基于用户请求可能性与时空特性的新型内容缓存部署方案的制作方法
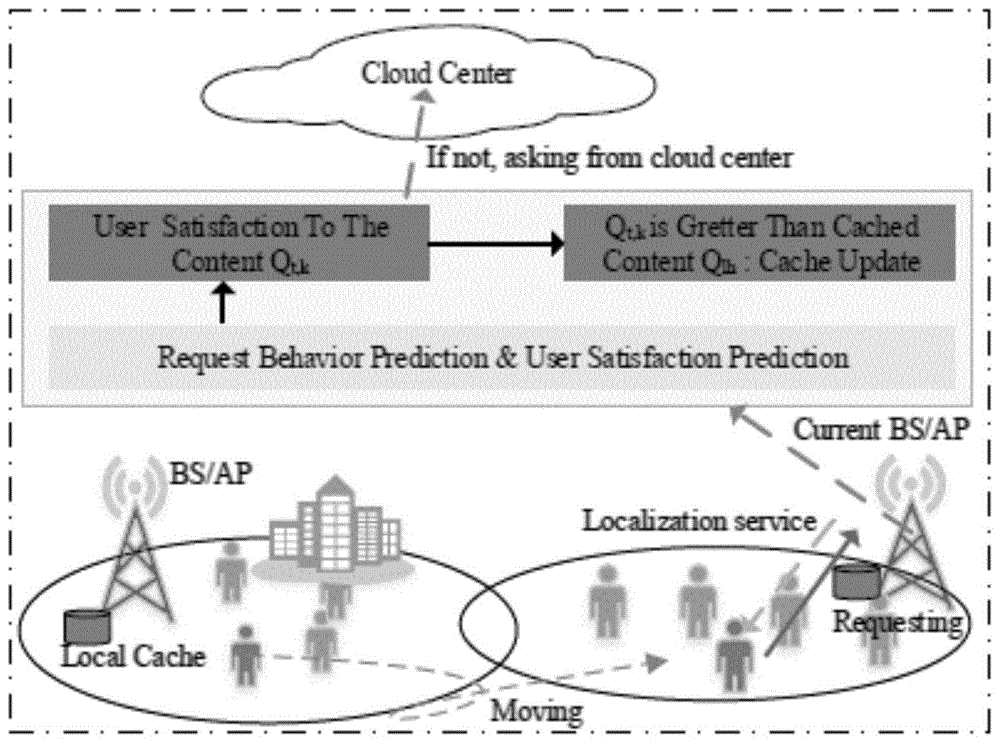
本发明涉及一种无线通信技术领域的边缘缓存部署方案,具体提出了一种基于用户请求可能性和考虑时空特性的用户偏好的新型内容缓存部署方案。
背景技术:
自从第五代移动通信技术提出以来,业界对通信系统便提出了高可靠性和低延迟的要求。同时,要求5g移动通信系统具有更高的系统容量,频谱效率,能效,场景适应性和更高的用户体验质量。然而,随着各种智能设备和多媒体应用的普及,对网络通信,特别是对于因特网视频业务的需求激增。现有的被动通信模式将大大增加在高峰数据通信时间期间阻塞的可能性,因此可以考虑选择主动通信方式,例如可以提前主动缓存内容的边缘缓存。一种可行的解决方案是将位于云中心的部分资源(例如通信,计算和缓存)迁移到更靠近用户的网络边缘,以便可以在本地提供用户经常请求的内容,减少通信延迟和转发负载,并可以提高整个网络的通信质量。
诸如fifo(先进先出),lru和lfu之类的传统缓存技术已广泛用于有线网络中,这些缓存策略通过简单的统计数据进行分析,用足够的缓存空间和计算资源来判断可能的缓存热点,并且服务区域通常很大。然而,在实际的通信场景中,与传统的有线网络不同,ap(接入点)的缓存容量和计算资源有限,覆盖范围较小,并且用户对内容的请求具有随机特征。因此,传统的缓存技术不能应用于变化的无线通信场景。为了确保为更多内容提供有效的本地化服务并达到最小化通信延迟的目的,边缘缓存技术面临着巨大的挑战。
经过对现有技术文献检索发现,sabrinamüller等在《ieeetransactionsonwirelesscommunications,vol.16,no.2,pp.1024-1036,feb.2017.》上发表的文章“context-awareproactivecontentcachingwithservicedifferentiationinwirelessnetworks(无线网络中具有服务区分功能的上下文感知主动内容缓存)”提出了一种上下文感知的主动缓存新算法。通过定期观察已连接用户的上下文信息,更新缓存内容然后观察缓存命中,可以考虑对上下文特定内容的受欢迎程度进行在线学习。然而,它忽略了内容相似度和用户偏好对内容流行度的影响,学习复杂度较高。
另经检索发现,yanxiangjiang等在《ieeetransactionsoncommunications,vol.67,no.2,pp.1268-1283,feb.2019.》上发表的文章“userpreferencelearning-basededgecachingforfogradioaccessnetwork(基于用户偏好学习的雾无线电接入网络边缘缓存)”提出了一种基于用户偏好学习的边缘缓存方案,考虑了边缘缓存的时空特性,并认为用户对内容的请求不只是遵循一定的分布,而是具有随机性,能够在线预测内容流行度,降低了计算复杂度,但是,用户在不同时间或地点对某些类型的内容的偏好程度可能存在较大差异,该文章提出的方案并没有考虑时间特性对于用户偏好的影响。
经检索还发现,r.sun等在《ieeetransactionsonvehiculartechnology,vol.69,no.1,pp.636-650,jan.2020.》上发表了文章“qoe-driventransmission-awarecacheplacementandcooperativebeamformingdesignincloud-rans(cloud-ran中qoe驱动的传输感知缓存放置和协作波束形成设计)”。该文章针对支持缓存的cloudran提出了一种短期传输策略下的长期感知传输缓存方案,以提高视频流的体验质量。然而,这些工作并没有利用大数据和基于优化工具设计缓存方案。因此,这些研究的应用可能在真实环境中受到限制,因为无论是应用哪种缓存策略,用户的偏好/满意度通常都不像统一的分布那样具有可追踪性。
