一种语音标注数据生成方法及装置、语音识别系统与流程
1.本发明涉及语音识别领域,尤其涉及一种语音标注数据生成方法及装置、语音识别系统。
背景技术:
2.近年来,深度学习逐渐成为人工智能领域的研究热点和主流发展方向,作为人工智能领域的一个重要分支,语音识别逐步成为国内外重要的研究方向,使用深度学习技术应用到语音识别领域更是时下的研究热点。作为人工智能和深度学习应用的一个重要方向,语音识别成为一个具有广阔前景的新兴高技术产业。
3.但是目前能在工业领域落地的语音识别模型都需要庞大的,高标注质量的语音数据进行训练,海量的标注数据依靠的是庞大的人工标注团队。标注工作量大,标注成本高已经成为一个需要迫切解决的问题。
技术实现要素:
4.为解决上述问题,本发明实施例公开了一种语音标注数据生成方法及装置、语音识别系统,通过识别出每个文本信息的开始时间节点与结束时间节点,在视频中截取对应的音频片段,将音频片段与文本信息对应匹配得到语音标注数据,实现了语音标注数据的自动生成,且生成的语音标注数据准确度高。
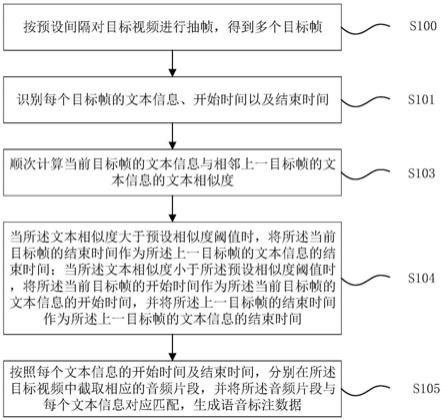
5.为达到上述目的,一种语音标注数据生成方法,包括:按预设间隔对目标视频进行抽帧,得到多个目标帧;识别每个目标帧的文本信息、开始时间以及结束时间;顺次计算当前目标帧的文本信息与相邻上一目标帧的文本信息的文本相似度;当所述文本相似度大于预设相似度阈值时,将所述当前目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;当所述文本相似度小于所述预设相似度阈值时,将所述当前目标帧的开始时间作为所述当前目标帧的文本信息的开始时间,并将所述上一目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;按照每个文本信息的开始时间及结束时间,分别在所述目标视频中截取相应的音频片段,并将所述音频片段与对应文本信息相匹配,生成语音标注数据。
6.进一步可选的,所述按预设间隔对目标视频进行抽帧,得到多个目标帧,包括:按预设间隔对目标视频进行抽帧,得到初始帧;识别目标视频中的片头时间段以及片尾时间段;删除所述初始帧中片头时间段内的视频帧以及片尾时间段内的视频帧,得到正片时间段对应的所述目标帧。
7.进一步可选的,所述在所述目标视频中截取相应的音频片段,包括:将所述目标视频转换成目标音频;在所述目标音频中截取相应的音频片段。
8.进一步可选的,所述识别每个目标帧的文本信息、开始时间以及结束时间之后,包括:将所述每个目标帧的文本信息、开始时间以及结束时间记录在字典文件中。
9.进一步可选的,所述识别每个目标帧的文本信息包括:通过ocr文字识别方法提取
所述每个目标帧的文本信息。
10.另一方面,本发明还提供了一种语音标注数据生成装置,包括:抽帧模块,用于按预设间隔对目标视频进行抽帧,得到多个目标帧;识别模块,用于识别每个目标帧的文本信息、开始时间以及结束时间;文本相似度计算模块,用于顺次计算当前目标帧的文本信息与相邻上一目标帧的文本信息的文本相似度;文本信息时间确定模块,用于当所述文本相似度大于预设相似度阈值时,将所述当前目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;当所述文本相似度小于所述预设相似度阈值时,将所述当前目标帧的开始时间作为所述当前目标帧的文本信息的开始时间,并将所述上一目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;音频截取模块,用于按照每个文本信息的开始时间及结束时间,分别在所述目标视频中截取相应的音频片段,并将所述音频片段与对应文本信息相匹配,生成语音标注数据。
