用于音频分析的装置和方法与流程
1.本发明涉及一种用于音频分析的装置和方法,具体地但不排他地,涉及对例如视频游戏应用的音频分量进行分类。
背景技术:
2.近几十年来,音频应用和服务变得越来越复杂和多样化,尤其是提供各种不同的空间音频应用和体验已经变得司空见惯。
3.在许多视听体验和应用中,音频感知变得越来越重要,并且在许多情况下可能被认为很重要,甚至比视觉感知更重要。例如,在视频游戏应用中,尤其是在诸如第一人称射击(fps)游戏之类的游戏中,用户必须同时使用视觉和听觉感官和感知来定位敌人、识别物体、检测爆炸等。音频场景传达对于准确定位游戏中的角色和对象非常有用的大量信息(例如指向不同声源的方向)。多通道音频允许进行空间音频表示,可以为用户提供更加身临其境的体验。然而,在许多实际场景中,用户可能无法访问多通道渲染系统,而限于渲染仅一个或两个通道(例如经由单个扬声器或立体声设置,例如经由耳机),导致空间音频信息至少部分丢失。
4.在一些情况下,音频元素的特性可以被视觉地表示。例如,wo2010/075634a1中已经描述了声音事件可视化系统。这种方法可以显示视觉信息,例如表示不同类型声音的图标。然而,呈现的信息量往往是有限的,增强这些信息以提供更多信息或提供更准确或可靠的信息将是有益的。
5.诸如上述声音事件可视化系统之类的应用受益于被提供表征音频元素的信息,并且具体地通过被提供与各个声音元素相关联的声源的信息而受益。然而,从其中不同的声音元素和音频源被组合成单个信号/通道集的音频信号中获得这样的信息是特别困难的。已经提出了许多算法来推导合适的信息,但这些算法往往不是最佳的,并且不能提供所需的尽可能多的数据或尽可能准确的数据。
6.因此,改进的方法将是有利的,具体而言,能够改进操作,提高可靠性,增加灵活性,促进实现,促进操作,改善资源利用,对音频元素和/或关联的音频源进行改进的、附加的和/或更准确的音频元素分析和表征,和/或改善性能的方法将是有利的。
技术实现要素:
7.因此,本发明寻求优选地单独或以任何组合的方式减轻、缓解或消除一个或多个上述缺点。
8.根据本发明的一方面,提供了一种装置,包括:接收器,其用于接收表示场景的音频的多通道音频信号;提取器,其用于通过对所述多通道信号应用空间滤波来提取至少第一定向音频分量,所述空间滤波取决于所述多通道音频信号;特征处理器,其用于确定所述第一定向音频分量的一组特征;分类器,其用于响应于所述一组特征而从多个音频源类别中确定所述第一定向音频分量的第一音频源类别,所述多个音频源类别中的每个音频源类
别与一组一个或多个音频源属性关联;以及分配器,其用于从与所述第一音频源类别关联的一组一个或多个音频源属性中将第一音频源属性分配给所述第一定向音频分量,其中所述提取器包括:分频器,其用于将所述多通道音频信号的音频通道信号划分为多个频率区间信号分量;方向估计器,其用于确定所述多个频率区间信号分量中的每个频率区间信号分量的方向;分组器,其响应于每个频率区间信号分量的所述方向而将频率区间信号分量分为多个组;以及生成器,其用于通过组合一组频率区间信号分量的所述频率区间信号分量来生成定向音频分量。
9.本发明可以为许多基于音频的应用提供改进的用户体验。该方法可以在许多场景中提供由多通道信号表示的音频场景中的各个音频源的改进的音频分类。本发明可以提供被估计为对应于音频场景/多通道信号中的特定音频源的各个音频分量的改进表征。
10.该方法可以在许多场景和实施例中提供改进的音频分析并且可以提供改进的和/或附加的信息。在许多实施例中,可以提供更准确和/或可靠的音频信息。
11.该方法具体可以提供适合于例如音频事件可视化(例如在第一人称视角游戏)的有利音频表征。
12.在许多实施例中,该方法可以提供音频分量的可靠、准确和/或低复杂性表征。
13.空间滤波可以取决于多通道信号的音频特性/内容。空间滤波可以生成第一定向音频分量以对应于通过在响应于多通道信号确定的方向上应用波束而提取的波束成形音频分量。空间滤波可以生成第一定向音频分量以对应于在响应于多通道信号确定的方向上形成的波束中的多通道信号中的音频。该方向可以是音频电平增加的方向,并且具体地可以是作为方向的函数的音频电平的局部或全局最大值的方向。
14.在许多实施例中,方向可以是角方向并且具体地可以是方位角和/或仰角方向。
15.音频源可以是场景中的特定源,例如产生声音的对象。因此,在一些实施例中,一个或多个音频源类别可以是与对象或(至少半)永久音频源相关/关联的类别。然而,音频源也可以是声音的特定时间原因,并且可以是产生声音的事件或活动。
16.具体来说,声音的源可以是特定的音频或声音事件。因此,术语音频源包括术语音频事件。在一些实施例中,一个或多个类别可以是与音频事件相关/关联的类别。一个或多个音频源类别可以是音频事件类别。
17.每个音频源类别可以表示特定的音频源类型/类/类别。每个音频源类别可以与表示属于该类别的音频源的一组一个或多个音频源属性关联。该组音频源属性可以包括用于音频源类别的标签或描述符。标签或描述符可以是语义描述。在一些实施例中,标签或描述符可以简单地是音频源类别的标识符,例如类别编号。
18.第一音频源属性具体可以是第一音频源类别本身的指示(例如标识),或者例如是第一音频源类别本身的标签或描述符。
19.分类器可以被布置为根据任何合适的标准或算法将第一音频源类别确定为与最接近地匹配第一定向音频分量的特征的特征相关联的类别。在一些实施例中,分类器可以基于机器学习来执行分类过程。
20.分类器可以被布置为响应于与多个音频源类别中的每个音频源类别的一组特征相比较的一组特征而从多个音频源类别中确定第一定向音频分量的第一音频源类别。
21.该组特征可以是第一定向音频分量的一组属性。
22.类别可以由音频分量的特征的匹配标准定义,由此如果特征满足匹配标准,则音频分量属于该类别。
23.音频源属性(特别是与类别关联)也可以称为音频源类别属性。
24.提取器包括:分频器,其用于将所述多通道音频信号的音频通道信号划分为多个频率区间信号分量;方向估计器,其用于确定所述多个频率区间信号分量中的每个频率区间信号分量的方向;分组器,其响应于每个频率区间信号分量的所述方向而将频率区间信号分量分为多个组;以及生成器,其用于通过组合一组频率区间信号分量的所述频率区间信号分量来生成定向音频分量。
25.空间滤波因此可以通过以下方式实现:将多通道音频信号的音频通道信号划分为多个频率区间信号分量;确定多个频率区间信号分量中的每个频率区间信号分量的方向;响应于每个频率区间信号分量的方向而将频率区间信号分量分为多个组;以及通过组合一组频率区间信号分量的频率区间信号分量来生成定向音频分量。
26.这可以提供用于确定适合分类的定向音频分量的特别有利的方法。
27.分频器通常可以被布置为也执行时间分频,并且具体地,分频器可以执行基于时隙的操作。因此,分频器可以被布置为将多通道音频信号的音频通道信号划分为多个时间(时间间隔和)频率区间信号分量。这种时频区间信号分量通常被称为时频瓦片。
28.分组器可以被布置为响应于每个频率区间信号分量的方向而将频率区间信号分量聚类为组/簇。
29.根据本发明的可选特征,所述装置还包括用于生成所述场景的图像的图像生成器;并且其中所述图像生成器被布置为在所述图像中包括图形元素,所述图形元素取决于所述第一音频源属性。
