助听器系统和方法与流程
助听器系统和方法
1.本技术是申请日为2019年10月10日、申请号为201980082480.1、发明名称为“助听器系统和方法”的发明专利申请的分案申请。
2.相关申请的交叉引用
3.本技术要求以下专利申请的优先权:2018年10月15日提交的美国临时专利申请第62/745,478号;2018年10月17日提交的美国临时专利申请第62/746,595号;2019年2月21日提交的美国临时专利申请第62/808,317号;和2019年6月5日提交的美国临时专利申请号62/857,773。所有前述申请在此全部引入作为参考。
技术领域
4.本公开总体上涉及用于捕获和处理来自用户的环境的图像和音频并使用从捕获的图像和音频导出的信息的设备和方法。
背景技术:
5.今天,技术进步使得可穿戴设备能够自动捕获图像和音频,并存储与捕获的图像和音频相关联的信息。在一项通常被称为“生活记录”的练习中,某些设备已经被用来数字记录一个人生活的方面和个人经历。一些个体记录他们的生活,这样他们就可以从过去的活动中获得瞬间,例如,社交活动、旅行等。生活记录在其他领域(如商业、健身和医疗保健以及社会研究)也可能有显著的好处。生活记录设备虽然对跟踪日常活动有用,但可以基于对捕获的图像和音频数据的分析,通过增强人在其环境中与反馈的交互的能力和其他高级功能来进行改进。
6.尽管用户可以用智能电话捕获图像和音频,并且一些智能电话应用可以处理捕获到的信息,但考虑到智能电话的尺寸和设计,智能电话可能不是用作生活记录装置的最佳平台。生活记录装置应该小而轻,以便于穿戴。此外,随着包括可穿戴装置在内的图像捕获设备的改进,可以提供附加功能来帮助用户在环境中和环境周围导航,识别他们遇到的人和对象,并向用户提供关于他们的环境和活动的反馈。因此,需要用于自动捕获和处理图像和音频以向装置用户提供有用信息的装置和方法,以及用于处理和利用由装置收集的信息的系统和方法。
技术实现要素:
7.与本公开一致的实施例提供了用于自动捕获和处理来自用户的环境的图像和音频的设备和方法,以及用于处理与用户的环境从用户的环境捕获的图像和音频相关的信息的系统和方法。
8.在一个实施例中,助听器系统可以选择性地放大从检测到的助听器系统用户的注视方向发出的声音。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机;至少一个麦克风,被配置为捕获来自用户的环境的声音;和至少一个处理器。处理器可以被编程为接收由照相机捕获的多个图像,接收代表由至少一个麦克风从用户的环境接收
的声音的音频信号,基于对多个图像中的至少一个图像的分析来确定用户的注视方向,引起对由至少一个麦克风从与用户的注视方向相关联的区域接收的至少一个音频信号的选择性调节,并且使得将至少一个经调节的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
9.在一个实施例中,一种方法可以选择性地放大从检测到的助听器系统用户的注视方向发出的声音。该方法可以包括接收由可穿戴照相机从用户的环境捕获的多个图像;接收代表由至少一个麦克风从用户的环境接收的声音的音频信号,基于对多个图像中的至少一个图像的分析来确定用户的注视方向,引起对由至少一个麦克风从与用户的注视方向相关联的区域接收的至少一个音频信号的选择性调节,使得将至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
10.在一个实施例中,助听器系统可以选择性地放大与被辨识的个体的语音相关联的音频信号。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机、被配置为从用户的环境捕获声音的至少一个麦克风以及至少一个处理器。处理器可以被编程为接收由照相机捕获的多个图像,在多个图像的至少一个中识别至少一个被辨识的个体的表示,接收代表由至少一个麦克风接收的声音的音频信号,引起对由至少一个麦克风从与至少一个被辨识的个体相关联的区域接收的至少一个音频信号的选择性调节,并且使得将至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
11.在一个实施例中,一种方法可以选择性地放大与被辨识的个体的语音相关联的音频信号。该方法可以包括接收由可穿戴照相机从用户的环境捕获的多个图像,在多个图像的至少一个中识别至少一个被辨识的个体的表示,接收代表由至少一个麦克风从用户的环境捕获的声音的音频信号,引引起对由至少一个麦克风从与至少一个被辨识的个体相关联的区域接收的至少一个音频信号的选择性调节,并且使得将至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
12.在一个实施例中,语音传输系统可以选择性地传输与被辨识的用户的语音相关联的音频信号。该系统可以包括至少一个麦克风和至少一个处理器,该麦克风被配置为捕获来自用户的环境的声音。处理器可以被编程为接收代表由至少一个麦克风捕获的声音的音频信号,基于对接收到的音频信号的分析,识别代表用户的被辨识的语音的一个或多个语音音频信号,使得向远程定位设备传输代表用户的被辨识的语音的一个或多个语音音频信号,并且阻止向远程定位设备传输不同于代表用户的被辨识的语音的一个或多个语音音频信号的至少一个背景噪声音频信号。
13.在一个实施例中,一种方法可以选择性地传输与被辨识的用户的语音相关联的音频信号。该方法可以包括:接收代表由至少一个麦克风从用户的环境捕获的声音的音频信号;基于对接收的音频信号的分析,识别代表用户的被辨识的语音的一个或多个语音音频信号;使得向远程定位设备传输代表用户的被辨识的语音的一个或多个语音音频信号;并且阻止向远程定位设备传输不同于代表用户的被辨识的语音的一个或多个语音音频信号的至少一个背景噪声音频信号。
14.在一个实施例中,助听器系统可以基于跟踪的嘴唇运动选择性地放大音频信号。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机、被配置为从用户的环境捕获声音的至少一个麦克风以及至少一个处理器。处理器可以被编程为接收由照相机
捕获的多个图像;在多个图像中的至少一个图像中识别至少一个个体的表示;基于对多个图像的分析,识别与个体的嘴相关联的至少一个嘴唇运动;接收代表由至少一个麦克风捕获的声音的音频信号;基于对由至少一个麦克风捕获的声音的分析,识别与第一语音相关联的至少第一音频信号和与不同于第一语音的第二语音相关联的至少第二音频信号;基于至少一个处理器确定第一音频信号与所识别的、与个体的嘴相关联的至少一个嘴唇运动相关联,引起对第一音频信号的选择性调节;并且使得选择性调节的第一音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
15.在一个实施例中,一种方法可以基于跟踪的嘴唇运动选择性地放大音频信号。该方法可以包括接收由可穿戴照相机从用户的环境捕获的多个图像;在多个图像中的至少一个图像中识别至少一个个体的表示;基于对多个图像的分析,识别与个体的嘴相关联的至少一个嘴唇运动;接收代表由至少一个麦克风从用户的环境捕获的声音的音频信号;基于对由至少一个麦克风捕获的声音的分析,识别与第一语音相关联的至少第一音频信号和与不同于第一语音的第二语音相关联的至少第二音频信号;基于至少一个处理器确定第一音频信号与所识别的、与个体的嘴相关联的至少一个嘴唇运动相关联,引起对第一音频信号的选择性调节;以及使得选择性调节的第一音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
16.在一个实施例中,用于放大音频信号的助听器系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机,以及被配置为从用户的环境捕获声音的至少一个麦克风。助听器系统还可以包括至少一个处理器,该处理器被编程为接收由照相机捕获的多个图像,并在多个图像中识别第一个体的表示和第二个体的表示。该至少一个处理器还可以被编程为从该至少一个麦克风接收与第一个体的语音相关联的第一音频信号,并且从该至少一个麦克风接收与第二个体的语音相关联的第二音频信号。该至少一个处理器还可以被编程为检测指示第一个体和第二个体之间的语音放大优先级的至少一个放大标准。至少一个处理器还可以被编程为当至少一个放大标准指示第一个体比第二个体具有语音放大优先级时,相对于第二音频信号选择性地放大第一音频信号,并且当至少一个放大标准指示第二个体比第一个体具有语音放大优先级时,相对于第一音频信号选择性地放大第二音频信号。该至少一个处理器还可以被编程为使得选择性放大的第一音频信号或第二音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
17.在一个实施例中,用于选择性地放大音频信号的计算机实施的方法可以包括接收由照相机从用户的环境捕获的多个图像,并且在多个图像中识别第一个体的表示和第二个体的表示。该方法还可以包括从至少一个麦克风接收与第一个体的语音相关联的第一音频信号,以及从至少一个麦克风接收与第二个体的语音相关联的第二音频信号。该方法还可以包括检测指示第一个体和第二个体之间的语音放大优先级的至少一个放大标准。该方法还可以包括当至少一个放大标准指示第一个体比第二个体具有语音放大优先级时,相对于第二音频信号选择性地放大第一音频信号,并且当至少一个放大标准指示第二个体比第一个体具有语音放大优先级时,相对于第一音频信号选择性地放大第二音频信号。该方法还可以包括使得选择性放大的第一音频信号或第二音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
18.在一个实施例中,非暂时性计算机可读介质存储指令,当由至少一个处理器执行
该指令时,该指令可以使得设备执行一种方法,该方法包括接收由照相机从用户的环境捕获的多个图像,并在多个图像中识别第一个体的表示和第二个体的表示。该方法还可以包括从至少一个麦克风接收与第一个体的语音相关联的第一音频信号,以及从至少一个麦克风接收与第二个体的语音相关联的第二音频信号。该方法还可以包括检测指示第一个体和第二个体之间的语音放大优先级的至少一个放大标准。该方法还可以包括当至少一个放大标准指示第一个体比第二个体具有语音放大优先级时,相对于第二音频信号选择性地放大第一音频信号,并且当至少一个放大标准指示第二个体比第一个体具有语音放大优先级时,相对于第一音频信号选择性地放大第二音频信号。该方法还可以包括使得选择性放大的第一音频信号或第二音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
19.在一个实施例中,用于选择性地放大音频信号的助听器系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机,以及被配置为从用户的环境捕获声音的至少一个麦克风。助听器系统还可以包括至少一个处理器,该处理器被编程为接收由照相机捕获的多个图像;在多个图像中识别一个或多个个体的表示;从至少一个麦克风接收与语音相关联的第一音频信号;基于对多个图像的分析,确定第一音频信号不与一个或多个个体中的任何一个个体的语音相关联;从至少一个麦克风接收与语音相关联的第二音频信号;基于对多个图像的分析,确定第二音频信号与一个或多个个体中的一个个体的语音相关联;引起第一音频信号的第一放大和第二音频信号的第二放大,其中第一放大在至少一个方面不同于第二放大;并且使得根据第一放大放大的第一音频信号和根据第二放大放大的第二音频信号中的至少一个传输到被配置为向用户的耳朵提供声音的听力接口设备。
20.在一个实施例中,用于选择性地放大音频信号的助听器系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机,以及被配置为从用户的环境捕获声音的至少一个麦克风。助听器系统还可以包括至少一个处理器,该处理器被编程为:接收由照相机捕获的第一多个图像;识别第一多个图像中的个体的表示;从至少一个麦克风接收代表语音的第一音频信号;基于对第一多个图像的分析,确定代表语音的第一音频信号与该个体相关联;相对于从至少一个麦克风接收的、代表来自个体以外的源的声音的其他音频信号,选择性地放大第一音频信号;接收由照相机捕获的第二多个图像;基于对第二多个图像的分析,确定该个体没有在第二多个图像中被表示;从至少一个麦克风接收代表语音的第二音频信号;基于对第一音频信号和第二音频信号的分析,确定第二音频信号与该个体相关联;相对于代表来自个体以外的源的声音的其他接收的音频信号,选择性地放大第二音频信号;并且使得选择性放大的第一音频信号或选择性放大的第二音频信号中的至少一个传输到被配置为向用户的耳朵提供声音的听力接口设备。
21.在一个实施例中,用于选择性地放大音频信号的助听器系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机,以及被配置为从用户的环境捕获声音的至少一个麦克风。助听器系统还可以包括至少一个处理器,该处理器被编程为:接收由照相机捕获的多个图像;在多个图像中识别一个或多个个体的表示;从至少一个麦克风接收与语音相关联的音频信号;基于对多个图像的分析,确定音频信号不与一个或多个个体中的任何一个个体的语音相关联;基于对音频信号的分析,确定音频信号与音频信号与公告相关的至少一个指示符相关联;基于音频信号与音频信号涉及公告的至少一个指示符相关联的确定,引起音频信号的选择性放大;并且使得选择性放大的音频信号传输到被配置为向用户
的耳朵提供声音的听力接口设备。
22.在一个实施例中,提供一种助听器系统。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机;至少一个麦克风,被配置为捕获来自用户的环境的声音;和至少一个处理器。处理器可以被编程为接收由照相机捕获的多个图像;在多个图像中的至少一个图像中识别至少一个个体的表示,并确定该至少一个个体是否是被辨识的个体。此外,如果至少一个个体被确定为被辨识的个体,则使得至少一个个体的图像显示在显示器上,并且选择性地调节从至少一个麦克风接收的并且被确定为与被辨识的个体相关联的至少一个音频信号;并且使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
23.在一个实施例中,提供一种助听器系统。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机;至少一个麦克风,被配置为捕获来自用户的环境的声音;和至少一个处理器。处理器可以被编程为从至少一个麦克风接收音频信号,并确定接收的音频信号是否与被辨识的个体相关联。此外,如果至少一个个体被确定为被辨识的个体,则使得至少一个个体的图像显示在显示器上,并且选择性地调节音频信号,并且使得调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
24.在一个实施例中,提供一种助听器系统。该系统可以包括被配置为从用户的环境捕获多个图像的可穿戴照相机;至少一个麦克风,被配置为捕获来自用户的环境的声音;和至少一个处理器。处理器可以被编程为从至少一个麦克风接收音频信号;基于对音频信号的分析,检测与第一时间段相关联的第一音频信号,其中第一音频信号代表单个个体的语音;基于对音频信号的分析,检测与第二时间段相关联的第二音频信号,其中第二时间段不同于第一时间段,并且其中第二音频信号代表两个或更多个个体的重叠语音;选择性地调节第一音频信号和第二音频信号,其中第一音频信号的选择性调节在至少一个方面不同于第二音频信号的选择性调节;并且使得调节后的第一音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
25.在一个实施例中,公开了一种助听器系统。该系统包括被配置为从用户的环境捕获多个图像的可穿戴照相机、被配置为从用户的环境捕获声音的至少一个麦克风、以及至少一个处理器,该处理器被编程为:接收由可穿戴照相机捕获的多个图像的;接收代表由至少一个麦克风捕获的声音的音频信号;从接收的音频信号中识别代表第一个体的语音的第一音频信号;在存储器中转录和存储对应于与第一个体的语音相关联的讲话的文本;确定第一个体是否是被辨识的个体;并且如果第一个体是被辨识的个体,则将第一被辨识的个体的标识符与所存储的对应于与第一个体的语音相关联的讲话的文本相关联。
26.在一个实施例中,公开了一种用于助听器系统的个体识别的计算机实施的方法。该方法包括:从可穿戴照相机接收多个图像;从至少一个麦克风接收代表声音的音频信号;从接收的音频信号中识别代表第一个体的语音的第一音频信号;转录和存储对应于与第一个体的语音相关联的讲话的文本;确定第一个体是否是被辨识的个体;并且如果第一个体是被辨识的个体,则将第一被辨识的个体的标识符与所存储的对应于与第一个体的语音相关联的讲话的文本相关联。
27.在一个实施例中,公开了一种非暂时性计算机可读存储介质。非暂时性计算机可读存储介质存储由至少一个处理器执行的程序指令,以执行:从可穿戴照相机接收多个图
像;从至少一个麦克风接收代表声音的音频信号;识别在多个图像中的至少一个图像中表示的第一个体;从接收的音频信号中识别代表第一个体的语音的第一音频信号;转录和存储对应于与第一个体的语音相关联的讲话的文本;确定第一个体是否是被辨识的个体;并且如果第一个体是被辨识的个体,则将第一被辨识的个体的标识符与所存储的对应于与第一个体的语音相关联的讲话的文本相关联。
28.在一个实施例中,提供了一种用于选择性地调节与被辨识的对象相关联的音频信号的助听器系统。该系统可以包括至少一个处理器,该处理器被编程为接收由可穿戴麦克风获取的音频信号,其中该音频信号代表从用户的环境中的对象发出的声音。该至少一个处理器可以分析接收到的音频信号,以获得与用户的环境中的发声对象相关联的隔离音频流。此外,该至少一个处理器可以从隔离的音频流中确定声纹,并且可以使用该声纹从数据库中检索与特定发声对象相关的信息。基于检索到的信息,至少一个处理器可以引起由可穿戴麦克风从与至少一个发声对象相关联的区域接收的至少一个音频信号的选择性调节,并且可以使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
29.在一个实施例中,提供了一种用于选择性地调节与被辨识的对象相关联的音频信号的方法。该方法可以包括接收由可穿戴麦克风获取的音频信号,其中音频信号代表从用户的环境中的对象发出的声音;分析接收到的音频信号以分离被确定为与用户的环境中的特定发声对象相关联的音频流;确定隔离音频流的声纹;使用所确定的声纹从数据库中检索与特定发声对象相关的信息;基于检索到的信息,引起由可穿戴麦克风从与至少一个发声对象相关联的区域接收的至少一个音频信号的选择性调节;以及使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
30.在一个实施例中,提供了一种用于选择性地调节与被辨识的对象相关联的音频信号的助听器系统。该系统可以包括至少一个处理器,该处理器被编程为接收由可穿戴照相机捕获的来自用户的环境的多个图像。至少一个处理器可以处理多个图像,以在多个图像中的至少一个图像中检测发声对象,并且使用多个图像中的至少一个图像来识别发声对象。至少一个处理器可以进一步使用所确定的发声对象的身份来从数据库中检索与发声对象相关的信息。至少一个处理器还可以接收由可穿戴麦克风获取的至少一个音频信号,其中至少一个音频信号代表包括从发声对象发出的声音的声音,并且使用检索到的信息分离至少一个音频信号以隔离从发声对象发出的声音,引起对声音的选择性调节以获得至少一个调节后的音频信号,并且可以使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
31.在一个实施例中,提供了一种用于选择性调整背景噪声的助听器系统。该系统可以包括至少一个处理器,该处理器被编程为接收在一个时间段期间由可穿戴照相机捕获的来自用户的环境的多个图像,并且接收表示在该时间段期间由可穿戴的麦克风获取的声音的至少一个音频信号。此外,至少一个处理器可以确定至少一个声音是由用户的环境中的发声对象产生的,但是在可穿戴照相机的视野之外,并且从数据库中检索与至少一个声音相关联的信息。基于检索到的信息,至少一个处理器可以引起在时间段期间由可穿戴麦克风获取的音频信号的选择性调节,并且使得调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
32.在一个实施例中,提供了一种用于选择性调整不同类型的背景噪声的方法。该方法可以包括接收在一段时间内由可穿戴照相机捕获的来自用户的环境的多个图像;接收代表在该时间段期间由可穿戴麦克风获取的来自用户的环境的声音的音频信号;确定声音中的至少一个是响应于来自用户的环境中的发声对象的声音而产生的,但是在可穿戴照相机的视野之外;基于检索到的信息,从数据库中检索与至少一个声音相关联的信息,引起在时间段期间由可穿戴麦克风获取的音频信号的选择性调节;以及使得调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
33.在一个实施例中,公开了一种用于识别用户的环境中的发声对象的系统。该系统可以包括至少一个存储设备,该存储设备被配置为存储对应于多个对象的参考视觉特性和参考声纹的数据库;和至少一个处理器。处理器可以被编程为接收由可穿戴照相机捕获的多个图像,其中多个图像中的至少一个图像描绘了用户的环境中的至少一个发声对象;分析所接收的多个图像中的至少一个图像,以确定与至少一个发声对象相关联的一个或多个视觉特性;鉴于一个或多个视觉特性,在数据库内识别至少一个发声对象,并确定识别的确定性程度;接收由可穿戴麦克风获取的音频信号,其中音频信号代表从至少一个发声对象发出的一个或多个声音;分析接收的音频信号以确定至少一个发声对象的声纹;当识别的确定性程度低于预定水平时,基于所确定的声纹进一步识别至少一个发声对象;并且基于至少一个发声对象的身份发起至少一个动作。
34.在一个实施例中,公开了一种用于识别用户的环境中的发声对象的方法。该方法可以包括访问对应于多个对象的参考视觉签名和参考语音签名的数据库;接收由可穿戴照相机捕获的多个图像,其中多个图像中的至少一个图像描绘了用户的环境中的至少一个发声对象;分析所接收的多个图像中的至少一个图像,以确定与至少一个发声对象相关联的一个或多个视觉特性;基于鉴于一个或多个视觉特性对数据库的检查,识别至少一个发声对象,并确定识别的确定性程度;接收由可穿戴麦克风获取的音频信号,其中音频信号代表从至少一个发声对象发出的一个或多个声音;分析接收的音频信号以确定至少一个发声对象的声纹;当识别的确定性程度低于预定水平时,基于所确定的声纹进一步识别至少一个发声对象;以及基于至少一个发声对象的身份启动至少一个动作。
35.在一个实施例中,软件产品可以存储在非暂时性计算机可读介质上,并且可以包括用于识别发声对象的方法的计算机可实施指令。该方法可以包括访问对应于多个对象的参考视觉签名和参考语音签名的数据库;接收由可穿戴照相机捕获的多个图像,其中多个图像中的至少一个图像描绘了用户的环境中的至少一个发声对象;分析所接收的多个图像中的至少一个图像,以确定与至少一个发声对象相关联的一个或多个视觉特性;基于鉴于一个或多个视觉特性对数据库的检查,识别至少一个发声对象,并确定识别的确定性程度;接收由可穿戴麦克风获取的音频信号,其中音频信号代表从至少一个发声对象发出的一个或多个声音;分析接收的音频信号以确定至少一个发声对象的声纹;当识别的确定性程度低于预定水平时,基于所确定的声纹进一步识别至少一个发声对象;以及基于至少一个发声对象的身份启动至少一个动作。
36.在一个实施例中,助听器系统可以选择性地调节音频信号。该助听器系统可以包括至少一个处理器,该处理器被编程为接收由可穿戴照相机捕获的多个图像,其中该多个图像描绘用户的环境中的对象;接收由可穿戴麦克风获取的音频信号,其中音频信号代表
从对象发出的声音;分析多个图像以识别用户的环境中的至少一个发声对象;从数据库中检索关于至少一个识别的发声对象的信息;基于检索到的信息,引起由可穿戴麦克风从与至少一个发声对象相关联的区域接收的至少一个音频信号的选择性调节;使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
37.在一个实施例中,公开了一种用于调整从用户的环境中的对象发出的声音的方法。该方法可以包括接收由可穿戴照相机捕获的多个图像,其中多个图像描绘用户的环境中的对象;接收由可穿戴麦克风获取的音频信号,其中音频信号代表从对象发出的声音;分析多个图像以识别用户的环境中的至少一个发声对象;从数据库中检索关于至少一个发声对象的信息;基于检索到的信息,引起由可穿戴麦克风从与至少一个发声对象相关联的区域获取的至少一个音频信号的选择性调节;使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。
38.在一个实施例中,软件产品可以存储在非暂时性计算机可读介质上,并且可以包括用于识别发声对象的方法的计算机可实施指令。该方法可以包括访问对应于多个对象的参考视觉签名和参考语音签名的数据库;接收由可穿戴照相机捕获的多个图像,其中多个图像中的至少一个图像描绘了用户的环境中的至少一个发声对象;分析所接收的多个图像中的至少一个图像,以确定与至少一个发声对象相关联的一个或多个视觉特性;基于鉴于一个或多个视觉特性对数据库的检查,识别至少一个发声对象,并确定识别的确定性程度;接收由可穿戴麦克风获取的音频信号,其中音频信号代表从至少一个发声对象发出的一个或多个声音;分析接收的音频信号以确定至少一个发声对象的声纹;当识别的确定性程度低于预定水平时,基于所确定的声纹进一步识别至少一个发声对象;以及基于至少一个发声对象的身份启动至少一个动作。
39.在一个实施例中,公开了一种听力接口设备。听力接口设备可以包括被配置为接收至少一个音频信号的接收器,其中该至少一个音频信号由可穿戴的麦克风获取,并且被至少一个处理器选择性地调节,该处理器被配置为接收由可穿戴照相机捕获的多个图像,在多个图像中识别至少一个发声对象,并且基于检索到的关于该至少一个发声对象的信息引起调节。助听器设备还可以包括电声换能器,该电声换能器被配置为向用户的耳朵提供来自至少一个音频信号的声音。
40.与其他公开的实施例一致,非暂时性计算机可读存储介质可以存储程序指令,该程序指令由至少一个处理器执行并执行这里描述的任何方法。
41.前面的一般描述和下面的详细描述仅仅是示例性和解释性的,而不是对权利要求的限制。
附图说明
42.并入并构成本公开的一部分的附图示出了各种公开的实施例。在附图中:
43.图1a是根据公开的实施例的用户穿戴可穿戴装置的示例的示意图。
44.图1b是根据公开的实施例的用户穿戴可穿戴装置的示例的示意图。
45.图1c是根据公开的实施例的用户穿戴可穿戴装置的示例的示意图。
46.图1d是根据公开的实施例的用户穿戴可穿戴装置的示例的示意图。
47.图2是与公开的实施例一致的示例系统的示意图。
48.图3a是图1a所示的可穿戴装置的示例的示意图。
49.图3b是图3a所示的可穿戴装置的示例的分解图。
50.图4a
‑
4k是从各种视点的图1b所示的可穿戴装置的示例的示意图。
51.图5a是示出根据第一实施例的可穿戴装置的组件的示例的框图。
52.图5b是示出根据第二实施例的可穿戴装置的组件的示例的框图。
53.图5c是示出根据第三实施例的可穿戴装置的组件的示例的框图。
54.图6示出了包含与本公开一致的软件模块的存储器的示例性实施例。
55.图7是包括可定向图像捕获单元的可穿戴装置的实施例的示意图。
56.图8是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
57.图9是穿戴与本公开的实施例一致的可穿戴装置的用户的示意图。
58.图10是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
59.图11是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
60.图12是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
61.图13是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
62.图14是与本公开一致的可固定到衣物上的可穿戴装置的实施例的示意图。
63.图15是包括电源的可穿戴装置电源单元的实施例的示意图。
64.图16是包括保护电路的可穿戴装置的示例性实施例的示意图。
65.图17a是根据公开的实施例的用户穿戴用于基于照相机的助听器设备的装置的示例的示意图。
66.图17b是与本公开一致的可固定到衣物上的装置的实施例的示意图。
67.图18是示出与本公开一致的基于照相机的助听器的使用的示例性环境的示意图。
68.图19是示出根据公开的实施例的用于选择性地放大从检测到的用户的注视方向发出的声音的示例性过程的流程图。
69.图20a是示出与本公开一致的具有语音和/或图像辨识的助听器的使用的示例性环境的示意图。
70.图20b示出了与本公开一致的包括面部和语音辨识组件的装置的示例性实施例。
71.图21是示出与公开的实施例一致的用于选择性地放大与被辨识的个体的语音相关联的音频信号的示例性过程的流程图。
72.图22是示出与公开的实施例一致的用于选择性地传输与被辨识的用户的语音相关联的音频信号的示例性过程的流程图。
73.图23a是示出与本公开一致的可在用户的环境中识别的示例性个体的示意图。
74.图23b是示出与本公开一致的可在用户的环境中识别的示例性个体的示意图。
75.图23c示出了与公开的实施例一致的示例性嘴唇跟踪系统。
76.图24是示出与本公开一致的嘴唇跟踪助听器的使用的示例性环境的示意图。
77.图25是示出基于与公开的实施例一致的跟踪的嘴唇运动选择性地放大音频信号的示例性过程的流程图。
78.图26是与本公开一致的示例性助听器系统的示意图。
79.图27是由与本公开一致的成像捕获设备捕获的示例性图像的示意图。
80.图28是用于选择性地放大音频信号的示例性过程的流程图。
81.图29是与本公开一致的示例性助听器系统的示意图。
82.图30a和30b是由与本公开一致的成像捕获设备捕获的示例性图像的示意图。
83.图31a是用于选择性地放大音频信号的示例性过程的流程图。
84.图31b是用于选择性地放大音频信号的示例性过程的流程图。
85.图31c是用于选择地性放大音频信号的示例性过程的流程图。
86.图32是根据公开的实施例的包括可穿戴装置的示例系统的示意图。
87.图33是根据公开的实施例的具有可穿戴装置的用户与其他人通信的示例图示。
88.图34a和34b是根据公开的实施例的描述从音频信号中隔离不同说话者的一个或多个语音的过程的示例流程图。
89.图35a是根据公开的实施例的描述从音频信号中分离说话者的语音的过程的示例流程图。
90.图35b是根据公开的实施例的描述向听力设备传输调节后的音频信号的过程的示例流程图。
91.图36a是根据公开的实施例的描述从音频信号中分离说话者的语音的过程的示例流程图。
92.图36b是与公开的实施例一致的可穿戴装置的模块的框图。
93.图37a
‑
37c是根据公开的实施例的描述向听力设备传输调节后的音频信号的过程的示例流程图。
94.图38a是示出根据示例实施例的助听器系统的框图。
