基于人工智能的异构网络多路径调度方法和系统
本发明涉及计算机网络传输控制领域,具体地说,本发明涉及一种基于经验驱动的异构网络多路径传输控制协议(mptcp)的调度方法和系统。
背景技术:
目前,最广泛使用的多路径解决方案是mptcp,它使得未修改的应用程序能够利用多个异构网络接口,如蜂窝网络、wifi和以太网。mptcp已经在linux内核中实现,并受到许多商业产品的支持。mptcp在tcp和应用层之间增加了一个外壳层,可以在每个网络接口上建立多个tcp子流。多路径调度器确定从发送队列分发到每个tcp子流上的数据包数量。然而,tcp子流的异构性使得设计一个好的调度器十分具有挑战性。错误的调度器会导致严重的数据包无序到达接收端,即调度在较快路径上的数据包不得不等待较慢路径上的数据包,从而到达接收端一个共享的无序队列。这种现象也被称为线头阻塞(hol)。由于延迟了数据包的发送,hol使得应用程序的交互性降低,导致用户体验不佳。
终端主机(endhost)必须维持一个很大的缓冲区,以重新组织无序的数据包。如果主机缓冲区是有限的,它将导致应用程序性能的急剧下降,因为当数据包突然到达时接收缓冲区必须拒绝一些包。此外,由于较慢的那个子流在等待时间内积累了大量空闲的发送窗口,较慢子流中阻塞数据包的数据级确认(data-levelacknowledgement,dataacked)将会导致数据包的突发。如果网络内缓冲区(即,路由器或者交换机的缓存)不够大,则无法存储这些突发数据包,就会导致严重的数据包丢失和拥塞窗口封顶。为了解决这些问题,daps首先提出无序发送的概念来实现有序到达。blest根据路径的属性(如往返时间(roundtriptime,rtt)、拥塞窗口大小(congestionwindows,cwnd)和发送窗口大小(sendwindows,swnd)计算较快子流的等待包。在继承这些思想的基础上,ecf增加了一个偏差来校准等待包的值,并取得了比daps和blest更好的性能。stms最终为每个子流保留一个间隙值(gap),以预分配未来的包,其性能优于ecf。通过简单的公式推导,我们发现daps、blest和ecf也是基于gap的调度器,它将不可控的无序队列大小(oqs)问题从接收端转换为发送端可调gap。
如图1所示,假设一个mptcp连接只有两个活动子流的情况,并将cwndf、cwnds、rttf、rtts表示为更快子流和更慢子流的可用cwnd和rtt。假设发送队列中有100个数据包,并且没有分配给任何子流。如果rttf有冗余的cwndf,则数据包被调度到rttf。如果rttf没有可用的空间,则使用cwnds将数据包调度到rtts。较慢的子流rtts总是发送序列号较预期大的数据包,而不是取序列号刚好在较快路径rttf上传输的数据包序号的后一个数据包。这样就为更快的路径在将来发送相应的数据包留下了一个序列间隙(gap),gap值是调度器分配给每条子流的数据,是考虑到两条子流的性能差异而预先分配的。当来自较慢路径的数据包到达时,来自较快路径的所有数据包(包括gap)已经到达,而且没有任何间隔。由于任何偏离其真实gap值的偏差都会导致接收端数据包无序到达。我们重建了stms和ecf中已经使用过的可控试验台。并将rttf、rtts随机设置为[20ms,50ms]和[50ms,100ms]。两条路径的带宽被设置为50mbps。数据包丢失率设置为0.01%。路由器的网内缓冲区设置为wifi为100包,lte为3000包。使用耦合拥塞控制balia,并将接收和发送缓冲区都设置为linux默认大小(6mb)。通过观测接收端的乱序队列的大小(oqs)。
