一种移动应用中定位数据真伪辨别的方法和系统
本发明涉及一种为移动应用中用户上传的地理位置的真实性进行判别的方法和系统,属于网络安全
技术领域:
。
背景技术:
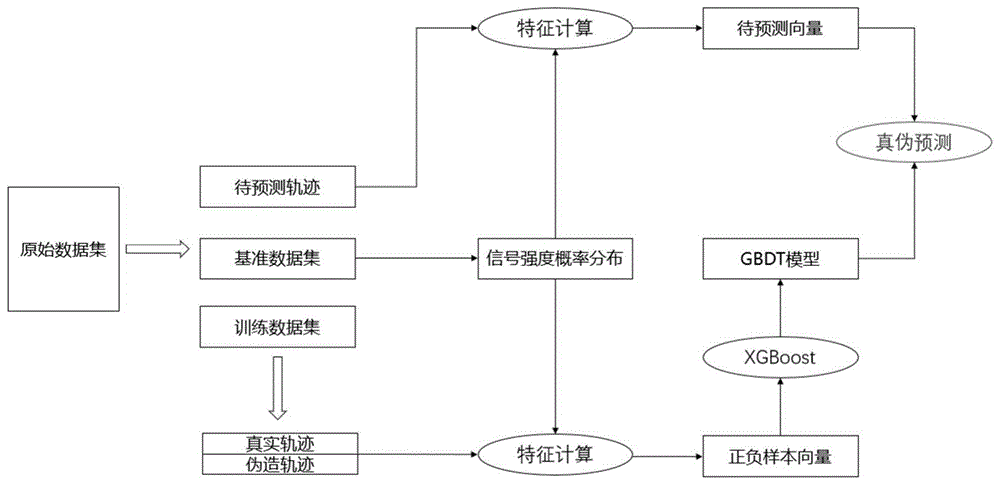
:基于地理位置提供服务(lbs)的移动应用如今越来越普遍,其中有一些应用会根据用户所处在位置的核验进行授权或者发放奖励,导致会有一些用户通过修改自己的定位来绕过对这些核验,常见的诸如线上的考勤打卡功能、增强现实(ar)手机游戏以及地理围栏功能等。这类用户的定位作弊行为会为应用运行带来损失。针对这种攻击,人们提出的防御方法主要有基于与特定设备的通信、基于附近用户提供的证明、基于环境信号和基于本地设备上的攻击行为检测四类方案。因为前两类方案中的假设性较强在现实中难以复刻,目前移动应用里一般使用后两种方案来辨别用户定位数据的真假。基于环境信号的检测方法一般将wifi信号信息、cell基站信息等数据与gps数据一同上传,服务商通过与数据库中的历史数据比对来判断gps数据的真实性。但这种方法存在缺陷,虽然用户无法直接获知某一区域的wifi与cell信息,但通过使用历史真实数据重放并添加随机噪声的方式仍然可以绕过这类方法的识别。基于本地设备上攻击行为的检测方案一般会检查设备是否被root,并且还会通过获取设备的应用安装列表来检查是否有一些黑名单中的工具软件。除此以外,还有检查应用代码的调用栈、应用中方法的签名是否被修改等手段来识别一些已知的修改数据手段。这类检测方法同样面临问题,一旦获取上述信息的手段被攻击者知悉,攻击者可以通过修改相关系统接口的返回值使服务提供方获取到错误的凭据,从而绕过这一类检测。因此,现有的防御检测方法都存在一些缺陷,需要加入一种新的方法来检测用户在使用应用时上传位置数据的真实性。相关知识:wifi指纹:wifi指纹在移动应用中一般是由wifi信号的接收强度值(rss)构成的向量,用于描述一个地点的wifi信息。因为rss受到与wifi路由器距离的影响,一般而言一份wifi指纹与该区域中的具体位置有一一对应的关系。xgboost:xgboost是基于梯度上升决策树(gbdt)的工程实现,本身为一款开源软件。它使用一些可选的基分类器集成去拟合特征向量与目标类表的映射关系,在迭代中不断让后面的基分类器去拟合前面基分类器的分类结果与目标结果的差值,最后所有基分类器的结果构成了特征向量预测属于各类别的概率。技术实现要素:发明目的:针对现有技术中存在的问题与不足,本发明提供一种移动应用中定位数据真伪辨别的方法和系统。假设所有获取到的数据都可能遭到了攻击者的篡改,并在此基础上对数据进行特征计算来加以校验,希望发现数据是否为真实的数据,使用的特征对添加随机噪声的重放类攻击具有很强的针对性。如果一名攻击者随意编造或是重放与当前定位相同的历史wifi指纹数据,通过比对数据库即可识别数据真伪;倘若攻击者进一步地为重放的数据添加了随机的小数值的噪声,通过本发明的方法和系统将可以识别出这类伪造数据。技术方案:一种基于wifi信息的移动应用中定位数据真伪辨别的方法,包括如下步骤:步骤1,从包含gps数据与wifi指纹数据的历史数据集中抽取一部分数据作为基准数据,并为所有基准数据计算rss概率分布;对于每一份待计算的基准数据,执行如下步骤:101,找出所有与待计算基准数据的定位坐标距离在设定范围内的其它基准数据;102,统计同一wifi信号在各基准数据中的rss值;所述各基准数据指的是101中的待计算基准数据和其他基准数据;103,根据待计算基准数据与设定范围内的其它基准数据的距离,结合赋予待计算基准数据自身的权重,计算每个wifi信号在待计算基准数据所对应位置可能被观测到不同rss值的概率。