95.图38b是示出与本公开一致的带有指令推导的助听器的使用的示例性环境的示意图。
96.图38c是根据公开的实施例的示例性助听器系统的示意图。
97.图39a和39b是示出根据第一实施例的用于推导助听器系统的指令的过程的流程图。
98.图40a和40b是示出根据第二实施例的用于推导助听器系统的指令的过程的流程图。
99.图41a是示出包含与本公开一致的软件模块的存储设备的示例性实施例的框图。
100.图41b是示出与本公开一致的选择性调节音频信号的助听器系统的用户的示例性环境的示意图。
101.图42a
‑
42f是由图41b所示的与本公开一致的助听器系统获取和处理的音频信号的示意图。
102.图43a是示出与公开的实施例一致的用于选择性地调节与被辨识的对象相关联的音频信号的示例性过程的流程图。
103.图43b是示出与公开的实施例一致的用于选择性地调节与被辨识的对象相关联的音频信号的另一示例性过程的流程图。
104.图44a是示出与回本公开一致的用户的示例性环境的示意图,该示例性环境包括负责背景噪声的发声对象。
105.图44b是与本公开一致的在图44a所示场景中由可穿戴麦克风获取的音频信号的示意图。
106.图44c是与本公开一致的在图44a所示场景中传输到听力接口设备的调节后的音频信号的示意图。
107.图45是示出与本公开一致的听力接口设备的组件的示例的框图。
108.图46a是示出与公开的实施例一致的,基于所确定的重要性等级选择性调整背景噪声的示例性过程的流程图。
109.图46b是示出与公开的实施例一致的选择性调整背景噪声的示例性过程的流程图。
110.图47a是示出与本公开一致的示例性助听器系统的框图。
111.图47b是示出与本公开一致的使用语音和视觉签名来识别对象的示例性环境的示意图。
112.图48是示出利用本公开显示发声对象的名称的示例性设备的图示。
113.图49是示出与公开的实施例一致的使用语音和视觉签名来识别对象的示例性过程的流程图。
114.图50a是示出与本公开一致的可以在用户的环境中识别的发声对象的示例的示意图。
115.图50b是与本公开一致的存储与发声对象相关联的信息的示例数据库的图示。
116.图51a和51b是示出与本公开一致的用于选择性调节音频信号的示例环境的示意图。
117.图52是示出与公开的实施例一致的用于调整从用户的环境中的对象发出的声音的示例性过程的流程图。
具体实施方式
118.以下详细描述参考了附图。在可能的情况下,在附图和以下描述中使用相同的附图标记来指代相同或相似的部分。虽然这里描述了几个说明性实施例,但是修改、和其他实施方式是可能的。例如,可以对附图中示出的组件进行替换、添加或修改,并且可以通过对所公开的方法进行替换、重新排序、移除或添加步骤来修改这里描述的说明性方法。因此,以下详细描述不限于所公开的实施例和示例。相反,适当的范围由所附权利要求来限定。
119.图1a示出了用户100穿戴与公开的实施例一致的与眼镜130物理连接(或集成)的装置110。眼镜130可以是处方眼镜、放大眼镜、非处方眼镜、安全眼镜、太阳镜等。此外,在一些实施例中,眼镜130可以包括框架和耳机、鼻架等的一部分以及一个或者没有镜头。因此,在一些实施例中,眼镜130可以主要用于支撑装置110和/或增强现实显示设备或其他光学显示设备。在一些实施例中,装置110可以包括用于捕获用户100的视野的实时图像数据的图像传感器(图1a中未示出)。术语“图像数据”包括从近红外、红外、可见光和紫外光谱中的光信号检索的任何形式的数据。图像数据可以包括视频剪辑和/或照片。
120.在一些实施例中,装置110可以与计算设备120无线或经由有线通信。
121.在一些实施例中,计算设备120可以包括例如智能电话、平板或专用处理单元,计算设备120可以是便携式的(例如,可以放在用户100的口袋中)。尽管在图1a中示出为外部设备,但在一些实施例中,计算设备120可以作为可穿戴装置110或眼镜130的一部分提供,无论是集成在其上还是安装在其上。
122.在一些实施例中,计算设备120可以包括在集成地提供或安装到眼镜130的增强现实显示设备或光学头戴式显示器中。在其他实施例中,计算设备120可以作为用户100的另一可穿戴或便携式装置的一部分提供,包括腕带、多功能手表、按钮、夹子等。并且在其他实施例中,计算设备120可以作为另一系统的一部分提供,诸如车载计算机或导航系统。本领域技术人员可以理解,不同类型的计算设备和设备的布置可以实施所公开的实施例的功能。因此,在其他实现中,计算设备120可以包括个人计算机(pc)、膝上型计算机、因特网服务器等。
123.图1b示出了与公开的实施例一致的用户100穿戴与项链140物理连接的装置110。装置110的这种配置可以适合于部分或全部时间不戴眼镜的用户。在本实施例中,用户100可以容易地穿戴装置110并将其取下。
124.图1c示出了与公开的实施例一致的用户100穿戴物理连接到腰带150的装置110。装置110的这种构造可以被设计成皮带扣。可选地,装置110可以包括用于连接到各种衣服物品的夹子,诸如腰带150,或者背心、口袋、衣领、帽子或衣服物品的其他部分。
125.图1d示出了与公开的实施例一致的用户100穿戴物理连接到腕带160的装置110。尽管根据该实施例,装置110的瞄准方向可能与用户100的视野不匹配,但是装置110可以包括基于被跟踪的指示用户100正朝腕带160的方向看的用户100的眼睛移动来识别手相关触发的能力。腕带160还可以包括加速度计、陀螺仪或其他传感器,用于确定用户100的手的运动或方向,以识别手相关触发。
126.图2是与公开的实施例一致的示例性系统200的示意图,该示例性系统200包括用户100穿戴的可穿戴装置110,以及能够通过网络240与装置110通信的可选计算设备120和/或服务器250。在一些实施例中,装置110可以捕获和分析图像数据,识别图像数据中存在的手相关触发,并且至少部分地基于手相关触发的识别来执行动作和/或向用户100提供反馈。在一些实施例中,可选计算设备120和/或服务器250可以提供附加功能以增强用户100与其环境的交互,如下面更详细地描述的。
127.根据公开的实施例,装置110可以包括图像传感器系统220,用于捕获用户100的视野的实时图像数据。在一些实施例中,装置110还可以包括处理单元210,用于控制和执行装置110的公开功能,诸如控制图像数据的捕获、分析图像数据,以及基于在图像数据中识别的手相关触发执行动作和/或输出反馈。根据所公开的实施例,手相关触发可以包括用户100执行的涉及用户100的手的一部分的手势。此外,与一些实施例一致,手相关触发可以包括手腕相关触发。此外,在一些实施例中,装置110可以包括反馈输出单元230,用于产生对用户100的信息输出。
128.如上所述,装置110可以包括用于捕获图像数据的图像传感器220。术语“图像传感器”是指能够检测近红外、红外、可见和紫外光谱中的光信号并将其转换成电信号的设备。电信号可用于形成图像或视频流(即,图像数据)。术语“图像数据”包括从近红外、红外、可见光和紫外光谱中的光信号检索的任何形式的数据。图像传感器的示例可包括半导体电荷耦合器件(ccd)、互补金属氧化物半导体(cmos)中的有源像素传感器或n型金属氧化物半导体(nmos、live mos)。在一些情况下,图像传感器220可以是包括在装置110中的照相机的一部分。
129.根据所公开的实施例,装置110还可以包括用于控制图像传感器220以捕获图像数
据和用于分析图像数据的处理器210。如下面关于图5a进一步详细讨论的,处理器210可以包括“处理设备”,用于根据存储的或可访问的提供期望功能的软件指令对图像数据和其他数据的一个或多个输入执行逻辑操作。在一些实施例中,处理器210还可以控制反馈输出单元230,以向用户100提供包括基于分析的图像数据和存储的软件指令的信息的反馈。如本文所使用的术语,“处理设备”可以访问存储可执行指令的存储器,或者在一些实施例中,“处理设备”本身可以包括可执行指令(例如,存储在包括在处理设备中的存储器中)。
130.在一些实施例中,提供给用户100的信息或反馈信息可以包括时间信息。时间信息可以包括与一天的当前时间相关的任何信息,并且如下面进一步描述的,可以以任何感官感知的方式呈现。在一些实施例中,时间信息可以包括预先配置格式的一天中的当前时间(例如,下午2:30或14:30)。时间信息可以包括用户当前时区的时间(例如,基于用户100的确定位置)以及另一期望位置的时区和/或一天中的时间的指示。在一些实施例中,时间信息可以包括相对于一天中一个或多个预定时间的小时或分钟数。例如,在一些实施例中,时间信息可以包括三小时十五分钟剩余直到特定小时的指示(例如,直到下午6:00),或者一些其他预定时间。时间信息还可以包括从特定活动开始以来经过的持续时间,诸如会议开始、慢跑开始或任何其他活动。在一些实施例中,可以基于分析的图像数据来确定活动。在其他实施例中,时间信息还可以包括与当前时间和一个或多个其他常规、周期性或预定事件相关的附加信息。例如,时间信息可以包括直到下一个预定事件的剩余分钟数的指示,如可以根据日历功能或从计算设备120或服务器250检索的其他信息来确定,如下面进一步详细讨论的。
131.反馈输出单元230可以包括一个或多个反馈系统,用于向用户100提供信息的输出。在所公开的实施例中,可通过任何类型的连接的音频或视频系统或两者来提供音频或视频反馈。根据所公开的实施例的信息反馈可以包括对用户100的听觉反馈(例如,使用蓝牙
tm
或其他有线或无线连接的扬声器,或骨传导耳机)。一些实施例的反馈输出单元230可以附加地或替代地向用户100产生可视的信息输出,例如,作为投射到眼镜130的镜头上的增强现实显示器的一部分,或者经由与装置110通信的单独的平视显示器提供,例如,作为计算设备120的一部分提供的显示器260,其可以包括车载汽车平视显示器、增强现实设备、虚拟现实设备、智能电话、pc、桌子等。
132.术语“计算设备”是指包括处理单元并且具有计算能力的设备。计算设备120的一些示例包括pc、膝上型计算机、平板或诸如汽车的车载计算系统的其他计算系统,例如,每个计算系统被配置为通过网络240直接与装置110或服务器250通信。计算设备120的另一示例包括具有显示器260的智能电话。在一些实施例中,计算设备120可以是特别为装置110配置的计算系统,并且可以被提供为装置110的整体或栓系在装置110上。装置110还可以经由任何已知的无线标准(例如,wi
‑
fi、等)以及近场电容耦合,和其他短距离无线技术或经由有线连接通过网络240连接到计算设备120。在计算设备120是智能电话的实施例中,计算设备120可以具有安装在其中的专用应用。例如,用户100可以在显示器260上观看源自装置110或由装置110触发的数据(例如,图像、视频剪辑、提取的信息、反馈信息等)。另外,用户100可以选择部分数据以存储在服务器250中。
133.网络240可以是共享的、公共的或私有的网络,可以包含广域网或局域网,并且可以通过有线和/或无线通信网络的任何合适的组合来实施。网络240还可以包括内部网或互
联网。在一些实施例中,网络240可以包括短程或近场无线通信系统,用于实现彼此靠近设置的装置110和计算设备120之间的通信,诸如在用户的人身上或附近。装置110可以例如使用无线模块(例如,wi
‑
fi,蜂窝)。在一些实施例中,装置110可以在连接到外部电源时使用无线模块,以延长电池寿命。此外,装置110和服务器250之间的通信可以通过任何合适的通信信道来实现,诸如电话网络、外联网、内联网、互联网、卫星通信、离线通信、无线通信、转发器通信、局域网(lan)、广域网(wan)和虚拟专用网(vpn)。
134.如图2所示,装置110可以经由网络240向/从服务器250传送或接收数据.在所公开的实施例中,从服务器250和/或计算设备120接收的数据可以包括基于所分析的图像数据的多种不同类型的信息,包括与商业产品或个人身份、所识别的地标以及能够存储在服务器250中或由服务器250访问的任何其他信息相关的信息。在一些实施例中,可以通过计算设备120接收和传输数据。服务器250和/或计算设备120可以从不同的数据源(例如,用户特定的数据库或用户的社交网络账户或其他账户、互联网和其他管理的或可访问的数据库),并根据所公开的实施例向装置110提供与分析的图像数据和被辨识的触发相关的信息。在一些实施例中,可以分析从不同数据源检索的日历相关信息,以提供特定时间信息或基于时间的上下文,用于基于分析的图像数据提供特定信息。
135.在图3a中更详细地示出了根据一些实施例(结合图1a讨论)的与眼镜130结合的可穿戴装置110的示例。在一些实施例中,装置110可以与能够容易地将装置110分离和重新连接到眼镜130的结构(图3a中未示出)相关联。在一些实施例中,当装置110连接到眼镜130时,图像传感器220获取设置的瞄准方向而不需要进行方向校准。图像传感器220的设定瞄准方向可以基本上与用户100的视野一致。例如,与图像传感器220相关联的照相机可以以预定角度安装在装置110内,安装位置稍微朝下(例如,距地平线5
‑
15度)。因此,图像传感器220的设定瞄准方向可以与用户100的视野基本匹配。
136.图3b是关于图3a讨论的实施例的组件的分解图。将装置110连接到眼镜130可以以下述方式进行。首先,可以使用支撑310侧面专用的螺钉320将支架310安装在眼镜130上。然后,装置110可以夹在支撑310上,使得其与用户100的视野对准。术语“支撑”包括能够将包括照相机的设备分离和重新连接到眼镜或另一物体(例如头盔)上的任何设备或结构。支撑310可由塑料(例如,聚碳酸酯)、金属(例如,铝)或塑料和金属的组合(例如,碳纤维石墨)制成。支撑310可使用螺钉、螺栓、卡扣或本领域使用的任何紧固装置安装在任何种类的眼镜(例如眼镜、太阳镜、3d眼镜、安全眼镜等)上。
137.在一些实施例中,支撑310可以包括用于脱离和重新接合装置110的快速释放机构。例如,支撑310和装置110可以包括磁性元件。作为替代示例,支撑310可包括阳闩锁构件,并且装置110可包括阴插座。在其他实施例中,支撑310可以是一副眼镜的组成部分,或者由验光师单独出售和安装。例如,支撑310可以被配置为安装在眼镜130的臂上靠近框架前部,但是在铰链之前。可选地,支撑310可以被配置为安装在眼镜130的桥上。
138.在一些实施例中,装置110可以作为眼镜框130的一部分来提供,有或没有镜片。另外,在一些实施例中,装置110可以被配置为提供投影到眼镜130的镜片上的增强现实显示(如果提供的话),或者可替换地,例如,根据所公开的实施例,可以包括用于投影时间信息的显示器。装置110可以包括附加显示器,或者可替换地,可以与单独提供的显示系统通信,该显示系统可以附接到或者可以不附接到眼镜130。
139.在一些实施例中,装置110可以以除可穿戴眼镜以外的形式实施,例如,如上文关于图1b
‑
1d所述。图4a是从装置110的前视点的装置110的附加实施例的示例的示意图。装置110包括图像传感器220、夹子(未示出)、功能按钮(未示出)和吊环410(用于将装置110连接到例如项链140),如图1b所示。当装置110挂在项链140上时,图像传感器220的瞄准方向可能与用户100的视野不完全一致,但是瞄准方向仍然与用户100的视野相关。
140.图4b是从装置110的侧方向的,装置110的第二实施例的示例的示意图。除了吊环410之外,如图4b所示,装置110还可以包括夹子420。用户100可以使用夹子420将装置110连接到衬衫或皮带150,如图1c所示。夹子420可以提供一种简单的机构,用于从不同的衣物上分离和重新接合装置110。在其它实施例中,装置110可包括用于与汽车安装架或通用支架的阳插销连接的阴插座。
141.在一些实施例中,装置110包括功能按钮430,用于使用户100向装置110提供输入。功能按钮430可接受不同类型的触觉输入(例如,轻触、点击、双击、长按、从右向左滑动、从左向右滑动)。在一些实施例中,每种类型的输入可以与不同的动作相关联。例如,轻触可与拍摄照片的功能相关联,而从右向左滑动可与记录视频的功能相关联。
142.如图4c所示,可以使用夹子431将装置110连接到用户100的衣服(例如衬衫、腰带、裤子等)的边缘处。例如,装置100的主体可以位于衣服的内表面附近,并且夹子431与衣服的外表面接合。在这样的实施例中,如图4c所示,图像传感器220(例如,用于可见光的照相机)可以伸出衣服的边缘之外。可替代地,夹子431可以与衣服的内表面接合,并且装置110的主体与衣服的外部相邻。在各种实施例中,衣服可以定位在夹子431和装置110的主体之间。
143.图4d中示出了装置110的示例性实施例。装置110包括夹子431,夹子431可以包括靠近装置110的主体435的前表面434的点(例如,432a和432b)。在示例实施例中,点432a、432b和前表面434之间的距离可以小于用户100的衣服的织物的典型厚度。例如,点432a、432b和表面434之间的距离可以小于t恤衫的厚度,例如,小于1毫米、小于2毫米、小于3毫米等,或者在某些情况下,夹子431的点432a、432b可以接触表面434。在各种实施例中,夹子431可以包括不接触表面434的点433,从而允许衣服插入夹子431和表面434之间。
144.图4d示意性地示出了被定义为前视图(f视图)、后视图(r视图)、顶视图(t视图)、侧视图(s视图)和底视图(b视图)的装置110的不同视图。当在随后的图中描述装置110时,将参考这些视图。图4d示出了一个示例性实施例,其中夹子431与传感器220位于装置110的同一侧(例如,装置110的前侧)。可替代地,夹子431可以定位在作为传感器220的装置110的相对侧(例如,装置110的后侧)。在各种实施例中,装置110可以包括功能按钮430,如图4d所示。
145.图4e至4k中示出装置110的各种视图。例如,图4e示出具有电连接441的装置110的视图。电连接441可以例如是usb端口,该usb端口可用于将数据传送到装置110/从装置110传送数据并向装置110提供电力。在示例实施例中,连接441可用于对图4e中示意性地示出的电池442充电。图4f示出包括传感器220和一个或多个麦克风443的装置110的f视图。在一些实施例中,装置110可以包括面向外部的多个麦克风443,其中麦克风443被配置为获得环境声音和与用户100交流的各种说话者的语音。图4g示出装置110的r视图。在一些实施例中,麦克风444可以定位在装置110的后侧,如图4g所示。麦克风444可用于检测来自用户100
的音频信号。应当注意,装置110可以在装置110的任何一侧(例如,前侧、后侧、左侧、右侧、顶部或底部)放置麦克风。在各种实施例中,一些麦克风可以位于第一侧(例如,麦克风443可以位于装置110的前面),而其他麦克风可以位于第二侧(例如,麦克风444可以位于装置110的背侧)。
146.图4h和4i示出了由所公开的实施例组成的装置110的不同侧面(即,装置110的s视图)。例如,图4h示出了传感器220的位置和夹子431的示例形状。图4j示出了包括功能按钮430的装置110的t视图,图4k示出了具有电连接441的装置110的b视图。
147.上面参考图3a、3b、4a和4b讨论的示例实施例不是限制性的。在一些实施例中,装置110可以以用于执行所公开的方法的任何合适的配置来实施。例如,回到图2,所公开的实施例可以实施根据任何配置的装置110,该任何配置包括执行图像分析并用于与反馈单元230通信的图像传感器220和处理器单元210。
148.图5a是示出根据示例性实施例的装置110的组件的框图。如图5a所示,并且如上类似地讨论,装置110包括图像传感器220、存储器550、处理器210、反馈输出单元230、无线收发器530和移动电源520。在其它实施例中,装置110还可以包括按钮、诸如麦克风的其它传感器和诸如加速计、陀螺仪、磁强计、温度传感器、颜色传感器、光传感器等惯性测量设备,装置110还可以包括数据端口570和电源连接510,其具有用于与外部电源或外部设备(未示出)连接的适当接口。
149.图5a所示的处理器210可以包括任何合适的处理设备。术语“处理设备”包括具有对一个或多个输入执行逻辑操作的电路的任何物理设备。例如,处理设备可以包括一个或多个集成电路、微芯片、微控制器、微处理器、全部或部分中央处理单元(cpu)、图形处理单元(gpu)、数字信号处理器(dsp)、现场可编程门阵列(fpga),或其它适合执行指令或执行逻辑运算的电路。例如,由处理设备执行的指令可以预加载到与处理设备集成或嵌入到处理设备中的存储器中,或者可以存储在单独的存储器(例如,存储器550)中。存储器550可以包括随机存取存储器(ram)、只读存储器(rom)、硬盘、光盘、磁介质、闪存、其他永久的、固定的或易失的存储器,或者能够存储指令的任何其他机制。
150.尽管在图5a所示的实施例中,装置110包括一个处理设备(例如,处理器210),但是装置110可以包括多个处理设备。每个处理设备可以具有相似的构造,或者处理设备可以具有彼此电连接或断开的不同构造。例如,处理设备可以是单独的电路或集成在单个电路中。当使用一个以上的处理设备时,处理设备可被配置为独立地或协作地操作。处理设备可以电、磁、光、声、机械或通过允许它们相互作用的其它方式耦合。
151.在一些实施例中,处理器210可以处理从用户100的环境捕获的多个图像,以确定与捕获后续图像相关的不同参数。例如,处理器210可以基于从捕获的图像数据导出的信息来确定以下至少一项的值:图像分辨率、压缩比、裁剪参数、帧速率、焦点、曝光时间、光圈大小和感光度。所确定的值可用于捕获至少一个后续图像。此外,处理器210可以检测用户的环境中包括至少一个手相关触发的图像,并通过反馈输出单元230执行动作和/或向用户提供信息输出。
152.在另一个实施例中,处理器210可以改变图像传感器220的瞄准方向。例如,当装置110附加有夹子420时,图像传感器220的瞄准方向可能与用户100的视野不一致。处理器210可以从分析的图像数据辨识某些情况,并调整图像传感器220的瞄准方向以捕获相关的图
像数据。例如,在一个实施例中,由于图像传感器220向下倾斜,处理器210可以检测到与另一个体的交互并感觉到该个体没有完全在视野中。响应于此,处理器210可以调整图像传感器220的瞄准方向以捕获个体的图像数据。还设想了其他情形,其中处理器210可以辨识需要调整图像传感器220的瞄准方向。
153.在一些实施例中,处理器210可以向反馈输出单元230通信传递数据,反馈输出单元230可以包括配置为向用户100提供信息的任何设备。反馈输出单元230可以被提供为装置110的一部分(如图所示),或者可以被提供在装置110的外部并且通信地耦合到装置110。反馈输出单元230可以被配置为基于从处理器210接收到的信号输出视觉或非视觉反馈,诸如当处理器210辨识出分析的图像数据中的手相关触发时。
154.术语“反馈”是指响应于在环境中处理至少一个图像而提供的任何输出或信息。在一些实施例中,如上所述,反馈可以包括时间信息、检测到的文本或数字、货币价值、品牌产品、个人身份,地标或其他环境状况或条件(包括交叉口的街道名称或红绿灯的颜色等)的标识以及与这些中的每一个相关联的其他信息的可听到的和可见的指示。例如,在一些实施例中,反馈可以包括关于完成交易仍然需要的货币量的附加信息、关于被识别的人的信息、检测到的地标等的历史信息或入场时间和价格等。在一些实施例中,反馈可以包括可听音调,触觉响应和/或用户100先前记录的信息。反馈输出单元230可以包括用于输出声学和触觉反馈的适当组件。例如,反馈输出单元230可以包括音频耳机、助听器类型的设备、扬声器、骨传导耳机、提供触觉提示的接口、振动感应刺激器等。在一些实施例中,处理器210可以经由无线收发器530、有线连接或其它通信接口与外部反馈输出单元230通信传递信号。在一些实施例中,反馈输出单元230还可以包括用于向用户100直观地显示信息的任何合适的显示设备。
155.如图5a所示,装置110包括存储器550。存储器550可包括处理器210可访问的一组或多组指令,以执行所公开的方法,一组或多组指令包括用于辨识图像数据中的手相关触发的指令。在一些实施例中,存储器550可以存储从用户100的环境捕获的图像数据(例如,图像、视频)。此外,存储器550可以存储特定于用户100的信息,例如已知个体的图像表示、最喜爱的产品、个人项目和日历或约会信息等。在一些实施例中,处理器210可以例如基于存储器550中的可用存储空间来确定要存储哪种类型的图像数据。在另一实施例中,处理器210可以从存储在存储器550中的图像数据提取信息。
156.如图5a中进一步所示,装置110包括移动电源520。术语“移动电源”包括能够提供电力的任何装置,其可以容易地用手携带(例如,移动电源520的重量可以小于一磅)。电源的移动性使得用户100能够在各种情况下使用装置110。在一些实施例中,移动电源520可包括一个或多个电池(例如,镍镉电池、镍金属氢化物电池和锂离子电池)或任何其他类型的电源。在其它实施例中,移动电源520可以是可充电的并且被包括在容纳装置110的外壳内。在又一其它实施例中,移动电源520可包括用于将环境能量转换成电能的一个或多个能量收集装置(例如,便携式太阳能单元、人体振动单元等)。
157.移动电源520可以为一个或多个无线收发器供电(例如,图5a中的无线收发器530)。术语“无线收发器”是指被配置为通过使用射频、红外频率、磁场或电场在空中接口上交换传输的任何设备。无线收发器530可以使用任何已知标准(例如,wi
‑
fi、蓝牙智能、802.15.4或zigbee)来发送和/或接收数据。在一些实施例中,无线收发器530可以将
数据(例如,原始图像数据、处理的图像数据、提取的信息)从装置110发送到计算设备120和/或服务器250。无线收发器530还可以从计算设备120和/或服务器250接收数据。在其他实施例中,无线收发器530可以向外部反馈输出单元230发送数据和指令。
158.图5b是示出根据另一示例实施例的装置110的组件的框图。在一些实施例中,装置110包括第一图像传感器220a、第二图像传感器220b、存储器550、第一处理器210a、第二处理器210b、反馈输出单元230、无线收发器530、移动电源520和电源连接器510。在图5b所示的布置中,每个图像传感器可以提供不同图像分辨率的图像,或者面向不同的方向。可替代地,每个图像传感器可以与不同的照相机(例如,广角照相机、窄角照相机、ir照相机等)相关联。在一些实施例中,装置110可以基于各种因素选择要使用哪个图像传感器。例如,处理器210a可以基于存储器550中的可用存储空间来确定以特定分辨率捕获后续图像。
159.装置110可以在第一处理模式和第二处理模式下操作,以使得第一处理模式可以比第二处理模式消耗更少的功率。例如,在第一处理模式中,装置110可以捕获图像并处理所捕获的图像,以基于例如识别的手相关触发来作出实时决策。在第二处理模式中,装置110可以从存储器550中存储的图像中提取信息并从存储器550中删除图像。在一些实施例中,移动电源520可以在第一处理模式中提供超过15小时的处理,在第二处理模式中提供大约3小时的处理。因此,不同的处理模式可以允许移动电源520在不同的时间段(例如,超过2小时、超过4小时、超过10小时等)产生足够的功率为装置110供电。
160.在一些实施例中,当由移动电源520供电时,装置110可以在第一处理模式下使用第一处理器210a,当由可经由电源连接器510连接的外部电源580供电时,在第二处理模式下使用第二处理器210b。在其他实施例中,装置110可以基于预定的条件确定要使用哪些处理器或哪些处理模式。即使当装置110不由外部电源580供电时,装置110也可以在第二处理模式下操作。例如,如果存储器550中用于存储新图像数据的可用存储空间低于预定阈值,则当装置110不由外部电源580供电时,装置110可以确定其应在第二处理模式下操作。
161.尽管在图5b中描绘了一个无线收发器,但是装置110可以包括一个以上的无线收发器(例如,两个无线收发器)。在具有多个无线收发器的布置中,每个无线收发器可以使用不同的标准来发送和/或接收数据。在一些实施例中,第一无线收发器可以使用蜂窝标准(例如,lte或gsm)与服务器250或计算设备120通信,并且第二无线收发器可以使用短程标准(例如,wi
‑
fi或fi或)与服务器250或计算设备120通信。在一些实施例中,当可穿戴设备由包括在可穿戴设备中的移动电源供电时,装置110可以使用第一无线收发器,并且当可穿戴设备由外部电源供电时,装置110可以使用第二无线收发器。
162.图5c是示出根据包括计算设备120的另一示例实施例的装置110的组件的框图。在本实施例中,装置110包括图像传感器220、存储器550a、第一处理器210、反馈输出单元230、无线收发器530a、移动电源520和电源连接器510。如图5c中进一步示出的,计算设备120包括处理器540、反馈输出单元545、存储器550b、无线收发器530b和显示器260。计算设备120的一个示例是具有安装在其中的专用应用的智能电话或平板。在其他实施例中,计算设备120可以包括任何配置,诸如车载汽车计算系统、pc、膝上型计算机以及与所公开的实施例一致的任何其他系统。在该示例中,用户100可以响应于显示器260上的手相关触发的识别来查看反馈输出。另外,用户100可以在显示器260上查看其他数据(例如,图像、视频剪辑、对象信息、时间表信息、提取的信息等)。另外,用户100可以经由计算设备120与服务器250
通信。
163.在一些实施例中,处理器210和处理器540被配置为从捕获的图像数据中提取信息。术语“提取信息”包括通过本领域技术人员已知的任何手段在捕获的图像数据中识别与对象、个体、位置、事件等相关联的信息的任何过程。在一些实施例中,装置110可以使用提取的信息向反馈输出单元230或计算设备120发送反馈或其他实时指示。在一些实施例中,处理器210可以在图像数据中识别站在用户100前面的个体,并向计算设备120发送该个体的姓名和用户100最后一次遇见该个体的时间。在另一实施例中,处理器210可在图像数据中识别一个或多个可见触发,包括手相关触发,并确定该触发是否与可穿戴设备的用户以外的人相关联,以选择性地确定是否执行与该触发相关联的动作。一个这样的动作可以是经由作为装置110的一部分(或与装置110通信)提供的反馈输出单元230或经由作为计算设备120的一部分提供的反馈单元545向用户100提供反馈。例如,反馈输出单元545可以与显示器260通信以使显示器260可见地输出信息。在一些实施例中,处理器210可以在图像数据中识别手相关触发,并向计算设备120发送该触发的指示。处理器540随后可处理所接收的触发信息并基于手相关触发经由反馈输出单元545或显示器260提供输出。在其它实施例中,处理器540可基于从装置110接收的图像数据来确定手相关触发并提供类似于上述的适当反馈。在一些实施例中,处理器540可以基于所识别的手相关触发向装置110提供指令或其他信息,例如环境信息。
164.在一些实施例中,处理器210可以识别分析图像中的其他环境信息,诸如站在用户100前面的个体,并向计算设备120发送与分析信息相关的信息,诸如个体的姓名和用户100最后一次遇见该个体的时间。在不同的实施例中,处理器540可以从捕获的图像数据中提取统计信息,并将统计信息转发给服务器250。例如,关于用户购买的项目的类型、或用户光顾特定商家的频率等的某些信息可以由处理器540确定。基于该信息,服务器250可以向计算设备120发送与用户偏好相关联的优惠券和折扣。
