一种互联网流量的控制方法及系统与流程
本发明涉及互联网流量控制
技术领域:
,具体涉及一种互联网流量的控制方法及系统。
背景技术:
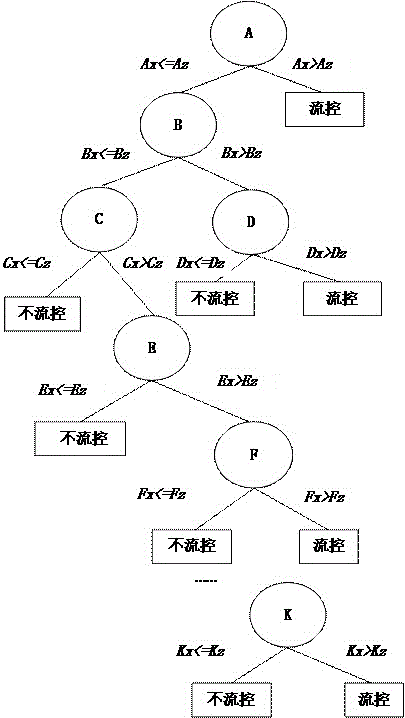
:互联网业务快速发展,网络业务越来越多,网络问题不断出现。运营商通过对链路快速扩容,能在一定程度上缓解链路承载提升用户体验,但无法保证网络内容的有效传播及健康传播,因此运营商需要清楚掌握网络流量内容,并对不合理网络流量进行链路流控和链路扩容,从而保障互联网产业健康发展。目前各运营商主要通过“基于业务流量占比定位异常流量技术”与“基于流向流量占比定位异常流量技术”来定位异常流量。“基于业务流量占比定位异常流量技术”和“基于流向流量占比定位异常流量技术”这两种方案,虽然能降低不合理流量达到一定的流控效果,但是该流控策略是针对各链路进行实施,在定位问题产生原因及下发流控策略过程中需要耗费大量的工作量和工作时间,且流控阈值是人工凭借经验或者探索制定,这种人工处理方式不能达到实时监控网络质量和实时下发流控策略的目的,同时缺乏数据支撑的科学性,所以这种流控策略相对来说低效率、低可靠、低产出。技术实现要素:有鉴于此,本发明提供一种互联网流量的控制方法及系统,以实现及时发现异常流量和快速定位,能够高效率、高可靠地有效控制流量,保障网络持续健康发展。为解决上述技术问题,本发明采用的技术方案是:一种互联网流量的控制方法,该方法包括:基于流控模型对超基准流量进行特征指标分析,判断其是否需要流控;对需要流控的特征指标制定流控策略,并实施该流控策略。优选地,流控模型为决策树模型。优选地,创建决策树模型的过程包括:获取样本数据,创建异常判定基准库;基于异常判定基准库的数据,构建流控决策树模型。优选地,基于异常判定基准库的数据,构建流控决策树模型的过程包括:确定异常判定基准库中各特征指标对决定是否流控的影响程度;基于特征指标对决定是否流控的影响程度构建决策树。优选地,各特征指标最终决定是否流控的影响程度通过其信息增益值表示。优选地,信息增益值的计算过程包括:获取样本数据中每个指标的多次取值,并顺序排列;任取其中两个连续的域值,将其平均值作为临时分割点进行分组,获取若干种分组模式;分别计算每种分组模式下统计的信息熵值;比较同一监测值指标不同分组模式下各信息熵值的大小,取出其中最大信息熵值及其所对应的分组模式。优选地,基于流控模型对超基准流量进行特征指标分析,判断其是否需要流控的过程包括:获取异常流量中的特征指标集;将特征指标集中各特征指标值与决策树模型中各节点进行比较。优选地,对需要流控的特征指标制定流控策略的过程包括:提取需要流控的指标及其指标值,确定该需要流控的流量产生的网络出口和链路组,并提取上一统计周期内对应该指标及指标值;设定流控阈值。优选地,流控阈值的计算公式为:一种互联网流量的控制系统,该系统包括:一异常定位模块,基于流控模型对超基准流量进行特征指标分析,判断其是否需要流控;以及一智能流控模块,对需要流控的特征指标制定流控策略,并实施该流控策略。本发明具有的优点和积极效果是:本发明通过预先创建的流控模型对超基准的流量进行特征指标分析,快速定位流量异常原因,并且针对异常发生的链路组进行下发总策略,以达到流量控制的效果。附图说明图1是本发明的决策树模型的结构示意图;图2是本发明的互联网流量的控制系统的结构示意图。具体实施方式为了更好的理解本发明,下面结合具体实施例和附图对本发明进行进一步的描述。本发明提供一种互联网流量的控制方法,该方法包括:基于流控模型对超基准流量进行特征指标分析,判断其是否需要流控;对需要流控的特征指标制定流控策略,并实施该流控策略。对于超基准的流量,现有技术中一般是需要提取超基准的流量详细明细进行一一分析,从而定位异常流量产生原因;例如“基于业务流量占比定位异常流量技术”中,对于超基准业务流量(考核指标值介于规定范围之外)进行大小类业务明细提取,并定位异常流量产生原因,根据产生异常流量的不同原因制定相关业务流控策略;“基于流向流量占比定位异常流量技术”中,对于超基准流向流量(考核指标值介于集团规定范围之外)进行流向明细话单提取,并定位异常流量产生原因,根据产生异常流量的不同原因指定相关流向流控策略;上述两种方案在定位异常流量产生原因及下发流控策略过程中需要耗费大量的工作量和工作时间。