步骤2,从步骤1中提到的历史数据集中没有作为基准数据的历史数据里选取一部分数据作为训练数据,并进行特征计算;对于每一份待计算特征的训练数据,执行如下步骤:201,找出所有与待计算训练数据的定位坐标距离在设定范围内的基准数据;202,统计201中基准数据中各wifi信号的rss值与待计算训练数据的rss值相同的概率;203,选取训练数据中每个wifi的rss值、训练数据定位与基准数据中位置的距离、每一基准数据中取训练数据中wifi的rss值的概率作为训练数据特征。步骤3,模型训练,执行如下步骤:301,随机挑选一半的真实wifi+gps轨迹数据进行伪造,伪造结果作为负样本;302,正负样本计算出的特征向量输入到xgboost中训练,得到分类器模型。步骤4,用户在上传定位进行证明时,服务器收集这一定位以及发送证明请求之前上传的定位与wifi数据,组成待判别轨迹;分析待判别轨迹是否为伪造轨迹,执行如下步骤:401,比对历史wifi指纹数据库中同一区域的wifi指纹和用户上传的wifi指纹,判断用户上传数据是否为虚构数据。如果是虚构数据,则认为用户此次上传的定位数据为伪造数据,否则继续执行后续步骤。402,比对历史数据库判断wifi指纹和gps经纬度是否为重放数据;如果是虚构数据,则认为用户此次上传的定位数据为伪造数据,否则继续执行后续步骤。403,对待判别轨迹中每个点按照步骤2基于同样的基准数据计算出特征向量,使用分类器模型预测每个点伪造的概率、即每个轨迹点数据的可信度最终倘若轨迹中可信度低于阈值p的轨迹点的比例超过阈值t则认为轨迹数据为伪造数据,反之则认为用户上传的轨迹数据为真实数据。基准数据计算:假设对于一个位于位置l0的基准数据,位置l0点中某一个wifi信号w的rss值为r0,同时在以位置l0点为圆心、半径为r的圆形区域内,存在n0份其它的基准数据也观测到了w的rss值为r0。而这个圆形区域中共有n个基准数据点中包含了w的rss值,第i个点与位置l0的距离为di。对于某个信号强度观测值rssk(rssk与r0不相等),n个数据点里有nk个点的观测值为该值。设待计算基准数据本身的权重为w,其它基准数据的总权重为1-w,其中每个基准数据的局部权重为与待计算数据距离的倒数。那么,对于在位置l0观测到w的各个rss值的概率可以由如下公式计算得到:对于基准数据集里所有的基准数据,其中每一个基准数据中的每一个wifi信号,我们都按照上述步骤计算各个基准数据点中包含的每个wifi信号的rss值概率分布。训练数据特征计算:对于一份采集自位置l0的wifi指纹(r1,r2,...,rn),选取距离l0最近的k份基准数据用于特征计算,设其中第j个基准数据的位置为lj,并用distance(li,lj)表示位置li到位置lj的距离。则特征向量的具体结构如下所示:feature=(rpd1,rpd2,…,rpdn)rpdi=(ri,pdii,pdi2,…,pdik)pdij=(p(rssi=ri|location=lj),distance(l0,lj))模型训练:使用xgboost进行定位数据的训练与预测,其中输入为上文提到的特征向量,输出为数据的可信程度、取值范围[0,1]。轨迹伪造:使用真实的包含wifi和gps数据的轨迹来生成伪造轨迹。