一种WEB端实时对讲系统及对讲方法与流程
本发明涉及web端通信技术,具体涉及一种web端实时对讲系统及对讲方法。
背景技术:
对讲机应用领域很广,主要应用在公安、民航、运输、水利、铁路、制造、建筑、服务等行业,用于团体成员间的联络和指挥调度,以提高沟通效率和提高处理突发事件的快速反应能力。随着对讲机进入民用市场,人们外出旅游、购物也开始越来越多地使用对讲机。
传统的模拟机的通话距离受限制,距离一长,通话质量就无法保证。随着互联网的发展,传统的模拟机已经不能满足人们的需求了。
由此可见,现急需一种稳定的对讲系统为本领域需解决的问题。
技术实现要素:
针对于现有模拟机存在通话质量不稳定的技术问题,本发明的目的在于提供一种web端实时对讲系统,在此基础上,还给出了web端实时对讲系统的对讲方法,很好地解决了上述的技术问题。
为了达到上述目的,本发明提供的web端实时对讲系统;包括web端,服务端采集单元,数据处理单元和数据接收处理单元;所述web端与服务端建立socket连接并进行数据交互,通过建立连接将web端相应的连接地址缓存至服务端内;所述采集单元,数据处理单元和数据接收处理单元均运行在web端上。
进一步地,所述采集单元是由声音传感器组成;所述声音传感器与web端进行配合使用,通过声音传感器将音频数据采集至web端中。
进一步地,所述数据处理单元包括合并压缩模块,分包解码压缩模块;所述合并压缩模块与分包解码压缩模块进行数据连接;
所述合并压缩模块将采集单元采集到的原始音频数据通过偏移量计算,将原始二维的pcm音频数据转换为一体来进行合并压缩;
所述分包解码压缩模块通过解码压缩将合并压缩后的音频数据转换成指定采样率,采样数的音频数据;通过分包算法将转换后的音频数据划分成pcm音频包;接着通过opus编码算法将划分后的pcm音频包进一步转换成opus格式的音频包;opus格式的音频包通过rtp进行封装排序;将音频包按照固定大小通过分包机制进行分包,最后将分包后的音频数据通过定时算法按照固定的时间间隔发送rtp格式的语音包到服务端。
进一步地,所述数据接收处理单元是由接收模块,解码解压缩模块,数据拼接模块和播放模块组成;所述接收模块,解码解压缩模块,数据拼接模块和播放模块依次进行数据连接;
所述解码解压缩模块是首先去掉数据包头和rtp头,将rtp语音包还原为opus格式的语音包,然后通过opus解码算法将opus格式的数据包解压缩为pcm原始数据包;
所述数据拼接模块接收到解码解压缩模块处理后的pcm语音包后,将pcm语音包根据语音包序号按照顺序依次进行合并;
所述播放模块通过播放器将排序合并后的语音包通过web端进行播放。
为了达到上述目的,本发明提供的一种web端实时对讲方法;所述对讲方法包括:
(1)将web端与服务端建立数据连接并获取声音传感器的使用权限;调用声音传感器采用单通道的模式进行音频流的采集;
(2)web端通过数据处理单元将原始音频数据合并与压缩实现将其转换为指定采样率以及采样位数的pcm音频数据,通过分包机制实现将pcm音频数据划分为固定大小的音频包,通过opus编码压缩实现将pcm音频数据转换为opus格式的音频包,通过rtp实现将opus压缩后的音频包封装排序,通过定时操作实现固定时间间隔将rtp语音包发送到目标服务端;
(3)服务端接收到数据处理单元处理后的数据来检验语音包是否符合规范,符合则进行转发,否则断开连接;
(4)当服务端将rtp语音包传输至web端进行接收时,web端的数据接收处理单元对rtp语音包进行接受处理。数据接收处理单元将接收到的rtp语音包去掉包头和rtp头,还原为opus格式的语音包,用opus解码算法转换为指定采样率以及采样数的pcm语音包,通过数据拼接将转换后的pcm语音包进行排序合并,通过web端的播放器进行播放。