技术实现要素:
本发明要解决的技术问题是克服现有技术中传统的缓存技术不能很好的应用于变化的无线通信场景的缺陷,提供一种通过协同过滤挖掘数据集内多维信息,从用户点击行为和用户满意度两方面综合考虑缓存评估的缓存方案。
为了解决上述技术问题,本发明提供了如下的技术方案:
本发明考虑了内容组合特征对用户请求行为的影响,与现有方法不同,基于逻辑回归算法学习内容的多维特征影响,挖掘数据特征值之间的相关性,从而构建了用户请求概率预测算法。此外,将时间特征的影响引入到用户满意度的学习过程中,构建包含用户、内容得分和时间的三维张量数据模型,用于获取在特定时间下用户对请求内容的评分值。基于上述方法获得的用户请求概率预测值与用户满意度评分预测值得到区域用户满意度值,并以此为依据制定缓存更新策略。
定义无线网络缓存模型。在无线网络的边缘,接入点ap的集合表示为
本发明是通过以下技术方案实现的,本发明包括如下步骤:
s1、将区域用户在时间t内对于某个可能请求的内容fk的满意程度定义为区域用户请求满意度qt,k。在时间t内,抽取请求内容fk的特征矢量xk以及在用户请求行为模型中学习到的参数向量
s2、利用请求内容特征向量xk特征向量符号一致问题、用户m对请求内容fk的偏好向量mk以及时间特征向量tk去预测用户在第t时间内对第k个请求内容的请求评分向量
s3、缓存更新。为了方便查看当前的请求内容是否已经缓存在本地,设置一个本地缓存内容集
此外,本发明中提出边缘缓存方案评估指标。令指示变量
当未缓存fk时,缓存状态保持不变,即
通过考虑用户点击行为和用户对内容的满意度(即用户对内容的评分),我们定义了一个新的缓存性能指标,即缓存满意率(csr)。令
为了优化csr,本发明将首先考虑内容多维特征的影响,提出请求行为预测算法。然后,本发明将时间特征的影响引入用户满意度学习过程。最后,本发明提出结合了用户点击动作和用户满意度的缓存算法。
所述的用户请求行为预测模型与用户满意度学习模型具体是:
1)用户请求行为预测模型(bpmm)
首先,对于每个请求
其中
为了评估用户请求行为预测错误,引入了针对用户m的逻辑损失函数
收集的样本集表示为
构造的数据集具有特征维度大,数据稀疏和不平衡的特征,因此,使用基于在线梯度下降(ogd)方案的正则化领导者(ftrl)模型进行学习bpmm模型中的多个组合特征。实际上,引入组合功能会导致更高的模型复杂性。即使引入了l_1-正则,传统的ogd方法也无法产生良好的稀疏性。所提出的参数学习算法引入了l_1-正则化以获得组合特征的稀疏参数估计结果,并通过使用l_2-正则项来平滑结果。具体过程如下:
令n为学习请求行为参数的样本数。然后,可以在第n个样本迭代之后获得参数向量
其中||·||1,||·||2分别表示l_1范数和l_2范数。l1,l2代表惩罚项系数。
样本本身在不同特征中具有不同的稀疏性,在bpmm模型中引入的特征隐藏向量也具有相似的稀疏性,这将导致在学习过程中不同维度的用户请求行为参数
然后,根据上述等式使用不同的学习率来学习参数
2)用户满意度学习模型
令{mm},{fk},{tt}分别表示用户,文件和时隙,
其中,mm,fk分别是用户特征矩阵
其中
本发明利用完全贝叶斯处理方法,将模型中的超参数也视为随机变量,由于多维积分求解困难,使用马尔科夫链蒙特卡罗方法进行近似求解。本发明使用最常用的求解多维参数的gibbs采样方法进行求解,即:
其中,l代表收集的样本数。由此,我们可以获得m,f,t,由此获得用户m在时间t对请求内容fk的评分预测值
与现有技术相比,本发明的有益效果是:本发明的边缘缓存策略同时考虑了用户请求行为与用户对请求内容的满意度信息,既能反映用户点击行为又能反映用户对内容的满意程度,更符合用户需求,本发明在总体缓存满意率上的性能略优于现存缓存方案,但是在本发明中提出的缓存方案评估指标csr上的性能显示出显著优势。