30.具体地,图像生成器可以被布置为响应于接收到的表示场景的视觉属性的视觉数据(例如视频或图像数据)而生成图像。可以接收表示场景的视听信号,该视听信号包括描述音频场景的多通道信号和描述视觉场景的视觉信号。图像生成器可以基于视觉信号生成图像并将图形元素添加到该图像。图形元素具体可以是用于覆盖场景图像的覆盖图形元素。
31.在一些实施例中,图像生成器可以生成场景的图像并且通过覆盖图形元素覆盖图像,图形元素取决于第一音频源属性。
32.根据本发明的可选特征,所述图像生成器被布置为响应于所述第一定向音频分量的方向估计而确定所述图形元素在所述图像中的位置。
33.方向估计通常可以由提取器作为空间滤波的一部分来确定。
34.根据本发明的可选特征,所述提取器被布置为生成对所述第一定向音频分量的方向估计,并且所述图形元素的属性取决于对所述第一定向音频分量的所述方向估计。
35.这可以允许音频事件的特别有利的可视化,并且可以例如向用户提供额外的空间信息。
36.根据本发明的可选特征,所述图形元素取决于所述一组特征中的至少一个特征。
37.根据本发明的可选特征,所述装置还包括用于根据所述多通道音频信号生成输出音频信号的音频处理器,所述音频处理器被布置为响应于所述第一音频源属性而改变所述多通道音频信号的处理。
38.本发明可以允许基于包括在多通道信号中的各个声音分量的特征的特别有利的音频处理/渲染改变。
39.所述音频处理器可以被布置为改变多通道音频信号的处理以修改对应于第一定向音频分量的多通道信号中的音频分量的属性。
40.所述音频处理器可以被布置为响应于第一音频源属性而改变多通道音频信号的处理以生成输出音频信号。
41.根据本发明的可选特征,所述音频处理器被布置为响应于所述第一音频源属性而改变所述输出音频信号中的所述第一定向音频分量的振幅和位置中的至少一个。
42.根据本发明的可选特征,所述音频处理器被布置为通过将频谱掩蔽应用于所述多通道音频信号来确定对应于不同音频源的多个音频分量,所述频谱掩蔽取决于所述第一音频源属性。
43.根据本发明的可选特征,所述提取器被布置为生成对所述第一定向音频分量的方向估计,并且所述音频处理器被布置为响应于对所述第一定向音频分量的所述方向估计而改变所述多通道音频信号的处理。
44.根据本发明的可选特征,所述音频处理器被布置为响应于所述一组特征中的至少一个特征而改变所述多通道音频信号的处理。
45.根据本发明的可选特征,所述分配器被布置为根据所述第一音频源类别的所述一组音频源属性确定所述第一定向音频分量的第二音频源属性,所述第二音频源属性与所述第一音频源属性应用于不同的音频源。
46.该方法对于多通道分类可能是特别有利和有效的,并且可以允许对多个源进行有效地检测和表征,即使这些源基本上在相同的方向上。
47.根据本发明的可选特征,所述分类器被布置为响应于所述一组特征而从所述多个音频源类别中确定所述第一定向音频分量的第二音频源类别;以及所述分配器被布置为根据所述第二音频源类别的一组音频源属性确定所述第一定向音频分量的第二音频源属性。
48.该方法对于多通道分类可能是特别有利和有效的,并且可以允许对多个源进行有效地检测和表征,即使这些源基本上在相同的方向上。
49.根据本发明的可选特征,所述提取器被布置为生成对所述第一定向音频分量的方向估计,并且所述装置还包括用于生成所述第一定向音频分量的表征数据的数据处理器,所述表征数据包括指示所述第一音频源属性、对所述第一定向音频分量的方向估计和所述一组特征中的至少一个特征的数据。
50.根据本发明的一方面,提供了一种方法,包括:接收表示场景的音频的多通道音频信号;通过对所述多通道信号应用空间滤波来提取至少第一定向音频分量,所述空间滤波取决于所述多通道音频信号;确定所述第一定向音频分量的一组特征;响应于所述一组特征而从多个音频源类别中确定所述第一定向音频分量的第一音频源类别,所述多个音频源类别中的每个音频源类别与一组一个或多个音频源属性关联;以及从与所述第一音频源类别关联的一组一个或多个音频源属性中将第一音频源属性分配给所述第一定向音频分量,其中所述提取包括:将所述多通道音频信号的音频通道信号划分为多个频率区间信号分量;确定所述多个频率区间信号分量中的每个频率区间信号分量的方向;响应于每个频率区间信号分量的所述方向而将频率区间信号分量分为多个组;以及通过组合一组频率区间
信号分量的所述频率区间信号分量来生成所述定向音频分量。
51.参考下文描述的实施例,本发明的这些和其他方面、特征和优点将是显而易见的并被阐明。
附图说明
52.本发明的实施例将仅通过示例并参考附图进行描述,其中
53.图1示出了根据本发明的一些实施例的音频事件可视化装置的元件的示例;
54.图2示出了根据本发明的一些实施例的音频分析器的元件的示例;
55.图3示出了根据本发明的一些实施例的音频分析器的提取器的元件的示例;
56.图4示出了根据本发明的一些实施例的音频处理器的元件的示例;
57.图5示出了根据本发明的一些实施例的方法的示例;以及
58.图6示出了根据本发明的一些实施例的方法的示例。
具体实施方式
59.下面的描述将侧重于音频事件可视化装置、方法和应用,但是应当理解,所描述的方法和原理可以用于许多其他目的,并且在其他实施例和应用中以许多不同的方式使用。
60.图1示出了音频事件可视化装置的元件的示例,该装置被布置为提供有关音频场景的音频的视觉信息。
61.音频事件可视化装置包括为场景提供视听数据的源101。视听数据具体可以包括表示视觉场景的视频或图像数据。视听数据还包括表示对应于视觉场景的音频场景的音频数据。因此,视听数据包括提供场景的组合视听表示的音频数据和视觉数据。视听数据例如可以是由诸如第一人称射击游戏之类的游戏应用生成的数据,因此视听数据可以表示呈现给用户/游戏者的场景的听觉和视觉感知。
62.在一些实施例中,源101可以是例如响应用户输入(例如来自游戏控制器)而动态生成视听数据的内部处理器,这种生成通常是实时的。例如,源101可以是执行游戏应用/程序的游戏处理器。在其他实施例中,源101例如可以是从外部源接收视听数据的接收器,并且视听数据例如可以预先生成。在其他场景中,视听数据可能来自不同的应用,作为合并的音频流和视频流,例如skype和同时在pc上运行的视频游戏。
63.表示音频场景的音频数据以多通道信号的形式提供。这对于许多应用来说都是实用的,因为它允许使用传统的基于通道的渲染系统(例如5.1或7.1环绕声系统)直接渲染音频。多通道信号是空间信号并且包括多个音频通道,每个通道与相对于名义收听位置的名义呈现位置/方向相关联。多通道信号提供在名义收听位置接收到的声音的表示。它提供了从名义收听位置感知的音频场景的表示。
64.如果使用具有与名义多通道渲染设置不同的空间能力的声音系统(例如传统立体声(例如基于耳机的)或单通道音频系统)来渲染多通道信号,则音频的空间感知会大大减少。这在许多应用中可能会降低用户体验,并且在许多场景中可能会有效地减少用户可用的信息。例如,在游戏应用中,它可能使游戏玩家确定其他游戏玩家或例如游戏环境中的物体、爆炸、镜头等的位置和方向变得更加困难。
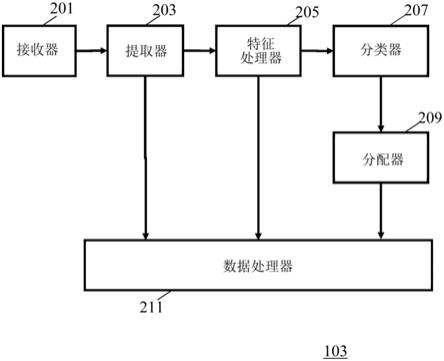
65.图1的音频事件可视化装置被布置为分析多通道信号以便表征音频场景的一个或
多个音频分量或源(包括事件)。源101相应地连接到音频分析器103,该分析器被布置为分析多通道信号。如下文将描述的,音频分析器103将生成多通道信号的至少一个音频分量的至少一个音频源属性。音频源属性通常可以指示相应的音频源被估计属于的类别或类。