165.当装置110连接到或无线连接到计算设备120时,装置110可以发送存储在存储器550a中的图像数据的至少一部分以存储在存储器550b中。在一些实施例中,在计算设备120确认图像数据的部分传输成功之后,处理器540可以删除图像数据的部分。术语“删除”意味着图像被标记为“已删除”,并且可以存储其他图像数据来代替它,但不一定意味着图像数据从存储器中物理地移除。
166.如受益于本公开的本领域技术人员将理解的,可以对所公开的实施例进行许多改变和/或修改。并非所有组件对于装置110的操作都是必需的。任何组件可以位于任何适当的设备中,并且组件可以被重新排列成各种配置,同时提供所公开的实施例的功能。例如,在一些实施例中,装置110可以包括照相机、处理器和用于向另一设备发送数据的无线收发器。因此,上述配置是示例,并且,不管上面讨论的配置如何,装置110都可以捕获、存储和/或处理图像。
167.此外,上述和以下描述涉及存储和/或处理图像或图像数据。在本文公开的实施例中,存储和/或处理的图像或图像数据可以包括由图像传感器220捕获的一个或多个图像的表示。如本文所使用的术语,图像(或图像数据)的“表示”可以包括整个图像或图像的一部分。图像(或图像数据)的表示可以具有与图像(或图像数据)相同的分辨率或更低的分辨率,和/或图像(或图像数据)的表示可以在某些方面被改变(例如,被压缩、具有更低的分辨
率、具有被改变的一种或多种颜色等)。
168.例如,装置110可以捕获图像并存储压缩为.jpg文件的图像的表示。作为另一示例,装置110可以捕获彩色图像,但是存储彩色图像的黑白表示。作为又一示例,装置110可以捕获图像并存储图像的不同表示(例如,图像的一部分)。例如,装置110可以存储图像的一部分,该部分包括出现在该图像中的人的面部,但是该部分基本上不包括该人周围的环境。类似地,装置110可以例如存储图像的一部分,该部分包括出现在图像中的产品,但基本上不包括产品周围的环境。作为又一示例,装置110可以以降低的分辨率(即,以具有比捕获图像的分辨率低的值的分辨率)存储图像的表示。存储图像的表示可以允许装置110节省存储器550中的存储空间。此外,图像的处理表示可以允许装置110提高处理效率和/或帮助保持电池寿命。
169.除上述之外,在一些实施例中,装置110或计算设备120中的任何一个经由处理器210或540可进一步处理捕获的图像数据,以提供辨识捕获的图像数据中的对象和/或手势和/或其他信息的附加功能。在一些实施例中,可以基于所识别的对象、手势或其他信息来采取动作。在一些实施例中,处理器210或540可在图像数据中识别一个或多个可见触发,包括手相关触发,并确定触发是否与用户以外的人相关联,以确定是否执行与触发相关联的动作。
170.本公开的一些实施例可以包括可固定到用户的衣物的装置。这种装置可以包括通过连接器可连接的两部分。捕获单元可以被设计成穿着在用户衣服的外面,并且可以包括用于捕获用户的环境的图像的图像传感器。捕获单元可以连接到或可连接到电源单元,电源单元可被配置为容纳电源和处理设备。捕获单元可以是包括照相机或用于捕获图像的其他设备的小型设备。捕获单元可以被设计成不显眼和不突出的,并且可以被配置为与隐藏在用户衣服中的电源单元通信。电源单元可以包括系统的更大方面,诸如收发器天线、至少一个电池、处理设备等。在一些实施例中,捕获单元和电源单元之间的通信可以由包括在连接器中的数据电缆提供,而在其他实施例中,可以在捕获单元和电源单元之间无线地实现通信。一些实施例可以允许改变捕获单元的图像传感器的方向,例如,以更好地捕获感兴趣的图像。
171.图6示出了与本公开一致的包含软件模块的存储器的示例性实施例。在存储器550中包括方向识别模块601、方向调整模块602和运动跟踪模块603。模块601、602、603可包含用于由包括在可穿戴装置中的至少一个处理设备(例如处理器210)执行的软件指令。方向识别模块601、方向调整模块602和运动跟踪模块603可以协作为并入无线装置110中的捕获单元提供方向调整。
172.图7示出了包括方向调整单元705的示例性捕获单元110。方向调整单元705可以被配置为允许调整图像传感器220。如图7所示,方向调整单元705可以包括眼球型调整机构。在替代实施例中,方向调整单元705可以包括万向节、可调节杆、可枢转的安装件以及用于调整图像传感器220的方向的任何其他合适单元。
173.图像传感器220可以被配置为与用户100的头部一起移动,使得图像传感器220的瞄准方向基本上与用户100的视野一致。例如,如上所述,根据捕获单元110的预定位置,与图像传感器220相关联的照相机可以以预定角度安装在捕获单元110内,安装位置稍微朝上或朝下。因此,图像传感器220的设定瞄准方向可以与用户100的视野匹配。在一些实施例
中,处理器210可以使用从图像传感器220提供的图像数据来改变图像传感器220的方向。例如,处理器210可以辨识用户正在阅读书籍,并且确定图像传感器220的瞄准方向与文本偏移。也就是说,由于每行文本的开头的单词没有完全被看到,处理器210可以确定图像传感器220在错误的方向上倾斜。响应于此,处理器210可以调整图像传感器220的瞄准方向。
174.方向识别模块601可配置为识别捕获单元710的图像传感器220的方向。例如,可以通过分析捕获单元110的图像传感器220捕获的图像、通过捕获单元710内的倾斜或姿态感测设备,以及通过测量相对于捕获单元710的其余部分的方向调整单元705的相对方向来识别图像传感器220的方向。
175.方向调整模块602可以被配置为调整捕获单元710的图像传感器220的方向。如上所述,图像传感器220可以安装在被配置用于移动的方向调整单元705上。方向调整单元705可以被配置为响应于来自方向调整模块602的命令而进行旋转和/或横向移动。在一些实施例中,方向调整单元705可以通过马达、电磁体、永磁体和/或其任何合适的组合来调整图像传感器220的方向。
176.在一些实施例中,监控模块603可被提供用于连续监控。这种连续监控可以包括跟踪包括在由图像传感器捕获的一个或多个图像中的对象的至少一部分的移动。例如,在一个实施例中,只要对象基本上保持在图像传感器220的视野内,装置110就可以跟踪对象。在附加实施例中,监控模块603可接合方向调整模块602以指示方向调整单元705连续地将图像传感器220朝向感兴趣的对象。例如,在一个实施例中,监控模块603可使图像传感器220调整方向以确保特定指定对象(例如,特定人的面部)即使在该指定对象四处移动时仍保持在图像传感器220的视野内。在另一实施例中,监控模块603可以连续监控包括在由图像传感器捕获的一个或多个图像中的感兴趣区域。例如,用户可以被特定任务(例如,在膝上型计算机上打字)占用,而图像传感器220保持定向在特定方向上,并且连续地从一系列图像监控每个图像的一部分以检测触发或其他事件。例如,在用户的注意力被占用的同时,图像传感器210可以朝向一件实验室设备,并且监控模块603可以被配置为监控实验室设备上的状态灯以获取状态的改变。
177.在与本公开一致的一些实施例中,捕获单元710可以包括多个图像传感器220。多个图像传感器220各自可以被配置为捕获不同的图像数据。例如,当提供多个图像传感器220时,图像传感器220可以捕获具有不同分辨率的图像,可以捕获更宽或更窄的视野,并且可以具有不同的放大率。图像传感器220可以配备有不同的透镜以允许这些不同的配置。在一些实施例中,多个图像传感器220可以包括具有不同方向的图像传感器220。因此,多个图像传感器220中的每一个可以指向不同的方向以捕获不同的图像。在一些实施例中,图像传感器220的视野可以重叠。多个图像传感器220各自可以例如通过与图像调整单元705配对而被配置用于方向调整。在一些实施例中,监控模块603或与存储器550相关联的另一模块可被配置为单独地调整多个图像传感器220的方向,以及根据需要打开或关闭多个图像传感器220中的每一个。在一些实施例中,监控由图像传感器220捕获的对象或人可以包括跟踪对象在多个图像传感器220的视野上的移动。
178.与本公开一致的实施例可以包括被配置为连接可穿戴装置的捕获单元和电源单元的连接器。符合本公开的捕获单元可以包括被配置为捕获用户的环境的图像的至少一个图像传感器。符合本公开的电源单元可以被配置为容纳电源和/或至少一个处理设备。与本
公开一致的连接器可以被配置为连接捕获单元和电源单元,并且可以被配置为将装置固定到衣物,使得捕获单元位于衣物的外表面上方,而电源单元位于衣物的内表面下方。与本公开一致的捕获单元、连接器和电源单元的示例性实施例将参考图8
‑
14进一步详细讨论。
179.图8是符合本公开的可穿戴装置110的一个实施例的示意图,该可穿戴装置110可安全地固定在衣物上。如图8所示,捕获单元710和电源单元720可以通过连接器730连接,使得捕获单元710位于衣物750的一侧,而电源单元720位于衣物750的相对侧。在一些实施例中,捕获单元710可以位于衣物750的外表面之上,并且电源单元720可以位于衣物750的内表面之下。电源单元720可以被配置为紧靠用户的皮肤放置。
180.捕获单元710可以包括图像传感器220和方向调整单元705(如图7所示)。电源单元720可以包括移动电源520和处理器210。电源单元720还可以包括先前讨论的可以是可穿戴装置110的一部分的元件的任何组合,包括但不限于无线收发器530、反馈输出单元230、存储器550和数据端口570。
181.连接器730可包括夹子715或设计成将捕获单元710和电源单元720卡入衣物750的其他机械连接,如图8所示。如图所示,夹子715可以在其边界连接到捕获单元710和电源单元720中的每个,并且可以围绕衣物750的物品的边缘将捕获单元710和电源单元720固定到位,连接器730还可以包括电源电缆760和数据电缆770。电源电缆760可以能够将功率从移动电源520传送到捕获单元710的图像传感器220。电源电缆760还可以配置为向捕获单元710的任何其他元件提供功率,例如,方向调整单元705。数据电缆770可以能够将捕获单元710中的图像传感器220的捕获图像数据传送到电源单元720中的处理器800。数据电缆770还可以进一步能够在捕获单元710和处理器800之间传送附加数据,例如方向调整单元705的控制指令。
182.图9是符合本公开的实施例的穿戴可穿戴装置110的用户100的示意图。如图9所示,捕获单元710位于用户100的衣服750的外表面上。捕获单元710经由围绕衣物750的边缘的连接器730连接到电源单元720(在该图示中未看到)。
183.在一些实施例中,连接器730可包括柔性印刷电路板(pcb)。图10示出了示例性实施例,其中连接器730包括柔性印刷电路板765。柔性印刷电路板765可以包括捕获单元710和电源单元720之间的数据连接和电源连接。因此,在一些实施例中,柔性印刷电路板765可用于替换电源电缆760和数据电缆770。在替代实施例中,除了电源电缆760和数据电缆770中的至少一个之外,还可以包括柔性印刷电路板765。在本文讨论的各种实施例中,柔性印刷电路板765可以替代电源电缆760和数据电缆770,或者可以除了电源电缆760和数据电缆770之外包括柔性印刷电路板765。
184.图11是符合本公开的可穿戴装置的另一实施例的示意图,该可穿戴装置可固定在衣物上。如图11所示,连接器730可以相对于捕获单元710和电源单元720位于中心。连接器730的中心位置可便于通过衣服750中的孔(诸如,例如,衣服750中现有的纽扣孔或设计用于容纳可穿戴装置110的衣服750中的专用孔)将装置110附在衣服750上。
185.图12是可固定在衣物上的可穿戴装置110的又一实施例的示意图。如图12所示,连接器730可以包括第一磁体731和第二磁体732。第一磁体731和第二磁体732可以将捕获单元710固定到电源单元720,并且衣物位于第一磁体731和第二磁体732之间。在包括第一磁体731和第二磁体732的实施例中,还可以包括电源电缆760和数据电缆770。在这些实施例
中,电源电缆760和数据电缆770可以是任何长度,并且可以在捕获单元710和电源单元720之间提供灵活的功率和数据连接。包括第一磁体731和第二磁体732的实施例可进一步包括除了或代替电源电缆760和/或数据电缆770的柔性pcb 765连接。在一些实施例中,第一磁体731或第二磁体732可由包含金属材料的物体代替。
186.图13是可固定在衣物上的可穿戴装置110的又一实施例的示意图。图13示出了其中可以在捕获单元710和电源单元720之间无线传输功率和数据的实施例。如图13所示,第一磁体731和第二磁体732可以设置为连接器730,以将捕获单元710和电源单元720固定到衣物750上。功率和/或数据可经由任何合适的无线技术(例如,磁耦合和/或电容耦合、近场通信技术、射频传输和任何其他适合于跨短距离传输数据和/或功率的无线技术)在捕获单元710和电源单元720之间传输。
187.图14示出了可穿戴装置110的又一实施例,该可穿戴装置110可固定在用户的衣物750上。如图14所示,连接器730可以包括为接触适配而设计的特征。例如,捕获单元710可以包括具有空心中心的环733,该空心中心具有略大于位于电源单元720上的盘状突起734的直径。当在它们之间与衣物750的织物压在一起时,盘状突起734可紧密地适配在环733内,从而将捕获单元710固定到电源单元720。图14示出了不包括捕获单元710和电源单元720之间的任何布线或其他物理连接的实施例。在本实施例中,捕获单元710和电源单元720可以无线地传送功率和数据。在替代实施例中,捕获单元710和电源单元720可以经由电缆760、数据电缆770和柔性印刷电路板765中的至少一个来传送功率和数据。
188.图15示出了与本文描述的实施例一致的电源单元720的另一方面。电源单元720可以被配置为位于直接靠着用户的皮肤。为了便于这样的定位,电源单元720还可以包括至少一个涂有生物相容性材料740的表面。生物相容性材料740可包括当在皮肤上穿戴较长时间时不会与用户的皮肤产生负面反应的材料。此类材料可包括例如硅酮、ptfe、聚酰亚胺胶带、聚酰亚胺、钛、镍钛合金、铂等。同样如图15所示,电源单元720的尺寸可以使得电源单元的内部容积基本上由移动电源520填充。也就是说,在一些实施例中,电源单元720的内部容积可以使得该容积不容纳除移动电源520之外的任何附加组件。在一些实施例中,移动电源520可利用其接近用户皮肤的优点。例如,移动电源520可以使用珀耳帖效应来产生功率和/或对电源充电。
189.在进一步的实施例中,可固定到衣物的装置可进一步包括与封装在电源单元720中的电源520相关联的保护电路。图16示出了包括保护电路775的示例性实施例。如图16所示,保护电路775可以相对于电源单元720远离放置。在替代实施例中,保护电路775还可以位于捕获单元710、柔性印刷电路板765或电源单元720中。
190.保护电路775可被配置为保护图像传感器220和/或捕获单元710的其他元件免于由移动电源520产生的潜在危险电流和/或电压。保护电路775可包括诸如电容器、电阻器、二极管、电感器等无源组件,以向捕获单元710的元件提供保护。在一些实施例中,保护电路775还可以包括有源组件,诸如晶体管,以向捕获单元710的元件提供保护。例如,在一些实施例中,保护电路775可以包括一个或多个用作保险丝的电阻器。每个保险丝可包括当流过保险丝的电流超过预定极限(例如,500毫安、900毫安、1安培、1.1安培、2安培、2.1安培、3安培等)时熔化的导线或带材(从而制动图像捕获单元710的电路和电源单元720的电路之间的连接)。任何或所有先前描述的实施例可以包括保护电路775。
191.在一些实施例中,可穿戴装置可以经由任何已知的无线标准(例如,蜂窝、wi
‑
fi、等)、或经由近场电容耦合、其他短程无线技术或经由有线连接通过一个或多个网络向计算设备(例如,智能电话、平板、手表、计算机等)传输数据。类似地,可穿戴装置可以经由任何已知的无线标准(例如,蜂窝、wi
‑
fi、等)、或经由近场电容耦合、其他短程无线技术或经由有线连接通过一个或多个网络从计算设备接收数据。发送到可穿戴装置和/或由无线装置接收的数据可以包括图像、图像的部分、与出现在分析的图像中的信息相关的或与分析的音频相关联的标识符,或者表示图像和/或音频数据的任何其他数据。例如,可以分析图像,并且可以将与图像中发生的活动相关的标识符发送到计算设备(例如,“配对设备”)。在本文描述的实施例中,可穿戴装置可以本地(在可穿戴装置上)和/或远程(经由计算设备)处理图像和/或音频。此外,在本文所描述的实施例中,可穿戴装置可以将与图像和/或音频的分析相关的数据传输到计算设备,以便进一步分析、显示和/或传输到另一设备(例如,配对设备)。此外,配对设备可以执行一个或多个应用(app),以处理、显示和/或分析从可穿戴装置接收的数据(例如,标识符、文本、图像、音频等)。
192.一些公开的实施例可以涉及用于确定至少一个关键字的系统、设备、方法和软件产品。例如,可以基于由装置110收集的数据来确定至少一个关键字。可以基于至少一个关键字来确定至少一个搜索查询。至少一个搜索查询可以被发送到搜索引擎。
193.在一些实施例中,可以基于由图像传感器220捕获的至少一个或多个图像来确定至少一个关键字。在某些情况下,可以从存储在存储器中的关键字池中选择至少一个关键字。在某些情况下,可以对由图像传感器220捕获的至少一幅图像执行光学字符识别(ocr),并且可以基于ocr结果确定至少一个关键字。在某些情况下,可以分析由图像传感器220捕获的至少一个图像以辨识:人、对象、位置、场景等。此外,可以基于被辨识的人、对象、位置、场景等确定至少一个关键字。例如,至少一个关键字可以包括:人的姓名、对象名称、地点名称、日期、运动队名称、电影名称、书籍名称等。
194.在一些实施例中,可以基于用户的行为来确定至少一个关键字。可以基于对由图像传感器220捕获的一个或多个图像的分析来确定用户的行为。在一些实施例中,可以基于用户和/或其他人的活动来确定至少一个关键字。可以分析由图像传感器220捕获的一个或多个图像以识别出现在由图像传感器220捕获的一个或多个图像中的用户和/或其他人的活动。在一些实施例中,可以基于装置110捕获的至少一个或多个音频段来确定至少一个关键字。在一些实施例中,可以至少基于与用户相关联的gps信息来确定至少一个关键字。在一些实施例中,可以至少基于当前时间和/或日期来确定至少一个关键字。
195.在一些实施例中,可以基于至少一个关键字确定至少一个搜索查询。在某些情况下,至少一个搜索查询可以包括至少一个关键字。在某些情况下,至少一个搜索查询可以包括用户提供的至少一个关键字和附加关键字。在某些情况下,至少一个搜索查询可以包括至少一个关键字和一个或多个图像,诸如由图像传感器220捕获的图像。在某些情况下,至少一个搜索查询可以包括至少一个关键字和一个或多个音频段,诸如由装置110捕获的音频段。
196.在一些实施例中,至少一个搜索查询可以被发送到搜索引擎。在一些实施例中,可以向用户提供由搜索引擎响应于至少一个搜索查询而提供的搜索结果。在一些实施例中,
至少一个搜索查询可用于访问数据库。
197.例如,在一个实施例中,关键字可以包括诸如喹诺亚的食品的类别的名称或食品产品的品牌名称;搜索将输出与期望的消费量、关于营养状况的事实等相关的信息。在另一个示例中,在一个实施例中,关键字可以包括餐厅的名称,并且搜索将输出与餐厅相关的信息,诸如菜单、开放时间、评论等。餐厅的名称可以使用在标牌图像上的ocr、使用gps信息等获得。在另一个示例中,在一个实施例中,关键字可以包括人的名称,并且搜索将提供来自该人的社交网络简档的信息。可以使用附着在该人衬衫上的姓名标签的图像上的ocr、使用面部辨识算法等获得该人的姓名。在另一个示例中,在一个实施例中,关键字可以包括书籍的名称,并且搜索将输出与该书相关的信息,诸如评论、销售统计、关于该书的作者的信息等等。在另一个示例中,在一个实施例中,关键字可以包括电影的名称,并且搜索将输出与电影相关的信息,诸如评论、票房统计、关于电影的放映的信息、放映时间等。在另一个示例中,在一个实施例中,关键字可以包括运动队的名称,并且搜索将输出与运动队相关的信息,诸如统计、最新结果、未来时间表、关于运动队队员的信息等。例如,可以使用音频辨识算法获得运动队的名称。
198.基于照相机的定向助听器
199.如前所述,所公开的实施例可以包括响应于处理环境中的至少一个图像,向一个或多个辅助设备提供反馈,例如听觉和触觉反馈。在一些实施例中,辅助设备可以是耳机或用于向用户提供听觉反馈的其他设备,例如助听器。传统助听器通常使用麦克风来放大用户的环境中的声音。然而,这些传统系统通常不能区分对设备穿戴者特别重要的声音,或者只能在有限的基础上进行区分。使用所公开实施例的系统和方法,提供了对传统助听器的各种改进,如下文详细描述的。
200.在一个实施例中,可以提供基于照相机的定向助听器,用于基于用户的注视方向选择性地放大声音。助听器可以与诸如装置110的图像捕获设备通信,以确定用户的注视方向。该注视方向可用于隔离和/或选择性地放大从该方向接收的声音(例如,来自用户注视方向上的个体的语音等)。可以抑制、衰减、过滤等从除用户注视方向之外的方向接收的声音。
201.图17a是根据公开的实施例的用户100穿戴用于基于照相机的听力接口设备1710的装置110的示例的示意图。如图所示,用户100可以穿着物理连接到用户100的衬衫或其他衣物的装置110。与所公开的实施例一致,如前面所述,装置110可以被定位在其它位置。例如,装置110可以物理地连接到项链、皮带、眼镜、腕带、按钮等。装置110可以被配置为与诸如听力接口设备1710的听力接口设备通信。这种通信可以通过有线连接,或者可以无线地进行(例如,使用蓝牙
tm
,nfc或无线通信的形式)。在一些实施例中,还可以包括一个或多个附加设备,诸如计算设备120。因此,本文中描述的关于装置110或处理器210的一个或多个过程或功能可以由计算设备120和/或处理器540执行。
202.听力接口设备1710可以是配置成向用户100提供听觉反馈的任何设备。听力接口设备1710可以对应于如上所述的反馈输出单元230,因此,反馈输出单元230的任何描述也可以应用于听力接口设备1710。在一些实施例中,听力接口设备1710可以与反馈输出单元230分离,并且可以被配置为从反馈输出单元230接收信号。如图17a所示,听力接口设备1710可以被放置在用户100的一只耳朵或两只耳朵中,类似于传统的听力接口设备。听力接
口设备1710可以是各种样式的,包括在耳道内、完全在耳道内、在耳内、在耳后、在耳上、在耳道中的接收器、开放式适配或各种其他样式。听力接口设备1710可以包括用于向用户100提供听觉反馈的一个或多个扬声器、用于检测用户100的环境中的声音的麦克风,内部电子、处理器、存储器等。在一些实施例中,除了麦克风或代替麦克风,听力接口设备1710可以包括一个或多个通信单元,尤其是一个或多个接收器,用于从装置110接收信号并将信号传送给用户100。
203.听力接口设备1710可以具有各种其他配置或放置位置。在一些实施例中,如图17a所示,听力接口设备1710可包括骨传导耳机1711。骨传导耳机1711可通过手术植入,并可通过将声音振动骨传导到内耳向用户100提供听觉反馈。听力接口设备1710还可以包括一个或多个耳机(例如无线耳机、耳上耳机等)或由用户100携带或穿戴的便携式扬声器。在一些实施例中,听力接口设备1710可以集成到其他设备中,诸如用户的蓝牙
tm
耳机、眼镜、头盔(如摩托车头盔、自行车头盔等)、帽子等。
204.装置110可被配置为确定用户100的用户注视方向1750。在一些实施例中,可以通过监控用户100的下巴或另一身体部分或面部相对于照相机传感器的光轴1751的方向来跟踪用户注视方向1750。装置110可以被配置为例如使用图像传感器220捕获用户的周围环境的一个或多个图像。捕获的图像可包括用户100的下巴的表示,其可用于确定用户注视方向1750。处理器210(和/或处理器210a和210b)可被配置为使用各种图像检测或处理算法(例如,使用卷积神经网络(cnn)、尺度不变特征变换(sift)、定向梯度直方图(hog)特征或其他技术)。基于检测到的用户100的下巴的表示,可以确定注视方向1750。可以部分地通过将检测到的用户100的下巴的表示与照相机传感器的光轴1751进行比较来确定注视方向1750。例如,光轴1751可以在每个图像中是已知的或固定的,并且处理器210可以通过比较用户100的下巴的表示角度与光轴1751的方向来确定注视方向1750。虽然使用用户100的下巴的表示来描述该过程,但是可以检测用于确定用户注视方向1750的各种其他特征,包括用户的脸、鼻子、眼睛、手等。
205.在其它实施例中,用户注视方向1750可以与光轴1751更紧密地对准。例如,如上所述,如图1a所示,装置110可以附在用户100的一副眼镜上。在本实施例中,用户注视方向1750可以与光轴1751的方向相同或接近。因此,可以基于图像传感器220的视图来确定或近似用户注视方向1750。
206.图17b是与本公开一致的可固定到衣物的装置的实施例的示意图。如图17a所示,装置110可以固定在一件衣服上,诸如用户110的衬衫。如上所讨论的,装置110可以固定在其它衣物(诸如用户100的腰带或裤子)上。装置110可以具有一个或多个照相机1730,其可以对应于图像传感器220。照相机1730可以被配置为捕获用户100的周围环境的图像。在一些实施例中,照相机1730可被配置为在捕获用户周围环境的相同图像中检测用户的下巴的表示,其可用于本公开中描述的其它功能。在其它实施例中,照相机1730可以是专用于确定用户注视方向1750的辅助或独立照相机。
207.装置110还可以包括一个或多个麦克风1720,用于从用户100的环境捕获声音。麦克风1720还可以被配置为确定用户100的环境中声音的方向性。例如,麦克风1720可包括一个或多个定向麦克风,其可对在特定方向上拾取声音更敏感。例如,麦克风1720可包括单向麦克风,其设计用于拾取来自单个方向或小范围方向的声音。麦克风1720还可以包括心形
麦克风,其可以对来自前面和侧面的声音敏感。麦克风1720还可以包括麦克风阵列,麦克风阵列可以包括附加麦克风,诸如装置110前面的麦克风1721,或者放置在装置110侧面的麦克风1722。在一些实施例中,麦克风1720可以是用于捕获多个音频信号的多端口麦克风。图17b中所示的麦克风仅作为示例,并且可以使用麦克风的任何适当数量、配置或位置。处理器210可被配置为区分用户100的环境中的声音并确定每个声音的近似方向性。例如,使用麦克风1720的阵列,处理器210可以比较麦克风1720中单个声音的相对定时或幅度,以确定相对于装置100的方向性。
208.作为其他音频分析操作之前的初步步骤,可以使用任何音频分类技术对从用户的环境捕获的声音进行分类。例如,声音可以被分类为包含音乐、音调、笑声、尖叫等的片段。各个段的指示可以记录在数据库中,并且可以证明对于生活记录应用非常有用。作为一个示例,所记录的信息可以使得系统能够在用户遇到另一个人时检索和/或确定情绪。此外,这样的处理相对快速且有效,并且不需要显著的计算资源,并且将信息传输到目的地不需要显著的带宽。此外,一旦音频的某些部分被分类为非讲话,就可以使用更多的计算资源来处理其他部分。
209.基于所确定的用户注视方向1750,处理器210可选择性地调节或放大来自与用户注视方向1750相关联的区域的声音。图18是示出用于使用与本公开一致的基于照相机的助听器的示例性环境的示意图。麦克风1720可以检测用户100的环境中的一个或多个声音1820、1821和1822。基于由处理器210确定的用户注视方向1750,可以确定与用户注视方向1750相关联的区域1830。如图18所示,区域1830可以由基于用户注视方向1750的圆锥体或方向范围来定义。角度范围可以由一个角度θ定义,如图18所示。角度θ示。可以是用于定义在用户100的环境中调节声音的范围(例如,10度、20度、45度)的任何合适的角度。
210.处理器210可以被配置为基于区域1830在用户100的环境中选择性地调节声音。调节后的音频信号可以发送到听力接口设备1710,因此可以向用户100提供与用户的注视方向相对应的听觉反馈。例如,处理器210可以确定声音1820(例如可以对应于个体1810的语音,或与噪声相对应)在区域1830内。处理器210随后可以对从麦克风1720接收到的音频信号执行各种调节技术。调节可以包括相对于其它音频信号放大被确定为对应于声音1820的音频信号。放大可以通过数字方式实现,例如,通过相对于其他信号处理与1820相关联的音频信号。放大也可以通过改变麦克风1720的一个或多个参数以聚焦于从与用户注视方向1750相关联的区域1830(例如感兴趣区域)发出的音频声音来实现。例如,麦克风1720可以是定向麦克风,并且处理器210可以执行操作以将麦克风1720聚焦于在声音1820或区域1830内的其他声音上。可以使用用于放大声音1820的各种其他技术,诸如使用波束形成麦克风阵列、声学望远镜技术等。
211.调节还可包括衰减或抑制从区域1830之外的方向接收的一个或多个音频信号。例如,处理器1820可以衰减声音1821和1822。类似于声音的放大1820,声音的衰减可以通过处理音频信号,或者通过改变与一个或多个麦克风1720相关联的一个或多个参数以定向焦点远离从区域1830外部发出的声音来发生。
212.在一些实施例中,调节可进一步包括改变与声音1820相对应的音频信号的音调,以使声音1820对用户100更加可感知。例如,用户100可以对特定范围内的音调具有较低的灵敏度,并且音频信号的调节可以调整声音1820的音高,以使其对用户100更加可感知。例
如,用户100可能在高于10khz的频率中经历听力损失。因此,处理器210可以将更高的频率(例如,在15khz处)重新映射到10khz。在一些实施例中,处理器210可被配置为改变与一个或多个音频信号相关联的讲话速率。因此,处理器210可以被配置为例如使用语音活动检测(vad)算法或技术来检测麦克风1720接收的一个或多个音频信号中的语音。如果声音1820被确定为对应于例如来自个体1810的语音或讲话,则处理器220可被配置为改变声音1820的回放速率。例如,可以降低个体1810的讲话速率,以使检测到的讲话对用户100更加可感知。可以执行各种其他处理,诸如调整声音1820的音调以保持与原始音频信号相同的音高,或者减少音频信号内的噪声。如果已经对与声音1820相关联的音频信号执行了语音辨识,则调节还可以包括基于检测到的讲话调整音频信号。例如,处理器210可以引入停顿或者增加单词和/或句子之间的停顿的持续时间,这可以使得讲话更容易理解。
213.然后,可将调节后的音频信号发送到听力接口设备1710并为用户100产生。因此,在调节后的音频信号中,声音1820可能更容易被用户100听到,比声音1821和1822(可能表示环境中的背景噪声)更大和/或更容易区分。