本发明通过协同过滤挖掘多维数据,从用户点击行为和用户满意度两方面综合考虑缓存评估,提出了一种新的缓存度量-缓存满意率(csr)来表示用户对缓存内容的标准化总体满意度值;本发明提出的缓存算法可以根据用户请求概率和用户满意度的乘积对缓存内容进行更新,并预测每个时间段的值;在用户请求概率预测学习中,引入了内容的多维特征的影响来挖掘数据特征之间的相关性。另一方面,我们构建了包含用户、内容得分以及相应时间的三维张量数据模型。利用实体之间固有的协作关系表述为一个概率张量因式分解问题。此外,还利用了一种完全的贝叶斯处理方法,以确保因子的演化是平滑的,并避免参数的调整;基于真实数据集的实验结果表明,本文算法的总体缓存命中率优于现有算法,在用户满意度性能方面取得了显著的效果。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是实施例系统模型图;
图2是实施例不同缓存容量下的总体缓存命中率效果图;
图3是实施例得到的不同请求内容的总体缓存满意度图;
图4是实施例得到的不同缓存容量下的总体缓存满意率效果图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
实施例
本实施例使用movielens数据集。从2010年1月1日至2018年9月25日的数据集中选择30个用户作为整体请求数据集。其中,选择数据的前2/3作为rbpl算法的初始化数据集,其余数据用作性能评估,包括步骤如下:
s1、s个aps均设置特定场景下的监测周期,用于定期监测区域用户集
s2、在时间t内,会抽取请求内容fk的特征矢量xk以及在用户请求行为模型中学习到的参数向量
s3、为了方便查看当前的请求内容是否已经缓存在本地,设置一个本地缓存内容集
所述用户请求行为预测模型与用户满意度学习模型具体是:
1)用户请求行为预测模型
第一步,当一个请求内容被发起的时候,对于当前区域用户
第二步,计算该用户的目标损失函数,计算在请求过程中的累计损失值,即:
第三步,判断是否需要重启用户请求行为参数学习模型,当
用户请求行为参数学习模型具体如下:
第一步,设置初始参数,获取模型样本集中第n个样本的特征向量,根据如下公式计算用户请求行为参数
第二步,获取该用户对当前请求内容的真实请求行为
计算损失函数:
根据公式
第三步,根据如下公式分别在各个特征值不为0的维度上更新模型参数:
返回步骤一循环执行,直到损失函数达到最小值时终止模型训练,获取用户请求行为参数
2)用户满意度学习模型
令{mm},{fk},{tt}分别表示用户,文件和时隙,
其中,mm,fk分别是用户特征矩阵
其中
本发明利用完全贝叶斯处理方法,将模型中的超参数也视为随机变量,由于多维积分求解困难,使用马尔科夫链蒙特卡罗方法进行近似求解。本发明使用最常用的求解多维参数的gibbs采样方法进行求解,即:
其中,l代表收集的样本数。由此,我们可以获得m,f,t,由此获得用户m在时间t对请求内容fk的评分预测值
本实施例方法得到的在不同缓存容量下的总体缓存命中率效果图如图2所示,与显现缓存策略相比,略占优势,图3表明本发明连续缓存具有较高区域rpsa的内容,而缓存满意度较低的内容将被替换,所以会显示出较高的缓存满意度值。本实施例得到的在不同缓存容量下的总体缓存满意率效果图如图4所示,本发明在用户满意率csr指标上的性能明显好于现有缓存策略,图中效果表明本发明通过挖掘数据集多维特征设计的新型缓存策略可以实现增强智能缓存,从而提高无线网络中用户的体验质量。
本实施例的优点:本边缘缓存策略同时考虑了用户请求行为与用户对请求内容的满意度信息,既能反映用户点击行为又能反映用户对内容的满意程度,更符合用户需求,本发明在总体缓存满意率上的性能略优于现存缓存方案,但是在本发明中提出的缓存方案评估指标csr上的性能显示出显著优势。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!