如图2(左)所示,实验结果表明基于gap的调度器确实能够在一定程度上减少接收端的乱序情况,但当mptcp建立超过三个子流时,linux原生的最小rtt优先调度器(minrtt)的oqs比基于gap的调度器都要小。此外如图2(右)所示,通过手动调整每个子流的gap值,并观测最小oqs以搜索并估计它们的真实gap值。随着存活子流数量的增加,现有的gap调度器的每条子流gap值与其真实值相差约10%-15%以上。通过简单分析可知,现有的调度器在为每一轮的活动子流分发数据包时,都必须根据rtt对这些子流的优先级进行排序,而rtt本身就是测不准的,因此错误顺序将最终累积每个gap值的误差。与此同时,这些的gap调度器都会使用一个确定的数学模型来计算gap的数值,这样就无法将tcp层众多的随机属性(如:丢包率、数据包交付率等)考虑进去。也就是说现有的调度器设计,都引入局限的人类经验,并对mptcp多子流的环境空间的进行了特殊化处理,如假设一个不超过两个子流的特定网络环境。但是,如果将tcp层所有的属性都考虑进来,将没有一个函数式的模型能够准确的衡量gap的值。因此,常规的建模方法不能自适应动态变化的mptcp多子流环境。
考虑到mptcp子流数量的动态性和子流tcp层属性的随机性,使用经验驱动的深度增强学习可以很好的解决这些问题。因为子流的创建过程可以是一个时间序列模型,而子流的优先级需要综合考虑其tcp层的全部属性,而使用transformer网络可以很好的解决子流的动态时序性,因为每条子流的属性条目可以看做一个词汇而词汇之间的差距就是我们需要调节的gap值。与此同时子流间的关联程度和子流唯一的标签位置可以使用transformer自带的多头注意(multi-headattention)和位置嵌入(positionembedding)方法得以很好的解决。与此同时,深度神经网络常用于非线性关系的函数估计器,从而能够应对子流属性的随机性,将经过transformer编码的子流属性输入到深度神经网络中,就能记住整个环境所有可能的状态变化。最后,使用深度增强学习模型整合上述两部分,将mptcp所处的多子流环境的变化当作状态空间,将调节gap的数值当作动作空间,而将调节后mptcp接收端的oqs变化情况当作反馈效用。就能通过强化学习的方式正反馈的将oqs尽可能的降低。
技术实现要素:
本发明的目的是为了克服在上述异构网络中多路径传输接收端遇到的数据包乱序问题,并提出了一种基于经验驱动的异构网络多路径调度方案。
针对现有技术的不足,本发明提出一种基于人工智能的异构网络多路径调度方法,其中包括:
步骤1、将应用层的待发送数据加入该发送队列,并建立多条用于将该待发送数据发送至终端设备网络接口的tcp子流;
步骤2、各tcp子流中该待发送数据成功发送至该终端设备网络接口后产生确认消息,得到该确认消息对应的tcp子流的属性条目,集合所有tcp子流的属性条目,得到状态空间;
步骤3、使用transformer网络编码该状态空间,得到当前时刻的编码信息,并将该当前时刻的各tcp子流的间隙值与该编码信息打包成数据包后存入存入重放缓冲区;
步骤4、批量采样该重放缓冲区中的数据包,得到历史样本,将该历史样本输入强化学习网络,该强化学习网络基于函数逼近的学习策略学习该历史样本,得到每条tcp子流的间隙调整值,基于该间隙调整值调度每条tcp子流的数据。
所述的基于人工智能的异构网络多路径调度方法,其中所有该tcp子流共享该发送队列。
所述的基于人工智能的异构网络多路径调度方法,其中步骤3中该transformer网络包括:
将每个tcp子流的状态嵌入到向量,得到各子流的状态向量,根据该状态向量,提取各子流之间的关系,将各子流之间的关系通过该全连接前馈网络输入至堆叠编码器后得到该编码信息。
所述的基于人工智能的异构网络多路径调度方法,其中步骤4中该历史样本包括:t时刻和t+1时刻的状态空间st,st+1,t时刻的tcp子流的gap调节动作at,t时刻的反馈函数rt。
所述的基于人工智能的异构网络多路径调度方法,其中该强化学习网络为dqn网络;
该步骤4具体包括:
以状态-动作对(st,at)为输入,输出相应的q值q(st,at),来表示期望得到折现后的累积奖励q(st,at;θ)=e[rt|st,at;θ),应用ε贪婪策略,遵循概率为1-ε的贪婪策略,选择概率为ε的随机动作,得到π*(s);
该dqn网络以权向量θq作为q网络,通过最小化损失函数l(θq)序列,来对该dqn网络进行训练或更新;l(θq)=e[(q(st,at;θq)-yt)2]。
本发明还提出了一种基于人工智能的异构网络多路径调度系统,其中包括:
模块1,用于将应用层的待发送数据加入发送队列,并建立多条用于将该待发送数据发送至终端设备网络接口的tcp子流;
模块2,用于使各tcp子流中该待发送数据成功发送至该终端设备网络接口后产生确认消息,得到该确认消息对应的tcp子流的属性条目,集合所有tcp子流的属性条目,得到状态空间;
模块3,用于以transformer网络编码该状态空间,得到当前时刻的编码信息,并将该当前时刻的各tcp子流的间隙值与该编码信息打包成数据包后存入存入重放缓冲区;
模块4、用于批量采样该重放缓冲区中的数据包,得到历史样本,将该历史样本输入强化学习网络,该强化学习网络基于函数逼近的学习策略学习该历史样本,得到每条tcp子流的间隙调整值,基于该间隙调整值调度每条tcp子流的数据。
所述的基于人工智能的异构网络多路径调度系统,其中所有该tcp子流共享该发送队列。
所述的基于人工智能的异构网络多路径调度系统,其中模块3中该transformer网络包括:
将每个tcp子流的状态嵌入到向量,得到各子流的状态向量,根据该状态向量,提取各子流之间的关系,将各子流之间的关系通过该全连接前馈网络输入至堆叠编码器后得到该编码信息。
所述的基于人工智能的异构网络多路径调度系统,其中模块4中该历史样本包括:t时刻和t+1时刻的状态空间st,st+1,t时刻的tcp子流的gap调节动作at,t时刻的反馈函数rt。
所述的基于人工智能的异构网络多路径调度系统,其中该强化学习网络为dqn网络;
该模块4具体包括:
以状态-动作对(st,at)为输入,输出相应的q值q(st,at),来表示期望得到折现后的累积奖励q(st,at;θ)=e[rt|st,at;θ),应用ε贪婪策略,遵循概率为1-ε的贪婪策略,选择概率为ε的随机动作,得到π*(s);
该dqn网络以权向量θq作为q网络,通过最小化损失函数l(θq)序列,来对该dqn网络进行训练或更新;l(θq)=e[(q(st,at;θq)-yt)2]。
由以上方案可知,本发明的优点在于:在linux内核中部署基于ac的数据包调度器,并在可控和真实的实验环境下对调度器进行评估。与目前最先进的基于gap的调度器技术相比,本发明的优点在于将子流的第99百分位oqs降低了68.3%,将吞吐量的聚合性能提高了12.7%,并将应用程序延迟降低了9.4%。
附图说明
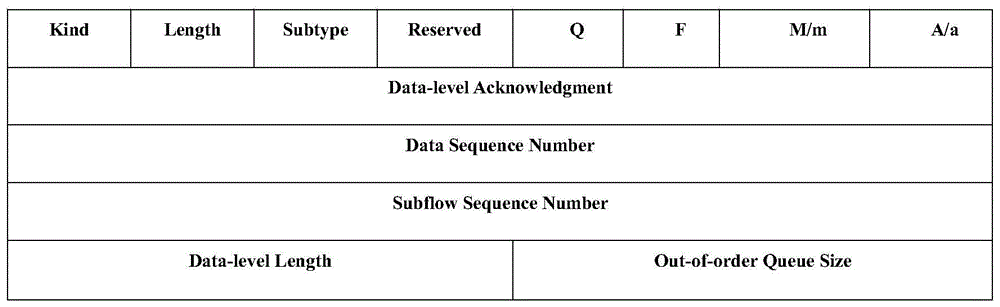
图1示出了子流的间隙值gap的基本概念。
图2示出了现存gap调度器导致的oqs和真实gap差异的分布情况。
图3示出了新增的q-bit位所在的位置。
图4示出转换动态自己的transformer网络结构图。
图5示出基于ac神经网络的数据包调度架构图。
图6示出ac深度调度器的具体更新步骤。
图7示出经验驱动gap调度器oqs与真实gap差异的分布情况。
图8示出经验驱动gap调度器的应用延迟改善情况。
图9示出经验驱动gap调度器的吞吐量提升情况。
具体实施方式
本发明设计了一种基于人工智能的多路径传输控制协议(mptcp)的数据包调度优化方法和系统。该系统利用transformer网络和深度增强神经网络,通过探索和利用的方式总结数据包调度的历史经验,从而准确且自适应地调节每条tcp子流的gap数值,以最小化多路径调度器接收端的乱序情况。主要包括如下:
关键点1:提出了一个深度增强学习多路径数据包调度框架,实现了基于经验驱动的mptcp数据包调度逻辑。不依赖于准确僵化的线形数学模型,充分考虑每条子流的tcp层的随机属性,根据异构无线网络的运行时状态,利用深度神经网络作为gap调节的函数近似,以实现准确且自适应的gap调节机制。
关键点2:整合transfomer网络作为异步actor-critic(ac)智能体网络的表示层,以编码的方式动态存储所有子流的原始状态。使用位置嵌入的方式让每个子流获得一个唯一的位置标签来映射gap值。利用自注意层计算任意两子流之间的关联度,以提高了每次调节gap的精度值。
关键点3:在数据序列信号保留区(datasequencesignaloption,dss)选项中为每个dataack增加一个新的标志位。与具有mp_capble能力的a-bit位选项合作,通过payload的方式将oqs信息包含到每个dataack数据包中。使得oqs能够从接收端被带回到发送端的调度器直接作为增强神经网络的反馈效用。其中mp_capble是mptcp的使能信号,即握手时只有带有这个信号,两端才能进行mptcp多路径传输。
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
为了对本发明的技术特征、目的和效果有更加清楚的理解,现参照附图对本发明提出基于深度增强神经网络的mptcp数据包调度优化方法和系统进一步详细说明。
因为向增强学习模型的状态空间中添加更多子流属性并不一定会带来显著的性能改进,反而会增加数据收集开销和训练的复杂性。现有gap调度器的众多实验可知,如往返时间rtt、拥塞窗口大小cwnd、数据包交付率(packetdeliveryrate,pdr)和数据包丢包率(packetlossrate,plr)与gap调节有很强的相关性。相关测量结果也表明,每一轮的dataacked和主机缓冲区的大小与乱序队列导致的数据包排队时延oqs-latency有关。因此,本发明将t时刻子流i的rtt、cwnd、pdr、plr、dataacked和mptcp每一轮的接收窗口的大小rwnd的状态属性条目表示为:sti=[dti,cti,bti,lti,wti,kti]。而n条子流的状态值构建的“状态空间”为:st=[st1,···,sti,···,stn]。为减少每次调节的误差,本发明将每次gap调节的动作gti最小调节单元设置为1个tcp数据包(大约1kb),而n子流的组成的“动作空间”为:at=[gt1,···,gti,···,gtn]。因为在接受方的乱序队列大小oqs是调度器优化的目标,本发明直接将oqs作为增强学习的反馈效用函数。如图3所示,本发明在dss选项的预留区域,为每个数据ack添加一个q-bit标志位301。配合mp_capable选项中的a-bit标志位302,当q&a=1时,占用“校验和”区域的两个八进制位303,将当前的oqs返回给调度器的发送方,然后效用函数表示为:rt=-oqs,其中a-bit标志位是用来返回checksum的,q-bit表示是否占用a-bit位原先的checksums的字段,以返回oqs。
图5示出了根据本发明的一个具体实施例,深度增强神经网络方法进行数据包gap自适应调整的工作流程图,该系统的更新步骤如下:
(1)步骤501:mptcp的调度器将来自应用层的数据,分发到终端设备配备的多个网络接口上。这期间,mptcp将会维持多条tcp子流,一对物理接口维持一条tcp子流。而且这些子流的建立和关闭是独立且动态的。因为所有的子流共享一个mptcp发送队列和接受队列,所以发送端的gap调节直接影响了接收端的oqs大小。
(2)步骤502:实现了n条tcp子流的传输层属性的采集模块,其中数据包交付速率的采集借鉴了bbr拥塞控制算法的pdr定义。每一轮连接级别的dataacked将采集到的n条子流的属性条目sti组成的状态空间st交付给transformer网络。