214.图19是示出与公开的实施例一致的用于选择性地放大从检测到的用户的注视方向发出的声音的示例性过程1900的流程图。过程1900可以由与装置110相关联的一个或多个处理器执行,例如处理器210。在一些实施例中,过程1900的一些或全部可以在装置110外部的处理器上执行。换句话说,处理器执行过程1900可以包括在作为麦克风1720和照相机1730的公共外壳中,或者可以包括在第二外壳中。例如,过程1900的一个或多个部分可以由听力接口设备1710或诸如计算设备120的辅助设备中的处理器来执行。
215.在步骤1910中,过程1900可以包括接收由照相机捕获的来自用户的环境的多个图像。照相机可以是诸如装置110的照相机1730的可穿戴照相机。在步骤1912中,过程1900可包括接收代表由至少一个麦克风接收的声音的音频信号。麦克风可以被配置为从用户的环境捕获声音。例如,如上所述,麦克风可以是麦克风1720。因此,麦克风可以包括定向麦克风、麦克风阵列、多端口麦克风或各种其他类型的麦克风。在一些实施例中,麦克风和可穿戴照相机可以包括在公共外壳中,例如装置110的外壳。执行过程1900的一个或多个处理器也可以包括在外壳中或者可以包括在第二外壳中。在这样的实施例中,(多个)处理器可以被配置为经由无线链路(例如蓝牙
tm
、nfc等)从公共外壳接收图像和/或音频信号。因此,公共外壳(例如,装置110)和第二外壳(例如,计算设备120)还可以包括发射器或各种其他通信组件。
216.在步骤1914中,过程1900可以包括基于对多个图像中的至少一个图像的分析来确定用户的注视方向。如上所述,可以使用各种技术来确定用户注视方向。在一些实施例中,可以至少部分地基于在一个或多个图像中检测到的用户的下巴的表示来确定注视方向。如上所述,可以处理图像以确定下巴相对于与可穿戴照相机的光轴的指向方向。
217.在步骤1916中,过程1900可以包括引起对由至少一个麦克风从与用户的注视方向相关联的区域接收的至少一个音频信号的选择性调节。如上所述,可以基于在步骤1914中确定的用户注视方向来确定区域。该范围可与关于注视方向的角宽度相关联(例如,10度、20度、45度等)。如上所述,可以对音频信号执行各种形式的调节。在一些实施例中,调节可包括改变音频信号的音调或回放速度。例如,调节可以包括改变与音频信号相关联的讲话速率。在一些实施例中,调节可以包括相对于从与用户的注视方向相关联的区域外部接收
的其他音频信号来放大音频信号。可以通过各种方式来执行放大,诸如操作配置成聚焦于从该区域发出的音频声音的定向麦克风,或者改变与麦克风相关联的一个或多个参数以使麦克风聚焦于从该区域发出的音频声音。放大可以包括衰减或抑制麦克风从与用户110的注视方向相关联的区域之外的方向接收的一个或多个音频信号。
218.在步骤1918中,处理1900可以包括使得至少一个调节后的音频信号发送到配置为向用户的耳朵提供声音的听力接口设备。例如,可以将调节后的音频信号发送到听力接口设备1710,该听力接口设备1710可向用户100提供与音频信号相对应的声音。执行过程1900的处理器可以进一步配置为使得代表背景噪声的一个或多个音频信号传输到听力接口设备,该音频信号可以相对于至少一个调节后的音频信号进行衰减。例如,处理器220可以配置为发送与声音1820、1821和1822相对应的音频信号。然而,与1820相关的信号可以根据声音1820在区域1830内的确定,以不同于声音1821和1822的方式(例如放大)来调整。在一些实施例中,听力接口设备1710可以包括与耳机相关联的扬声器。例如,听力接口设备可以至少部分插入用户的耳朵中,以向用户提供音频。听力接口设备也可以是耳朵外部的,诸如耳后听力设备、一个或多个耳机、小型便携式扬声器等。在一些实施例中,听力接口设备可以包括骨传导麦克风,其配置为通过用户头部的骨骼的振动向用户提供音频信号。此类设备可以与用户皮肤的外部接触,也可以通过手术植入并附着在用户的骨骼上。
219.具有语音和/或图像辨识的助听器
220.与公开的实施例一致,助听器可以选择性地放大与被辨识的个体的语音相关联的音频信号。助听器系统可以存储被辨识的人的语音特征和/或面部特征,以帮助识别和选择性放大。例如,当个体进入装置110的视野时,该个体可以被辨识为已经被引入到设备中的个体,或者过去可能已经与用户100交互过的个体(例如,朋友、同事、亲戚、先前的熟人等)。因此,与被辨识的个体的语音相关联的音频信号可以相对于用户的环境中的其他声音被隔离和/或选择性地放大。与从个体方向以外的方向接收的声音相关联的音频信号可以被抑制、衰减、滤波等。
221.用户100可以穿戴类似于上面讨论的基于照相机的助听器设备的助听器设备。例如,助听器设备可以是听力接口设备1720,如图17a所示。听力接口设备1710可以是配置成向用户100提供听觉反馈的任何设备。听力接口设备1710可以被放置在用户100的一个或两个耳朵中,类似于传统的听力接口设备。如上所述,听力接口设备1710可以是各种样式的,包括在耳道内、完全在耳道内、在耳内、在耳后、在耳上、在耳道中的接收器、开放式配合或各种其他样式。听力接口设备1710可以包括用于向用户100提供听觉反馈的一个或多个扬声器、用于从诸如装置110的另一系统接收信号的通信单元、用于在用户100的环境中检测声音的麦克风、内部电子、处理器、存储器,听力接口设备1710可以对应于反馈输出单元230,或者可以与反馈输出单元230分离,并且可以被配置为从反馈输出单元230接收信号。
222.在在一些实施例中,听力接口设备1710可以包括骨传导耳机1711,如图17a所示。骨传导耳机1711可以通过手术植入,并且可以通过将声音振动骨传导到内耳向用户100提供听觉反馈。听力接口设备1710还可包括一个或多个耳机(例如,无线耳机、耳上耳机等)或由用户100携带或穿戴的便携式扬声器。在一些实施例中,听力接口设备1710可以集成到其他设备中,诸如蓝牙
tm
、使用者的耳机、眼镜、头盔(如摩托车头盔、自行车头盔等)、帽子等。
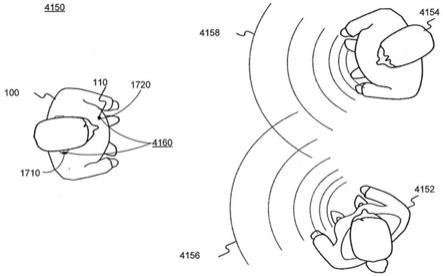
223.听力接口设备1710可以被配置为与诸如装置110的照相机设备通信。这种通信可
以通过有线连接,或者可以无线地(例如,使用蓝牙
tm
、nfc或无线通信的形式)进行。如上所述,装置110可以由用户100以各种配置穿戴,包括物理地连接到衬衫、项链、腰带、眼镜、腕带、按钮或与用户100相关联的其他物品。在一些实施例中,还可以包括一个或多个附加设备,例如计算设备120。因此,本文中描述的关于装置110或处理器210的一个或多个过程或功能可以由计算设备120和/或处理器540执行。
224.如上所述,装置110可以包括至少一个麦克风和至少一个图像捕获设备。装置110可包括麦克风1720,如关于图17b所述。麦克风1720可以被配置为确定用户100的环境中声音的方向性。例如,麦克风1720可以包括一个或多个定向麦克风、麦克风阵列、多端口麦克风等。图17b中所示的麦克风仅作为示例,并且可以使用麦克风的任何适当数量、配置或位置。处理器210可被配置为区分用户100的环境中的声音并确定每个声音的近似方向性。例如,使用麦克风1720的阵列,处理器210可以比较麦克风1720中单个声音的相对定时或幅度,以确定相对于装置100的方向性。装置110可包括一个或多个照相机,例如照相机1730,其可对应于图像传感器220。照相机1730可被配置为捕获用户100的周围环境的图像。
225.装置110可以被配置为辨识用户100环境中的个体。图20a是示出与本公开一致的用于使用具有语音和/或图像辨识的助听器的示例性环境的示意图。装置110可配置为辨识与用户100环境中的个体2010相关联的面部2011或语音2012。例如,装置110可以配置成使用照相机1730捕获用户100的周围环境的一个或多个图像。所捕获的图像可以包括被辨识的个体2010的表示,该个体2010可以是用户100的朋友、同事、亲戚或先前的熟人。处理器210(和/或处理器210a和210b)可配置为使用各种面部辨识技术(如元件2011所表示)分析捕获的图像并检测被辨识的用户。因此,装置110,或具体存储器550可包括一个或多个面部或语音辨识组件。
226.图20b示出了包括与本公开一致的面部和语音辨识组件的装置110的示例性实施例。装置110在图20b中以简化形式示出,并且装置110可以包含附加元件或者可以具有替代配置,例如,如图5a
‑
5c所示。存储器550(或550a或550b)可包括面部辨识组件2040和语音辨识组件2041。如图6所示,这些组件可以替代方向识别模块601、方向调整模块602和运动跟踪模块603,或者作为方向识别模块601、方向调整模块602和运动跟踪模块603的补充。组件2040和2041可以包含用于由包括在可穿戴装置中的至少一个处理设备(例如处理器210)执行的软件指令。组件2040和2041仅作为示例示出在存储器550内,并且可以位于系统内的其他位置。例如,组件2040和2041可以位于听力接口设备1710、计算设备120、远程服务器或另一关联设备中。
227.面部辨识组件2040可被配置为在用户100的环境中识别一个或多个面部。例如,面部辨识组件2040可以识别个体2010的面部2011上的面部特征,诸如眼睛、鼻子、颧骨、下巴或其他特征。面部辨识组件2040随后可分析这些特征的相对大小和位置以识别用户。面部辨识组件2040可以利用一个或多个算法来分析检测到的特征,诸如主成分分析(例如,使用特征脸)、线性判别分析、弹性束图匹配(例如,使用fisherface)、局部二元模式直方图(lbph)、尺度不变特征变换(sift),加速鲁棒特征(surf)等。其他面部辨识技术,诸如三维识别、皮肤纹理分析和/或热成像,也可用于识别个体。除了面部特征之外的其他特征也可用于识别,诸如身高、体型或个体的其他区别特征。
228.面部辨识组件2040可以访问与用户100相关联的数据库或数据,以确定检测到的
面部特征是否对应于被辨识的个体。例如,处理器210可以访问数据库2050,该数据库2050包含关于用户100已知的个体的信息以及表示相关联的面部特征或其他识别特征的数据。此类数据可包括个体的一个或多个图像,或可用于通过面部辨识进行识别的代表用户面部的数据。数据库2050可以是能够存储关于一个或多个个体的信息的任何设备,并且可以包括硬盘驱动器、固态驱动器、web存储平台、远程服务器等。数据库2050可位于装置110内(例如,存储器550内)或装置110外部,如图20b所示。在一些实施例中,数据库2050可与社交网络平台(诸如脸书
tm
、领英
tm
tm
等)相关联。面部辨识组件2040还可以访问用户100的联系人列表,诸如用户电话上的联系人列表、基于web的联系人列表(诸如,通过outlook
tm
、skype
tm
、谷歌
tm
、salesforce
tm
等)或与听力接口设备1710相关的专用联系人列表。在一些实施例中,可由装置110通过先前的面部辨识分析来编译数据库2050。例如,处理器210可以被配置为将与在由装置110捕获的图像中辨识的一个或多个面部相关联的数据存储在数据库2050中。每次在图像中检测到面部时,可将检测到的面部特征或其他数据与数据库2050中先前识别的面部进行比较。如果个体先前已经被系统在超过某一阈值的数量的实例中辨识,如果个体已经被显式地引入到装置110等,则面部辨识组件2040可以确定该个体是用户100的被辨识的个体。
229.在一些实施例中,用户100可以访问数据库2050,诸如通过web接口、移动设备上的应用、或通过装置110或关联设备。例如,用户100可以选择哪些联系人可由装置110辨识和/或手动删除或添加某些联系人。在一些实施例中,用户或管理员可以训练面部辨识组件2040。例如,用户100可以选择确认或拒绝由面部辨识组件2040进行的识别,这可以提高系统的准确性。这种训练可以实时进行,因为个体2010正在被辨识,或者在稍后的某个时间。
230.其他数据或信息也可以通知面部辨识过程。在一些实施例中,处理器210可以使用各种技术来辨识个体2010的语音,如下面进一步详细描述的。被辨识的语音模式和检测到的面部特征可以单独使用或组合使用,以确定个体2010被装置110辨识。如上所述,处理器210还可确定用户注视方向1750,其可用于验证个体2010的身份。例如,如果用户100正朝着个体2010的方向看(特别是持续长时间段),这可以指示个体2010被用户100辨识,这可以用于增加面部辨识组件2040或其他识别装置的置信度。
231.处理器210还可以被配置为基于与个体2010的语音相关联的声音的一个或多个检测到的音频特征来确定个体2010是否被用户100辨识。返回到图20a,处理器210可以确定声音2020对应于用户2010的声音2012。处理器210可分析代表由麦克风1720捕获的声音2020的音频信号,以确定个体2010是否被用户100辨识。这可以使用语音辨识组件2041(图20b)来执行,并且可以包括一个或多个语音辨识算法,诸如隐马尔可夫模型、动态时间扭曲、神经网络或其他技术。语音辨识组件和/或处理器210可以访问数据库2050,数据库2050还可以包括一个或多个个体的声纹。语音辨识组件2041可以分析代表声音2020的音频信号,以确定语音2012是否匹配数据库2050中个体的声纹。因此,数据库2050可以包含与多个个体相关联的声纹数据,类似于上述存储的面部辨识数据。在确定匹配之后,个体2010可以被确定为用户100的被辨识的个体。这个过程可以单独使用,或者与上面描述的面部辨识技术结合使用。例如,可以使用面部辨识组件2040来辨识个体2010,并且可以使用语音辨识组件2041来验证个体2010,反之亦然。
232.在一些实施例中,装置110可以检测不在装置110视野内的个体的语音。例如,可以
通过扬声器电话、从后座等听到语音。在这样的实施例中,在视野中没有说话者的情况下,可以仅基于个体的语音来识别个体。处理器110可以如上所述分析个体的语音,例如,通过确定检测到的语音是否与数据库2050中个体的声纹匹配。
233.在确定个体2010是用户100的被辨识的个体之后,处理器210可以引起与被辨识的个体相关联的音频的选择性调节。调节后的音频信号可以被发送到听力接口设备1710,并且因此可以向用户100提供基于被辨识的个体调节后的音频。例如,调节可包括相对于其他音频信号放大被确定为对应于声音2020(其可对应于个体2010的语音2012)的音频信号。在一些实施例中,放大可以数字地完成,例如通过相对于其他信号处理与声音2020相关联的音频信号。可替代地或者可选地,可以通过改变麦克风1720的一个或多个参数以聚焦于与个体2010相关联的音频声音来实现放大。例如,麦克风1720可以是定向麦克风,并且处理器210可以执行将麦克风1720聚焦于声音2020的操作。可以使用用于放大声音的各种其他技术,例如使用波束形成麦克风阵列、声学望远镜技术等。
234.在一些实施例中,选择性调节可以包括衰减或抑制从与个体2010不相关联的方向接收的一个或多个音频信号。例如,处理器210可以衰减声音2021和/或2022。与声音2020的放大类似,声音衰减可通过处理音频信号或通过改变与麦克风1720相关联的一个或多个参数以定向焦点远离与个体2010不相关联的声音来发生。
235.选择性调节可以进一步包括确定个体2010是否在说话。例如,处理器210可以被配置为分析包含个体2010的表示的图像或视频,以例如基于检测到的被辨识的个体的嘴唇的运动来确定个体2010何时在说话。这也可以通过分析麦克风1720接收的音频信号来确定,例如通过检测个体2010的语音2012。在一些实施例中,选择性调节可以基于被辨识的个体是否在说话而动态发生(开始和/或终止)。
236.在一些实施例中,调节可以进一步包括改变对应于声音2020的一个或多个音频信号的音调,以使声音对用户100更加可感知。例如,用户100可能对特定范围内的音调具有较低的敏感度,并且音频信号的调节可以调整声音2020的音高。在一些实施例中,处理器210可以被配置为改变与一个或多个音频信号相关联的讲话速率。例如,声音2020可以被确定为对应于个体2010的声音2012。处理器210可以被配置为改变个体2010的讲话速率,以使检测到的讲话对用户100来说更加可感知。可以执行各种其他处理,例如调整声音2020的音调以保持与原始音频信号相同的音高,或者减少音频信号中的噪声。
237.在一些实施例中,处理器210可以确定与个体2010相关联的区域2030。区域2030可以相对于装置110或用户100与个体2010的方向相关联。可以使用照相机1730和/或麦克风1720使用上述方法来确定个体2010的方向。如图2所示。在图20a中,区域2030可以由基于个体2010的确定方向的圆锥或方向范围来定义。角度的范围可以由角度θ来定义,如图20a所示。角度θ可以是用于定义在用户100的环境中调节声音的范围的任何合适的角度(例如,10度,20度,45度)。随着个体2010相对于装置110的位置改变,可以动态计算区域2030。例如,当用户100转向时,或者如果个体1020在环境内移动,处理器210可以被配置为跟踪环境内的个体2010并动态更新区域2030。区域2030可以用于选择性调节,例如通过放大与区域2030相关联的声音和/或衰减被确定为从区域2030外部发出的声音。
238.然后,调节后的音频信号可以被传输到听力接口设备1710,并为用户100产生。因此,在调节后的音频信号中,声音2020(特别是声音2012)可以比声音2021和2022更大和/或
更容易区分,声音2021和2022可以表示环境中的背景噪声。
239.在一些实施例中,处理器210可以基于捕获的图像或视频执行进一步的分析,以确定如何选择性地调节与被辨识的个体相关联的音频信号。在一些实施例中,处理器210可以分析捕获的图像,以相对于其他个体选择性地调节与一个个体相关联的音频。例如,处理器210可以基于图像确定被辨识的个体相对于用户的方向,并且可以基于该方向确定如何选择性地调节与该个体相关联的音频信号。如果被辨识的个体正站在用户的前面,则与该用户相关联的音频可以相对于与站在用户侧面的个体相关联的音频被放大(或者以其他方式被选择性地调节)。类似地,处理器210可以基于与用户的接近度选择性地调节与个体相关联的音频信号。处理器210可以基于捕获的图像确定从用户到每个个体的距离,并且可以基于该距离选择性地调节与个体相关联的音频信号。例如,离用户更近的个体可能比离用户更远的个体优先权更高。
240.在一些实施例中,与被辨识的个体相关联的音频信号的选择性调节可以基于用户的环境中的个体的身份。例如,在图像中检测到多个个体的情况下,处理器210可以使用一种或多种面部辨识技术来识别个体,如上所述。与用户100已知的个体相关联的音频信号可以被选择性地放大或以其他方式被调节为优先于未知个体。例如,处理器210可以被配置为衰减或静音与用户的环境中的旁观者相关联的音频信号,诸如嘈杂的办公室伙伴等。在一些实施例中,处理器210还可以确定个体的层次结构,并基于个体的相对状态给出优先级。该层次结构可以基于个体在家庭或组织(例如,公司、运动队、俱乐部等)中相对于用户的位置。例如,用户的老板可能比同事或维护人员的级别高,因此在选择性调节过程中可能具有优先权。在一些实施例中,可以基于列表或数据库来确定层次结构。被系统辨识的个体可以被单独排序或者被分组到具有优先级的等级中。该数据库可以专门为此目的而维护,也可以从外部访问。例如,数据库可以与用户的社交网络(例如,脸书
tm
、领英
tm
等)相关联并且个体可以基于他们的分组或与用户的关系来排列优先级。例如,被识别为“密友”或家人的个体可能优先于用户的熟人。
241.选择性调节可以基于基于捕获的图像确定的一个或多个个体的确定行为。在一些实施例中,处理器210可以被配置为确定图像中的个体的注视方向。因此,选择性调节可以基于其他个体对被辨识的个体的行为。例如,处理器210可以选择性地调节与一个或多个其他用户正在注视的第一个体相关联的音频。如果个体的注意力转移到第二个体,则处理器210可以切换到选择性地调节与第二用户相关联的音频。在一些实施例中,处理器210可以被配置为基于被辨识的个体是在对用户说话还是对另一个个体说话来选择性地调节音频。例如,当被辨识的个体正在对用户说话时,选择性调节可以包括相对于从与被辨识的个体相关联的区域之外的方向接收的其他音频信号放大与被辨识的个体相关联的音频信号。当被辨识的个体正在与另一个个体说话时,选择性调节可以包括相对于从与被辨识的个体相关联的区域之外的方向接收的其他音频信号来衰减音频信号。
242.在一些实施例中,处理器210可以访问个体的一个或多个声纹,这可以促进个体2010的语音2012相对于其他声音或语音的选择性调节。具有说话者的声纹,特别是高质量的声纹,可以提供快速有效的说话者分离。例如,当用户独自说话时,优选地在安静的环境中,可以收集高质量的声纹。通过具有一个或多个说话者的声纹,可以使用滑动时间窗口几乎实时地(例如以最小的延迟)分离正在进行的语音信号。延迟可以是例如10ms、20ms、
30ms、50ms、100ms等。取决于声纹的质量、捕获的音频的质量、说话者和其他(多个)说话者之间的特征差异、可用的处理资源、所需的分离质量等,可以选择不同的时间窗口。在一些实施例中,可以从个体单独说话的谈话片段中提取声纹,然后用于在谈话的稍后阶段分离个体的语音,而不管该个体的语音是否被辨识。
243.可以如下执行语音分离:可以从单个说话者的干净音频中提取频谱特征,也称为频谱属性、频谱包络或频谱图,并将其馈送到预先训练的第一神经网络中,第一神经网络基于提取的特征生成或更新说话者语音的签名。音频可以是例如一秒钟的干净语音。输出签名可以是表示说话者语音的向量,使得向量和从同一说话者的语音中提取的另一个向量之间的距离通常小于向量和从另一个说话者的语音中提取的向量之间的距离。说话者的模型可以从捕获的音频中预先生成。可替换地或附加地,模型可以在只有说话者说话的音频片段之后生成,随后是另一个听到说话者和另一个说话者(或背景噪声)并且需要分离的片段。
244.然后,为了从噪声音频中的附加说话者或背景噪声中分离说话者的语音,第二预先训练的神经网络可以接收噪声音频和说话者的签名,并输出从噪声音频中提取的说话者的语音的音频(也可以表示为属性),该音频与其他讲话或背景噪声分离。应当理解,可以使用相同或附加的神经网络来分离多个说话者的语音。例如,如果有两个可能的说话者,可以激活两个神经网络,每个神经网络具有相同噪声输出和两个说话者之一的模型。可替换地,神经网络可以接收两个或更多个说话者的语音签名,并分别输出说话者中的每一个的语音。因此,系统可以生成两个或更多不同的音频输出,每个音频输出包括相应说话者的讲话。在一些实施例中,如果分离是不可能的,则输入语音可以仅从背景噪声中清除。
245.图21是示出与所公开的实施例一致的用于选择性地放大与被辨识的个体的语音相关联的音频信号的示例性过程2100的流程图。过程2100可由与装置110相关联的一个或多个处理器(例如处理器210)执行。在一些实施例中,过程2100的部分或全部可在装置110外部的处理器上执行。换句话说,处理器执行过程2100可以包括在与麦克风1720和照相机1730相同的公共外壳中,或者可以包括在第二外壳中。例如,过程2100的一个或多个部分可以由听力接口设备1710或辅助设备(例如计算设备120)中的处理器执行。
246.在步骤2110中,过程2100可以包括接收由照相机捕获的来自用户的环境的多个图像。图像可以由诸如装置110的照相机1730的可穿戴照相机捕获。在步骤2112中,过程2100可以包括在多个图像的至少一个中识别被辨识的个体的表示。如上所述,处理器210可以使用面部辨识组件2040来辨识个体2010。例如,个体2010可以是用户的朋友、同事、亲戚或以前的熟人。处理器210可以基于与个体相关联的一个或多个检测到的面部特征来确定在多个图像中的至少一个图像中表示的个体是否是被辨识的个体。如上所述,处理器210还可以基于被确定为与个体的语音相关联的声音的一个或多个检测到的音频特征来确定个体是否被辨识。
247.在步骤2114中,过程2100可以包括接收代表由麦克风捕获的声音的音频信号。例如,装置110可以接收由麦克风1720捕获的代表声音2020、2021和2022的音频信号。因此,如上所述,麦克风可以包括定向麦克风、麦克风阵列、多端口麦克风或各种其他类型的麦克风。在一些实施例中,麦克风和可穿戴照相机可以包括在公共外壳中,诸如装置110的外壳。执行过程2100的一个或多个处理器(例如,处理器210)也可以包括在外壳中,或者可以被包
括在第二外壳中。在使用第二外壳的情况下,(多个)处理器可以被配置为经由无线链路(例如蓝牙
tm
、nfc等)从公共外壳接收图像和/或音频信号。因此,公共外壳(例如,装置110)和第二外壳(例如,计算设备120)还可以包括发射器,接收器或各种其他通信组件。
248.在步骤2116中,过程2100可包括引起至少一个麦克风从与至少一个被辨识的个体相关联的区域接收的至少一个音频信号的选择性调节。如上所述,可以基于基于多个图像或音频信号中的一个或多个的被辨识的个体的确定方向来确定区域。该范围可以与关于被辨识的个体的方向的角宽度相关联(例如,10度、20度、45度等)。
249.如上所述,可以对音频信号执行各种形式的调节。在一些实施例中,调节可以包括改变音频信号的音调或回放速度。例如,调节可以包括改变与音频信号相关联的讲话速率。在一些实施例中,调节可以包括音频信号相对于从与被辨识的个体相关联的区域外部接收的其他音频信号的放大。放大可以通过各种手段来执行,诸如定向麦克风的操作,该定向麦克风被配置为聚焦于从该区域发出的音频声音,或者改变与麦克风相关联的一个或多个参数以使麦克风聚焦于从该区域发出的音频声音。放大可以包括衰减或抑制麦克风从该区域之外的方向接收的一个或多个音频信号。在一些实施例中,步骤2116可以进一步包括基于对多个图像的分析来确定被辨识的个体正在说话,并且基于被辨识的个体正在说话的确定来触发选择性调节。例如,被辨识的个体正在说话的确定可以基于检测到的被辨识的个体的嘴唇的运动。在一些实施例中,选择性调节可以基于如上所述对捕获图像的进一步分析,例如,基于被辨识的个体的方向或接近度、被辨识的个体的身份、其他个体的行为等。
250.在步骤2118中,过程2100可以包括使得至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。例如,调节后的音频信号可以被传输到听力接口设备1710,听力接口设备1710可以向用户100提供对应于音频信号的声音。执行过程2100的处理器还可以被配置为使得向听力接口设备传输表示背景噪声的一个或多个音频信号,该背景噪声可以相对于至少一个调节后的音频信号被衰减。例如,处理器210可以被配置为发送对应于声音2020、2021和2022的音频信号。然而,基于声音2020在区域2030内的确定,可以相对于声音2021和2022放大与2020相关联的信号。在一些实施例中,听力接口设备1710可以包括与耳机相关联的扬声器。例如,听力接口设备1710可以至少部分地插入到用户的耳朵中,用于向用户提供音频。听力接口设备也可以在耳朵外部,诸如耳后听力设备、一个或多个耳机、小型便携式扬声器等。在一些实施例中,听力接口设备可以包括骨传导麦克风,其被配置为通过用户头部骨骼的振动向用户提供音频信号。这种装置可以放置成与使用者皮肤的外部接触,或者可以通过外科手术植入并附着到使用者的骨骼上。
251.除了辨识对用户100说话的个体的语音之外,上述系统和方法也可以用于辨识用户100语音。例如,语音辨识单元2041可以被配置为分析代表从用户的环境收集的声音的音频信号,以辨识用户100的语音。类似于被辨识的个体的语音的选择性调节,用户100的语音可以被选择性地调节。例如,声音可以由麦克风1720收集,或者由诸如移动电话(或链接到移动电话的设备)的另一设备的麦克风收集。对应于用户100的语音的音频信号可以选择性地传输到远程设备,例如,通过放大用户100的语音和/或衰减或消除除用户语音之外的所有声音。因此,可以收集和/或存储装置110的一个或多个用户的声纹,以便于检测和/或隔离用户的语音,如上面进一步详细描述的。
252.图22是示出与所公开的实施例一致的用于选择性地传输与被辨识的用户的语音
相关联的音频信号的示例性过程2200的流程图。过程2200可以由与装置110相关联的一个或多个处理器执行,例如处理器210。
253.在步骤2210中,过程2200可以包括接收代表由麦克风捕获的声音的音频信号。例如,装置110可以接收由麦克风1720捕获的代表声音2020、2021和2022的音频信号。因此,如上所述,麦克风可以包括定向麦克风、麦克风阵列、多端口麦克风或各种其他类型的麦克风。在步骤2212中,过程2200可以包括基于对接收到的音频信号的分析,识别代表用户的被辨识的别语音的一个或多个语音音频信号。例如,可以基于与用户相关联的声纹来辨识用户的语音,声纹可以存储在存储器550、数据库2050或其他合适的位置中。处理器210可以例如使用语音辨识组件2041来辨识用户的语音。处理器210可以使用滑动时间窗口几乎实时地(例如以最小的延迟)分离与用户相关联的正在进行的语音信号。可以根据上述方法通过提取音频信号的频谱特征来分离语音。
254.在步骤2214中,过程2200可以包括引起向远程定位设备传输表示用户的被辨识的语音的一个或多个语音音频信号。远程定位设备可以是被配置为通过有线或无线通信形式远程接收音频信号的任何设备。在一些实施例中,远程定位设备可以是用户的另一设备,诸如移动电话、音频接口设备或另一种形式的计算设备。在一些实施例中,语音音频信号可以由远程定位设备处理和/或进一步传输。在步骤2216中,过程2200可以包括阻止向远程定位设备传输不同于表示用户的被辨识的语音的一个或多个语音音频信号的至少一个背景噪声音频信号。例如,处理器210可以衰减和/或消除与可能代表背景噪声的声音2020、2021或2023相关联的音频信号。使用上述音频处理技术,可以将用户的语音与其他噪声分离。
255.在示例性图示中,语音音频信号可以由用户穿戴的耳机或其他设备捕获。用户的语音可以被辨识并与用户的环境中的背景噪声隔离。耳机可以将用户语音的调节后的音频信号传输到用户的移动电话。例如,用户可能正在进行电话呼叫,并且调节后的音频信号可以由移动电话发送给呼叫的接收者。用户的语音也可以由远程定位设备记录。例如,音频信号可以存储在远程服务器或其他计算设备上。在一些实施例中,远程定位设备可以处理接收到的音频信号,例如,将被辨识的用户的语音转换成文本。
256.嘴唇跟踪助听器
257.与公开的实施例一致,助听器系统可以基于跟踪的嘴唇运动选择性地放大音频信号。助听器系统分析捕获的用户的环境图像,以检测个体嘴唇并跟踪个体嘴唇的运动。跟踪的嘴唇运动可以用作选择性放大由助听器系统接收的音频的提示。例如,被确定为与跟踪的嘴唇运动同步或者与跟踪的嘴唇运动一致的语音信号可以被选择性地放大或者以其他方式被调节。与检测到的嘴唇运动不相关联的音频信号可以被抑制、衰减、过滤等。
258.用户100可以穿戴与上述基于照相机的助听器一致的助听器。例如,助听器设备可以是听力接口设备1710,如图17a所示。听力接口设备1710可以是配置成向用户100提供听觉反馈的任何设备。听力接口设备1710可以被放置在用户100的一个或两个耳朵中,类似于传统的听力接口设备。如上所述,听力接口设备1710可以是各种样式的,包括在耳道内、完全在耳道内、在耳内、在耳后、在耳上、在耳道中的接收器、开放式适配或各种其他样式。听力接口设备1710可以包括一个或多个扬声器,用于向用户100提供听觉反馈,用于检测用户100的环境中的声音的麦克风,内部电子、处理器、存储器等。在一些实施例中,除了麦克风或代替麦克风,听力接口设备1710可以包括一个或多个通信单元,以及一个或多个接收器,