本发明通过预先创建的流控模型对超基准的流量进行特征指标分析,快速定位流量异常原因,并且针对异常发生的链路组进行下发总策略,以达到流量控制的效果。进一步地,本发明中流控模型为决策树模型,该决策树模型基于异常判定基准库进行创建;创建决策树模型的过程包括:获取样本数据,创建异常判定基准库;基于异常判定基准库的数据,构建流控决策树模型。获取以往流量超基准时的特征指标值及流控处理方式,并提取能够体现流量超基准现象特征的指标作为特征指标,特征指标构成集合database={valuea,valueb,valuec,valued,valuee…},考核指标超基准值时集合database中各特征指标数据值,及相应案例是否进行流控的处理决定,构成异常判定基准库,借助信息增益算法计算各特征指标的信息增益值,从而构建流控决策树模型。具体地,异常判定基准库详细数据格式如表1所示:表1异常判定基准库详细数据时间database中指标d—adatabase中指标d—bdatabase中指标d—cdatabase中指标d—ddatabase中指标d—edatabase中指标d—fdatabase中其他指标流控与否y/ntime1a1b1c1d1e1f1…ytime2a2b2c2d2e2f2…y….……………………timezazbzczdzezfz…n(注:异常判定基准库仅保留最近的z条记录(z大于1000),以时间字段为判定依据)进一步地,基于异常判定基准库的数据,借助决策树算法,构建流控决策树模型的过程包括:确定异常判定基准库中各特征指标对决定是否流控的影响程度;基于特征指标对决定是否流控的影响程度构建决策树。其中,各特征指标最终决定是否流控的影响程度通过其信息增益值表示。具体地,首先判断异常判定基准库中指标集合database中各特征指标对决定是否流控的影响程度,即计算指标集合database中各特征指标的信息增益,从而构建决策树。信息增益是针对每个特征指标而言的,就是看一个特征指标,有它和没它的时候“流控与否”指标的信息量各是多少,两者的差值就是这个特征指标给“流控与否”指标带来的信息量,即增益。因此,某个特征指标的信息增益=整个异常判定基准库的信息熵-某个特征指标的信息熵。信息熵是确定异常判定基准库中各特征指标取值的混乱复杂程度。通过对各特征指标信息熵计算结果的大小来判定该指标在样本数据中的复杂程度,信息熵结果取值越大,其指标取值混乱程度越高,取值越分散,相反信息熵结算结果值越小,其取值混乱程度越低,取值越集中。信息熵计算公式如下:其中|y|为最后结果分类种类,本方案中整个异常判定基准库的信息熵的计算中,y的取值则为2(最后结果包含流控,不流控两种处理方案),pk为这个决策项对应该结果产生的概率(取值介于0到1之间,该决策项全部pk之和=1)。信息增益计算公式如下:gain(a)=ent–ent(a)其中,gain(a)表示a特征指标的信息增益,ent表示整个异常判定基准库的信息熵,ent(a)表示a特征指标的信息熵。gain(a)的值越大,a特征指标的信息增益越大,表示a特征指标对是否需要流控的影响越大。根据此算法,依次对指标集合database中的特征指标的信息增益进行计算。进一步地,信息增益值的计算过程包括:获取样本数据中每个指标的多次取值,并顺序排列;任取其中两个连续的域值,将其平均值作为临时分割点进行分组,获取若干种分组模式;分别计算每种分组模式下统计的信息熵值;比较同一监测值指标不同分组模式下各信息熵值的大小,取出其中最大信息熵值及其所对应的分组模式。具体地,由于采集的数据中每个字段的取值都是连续型变量,无法对其取值进行聚类分组,因此我们对本次采集数据中第一个指标字段a的多次取值按照由小到大的顺序进行排序{a1,a2,a3…az},任取其中两个连续的域值ap和a(p+1)(其中0<p<z-1),将其平均值作为临时分割点,对于包含z个域的集合我们会有(z-1)种不同的分组方式,分别计算每种分组模式下统计的信息熵值e1,e2,e3…ez,比较同一监测值指标不同分组模式下各信息熵值的大小,取出其中最大值en及其所对应的分组模式,按照上述方式对特征指标集中每个特征指标都进行此类操作,定位各特征指标中信息熵最大的分组模式,同时计算得到集合database中各特征指标a,b,c,d,e,f,g…k(假设集合database中包含k个质量指标)分别对应的信息熵值z1,z2,z3,z4,z5,z6…zk(由左到右依次递减,z1>z2>z3=z4>z5>z6>…>zk),其对应的分裂点分别为az,bz,cz,dz,ez,fz,gz…kz。