11.进一步可选的,所述抽帧模块包括:初始帧获取单元,用于按预设间隔对目标视频进行抽帧,得到初始帧;片头片尾识别单元,用于识别目标视频中的片头时间段以及片尾时间段;目标帧获取单元,用于删除所述初始帧中片头时间段内的视频帧以及片尾时间段内的视频帧,得到正片时间段对应的所述目标帧。
12.进一步可选的,所述音频截取模块包括:转换单元,用于将所述目标视频转换成目标音频;音频截取单元,用于在所述目标音频中截取相应的音频片段。
13.进一步可选的,该装置还包括:记录模块,用于将所述每个目标帧的文本信息、开始时间以及结束时间记录在字典文件中。
14.另一方面,本发明还提供了一种语音识别系统,包括利用上述的语音标注数据生成方法生成的语音标注数据的训练样本集。
15.上述技术方案有如下有益效果:识别视频中的文本信息,并使用文本相似度算法对文本信息进行阈值分割,阈值作为文本信息改变的依据,并根据文本信息的开始时间以及结束时间对目标视频进行对应音频截取,以获得音频片段与对应文本信息相匹配后的语音标注数据,在保证语音数据准确度的基础上减少了人工标注工作量,提高了语音标注数据生成的效率。
附图说明
16.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
17.图1是本发明实施例提供的一种语音标注数据生成方法流程图;
18.图2是本发明另一种实施例提供的语音标注数据生成方法流程图;
19.图3是本发明实施例提供的语音标注数据生成装置结构框图;
20.图4是本发明实施例提供的采用语音标注数据生成方法生成的语音的标注数据示意图。
21.附图标记:100
‑
抽帧模块200
‑
识别模块300
‑
文本相似度计算模块400
‑
文本信息时间确定模块500
‑
音频截取模块
具体实施方式
22.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
23.现有技术中生成语音标注数据均是采用人工标注的方法,但是人工标注的方法工作量大,效率低且标注成本高。
24.图1为本发明实施例提供的语音标注数据生成方法的流程图,为解决上述问题,本发明实施例提供了一种语音标注数据生成方法,包括:
25.s100、按预设间隔对目标视频进行抽帧,得到多个目标帧;
26.在目标视频中按预设间隔抽取多个目标帧;其中,预设间隔可根据具体需求进行调整。在一个可选的实施方式中,也可将目标视频中的所有帧都作为目标帧。
27.s101、识别每个目标帧的文本信息、开始时间以及结束时间;
28.对每个目标帧的文本信息进行识别(本实施例中,文本信息指视频字幕文本),同时识别出每个目标帧的开始时间以及结束时间,用于后续确定每个文本信息的开始时间与结束时间。
29.s103、顺次计算当前目标帧的文本信息与相邻上一目标帧的文本信息的文本相似度;
30.将一个目标帧的信息记录完成后,将当前目标帧的文本信息与相邻的上一目标帧的文本信息进行相似度比较,得到一个文本相似度。可选的,文本相似度为一个数值。
31.s104、当所述文本相似度大于预设相似度阈值时,将所述当前目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;当所述文本相似度小于所述预设相似度阈值时,将所述当前目标帧的开始时间作为所述当前目标帧的文本信息的开始时间,并将所述上一目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;
32.若文本相似度大于预设相似度阈值,则判定当前目标帧的文本信息与上一目标帧的文本信息为同一个文本信息,将当前帧的结束时间记为上一目标帧的文本信息的结束时间。可选的,该当前帧的结束时间并不一定是上一目标帧的文本信息的最终结束时间,后续可能更新为下一帧的结束时间。若文本相似度小于预设相似度阈值,则判定当前目标帧的文本信息与上一目标帧的文本信息并非同一个文本信息,将当前目标帧的开始时间记为当前目标帧的文本信息的开始时间。此处的当前目标帧的开始时间已为当前目标帧的文本信息最终确定的开始时间;同时,将上一目标帧的结束时间记为其对应的文本信息的结束时间,此处的结束时间已为上一个文本信息最终确定的结束时间,不再更新。