本发明提供的web端实时对讲系统及对讲方法,本方案可以将采集的原始音频数据通过处理后持续的向后台服务器发送语音包,并且传输可靠稳定,整体提高了通话的质量和稳定性。
附图说明
以下结合附图和具体实施方式来进一步说明本发明。
图1为本web端实时对讲系统的结构示意图;
图2为本web端采集单元的结构示意图;
图3为本web端实时对讲系统语音传输的流程示意图;
图4为本web端实时对讲系统音频数据播放的流程示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明。
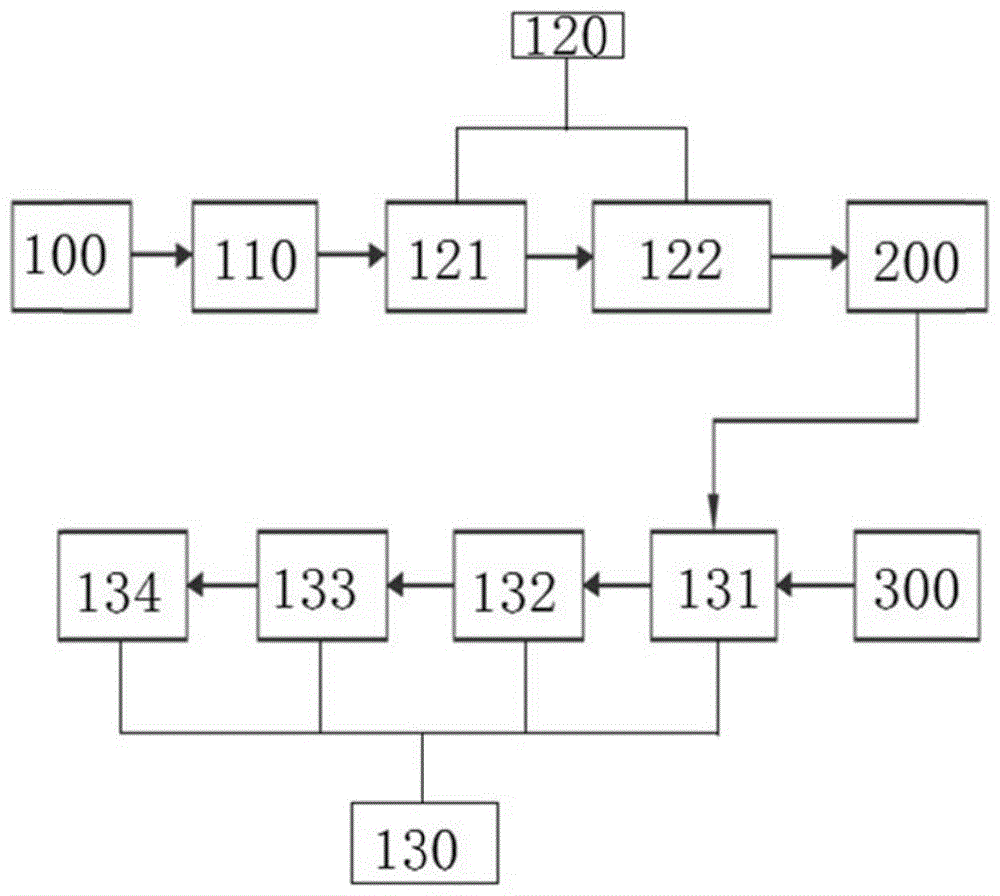
参见图1,本方案给出的web端进实时对讲功能的实现是由web客户,100和服务端200组成的;web端100与服务端200连接来进行实时录音或接收音频数据播放。
在web端100录音或接收音频数据播放之前,需要确保web端100与服务端200之间建立socket连接,并且使得web端100相应的连接地址缓存在服务端200;如果web端100与服务端200建立连接失败,则提示错误信息。因此,web端100与服务端200连接是web端实时对讲系统运行的前提。
其中,web端100对讲系统包括采集单元110,数据处理单元120和数据接收处理单元130。
进一步地,参见图2,采集单元110用于声音的采集,采集单元110是在web端100上运行,还设有声音传感器111和播放器135进行配合使用。采集单元110在web端100与服务端200连接成功后,操作对讲按钮140通过声音传感,111进行录音传输来实现实时对讲。
首先,通过getusermedia方法获取声音传感器111的访问权限,不允许访问声音传感器111则提示错误信息;若允许访问,则调用声音传感器111进行录音,录音后通过数据处理单元120对音频数据进行处理。
数据处理单元120用于对音频数据进行处理,其包括合并压缩模块121,分包解码压缩模块122。其中,合并压缩模块121与分包解码压缩模块122进行数据连接。
合并压缩模块121用于将采集单元采集的音频数据进行合并压缩。
作为举例,通过audiocontext和audioprocess方法获取原始音频的采样率为48000,数据为浮点型32位的pcm音频数据流,占用的资源较大,原始的pcm音频流是二维数组,通过偏移量计算,将二维的pcm音频数据转换为一体将音频数据达到合并压缩的目的,然后将合并压缩后的音频数据传输给分包解码压缩模块122。
分包解码压缩模块122用于对合并压缩后的音频数据进行分包解码压缩,即将采集的原始音频数据压缩转换成指定采样率的音频数据。
作为举例,分包解码压缩就是先将合并压缩后的音频数据进行编码压缩,就是将合并压缩后的音频数据先转换为采样率为8000,采样数为16位整型的pcm音频数据。
然后按照音频分包算法将该转换后的音频数据划分为480长度的16位整型的pcm音频包。
将采集的原始音频数据压缩转换成指定采样率的音频数据是为了在不影响音频质量的前提下缩减音频数据,可以减轻服务端负载。
接着,将通过音频分包算法转换后的音频数据进一步编码压缩,采用opus编码算法进行进一步编码压缩,将通过音频分包算法编码压缩过的数据转换成数据量更小的高保真opus格式的音频包。
这里不限定于采用opus编码吗算法进行编码压缩,本方案优选opus编码算法是由于opus是一个高保真的适合在网络中传输的语音编码格式,相对于其它编码格式来说,保真性更好。