进一步地,通过上述过程中计算得到的各特征指标的信息增益值的大小构建决策树模型。具体地,上述过程中信息熵和信息增益的计算公式,可以确定了各特征指标的信息增益值的大小,基于特征指标对最终决定是否流控的影响程度构建决策树,即:取信息增益最大的特征指标a作为决策树的数根,并依次排列构建决策树,具体如图1所示。本发明通过对日常考核指标进行监测,获取超基准流量,然后通过流控模型对超基准流量进行特征指标分析,从而判断超基准流量是否需要流控;具体地,本发明通过dpi探针采集报文,然后合成符合统一规范的xdr话单(即用户上网记录,是基于互联网全量数据进行处理后生成的信令过程和业务传输过程的会话级详细记录,包含了用户所有的上网信息,包括dpi识别到的大小类业务标签、用户访问的域名信息和资源服务器归属ip、以及上下行流量数据等);然后根据资源所在服务器及业务分类的不同分别为其打上业务和流向的不同标签,并根据流向、链路组、网络出口的不同,对各考核指标进行日常监测,如果有超基准流量情况,进行告警。进一步地,对于超基准流量,获取超基准流量中的特征指标集;将特征指标集中各特征指标值与流控模型中各节点进行比较。具体地,如果检测到某考核指标x超基准流量,则将指标x及其特征指标集x={ax,bx,cx,dx,ex,fx…kx}取出,放入流控模型中进行特征分析,具体为将特征指标集x={ax,bx,cx,dx,ex,fx…kx}的各节点与流控模型的各节点进行比较;在对比的过程中,如果对比的结果指向其他指标的根节点,则还需要考虑该根节点是否需要流控,如果对比的结果指向了流控或者不流控的确定结果,则结束该指标的对比。下面以特征指标集x={ax,bx,cx,dx,ex,fx…kx}为例,对对比的过程进行详细说明。step1:提取特征字段a对应采集数据集合x中对应指标计算结果ax,比较ax与决策树树根az的大小:1若特征字段a的增量比ax>az,则对于本次超基准流量进行流控,并将异常定位结果告知智能流控模块,同时将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段a的增量比ax<=az,则不能轻易判断出本次超基准流量是否需要流控,需结合其他特征指标进行下一特征指标的比较操作。step2:提取特征字段b对应采集数据集合x中对应指标计算结果bx,比较bx与决策树节点bz的大小:1若特征字段b的增量比bx<=bz,则不能轻易判断出本次超基准流量是否需要流控,需结合下一特征指标c的分裂点cz进行比较操作。2若特征字段b的增量比bx>bz,也不能轻易判断出本次超基准流量是否需要流控,需结合下一特征指标d的分裂点dz进行比较操作。step3-1:提取特征字段c对应采集数据集合x中对应指标计算结果cx,比较cx与决策树节点cz的大小:1若特征字段c的增量比cx<=cz,则对于本次超基准流量不进行流控,为此条记录添加不流控标签,并将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段c的增量比cx>cz,则不能轻易判断出本次超基准流量是否需要流控,需结合下一特征指标e的分裂点ez进行比较操作。step3-2:提取特征字段d对应采集数据集合x中对应指标计算结果dx,比较dx与决策树节点dz的大小:1若特征字段d的增量比dx<=dz,则对于本次超基准流量不进行流控,为此条记录添加不流控标签,并将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段d的增量比dx>dz,则对于本次超基准流量进行流控,并将异常定位结果告知智能流控模块,同时将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。