(3)步骤503:使用transformer网络对原始的子流状态空间编码,如图4所示,每个编码器401由两个子层组成。第一层是一个多头自注意层402,用于将多条子流之间的相关关系提取出来,以计算后面的gap差异,第二层是一个简单的位置全连接的前馈网络403,用于调整神经网络参数。将两个规范化层404部署为围绕每个编码器的剩余连接。通过词嵌入模块405将每个状态sti嵌入到向量中。每个状态sti的唯一位置由位置编码406决定。然后st的向量被传递给具有远程依赖的自注意模块。输出经过ex层堆叠编码器处理后,作为强化学习actor-critic网络的输入返回。
(4)步骤504:通过使用经验回放,深度增强学习模型将历史的状态转移样本(st,at,rt,st+1),存储到重放缓冲区中,然后,通过重放缓冲区中的小批量采样而不是立即收集的状态转移来更新神经网络的的参数值。其中小批量采样可以是随机抽取状态转移样本,然后喂给神经网络。使用这种方式,增强学习的智能体才能够打破了观察序列中的相关性,从而学习一个更加独立和相同分布的过去经验池。
(5)步骤505:使用用函数逼近技术来学习动作策略。一个函数逼近器由一个向量θ参数化,它的大小比所有可能的状态-动作对的数目小得多(因此数学上易于处理)。函数逼近器可以有多种形式。deep-mind设计了deepq-networks(dqn),该算法利用dnn逼近器扩展了传统q-learning算法。
dqn以步骤504中的状态-动作对(st,at)为输入,输出相应的q值q(st,at),来表示期望得到折现后的累积奖励q(st,at;θ)=e[rt|st,at;θ),θ用来表示当前估计函数:神经网络的参数组成的向量。然后,rt为训练过程t时刻的反馈函数,应用ε贪婪策略,ε的值可根据训练效果进行调节,遵循概率为1-ε的贪婪策略,选择概率为ε的随机动作,得到π*(s),其中s是状态空间的抽象化,之前的st是t时刻的状态。由于dqn是指一个神经网络函数逼近器,以权向量θq作为q网络。则可以通过最小化每次迭代时变化公式(1)的损失函数l(θq)序列,来对q网络进行训练或更新。
l(θq)=e[(q(st,at;θq)-yt)2]公式(1)
其中
e表示计算累计平均,yt是根据bellmanequation推导的目标函数。上标q是为了标示神经网络是用来产生q值。同理上标miu是表示这个神经网络是用来产生策略。
考虑到dqn只能处理离散和低维的动作空间。而许多感兴趣的任务,如我们的gap调节调度器有连续的高维动作空间。为了满足连续控制的要求,工程上常用方法是策略梯度,主要包括基于行为者批评的方法,也被称为深度确定性策略梯度(ddpg)。因此,本发明将dqn和最新的确定性策略梯度结合起来用于gap调节的连续控制。基于ddpg需要同时维护四个dnn。两个dnn是评论家(critics)网络q(st,at,θq)和表演者(actor)网络:μ(st;θμ)。其中这两个网络的权值分别为:θq和θμ。另外,还有两个复制的dnns,目标表演者(targetactor)网络μ(st;θμ′)和目标批评家(targetcritic)网络q(st,at;θq′)用于表演者网络和评论家网络的平滑更新。对于任意概率态分布ρ和起始分布j,上述dnn的参数θq和θμ按公式(2)(3)进行梯度更新。然后使用公式(4)更新演员和评论员的目标网络,让他们慢慢跟踪这θq和θμ两个的深度神经网络,τ<<1。算法最终的更新步骤如图6所示。
θ′←τθ+(1-τ)θ′公式(4)