然后对opus格式的音频包通过rtp进行封装排序,作为举例,添加长度为4个字节表示数据长度和长度为4个字节表示数据类型共8个字节的数据包头,将音频包按照固定大小通过分包机制进行分包,最后将分包后的音频数据通过定时算法按照固定的时间间隔发送rtp格式的语音包到服务端200。
将音频包进行分包并按照固定的时间间隔传输,可以实现实时传输,降低传输中的延迟。
由上述采集模块和数据处理单元之间相互配合实现了语音传输至客户端的功能。
服务端200接收到数据处理单元120处理后的数据根据4个字节长度表示数据包长度、4个字节长度表示数据包类型以及12个字节长度的rtp头来检验语音包是否符合规范,符合则进行转发,否则断开连接。
同时,服务端200将检验合格的语音包转发至web端300,web端300通过数据接收处理单元130实时接收和处理服务端所300发送的rtp格式的语音包;本方案可以增设多个web接收端并与服务端200连接,进行音频数据的接收,可以实现一端对讲,多端收听的功能。
数据接收处理单元130用于接收服务端200的语音包并进行处理后,通过web端播放出来,其是由接收模块131,解码解压缩模块132,数据拼接模块133和播放模块134组成。其中,接收模块131,解码解压缩模块132,数据拼接模块133和播放模块134依次进行数据连接。
进一步地,接收模块131用于接收服务端200所发送的rtp语音包,将所接收到的语音包传输给解码解压缩模块132。
解码解压缩模块132用于对服务端200传输的rtp语音包进行解码解压缩。
去掉8个字节长度的数据包头和12字节长度的rtp头,将rtp语音包还原为opus格式的语音包。
将去掉包头和rtp头的opus语音包通过opus解码算法进行解压缩转换为采样率为8000,采样位数为16位整型的固定大小的pcm语音包并传输给数据拼接模块。
数据拼接模块133用于将解码解压缩后的pcm语音包进行排序合并。
数据拼接模块133接收到解码解压缩模块132处理后的pcm语音包后,将pcm语音包根据语音包序号按照顺序依次进行合并。
播放模块134用于对排序合并后的语音包通过web端的播放器135进行播放,直至对讲结束。
由上述数据接收处理单元的工作实现了web端实时对讲系统音频数据播放的功能。
下面举例说明其在具体应用时的工作过程:
参见图3,首先,将web端100与服务端200建立连接,使用getusermedia和audiocontext方法获取访问声音传感器111的权限,然后调用声音传感器111采用单通道的模式进行音频流的采集。
web端通过数据处理单元120将原始音频数据合并与压缩实现将其转换为指定采样率以及采样位数的pcm音频数据,通过分包机制实现将pcm音频数据划分为固定大小的音频包,通过opus编码压缩实现将pcm音频数据转换为opus格式的音频包,通过rtp实现将opus压缩后的音频包封装排序,通过定时操作实现固定时间间隔将rtp语音包发送到目标服务端。
服务端200接收到数据处理单元120处理后的数据根据4个字节长度表示数据包长度、4个字节长度表示数据包类型以及12个字节长度的rtp头来检验语音包是否符合规范,符合则进行转发,否则断开连接。
参见图4,当服务端200将rtp语音包传输至web端进行接收时,将rtp语音包去掉包头和rtp头,还原为opus格式的语音包,然后用过opus解码算法转换为指定采样率以及采样数的pcm语音包,通过数据拼接将转换后的pcm语音包进行排序合并,通过web端的播放器135进行播放。
由上述方案构成的一种web端实时对讲系统实现了一端对讲,多端收听的功能,操作简单,方便快捷,无视对讲距离,对讲语音保存,解决了传统对讲中距离限制,数据无法保存的问题。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!