33.现以一个具体实例对完整的文本信息开始时间、结束时间的确定过程进行说明。
34.参见图4,在当前目标帧中提取到“在第一弹下载的视频在哪里找呢”这一文本信息,且这一文本信息与上一目标帧的文本信息的文本相似度小于预设相似度阈值,即将当前目标帧(第一目标帧)的开始时间记为该文本信息的开始时间,将当前目标帧的结束时间记为该文本信息的结束时为“在第一弹下载的视频在哪里找呢”,此时计算第二目标帧对应的文本信息“在第一弹下载的视频在哪里找呢”与第一目标帧对应的文本信息“在第一弹下载的视频在哪里找呢”的文本相似度,得到的文本相似度大于预设相似度阈值,即判定第二
目标帧对应的文本信息与第一目标帧的文本信息为同一文本信息,进而,将第二目标帧的结束时间记为“在第一弹下载的视频在哪里找呢”这一文本信息的结束时间。继续对目标视频进行抽帧,得到第二目标帧的下一目标帧(第三目标帧),识别出第三目标帧的文本信息“打开第一弹点击我”,计算第三目标帧的文本信息与第二目标帧的文本信息的文本相似度,得到的文本相似度小于预设相似度阈值,判定第三目标帧的文本信息与第二目标帧的文本信息并非同一文本信息,不再更新“在第一弹下载的视频在哪里找呢”的结束时间。那么“在第一弹下载的视频在哪里找呢”这一文本信息的开始时间即为第一目标帧的开始时间,结束时间即为第二目标帧的结束时间。
35.s105、按照每个文本信息的开始时间及结束时间,分别在所述目标视频中截取相应的音频片段,并将所述音频片段与对应文本信息相匹配,生成语音标注数据。
36.采用步骤s104的方法确定每个文本信息的开始时间与结束时间之后,根据每个文本信息的开始时间与结束时间,在目标视频中截取相应的音频片段,最终输出每个文本信息以及与每个文本信息对应匹配的音频片段,即语音标注数据,参见图4。
37.由于获得了文本信息的具体时间节点,且根据文本信息的具体时间节点作为依据对音频文件进行截取,因此得到的语音标注数据中每个文本信息与对应的语音片段对齐的精准度高,另外上述方法实现了语音标注数据的自动生成,减少了人工标注的工作量,提高了语音标注数据的生成效率。
38.如图2所示,作为一种可能的实现方式,所述按预设间隔对目标视频进行抽帧,得到多个目标帧,包括:
39.s1001、按预设间隔对目标视频进行抽帧,得到初始帧;s1002、识别目标视频中的片头时间段以及片尾时间段;s1003、删除所述初始帧中片头时间段内的视频帧以及片尾时间段内的视频帧,得到正片时间段对应的所述目标帧。
40.为去除冗余数据,加快语音标注数据的生成速度,提高语音标注数据的生成质量,需要去除存在于片头片尾的视频帧。为达到上述目的,需要在目标视频中进行冗余数据分析,获得片头时间节点以及片尾时间节点,将存在于片头时间段内的视频帧与存在于片尾时间段内的视频帧删除,不使其进行下一步的文本信息识别操作。删除片头时间段、片尾时间段内的视频帧后得到的目标帧用于进行下一步的文本信息识别操作。这样识别出的文本信息信息量更大,更有实用价值,因此提升了语音标注数据的有效性;同时,删除了冗余的视频帧,减少了数据处理量,提高了语音标注数据的生成效率。
41.作为一种可选的实施方式,所述在所述目标视频中截取相应的音频片段,包括:将所述目标视频转换成目标音频;在所述目标音频中截取相应的音频片段。
42.为实现在目标视频中截取音频片段,本实施例首先将目标视频进行视频到音频的转换。作为一种优选的实施方式,本实施例采用python音视频处理工具包ffmpeg将目标视频转换成目标音频。进一步的,在目标音频中根据每个文本信息的开始时间以及结束时间截取相应的音频片段。