66.通常,音频分析器103可以生成音频场景中的多个音频源的音频源属性。此外,音频分析器103通常可以提供附加信息,例如在确定音频源属性的过程中已经生成的多通道信号的定向音频分量的方向信息和/或特征/属性。
67.给定估计的音频源的确定的音频源属性以及通常的方向和特征数据被提供给渲染器105。渲染器105进一步被提供来自源101的视觉数据并且被布置为渲染该视觉数据。例如,渲染器可以渲染由视觉数据图像表示的图像以呈现在合适的显示器上,例如计算机监视器、电视或虚拟现实头戴式装置。
68.除了图像的渲染之外,渲染器105还被布置为向渲染图像添加图形元素(通常是覆盖图形(或多个图形))。图形元素可以提供音频场景/多通道信号的属性的视觉指示。具体地,可以生成覆盖图形并将其覆盖在渲染图像上,该覆盖图形是音频源属性的指示,例如爆炸的指示。在许多实施例中,覆盖图形还可以包括声音的对应方向和/或特征的指示。
69.例如,渲染器105可以生成爆炸的覆盖图形,该图形描绘了识别检测到的声音是爆炸的标签以及指向声音方向的箭头,并且具有对应于声音的响度的长度。覆盖图形可以相应地提供音频场景的特性的视觉表示,其可以向用户提供额外的信息,例如在所使用的音响系统无法提供此类数据的情况下(或例如,如果应用在无声的情况下使用(例如,如果用户无法使用耳机或听力受损))。
70.图1的装置因此可以在许多实施例和场景中提供改进的用户体验和附加信息。然而,性能和用户体验在很大程度上取决于由音频分析器103执行的分析以及由此可以提供的音频源的信息和特性。例如,仅提供对音频场景中音频分量的方向和电平的估计将往往只允许非常有限的相对视觉反馈。在下文中,将描述音频分析器103,该分析器能够执行特定分析以生成改进且特别有利的数据,这样允许在许多实施例、场景和应用中改进性能和使用。具体可以在诸如图1的音频事件可视化装置中提供改进和/或增强的音频属性可视化,音频分析器的操作描述将侧重于该上下文和使用生成的数据来可视化音频场景的音频属性。
71.图2示出了根据本发明的一些实施例的音频分析器的示例。图2具体地说明了图1的音频分析器103。
72.音频分析器103包括接收器201,其在特定情况下从源101接收多通道信号。
73.接收器201耦合到提取器203或空间滤波器,其被布置为通过对多通道信号应用空间滤波来从多通道信号中提取至少一个并且通常是多个定向音频分量。
74.每个定向音频分量可以具体地对应于来自多通道信号的名义收听位置的给定方向/波束上的多通道信号的音频。多通道信号时表示来自给定收听位置的音频场景的空间音频信号。它包括多个对应于场景中不同音源的音频分量,这些分量组合成多通道信号的通道。一些音频分量可对应于对听者几乎没有或没有方向提示的音频。例如,音频场景可能包括来自非定向分布式和漫射音频源(例如环境或背景噪声/音频)的音频。其他音频分量可能对应于提供方向提示的音频,特别是一些音频分量可对应于在音频场景中明确定义的位置发生的特定的音频源/事件,例如经由直接路径到达收听位置,从而提供强烈、清晰且
精准的空间线索。
75.音频分量由多通道信号的音频通道信号表示。如本领域技术人员公知的,对于给定的音频分量,每个音频通道信号可以包括取决于音频源的性质和空间位置的贡献。例如,漫射背景音频可以在每个音频通道中基本相同且非相干地表示,而来自对应于仅一个音频通道的名义位置的空间位置的点源可以仅在该音频通道中表示,而在任何其他音频通道信号中没有贡献。
76.因此,使用对应的多通道音频系统收听多通道信号的听者通常会感知一些漫射和非空间特定的音频源以及通常感知一个或多个空间特定的声源,例如被感知为点源的声源。听者会倾向于感知来自特定方向和角度的这种声音。
77.通常,音频场景会随着在不同时间发生的音频源/事件而动态地改变特征。例如,对于第一人称射击游戏,背景音频可能是相对恒定的,并辅以诸如枪声、爆炸(作为与各个游戏事件相关联的各个音频事件发生)之类的音频。
78.空间滤波器可以是角度滤波器,并且每个定向音频分量可以对应于通过将空间(例如,角度)滤波器应用于多通道信号而产生的多通道信号的音频。空间滤波器可以对应于波束成形模式,并且定向音频分量可以对应于在对应于空间滤波器响应的波束中的(名义)收听位置处接收的音频。因此,定向音频分量可以对应于将在收听位置从定向麦克风(或麦克风阵列)接收的音频,该定向麦克风具有对应于角度滤波器的波束成形(具体地,波束成形和角度滤波器具有与方位角和/或仰角的函数相同的衰减)。
79.提取器203被布置为执行自适应空间滤波,具体而言,空间滤波取决于多通道音频信号本身。因此,不是空间滤波是恒定的、预定的空间滤波,而是提取器203被布置为基于多通道信号的属性改变和修改空间滤波。
80.提取器203可以具体地被布置为改变空间滤波以选择多通道信号中的音频源和音频分量。提取器203可以被布置为改变空间滤波以在多通道信号表现出增加的音频电平的方向上引导波束(相对于其他方向)。
81.应当理解,可以使用用于改变空间滤波以选择多通道信号中的音频源/分量的任何合适的方法。例如,在一些实施例中,可以定义多个不同的预定滤波器并将其应用于多通道信号,从而生成多个空间滤波信号。例如,可以每10
°
生成一个空间滤波信号,从而产生36个信号。提取器203然后可以检测具有最高信号电平的信号并且选择它作为要进一步处理/分析的定向音频分量(或者,例如可以选择最高的n个信号来生成n个定向音频分量)。
82.作为另一示例,在一些实施例中,每个时频隙可以被赋予表示该时频隙中音频的(主要)源的潜在“位置”的角度值。然后,几个时频隙可能具有类似的反映声学活动方向的角度值。
83.典型的音频场景包含相对于参考点(听者)的不同位置(例如前面、左边和后面)的声源实例。生成的音频信号通常不会保留源的空间信息(只有对象格式才会这样做)。空间提取可以被认为是一种基于根据观察到的多通道信号计算出的位置来检索原始信号的方式。提取器203可以执行场景的音频源检测/估计并且这可以包括估计这些音频源的方向/空间属性。
84.提取器203耦合到特征处理器205,提取器203可以向特征处理器205提供通过空间滤波生成的定向音频分量。特征处理器205被布置为确定每个定向音频分量的一组特征。
85.定向音频分量的特征可以是指示定向音频分量的属性(或一组属性)的值(或值集)。在许多实施例中,特征可以是定向音频分量的属性,例如信号电平、频率分布、时序等。
86.特征可以是标准音频描述符或例如自定义特征。例如,对于表示定向音频分量的信号,可以从以下位置提取特征:
[0087]-相应的时域信号(自相关、过零率等),
[0088]-相应的频域信号(能量、谱矩等),
[0089]-相应的谐波域信号(基频等),
[0090]-相应的倒谱域信号(梅尔频率倒频谱系数等),
[0091]-感知过滤的信号(bark、erb系数等)。
[0092]
应当理解,用于提取、确定和生成表示音频信号的属性的特征的许多不同方法和算法是本领域技术人员已知的并且可以使用任何合适的方法。
[0093]
在具体示例中,特征处理器205可以生成由从定向音频分量信号yj(t)中提取的表示的一组特征。
[0094]
特征处理器205耦合到分类器207,该分类器被布置为响应于该组特征而从多个音频源类别中确定每个定向音频分量的音频源类别。
[0095]
因此,分类器207可能已存储音频源的一组类别(类/组/集),其中给定类别内的音频源具有一些共享属性或特性。
