一种负载均衡方法及相关装置与流程
本申请涉及计算机技术领域,特别涉及一种负载均衡方法、负载均衡装置、服务器以及计算机可读存储介质。
背景技术:
目前为了保持入口流量的稳定运行,一般采用四层负载均衡。四层负载均衡工作在osi(opensysteminterconnectionreferencemodel,开放式系统互联通信参考模型)模型的传输层,由于在传输层,只有tcp(transmissioncontrolprotocol,传输控制协议)/udp(userdatagramprotocol,用户数据报协议)协议,这两种协议中除了包含源ip(internetprotocol,网际互连协议)、目标ip以外,还包含源端口号及目的端口号。四层负载均衡服务器在接收到客户端请求后,通过修改数据包的地址信息将流量转发到应用服务器。
相关技术中,一般软负载均衡方案是基于linux内核的网络协议栈,但是随着网卡速率的不断提升,linux内核的处理能力降低了网络交换的效率,进一步的降低了实现的软负载均衡的效率,也降低了负载均衡性能。
因此,如何提高负载均衡的性能是本领域技术人员关注的重点问题。
技术实现要素:
本申请的目的是提供一种负载均衡方法、负载均衡装置、服务器以及计算机可读存储介质,通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步提高了负载均衡的性能。
为解决上述技术问题,本申请提供一种负载均衡方法,包括:
负载均衡服务器控制多个网卡队列接收通过ecmp协议分发的流量数据;
采用与每个网卡队列绑定的cpu对所述流量数据进行解封处理,得到待转发数据;
通过配置的nginx的负载均衡功能采用轻量级ip协议栈将所述待转发数据进行封装转发。
可选的,采用与每个网卡队列绑定的cpu对所述流量数据进行解封处理,得到待转发数据,包括:
根据dpdk库确定每个网卡队列绑定的cpu;
每个网卡队列将流量数据发送至对应的cpu中,控制所述cpu对接收到的流量数据进行解封处理,得到待转发数据。
可选的,通过配置的nginx的负载均衡功能采用轻量级ip协议栈将所述待转发数据进行封装转发,包括:
通过配置的所述nginx的负载均衡功能对所述待换发数据确定对应的转发地址;
采用所述轻量级ip协议栈将所述待转发数据进行封装,并根据对应的转发地址进行发送。
可选的,在所述将所述待转发数据进行封装转发的步骤之前,还包括:
将移植的freebsd用户空间协议栈进行配置,得到所述轻量级ip协议栈。
可选的,还包括:
交换机根据所述ecmp协议将接收到的原始流量数据分流发送至所述多个网卡队列。
可选的,还包括:
所述负载均衡服务器的控制平面cpu通过无锁队列与所述多个网卡队列对应的cpu进行通信。
本申请还提供一种负载均衡装置,包括:
流量数据接收模块,用于控制多个网卡队列接收通过ecmp协议分发的流量数据;
解封处理模块,用于采用与每个网卡队列绑定的cpu对所述流量数据进行解封处理,得到待转发数据;
封装转发模块,用于通过配置的nginx的负载均衡功能采用轻量级ip协议栈将所述待转发数据进行封装转发。
可选的,还包括:
协议栈获取模块,用于将移植的freebsd用户空间协议栈进行配置,得到所述轻量级ip协议栈。
可选的,还包括:
交换机,用于根据所述ecmp协议将接收到的原始流量数据分流发送至所述多个网卡队列。
可选的,还包括:
控制平面cpu,用于通过无锁队列与所述多个网卡队列对应的cpu进行通信。
本申请还提供一种服务器,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现如上所述的负载均衡方法的步骤。