用于从装置110接收信号并将信号传送给用户100。听力接口设备1710可以对应于反馈输出单元230,或者可以与反馈输出单元230分离,并且可以被配置为从反馈输出单元230接收信号。
259.在一些实施例中,听力接口设备1710可以包括骨传导耳机1711,如图17a所示。骨传导耳机1711可以通过手术植入,并且可以通过将声音振动骨传导到内耳向用户100提供听觉反馈。听力接口设备1710还可包括一个或多个耳机(例如,无线耳机、耳上耳机等)或由用户100携带或穿戴的便携式扬声器。在一些实施例中,听力接口设备1710可以集成到其他设备中,诸如蓝牙
tm
,使用者的耳机、眼镜、头盔(如摩托车头盔、自行车头盔等)、帽子等。
260.听力接口设备1710可以被配置为与诸如装置110的照相机设备通信。这种通信可以通过有线连接,或者可以无线地(例如,使用蓝牙
tm
、nfc或无线通信的形式)进行。如上所述,装置110可以由用户100以各种配置穿戴,包括物理地连接到衬衫、项链、腰带、眼镜、腕带、按钮或与用户100相关联的其他物品。在一些实施例中,还可以包括一个或多个附加设备,例如计算设备120。因此,本文中描述的关于装置110或处理器210的一个或多个过程或功能可以由计算设备120和/或处理器540执行。
261.如上所述,装置110可以包括至少一个麦克风和至少一个图像捕获设备。装置110可包括麦克风1720,如关于图17b所述。麦克风1720可以被配置为确定用户100的环境中声音的方向性。例如,麦克风1720可以包括一个或多个定向麦克风、麦克风阵列、多端口麦克风等。图17b中所示的麦克风仅作为示例,并且可以使用麦克风的任何适当数量、配置或位置。处理器210可被配置为区分用户100的环境中的声音并确定每个声音的近似方向性。例如,使用麦克风1720的阵列,处理器210可以比较麦克风1720中单个声音的相对定时或幅度,以确定相对于装置100的方向性。装置110可包括一个或多个照相机,例如照相机1730,其可对应于图像传感器220。照相机1730可被配置为捕获用户100的周围环境的图像。
262.处理器210(和/或处理器210a和210b)可被配置为检测与用户100的环境中的个体相关联的嘴和/或嘴唇。图23a和23b示出了可由照相机1730在与本公开一致的用户的环境中捕获的示例性个体2310。如图23所示,个体2310可以物理地存在于用户100的环境中。处理器210可被配置为分析由照相机1730捕获的图像以检测图像中个体2310的表示。处理器210可以使用如上所述的面部辨识组件(例如面部辨识组件2040)来检测和识别用户100的环境中的个体。处理器210可被配置为检测用户2310的一个或多个面部特征,包括个体2310的嘴2311。因此,处理器210可以使用一个或多个面部辨识和/或特征识别技术,如下进一步所述。
263.在一些实施例中,处理器210可以从用户100的环境检测个体2310的视觉表示,诸如用户2310的视频。如图23b所示,可以在显示设备2301的显示器上检测用户2310。显示设备2301可以是能够显示个体的视觉表示的任何设备。例如,显示设备可以是个人计算机、膝上型计算机、移动电话、平板、电视、电影屏幕、手持游戏设备、视频会议设备(例如,facebook portal
tm
)、婴儿监控器等。个体2310的视觉表示可以是个体2310的实时视频馈送,诸如视频呼叫、会议呼叫、监控视频等。在其他实施例中,个体2310的视觉表示可以是预先录制的视频或图像,诸如视频消息、电视节目,或者电影。处理器210可以基于个体2310的视觉表示来检测一个或多个面部特征,包括个体2310的嘴2311。
264.图23c示出了与所公开的实施例一致的示例性嘴唇跟踪系统。处理器210可被配置
为检测个体2310的一个或多个面部特征,其可包括但不限于个体的嘴2311。因此,处理器210可以使用一个或多个图像处理技术来辨识用户的面部特征,诸如卷积神经网络(cnn)、尺度不变特征变换(sift)、定向梯度直方图(hog)特征或其他技术。在一些实施例中,处理器210可被配置为检测与个体2310的嘴2311相关联的一个或多个点2320。点2320可表示个体嘴的一个或多个特征点,诸如沿着个体嘴唇或个体嘴角的一个或多个点。图23c中所示的点仅用于说明目的,并且应当理解,可以通过一个或多个图像处理技术来确定或识别用于跟踪个体嘴唇的任何点。点2320可在各种其他位置被检测,包括与个体的牙齿、舌头、脸颊、下巴、眼睛等相关联的点。处理器210可基于点2320或基于捕获的图像来确定嘴2311的一个或多个轮廓(例如,由线或多边形表示)。轮廓可以表示整个嘴2311或者可以包括多个轮廓,例如包括表示上唇的轮廓和表示下唇的轮廓。每个嘴唇还可以由多个轮廓表示,诸如每个嘴唇的上边缘轮廓和下边缘轮廓。处理器210可进一步使用各种其它技术或特征,诸如颜色、边缘、形状或运动检测算法来识别个体2310的嘴唇。识别出的嘴唇可以在多个帧或图像上被跟踪。处理器210可以使用一个或多个视频跟踪算法,诸如均值漂移跟踪、轮廓跟踪(例如,压缩算法)或各种其他技术。因此,处理器210可以被配置为实时跟踪个体2310的嘴唇的移动。
265.如果需要,可以使用个体2310的跟踪的嘴唇运动来分离,并选择性地调节用户100的环境中的一个或多个声音。图24是示出用于使用与本公开一致的的嘴唇跟踪助听器的示例性环境2400的示意图。用户100穿戴的装置110可被配置为识别环境2400内的一个或多个个体。例如,装置110可以被配置为使用照相机1730捕获周围环境2400的一个或多个图像。捕获的图像可以包括个体2310和2410的表示,这些个体可以存在于环境2400中。处理器210可被配置为使用上述方法检测个体2310和2410的嘴并跟踪其各自的嘴唇运动。在一些实施例中,处理器210还可以被配置为识别个体2310和2410,例如,通过检测个体2310和2410的面部特征并将其与数据库进行比较,如前面所讨论的。
266.除了检测图像外,装置110还可以配置为在用户100的环境中检测一个或多个声音。例如,麦克风1720可以在环境2400内检测一个或多个声音2421、2422和2423。在一些实施例中,声音可以表示不同个体的语音。例如,如图24所示,声音2421可以表示个体2310的语音,声音2422可以表示个体2410的语音。声音2423可表示环境2400内的其他声音和/或背景噪声。处理器210可配置为分析声音2421、2422和2423,以分离和识别与语音相关的音频信号。例如,处理器210可以使用上述一个或多个语音或语音活动检测(vad)算法和/或语音分离技术。当在环境中检测到多个语音时,处理器210可以隔离与每个语音相关联的音频信号。在一些实施例中,处理器210可以对与检测到的语音活动相关联的音频信号进行进一步分析,以辨识个体的讲话。例如,处理器210可以使用一个或多个语音辨识算法(例如,隐藏马尔可夫模型、动态时间扭曲、神经网络或其他技术)来辨识个体的语音。处理器210还可以配置为使用各种语音到文本算法辨识个体2310所说的单词。在一些实施例中,装置110可以通过诸如无线收发器530等通信组件从另一设备接收音频信号,而不是使用麦克风1710。例如,如果用户100在视频呼叫上,则装置110可以从显示设备2301或其他辅助设备接收代表用户2310的语音的音频信号。
267.处理器210可以基于嘴唇运动和检测到的声音来确定环境2400中的哪些个体正在说话。例如,处理器2310可以跟踪与嘴2311相关联的嘴唇运动,以确定个体2310正在说话。
可以在检测到的嘴唇运动和接收到的音频信号之间进行比较分析。在一些实施例中,处理器210可以基于在检测到声音2421的同时嘴2311正在移动的确定来确定个体2310正在说话。例如,当个体2310的嘴唇停止移动时,这可以对应于与声音2421相关联的音频信号中的静默或音量降低的时间段。在一些实施例中,处理器210可以被配置为确定嘴2311的特定运动是否对应于接收到的音频信号。例如,处理器210可以分析接收到的音频信号,以识别接收到的音频信号中的特定音素、音素组合或单词。处理器210可以辨识嘴2311的特定嘴唇运动是否对应于所识别的单词或音素。可以实施各种机器学习或深度学习技术来将预期的嘴唇运动与检测到的音频相关联。例如,已知声音和相应嘴唇运动的训练数据集可以被馈送到机器学习算法,以开发用于将检测到的声音与预期嘴唇运动相关联的模型。与装置110相关联的其他数据还可以结合检测到的嘴唇运动来确定和/或验证个体2310是否在说话,例如用户100或个体2310的注视方向、检测到的用户2310的身份、用户2310的被辨识的声纹等。
268.基于检测到的唇部运动,处理器210可引起对与个体2310相关联的音频的选择性调节。调节可包括相对于其它音频信号放大确定为对应于声音2421(其可对应于个体2310的语音)的音频信号。在一些实施例中,放大可以数字地完成,例如通过相对于其他信号处理与声音2421相关联的音频信号。可替代地或者可选地,可以通过改变麦克风1720的一个或多个参数以聚焦于与个体2310相关联的音频声音来实现放大。例如,麦克风1720可以是定向麦克风,并且处理器210可以执行将麦克风1720聚焦于声音2421的操作。可以使用用于放大声音2421的各种其他技术,例如使用波束形成麦克风阵列、声学望远镜技术等。调节后的音频信号可以被发送到听力接口设备1710,并且因此可以向用户100提供基于正在说话的个体的调节后的音频。
269.在一些实施例中,选择性调节可以包括衰减或抑制与个体2310不相关联的一个或多个音频信号,诸如声音2422和2423。类似于声音2421的放大,声音的衰减可以通过处理音频信号来发生,或者通过改变与麦克风1720相关联的一个或多个参数来定向焦点远离与个体2310不相关联的声音。
270.在一些实施例中,调节可进一步包括改变与声音2421相对应的音频信号的音调,以使声音2421对用户100更加可感知。例如,用户100可以对特定范围内的音调具有较低的灵敏度,并且音频信号的调节可以调整声音2421的音高,以使其对用户100更加可感知。例如,用户100可能在高于10khz的频率中经历听力损失。因此,处理器210可以将更高的频率(例如,在15khz处)重新映射到10khz。在一些实施例中,处理器210可被配置为改变与一个或多个音频信号相关联的讲话速率。处理器210可以被配置为改变个体2310的讲话速率,以使检测到的讲话对用户100更加可感知。如果已经对与声音2421相关联的音频信号执行了语音辨识,调节还可以包括基于检测到的讲话调整音频信号。例如,处理器210可以引入停顿或者增加单词和/或句子之间的停顿的持续时间,这可以使得讲话更容易理解。可以执行各种其他处理,例如调整声音2421的音调以保持与原始音频信号相同的音高,或者减少音频信号内的噪声。
271.调节后的音频信号然后可以被传输到听力接口设备1710,然后为用户100产生。因此,在调节后的音频信号中,声音2421(可以比声音2422和2423更大和/或更容易区分。
272.处理器210可以被配置为基于与音频信号相关联的哪些个体当前正在讲话来选择
性地调节多个音频信号。例如,个体2310和个体2410可以参与环境2400内的谈话,并且处理器210可以被配置为基于个体2310和2410各自的嘴唇运动,从调节与声音2421相关联的音频信号转变为调节与声音2422相关联的音频信号。例如,个体2310的嘴唇运动可以指示个体2310已经停止说话,或者与个体2410相关联的嘴唇运动可以指示个体2410已经开始说话。因此,处理器210可以在选择性地调节与声音2421相关联的音频信号和与声音2422相关联的音频信号之间转换。在一些实施例中,处理器210可以被配置为同时处理和/或调节两个音频信号,但是仅基于哪个个体在讲话选择性地将调节后的音频传输到听力接口设备1710。在实施语音辨识的情况下,处理器210可以基于讲话的上下文来确定和/或预测说话者之间的转换。例如,处理器210可以分析与声音2421相关联的音频信号,以确定个体2310已经到达句子的结尾或者已经问了问题,这可以指示个体2310已经结束或者即将结束说话。
273.在一些实施例中,处理器210可以被配置为在多个活跃说话者之间进行选择,以选择性地调节音频信号。例如,个体2310和2410可能同时说话,或者他们的讲话在谈话期间可能重叠。处理器210可以相对于其他个体选择性地调节与一个说话的个体相关联的音频。这可以包括在其他说话者开始说话时,给予已经开始但尚未完成单词或句子或尚未完成全部讲话的说话者优先级。如上所述,该确定也可以由讲话的上下文来驱动。
274.在选择活跃的说话者时,还可以考虑各种其他因素。例如,可以确定用户的注视方向,并且可以给予活跃说话者当中的在用户的注视方向中的个体更高的优先级。优先级也可以根据说话者的注视方向来分配。例如,如果个体2310注视着用户100并且个体2410注视着别处,则可以选择性地调节与个体2310相关联的音频信号。在一些实施例中,可以基于环境2400中其他个体的相对行为来分配优先级。例如,如果个体2310和个体2410都在讲话,并且注视个体2410的其他个体多于注视个体2310的其他个体,则与个体2410相关联的音频信号可以相对于与个体2310相关联的音频信号被选择性地调节。在确定个人身份的实施例中,如前面更详细地讨论的,可以基于说话者的相对状态来分配优先级。用户100还可以通过预定的设置或通过主动选择要关注的说话者来提供其中说话者被安排更高优先级的输入。
275.处理器210还可以基于如何检测个体2310的表示来分配优先级。虽然个体2310和2410被示为物理上存在于环境2400中,但是一个或多个个体可以被检测为该个体的视觉表示(例如,在显示设备上),如图23b所示。处理器210可以基于说话者是否物理存在于环境2400中来安排它们的优先级。例如,处理器210可以将物理上在场的说话者优先于显示器上的说话者。可替代地,例如,如果用户100正在视频会议上或者如果用户100正在观看电影,则处理器210可以将视频优先于房间中的说话者。优先的说话者或说话者类型(例如,存在与否)也可以由用户100使用与装置110相关联的用户界面来指示。
276.图25是示出与公开的实施例一致的基于跟踪的嘴唇运动选择性放大音频信号的示例性过程2500的流程图。过程2500可以由与装置110相关联的一个或多个处理器来执行,诸如处理器210。(多个)处理器可以被包括在与麦克风1720和照相机1730相同的公共外壳中,麦克风1720和照相机1730也可以用于过程2500。在一些实施例中,过程2500的一些或全部可以在装置110外部的处理器上执行,装置110可以包括在第二外壳中。例如,过程2500的一个或多个部分可以由听力接口设备1710中的处理器或者诸如计算设备120或显示设备
2301的辅助设备来执行。在这样的实施例中,处理器可以被配置为经由公共外壳中的发射器和第二外壳中的接收器之间的无线链路来接收捕获的图像。
277.在步骤2510中,过程2500可以包括接收由可穿戴照相机用户的环境从用户的环境捕获的多个图像。图像可以由诸如装置110的照相机1730的可穿戴照相机捕获。在步骤2520中,过程2500可以包括在多个图像中的至少一个图像中识别至少一个个体的表示。可以使用各种图像检测算法来识别个体,例如哈尔级联、定向梯度直方图、深度卷积神经网络、尺度不变特征变换等。在一些实施例中,处理器210可以被配置为例如从显示设备检测个体的视觉表示,如图23b所示。
278.在步骤2530中,过程2500可以包括基于对多个图像的分析,识别与个体的嘴相关联的至少一个嘴唇运动或嘴唇位置。处理器210可以被配置为识别与个体的嘴相关联的一个或多个点。在一些实施例中,处理器210可以形成与个体的嘴相关联的轮廓,该轮廓可以定义与个体的嘴或嘴唇相关联的边界。可以在多个帧或图像上跟踪图像中识别的嘴唇,以识别嘴唇运动。因此,如上所述,处理器210可以使用各种视频跟踪算法。
279.在步骤2540中,过程2500可以包括接收代表由麦克风从用户的环境捕获的声音的音频信号。例如,装置110可以接收代表由麦克风1720捕获的声音2421、2422和2423的音频信号。在步骤2550中,过程2500可以包括基于对麦克风捕获的声音的分析,识别与第一语音相关联的第一音频信号和与不同于第一语音的第二语音相关联的第二音频信号。例如,处理器210可以识别与声音2421和2422相关联的音频信号,分别代表个体2310和2410的语音。处理器210可以分析从麦克风1720接收的声音,以使用任何当前已知或未来开发的技术或算法来分离第一和第二语音。步骤2550还可以包括识别附加语音,诸如声音2423,其可以包括用户的环境中的附加语音或背景噪声。在一些实施例中,处理器210可以对第一和第二音频信号执行进一步的分析,例如,通过使用其可用的声纹来确定个体2310和2410的身份。替代地或附加地,处理器210可以使用语音辨识工具或算法来辨识个体的讲话。
280.在步骤2560中,过程2500可以包括基于确定第一音频信号与所识别的与个体的嘴相关联的嘴唇运动相关联,来引起对第一音频信号的选择性调节。处理器210可以将识别的嘴唇运动与步骤2550中识别的第一和第二音频信号进行比较。例如,处理器210可以将检测到的嘴唇运动的定时与音频信号中的语音模式的定时进行比较。在检测到讲话的实施例中,如上所述,处理器210可以进一步将特定的嘴唇运动与在音频信号中检测到的音素或其他特征进行比较。因此,处理器210可以确定第一音频信号与检测到的嘴唇运动相关联,并且因此与正在说话的个体相关联。
281.如上所述,可以执行各种形式的选择性调节。在一些实施例中,调节可以包括改变音频信号的音调或回放速度。例如,调节可以包括重新映射音频频率或者改变与音频信号相关联的讲话速率。在一些实施例中,调节可以包括第一音频信号相对于其他音频信号的放大。放大可以通过各种方式来执行,例如定向麦克风的操作、改变与麦克风相关联的一个或多个参数、或者对音频信号进行数字处理。调节可以包括衰减或抑制与检测到的嘴唇运动不相关联的一个或多个音频信号。衰减的音频信号可以包括与在用户的环境中检测到的其他声音相关联的音频信号,包括诸如第二音频信号的其他语音。例如,处理器210可以基于确定第二音频信号与所识别的与个体的嘴相关联的嘴唇运动不相关联,来选择性地衰减第二音频信号。在一些实施例中,处理器可以被配置为当第一个体的识别的嘴唇运动指示
第一个体已经完成句子或者已经结束讲话时,从与第一个体相关联的音频信号的调节转换到与第二个体相关联的音频信号的调节。
282.在步骤2570中,过程2500可以包括使得选择性调节后的第一音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。例如,经调节的音频信号可以被传输到听力接口设备1710,听力接口设备1710可以向用户100提供对应于第一音频信号的声音。也可以传输诸如第二音频信号的附加声音。例如,处理器210可以被配置为发送对应于声音2421、2422和2423的音频信号。然而,如上所述,可以相对于声音2422和2423放大可能与检测到的个体2310的嘴唇运动相关联的第一音频信号。在一些实施例中,听力接口1710设备可以包括与耳机相关联的扬声器。例如,听力接口设备可以至少部分地插入到用户的耳朵中,用于向用户提供音频。听力接口设备也可以在耳朵外部,诸如耳后听力设备、一个或多个耳机、小型便携式扬声器等。在一些实施例中,听力接口设备可以包括骨传导麦克风,其被配置为通过用户头部骨骼的振动向用户提供音频信号。这种装置可以放置成与使用者皮肤的外部接触,或者可以通过外科手术植入并附着到使用者的骨骼上。
283.感兴趣说话者的选择性放大
284.所公开的系统和方法可以使助听器系统能够选择性地放大音频信号,并将放大的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。例如,系统可以通过分析捕获的图像来辨识多个说话者,但是可以选择性地放大检测到的说话者的语音之一。选择用于放大的语音可以基于层次结构或其他合适的区分器。在一个示例中,用户正在注视的说话者的语音可以被放大。在另一个示例中,检测到的朝向用户的说话者的语音可以被放大。在另一个示例中,在讲话重叠的情况下,当另一个说话者已经开始讲话时可以选择已经开始讲话但还没有结束讲话的说话者的语音。
285.图26示出了穿戴示例性助听器系统的用户。用户2601可以穿戴可穿戴设备2631。可穿戴设备2631可以包括图像传感器,该图像传感器被配置为捕获用户2601的环境的图像。如图26所示,第一个体2611可以站在用户2601的前面并朝用户2601的方向看。此外,第二个体2612也可以站在用户2601的前面,但是朝远离用户2601的方向看。可穿戴设备2631的图像传感器可以捕获一个或多个图像,包括第一个体2611和第二个体2612。
286.图27示出了图26所示的用户2601的环境的示例性图像2700。可以由可穿戴设备2631的图像传感器捕获。图像2700可以包括第一个体2611的呈现2711和第二个体2612的呈现2712。
287.可穿戴设备2631还可以包括至少一个处理器,该处理器被配置为分析由图像传感器捕获的图像。处理器还可以基于图像分析来识别图像中包括的一个或多个个体。例如,处理器可以从图像传感器接收图像2700(如图27所示)。处理器还可以识别包括在图像中的第一个体2611和第二个体2612。
288.可穿戴设备2631还可以包括至少一个麦克风,该麦克风被配置为从用户2601的环境接收一个或多个音频信号。例如,麦克风可以被配置为接收(或检测)与第一个体的语音相关联的第一音频信号2611和与第二个体的语音相关联的第二音频信号2612。
289.处理器可以检测指示第一个体和第二个体之间的语音放大优先级的至少一个放大标准。一些放大标准可能是静态的,而另一些可能是动态的。例如,基于图像2700的分析,处理器可以检测到第一个体2611正朝着用户2601的方向看,而第二个体2612正朝着远离用
户2601的方向看,这可以指示第一个体2611的语音放大优先级应该高于第二个体2612。处理器还可以基于语音放大优先级选择性地放大第一音频信号。
290.可穿戴设备2631还可以包括诸如听力接口设备1710的听力接口设备,其被配置为接收音频信号并向用户2601的耳朵提供声音。例如,听力接口设备可以接收放大的第一音频信号,并基于放大的第一音频信号向用户2601提供声音。在一些实施例中,听力接口设备可以接收放大的第一音频信号和未处理的第二音频信号,并基于放大的第一音频信号和第二音频信号向用户2601提供声音。
291.图28是用于选择性地放大音频信号的示例性处理2800的流程图。在步骤2801,助听器系统(例如,装置110)可以接收用户的环境的多个图像。例如,助听器系统可以包括处理器(例如处理器210),该处理器配置成接收由图像传感器(例如图像传感器220)捕获的用户的环境的图像。在一些实施例中,图像传感器可以是包括助听器系统的照相机的一部分。例如,如图26所示,用户261可以穿戴可穿戴设备2631,该可穿戴设备2631可包括配置为捕获用户的环境的图像的图像传感器。助听器系统的处理器可以从可穿戴设备2631接收图像。
292.在一些实施例中,处理器可以被配置为控制图像传感器来捕获图像。例如,处理器可以检测用户执行的手势(手指指向手势),并基于检测到的手势控制图像传感器捕获图像(例如,基于手指指向手势的方向来调整图像传感器的视野)。作为另一个示例,助听器系统可以包括配置成检测(或接收)来自用户的环境的音频信号的麦克风。处理器可以从麦克风接收音频信号,并检测附近一个或多个个体的语音。如果检测到语音,处理器可以控制图像传感器捕获图像。
293.在一些实施例中,处理器可以经由任何已知的无线标准(例如,蜂窝、wi
‑
fi、等)、或经由近场电容耦合、其他短程无线技术或经由有线连接通过一个或多个网络从图像传感器接收数据或向其发送数据。例如,处理器还可以被配置为经由包括图像传感器的外壳中的发射器和包括处理器的外壳中的接收器之间的无线链路从图像传感器接收数据(例如,捕获的图像等)。
294.在步骤2803,处理器可以分析从图像传感器接收的一个或多个图像,并且识别图像中包括一个或多个个体。例如,如图26所示,两个个体
‑
第一个体2611和第二个体2612
‑
站在用户2601前面(第一个体2611可能比第二个体2612站得更靠近用户2601)。图像传感器可以被配置为捕获用户2601的环境的图像2700(如图27所示),包括第一个体2611和第二个体2612。处理器可以分析图像2700并在图像2700中识别第一个体2611的表示2711和第二个体2612的表示2712。第一个体2611的表示2711可能看起来比第二个体2612的表示2712大,因为第一个体2611可能比第二个体2612更靠近用户2601。在一些实施例中,处理器可以基于对象识别技术(例如,用于辨识对象的深度学习算法)来识别一个或多个个体。
295.在一些实施例中,处理器可以辨识包括在图像中的一个或多个个体。例如,处理器可以基于人类识别技术(例如,用于辨识个体的深度学习算法)辨识个体中的一个是家庭成员或朋友。在一些实施例中,处理器可以被配置为检索与被辨识的个体相关的信息(例如,个体的名称和用户最后一次遇到该个体的时间)。处理器还可以通过助听器接口和/或反馈输出单元向用户发送信息。
296.在在一些实施例中,处理器可被配置为基于对图像的分析来确定一个或多个所识
别的个体和/或用户中的每一个的视觉线(或注视方向)。例如,个体可以注视用户,并且处理器可以基于图像分析确定个体的注视方向朝向用户。作为另一示例,处理器可以基于图像分析确定用户的注视方向。
297.在步骤2805,处理器可以从至少一个麦克风接收与第一个体的语音相关联的第一音频信号。例如,助听器系统可以包括一个或多个麦克风,麦克风被配置为检测(或接收)来自用户的环境的音频信号。举例来说,可穿戴设备2631(例如,图26中所示)可包括麦克风,其被配置为接收与第一个体2611相关联的第一音频信号,并且可接收与站在用户2601前面的第二个体2612相关联的第二音频信号。处理器可以从麦克风接收第一音频信号。在一些实施例中,处理器可以经由任何已知的无线标准(例如,蜂窝、wi
‑
fi、等)、或经由近场电容耦合、其他短程无线技术或经由有线连接通过一个或多个网络从麦克风接收数据。例如,处理器还可以被配置为经由包括麦克风的外壳中的发射器和包括处理器的外壳中的接收器之间的无线链路从麦克风接收数据(例如,音频信号等)。
298.在一些实施例中,处理器可以配置成控制麦克风检测(或接收)音频信号和/或将音频信号发送到处理设备(和/或助听器接口)。例如,处理器可以基于对音频信号的分析来识别一个或多个个体。如果识别出一个或多个个体,则处理器可激活麦克风以接收音频信号。在一些实施例中,如果辨识出说话者并且将音频信号发送到处理设备,则只要说话者保持讲话(或者停顿小于阈值),就可以将与说话者相关联的音频信号发送到处理设备。在一些实施例中,只要说话者保持讲话(或停顿小于阈值),即使捕获了其他语音(无论是否被辨识),与说话者相关联的音频信号也可以被发送到处理设备,以让用户连续地收听说话者。例如,处理器可以被配置为继续使得第一音频信号而不是第二音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备,直到在与第一个体的语音相关联的讲话中检测到超过预定长度的停顿。在一些实施例中,说话中的短暂停顿(例如,呼吸停顿或用于搜索单词的停顿)仍可被视为连续讲话。在一些实施例中,高达预定长度的停顿可被视为连续语音的一部分,而更长的时间段可被认为说话者的讲话结束,使得其他说话者可被检测或放大或放大到不同程度。
299.在一些实施例中,麦克风可包括定向麦克风(例如,双向麦克风、全向麦克风等)、麦克风阵列等,或其组合。在一些实施例中,处理器可以被配置为基于接收到的音频信号来确定一个或多个被识别的个体和/或用户中的每一个的说话方向。例如,麦克风可以包括一个或多个定向麦克风,并且处理器可以被配置为基于与个体相关联的音频信号来确定个体的讲话方向。
300.在步骤2807,处理器可以从麦克风接收与第二个体的语音相关联的第二音频信号。例如,图26所示的可穿戴设备2631可以包括麦克风,麦克风被配置为接收与站在用户2601前面的第二个体2612相关联的第二音频信号。
301.在一些实施例中,处理器可被配置为从麦克风接收音频信号并辨识与接收到的音频信号相关联的个体。例如,处理器可以基于个体的语音特征(例如,个体的语音速度、音高等)来辨识个体。在一些实施例中,处理器可被配置为检索与被辨识的个体有关的信息(例如,个体的姓名和与个体最后一次见面的时间)。处理器还可以经由助听器接口和/或反馈输出单元向用户发送信息。
302.在一些实施例中,处理器可被配置为基于对音频信号和从图像传感器接收的一个
或多个图像的分析来辨识与音频信号相关联的个体。例如,处理器可以基于对音频信号的分析来确定个体和音频信号的关联的第一置信得分。处理器还可以基于对从图像传感器接收到的一个或多个图像的分析(类似于步骤2803中的识别处理)来确定个体和音频信号的关联的第二置信得分。处理器还可基于第一和第二置信得分确定总体置信得分,并基于总体置信得分识别个体(例如,如果总体置信得分超过阈值则识别个体)。举例来说,处理器可基于对音频信号的分析来确定特定个体与音频信号的关联的第一置信得分9(满分10)。处理器还可以基于对从图像传感器接收的一个或多个图像的分析来确定特定个体与音频信号的关联的第二置信得分2(满分10)。处理器可进一步确定11的总体置信得分(即,总共20分中的2加9),并且如果阈值为16,则确定该个体与音频信号不相关。作为另一示例,处理器可确定第一置信得分9和第二置信得分8。处理器还可以确定总体置信得分为17,并辨识与音频信号相关联的个体。在一些实施例中,处理器可基于加权第一置信得分和/或加权第二置信得分来确定总体置信得分。
303.在一些实施例中,麦克风和图像传感器(或包括图像传感器的可穿戴照相机)可以被包括在公共外壳中。例如,图26所示的可穿戴设备2631可以在一个公共外壳中包括麦克风和可穿戴照相机。可选地,麦克风可以包括在不同于安装可穿戴照相机的外壳的外壳中。
304.在一些实施例中,处理器可以与麦克风和可穿戴照相机中的至少一个包括在公共外壳中。例如,处理器也可以包括在麦克风和可穿戴照相机都包括在其中的公共外壳中。可替代地,处理器可以被包括在与安装麦克风和可穿戴照相机的公共外壳分开的外壳中。处理器还可以被配置为经由公共外壳(其中包括麦克风和可穿戴照相机)中的发射器和第二外壳(其中包括处理器)中的接收器之间的无线链路从可穿戴照相机和/或麦克风接收数据(例如,捕获的图像、检测到的音频信号等)。
305.在步骤2809,处理器可以检测指示第一个体和第二个体之间的语音放大优先级的至少一个放大标准。放大标准的检测可以基于对接收到的图像和/或音频信号的分析。例如,处理器可以基于例如图像分析来检测第一个体比第二个体更靠近用户。用户比第二个体更接近第一个体的检测可以是指示第一个体相对于第二个体的语音放大优先级的放大标准。