[0096]
音频源可以是音频的任何原因或发起者,并且可以指例如场景中的特定对象或时间事件。因此,音频源可以是音频源对象和/或音频源事件。音频源可以被认为是在时间上受到限制的(例如,短时间发生并对应于一个音频事件)或可以例如被认为具有更长的时间扩展(例如,对应于产生音频的永久对象)。在一些实施例中,该组类别可以与音频事件和音频源对象相关联,例如,一些类别可以表示特定的音频事件,而一些类别可能表示音频生成对象。
[0097]
在一些实施例中,一个或多个类别可以与特定类型的音频事件相关联,例如爆炸、枪声、说话的人等。在一些实施例中,一个或多个类别可以例如通过具有由这样的音频源(例如音乐、扩散噪声等)生成的音频的共同属性来确定。因此,每个类别的确切性质和特性(包括类别的原因或特性)可取决于各个实施例。
[0098]
音频源类别与来自属于该类别的音频源的音频的某些属性或特性相关联。具体地,每个类别可以与指示来自该类别的音频源的音频的属性的一组特征关联。特征可以反映对于属于该类别的音频源始终存在的属性,或者可以反映对于属于该类别的音频通常存在或可能仅有时存在的属性。通常,与给定类别相关联的特征可能是这些特征的组合。
[0099]
与类别相关联的一组特征可以直接匹配为定向音频分量确定的一组特征,即,在为定向音频分量确定的每个特征与为每个类别存储的特征之间可以存在直接匹配。然而,在许多实施例中,该组特征可能不相同。例如,某些定向音频分量和/或类别的某些特征可能是可选的,并且可能仅在针对类别和定向音频分量都存在时才被考虑。在一些实施例中,定向音频分量和/或一个或多个类别的特征可以被处理或组合以实现匹配。
[0100]
分类器207被布置为响应于为定向音频分量确定的特征而确定定向音频分量的音频源类别。具体地,对于由空间滤波生成并且针对其已确定特征的定向音频分量中的至少一个,分类器207继续选择至少一个类别。根据任何合适的标准或算法,可以具体地将类别
确定为其一组特征与定向音频分量的特征最接近地匹配的类别。
[0101]
多个类别中的每个类别与由该类别音频源的中的一个音频源生成的音频的多个特性、属性、特征相关联。每个类别可以与一种类型的音频源相关联,即它不与给定音频源的一个特定实例相关联,而是与具有至少一个共同特性的音频源的类别、分类、组、集等相关联。
[0102]
分类器207可以相应地继续确定被认为与定向音频分量(的属性)最接近地匹配的音频源类别。
[0103]
分类器207耦合到分配器209,该分配器被布置为从与分类器207发现定向音频分量所属的音频源类别相关联的一组音频源属性中将音频源属性分配给定向音频分量。
[0104]
在许多实施例中,音频源属性可以简单地是由分类器207确定的音频源类别,即它可以简单地是所确定的类别的标识。例如,每个类别可以与指示特定类型的音频源(例如说话的人、爆炸、尖叫、枪声、警报器、发动机噪生等)的标签或描述符相关联。可以相应地将该标签或描述符分配给定向音频分量,从而识别定向音频分量被认为表示的音频源的类型。
[0105]
在一些实施例中,分配器207可以附加地或替代地分配其他音频源数据。例如,类别可以与该类别所表示的音频源生成的相应音频的一些典型属性相关联。例如,它可能与典型的频率特性(例如,雷声往往在低频处具有能量集中)、空间确定性(例如,指示音频源的典型空间扩展)等相关联。
[0106]
在一些实施例中,分配器209还可以被布置为将音频属性数据之外的其他数据分配给定向音频分量。例如,对于每个类别,可以存储威胁或危险级别并且可以将该数据分配给定向音频分量。例如,标记为(和相应的)狮吼的音频源类别可能被分配高危险级别,而标记为(和相应的)鸟鸣的音频源类别可能被分配低危险级别。
[0107]
分类器207因此被布置为执行分类以确定通过空间滤波从多通道信号中提取的一个或多个定向音频分量的类/类别。分配器209然后可以基于所识别的类/类别将特征数据分配给定向音频分量,并且具体地,分配器209可以分配指示类/类别本身的数据。具体地,分类器207和分配器209可以用作分类系统,该分类系统输出对应于与所识别的类/类别相关联的声音事件的标签。
[0108]
在一些实施例中,分类器207可以执行可以同时使用的多个分类/归类,例如使用已确定类别的潜在层次结构。例如,可以使用区分动物与人类的分类器、从太平洋动物中确定危险动物的分类器、以及区分儿童与成人的分类器。所有这些信息都可以在渲染器105中具有视觉对应物。
[0109]
在一些实施例中,分类可以相对简单,其中基于将定向音频分量的特征值与类别的对应特征值进行比较并选择导致最低距离量度的类别来计算距离量度。
[0110]
在许多实施例中,可以使用更复杂的方法。例如,分类可以基于使用机器学习算法的分类方法输出对应于声音事件的标签,机器学习算法学习通过示例数据集对声音进行分类。该算法可以通过最小化真实值zi和预测值之间的损失函数来训练,并且在训练之后,最小化给定定向音频分量的损失函数的类别可以被选为该定向音频分量的相应类别。
[0111]
特定算法使用称为归一化功率谱(nps)的特定特征,该特征通过以下方式构造:
[0112]
取帧的傅立叶变换(ft)xj=ft(yj),
[0113]
取平方值ft|xj|2[0114]
将其归一化,使其总和为1
[0115]
然后,使用具有多项式核的核密度估计的非参数密度估计允许针对分类导出最大后验(map)决策规则:
[0116][0117]
因此,在一些实施例中,可以提供输出对应于声音事件的标签的分类系统,其中r是作为上面给出的p(zj|xj)的最小化给出的决策规则。更详细的描述可以在maxime baelde、christophe biernacki、greff等人发表的“real-time monophonic and polyphonic audioclassification from power spectra(根据功率谱的实时单通道和多通道音频分类)”中找到,此文章可从https://hal.archives-ouvertes.fr/hal-01834221v2获得,将在《pattern recognition》中发布。
[0118]
然后可以将标签,并且通常将附加信息提供给渲染器105,该渲染器可以继续生成分类结果的视觉表示。作为一个简单的示例,渲染器105可以简单地呈现一个或多个选定类别的标签。因此,如果系统检测到存在对应于特定类别的定向音频分量,则可提供视觉指示以指示已在音频场景中识别出对应的音频源。例如,如果分类已经识别出存在被分类为属于与爆炸声源(爆炸声事件)相关联的类别的定向音频分量,则渲染器105可以呈现表示“爆炸”的标签。
[0119]
因此,系统可以例如实时地显示空间和语义音频信息,并可向用户提供增强或附加的信息。
[0120]
在一些实施例中,提取器203可以被布置为通过将多通道信号划分为典型的小段并基于每个段的估计的主导信号方向将这些段进行分组来执行空间滤波。
[0121]
图3示出了根据该方法的提取器203的示例。
[0122]
在该示例中,提取器203包括分频器301,该分频器被布置为将多通道音频信号的音频通道信号划分为多个频率区间信号分量或段。分频通常在时间帧/隙/间隔/段中执行,因此分频器301为多通道信号的每个通道信号生成时频段。
[0123]