43.作为一种可选的实施方式,所述识别每个目标帧的文本信息、开始时间以及结束时间之后,包括:s102、将所述每个目标帧的文本信息、开始时间以及结束时间记录在字典文件中。
44.为方便实现音频切割,在识别到目标帧的文本信息、开始时间以及结束时间后,可
将这些信息记录在字典文件中,便于后续对信息进行更新。例如,在字典文件中及时更新最新的文本信息结束时间以及删除非文本信息结束时间的目标帧的结束时间。可根据字典文件中记载的文本信息,文本信息开始时间以及文本信息结束时间对目标视频进行音频片段截取操作。
45.作为一种可选的实施方式,所述识别每个目标帧的文本信息包括:通过ocr文字识别方法提取所述每个目标帧的文本信息。
46.如图3所示,另一方面,本发明还提供了一种语音标注数据生成装置,包括:
47.抽帧模块100,用于按预设间隔对目标视频进行抽帧,得到多个目标帧;
48.在目标视频中按预设间隔抽取多个目标帧;其中,预设间隔可根据具体需求进行调整。在一个可选的实施方式中,也可将目标视频中的所有帧都作为目标帧。
49.识别模块200,用于识别每个目标帧的文本信息、开始时间以及结束时间;
50.对每个目标帧的文本信息进行识别(本实施例中,文本信息指字幕文本),同时识别出每个目标帧的开始时间以及结束时间,用于后续确定每个文本信息的开始时间与结束时间。
51.文本相似度计算模块300,用于顺次计算当前目标帧的文本信息与相邻上一目标帧的文本信息的文本相似度;
52.将一个目标帧的信息记录完成后,将当前目标帧的文本信息与相邻的上一目标帧的文本信息进行相似度比较,得到一个文本相似度。可选的,文本相似度为一个数值。
53.文本信息时间确定模块400,用于当所述文本相似度大于预设相似度阈值时,将所述当前目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;当所述文本相似度小于所述预设相似度阈值时,将所述当前目标帧的开始时间作为所述当前目标帧的文本信息的开始时间,并将所述上一目标帧的结束时间作为所述上一目标帧的文本信息的结束时间;
54.若文本相似度大于预设相似度阈值,则判定当前目标帧的文本信息与上一目标帧的文本信息为同一个文本信息,将当前帧的结束时间记为上一目标帧的文本信息的结束时间。可选的,该当前帧的结束时间并不一定是上一目标帧的文本信息的最终结束时间,后续可能更新为下一帧的结束时间。若文本相似度小于预设相似度阈值,则判定当前目标帧的文本信息与上一目标帧的文本信息并非同一个文本信息,将当前目标帧的开始时间记为当前目标帧的文本信息的开始时间。此处的当前目标帧的开始时间已为当前目标帧的文本信息最终确定的开始时间;同时,将上一目标帧的结束时间记为其对应的文本信息的结束时间,此处的结束时间已为上一个文本信息最终确定的结束时间,不再更新。
55.现以一个具体实例对完整的文本信息开始时间、结束时间的确定过程进行说明。
56.参见图4,在当前目标帧中提取到“在第一弹下载的视频在哪里找呢”这一文本信息,且这一文本信息与上一目标帧的文本信息的文本相似度小于预设相似度阈值,即将当前目标帧(第一目标帧)的开始时间记为该文本信息的开始时间,将当前目标帧的结束时间记为该文本信息的结束时为“在第一弹下载的视频在哪里找呢”,此时计算第二目标帧对应的文本信息“在第一弹下载的视频在哪里找呢”与第一目标帧对应的文本信息“在第一弹下载的视频在哪里找呢”的文本相似度,得到的文本相似度大于预设相似度阈值,即判定第二目标帧对应的文本信息与第一目标帧的文本信息为同一文本信息,进而,将第二目标帧的