综上所述,本发明推导并统一了异构网络条件下基于gap的mptcp数据包调度算法。为了实现一个精确且自适应的数据包调度模块,本发明设计了一个基于经验驱动的智能系统,该系统将每条mptcp连接tcp子流的可变状态输入到transformer网络中,该网络由ex=6叠层编码器构成,每个编码器的输入嵌入是一个大小为512的向量空间。而actor网络由两个完全连接的隐藏层分别由48和48个神经元组成。在两个隐层中使用经过整流的线性函数进行激活。输出层的激活使用双曲正切函数。critic网络也有两个隐藏层,与执行者网络相同,除了一个额外的输出层,输出层只有一个线性神经元(没有激活功能)。在训练过程中,本发明使用adam方法对actor和critic的神经网络参数进行学习,且学习率分别为10-4和10-3。软目标更新设置为τ=0.001,将默认权重设置为α=0.5,并使用折扣因子γ=0.99,为了兼容性,本发明使用tflearn深度学习库的tensorflowapi训练和测试深度神经网络。本发明在linux内核中实现了包调度器,它通过系统调用setsockopt()来执行用户空间中来自actor-network的每个子流的gap间隙调整。并调用getsockopt()来捕获原始网络状态和oqs度量。最终收敛的ac网络能够监控网络状态,并调整每条子流的gap值,使mptcp连接的奖赏效用最大化。如图7所示,基于经验驱动的数据包调度器的准确性在于它能搜索最优的行动策略,与真实gap的偏差仅为1.2%-3.3%。而它的适应性在于它在变化的网络条件和拥塞控制算法中表现得更好。在可控的和现实的实验中,如图9本发明设计的调度系统使mptcp连接的第99百分位oqs降低了68.3%。如图8与当前最先进的调度器相比,它允许在批量流量的应用程序goodput中增加12.7%,并减少应用程序延迟9.4%。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还提出了一种基于人工智能的异构网络多路径调度系统,其中包括:
模块1,用于将应用层的待发送数据加入发送队列,并建立多条用于将该待发送数据发送至终端设备网络接口的tcp子流;
模块2,用于使各tcp子流中该待发送数据成功发送至该终端设备网络接口后产生确认消息,得到该确认消息对应的tcp子流的属性条目,集合所有tcp子流的属性条目,得到状态空间;
模块3,用于以transformer网络编码该状态空间,得到当前时刻的编码信息,并将该当前时刻的各tcp子流的间隙值与该编码信息打包成数据包后存入存入重放缓冲区;
模块4、用于批量采样该重放缓冲区中的数据包,得到历史样本,将该历史样本输入强化学习网络,该强化学习网络基于函数逼近的学习策略学习该历史样本,得到每条tcp子流的间隙调整值,基于该间隙调整值调度每条tcp子流的数据。
所述的基于人工智能的异构网络多路径调度系统,其中所有该tcp子流共享该发送队列。
所述的基于人工智能的异构网络多路径调度系统,其中模块3中该transformer网络包括:
将每个tcp子流的状态嵌入到向量,得到各子流的状态向量,根据该状态向量,提取各子流之间的关系,将各子流之间的关系通过该全连接前馈网络输入至堆叠编码器后得到该编码信息。
所述的基于人工智能的异构网络多路径调度系统,其中模块4中该历史样本包括:t时刻和t+1时刻的状态空间st,st+1,t时刻的tcp子流的gap调节动作at,t时刻的反馈函数rt。
所述的基于人工智能的异构网络多路径调度系统,其中该强化学习网络为dqn网络;
该模块4具体包括:
以状态-动作对(st,at)为输入,输出相应的q值q(st,at),来表示期望得到折现后的累积奖励q(st,at;θ)=e[rt|st,at;θ),应用ε贪婪策略,遵循概率为1-ε的贪婪策略,选择概率为ε的随机动作,得到π*(s);
该dqn网络以权向量θq作为q网络,通过最小化损失函数l(θq)序列,来对该dqn网络进行训练或更新;l(θq)=e[(q(st,at;θq)-yt)2]。
- 还没有人留言评论。精彩留言会获得点赞!