这样的时频段通常被称为时频瓦片,因此分频器301被布置为将每个音频通道信号分割成时频瓦片。分频器301可以具体地通过将每个信号划分为时间段(使用本领域技术人员已知的合适的加窗)并对每个窗口中的信号执行fft来执行该分频。然后,每个生成的bin值对应于时间段和bin频率的特定时频瓦片。
[0124]
分频器301耦合到方向估计器303,该方向估计器被布置为针对每个时频瓦片估计该时频区间中的声音的方向。这可以具体地通过比较来自所有音频信号的相应时频瓦片的信号电平来完成。例如,如果一个通道的信号电平非常高而所有其他通道的信号电平都非常低,则该时频瓦片中的音频很可能是由与该通道相关联的名义(扬声器)位置方向上的单
个主导声源引起的。如果主导声源位于音频通道位置之间的方向上,则之间具有该时频瓦片中的主导音频源的两个通道中的相对信号电平比其他通道高得多。
[0125]
因此,作为低复杂度的示例,方向估计器303可以被布置为生成对给定时频瓦片的方向估计,作为与每个通道相关联的位置的加权组合,并且其中权重随着时频瓦片中信号电平的增加而增加。
[0126]
应当理解,对于漫射性更强和方向性更差的声源,包括通过多次反射到达收听者的声源,方向估计往往不那么具体。类似地,对于没有单一主要声源的时频瓦片,方向估计也不太明确。然而,所描述的使用加权组合来确定方向估计的低复杂度方法在许多场景中仍可提供可接受的性能。实际上,在这些情况下,较不具体的方向估计可能导致估计的变化增加,这可能导致此类时频瓦片在定向音频分量的后续生成中具有较小的平均贡献。在其他实施例中,可以生成并随后使用对给定时频瓦片的方向估计的特异性的度量。
[0127]
方向估计器303耦合到分组器305,该分组器被布置成响应于分量/瓦片的估计的方向而将频率区间信号分量,即时频瓦片,进行分组。分组器305可以将瓦片分组为对应于不同方向的组,其中每组的瓦片具有彼此接近的方向估计。因此,每组瓦片可以包括其方向估计基本相同或足够接近的瓦片。例如,每个瓦片可以被确定为属于这样的组:即,瓦片的方向估计和该组的(可能加权的)平均方向估计之间的差异尽可能小,即每个瓦片属于具有最接近的平均方向估计的组。在许多实施例中,方向估计可以是角方向估计。
[0128]
应当理解,用于对值进行分组的许多不同方法和算法是已知的,并且可以使用任何合适的方法。例如,不同的聚类算法是已知的并且可以应用于提供适应特定值集的分组。在一些实施例中,所有瓦片可以被分成一个组。在其他实施例中,一些瓦片例如可以被丢弃。例如,如果认为瓦片没有可靠或特定的方向估计,例如由于该瓦片中没有主导声源,则可以丢弃该瓦片并且不将其分配给任何组。
[0129]
分组器305耦合到音频分量生成器307,该音频分量生成器被布置为生成对应于不同簇/组的定向音频分量。
[0130]
在一些实施例中,这可以通过组合每个组的频率区间信号分量(即时频瓦片),直接使用组来完成。
[0131]
例如,可以选择分配给特定组的所有fft bin,因此可以选择被估计为包括从给定方向接收到的主导声音的一组fft bin。可以估计未包括在该组中的bin的fft bin值,例如通过在选定的fft bin之间进行插值。然后可以通过逆fft将得到的时频信号转换到时域。以这种方式,可以生成表示来自给定方向的声音的定向音频分量的时域和频域表示。然后可以将时域和频域表示提供给特征处理器205,该特征处理器可以继续为该定向音频分量生成一组特征。
[0132]
作为另一示例,可以确定主方向,例如被确定为给定组的均或平均(角度)方向。可以将使用预定空间滤波器形状/波束成形形状的空间滤波应用于多通道信号,其中形状的中心指向组的确定的平均方向。
[0133]
用于确定定向音频分量的特定方法例如可以遵循ep3297298a1中公开的方法。
[0134]
提取器203可以通过三阶段方法执行空间滤波:
[0135]
1.空间分析可以计算多通道信号x(t)的定向活动,这会产生一组根据频率的角度θ(f,t)。
[0136]
2.然后可以对角度进行聚类以获得活动方向的数量dj(f,t)。
[0137]
3.接着可以基于先前的结果执行空间频率掩蔽以获得分离的信号yj(t)。可以依次应用空间掩蔽和频率掩蔽。
[0138]
该方法可以允许丢弃一组根据频率的角度θ(f,t)中的非直接路径贡献(主要是反射)。
[0139]
关于第一步,使用分析多通道信号x(t)的方法来提取信号内部声音的空间方向性。该方法以多通道信号作为输入,并且输出与每个频率相关的角度θ(f,t),即可以输出每个时频区间的角度。例如,可以确定所谓的主动和反应强度向量并将其用于提取角度。主动强度向量da(f,t)r指示归一化复强度i(f,t)向量的实部,并且在感知上与主要定向声场相关。反应强度向量dr(f,t)指示归一化复强度向量的虚部,并且在感知上与环境扩散声场相关。
[0140]
关于第二步,一旦找到基本“源”分量在时间t θ(f,t)的空间位置(角度),就可以对其进行分析以提取声音所在的主方向dj(t)。这可以通过将θ(f,t)聚类成几个簇,然后确定这些簇的平均值作为主方向来完成。聚类还给出了在时间t处出现的活动声源/事件的数量。如果不知道活动事件的数量,则可以进行模型选择以获得最佳事件数量:其理念是将不同数量的事件进行聚类并保留优化特定标准的模型。完成此目标的一种可能的方法是将混合模型(例如高斯混合模型)拟合到数据,并且例如保留优化bic(贝叶斯信息准则)的模型。作为另一示例,可以使用k-means算法或其他聚类算法。
[0141]
关于第三步,在给定几个方向的情况下,装置可以过滤每个方向的每个源。可以使用空间窗口w(f,dj)函数(如矩形窗口或正弦窗口)来平滑主方向周围的滤波。该理念是收集对应于dj(t)的频率并计算在这个方向上过滤的主源。然后使用ifft yj(t)将这些源转换为时域。
[0142]
应当理解,这些步骤中的一些可以联合执行,例如迭代这些步骤。具体地,可以联合执行第一步和第二步,或第二步和第三步。
[0143]
所描述的方法可以提供一种特别有效的方法来检测和例如标记由多通道信号表示的音频场景中的单个声源/事件。具体而言,它可以利用空间声源分离,从而例如允许识别和标记单个音频源。
[0144]
然而,该方法还可以提供用于检测多个声源(实际上是检测相对于收听位置的相同方向上的多个声源)的特别有效的性能。因此,在许多实施例中,音频分析器103可以执行多通道分类。
[0145]
具体地,分配器209可以被布置为向一个定向音频分量分配两个音频源属性,例如两个类别标签,其中这两个属性与不同的音频源/事件相关。例如,分配器209可以将两个不同的音频源标签分配给一个定向音频分量,反映出估计定向音频分量包括来自同一总体方向上的两个不同音频源的贡献。
[0146]
在一些实施例中,一个或多个音频源类别可以与一个以上的音频源相关联。例如,一个类别可同时对应于爆炸和尖叫。这种类别的特征可以相应地反映爆炸和尖叫的组合音频。如果检测到此类类别与定向音频分量的特征最接近地匹配,则可以认为这对应于两个音频源(尖叫声和爆炸声)并且可以被分配两个标签。在实践中,这种组合的音频源特征和决策标准可以通过广泛的训练过程来确定。
[0147]
在其他实施例中,音频分析器103可以被布置为为定向音频分量确定不止一个类别。因此,对于定向音频分量,可以确定它与第一和第二类别接近地匹配,并且可以将这两个类别的标签分配给定向音频分量。例如,如果确定匹配度量超过了与尖叫相关联的类别和与爆炸相关联的类别的阈值,则该定向音频分量将被分配尖叫标签和爆炸标签。因此,在这样的示例中,对于一个定向音频分量可能潜在地产生多类分类,并且因此这可以被分配来自多个类的数据。