生成伪造轨迹的方法为,对于真实轨迹中每一个点的经纬度数据,为其在x轴和y轴上分别添加一个取值范围在[-1,1]的随机偏移,单位为米;对于每一个wifi指纹数据,为每个rss值添加一个随机取自集合{-1,0,1}的偏移。用户数据上传:用户在启动移动应用后,应用就会启动一个后台服务按一定时间间隔上传gps定位与扫描到的wifi指纹数据。当用户使用需要验证定位的功能时,服务器端会收集这一段时间的轨迹数据并汇总,用于后续的分析。轨迹分析:判断轨迹是否为虚构:通过比对用户上传的轨迹数据中的wifi信息与历史数据中这一区域的wifi信息,查看每一信号的bssid和ssid,如果历史数据中包含的wifi信号在用户此次上传的wifi指纹数据里的比例低于设定值、或是用户上传数据中没有出现在历史数据中的wifi信号的比例高于设定值,则认为用户因为没有实际前往该区域而虚构了不存在的wifi指纹。判断轨迹是否为重放:通过比对用户上传的轨迹数据与用户所有的历史数据,查看是否存在一条历史轨迹中每一个点的gps信息与对应的wifi信息与此次上传数据相同,来判断用户是否没有前往定位地点而是重放了一条历史轨迹数据。判断轨迹是否为伪造:将用户上传的轨迹中每一个点包含的gps数据与wifi数据基于基准数据计算出特征向量,输入到训练出的分类器模型,得到每一个点的可信程度。我们设置p为每个点的可信度阈值,t为每条轨迹的可信度阈值,那么设一条轨迹经过特征生成与分类,得到了一个概率集合ll=(p1,p2,…,pn)其中pi表示轨迹中第i个点数据的可信程度,那么仅当满足下面条件时我们才认为轨迹为真实数据。count(i|pi≥p)为统计整条轨迹中分类器输出的概率值pi大于阈值p的轨迹点的个数。一种基于wifi信息的移动应用中定位数据真伪辨别的系统,包括如下模块:基准数据计算模块,用于为所有基准数据计算rss概率分布;对于每一份待计算的基准数据,找出所有与待计算基准数据的定位坐标距离在设定范围内的其它基准数据;统计同一wifi信号在各基准数据中的rss值;根据与基准数据的距离结合权重计算不同rss值的概率。训练数据特征计算模块,对于每一份待计算特征的训练数据,找出所有与待计算训练数据的定位坐标距离在设定范围内的基准数据;统计基准数据中各wifi信号的rss值与待计算训练数据的rss值相同的概率;选取训练数据中每个wifi的rss值、训练数据定位与基准数据中位置的距离、每一基准数据中取训练数据中wifi的rss值的概率作为训练数据特征。分类器模型训练模块,随机挑选一半的真实wifi+gps轨迹数据进行伪造,伪造结果作为负样本;正负样本计算出的特征向量输入到xgboost中训练,得到分类器模型。用户数据上传与轨迹分析模块,用户在上传定位进行证明时,服务器收集这一定位以及发送证明请求之前上传的定位与wifi数据,组成待判别轨迹;分析待判别轨迹是否为伪造轨迹;比对数据库判断wifi指纹是否为虚构数据;比对数据库判断wifi指纹和gps经纬度是否为重放数据;计算出待判别轨迹中每个点基于基准数据的特征向量,使用分类器模型预测伪造的概率,最终综合各个点的结果判断轨迹是否为伪造数据。有益效果:相对于现有技术,本发明提供的移动应用中定位数据真伪辨别的方法和系统,具有如下优点:(1)无需服务提供方收集新的数据,大部分服务提供方都已经拥有完善的wifi指纹数据库,可以直接在此基础上实现本发明。(2)不需要引入额外的系统或是硬件设备,基于现有的智能手机和移动应用即可将本发明投入使用。(3)不需要保证用户上传数据的真实性,可以在包含可信数据的数据库的基础上检测用户上传的不完全可信的数据是否为伪造数据。