本申请还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的负载均衡方法的步骤。
本申请所提供的一种负载均衡方法,包括:负载均衡服务器控制多个网卡队列接收通过ecmp协议分发的流量数据;采用与每个网卡队列绑定的cpu对所述流量数据进行解封处理,得到待转发数据;通过配置的nginx的负载均衡功能采用轻量级ip协议栈将所述待转发数据进行封装转发。
通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步采用绑定的cpu进行处理,避免了锁处理降低数据处理的等待时间,提高了负载均衡的性能。
本申请还提供一种负载均衡装置、服务器以及计算机可读存储介质,具有以上有益效果,在此不做赘述。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
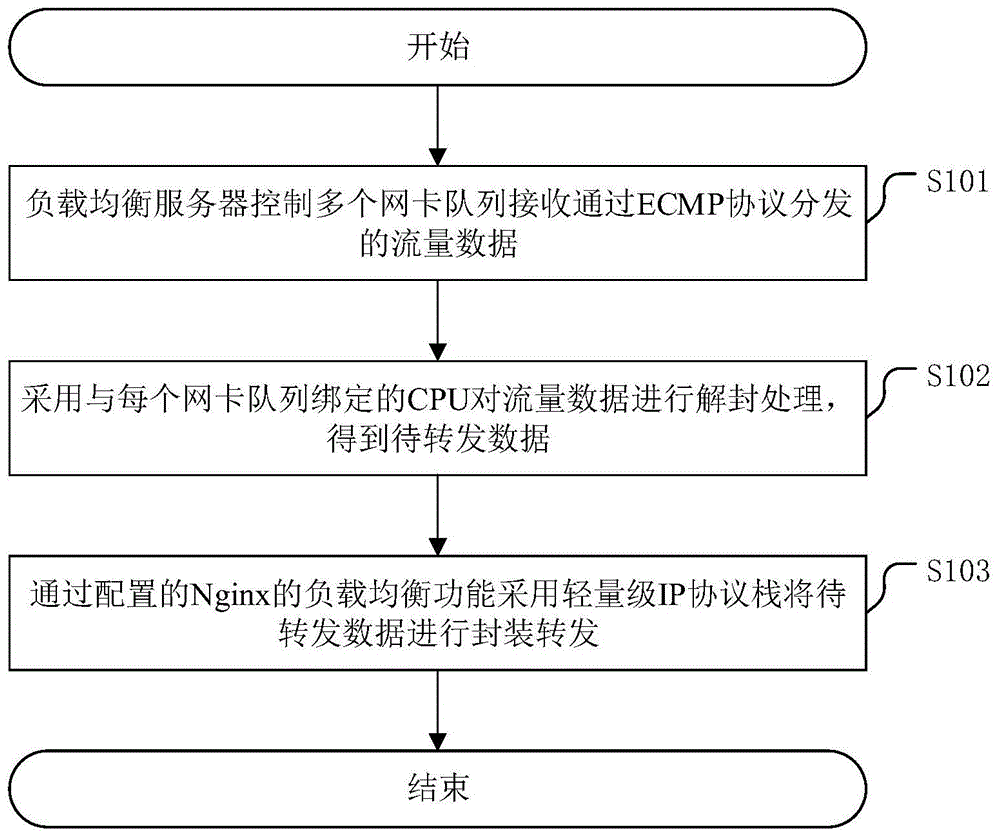
图1为本申请实施例所提供的一种负载均衡方法的流程图;
图2为本申请实施例所提供一种负载均衡装置的结构示意图;
图3为本申请实施例所提供的负载均衡方法的结构示意图。
具体实施方式
本申请的核心是提供一种负载均衡方法、负载均衡装置、服务器以及计算机可读存储介质,通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步提高了负载均衡的性能。
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
相关技术中,一般软负载均衡方案是基于linux内核的网络协议栈,但是随着网卡速率的不断提升,linux内核的处理能力降低了网络交换的效率,进一步的降低了实现的软负载均衡的效率,降低了负载均衡性能。
因此,本申请提供一种负载均衡方法,通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步采用绑定的cpu进行处理,避免了锁处理降低数据处理的等待时间,提高了负载均衡的性能。
以下通过一个实施例,对本申请提供的一种负载均衡方法进行说明。
请参考图1,图1为本申请实施例所提供的一种负载均衡方法的流程图。
本实施例中,可以采用内核旁路技术,诸如dpdk(dataplanedevelopmentkit),数据平面开发套件)、netmap(输入输出框架)。内核旁路的作用主要是通过linux处理控制流,所有的数据流都在用户空间处理,因此内核旁路可以有效避免内核包拷贝、性能调度、系统调用以及中断引起的性能瓶颈。并且,内核旁路技术通过多种优化手段可以获得更高的性能。
因此,本实施例中的将控制面与数据面分离,控制面走传统的内核协议栈,数据面走轻量级ip协议栈。采用经典的master(管理者)/worker(工作者)模型。master处理控制平面,比如参数配置、统计获取等;worker实现核心负载均衡、调度、数据转发功能。另外,使用多线程模型,每个线程绑定到一个cpu(centralprocessingunit,中央处理器)物理核心上,并且禁止这些cpu被调度。这些cpu只运行master或者某个worker,以此避免上下文切换,别的进程不会被调度到这些cpu,worker也不会迁移到其他cpu造成缓存失效,提高设备进行负载均衡的并行处理能力。
该方法可以包括:
s101,负载均衡服务器控制多个网卡队列接收通过ecmp协议分发的流量数据;