[0148]
因此,在一些实施例中,音频分类可以由多通道分类器执行,使得能够在每个方向输出多个标签。
[0149]
实际上,不是假设每个定向音频分量仅包含一个活动源(单通道情况),相反,该方法可以允许多个音频源与单个定向音频分量相关联。例如,如果假设定向音频分量包含来自两个不同类别/类z1和z2的两个不同信号x1和x2,则可以使用单个信号和信号相关比例φ来计算信号x的混合nps特征:
[0150]
x=φx1+(1-φ)x2[0151]
其中φ=p1/(p1+p2)是每个源的功率相对于两个功率之和的比率。然后可以使用单通道核的混合来构建多通道决策规则。
[0152]
由于多通道nps是单通道nps的加权和,因此决策规则基于相同的条件概率(如之前定义的最大后验概率(map)),但核密度估计中使用的原型是基于单通道的多通道nps。因此,这种多通道分类方法仅从单个声音中学习混合声音,与标准多通道分类器相比,这是一个优势。
[0153]
音频分析器103可以相应地确定多通道信号的一个或多个定向音频分量的一个或多个类别/类。具体地,可以将声源标签应用于一个或多个定向音频分量。
[0154]
如前所述,音频分析器103生成用于分类的数据。在许多实施例中,该数据还可用于分类之外的其他目的。
[0155]
具体地,作为定向音频分量的空间滤波和提取的一部分,提取器203通常可以确定对定向音频分量的特定方向估计。在一些实施例中,该方向数据也可以例如由渲染器105输出和使用。
[0156]
此外,特征处理器205确定分类器207用于分类的多个特征。在一些实施例中,这些特征中的一个或多个(或实际上是分类器207未使用的潜在其他特征)可被输出以例如由渲染器105进一步使用。
[0157]
在图2的具体示例中,音频分析器103包括数据处理器211,该数据处理器被布置为生成定向音频分量的表征数据。对于这些定向音频分量中的至少一个,该表征数据包括指示被分配的音频源属性(通常是声源标签)、对定向音频分量的方向估计以及为定向音频分量确定的一组特征中的至少一个特征的数据。
[0158]
因此,在这样的实施例中,音频分析器103可以生成组合且一致的数据集,该数据集指示为此具有相关联的特征的音频源/事件的方向和类型。这可以提供特别有利的数据集,允许对音频源进行非常有用的表征。这可以为许多应用提供显著改进的性能,例如对于诸如图1的音频可视化系统。
[0159]
在图1的示例中,来自音频分析器103的输出被提供给渲染器105并用于提供一个或多个分类的定向音频分量的视觉表示。
[0160]
应当理解,准确的视觉表示,以及实际上表示什么数据,可以取决于各个实施例和特定应用的偏好和要求。
[0161]
在许多实施例中,渲染器105可以被布置为渲染图形元素,该图形元素可以例如是覆盖场景(即视觉场景表示)的相应图像图形元素。然而,在其他实施例中,文字或例如图形可能不会覆盖图像,但可能例如显示在辅助屏幕或辅助显示器上,如led阵列(例如嵌入键盘或屏幕周围)。
[0162]
在许多实施例中,渲染器105可以被布置为生成表示一个或多个定向音频分量的特性或属性的图形元素(具体地为覆盖图形)。图形元素可以被包括在场景的图像中,并且具体可以是覆盖在场景图像之上的覆盖图形,从而提供有关音频场景的附加视觉信息。
[0163]
该图形通常可以指示被分配给定向音频分量的音频源属性,例如具体地为类别名称或标签。该信息例如可以由标签的文本呈现提供。在其他实施例中,可以渲染图形表示,例如图标。例如,枪声可以通过覆盖图像的枪的轮廓来指示。在一些实施例中,图形元素的存在本身可以指示特定类别。例如,渲染器105可以被设置为例如当在音频场景中检测到特定声音时,在屏幕的一部分上添加透明颜色叠加,并且这种颜色色调的存在可表明已在特定方向上检测到该类别的声音(例如红色色调可能表示大爆炸)。
[0164]
在许多实施例中,(覆盖)图形元素可以进一步指示定向音频分量的方向。例如,图形元素的属性可以指示朝向检测到的声源的方向。
[0165]
在一些实施例中,这可以通过响应于对定向音频分量的方向估计来改变渲染图像中的图形元素位置来完成。例如,方向估计可以指示相应的音频源是在当前观看者取向的左侧还是右侧,并且图形元素可以根据这一点定位在左侧或右侧。在一些实施例中,图形元素(例如图标)可以被定位在图像上,使得它被感知为在为估计的音频源方向上。如果此方向在当前视口之外,则图形元素可能位于屏幕边缘,尽可能靠近估计的方向。
[0166]
在一些实施例中,图形元素本身可以取决于对定向音频分量的方向估计。因此,图形元素的属性可以取决于方向估计。例如,当检测到属于特定类别的定向音频分量时,可以生成并渲染圆圈形状的图形元素。在这个圆圈内,可以显示一个十字,指示朝向声源的方向和距离,从而提供显示声源相对于用户的估计位置的雷达效果。在这样的示例中,可以基于到音频源的估计方向(和距离)来调整十字的位置,从而调整所渲染的图形元素。
[0167]
在一些实施例中,图形元素的取向可以取决于对定向音频分量的方向估计。例如,图形元素可以是位于渲染图像中相同位置但被取向为指向声源的估计方向的箭头。因此,箭头形式的图形元素可以朝向声源旋转。需要指出,这相当于根据估计方向改变图形元素的内容(例如,指向不同方向的箭头可被认为是发生旋转的同一个图形,也可被认为是不同的图形元素)。
[0168]
在一些实施例中,图形元素取决于由特征处理器205确定的一个或多个特征。例如,表示定向音频分量的图形元素的颜色可以取决于定向音频分量的电平,例如,对于低音频电平,可以呈现绿色图形元素,而对于高音频电平,可以呈现同一图形元素,但是呈现为红色。
[0169]
在许多应用和实施例中,音频特征、方向(通常是距离)估计和声源/事件的类/类别的特定组合可以提供非常有利的音频视觉表示。
[0170]
如上所述,在一些实施例中,渲染器105可以有效地提供雷达效果。这可以采用显
示活动区域的圆圈的形状或指向活动方向的箭头(或多个)的形状。
[0171]
作为另一示例,可视化例如可以采取滚动时间线的形式,显示有关检测到的音频的方向和标签的信息,其中音频事件出现在屏幕的一侧,一段时间后消失在另一侧,从而向用户提供最近的音频历史记录。
[0172]
作为另一示例,可以使用辅助显示装置(特别是不呈现视觉场景的显示装置),例如发光的(可能有颜色的)键盘、第二屏幕(例如智能手机)等。
[0173]
在不同的实施例中,类别/类标签的符号表示可以以不同方式显示。它可以是描述标签或事件的文本或文字(例如“大爆炸”、“几声枪响”)。它例如可以是表示类标签的图标。与给定标签关联的颜色也可以表示音频事件。除了文字或颜色可视化之外,也可使用透明图标来显示类事件,图标透明度例如可以由相应音频类的能量决定。
[0174]
在一些实施例中,图形元素(例如作为雷达或时间线效果)可以是类特定的。例如,可以基于选定的类标签激活雷达,即仅当检测到属于特定类别的定向音频分量时激活。类似地,如果没有活动或者如果定向音频分量的确定的类别不包括与图形元素相关联的任何类别,则可以停用图形元素。
[0175]
在一些实施例中,单个图形元素可以反映多个类别的属性。例如,它可以显示多个音频源的属性。
[0176]