附图说明图1是本发明提出方案的整体架构;图2是计算基准数据rss概率分布的示意图;图3是基于历史轨迹添加噪声伪造轨迹的示意图;图4是对单个轨迹点预测结果中正负样本可信度均值和中位数的柱状图。具体实施方式下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。本发明专注于解决lbs移动应用中用户进行位置欺骗的问题,用户可能通过使用xposed、frida等工具修改应用中定位数据的值,使得应用按照伪造的定位结果为用户提供服务。本发明的方法尝试基于大量的历史数据来推算一个区域中在各个地点可以接收到不同强度的wifi信号的概率,从而分辨用户上传的wifi信号强度是否经过了伪造,并进一步地比对用户的gps数据与wifi数据是否匹配,来判断用户上传的定位数据是否经过了伪造。不同于单纯的gps数据,用户很难通过公开的服务查询指定地点的wifi信息。即使使用重放并添加随机噪声的伪造方式,也由于很难有足够的数据来分析wifi信号在某一处的强度分布,导致伪造后的wifi指纹可能过多的数值属于低概率取值、甚至有一些数值越界不再属于合理的波动区间。基于wifi信息的移动应用中定位数据真伪辨别的方法,详细介绍如下:首先我们选取一部分可信的gps+wifi指纹的历史数据用于基准数据的计算,基准数据的作用是描述在某一个地点可以接收到每个wifi信号的不同rss值的概率,并用于后续为待预测的gps+wifi指纹数据计算特征向量。对于一份待计算的基准数据,我们收集与该数据的定位距离在一定范围内的其它历史数据,并统计它们的wifi信号强度的rss值,结合待计算数据中的rss值来计算wifi信号的rss值概率分布。由于用户的真实gps数据与wifi数据受到遮挡、设备抖动等因素的影响,本身就会存在噪声,所以我们认为一定距离内的gps数据可能实际中处于同一位置、或是某个rss值实际在那个位置是另一个值,因此处于一定范围内的历史数据点的wifi指纹可以看作能够进行交换。以图2为例,待计算数据中某一wifi信号的rss值为rss_0,同时在距离r范围以内有3份历史数据接收到的这一wifi信号rss值分别为rss_1、rss_2和rss_0,距离分别为d1、d2和d3。那么,我们假设待计算数据的位置为l0,并将图中这一wifi信号标记为w,则我们认为实际中在l0观测到的w的rss值也有概率会是rss_1或rss_2。考虑到距离越近时取值的可能性越高,我们取距离的倒数为权重,并设在l0本身有观测到的取值的概率为w,那么我们可以计算得到为所有的基准数据计算了概率分布后,开始为待预测的数据建立特征向量。考虑到rss值越高时波动的幅度其实越小,同时基准数据与待预测数据的距离影响着基准数据对待预测数据的参考价值,我们选择仅分析rss值最大的m个wifi信号以及距离最近的k份基准数据,并保留待预测数据中的rss值以及每一份使用概率值的基准数据与待预测数据的距离用于构建特征向量。假设待预测数据的位置为l0、wifi指纹是(r1,r2,...,rn),而最终们选取了距离l0最近的k份基准数据用于特征计算,其中第j个基准数据的位置为lj,并用distance(li,lj)表示位置li到位置lj的距离。则特征向量的具体结构如下所示:feature=(rpd1,rpd2,…,rpdn)rpdi=(ri,pdii,pdi2,…,pdik)pdij=(p(rssi=ri|location=lj),distance(l0,lj))选取一批与计算基准数据所使用数据不同的历史数据,并随机挑选其中的一部分用于生成伪造数据。