可见,本步骤旨在每个网卡队列接收到分发的数据流量。其中,本实施例中的负载均衡服务器包括了多个网卡,对该多个网卡分配多个网卡队列。其中,可以是多个网卡对应一个网卡队列,也可以是一个网卡对应多个网卡队列,在此不做具体限定。进一步的,可以是根据dpdk库确定每个网卡队列绑定的cpu;每个网卡队列将流量数据发送至对应的cpu中,控制所述cpu对接收到的流量数据进行解封处理,得到待转发数据。
其中,ecmp(equalcostmulti-path,等价路由)协议是指等价多路径协议。即存在多条到达同一个目的地址的相同开销的路径。当设备支持等价路由时,发往该目的ip(internetprotocol,网际互连协议)或者目的网段的三层转发流量就可以通过不同的路径分担,实现网络的负载均衡,并在其中某些路径出现故障时,由其它路径代替完成转发处理,实现路由冗余备份功能。
进一步的,本实施例为了提高数据分发的可靠性,还可以包括:
交换机根据ecmp协议将接收到的原始流量数据分流发送至多个网卡队列。
可见,本可选方案中说明本实施例中的流量数据如何被分发。具体的,本实施例中通过交换机根据ecmp协议将接收到的原始流量数据分流发送至多个网卡队列。其中,交换机可以是实体交换机,也可以是虚拟交换机。
s102,采用与每个网卡队列绑定的cpu对流量数据进行解封处理,得到待转发数据;
在s101的基础上,本步骤旨在采用与每个网卡队列绑定的cpu对流量数据进行解封处理,得到待转发数据。进一步的,本步骤可以包括:通过配置的所述nginx的负载均衡功能对所述待换发数据确定对应的转发地址;采用所述轻量级ip协议栈将所述待转发数据进行封装,并根据对应的转发地址进行发送。
其中,对每个网卡队列绑定有对应的cpu,该cpu仅仅处理对应的网卡队列的数据。因此,可以避免各个网卡队列之间的数据处理相互影响。在具体的实施例过程中,可以避免对数据进行加锁处理。由于没有加锁处理,因此在数据处理中避免了数据锁导致的等待问题,降低了数据进行处理的时长,提高了处理速度。
进一步的,为了提高数据的处理能力,使本实施例中的网卡支持多个队列,队列可以和cpu绑定,使不同的cpu处理对应的网卡队列的流量,分摊工作量,实现并行处理和线性扩展。由各个worker使用dpdk的api处理不同的网卡队列,每个worker处理某网卡的一个接收队列,一个发送队列,实现了处理能力随cpu核心、网卡队列数的增加而线性增长,增加了处理数据的能力。
s103,通过配置的nginx的负载均衡功能采用轻量级ip协议栈将待转发数据进行封装转发。
在s102的基础上,本步骤旨在通过配置的nginx的负载均衡功能采用轻量级ip协议栈将待转发数据进行封装转发。也就是,先通过配置的nginx的负载均衡功能进行负载均衡分配处理,然后根据轻量级ip协议栈将负载均衡分配好的数据进行封装转发。
其中,nginx是一个高性能的http和反向代理web服务。nginx作为负载均衡服务:nginx既可以在内部直接支持rails和php程序对外进行服务,也可以支持作为http(hypertexttransferprotocol,超文本传输协议)代理服务对外进行服务。
进一步的,为了提高本实施例中使用协议栈的性能,本实施例还可以包括:
将移植的freebsd用户空间协议栈进行配置,得到轻量级ip协议栈。
可见,本可选方案主要是说明如何获取到轻量级ip协议栈。其中,可以是通过将freebsd用户空间协议栈进行移植获取到该轻量级ip协议栈。
进一步的,本实施例还可以包括:
负载均衡服务器的控制平面cpu通过无锁队列与多个网卡队列对应的cpu进行通信。