306.在一些实施例中,放大标准可包括用户相对于第一和/或第二个体的位置和/或方向、用户的注视方向、说话者(例如,第一个体、第二个体等)的注视方向等,或其组合。例如,如果检测到用户比第一个体更朝向第二个体(基于对图像和/或音频信号的分析),则处理器可以检测到第二个体具有比第一个体更高的语音放大优先级。可替代地地或额外地,放大标准可涉及第一个体和/或第二个体的身份。例如,处理器可将第一个体识别为家庭成员(但不辨识第二个体),并确定第一个体具有比第二个体更高的语音放大优先级。
307.在一些实施例中,放大标准可以包括用户的注视方向,并且可以基于用户的注视方向是与第一个体相关还是与第二个体相关来确定第一个体和第二个体之间的语音放大优先级。例如,处理器可以基于对由图像传感器捕获的图像的分析来确定用户的注视方向,并且确定用户是更朝向第一个体还是第二个体。作为另一示例,处理器可被配置为通过检测至少一个图像中的用户的下巴的表示并基于检测到的与用户的下巴相关联的方向来检测用户的注视方向。如果用户的注视方向相比于第二个体与第一个体更相关性,则处理器可以确定第一个体具有比第二个体更高的语音放大优先级。
308.在一些实施例中,放大标准可包括说话者(例如,第一个体、第二个体等)的注视方向,并且第一和第二个体之间的语音放大优先级可以基于第一个体还是第二个体正在基于说话者的注视方向在用户的方向上注视来确定。例如,如果处理器确定第一个体正在基于第一个体的说话者注视在第用户的方向上注视,并且第二个体正在远离用户的方向上注视,则第一个体可能比第二个体具有更高的语音放大优先级。另一方面,如果处理器确定第二个体正在用户的方向上注视并且第一个体正在远离用户的方向上注视,则第二个体可能比第一个体具有更高的语音放大优先级。在一些实施例中,处理器可以被配置为基于根据由图像传感器捕获的图像确定的说话者的面部特征(例如,眼睛、面部的方向等)来检测说话者的注视方向。
309.在一些实施例中,放大标准可以包括讲话连续性,该讲话连续性指示已经开始讲话但在另一个说话者已经开始讲话时尚未结束的说话者。例如,第一个体已经开始讲话了,但是当第二个体开始讲话时还没有结束。处理器可以确定第一个体可以具有讲话连续性并且具有比第二个体更高的放大优先级。
310.在一些实施例中,放大标准可以包括用户与第一个体和第二个体中的一个之间的关系。例如,处理器可以识别第一个体和/或第二个体(如本公开的其他地方所述),并确定用户与第一个体和第二个体中的一个之间的关系。举例来说,处理器可以确定个体中的一个是用户的家庭成员或朋友,并且基于所确定的关系来确定放大优先级。示例性关系可包括家庭成员、朋友、熟人、同事、陌生人等,或其组合。可替代地或额外地,放大标准可以包括第一个体和第二个体之间的关系。例如,处理器可以确定第一个体是第二个体的主管(即,一种关系类型)。可替代地或额外地,放大标准可以包括用户、第一个体和第二个体之间的关系。例如,处理器可以确定第一个体是用户和第二个体的管理者。在一些实施例中,处理器可以基于第一个体和/或第二个体与用户的关系的接近程度来确定放大优先级。例如,处理器可以确定第一个体是用户的直系亲属,第二个体是用户的朋友,并且确定第一个体比第二个体更接近用户(就关系而言)。处理器还可以确定第一个体具有比第二个体更高的放大优先级。可替代地或额外地,处理器可以基于所确定的关系的层次结构来确定放大优先级。例如,处理器可以确定第一个体是第二个体的主管(即,一种关系类型),并且确定第一个体具有比第二个体更高的放大优先级。
311.在步骤2811,处理器可基于语音放大优先级选择性地放大第一音频信号或第二音频信号。例如,如果第一音频信号具有比第二音频信号更高的语音放大优先级,则处理器可以放大第一音频信号。类似地,如果第二音频信号具有比第一音频信号更高的语音放大优先级,则处理器可以放大第二音频信号。
312.在一些实施例中,处理器可以将音频信号(第一音频信号或第二音频信号)放大到预定的声音等级。可替代地或额外地,处理器可以通过将声音等级增加一个百分比来放大音频信号。可替代地或额外地,当放大音频信号时,处理器可被配置为衰减一个或多个其他音频信号(例如,通过将其他(多个)信号的声音等级降低到预定声音等级或预定百分比)。例如,如果第一音频信号具有比第二音频信号更高的语音放大优先级,则处理器可以被配置为将第一音频信号放大50%并且将第二音频信号衰减50%。
313.在一些实施例中,助听器系统可以包括音频放大电路,音频放大电路被配置为选择性地放大音频信号。音频放大电路可以接收来自两个或更多个输入音频传感器的输入。
例如,第一输入音频换能器可以接收第一音频信号,并且第二输入音频换能器可以接收第二音频信号。处理器可使音频放大电路基于第一音频信号或第二音频信号的语音放大优先级放大其中一个。可替代地或额外地,处理器可使音频放大电路衰减具有较低语音放大优先级的音频信号。
314.在步骤2813,处理器可以使选择性放大的音频信号传输到听力接口设备。例如,处理器可使发射器经由无线网络(例如,蜂窝、wi
‑
fi、等)或经由近场电容耦合,其他短程无线技术或经由有线连接将放大的音频信号传输到听力接口设备。可替代地或额外地,处理器使得将未处理的(多个)音频信号(和/或选择性衰减的音频信号)传输到听力接口设备。
315.听力接口设备还可以配置为基于放大的音频信号向用户的耳朵传送声音。例如,听力接口设备可以接收放大的音频信号(例如,放大的第一音频信号),并基于放大的音频信号向用户的耳朵传送声音。在一些实施例中,听力接口设备还可以接收一个或多个未处理的音频信号和/或一个或多个衰减的音频信号。例如,听力接口设备可以接收放大的第一音频信号和未处理的第二音频信号。听力接口设备可以基于放大的第一音频信号和第二音频信号来传送声音。
316.在一些实施例中,听力接口设备可以包括与耳机相关联的扬声器。例如,听力接口设备可以包括入耳式耳机。作为另一示例,听力接口设备可以包括包括在可穿戴设备(例如,可穿戴设备2631)中的扬声器。在一些实施例中,听力接口设备可包括耳机、头戴式耳机、扬声器等,或其组合。
317.在一些实施例中,听力接口设备可以包括骨传导麦克风。
318.相对于扬声器电话用户语音的差分放大
319.公开的系统和方法可使助听器系统能够通过图像分析确定一个组中的至少一个说话者经由扬声器电话参加一个组会议(例如,通过在即使图像分析指示组中没有存在可见的说话者的情况下接收至少一个语音信号)。这样的语音信号可以来自通过扬声器电话参加会议的人或者来自可穿戴照相机视野(fov)之外的人,例如当可穿戴照相机面向前方时坐在汽车后座上的说话者。在这种场景下,语音信号可能比从物理上存在于组中或在用户前面的个体(例如,具有到用户的声音收集麦克风的不受阻碍的路径)接收的语音信号弱。被确定为从不同于被成像个体的源接收的音频信号可以相对于从被成像个体接收的音频信号被不同地放大(例如,使用更高的增益)。在一个实施例中,系统可以通过在捕获的图像中检测存在于系统照相机的fov中的扬声器电话设备或类似设备,至少部分地检测扬声器电话参与者的存在。
320.在一些实施例中,系统可自动识别小组讨论中出现的个体(例如,经由面部辨识、语音辨识或两者),并将讨论参与者记录在数据库中。系统还可以通过语音辨识或基于其他标准(诸如会议邀请记录、先前已知的关联等)来确定通过电话(或在照相机fov之外)参与讨论的至少一个人的身份。系统可以记录参与者的身份。在一些实施例中,系统可放大先前出现在照相机fov中但已离开该fov并且随后(例如,在乘车期间或在用户家中等)讲话的人的语音。在一些实施例中,系统还可以放大某些声音信号。例如,系统可能会放大火警、警报器、小孩的哭声、语音警告(例如,“求救!”)。可替代地或额外地,一些(预定的、被辨识的或没有被辨识的)声音,无论是否被辨识或被预定,都可以延迟放大和发送。例如,在一个机
场,当有关于航班的通告时,系统可能会意识到只有在提到航班号之后,这才是一个重要的通告。系统可以播放整个通告,即使该语音不是用户所知道的任何人的语音。
321.图29示出了示范性助听器系统。用户2901可以穿戴可穿戴设备2931。可穿戴设备2931可包括配置为捕获用户2901环境的图像的图像传感器。如图29所示,用户2901可以坐在桌子的一侧。第一个体2911和第二个体2912可坐在桌子的另一侧。可穿戴设备2931的图像传感器可以捕获用户2901的环境的一个或多个图像,包括第一个体2911、第二个体2912和扬声器电话2921。
322.图30a和30b示出了图29所示的用户2901的环境的示例性图像3000a和3000b。图像3000a可以包括第一个体3011的表示3011、第二个体3012的表示3012和扬声器电话2921的表示3021。图像3000b可以包括第二个体3012的表示3012和扬声器电话2921的表示3021(第一个体可以不在照相机的fov中)。可穿戴设备2931还可以包括至少一个处理器,该处理器被配置为分析由图像传感器捕获的图像。处理器还可以基于图像分析识别图像中包括的一个或多个个体和一个或多个对象的表示。例如,处理器可以从图像传感器接收图像3000a和/或3000b(如图30a和30b所示),并识别图像中包括的第一个体2911、第二个体2912和扬声器电话2921的表示。在一些实施例中,处理器可被编程为执行过程3110、过程3130和/或过程3150的一个或多个步骤(分别如图31a、31b和31c所示)。
323.在一些实施例中,可穿戴设备2931可配置为基于图像、(多个)检测到的音频信号、另一类型的数据等或其组合来自动识别一个或多个个体。例如,可穿戴设备2931可以基于使用面部辨识技术的图像自动识别第一个体2911和第二个体2912。可替代地或额外地,可穿戴设备2931可以基于与检测到的音频信号相关联的语音辨识(例如,个体的声纹)来自动识别个体。例如,可穿戴设备2931可基于检测到的与个体相关联的音频信号,自动识别不与用户2901在房间中并且正经由扬声器电话2921参与会议呼叫的个体。可替代地或额外地,可穿戴设备2931可基于与用户相关联的日历邀请或用户的先前已知关联来自动识别个体。例如,可穿戴设备2931可接收与日历邀请有关的数据,该数据可包括一个或多个参与者的身份。可穿戴设备2931可将个体识别为日历邀请中包括的参与者之一。在一些实施例中,可穿戴设备2931可进一步将一个或多个个体的标识记录在数据库中。
324.可穿戴设备2931还可以包括至少一个麦克风,其被配置为从用户2901的环境接收一个或多个音频信号。例如,麦克风可被配置为接收(或检测)与第一个体2911和/或第二个体2912相关联的音频信号和/或诸如背景噪声的附加音频。麦克风还可被配置为接收(或检测)与扬声器电话2921相关联的音频信号(例如,通过扬声器电话2921参与会议的第三个体的语音)。
325.在一些实施例中,麦克风可包括定向麦克风(例如,双向麦克风、全向麦克风等)、麦克风阵列等,或其组合。在一些实施例中,处理器可以被配置为基于接收到的音频信号来确定一个或多个被识别的个体和/或用户中的每一个的说话方向。例如,麦克风可以包括一个或多个定向麦克风,并且处理器可以被配置为基于与个体相关联的音频信号来确定个体的讲话方向。
326.可穿戴设备2931还可以基于对图像的分析来确定接收到的音频信号是否与在图像中检测到的一个或多个个体的语音相关联。例如,可穿戴设备2931可接收第一音频信号并基于对图像的分析确定第一音频信号与在图像中识别的任何个体(例如,第一个体2911
和第二个体2912)不相关。此外,可穿戴设备2931可接收第二音频信号并确定第二音频信号与第一个体2911的语音相关联。可穿戴设备2931还可以基于图像和/或音频信号来确定音频信号的源。例如,可穿戴设备2931可基于图像分析检测与第一个体2911相关联的嘴唇运动。可穿戴设备2931还可以确定检测到的嘴唇运动对应于第二音频信号,并且确定第二音频信号的源是第一个体2911。作为另一示例,可穿戴设备2931可确定音频信号来自扬声器。在一些实施例中,扬声器可包括扬声器电话、网络连接扬声器(例如蓝牙或wifi扬声器)、有线扬声器、移动电话等,或其组合。举例来说,可穿戴设备2931可通过通过分析一个或多个图像来检测被识别为扬声器电话的设备的表示来确定扬声器包括在扬声器电话中。
327.可穿戴设备2931还可以进一步引起第一音频信号的第一放大和第二音频信号的第二放大。第一放大在至少一个方面可以与第二放大不同。例如,可穿戴设备2931可以将第一音频信大第一增益水平,并将第二音频信号放大第二增益水平。在一些实施例中,第一增益水平可以大于第二增益水平。
328.可穿戴设备2931可与听力接口设备(例如,耳机)通信,该听力接口设备被配置为接收音频信号并向用户2901的耳朵提供声音。例如,可穿戴设备2931可使得根据第一放大而放大的第一音频信号和根据第二放大而放大的第二音频信号中的至少一个传输到被配置成向用户2901的耳朵提供声音的听力接口设备。例如,处理器可使发射器经由无线网络(例如,蜂窝、wi
‑
fi、等)或经由近场电容耦合、其他短程无线技术或经由有线连接将根据第一放大而放大的第一音频信号和根据第二放大而放大的第二音频信号中的至少一个发送到听力接口设备。
329.在一些实施例中,听力接口设备可包括与耳机相关联的扬声器。例如,听力接口设备可以包括在耳内、在耳道内、完全在耳道内、在耳后、在耳上、在耳道中的接收器、开放式适配或各种其他类型的耳机。作为另一示例,听力接口设备可以包括包括在可穿戴设备(例如,可穿戴设备2631)中的扬声器。在一些实施例中,听力接口设备可包括耳机、头戴式耳机、扬声器等,或其组合。在一些实施例中,听力接口设备可以包括骨传导麦克风。
330.在一些实施例中,麦克风和图像传感器(或包括图像传感器的可穿戴照相机)可以包括在公共外壳中。例如,图29所示的可穿戴设备2931可以在公共外壳中包括麦克风和可穿戴照相机两者。可替代地,麦克风可以包括在与安装有可穿戴照相机的外壳不同的外壳中。
331.在一些实施例中,处理器可以包括在具有麦克风和可穿戴照相机中的至少一个的公共外壳中。例如,处理器还可以包括在包括麦克风和可穿戴照相机两者的公共外壳中。可替代地,处理器可以包括在与安装麦克风和可穿戴照相机的公共外壳不同的单独外壳中。处理器还可以被配置为经由公共外壳(其中包括麦克风和可穿戴照相机)中的发射器和第二外壳(其中包括处理器)中的接收器之间的无线链路从可穿戴照相机和/或麦克风接收数据(例如,捕获的图像、检测到的音频信号等)。
332.图31a是用于选择性地放大音频信号的示例性处理的流程图。在步骤3111,助听器系统可以接收由照相机捕获的多个图像。例如,助听器系统可以包括处理器(例如,处理器210),其被配置为接收由图像传感器(例如,图像传感器220)捕获的用户的环境的图像。在一些实施例中,图像传感器可以是包括在助听器系统中的照相机的一部分。作为示例,如图29所示,用户2901可以穿戴可穿戴设备2931,该可穿戴设备2931可以包括被配置为捕获用
户的环境的图像的图像传感器。助听器系统的处理器可以从可穿戴设备2931接收图像。
333.在一些实施例中,助听器系统可以控制图像传感器以捕获图像。例如,处理器可以检测由用户执行的手势(手指指向手势),并控制图像传感器基于检测到的手势捕获图像(例如,基于手指指向手势的方向调整图像传感器的视野)。作为另一示例,助听器系统可以包括麦克风,其被配置为从用户的环境检测(或接收)音频信号。处理器可以从麦克风接收音频信号并检测附近一个或多个个体的语音。如果检测到语音,处理器可以控制图像传感器捕获图像。
334.在一些实施例中,处理器可以经由任何已知的无线标准(例如,蜂窝、wi
‑
fi、等)或经由近场电容耦合、其他短距离无线技术,或经由有线连接通过一个或多个网络从图像传感器接收数据或向图像传感器发送数据。例如,处理器还可以被配置为经由包括图像传感器的外壳中的发射器和包括处理器的外壳中的接收器之间的无线链路从图像传感器接收数据(例如,捕获的图像等)。
335.在步骤3113,助听器系统可以在多个图像中识别一个或多个个体的表示。例如,处理器可以识别图像中第一个体2911和第二个体2912的表示。例如,处理器可以分析图30a所示的图像3000a,并识别第一个体2911的表示3011和第二个体2912的表示3012。在一些实施例中,处理器还可以识别包括在图像中的一个或多个对象的表示。例如,处理器可以在图像3000a中识别扬声器电话2921的表示3021(如图29所示)。
336.在一些实施例中,处理器可以配置为基于检测到的图像、(多个)检测到的音频信号、另一种数据类型等或其组合自动识别一个或多个个体。例如,处理器可以基于使用面部辨识技术的图像自动识别第一个体2911和第二个体2912。可替代地,处理器可以基于与检测到的音频信号相关联的语音辨识(例如,个体的声纹)自动识别个体。可替代地,处理器可以基于与用户相关联的日历邀请或用户的先前已知关联自动识别个体。例如,处理器可以接收与日历邀请相关的数据,该数据可以包括一个或多个参与者的身份。处理器可以将第一个体2911识别为日历邀请中包括的参与者之一。在一些实施例中,处理器可以进一步记录数据库中一个或多个个体的标识。
337.在步骤3115,助听器系统可以从至少一个麦克风接收与语音相关联的第一音频信号。例如,助听器系统可以包括麦克风,麦克风被配置为从用户2901的环境接收(或检测)音频信号,包括与语音相关联的第一音频信号。
338.在步骤3117,助听器系统可以基于对多个图像的分析来确定第一音频信号不与一个或多个个体中的任何一个个体的语音相关联。例如,处理器可以分析图像以检测在图像中检测到的(多个)个体的面部表情(例如,嘴唇运动)。处理器可以通过分析检测到的与第一个体2911和/或第二个体2912的嘴相关联的嘴唇运动来确定第一音频信号不与一个或多个个体中的任何一个个体的语音相关联,以及确定第一音频信号不对应于检测到的与第一个体2911和/或第二个体2912的嘴相关联的嘴唇运动。第一音频信号可与在照相机fov之外的个体的语音相关联(例如,通过扬声器电话2921参加会议呼叫的个体或在房间中但远离用户2901而坐的个体)。
339.在一些实施例中,处理器可以识别第一音频信号的源。例如,处理器可以基于与检测到的音频信号相关联的语音辨识(例如,个体的声纹)来自动识别个体。举例来说,处理器可基于对第一音频信号的分析,自动识别不与用户2901在房间中且正经由扬声器电话2921
参与会议呼叫的个体。可替代地或额外地,处理器可基于与用户相关联的日历邀请或用户的先前已知关联来自动识别个体。例如,处理器可以接收与日历邀请有关的数据,该数据可以包括一个或多个参与者的身份。处理器可以将个体识别为日历邀请中包括的参与者之一。在一些实施例中,处理器还可以在数据库中记录一个或多个个体的标识。参与者可能更早被捕获,然后从图像中消失(可能去了另一个房间)。
340.在步骤3119,助听器系统可从至少一个麦克风接收与语音相关联的第二音频信号。助听器系统可以同时或在不同时间接收第一音频信号和第二音频信号。在一些实施例中,第一音频信号的至少一部分可以与第二音频信号的一部分重叠。可以通过任何语音分离技术来分离语音,例如使用仅一个说话者讲话的时段,如上所述。
341.在步骤3121,助听器系统可以基于对多个图像的分析来确定第二音频信号与一个或多个个体中的一个个体的语音相关联。例如,处理器可以通过分析检测到的与第一个体2911(和/或第二个体2912)的嘴相关联的嘴唇运动并确定第二音频信号对应于检测到的与第一个体2911(和/或第二个体2912)的嘴相关联的嘴唇运动来确定第二音频信号与第一个体2911(和/或第二个体2912)相关联。
342.在一些实施例中,处理器可被配置为基于图像、(多个)检测到的音频信号、另一类型的数据等或其组合,自动识别与第一音频信号和/或第二音频信号相关联的一个或多个个体。例如,处理器可以基于使用面部辨识技术的图像自动识别与第二音频信号相关联的第一个体2911(和/或第二个体2912)。可替代地或额外地,处理器可以基于与检测到的音频信号相关联的语音辨识(例如,个体的声纹)来自动识别个体。可替代地或额外地,处理器可基于与用户相关联的日历邀请或用户的先前已知关联来自动识别个体。例如,处理器可以接收与日历邀请有关的数据,该数据可以包括一个或多个参与者的身份。处理器可以将个体识别为日历邀请中包括的参与者之一。在一些实施例中,处理器还可以在数据库中记录一个或多个个体的标识。
343.在步骤3123,助听器系统可引起第一音频信号的第一放大和第二音频信号的第二放大。第一放大可以在至少一个方面不同于第二放大。例如,处理器可以将第一音频信号放大第一增益水平,并且将第二音频信号放大第二增益水平。在一些实施例中,第一增益水平可以大于第二增益水平。
344.在一些实施例中,处理器可以将第一音频信号放大到第一预定声音级别,将第二音频信号放大到第二预定声音级别。第一预定声音级别可以低于、大于或等于第二预声音级别。可替代地或额外地,处理器可以通过将声音级别增加第一百分比来放大第一音频信号,并且通过将声音级别增加第二百分比来放大第二音频信号。
345.在步骤3125,助听器系统可使得根据第一放大而放大的第一音频信号和根据第二放大而放大的第二音频信号中的至少一个传输到被配置成向用户的耳朵提供声音的听力接口设备。例如,处理器可以包括发射器,其被配置为经由无线网络(例如,蜂窝、wi
‑
fi、等)或经由近场电容耦合、其他短距离无线技术或经由有线连接将放大的(多个)音频信号(例如,放大的第一音频信号、放大的第二音频信号等)发送到听力接口设备。听力接口设备可以包括与耳机相关联的扬声器。例如,听力接口设备可以包括入耳式耳机。作为另一示例,听力接口设备可以包括包括在可穿戴设备(例如,可穿戴设备2931)中的扬声器。在一些实施例中,听力接口设备可包括耳机、头戴式耳机、扬声器等,或其组合。
346.图31b是用于选择性地放大音频信号的示例性过程3130的流程图。在步骤3131,助听器系统(例如,装置110)可以接收第一多个图像。例如,助听器系统可以包括处理器(例如,处理器210),其被配置为接收由图像传感器(例如,图像传感器220)捕获的用户的环境的图像。在一些实施例中,图像传感器可以是助听器系统中包括的照相机的一部分。作为示例,如图29所示,用户2901可以穿戴处理器,该处理器可以包括被配置为捕获用户的环境的图像的图像传感器。助听器系统的处理器可以从可穿戴设备2931接收图像。
347.在步骤3133,助听器系统可以识别第一多个图像中的个体的表示。在一些实施例中,助听器系统可以使用与上述过程3110的步骤3113的方法类似的方法来识别第一多个图像中的个体(和或对象)的表示。例如,处理器可被配置为分析图像3000a并基于图像分析识别图像3000a中第一个体2911的表示3011和/或第二个体2912的表示3012。在一些实施例中,处理器还可以自动识别个体,并将个体的标识记录到数据库中,如本公开的其他地方所述。
348.在步骤3135,助听器系统从至少一个麦克风接收代表语音的第一音频信号。例如,助听器系统可以包括麦克风,麦克风被配置为从用户2901的环境接收(或检测)音频信号,包括与语音相关联的第一音频信号。在一些实施例中,麦克风可包括定向麦克风(例如,双向麦克风、全向麦克风等)、麦克风阵列等,或其组合。
349.在一些实施例中,麦克风和图像传感器(或包括图像传感器的可穿戴照相机)可以包括在公共外壳中。可替代地,麦克风可以包括在与安装有可穿戴照相机的外壳不同的外壳中。在一些实施例中,处理器可以包括在具有麦克风和可穿戴照相机中的至少一个的公共外壳中。例如,处理器还可以包括在包括麦克风和可穿戴照相机两者的公共外壳中。可替代地,处理器可以包括在与安装麦克风和可穿戴照相机的公共外壳不同的单独外壳中。处理器还可以被配置为经由公共外壳(其中包括麦克风和可穿戴照相机)中的发射器和第二外壳(其中包括处理器)中的接收器之间的无线链路从可穿戴照相机和/或麦克风接收数据(例如,捕获的图像、检测到的音频信号等)。
350.在步骤3137,助听器系统可基于对第一多个图像的分析来确定代表语音的第一音频信号与个体相关联。在一些实施例中,助听器系统可以基于对第一多个图像的分析,使用与上述过程3110的步骤3121的方法类似的方法来确定代表语音的第一音频信号与个体相关联。例如,处理器可以通过分析检测到的与第一个体2911(和/或第二个体2912)的嘴相关联的嘴唇运动并确定第一音频信号对应于检测到的与第一个体2911(和/或第二个体2912)的嘴相关联的嘴唇运动来确定第一音频信号与第一个体2911(和/或第二个体2912)相关联。
351.在步骤3139,助听器系统可以相对于从至少一个麦克风接收的、其他音频信号选择性地放大第一音频信号,该其它音频信号代表来自个体以外的源的声音。例如,处理器可以将第一音频信号放大第一增益水平。可替代地或额外地,处理器可以将第一音频信号放大到第一预定声音级别。可替代地或额外地,处理器可以通过将声音级别增加一个百分比来放大第一音频信号。
352.在步骤3141,助听器系统可以接收由照相机捕获的第二多个图像。在一些实施例中,助听器系统可以在第一多个图像之后接收第二多个图像。例如,处理器可以接收在第一时间段期间由照相机捕获的第一多个图像,并且接收在第二时间段期间由照相机捕获的第
二多个图像。助听器系统可以使用与上述步骤3131类似的方法来接收第二多个图像。例如,助听器系统可以接收图30b所示的图像3000b(作为第二多个图像之一)。
353.在步骤3143,助听器系统可以从至少一个麦克风接收代表与该个体相关联的语音的第二音频信号。在一些实施例中,助听器系统可以接收代表第一音频信号之后的语音的第二音频信号。例如,可以从个体通过其讲话(例如,个体在电话呼叫中通过扬声器电话2921说话)的扬声器(例如,扬声器电话2921)接收第二音频信号。作为另一示例,可以直接从个体接收第二音频信号。在一些实施例中,助听器系统可以使用类似于上述步骤3135的方法接收第二音频信号。
354.在步骤3145,助听器系统可基于对第二多个图像的分析来确定个体未在第二多个图像中被表示。例如,助听器系统可以基于对图30b中所示的图像3000b的分析来确定,当捕获到图像3000b时,第一个体2911可以在照相机的fov之外(例如,已经离开房间或者尽管留在房间但在fov之外)。处理器可以分析第二多个图像并且确定个体没有在第二多个图像中被表示。
355.在步骤3147,助听器系统可以相对于代表来自个体以外的源的声音的其他接收的音频信号来选择性地放大第二音频信号。在一些实施例中,处理器可以选择性地将第二音频信号放大第二增益水平。可替代地或额外地,处理器可以将第二音频信号放大到第二预定声音级别。可替代地或额外地,处理器可以通过将声音级别增加一个百分比来放大第二音频信号。
356.在步骤3149,助听器系统可以引起选择性放大的第一音频信号或选择性放大的第二音频信号中的至少一个传输到听力接口设备。本公开的其他部分描述了将放大的音频信号传输到听力接口设备。例如,处理器可使发射器经由无线网络(例如蜂窝、wi
‑
fi、等)、或经由近场电容耦合、其他短程无线技术或经由有线连接将选择性放大的第一音频信号或选择性放大的第二音频信号中的至少一个发送到听力接口设备。
357.在一些实施例中,听力接口设备可以包括与耳机相关联的扬声器。例如,听力接口设备可以包括入耳式耳机。作为另一示例,听力接口设备可以包括包括在可穿戴设备(例如,可穿戴设备2631)中的扬声器。在一些实施例中,听力接口设备可包括耳机、头戴式耳机、扬声器等,或其组合。在一些实施例中,听力接口设备可以包括骨传导麦克风。
358.图31c是用于选择性地放大音频信号的示例性处理的流程图。在步骤3151,助听器系统可以接收多个图像。助听器系统可以基于类似于上述过程3110的步骤3111的方法接收多个图像。例如,用户2901可以穿戴可穿戴设备2931,该可穿戴设备2931可以包括被配置为捕获用户的环境的图像的图像传感器。助听器系统的处理器可以从可穿戴设备2931接收图像。
359.在步骤3153,助听器系统可以在多个图像中识别一个或多个个体的表示。助听器系统可以基于类似于上述处理3110的步骤3113的方法,在多个图像中识别一个或多个个体的表示。例如,处理器可以分析图30a中所示的图像3000a,并识别第一个体2911的表示3011和第二个体2912的表示3012。在一些实施例中,处理器还可以识别包括在图像中的一个或多个对象的表示。例如,处理器可以在图像30001中识别扬声器电话2921的表示3021(如图29所示)。
360.在步骤3155,助听器系统可以从至少一个麦克风接收与语音相关联的第一音频信
号。在一些实施例中,助听器系统可以基于类似于上述过程3110的步骤3115的方法从至少一个麦克风接收第一音频信号。例如,处理器可以包括麦克风,麦克风被配置为从用户2901的环境接收(或检测)音频信号,包括与语音相关联的第一音频信号。
361.在步骤3157,助听器系统可以根据图像的分析确定第一音频信号不与一个或多个个体中的任何一个个体的语音相关联。在一些实施例中,该确定可以基于类似于上述过程3110的步骤3117的方法。例如,处理器可以分析图像以检测在第一多个图像中检测到的(多个)个体的面部表情(例如嘴唇运动)。处理器可以确定第一音频信号不与一个或多个个体中的任何一个个体的语音相关联,是通过分析检测到的与第一个体2911和/或第二个体2912的嘴相关联的嘴唇运动并且确定第一音频信号不对应于检测到的与第一个体2911和/或第二个体2912的嘴相关联的嘴唇运动来进行的。
362.在步骤3159,助听器系统可以基于对音频信号的分析来确定音频信号与音频信号与公告相关的至少一个指示符相关联。例如,处理器可以分析接收到的音频信号以确定与音频信号相关联的内容。处理器还可以基于内容确定音频信号与公告相关。公告可以包括意图用于一组人的通信,其中设备用户可以是其中的一部分(例如,在机场广播的登机口通告)。另一个示例是,公告可以是呼救(例如求救等)。
363.在一些实施例中,音频信号与公告相关的至少一个指示符可以包括与音频信号相关联的被辨识的声音、单词或短语。例如,处理器可辨识与机场通告(例如,航班号)相关联的一个或多个单词或短语,并基于所辨识的单词或短语确定音频信号与公告相关。作为另一示例,音频信号可包括诸如“帮助”、“小心”、“注意”、“通告”(或其它语言中的类似单词或短语)等的单词(或短语)或其组合。处理器可以分析音频信号并辨识这样的单词(或短语),并且基于所识别的单词(或短语)确定音频信号与公告相关。可替代地或额外地,音频信号与公告相关的至少一个指示符可以包括相对于环境噪声水平的音频信号的音量水平,其可以指示音频信号与喊叫、尖叫、通过扬声器的公告等或其组合相关。例如,处理器可以确定音频信号的音量水平大于环境噪声水平一个阈值,并且确定音频信号可能与公告或需要注意的事件有关。可替代地或额外地,音频信号与公告相关的至少一个指示符包括与音频信号相关联的至少一个信号分量,该信号分量指示由扬声器产生音频信号。例如,音频信号可与通过一个或多个扬声器的广播相关,其可包括指示通过公共广播系统的语音放大或语音再现的一个或多个信号特征。
364.在步骤3161,助听器系统可基于音频信号与音频信号与公告有关的至少一个指示符相关联的确定来引起音频信号的选择性放大。例如,处理器可以放大与公告相关联的音频信号。在一些实施例中,处理器可以将音频信号放大到预定的声音级别。可替代地或额外地,处理器可以通过将声音级别增加一个百分比来放大音频信号。可选地或可替代地,当放大音频信号时,处理器可被配置为衰减一个或多个其他音频信号(例如,通过将其他信号的声音级别降低到预定声音级别或预定百分比)。例如,处理器可被配置为将与公告相关联的音频信号放大50%,并将一个或多个其他音频信号衰减50%。