由于wifi指纹的地域性和对位置变化的敏感性,攻击者唯一的伪造方法就是使用真实的历史数据并在此基础上添加一些随机的噪声来避免与历史数据完全重合,我们也使用同样的方法伪造出一批数据作为负样本。对于每一份训练数据,使用上文的方法基于基准数据计算出特征向量,并输入xgboost训练,最终得到一个分类器模型,可以预测一个特征向量来自真实定位数据的概率。当用户启动应用时,一个后台服务会被同时启动,它将按一定时间间隔上传gps定位与扫描到的wifi指纹数据。当用户在之后某一时刻使用某些需要验证定位的功能时,服务器端会收集这一段时间的轨迹数据并汇总,用于后续的分析。在服务器端,对于汇总后的轨迹中的每一份数据,我们首先会判断这些数据是否为虚构数据或是重放数据。攻击者可能没有发现wifi数据的上传、或是没有真实的wifi指纹数据用于构造伪造数据,此时上传数据中的wifi信号数据的bssid和ssid等标识会与gps数据不匹配,我们可以直接判定用户作弊。攻击者也有可能只是单纯的重放了真实数据而没有添加噪声,因为无论是gps数据还是wifi的rss值都会因为非常多的随机不可控因素产生数值上的抖动,所以出现两条gps数据和wifi指纹数据完全一模一样的概率是非常低的,如果我们发现存在一条与用户上传数据完全重合的轨迹,我们也可以直接判定用户伪造了自己的定位数据。如果上面两步中没有发现用户数据的异常,我们就按上文的方法寻找同一区域的基准数据并计算出特征向量,输入训练好的分类器模型,得到每一份数据属于真实数据的概率。然后我们分别以p和t作为单份数据的阈值和整条轨迹的阈值,认为当xgboost输出的概率大于等于p时数据为真实数据,同时整条轨迹中真实数据的比例超过t时,用户轨迹为真实轨迹,即本发明提供的移动应用中定位数据真伪辨别的系统和方法的实施方式一样,不再赘述。实验结果:为了能够证明本发明的效果,我们在真实采集的数据集上进行了实验。实验数据采集自江苏省南京市栖霞区的仙林金鹰a区,采集者手持设备围绕a区建筑循环移动,设备每隔两秒记录一次最新的gps数据和wifi指纹数据,最终共采集了4826份gps+wifi的数据记录。实验基于leaveoneout的策略进行,即每一次抽取一条轨迹作为待预测数据,并将剩余数据切分分别作为基准数据和训练数据,训练数据中随机抽取一半数据按前文的方法生成伪造数据,共同构成训练集用于训练分类器模型。我们同样的对待预测轨迹按上文方法生成负样本,使用训练出的分类器分别对正负样本基于基准数据算出的特征向量进行预测,然后根据p和t的取值确定轨迹的预测结果。表1展示了实验中一些变量的符号和含义:表1表2展示了r=3、n=10、k=3、m=7、p=0.5、t=0.5时轨迹的预测效果:表2指标数值准确率0.963265306122449精确率0.9719953325554259召回率0.9552752293577982其中,我们记预测数据中正样本被分类正确的个数为tp、被分类错误的个数为fp,负样本被分类正确的个数为tn、被分类错误的个数为fn。那么,表2中的指标分别可以由如下计算公式得到:其中,p=0.91、t=0.25时有最高的准确率98.4%。另外,图4展示了对于单个点数据,xgboost分类器对正样本和负样本预测的输出概率的均值和中位数。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1