可见,本可选方案中的控制平面cpu与网卡队列对应的cpu之间通过无锁队列进行通行。也就是说,本实施例中的控制面的cpu与数据面的cpu直接通过无锁队列进行通行,避免出现cpu之间的等待情况,提高数据交换的效率。
综上,本实施例通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步采用绑定的cpu进行处理,避免了锁处理降低数据处理的等待时间,提高了负载均衡的性能。
以下通过一个具体的实施例,对本申请提供的一种负载均衡方法做进一步说明。
本实施例的网络结构,首先通过交换机堆叠组网,服务器和交换机间的bgp(bordergatewayprotocol,邻居发现协议),以及交换机本身的ecmp协议,实现了多活以及动态扩容、缩容的功能。
以4台slb(serverloadbalancer,负载均衡服务器)集群为例,同一集群内的slb宣告相同的vip(virtualipaddress,虚拟ip地址),在交换机侧形成ecmp等价路由,交换机根据五元组进行分流。当一台服务器(slb1)故障时,ecmp等价路由会减少,ecmp重新hash,原先没有故障服务器(slb2)上的会话也会重新调度到另外的机器上处理,会造成不必要的抖动。为了保证故障机器的流量被均分到剩余三台slb上,正常服务器上原先的流量保持不变,交换机需要支持一致性hash。ecmp等价路由会将流量均等的分配到4台slb服务器,而交换机的一直性hash则避免了当服务器出现故障时流量不必要的抖动。提高了集群系统的可靠性。
其中,高性能软负载均衡实现原理,基于dpdk和nginx实现,采用诸多的加速技术,转发效率高于内核态转发,匹配用户习惯,减少学习成本。
请参考图3,图3为本申请实施例所提供的负载均衡方法的结构示意图。
具体的,控制面与数据面分离,控制面走传统的内核协议栈,数据面走轻量级ip协议栈。采用经典的master/worker模型。master处理控制平面,比如参数配置、统计获取等;worker实现核心负载均衡、调度、数据转发功能。另外,使用多线程模型,每个线程绑定到一个cpu物理核心上,并且禁止这些cpu被调度。这些cpu只运行master或者某个worker,以此避免上下文切换,别的进程不会被调度到这些cpu,worker也不会迁移到其他cpu造成缓存失效。同时针对与交换机间的bgp报文处理,使用dpdk的rte_flow(dpdk中的功能)技术对报文精确匹配,利用五元组精确匹配bgp报文,bgp报文的处理会先于数据流量的处理,保证了服务器与交换机间的bgp邻居不断开。
进一步的,内核性能问题的一大原因就是资源共享和锁。因此,被频繁访问的关键数据需要尽可能的实现无锁化,其中一个方法是将数据做到per-cpu(每个cpu)化,每个cpu只处理自己本地的数据,不需要访问其他cpu的数据,这样就可以避免加锁。针对软负载均衡来说,其中的连接表、邻居表、路由表等都是频繁修改或者频繁查找的数据,都做到了per-cpu化。每个cpu维护不同的连接表,同一个数据流的包,只会出现在某个cpu上,不会落到其他的cpu上。这样就可以做到不同的cpu只维护自己本地的表,无需加锁。
相关技术中的网卡支持多个队列,队列可以和cpu绑定,让不同的cpu处理不同的网卡队列的流量,分摊工作量,实现并行处理和线性扩展。由各个worker使用dpdk的api处理不同的网卡队列,每个worker处理某网卡的一个接收队列,一个发送队列,实现了处理能力随cpu核心、网卡队列数的增加而线性增长。