365.在一些实施例中,处理器可以确定与公告(例如,机场的公告)相关的音频信号是否与用户相关,并且可以基于确定的结果选择性地放大音频信号。例如,处理器可以确定音频信号与与用户不相关联的航班有关,并且可以不相应地放大音频信号。作为另一示例,处理器可确定与音频信号相关联的公告与用户航班的登机门改变有关。处理器还可以选择性
地放大音频信号。在一些实施例中,处理器可以基于对存储在与用户相关联的移动设备上的日历条目或预订通知的自动检查来确定机场通告是否与用户相关。例如,处理器可以访问存储在与用户相关联的移动设备上的与日历条目或预订通知有关的数据,并基于所访问的数据确定与用户将乘坐的航班有关的航班信息(例如,航班号)。处理器还可以基于航班信息和音频信号(例如,与音频信号相关联的消息的内容)来确定与音频信号相关联的公告是否与用户相关。
366.在一些实施例中,助听器系统可以捕获在预定长度的移动时间窗口期间接收的一个或多个音频信号,并且,处理器可编程为引起在移动时间窗口内但在确定音频信号与公告相关之前接收的音频信号的一部分的选择性放大和传输。例如,助听器系统可以辨识出语音通信流(以一个或多个音频信号的形式)包括公告。识别可能在公告开始后进行。处理器可以使用捕获的(多个)音频信号的移动时间窗口返回公告的开始,并从时间窗口中提取与完整通告相关的信息,并选择性地放大该完整通告(以一个或多个音频信号的形式)给用户。(多个)放大的音频信号可以相对于原始通告延时传输给用户。
367.在步骤3163,助听器系统可使得选择性放大的音频信号传输到听力接口设备。例如,处理器可使得发射器经由无线网络(例如,蜂窝、wi
‑
fi、fi、等)、或经由近场电容耦合、其他短距离无线技术或经由有线连接将放大的音频信号发送到听力接口设备。可替代地或额外地,处理器可使得未处理的(多个)音频信号(和/或选择性衰减的音频信号)传输到听力接口设备。
368.选择性调节音频信号
369.根据本公开的各种实施例,诸如装置110之类的可穿戴设备可以被配置为除了使用图像信息之外还使用音频信息。例如,装置110可以经由一个或多个麦克风检测和捕获用户(例如,用户100)的环境中的声音。装置110可以使用该音频信息代替图像和/或视频信息,或者与图像和/或视频信息组合使用,以确定情况、识别人、执行活动等。对于穿戴助听器系统的人,图像和/或视频信息可以在各种情况下补充音频信息。例如,使用助听器的人经常会发现,助听器在拥挤的环境中没有表现得最优。在这种情况下,各种环境声音可能被放大,并阻止穿戴助听器的用户(例如,用户100)清楚地区分与用户100直接相关的声音,诸如来自与用户100交流的人的谈话词或声音。在这种情况下,图像数据可用于识别与用户100相关的个体(例如,与用户100谈话的个体)。
370.根据本公开的一个实施例,提供了一种助听器系统。助听器系统可以包括配置成从用户100的环境捕获多个图像的可穿戴照相机。在各种实施例中,助听器系统可以包括至少一个麦克风,其被配置为从用户的环境捕获声音。在一些实施例中,助听器系统可以包括多于一个的麦克风。在示例实施例中,助听器系统可包括用于捕获第一波长范围内的音频信号的第一麦克风和用于捕获第二波长范围内的音频信号的第二麦克风。
371.助听器系统可以包括至少一个处理器,该处理器被编程为接收由可穿戴照相机捕获的多个图像,并且在多个图像中的至少一个图像中识别至少一个个体的表示。处理器可以被配置为使用基于计算机的模型从接收到的图像中提取人的图像。例如,处理器可以使用神经网络模型(例如,卷积神经网络(cnn))来辨识接收图像中的人的图像。在示例性实施例中,助听器系统可被配置为在垂直于用户100的面部的方向(例如,基于与用户的下巴相关联的方向确定,该方向可以垂直于用户100的下巴)上捕获图像以辨别捕获图像中的说话
者。
372.助听器系统可并入装置110中,或者在一些实施例中,装置110可构成助听器系统。如上所述,结合图2,装置110可以经由网络240向服务器250传送数据或从服务器250接收数据。在示例性实施例中,接收到的图像中的人的图像可以被传送到服务器250以进行图像分析。服务器250可以包括处理器,该处理器被配置为访问与服务器250相关联的数据库,该数据库包含与用户100相关的人的各种图像,并将这些图像与由装置110传送到服务器250的人的一个或多个图像进行比较。
373.在示例实施例中,服务器250的数据库可以选择用户100的朋友、用户100的亲属、用户100的同事、用户100过去遇到的人等的图像,来与助听器系统捕获的人的一个或多个图像进行比较。在一些实施例中,助听器系统可以访问全球定位系统(gps),并且可以确定用户100的位置。例如,助听器系统可以包括gps系统,或者它可以与包括gps系统(或者用于确定移动设备的位置的替代系统,例如wi
‑
fi、本地网络等)的用户100的移动设备(例如,智能电话、平板、膝上型等)通信,以获得位置数据(例如,用户100的坐标,用户100的地址、用户100的移动设备的ip地址等)。助听器系统可以将用户100的位置传送给服务器250。在一个示例实施例中,服务器250可以被配置为从数据库(例如,存储在服务器250中)中选择可能在用户100的位置找到的人的图像。例如,当用户100位于工作地点时,可以首先选择同事的图像。
374.附加地或替代地,当可穿戴照相机捕获用户100的环境的图像时,助听器系统可以与服务器250通信一次。在示例实施例中,服务器250可以配置为从数据库(例如,存储在服务器250中)中选择在通信时很可能在用户100的位置被发现的人的图像。例如,当用户100位于家中且时间对应于晚餐时间时,可以首先选择亲属的图像。
375.在各种实施例中,可以由服务器250的处理器使用任何合适的方法将从由助听器系统的可穿戴照相机捕获的图像获得的人的图像与从服务器250的数据库中选择的各种图像进行比较。例如,可以使用诸如cnn之类的神经网络或任何其他合适的基于计算机的方法来比较图像。在一些实施例中,基于计算机的模型可以分配一个可能性,该可能性指示从捕获的图像获得的人的图像与在服务器250的数据库中找到的至少一个图像的匹配程度。在示例实施例中,可能性可以是从捕获的图像获得的人的图像与服务器250的数据库中找到的至少一个图像相匹配的概率,并且可以在从0到1的值的范围内。
376.在各种实施例中,服务器250的数据库中的图像可以具有可与相关图像相关联地存储在服务器250的数据库中的相关联数据记录。例如,来自数据库的图像可以具有与人相关联的数据记录,并且数据记录可以包括人的姓名、与用户100的关系、该人与用户100见面的日期和时间等。在一些情况下,一个数据记录可以与位于服务器250的数据库中的多个图像相关联。可以为一个或多个相关联的图像从数据库中检索数据记录。例如,服务器250可以被配置为使用处理器检索一个或多个相关联图像的数据记录。附加地或可替代地,可以从数据库中为相关联的数据记录检索一个或多个图像。在示例实施例中,可以将从捕获的图像获得的人的图像与来自服务器250的数据库的对应于相同数据记录的多个图像进行比较以建立可能性。在各种实施例中,如果可能性高于预定阈值,则助听器系统可以建立从捕获的图像获得的人的图像与来自数据库的数据记录匹配。
377.在示例实施例中,可以链接存储在服务器250的数据库中的图像的数据记录。例
如,一个人的数据记录可以与另一个人的数据记录相链接,其中链接可以包括所链接的数据记录之间的任何合适的关系信息。在某些情况下,该链接可用于定义其数据记录存储在数据库中的人之间的关系。例如,人可以被定义为同事、朋友、竞争对手、邻居、队友、同一产品的崇拜者、个人、歌手、演员等。在各种实施例中,服务器250可以使用数据记录之间的链接来重新评估从捕获的图像中识别的人与在服务器250的数据库中找到的个体的图像匹配的可能性。例如,如果在服务器250的数据库中找到的个体的图像的数据记录包括到用户100的数据记录的链接,则可能性值可以增加。例如,如果链接指示用户100是个体的同事,并且用户100位于工作地点,则可能性值可以增加。在一些实施例中,与第一个体(例如,同事)的第一次相遇可以影响在第二次相遇期间从捕获的图像中识别的第二个体(例如,另一同事)与在服务器250的数据库中找到的个体的数据记录相匹配的可能性值。
378.尽管上面的讨论描述了使用服务器250来分析由用户100的可穿戴设备捕获的图像,但是附加地,或者可替代地,助听器系统的处理器可用于分析图像。例如,助听器系统的处理器可以被配置为从服务器250的数据库接收人的各种图像或特征以及这些图像或特征的相关数据记录,以及将接收到的图像或特征与在捕获的图像中识别的人的图像或特征进行比较。与上面讨论的实施例类似,助听器系统的处理器可以使用基于计算机的模型来比较图像,并且可以从数据库接收与用户100的位置或时间相关的图像。在示例实施例中,基于计算机的模型可以包括诸如卷积神经网络(cnn)之类的神经网络。在一些实施例中,确定至少一个个体是否是被辨识的个体可以基于可以用于分析一个或多个图像的经训练的神经网络的输出,该神经网络被提供有多个图像中的至少一个。在一些实施例中,可以基于基于对多个图像中的至少一个图像的分析而检测到的与至少一个个体相关联的一个或多个面部特征来确定至少一个个体是否是被辨识的个体。例如,基于计算机的模型(诸如cnn)可用于分析图像并将捕获图像中识别的人的面部特征或面部特征之间的关系与存储在服务器250的数据库中的图像中找到的人的面部特征及其之间的关系进行比较。在一些实施例中,可以将人的面部动态运动的视频与从数据库获得的用于各种人的视频数据记录进行比较,以建立在视频中捕获的人是被辨识的个体。
379.在各种实施例中,助听器系统可包括至少一个处理器,该处理器被编程为从至少一个麦克风接收音频信号。在示例实施例中,至少一个处理器可被配置为使用基于计算机的模型来确定接收到的音频信号是否与所识别的个体相关联。例如,基于计算机的模型可以是神经网络模型(例如,卷积神经网络(cnn))等。在一些情况下,音频信号可以包括来自多个源的多个音频信号(例如,来自与用户100谈话的说话者的音频信号、环境音频信号等)。在各种实施例中,可以基于对助听器系统的麦克风接收的至少一个音频信号(例如,与用户100与一个或多个说话者谈话有关的音频信号)的分析来确定至少一个个体是否是被辨识的个体。在示例性实施例中,可以基于检测到的用户的注视方向来确定音频信号与被辨识的个体相关联,该注视方向是基于在多个图像中的至少一个图像中检测到的与用户的下巴相关联的方向来确定的。
380.在示例实施例中,在音频信号中检测与一个或多个被辨识的个体(例如,其声纹和数据记录可用(例如在服务器250的数据库或其他地方)的个体)相关联的预定语音特征中的一个或多个可用于识别并辨识一个或多个说话者。例如,对被辨识的个体的语音特征的检测可以确定接收到的音频信号是否与被辨识的个体相关联。如本文所使用的,术语“声
纹”可指唯一地标识说话者的人类语音的一组可测量特征(或特征范围)。在一些实施例中,这些参数可以基于说话者的嘴、喉咙和附加器官的物理配置,和/或可以表达为与由说话者发音的各个音节相关的一组声音、与说话者发音的各种单词相关的一组声音,说话者的语音的移调和转调、说话者的讲话的节奏等。
381.在各种实施例中,服务器250可以从各种源接收用于各种个体的图像和音频信息(例如,声纹)。例如,图32示出服务器250从穿戴装置110的用户100接收图像3211和音频数据3212。在一些情况下,图像和音频数据可以经由计算设备120(例如,智能电话、膝上型计算机、平板等)提交到服务器250。在一些实施例中,服务器250可以被配置为在与用户100或者与图像3211中识别的一个或多个个体相关联的社交网络3220(例如,页/页/页、邮件、等)上访问可用的信息(例如,图像、视频、音频数据等)。来自社交网络3220的信息可以包括与用户100的朋友、用户100的朋友的朋友等相关的数据。在一些实施例中,服务器250可以从不使用助听器系统(例如,如图32所示的装置110)但具有与服务器250相关联的用户简档的个体接收信息。例如,用户3230可以是用户100的亲属、同事、朋友等,并且可以具有与服务器250相关联的用户简档。在各种实施例中,用户3230可以取得图像/视频和/或音频数据3231(例如,如图32所示的自拍),并将数据3231上载到服务器250。在各种实施例中,用户3230可以将诸如相关联的数据记录(例如,用户3230的名称、位置等)的信息上载到服务器250。在一个示例实施例中,一个或多个处理器可以被编程为将图像3211和音频数据3212发送到与个体遇到的人有关的数据库。例如,一个或多个处理器可被配置为在当谈话的说话者被识别并被辨识时发送图像3211和音频数据3212,或/和即使那些说话者没有被辨识也发送图像3211和音频数据3212。
382.在各种实施例中,助听器系统可被配置为经由视觉或音频数据与用户100交互。例如,助听器系统可以使用经由耳机设备等传送给用户100的音频信号经由显示器与用户100交互。在示例性实施例中,助听器系统可以通过将可穿戴设备捕获的图像与如上所述存储在服务器250的数据库中的图像和相关数据记录进行比较来确定至少一个个体是否是被辨识的个体。当从捕获图像获得的人的图像与来自数据库的数据记录相匹配的可能性高于预定阈值时,助听器系统可以确定在图像中捕获的个体是被辨识的个体。
383.在某些情况下,当可能性不够高(例如,低于预定阈值)时,助听器系统可被配置为为在捕获的一个或多个图像中显示的人建议各种可能的姓名。助听器系统随后可允许用户100选择用户100认为与捕获图像中显示的人最匹配的姓名。对于当助听器系统包括显示器(例如,移动电话、平板、具有显示器260的设备120,如图2所示等)的情况,助听器系统可以使得至少一个个体的图像显示在显示器上。在一些实施例中,助听器系统可以向用户100呈现与在捕获的一个或多个图像中显示的人的一个或多个建议的可能姓名相关联的个体的一个或多个图像。例如,助听器系统可以在设备120的显示器260上显示个体的一个或多个图像。此外,助听器系统可以向用户100通知与一个或多个建议的可能姓名相关联的个体的其他信息(例如,个体的估计/预期位置、个体的职业等)以便于用户100选择用户100认为与在捕获图像中显示的人最匹配的个体的姓名。
384.在某些情况下,显示器可以包括有可穿戴照相机和至少一个麦克风共用的外壳。在某些情况下,可穿戴照相机和至少一个麦克风可以包括在公共外壳中,并且显示器可以
位于其他地方。在一些实施例中,公共外壳还可以包括处理器。在某些情况下,助听器系统可能包括公共外壳中可能不包括的各种元件和设备。例如,助听器系统可以包括不包括在公共外壳中的第二处理器。在一些实施例中,至少一个处理器被配置为经由公共外壳中的发射器和第二外壳中的接收器之间的无线链路来接收捕获的图像。例如,第二外壳可以与配对的(例如,使用任何合适的方法无线连接或有线连接的)移动设备相关联。如上所述,显示器可以是与助听器系统配对的第二外壳(例如,诸如智能电话、平板、膝上型计算机等的移动设备)的一部分。
385.在一个示例实施例中,可以从存储器中存储的数据库(例如,服务器250的数据库)检索显示器260上显示的至少一个个体的图像,该数据库将被辨识的个体与从图像中提取的相应图像或特征相关联,如上所述。在一些情况下,可以从至少一个图像中提取(例如,导出)至少一个个体的显示的图像。
386.对于当至少一个个体被确定为被辨识的个体的情况,助听器系统可以被配置为通知用户100该个体已经被辨识。例如,当助听器系统包括显示器时,助听器系统可使至少一个个体的图像显示在显示器上(例如,设备120的显示器260)。
387.在某些情况下,助听器系统可以配置为显示从与被辨识的个体相关联的数据记录中获得的信息,诸如个体姓名、地址、与用户100的关系等。额外地,或可替代地,助听器系统可以被配置为通知用户100已经使用音频信号辨识了个体,该音频信号使用任何合适的方式(例如,使用一个或多个耳机设备,扬声器,等)传送到用户100。例如,助听器系统可以通过一个或多个耳机设备通知用户100从与被辨识的个体相关联的数据记录中获得的信息,例如个体姓名、地址、与用户100的关系等。额外地,或可替代地,助听器系统可以使用任何其他合适的方法(例如,经由文本消息、触觉信号等)通知用户100已经辨识了该个体。
388.助听器系统可选择性地调节至少一个音频信号,该音频信号从至少一个麦克风接收并且被确定为与被辨识的个体相关。音频信号的选择性调节可涉及从音频信号中过滤所选音频信号。在某些情况下,选择性调节可包括衰减音频信号。可替代地,选择性调节可以包括音频信号的放大。在示例性实施例中,所选音频信号可对应于与用户100与另一人的谈话有关的音频。在一些情况下,音频信号可以包括环境噪声(例如,各种背景声音,诸如音乐、来自不参与与用户100的谈话的人的声音/噪声等),并且所选音频信号可以包括参与与用户100的谈话的人(称为说话者)的讲话。在一些实施例中,选择性调节可包括改变与至少一个音频信号相关联的音调或改变与至少一个音频信号相关联的讲话速率。
389.可以使用任何合适的方法(例如,使用安装在用户100上不同位置的多个可穿戴麦克风)来执行说话者的语音与背景声音的分离。在某些情况下,至少一个麦克风可以是定向麦克风或麦克风阵列。例如,一个麦克风可以捕获背景噪声,而另一个麦克风可以捕获包括背景噪声以及特定人的语音的音频信号。然后可以通过从组合音频中减去背景噪声来获得语音。在某些情况下,能够将音频发送到助听器系统的一些麦克风可以由讲话的人(例如,说话者)穿戴。例如,用户100可以将可移动麦克风递给正在讲话的人。在一些情况下,可能有两个或更多的人参与与用户100的谈话,有或没有背景噪声。例如,图33示出了穿戴图像捕获设备3322和音频捕获设备3323的用户100与说话者3302和说话者3303交互。在这种情况下,知道至少一个说话者的身份或说话者的数量可能有助于分离语音。
390.可以使用例如说话者估计算法来获得说话者的数目。该算法可以接收图像数据
(例如,由装置110捕获的说话者3302的图像和说话者3303的图像),并且基于接收到的图像,输出谈话是否包括多个说话者。助听器系统可以通过找到一对面朝对方的人来识别和辨识说话者3302和说话者3303。助听器系统可能会捕获多张图像,以确保两人在一段时间内继续彼此面对。在一些实施例中,助听器系统可基于说话者3302和3303的面部方向、说话者的手势(例如,当第二人说话时个体中的一个点头)、手势和声音的定时等来识别说话者3302和3303参与到与用户100的谈话。在一些实施例中,至少一个说话者(例如,说话者3302)可以通过他或她的声纹来识别。在一些实施例中,用户100可以通过使用用户100头部和/或头部姿势的定位来帮助助听器确定说话者的数量。说话者估计算法可以输出谈话是否包括无讲话(例如,仅存在背景噪声)、单个说话者还是多个说话者。
391.头部定位和/或头部姿势可用于确定说话者的数量,并且还可用于确定哪个音频信号与哪个说话者相关联。在各种实施例中,用户100的头部定位可包括将用户100的面部朝向正在讲话的说话者(例如,如图33所示的说话者3303),并将该位置保持至少预定的持续时间(例如,一秒钟、几秒钟或说话者3303的讲话的持续时间)。
392.在一些实施例中,助听器系统可被配置为使用从说话者3302和3303接收的用户100音频信号的头部位置之间的相关性来建立谈话的说话者的数量。额外地,可替代地,诸如点头、摇头、特定头部运动、面部运动等头部姿势也可用于向助听器系统指示谈话中的说话者的数量以及哪个音频信号与哪个说话者相关联。
393.在一些实施例中,音频信号(例如来自说话者3302和说话者3303的信号)的属性可以单独使用,也可以与图像数据以及头部定位数据和头部姿势结合使用,以确定谈话中的说话者的数量,以及哪个音频信号与哪个说话者相关联。例如,如果音频信号包括具有第一明显音调、节奏、响度等的第一音频信号,并且第二音频信号包括第二明显音调、节奏、响度等,则助听器系统可以确定谈话中有两个说话者。此外,当这些信号不重叠时,助听器系统可以区分第一和第二音频信号(例如,当说话者3302和3303不同时讲话时,这是谈话中的典型情况)。
394.在一些实施例中,助听器系统可以分析其中一个说话者(例如,说话者3302)的讲话内容或讲话节奏,以区分说话者3302和3303的语音。例如,助听器系统可基于讲话的内容或讲话节奏来确定说话者3302可能正在等待来自说话者3303的响应。例如,当说话者3302向说话者3303询问问题或从说话者3303请求信息时,可能出现这种情况。在一些实施例中,助听器系统可以检测到一些关键字,这些关键字可以指示说话者3302正在等待来自说话者3303的响应(例如,关键字可以包括“告诉我们”、“你怎么认为”等)。在某些情况下,说话者3302的讲话的内容或节奏可指示说话这3302正计划继续讲话。例如,说话这3302可以使用诸如“我不同意你的意见,因为”、“列表包括五项,第一项是”等短语。
395.在各种实施例中,助听器系统可被配置为记录或转录多个说话者之间的谈话。转录过程可以由助听器系统捕获的图像来辅助。例如,助听器系统可以识别和辨识说话者3302和/或说话者3303。说话者3302可以面对说话者3303(图33中未示出),并且,基于由助听器系统的图像捕获设备3322捕获的图像,助听器系统可以确定说话者3302正在对说话者3303寻址。助听器系统可以被配置为转录说话者3302和说话者3303之间的谈话,并且将第一讲话识别为属于说话者3302,将第二讲话识别为属于说话者3303。
396.在各种实施例中,可以使用与说话者的讲话相关联的音频信号获得说话者的声
纹,并存储在服务器250的数据库中,以供进一步参考。所存储的语音数据可以包括一个或多个声纹,这些声纹可以从说话者的一个或多个讲话中获得。在一个示例实施例中,根据与在至少一个音频信号中检测到的被辨识的个体相关联的一个或多个预定声纹特性,可以确定至少一个音频信号与被辨识的个体相关联。预定的声纹可以与人及其一个或多个图像或视觉特性相关联存储,并且可以随时间而可选地更新、增强等。当说话者在一个或多个图像中被辨识时,可以检索一个或多个声纹,并用于将特定语音与语音的混合分离。在示例性实施例中,声纹可以存储在服务器250的数据库中,并且可以与与说话者对应的数据记录相关联。此外,声纹还可以与说话者的一个或多个图像相关联,该图像与数据记录相关。
397.可替代地,例如,如果没有识别说话者,则可以从当只有该说话者参与谈话时的谈话的早期部分提取说话者的声纹。声纹的提取可以在说话者数量算法指示单个说话者的音频片段上执行。提取的声纹随后可用于稍后在谈话中用于将说话者的语音与其他语音分离。分离的语音可以用于任何目的,例如通过电话传输、传输到麦克风、传输到助听器等。
398.在一些情况下,助听器系统可被配置为从第一说话者(例如,说话者3302)获得第一音频样本,该第一音频样本与从第二说话者(例如,说话者3303)获得的第二音频样本分离。助听器系统可以使用第一音频样本来确定说话者3302的第一声纹,并且使用第二音频样本来确定说话者3303的第二声纹。如上所述,可以使用由诸如装置110的装置捕获的图像来识别与用户100交流的说话者。如果说话者位于由助听器系统的可穿戴照相机捕获的用户视野的中心,则可以将个体识别为说话者。在其他实施例中,说话者可以被识别为在一个或多个图像中被辨识的用户的下巴所指向的说话者。
399.声纹提取可通过用户100的头部位置和/或头部姿势来实现。例如,在谈话开始时,用户100可以通过注视说话者3303使他/她的脸朝向正在与用户100交谈的说话者,如图33中所示。类似地,当说话者3302正在讲话时,用户100可以注视说话者3302以向助听器系统指示助听器系统接收到的音频信号主要是由于说话者3302的语音引起的。在示例实施例中,在谈话开始时,助听器系统可以不被配置为在获得足够的数据(例如,声纹相关数据)以充分分离语音之前将特定语音从语音的混合中分离。然而,一旦助听器系统接收到足够的信息以充分分离语音,则助听器系统可以通过分离参与与用户100的谈话的说话者的语音来选择性地调节(例如,突然地或逐渐地)与用户100的谈话相关的音频信号。
400.在各种实施例中,说话者的声纹和特别是高质量的声纹可以提供快速有效的说话者分离。例如,当说话者单独讲话时,优选在安静环境中,可以收集说话者的高质量声纹。具有一个或多个说话者的声纹的助听器系统的处理器,使用滑动时间窗口几乎实时地(例如以最小的延迟)分离正在进行的语音信号。延迟可以是例如10毫秒、20毫秒、30毫秒、50毫秒、100毫秒等。根据声纹的质量、捕获的音频的质量、说话者和其他(多个)说话者之间的特性差异、可用的处理资源、所需的分离质量等,可以选择不同的时间窗口。
401.声纹提取可以通过从单个说话者的干净音频中提取频谱特征(也称为频谱属性、频谱包络或频谱图)来执行。干净的音频可以包括与诸如背景噪声或其它语音之类的任何其它声音隔离的单个说话者的语音的短样本(例如,1秒长、2秒长等)。干净的音频可以输入到基于计算机的模型中,诸如预先训练的神经网络,该神经网络基于提取的特征输出说话者的语音的签名。这种说话者的语音的签名可以包括与说话者的声纹相同的信息。额外地,或者可替代地,说话者的语音的签名可以包括可用于获得说话者的声纹的音频信息。在一
些情况下,说话者的语音的签名可以包括音频信息,该音频信息可以用于获得确定说话者的声纹所需的至少一些数据。
402.输出签名可以是数字向量。例如,对于提交给基于计算机的模型(例如,经训练的神经网络)的每个音频样本,基于计算机的模型可以输出形成向量的一组数字。任何合适的基于计算机的模型可用于处理由助听器系统的一个或多个麦克风捕获的音频数据以返回输出签名。在示例实施例中,基于计算机的模型可以检测和输出捕获的音频的各种统计特性,诸如音频的平均响度或平均音高、音频的频谱频率、响度的改变或音频的音高、音频的节奏模式等。这些参数可用于形成包括形成向量的一组数字的输出签名。
403.输出签名可以是表示说话者的语音的第一向量,使得第一向量与从相同的说话者的语音提取的另一向量(即,另一输出标签)之间的距离通常小于该说话者的语音的输出标签和从另一说话者的语音提取的输出标签之间的距离。在一些实施例中,说话者语音的输出签名可以是说话者的声纹,并且可以包括声谱图,该声谱图可以是在垂直轴上显示声音的频率和在水平轴上显示时间的图。不同的讲话声音可能会在图中产生不同的形状。声纹可以视觉地表示,并且可以包括颜色或灰色的阴影,以表示说话者的语音的声学质量。
404.图34a示出了用于分离音频信号中的语音的过程3400的流程图。在步骤3451,助听器系统可以接收音频信号3401。助听器系统可以包括基于计算机的模型3403,用于使用上述任何合适的方法将与说话者的语音相对应的音频信号与背景声音分离。在一些情况下,助听器系统可在谈话开始之前记录“房间音调”,其中房间音调可指用户100的环境的自然噪声。与房间音调相对应的音频签名可用于从包含谈话语音的音频信号中滤除背景噪声。
405.在步骤3452,模型3403可以输出语音音频信号3404。在步骤3453,信号3404可由语音模型3410接收,并且在步骤3454,语音模型可为说话者的语音输出声纹3411。模型3410可以使用上面描述的用于从说话者的语音获得声纹3411的任何合适方法,例如从说话者的语音提取谱图、提取统计音频特征等等。在过程3400的步骤3455,基于计算机的模型3430可接收声纹3411和音频信号3421,其可包括背景声音和/或一个或多个个体的一个或多个语音。
406.在各种实施例中,基于计算机的模型3430可以是神经网络。在步骤3456,模型3430可以接收噪声音频信号3421和说话者的签名或声纹3411,并且在步骤3457a或/和3457b,输出与语音3431a和/或语音3431b相关的音频信号。应当注意,滤波(即,分离)语音3431a和/或3431b可用于为说话者准备可由基于计算机的模型3430使用的附加声纹(或/和输出签名)。在一些实施例中,在步骤3455,可以使用一个以上的声纹(例如,声纹3411)作为模型3430的输入。在一些实施例中,多个声纹可对应于相同的个体,并且在其他实施例中,声纹中的一些可对应于第一人(例如,说话者3303,如图33所示),而其他声纹可对应于第二人(例如,说话者3302,如图33所示)。
407.图34b示出了用于使用视频信号从音频信号分离语音信号的说明性过程3470。在步骤3461,模型3445可以接收与用户100与说话者3302和3303的谈话有关的数据3443。数据3443可以包括视频信号3441和音频信号3421。视频信号3441可以指示说话者(例如,说话者3303)是在说话还是沉默。例如,视频信号3441可以显示说话者3303的嘴唇运动。音频信号3421可以包括背景声音以及说话者3302和3303的可能重叠或可能不重叠的语音。例如,说话者3302的语音可以与说话者3303的语音短暂重叠。模型3445可通过使说话者3303(或说话者3302)的嘴唇运动与在音频信号3421中识别的单词/声音同步来识别和分离说话者
3302和3303的语音。在一些实施例中,助听器系统可被配置为为两个说话者收集视频和音频数据。例如,助听器系统可以被配置为在谈话期间检测说话者3302和说话者3303的嘴唇运动。在步骤3457a或/和3457b,模型3445可以输出与语音3431和/或语音3432相关的音频信号。
408.在各种实施例中,由过程3400或过程3470中描述的助听器系统处理的选择性调节的音频信号(例如,语音3431a或语音3431b)可以被发送到用于将音频信号传送给用户100的接口设备(例如,耳机、头戴式耳机、扬声器、显示器、振动或触觉设备等)。在各种实施例中,接口设备可以是助听器系统的一部分。在一个示例实施例中,接口设备可以向用户100发送音频信号(例如,通过耳机发送给用户100的信号)、视觉信号(例如,写在屏幕上的文本或经由无声语言与用户100交流的人的视频)、振动信号、触觉信号(例如,视觉障碍者用来阅读的触觉字母)、电信号等。在示例实施例中,接口设备可以包括听力接口设备,其被配置为向用户的耳朵提供声音。在示例实施例中,听力接口设备可包括与耳机或骨传导麦克风相关联的扬声器。
409.在一些实施例中,助听器系统的听力接口设备可以向用户100发送与说话者的讲话相对应的音频信号,因为它是从助听器系统的一个或多个麦克风捕获的音频信号中提取的。额外地,或可替代地,助听器系统可以被配置为调整与说话者的讲话相对应的音频信号的一个或多个参数。例如,助听器系统可以在经由听力接口设备向用户100提供信号之前调整音频信号的音高、响度、节奏等。在一些实施例中,助听器系统可以配置为转录说话者的讲话、调整转录的讲话,以及使用文本到语音的自然语音人工智能读取器读取转录讲话。在一些实施例中,当检测到多个语音(例如,当语音3431a和3431b重叠时),助听器系统可以被配置为相对于另一个语音对一个语音进行时移,以减少重叠。可替代地,助听器系统可以配置为调整其中一个语音(例如,语音3431a)的一个或多个特征,以进一步区分其与语音3431b。例如,可以调整语音3431a的音调、节奏等,以区分语音3431a和语音3431b。
410.在一些实施例中,当存在多个麦克风(例如,存在两个麦克风)时,可以使用在两个麦克风之间测量的音频信号的延迟来确定与说话者的语音相关的音频信号的方向特性。在示例实施例中,用户100可以具有定位在左耳旁边的左麦克风和定位在右耳旁边的右麦克风。与用户100进行谈话的左说话者可以稍微位于用户100的左侧,并且来自左说话者的音频信号可以首先到达左麦克风,然后到达右麦克风,从而导致由两个麦克风接收的音频信号之间的相移。相移可用于区别于可能没有明确定义的相移或可能具有不同相移的其他信号。例如,如果存在另一个说话者(例如,位于用户100稍右侧的右说话者),则来自右说话者的音频信号可以具有与左说话者的相移不同的相移。例如,来自右说话者的音频信号可以首先到达用户100的右麦克风,然后到达用户100的左麦克风,从而导致与左说话者的相移具有相反符号的相移。在各种实施例中,用户100可以使用左麦克风和右麦克风移动他/她的头部以进一步区分左说话者和右说话者。