step4:提取特征字段e对应采集数据集合x中对应指标计算结果ex,比较ex与决策树节点ez的大小:1若特征字段e的增量比ex<=ez,则对于本次超基准流量不进行流控,为此条记录添加不流控标签,并将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段e的增量比ex>ez,则不能轻易判断出本次超基准流量是否需要流控,需结合下一特征指标f的分裂点fz进行比较操作。step5:提取特征字段f对应采集数据集合x中对应指标计算结果fx,比较fx与决策树节点fz的大小:1若特征字段f的增量比fx<=fz,则对于本次超基准流量不进行流控,为此条记录添加不流控标签,并将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段f的增量比fx>fz,则对于本次超基准流量进行流控,并将异常定位结果告知智能流控模块,同时将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。step6:如此往复循环如上操作,直至提取特征字段k对应采集数据集合x中对应指标计算结果kx,比较kx与决策树节点kz的大小:1若特征字段k的增量比kx<=kz,则对于本次超基准流量不进行流控,为此条记录添加不流控标签,并将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。2若特征字段k的增量比kx>kz,则对于本次超基准流量进行流控,并将异常定位结果告知智能流控模块,同时将该条记录和评估结果追加至异常判定基准库,对异常判定基准库进行迭代,以达到更新异常判定基准库的目的。至此,通过预先建立好的流控模型对超基准指标进行分析,确定本次超基准指标是否需要流控。进一步地,对于需要流控的指标制定流控策略,并进行实施,具体包括提取需要流控的指标及其指标值,确定该需要流控的流量产生的网络出口和链路组,并提取上一统计周期内对应该指标及指标值;设定流控阈值;根据已设定流量阈值针对该网络出口的该链路组下发流量控制策略。具体需要流控的指标例如为x={ax,bx,cx,dx,ex,fx..kx},其指标值为n,确定超基准流量产生的网络出口和链路组,并提取上一统计周期内对应该指标x及指标值n’;然后根据该指标的本周期的指标值以及上一周期的指标值设定流控阈值,具体,流控阈值的计算公式为:根据已设定流量阈值针对该网络出口的该链路组下发流量控制策略,通过智能流控手段抑制整个链路组的流量和流量的增长,该流控策略会根据该链路组中各链路的流量大小和流量的业务组成自动分配流控阈值给各个链路,并每半个小时更新一次各链路的策略,因此称之为智能流控,可在保证指标x达到考核指标要求的同时,节省了人工成本并保障了网络的安全性。进一步地,本发明提供一种互联网流量的控制系统,该系统包括:一异常定位模块,基于流控模型对超基准流量进行特征指标分析,判断其是否需要流控;以及一智能流控模块,对需要流控的特征指标制定流控策略,并实施该流控策略。在本发明的一个具体的实施例中,还包括一资源匹配模块以及一流量监测模块,具体如图2所示,通过统一dpi探针采集报文,并合成符合运营商统一规范的xdr话单(即用户上网记录),包含dpi识别到的大小类业务标签,用户访问的域名信息和资源服务器归属ip,以及上下行流量等数据。再将合成的xdr话单输送给资源匹配模块,通过与资源匹配模块匹配识别用户访问资源的归属信息。资源匹配模块在用户访问互联网某一资源时,可根据资源所在服务器及业务分类的不同分别为其打上业务和流向的不同标签。流量监测模块根据流向、链路组、网络出口的不同,对各考核指标进行日常监测,如果有超基准流量情况,进行告警,通知异常定位模块。异常定位模块对特征指标集合database中的指标进行计算,并将计算结果传输至决策数模型,进行是否流控的评估。如需流控,异常定位模块将异常和导致异常信息增益最大的指标及指标值告知智能流控模块,智能流控模块根据异常发生的链路组进行下发总策略,以达到流量控制的效果。以上对本发明的实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明范围所作的均等变化与改进等,均应仍归属于本专利涵盖范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1