结束时间记为“在第一弹下载的视频在哪里找呢”这一文本信息的结束时间。继续对目标视频进行抽帧,得到第二目标帧的下一目标帧(第三目标帧),识别出第三目标帧的文本信息“打开第一弹点击我”,计算第三目标帧的文本信息与第二目标帧的文本信息的文本相似度,得到的文本相似度小于预设相似度阈值,判定第三目标帧的文本信息与第二目标帧的文本信息并非同一文本信息,不再更新“在第一弹下载的视频在哪里找呢”的结束时间。那么“在第一弹下载的视频在哪里找呢”这一文本信息的开始时间即为第一目标帧的开始时间,结束时间即为第二目标帧的结束时间。
57.音频截取模块500,用于按照每个文本信息的开始时间及结束时间,分别在所述目标视频中截取相应的音频片段,并将所述音频片段与对应文本信息相匹配,生成语音标注数据。
58.确定每个文本信息的开始时间与结束时间之后,根据每个文本信息的开始时间与结束时间,在目标视频中截取相应的音频片段,最终输出每个文本信息以及与每个文本信息对应匹配的音频片段,即语音标注数据,参见图4。
59.由于获得了文本信息的具体时间节点,且根据文本信息的具体时间节点作为依据对音频文件进行截取,因此得到的语音标注数据中每个文本信息与对应的语音片段对齐的精准度高,另外上述方法实现了语音标注数据的自动生成,减少了人工标注的工作量,提高了语音标注数据的生成效率。
60.作为一种可选的实施方式,所述抽帧模块100包括:初始帧获取单元,用于按预设间隔对目标视频进行抽帧,得到初始帧;片头片尾识别单元,用于识别目标视频中的片头时间段以及片尾时间段;目标帧获取单元,用于将所述初始帧中片头时间段内的视频帧以及片尾时间段内的视频帧删除,得到正片时间段对应的所述目标帧。
61.为去除冗余数据,加快语音标注数据的生成速度,提高语音标注数据的生成质量,需要去除存在于片头片尾的视频帧。为达到上述目的,需要在目标视频中进行冗余数据分析,获得片头时间节点以及片尾时间节点,将存在于片头时间段内的视频帧与存在于片尾时间段内的视频帧删除,不使其进行下一步的文本信息识别操作。删除片头时间段、片尾时间段内的视频帧后得到的目标帧用于进行下一步的文本信息识别操作。这样识别出的文本信息信息量更大,更有实用价值,因此提升了语音标注数据的有效性;同时,删除了冗余的视频帧,减少了数据处理量,提高了语音标注数据的生成效率。
62.作为一种可选的实施方式,所述音频截取模块500包括:转换单元,用于将所述目标视频转换成目标音频;音频截取单元,用于在所述目标音频中截取相应的音频片段。
63.为实现在目标视频中截取音频片段,本实施例首先将目标视频进行视频到音频的转换。作为一种优选的实施方式,本实施例采用python音视频处理工具包ffmpeg将目标视频转换成目标音频。进一步的,在目标音频中根据每个文本信息的开始时间以及结束时间截取相应的音频片段。
64.作为一种可选的实施方式,该装置还包括:记录模块600,用于将所述每个目标帧的文本信息、开始时间以及结束时间记录在字典文件中。
65.为方便实现音频切割,在识别到目标帧的文本信息、开始时间以及结束时间后,可将这些信息记录在字典文件中,便于后续对信息进行更新。例如,在字典文件中及时更新最新的文本信息结束时间以及删除非文本信息结束时间的目标帧的结束时间。可根据字典文
件中记载的文本信息,文本信息开始时间以及文本信息结束时间对目标视频进行音频片段截取操作。
66.另一方面,本发明还提供了一种语音识别系统,包括利用上述的语音标注数据生成方法生成的语音标注数据的训练样本集。
67.语音识别系统中的语音识别模型使用上述方法生成的语音标注数据训练样本集进行悬训练而成,其识别准确度高。
68.上述技术方案有如下有益效果:识别视频中的文本信息,并使用文本相似度算法对文本信息进行阈值分割,阈值作为文本信息改变的依据,并根据文本信息的开始时间以及结束时间对目标视频进行对应音频截取,以获得音频片段与对应文本信息相匹配后的语音标注数据,在保证语音数据准确度的基础上减少了人工标注工作量,提高了语音标注数据生成的效率。
69.以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1