进一步的,四层负载均衡并不需要完整的协议栈,但还是需要基本的网络组件。因此,本实施例中采用dpdk完成和周围设备的交互、确定分组走向、回应ping请求、健全性检查、以及ip地址管理等基本工作。使用dpdk提高了收发包性能,但也绕过了内核协议栈,依赖的协议栈需要自己实现,通过移植freebsd用户空间的协议栈,实现了软负载均衡自己的轻量级协议栈。
控制平面的master与数据平面的woker实现了跨cpu无锁消息,通信中不会存在互相影响、相互等待的情况,因为那会影响性能。为此,使用了dpdk提供的无锁rte_ring库,从底层保证通信是无锁的,并且在此之上封装一层消息机制来支持一对一,一对多,同步或异步的消息。加快了跨cpu的通信的速率。
可见,本实施例通过绑定的cpu对接收到的流量数据进行解封处理,进一步通过nginx的负载均衡功能采用轻量级ip协议栈将数据进行封装转发,而不是采用linux内核的网络协议栈进行处理,提高了负载均衡的处理能力,进一步采用绑定的cpu进行处理,避免了锁处理降低数据处理的等待时间,提高了负载均衡的性能。
下面对本申请实施例提供的负载均衡装置进行介绍,下文描述的负载均衡装置与上文描述的负载均衡方法可相互对应参照。
请参考图2,图2为本申请实施例所提供一种负载均衡装置的结构示意图。
本实施例中,该装置可以包括:
流量数据接收模块100,用于控制多个网卡队列接收通过ecmp协议分发的流量数据;
解封处理模块200,用于采用与每个网卡队列绑定的cpu对流量数据进行解封处理,得到待转发数据;
封装转发模块300,用于通过配置的nginx的负载均衡功能采用轻量级ip协议栈将待转发数据进行封装转发。
可选的,该解封处理模块200,可以包括:
cpu绑定单元,用于根据dpdk库确定每个网卡队列绑定的cpu;
数据解封单元,用于每个网卡队列将流量数据发送至对应的cpu中,控制所述cpu对接收到的流量数据进行解封处理,得到待转发数据。
可选的,该封装转发模块300,可以包括:
转发处理单元,用于通过配置的所述nginx的负载均衡功能对所述待换发数据确定对应的转发地址;
封装单元,用于采用所述轻量级ip协议栈将所述待转发数据进行封装,并根据对应的转发地址进行发送。
可选的,该装置还可以包括;
协议栈获取模块,用于将移植的freebsd用户空间协议栈进行配置,得到轻量级ip协议栈。
可选的,该装置还可以包括;
交换机,用于根据ecmp协议将接收到的原始流量数据分流发送至多个网卡队列。
可选的,该装置还可以包括;
控制平面cpu,用于通过无锁队列与多个网卡队列对应的cpu进行通信。
本申请实施例还提供一种服务器,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现如以上实施例所述的负载均衡方法的步骤。
本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如以上实施例所述的负载均衡方法的步骤。
说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以直接用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上对本申请所提供的一种负载均衡方法、负载均衡装置、服务器以及计算机可读存储介质进行了详细介绍。本文中应用了具体个例对本申请的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以对本申请进行若干改进和修饰,这些改进和修饰也落入本申请权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!