数据信号yd和估计的信道信息
s22、将信道估计结果
式子中,(·)t代表着转置,tanh为双曲线函数,ζi、θi和γi为学习参数。
进一步的,s3具体包括:
s31、信道估计模块深度学习网络net1的训练,损失函数设置为平方误差损失(mse):
其中χ为线下产生的该数据模块训练集,|χ|表示训练集的大小。
s32、信号检测模块深度学习网络net2的训练采用逐级训练的方式,所谓逐层训练,指的是训练多次,每次训练的层数依次递增,前一次的训练结果作为下一次训练的初始化结果,其中第i轮的训练损失函数设置为平方误差损失(mse):
其中ν为线下产生的该模块数据训练集,|ν|表示训练集的大小。
附图说明
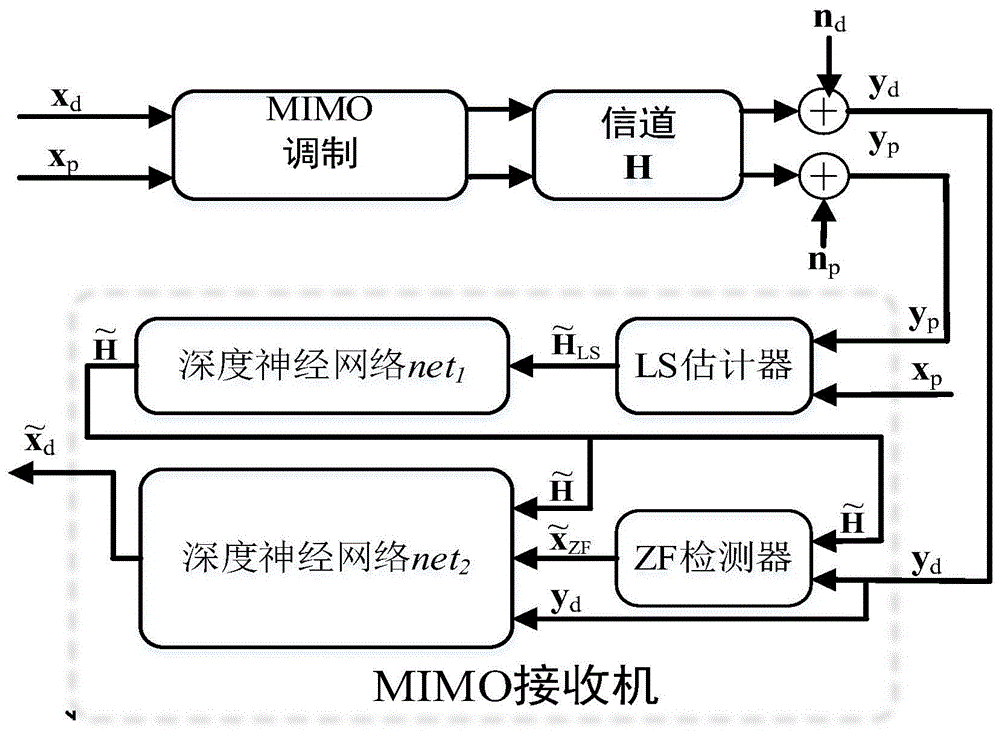
图1为本发明的一个实施案例的mimo系统流程示意图;
图2为本发明的基于深度学习的信道估计模块框图;
图3为本发明的基于深度学习的信号检测模块框图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护权限不限于下述的实施例。
本实施例通过以下步骤实现:
如图1所示,是实施案例的mimo系统流程示意图,其中,假设在一个相干时间内,信道信息保持不变,导频信号和数据信道在一个帧内传输。发送数据的星座调制方式为qpsk,在发射端,由多个单天线的用户构成,接收端为配置了多个天线的基站。发送信号经过信道传输后在接收端被接收。本方法具体包括以下步骤:
(1)信道估计
接收信号由导频信号和数据信号组成,即y=(yp,yd),其中yp是接收的导频信号,yd是接收的数据信号。将接收导频信号yp和本地导频信号xp输入到最小二乘(ls)信道估计器进行初始化结果
将最小二乘估计器得到的初始化结果
o=net1(i)=f0(w0fl(wlfl-1(...f1(w1i+b1)...)+bl)+b0)
其中,i和o分别为深度神经网络的输入和输出数据,wi、bi和fi(i=0,1,...,l)分别为第i层神经网络的权重、偏差和激活函数,其中l为隐含层的层数。因此通过net1得到的更为精确的信道信息
(2)信号检测
将接收的数据信号yd和估计的信道信息
将信道估计结果
式子中,(·)t代表着转置,tanh为双曲线函数,ζi、θi和γi为可学习参数。
(3)深度学习网络的训练
信道估计模块深度学习网络net1的训练,损失函数设置为平方误差损失:
其中χ为线下产生的训练集,|χ|表示训练集的大小。
信号检测模块深度学习网络net2的训练采用逐级训练的方式,所谓逐层训练,指的是训练多次,每次训练的层数依次递增,前一次的训练结果作为下一次训练的初始化结果,其中第i轮的训练损失函数设置为平方误差损失:
其中ν为线下产生的训练集,|ν|表示训练集的大小。
在训练的过程中,我们采用一种随机梯度下降(sgd)的方法,即adam优化算法。训练时采用批量训练,其中,在训练信道估计模块的时候,每一个批量的大小为500条数据集,一共训练200轮,每轮中包含10个批量,初始学习速率设置为为0.001,并且在接下来的训练中每40轮,学习速率缩小5倍。在训练信号检测的模块中,学习速率设置为0.001,对于每一层都训练1000轮,每一轮中包含1250组训练数据。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!