需要指出,该方法是3d兼容的。例如,音频分析器103有可能向渲染器105提供具有对应类别的3d方向,即取向和高度信息。渲染器105然后可以在表示中包括这样的信息。例如,图形元素可以根据方位角估计水平移动,基于高度估计在图像中垂直移动,以及基于距离估计调整大小。
[0177]
在一些实施例中,渲染可以呈现在标准二维显示器上,但是该方法同样适用于3d显示器。可视化例如可以在头戴式显示器(hmd)上。通常,这样的设备知道用户头部的取向(或fps的观看者的取向)并且音频的渲染(由视频游戏引擎进行)通常适于反映或补偿头部取向或位置的变化。
[0178]
在经典场景中,渲染器105不需要根据角度取向来补偿头部取向,因为例如视频游戏的音频引擎已经基于头部取向(或fps的观看者的取向)调整了音频的渲染。因此,分析器103将处理已经适应头部取向(或fps的观看者的取向)的音频流。相反,在来自固定方向的声音事件的情况下(例如,当声音事件时间短或当声音事件的显示时间比音频事件本身长时),该固定角度信息可以优选地由渲染器105根据头部取向调整。实际上,在这种情况下,显示结束时的头部取向与显示开始时相比可能已经发生变化,而声音事件不再存在于音频流中。
[0179]
与传统系统相比,所描述的方法改进了可视化并且可以相应地提供增强和改进的用户体验。传统系统倾向于仅提供当前呈现的音频属性的一些指示,并且在实践中使得用户难以有效地解释(通常提供太多信息(例如,各个方向的原始音频能量))。所描述的方法例如可以包括一个实时多通道分类步骤,允许将类别/类型/类标签分配给音频内容的各个部分。这提供了改进的可视化并且例如可以使系统能够显示更具体的音频可视化,使用户更容易理解。
[0180]
所描述的方法提供了一种系统,该系统能够确定和例如实时地显示空间和相关语义音频信息。在许多实施例中,该方法可以使用机器学习来定位和识别多通道音频流(例如
5.1)内的不同声源。该方法可以执行音频场景的空间分析以将流分离成几个单通道信号(定向音频分量),然后使用分类算法对这些信号进行分类。结果然后可以具体地用作可视化器(渲染器105)的输入。
[0181]
在前面的实施例中,由音频分析器103生成的数据用于音频场景中存在的音频事件的可视化。然而,应当理解,数据可以替代地或附加地用于其他目的。
[0182]
在许多实施例中,数据可用于调整多通道信号的音频处理,特别是音频渲染。这种装置的一个示例在图4中示出。在该示例中,来自音频分析器103的输出被提供给也接收多通道信号的音频处理器401。该装置可以对应于图1的相应装置,但是音频分析器103的输出由音频处理器401使用。在许多实施例中,该装置可以同时包括图2中的音频处理器401和图1中的渲染器105,并且由音频分析器103生成的数据可用于可视化和用于调整音频处理。音频分析器103同时用于可视化和音频处理的方法的示例也在图5中示出。
[0183]
在一些实施例中,音频处理器401可以被布置为根据多通道音频信号生成输出音频信号,其中基于来自音频分析器103的数据调整生成该输出音频信号的音频处理。在许多实施例中,输出音频信号可以是直接提供给例如用于渲染的扬声器的信号,或者例如可以是用于进一步处理的音频信号。例如,它可以是输入到双耳处理器以生成使用耳机渲染的双耳输出信号的输出信号。
[0184]
调整可以具体地响应于所分配的音频源属性(或多个属性),并且通常可以通过调整音频处理的参数来实现。音频参数的变化会导致生成的输出音频信号发生变化。例如,在一些实施例中,可以基于在音频场景中检测到特定音频源的存在来修改增益参数。例如,如果检测到雷声,则整体信号电平可能会增加。作为另一示例,可以改变音频处理的频率响应。例如,可以在检测到爆炸后引入低通滤波(例如模拟爆炸后的暂时性听力损伤)。
[0185]
在许多实施例中,调整可以基于检测到的定向音频分量。例如,在一些实施例中,音频处理器401可以被布置为检测特定声源类型已经被检测到,然后试图从音频场景中去除这个声源。
[0186]
例如,音频处理器401可以响应于从音频分析器103接收到指示多通道信号包括对应于警报器的声源的数据而从多通道信号中减去相应的定向音频分量。例如,可以通过将空间滤波器应用于多通道信号来做到这一点,其中该空间滤波器与选择/生成定向音频分量的空间滤波器互补。作为另一示例,多通道信号可以由提取器203生成的时频瓦片表示,并且音频处理器401可以去除检测到属于定向音频分量的所有时频瓦片(例如针对剩余的时频瓦片用内插值替换它们)。
[0187]
在许多实施例中,音频处理器401可以被布置为响应于第一音频源属性而调整第一定向音频分量的振幅和位置中的至少一个。
[0188]
例如,不是完全去除定向音频分量,相反,音频处理器401可以被布置为相对于音频场景的其余部分增加或减小定向音频分量的相对信号电平。例如可以通过应用互补空间滤波和/或缩放属于特定定向音频分量的时频瓦片来实现这一点。作为另一示例,多通道信号可以被合成以直接对应于定向音频分量并且可以将该信号分量加到多通道信号中,或从中减去该信号分量。
[0189]
定向音频分量的位置例如可以通过以下方式进行修改:合成对应于定向音频分量的多通道信号,从多通道信号中减去它,对合成的多通道信号应用旋转以改变相关联的位
置(例如,通过应用矩阵运算),并将旋转后的合成多通道信号与多通道信号相加。
[0190]
作为另一示例,定向音频分量的位置可以在音频处理器401接收它之前,在由提取器203提供的空间元数据级别上直接修改。
[0191]
在许多实施例中,还可以响应于由特征处理器205生成的方向估计来调整音频处理。例如,如果声源被音频处理器401检测为增加(或减弱),则音频处理器401可以根据预期效果增强或减弱该检测到的声音。
[0192]
在许多实施例中,音频处理可替代地或附加地响应于由提取器203生成的特征而调整。例如,音频处理可根据给定声音的传入方向增强或减弱给定声音。
[0193]
例如,前面两个示例的组合将导致音频处理器401能够增强从后面接近的声音,反映这种类型的声音对象潜在地指示危险。
[0194]
在许多实施例中,音频处理器401可以通过将频谱掩蔽应用于多通道音频信号来确定不同音频源的一个或多个音频分量,其中频谱掩蔽取决于音频分析器103检测到的类别。例如,只有在检测到给定类别时才可以应用频谱掩蔽。在其他实施例中,提取给定音频分量的给定频率滤波器的频率响应可取决于特定类别。例如,可以使用不同的滤波器来提取与鸟鸣对应的音频源和与雷声对应的音频源。
[0195]
因此,在一些实施例中,每个类别可以与一组频谱掩蔽属性关联,并且音频处理器可以被布置为将频谱掩蔽应用于多通道音频信号,其中频谱掩蔽响应于频谱掩蔽属性而生成。
[0196]
在许多实施例中,还可以基于提取器203的操作确定滤波器。例如,可以分析对应于特定定向音频分量的时频瓦片以检测其中定向音频分量被视为主导音频源的一个或多个频域。然后可以设计用于提取该定向音频分量的频谱掩蔽滤波器,使其具有相应的频率响应。
[0197]
在许多实施例中,定向音频分量可以由提取器203直接生成或由如前所述的空间滤波生成。然而,在每个定向音频分量可以包括对应于一个以上音频源的音频的情况下,可以通过对定向音频分量应用频谱滤波来分离这些音频。
[0198]
在许多实施例中,音频处理器401可以被布置为执行可被称为音频再利用的过程。音频再利用包括更改音频场景的参数/属性,包括去除或移动某些音频源。
[0199]
在这些实施例中,可执行频谱掩蔽步骤(也称为单通道音频源分离)以重构信号sk(t)。在每个方向有多个源的情况下,可以执行附加的频谱分离步骤以提取定向音频分量中的混合源。这种频谱分离可以使用例如以下文献中描述的矩阵分解来执行:barker和t.virtanen等人发表的“blind separation of audio mixtures through nonnegativetensor factorization of modulation spectrograms(通过调制频谱图的非负张量分解对音频混合进行盲分离,《ieee/acm transactions on audio,speech,and language processing》24.12(2016年12月),第2377-2389页)”或n.takahashi和y.mitsufuji发表的“multi-scale multi-band densenets for audio source separation(用于音频源分离的多尺度多频段密集网络,《ieee workshop on applications of signal processing to audio and acoustics (waspaa)》,2017年10月,第21-25页)”。
[0200]
在这样的频谱分离步骤之后,可以使用维纳滤波器重建时间信号。为了使生成的
类别/标签与生成的信号匹配,源分离步骤优选地由音频分析器103生成的结果控制。
[0201]
音频再利用例如可以包括将渲染效果应用于提取的源信号(具体地应用于定向音频分量),例如增益、混响等。
[0202]
作为另一示例,对应于定向音频分量的已提取音频信号可基于相关联的检测类别来静音或增强。例如,在多人在线战斗竞技场(moba)游戏中增强ping(即提醒队友在给定位置看到对手的音频警报)或在第一人称射击游戏中增强炸弹即将爆炸的声音可能很有用。此外,一些视频游戏声音场景往往会被感知为过于模糊(音频信息过多),因此在许多应用中的有利效果是去除音频场景的正面或可见的音频源。在后一种情况下,还可以估计音频-视频映射。
[0203]
在一些实施例中,音频再利用可以包括声源的再空间化,即通过在其他位置重新合成一个或多个定向音频分量。
[0204]
应当理解,在许多实施例中,渲染器105和/或音频处理器401的操作还可以响应于经由合适的用户界面提供的用户输入而调整。
[0205]
例如,用户可以选择他希望应用该过程的方向或区域(例如,仅后场,无前近场)。这可以针对各个类别进行具体控制,从而针对不同类别实现不同的操作。应当理解,可以设想许多不同的方法,例如:
[0206]
·
要求用户选择声源类别并根据此声音是否处于活动状态激活或停用雷达。
[0207]
·
要求用户选择一个类别并增强或消除特定声音。
[0208]
图6示出了对音频进行分类的方法的示例。
[0209]
该方法开始于步骤601,其中接收表示场景的音频的多通道音频信号。
[0210]
步骤601之后是步骤603,其中通过对多通道信号应用空间滤波来提取至少第一定向音频分量,空间滤波取决于多通道音频信号。
[0211]
步骤603之后是步骤605,其中为第一定向音频分量确定一组特征。
[0212]
步骤605之后是步骤607,其中响应于该组特征而从多个音频源类别中确定第一定向音频分量的第一音频源类别。
[0213]
步骤607之后是步骤609,其中从第一音频源类别的一组音频源属性中将第一音频源属性分配给第一定向音频分量。
[0214]
上面的描述侧重于使用音频源属性以及潜在地确定的特征和方向来调整视听渲染。然而,应当理解,在其他实施例中,生成的数据可以用于其他目的。
[0215]
例如,在一些实施例中,声音事件及其音频源属性(例如空间中的位置)的检测可用于触发动作、过程、程序、操作等。
[0216]
例如,视频游戏流转换器可以实时地生成视频,以便观看者可以关注流转换器的游戏。在这种情况下,如果基于特定的声音和/或方向识别出进来的角色,则触发脚本以将动画添加到流转换器视频中对于流转换器来说很有用。
[0217]
一种装置可以包括:接收器(201),其用于接收表示场景的音频的多通道音频信号;提取器(203),其用于通过对多通道信号应用空间滤波来提取至少第一定向音频分量,其中空间滤波取决于多通道音频信号;特征处理器(205),其用于确定第一定向音频分量的一组特征;分类器(207),其用于响应于该组特征而从多个音频源类别中确定第一定向音频分量的第一音频源类别;以及分配器(209),其用于从第一音频源类别的一组音频源属性中
将第一音频源属性分配给第一定向音频分量。
[0218]
对于这样的装置,可选地,提取器(203)包括:分频器(301),其用于将多通道音频信号的音频通道信号划分为多个频率区间信号分量;方向估计器(303),其用于确定多个频率区间信号分量中的每个频率区间信号分量的方向;分组器(305),其响应于每个频率区间信号分量的方向而将频率区间信号分量分为多个组;以及生成器(307),其用于通过组合一组频率区间信号分量的频率区间信号分量来生成定向音频分量。
[0219]
一种方法可以包括:接收表示场景音频的多通道音频信号;通过对多通道信号应用空间滤波来提取至少第一定向音频分量,空间滤波取决于多通道音频信号;确定第一定向音频分量的一组特征;响应于该组特征而从多个音频源类别中确定第一定向音频分量的第一音频源类别;以及从第一音频源类别的一组音频源属性中将第一音频源属性分配给第一定向音频分量。
[0220]
在这种方法中,可选地,提取包括:将多通道音频信号的音频通道信号划分为多个频率区间信号分量;确定多个频率区间信号分量中的每个频率区间信号分量的方向;响应于每个频率区间信号分量的方向而将频率区间信号分量分为多个组;以及通过组合一组频率区间信号分量的频率区间信号分量来生成定向音频分量。
[0221]
这种方法的装置和方法可以使用其他方法进行提取。
[0222]
本发明可以使用硬件、软件、固件或这些的任何组合,或者实际上以任何合适的方式来实现。各个特征和功能实体可以以任何合适的方式在物理上、功能上和逻辑上实现,包括单个单元、多个单元或使用分布式处理。
[0223]
包括在不同权利要求中的各个特征可能被有利地组合,并且包括在不同权利要求中并不意味着这样的特征组合是不可行的和/或有利的。此外,在一个权利要求类别中包含一个特征并不意味着限于这一类别,而是表明该特征同样适用于其他适当的权利要求类别。权利要求中的特征顺序并不暗示这些特征必须以任何特定的顺序工作,特别是方法权利要求中的各个步骤的顺序并不暗示这些步骤必须按此顺序执行。单数引用不排除复数。因此,对“一”、“一个”、“第一”、“第二”等的引用并不排除多个。对“第一”、“第二”等的引用并不暗示相应特征之间的任何特定排序、顺序或关系,而仅被解释为标签。权利要求中的参考标号仅作为说明示例而提供,并不限制权利要求的范围。
[0224]
本发明不限于在此阐述的具体形式并且本发明的范围仅由所附权利要求限制。此外,尽管特征可能看起来是结合特定实施例来描述的,但是这些特征可以适当地与其他实施例的特征组合。在权利要求中,术语“包括”不表示仅对这些特征的任何限制并且不排除其他特征的存在。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1