411.在某些情况下,由于一个或多个说话者的声纹不可用、一个或多个说话者的低质量声纹、不同说话者的两个或更多个语音彼此相似等原因,不同说话者的音频信号无法由助听器系统分离。在这种情况下,当确定谈话中存在两个或更多个语音时,输出信号可能被静音。此功能可帮助用户100在嘈杂的环境中适应。例如,这样的功能可以防止用户100在无法理解所说的内容的同时听到响亮和不愉快的噪音。因此,如上所述,使输出信号静音可以
不会降低用户100对谈话的理解,而是可以降低环境噪声,从而在谈话期间以改进用户100舒适度。在各种实施例中,输出信号的静音可以是部分的(也称为输出信号的抑制)。
412.图35a示出用于将从音频信号分离的语音发送到诸如助听器系统的耳机等设备的示例性过程3500。在步骤3504,可由助听器系统的处理器或服务器250的处理器接收由上述装置捕获的一个或多个图像。在一些实施例中,图像可以基本上按照用户的视线捕获,使得与用户100交流的说话者位于图像的中心或附近。在步骤3508,可以使用如上所述的任何适当方法在捕获的图像中识别说话者。在步骤3512,可以辨识说话者。说话者识别可以涉及在图像中定位人,而对说话者的辨识可涉及将被识别的人辨识为特定已知人。如果设备先前捕获了该人,并且他或她的姓名或另一细节被用户或以任何其它方式提供,则可以辨识该人。可以使用上述任何合适的方法来完成说话者的辨识。在步骤3514,被辨识的个体的图像可以显示在与助听器系统相关联的显示器上。例如,可以从数据库检索被辨识的个体的图像,并显示在与助听器系统配对的移动设备上。
413.在步骤3516,助听器系统的麦克风可以接收音频信号(例如,用户100与另一个体交流的音频信号)。音频信号可由助听器系统的处理器进一步分析。在示例实施例中,处理器可被配置为确定捕获的音频信号是否对应于被辨识的个体。例如,处理器可以被配置为基于个体的身份从存储设备检索被辨识的个体的声纹。例如,可以从服务器250的数据库检索声纹。额外地,或可替代地,可以通过在不包含来自其他说话者的音频信号和/或不包含大量环境噪声的谈话期间分析说话者的讲话来获得声纹。例如,谈话可以首先在安静的环境(例如,到达活动地点之前的汽车)中进行,随后谈话在餐厅进行(例如,嘈杂的环境)。
414.在步骤3520,接收到的音频信号可由处理器选择性地调节。额外地,或可替代地,接收到的音频信号可以被发送到服务器250,并由服务器250的处理器之一选择性地调节。在示例实施例中,选择性地调节可以包括从音频信号分离一个或多个说话者的语音。可以使用上述任一方法来执行分离。在一些实施例中,如果在步骤3512说话者被辨识,并且在步骤3602获得说话者的声纹,则可以通过仅提取特定说话者的语音而不是提取参与谈话的所有语音或背景声音(例如,不直接与用户100接触的语音)来分离接收到的音频。选择性调节可以使用上面讨论的任何合适的方法。
415.在步骤3524,可以将说话者的语音提供给用户100的助听器系统,以帮助用户100专注于与说话者的谈话,同时减少来自环境噪声和/或其他背景声音的干扰。如上所述,与说话者的语音相关的音频信号可以由助听器系统改变(例如,可以通过改变语音的音调、使用噪声消除或其他方法来放大和/或以其他方式改变语音)。
416.在各种实施例中,音频处理可以与图像处理技术相结合,例如通过识别并且在某些情况下辨识说话者,将接收的音频和与用户100交流的说话者的嘴唇的运动和\或基于说话者的嘴唇的运动的唇读(例如,声音“基于说可以由张开他或她的嘴的人发出)同步。在另一示例中,如果在用户100的环境中没有人正在讲话,则可以检测并消除背景噪声。
417.在一些实施例中,用户100接收的音频信号可以经由不同的信道到达用户100。例如,用户100可以参与与说话者的电话音频/视频谈话,并且背景噪声可能是由于用户100的环境引起的。在这种情况下,可以抑制背景噪声。
418.在各种实施例中,助听器系统可由电池操作。为了延长助听器系统的功能,可以使用各种方法来降低助听器系统的功耗。例如,助听器系统可以优化捕获视频帧的速率、降低
捕获图像的分辨率、优化捕获图像的压缩和/或优化捕获音频信号的压缩/质量。用于降低助听器系统的功耗的其他步骤可以包括优化从助听器系统到服务器250的数据传递过程。例如,助听器系统可以被配置为周期性地向服务器250传递数据,当助听器系统的功耗降低发生时,数据传递之间的时间间隔增加。
419.如上所述,在各种实施例中,可以在将对应于说话者的讲话的语音信号发送给用户100之前对其进行操作。例如,如果讲话速率超过预定值,则讲话可以被减慢并且以较低的速率发送到助听器系统。在呼吸或其他停顿期间,较低的速率可能会得到补偿,以免累积延迟。在进一步的实施例中,可以替换俚语或不恰当的词。例如,这些功能可能有助于帮助老年人与年轻人(例如他们的孙子孙女)进行交流。在一些实施例中,可以加速较慢的讲话,这可以帮助防止无聊或允许用户更快速地收听音频。
420.在一些实施例中,数据库可被配置为建立与各种说话者的各种相遇的时间线,并按时间顺序(chronologically)跟踪与不同个体的相遇。在一些情况下,基于从用户100接收到的输入,助听器系统的一个或多个处理器可被配置为放弃向数据库发送与在多个图像中识别的一个或多个个体的相遇有关的信息,从而防止此类信息的存储。例如,如果用户100认为相遇不重要,或者如果她/他不希望该信息可供第三方和/或用户100稍后访问/检查,则与相遇相关的信息可被忽略(即,不存储在服务器250的数据库中)。在某些情况下,为了防止访问存储在数据库中的信息,可以对信息进行密码保护。
421.在一些实例中,助听器系统的一个或多个处理器可配置为放弃向数据库发送与一个或多个被确定为与预定个体组相关联的个体的相遇有关的信息。例如,可以通过识别一组成员或识别该组中的个体的属性(例如,穿制服的所有个体)来识别一组个体。个体的属性可由用户100识别并使用助听器系统的用户界面输入。在某些情况下,可以从助听器系统捕获的图像推断个体的属性。在示例实施例中,一个或多个预定的个体组可以包括办公室工作人员、服务人员或用户100不与其参与语音交互的各种个体。在一些实施例中,预定组可以包括不参与与用户100的谈话的个体,并且在一些实施例中,预定组可以包括不参与与参与与用户100的谈话的个体的谈话的个体。如果用户100认为与被确定为与预定的个体组相关联的一个或多个个体的相遇不重要,或者如果她/他不希望第三方和/或用户100稍后访问/检查该信息,则与该相遇相关的信息可以被忽略(即,不存储在服务器250的数据库中)。在某些情况下,为了防止访问存储在数据库中的信息,可以对信息进行密码保护。
422.图35b是用于在时间轴中记录相遇的说明性过程3550。在过程3550的步骤3551,助听器系统可被配置为使用上述任何合适的方法为用户100捕获与个体的相遇。例如,助听器系统可以被配置为通过引导助听器系统的照相机和麦克风来捕获与相遇有关的图像/视频数据和音频数据来捕获相遇。在步骤3553,助听器系统可从用户100获得是否应忽略该相遇的输入。例如,助听器系统可以从用户100获得音频信号以忽略相遇。额外地,或可替代地,助听器系统可以通过触摸屏(例如,与助听器系统配对的移动设备的触摸屏)获得关于忽略相遇的用户100输入。如果确定不忽略该相遇(步骤3553,否),则可在步骤3555将该相遇记录在时间线中。相遇的记录可允许用户100通过指定相遇的一些识别特性来检索与相遇相关联的信息,诸如相遇的日期和时间、相遇的性质、相遇中识别和辨识的说话者、谈话的主题,等等。如果确定该相遇被忽略(步骤3553,是),则该相遇可能不会被记录,并且过程3550可以被终止。在一些实施例中,如果确定该相遇被忽略(步骤3553,是),则该相遇可以在从
时间线中删除之前被记录预定时间段。这种相遇的时间记录可以允许用户100改变他/她的关于忽略相遇的想法。
423.选择性调节包括重叠语音的音频信号
424.在一些实施例中,助听器系统可以包括至少一个处理器,该处理器被编程为从至少一个麦克风接收音频信号。处理器可被配置为基于对音频信号的分析来检测与第一时间段相关联的第一音频信号,其中第一音频信号代表单个个体的语音。另外,处理器可被配置为基于对音频信号的分析来检测与第二时间段相关联的第二音频信号,其中第二时间段不同于第一时间段,并且其中第二音频信号代表两个或更多个个体的重叠语音。
425.与重叠语音相对应的音频信号可以包括至少两个重叠语音,并且在某些情况下,可以包括两个以上的语音。在一些情况下,一些重叠语音可能非常接近用户100,并且具有高幅度,而其他重叠语音可能更远离用户100,并且具有较低幅度。在某些情况下,高幅度的语音可能与低幅度的语音重叠。在各种实施例中,当在第一时间间隔期间发射与第一语音相关联的语音时,第一和第二语音重叠,在第二时间间隔期间发射与第二语音相关联的语音,并且第一和第二时间间隔重叠。在某些情况下,第一和第二时间窗口可能部分重叠。例如,第一时间窗口的一部分可以与第二时间窗口的一部分重叠。应当注意,第一时间窗的持续时间可以短于或长于第二时间窗的持续时间。
426.当音频信号包含两个以上的语音时,两个以上的语音可能重叠。例如,当音频信号包括第一、第二和第三语音时,第一和第二语音可以重叠,第二和第三语音可以重叠,第三和第一语音可以重叠,并且在某些情况下,所有三个语音可以重叠。
427.在一个示例性实施例中,处理器可选择性地调节第一音频信号和第二音频信号,其中,相对于第二音频信号的选择性调节,第一音频信号的选择性调节至少在一个方面不同。例如,选择性地调节第一音频信号可以包括去除背景声音和分离在第一音频信号中检测到的个体的语音。额外地,或者可替代地,选择性地调节第一音频信号可以包括信号的放大、改变信号的音调或者改变与信号相关联的讲话速率。在示例实施例中,选择性地调节第二音频信号可以包括第二音频信号的放大。在一些情况下,当第一和第二音频信号都被放大时,与第二音频信号相关联的放大水平可以小于与第一音频信号相关联的放大水平。在一些实施例中,第二音频信号的选择性调节包括信号的衰减。例如,信号可以被完全或部分衰减。在一些情况下,第二音频信号的一些频率可以被衰减。额外地,或者可替代地,第二音频信号的一些部分可以衰减,而其他部分可以不变或放大。在一些情况下,第二音频信号的幅度可以以时间依赖的方式衰减,并且在一些情况下,第二音频信号的一组频率的幅度可以以时间依赖的方式衰减。在一些情况下,第二音频信号的选择性调节包括放弃将第二音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。例如,当第二信号中语音不可清楚地辨别,并且可能对用户100造成混淆时,第二音频信号可以不被发送到听力接口设备。
428.在各种实施例中,助听器系统的至少一个处理器可以被编程来分析由可穿戴照相机(例如,图像捕获设备3322)捕获的多个图像,并且在多个图像的至少一个图像中识别与第一音频信号相关联的单个个体的表示。例如,处理器可以被编程为捕获与个体的面部表情相关的视频数据,并通过评估面部表情和在第一音频信号中检测到的声音之间的相关性来分析视频帧。在某些情况下,分析可以识别特定面部表情和特定声音或声音波动之间的
相关性。例如,与特定嘴唇运动相关的面部表情可以与在第一音频信号中捕获的谈话期间可能已经说过的声音或单词相关联。在一些实施例中,多个图像的分析由基于计算机的模型(诸如,经训练的神经网络)执行。例如,经训练的神经网络可被训练成接收与个体面部表情相关的图像和/或视频数据,并预测与所接收的图像和/或视频数据相关联的声音。例如,经训练的神经网络可以被训练成接收与个体的面部表情和声音相关的图像和/或视频数据,并输出面部表情是否对应于声音。在一些实施例中,可在可穿戴照相机捕获的一个或多个图像中识别其他因素,诸如个体的姿势、个体的位置、个体脸部的方向等。这些因素可单独使用或与个体的面部表情组合使用以确定个体是否与第一音频信号相关联。
429.在一些实施例中,至少一个音频信号(例如,第一音频信号)被确定为与基于用户的嘴唇运动而被辨识的个体相关联,用户的嘴唇的运动基于多个图像的分析而被检测。例如,可以基于检测到的嘴唇运动是否与和至少一个音频信号相关联的语音信号一致的确定来确定第一音频信号与被辨识的个体相关联。
430.在各种实施例中,助听器系统的至少一个处理器被配置为将调节后的第一音频信号传输到听力接口设备,该听力接口设备被配置为使用上述任何合适的方法向用户100的耳朵提供声音语音。在一些实施例中,处理器还可以被配置为将调节后的第二音频信号传输到听力接口设备,该听力接口设备被配置为使用上述任何合适的方法向用户100的耳朵提供声音。
431.图36a示出描述用于从与用户100交流的说话者向用户100发送语音数据的示例性步骤的说明性过程3600。在步骤3602,助听器系统可以接收捕获的音频。过程3600的步骤3602可以类似于过程3500的步骤3516。在步骤3603,助听器系统可以确定接收到的音频是否包括单个说话者的讲话。这种确定可以使用上述任何合适的方法来完成(例如,使用可确定与用于说话者的讲话的音频信号相对应的相移的多个麦克风,使用可将说话者的声纹作为输入的基于计算机的模型,可以评估说话者的数量的分析算法等)。如果助听器系统确定接收到的音频包括来自单个说话者的讲话(步骤3603,是),则在步骤3605,可以从音频中提取说话者的声纹,并且可选地用于增强先前可用的声纹。在一些实施例中,声纹可以与助听器系统辨识的说话者相关联,并且在一些实施例中,当说话者未被辨识时,可以为说话者提取声纹。在一些实施例中,如果说话者存在声纹,则可以不从接收的音频数据中提取新的声纹。在步骤3607,如上所述,可以将说话者的语音发送到助听器系统的听力接口设备并作为音频信号传送给用户100。在一些实施例中,可以经由视觉接口、触觉接口等将语音发送给用户100。
432.如果在步骤3603助听器系统确定接收到的音频信号包括多个说话者的声音(步骤3603,否),则过程3600可被配置为遵循步骤3604并确定是否可获得至少一个说话者的声纹。在各种实施例中,如果助听器系统辨识出一个或多个说话者,则助听器系统可以访问与一个或多个说话者相关联的数据并确定相关声纹是否可用。例如,助听器系统可以从服务器250的数据库访问说话者数据记录以确定声纹是否可用。步骤3604可以使用经训练的模型来确定音频信号是否包括与特定声纹相关联的讲话,或者提供音频信号包括与特定声纹相关联的讲话的概率。
433.在一些实施例中,一旦辨识与用户100交流的说话者,并且她或他的语音音频数据与用于谈话的音频信号分离并发送给用户100,即使其他语音(无论是否被辨识)被捕获/当
其他语音(无论是否被辨识)被捕获时,只要说话者连续地讲话,音频数据可以被发送。这样的方法可用于允许用户100连续地听说话者。讲话中短暂的中断(例如,呼吸中断或搜索单词时的停顿)仍然可以被视为连续的讲话。在一些实施例中,可将高达预定长度的停顿视为连续讲话的一部分,而更长的时间可被视为说话者的讲话结束,以便可以检测或放大其他说话者。
434.如果声纹可用,(步骤3604,是),则在步骤3606,说话者的语音可以从音频数据中分离并发送给用户100。如果没有声纹可用,和/或如果说话者的语音与音频数据的分离不成功,(步骤3604,否),助听器系统可在步骤3601使输出静音。可以使用上述任一方法使输出静音。在一些实施例中,例如,当在餐厅中与人讲话并且看到侍者走近并且说话但没有听到任何声音时,完全静音其余语音可产生不安和断章取义的感觉。因此,为其他声音提供低但正的放大,例如,10%、20%或任何其他合适程度的音量,对于用户100来说可能感觉更自然。类似地,如果助听器系统没有辨识任何语音,则可以将环境噪声的响度降低到预定水平,而不是使所有声音静音。在这种情况下,与环境声音相关的音频可以以较低的音量(例如,原始音量的10%)发送以获得更自然的感觉,使得用户100例如能够在餐厅听到一些背景噪声。助听器系统选择的响度等级可以由用户设置,也可以根据环境状况、用户100的位置、一天中的时间等而预先确定。
435.助听器系统可被配置为处理环境声音并确定某些声音是否可以被静音或抑制。例如,可能重要且与用户100相关的声音可以不被过滤、抑制或静音。例如,紧急声音,诸如火警、警笛声、尖叫声、小孩哭泣声等,不能被静音、调整或抑制。
436.在一些实施例中,一些声音(无论是预定的、是否被辨识)可以延迟放大和发送。例如,在机场,当有关于航班的通告时,设备可能会意识到只有在提及航班号之后,这才是重要的通告。然后,即使通告的声音可能与参与在和用户100的谈话中的说话者的语音不相关,它也可以播放整个通告。
437.在各种实施例中,语音分离和放大过程可能与时间有关,并且可能取决于助听器系统的麦克风捕获的音频内容,例如,可以通过分析助听器系统捕获的图像来确定环境因素。在一些实施例中,助听器系统可在预定滑动时间窗口期间收集音频数据,然后在该窗口内分离语音音频数据。对于短时间窗口(例如,毫秒、几毫秒、一秒、几秒等),用户100可能只经历捕获的音频和发送给用户100的语音数据之间的短延迟。在示例实施例中,时间窗口可以小于一秒,例如,10毫秒、20毫秒、50毫秒、100毫秒等。
438.在一些实施例中,助听器系统可使用户100从某些个体中选择音频语音信号,以优先于其他音频语音信号。在各种实施例中,可以提取和存储这些个体的声纹。如果在助听器系统捕获的图像中辨识出所指示的说话者中的一个,或者如果在捕获的音频辨识识别出他们的语音,则这些选定的语音可以相对于其他说话者的语音或其他声音(诸如来自电视或说话者的声音)来放大。例如,可以为用户100识别和放大父母、配偶、孩子、孙子、曾孙或其他家庭成员的语音,使得用户100能够相对于其他语音或其他环境声音识别这些语音。
439.在一些实施例中,当助听器系统捕获到与被辨识的个体的语音/声音(包括用户100的语音)相关的音频信号时,助听器系统可以与各种其他设备交互。例如,助听器系统可以与可能影响用户100的环境的智能家居设备交互。例如,助听器系统可以与智能家庭设备交互以打开/关闭灯、发出特殊声音、打开/关闭电视等等。
440.与语音无关的音频声音可以与其他音频信号分离。例如,这种音频声音可能包括狗吠叫或嚎叫的声音、婴儿哭声或发出声音、玻璃破碎的声音、掉落物体的声音、吱吱声/开门/关门声、门铃声等。这些声音可以相对于其他可能不太重要的环境声音(例如,电台的声音)放大。
441.放大后的语音可以通过助听器提供给用户100,而其他声音可以被静音或抑制。用户100可以配置助听器系统以静音或抑制所选个体的语音(例如,用户100可以经由助听器系统的接口设备选择所选个体)。例如,所选个体可以在由助听器系统捕获的一个或多个图像中辨识,或者这些个体可以在捕获的音频中由于其声纹而被辨识。如上所述,除了或替代放大与所选语音相关的音频信号,还可以增强语音的音频信号,例如,可以改变音调,或者可以进行其他调整。
442.在一些实施例中,助听器系统可为各种说话者创建语音的“层次结构”,其中该层次结构可以是也可以不是时间或情况依赖的。例如,在讲课期间,即使当用户正看着另一个人时,用户100可能希望演讲者的语音被放大。在示例实施例中,当用户100在会议中时,用户100可能希望接收来自所选人员或一群人(例如,来自用户100的主管)的讲话。在一些实施例中,用户100可以分离捕获的音频数据中的各种语音,但是只放大一个选定的语音。在各种实施例中,可以记录或/和转录其他语音。在一些情况下,用户100可以丢弃某些被认为不重要的个体的语音。
443.在各种实施例中,助听器系统可以是装置110,其可以包括如上所述的处理器和存储器。助听器系统可以包括软件应用,该软件应用可以包含存储在助听器系统的存储器3650中的软件模块,如图36b示意地示出的。软件模块可以包括说话者识别模块3654、说话者分离模块3658、说话者和语音匹配模块3662、声纹处理模块3666和用户接口3670。
444.模块3654、3658、3662、3666和3670可包含用于由包括在可穿戴装置中的至少一个处理设备(例如处理器210)执行的软件指令。在一些实施例中,模块中的任何一个或多个可有助于处理来自图像传感器(例如,图像传感器220)的一个或多个图像,并且有助于音频传感器生成一组指令来帮助用户100改进用户100听到一个或多个说话者的语音。
445.说话者识别模块3654可用于识别由该装置捕获的图像中的一个或多个说话者,以使得可以识别与用户100交流的说话者。说话者识别模块3654可以通过在可以显示用户100的视野的捕获图像中的他\她的位置来识别说话者。例如,如果说话者位于图像的中心,则说话者可能位于视野的中心。在一些实施例中,用户100头部的方向可用于识别说话者。例如,助听器系统可以被配置为在垂直于用户100的面部(例如,垂直于用户100的下巴)的方向上捕获图像,以辨别捕获图像中的说话者。在一些实施例中,如前面所讨论的,模块3654可以识别说话者的数据记录。在示例性实施例中,模块3654可以基于检测到的用户的注视方向(基于与在多个图像中的至少一个图像中检测到的用户的下巴相关联的方向确定)将至少一个音频信号与被辨识的和被辨别的个体相关联。
446.声纹处理模块3666可用于使用例如小波变换或一个或多个人的语音的任何其他属性来生成、存储或检索声纹。声纹处理模块3666可以使用任何合适的算法来确定音频信号是否包括讲话,以及确定是否有一个或多个说话者参与谈话。然后,可以使用如上所述的神经网络从单个讲话音频中提取声纹。使用声纹处理模块3666获得的信息可以被发送到说话者识别模块3654,并且模块3654可以将所识别的说话者与声纹相关联。
447.在各种实施例中,说话者分离模块3658可以接收由设备捕获的噪声音频和一个或多个扬说话者的声纹,并且使用上述任一方法为一个或多个说话者分离一个或多个语音。在一些实施例中,例如当没有可用于说话这的声纹时,可以根据捕获的图像来执行将语音与特定说话者的匹配,例如通过将识别出的单词与说话者的嘴唇运动匹配、通过匹配讲话和静默时间段等。
448.在一些实施例中,当从捕获的图像确定说话者的身份时,说话者和语音匹配模块3662可用于将说话者的身份与对应于使用说话者分离模块3658检测到的说话者的语音的音频信号匹配。在一些实施例中,当没有建立说话者身份时,模块3662可以使用说话者的图像来与说话者的语音的音频信号相对应。
449.在各种实施例中,助听器系统可以包括用户接口3670,以允许用户100改变助听器系统的性能特性。在一些实施例中,用户接口3670可以包括用于从用户100接收视觉、音频、触觉或任何其他合适信号的接口。例如,该界面可以包括可以是移动设备(例如,智能手机、膝上型计算机、平板等)的一部分的显示器。在一个示例实施例中,该界面可以包括触摸屏、图形用户界面(gui),该图形用户界面(gui)具有可以由用户手势或适当的物理或虚拟(即,在屏幕上)设备(如键盘、鼠标等)操纵的gui元件。在一些实施例中,接口3670可以是能够接收用于调整助听器系统的一个或多个参数的用户100音频输入(例如,用户100语音输入)的音频接口。例如,用户100可以使用音频输入、由助听器系统产生的音频信号的音高、音频信号的节奏等来调整助听器系统产生的音频信号的响度。在一些实施例中,用户接口3670可以被配置为帮助用户100识别与用户100谈话的说话者的数据记录,并促进说话者的语音与助听器系统的麦克风捕获的音频数据的分离。例如,接口3670可以提示用户100从可用名称的列表中选择说话者的姓名、显示说话者的图像、选择与说话者的语音相对应的音频流等。
450.图37a示出将调节后的音频信号发送到设备(例如助听器系统的耳机)的说明性过程3700。在步骤3504,助听器系统可以捕获参与和用户100的谈话的说话者的一个或多个图像。过程3700的步骤3504可以与过程3500的步骤3504相同。在步骤3508,可以如上所述识别说话者。在各种实施例中,过程3700的步骤3508可以与过程3500的步骤3508相同。在步骤3701,助听器系统可以确定是否使用上述任何合适的方法来辨识所识别的说话者。如果说话者被辨识(步骤3701,是),则在步骤3703中可以显示被辨识的人的图像。如果说话者未被辨识(步骤3701,否),则过程3700可被终止。在一些实施例中,如果说话者未被辨识,则与说话者的语音相关联的音频信号可以如上所述被静音或抑制。
451.在步骤3516,助听器系统的处理器可以接收与用户100和一个或多个说话者谈话有关的音频数据。在各种实施例中,过程3700的步骤3516可以与过程3500的步骤3602相同。在步骤3705,助听器系统的处理器可以使用上述任何合适的方法选择性地调节接收到的音频数据。例如,处理器可以通过分析数据并从接收到的音频数据中分离与一个或多个说话者相关的一个或多个语音数据来选择性地调节接收到的音频数据。在一些实施例中,选择性地调节音频数据可以包括如上所述移除音频背景噪声数据。
452.在步骤3707,可向用户100的助听器系统提供(例如)调节后的音频信号。例如,可将调节后的音频信号提供给听力接口设备(例如,耳机、头戴式耳机、扬声器等)。步骤3707可以类似于过程3500的步骤3524。
453.图37b示出了将调节后的音频信号发送到设备(例如助听器系统的耳机)的说明性
过程3760。在步骤3761,助听器系统的处理器可被编程为从至少一个麦克风接收音频信号。在各种实施例中,步骤3761可以与过程3500的步骤3602相同。
454.在步骤3762,助听器系统的处理器可确定音频信号是否与被辨识的个体的语音相关联或包括被辨识的个体的讲话。处理器可以使用上面描述的任何合适的方法进行确定,诸如使用训练的引擎,将个体的音频信号与正在被辨识其图像的人的声纹进行比较,等等。
455.在步骤3763,可以在用户100可用的计算设备(例如,移动设备)的屏幕上显示个体的图像。在各种实施例中,步骤3763可以与过程3500的步骤3514相同。在步骤3764,助听器系统的处理器可选择性地调节接收到的音频信号。在各种实施例中,步骤3764可以与过程3500的步骤3520相同。在一些实施例中,可以将音频信号发送到服务器250,并且服务器250的处理器可以选择性地调节音频信号。可以使用上述任何合适的方法来实现对所接收音频信号的选择性调节。例如,助听器系统的处理器可以通过分析信号并从接收到的音频信号中分离与一个或多个说话者相关的一个或多个语音数据来选择性地调节接收到的音频信号。在一些实施例中,选择性地调节音频信号可以包括如上所述移除音频背景噪声数据。
456.在步骤3766,可将调节后的音频信号提供给用户100的助听器接口。例如,调节后的音频信号可以被发送到听力接口设备(例如,耳机、头戴式耳机、扬声器等)。步骤3766可以类似于过程3500的步骤3524。
457.图37c示出将调节后的音频信号发送到设备(例如助听器系统的耳机)的说明性过程3770。在步骤3771,助听器系统的处理器可被编程为从至少一个麦克风接收音频信号。在各种实施例中,步骤3771可以与过程3500的步骤3516相同。
458.在步骤3772,助听器系统的处理器可以基于对音频信号的分析检测与第一时间段相关联的第一音频信号,其中第一音频信号代表单个个体的语音。在示例性实施例中,第一音频信号可以对应于在第一时间窗口期间与用户100交流的单个人。可替代地,在第一时间窗口中,多个个体可以与用户100交流,多个个体具有不同的语音,助听器系统的处理器能够使用上述任何适当方法来分离不同语音。在一些实施例中,与第一时间窗口相关联的音频信号可以发送到服务器250,服务器250的处理器可以分离音频信号以提取与用户100交流的个体的语音。
459.在步骤3773,助听器系统的处理器可以基于对音频信号的分析,检测与第二时间段相关联的第二音频信号,其中第二时间段与第一时间段不同,其中第二音频信号代表两个或更多个个体的重叠语音。例如,当多个说话者同时讲话时,第二时间窗口可以对应于实例。在一些实施例中,第一或第二时间窗口可以不必对应于连续时间间隔。例如,在谈话期间,单个个体的讲话可能会在不同时间被其他个体的语音重叠。在这种情况下,单个个体讲话的时间对应于第一时间窗口并且多个个体讲话的时间对应于第二时间窗口。
460.在步骤3774,可以使用上述任何适当方法选择性地调节第一检测到的音频信号。在各种实施例中,步骤3774可以类似于过程3500的步骤3520。在步骤3775,可以使用上述任何适当方法选择性地调节第二检测到的音频信号。在各种实施例中,第一音频信号的选择性调节可以在至少一个方面相对于第二音频信号的选择性调节不同。例如,当第二音频信号可以被抑制时,可以放大第一音频信号。在各种实施例中,可以分离和抑制第二音频信号中呈现的一些语音,并且可以放大或以如上所述的任何适当方式放大或调整在第二音频信号中呈现的其他语音。
461.在步骤3776,可将调节后的音频信号提供给用户100的助听器系统。例如,调节后的音频信号可以被发送到听力接口设备(例如,耳机、头戴式耳机、扬声器等)。步骤3776可以类似于过程3500的步骤3524。
462.在各种实施例中,助听器系统的处理器可编程为分析由助听器系统的可穿戴照相机捕获的一个或多个图像,并识别两个或更多个个体,其中,第一音频信号和第二音频信号的选择调节基于与两个或更多个个体中的至少一个个体的身份相关联的信息。例如,如果用户100清楚地听到所识别个体(例如,当个体之一是用户的老板时)的语音是重要的,所识别个体的语音可以被放大。在各种实施例中,可以使用上面讨论的任何适当方法来识别两个个体中的一个。例如,可以使用经训练以辨识图像中的人的、基于计算机的模型来识别个体。在一些情况下,还可以基于在第一音频信号或第二音频信号内检测到的音频信号来识别个体。例如,助听器系统可从服务器250的数据库检索已知个体的各种声纹,并使用检索到的声纹中的一个或多个来识别第一音频信号或第二音频信号内的已知个体的语音。
463.在一些实施例中,助听器系统可配置为调节第一和第二音频信号,并以上文讨论的任何适当方式调整与所识别个体相关联的语音。例如,助听器系统可以抑制与所识别的一个或多个个体相关联的一个或多个语音、放大一个或多个语音、改变一个或多个语音的音高或速率等。作为另一示例,当存在两个个体并且识别出一个个体时,所识别个体的语音可以被放大,并且第二个体的语音可以被抑制。作为又一示例,第二个体的语音可以被转录并显示在与用户100的助听器系统相关联的设备上。
464.在各种实施例中,当音频信号包含各种个体的重叠语音时,助听器系统可识别与语音相关的音频信号,并使用任何合适的逻辑选择性地调节(例如,通过放大和抑制语音)音频信号。例如,助听器系统可以放大与特定主题相关的语音、与用户100进行谈话的个体的语音、与特定个体进行谈话的个体的语音、由用户100选择的个体的语音等。在一些情况下,助听器系统可被配置为抑制背景谈话(例如,不直接与用户100谈话的各种说话者之间的谈话)的重叠语音。在某些情况下,助听器系统可抑制助听器系统不能转录的语音(例如,不能清晰听到的语音,或不呈现可辨别有用信息(诸如产生可被解释为对应于单词的声音的语音)的语音)。
465.识别信息和相关联的个体
466.根据本公开的实施例,助听器系统可以辨识用户(如图1a
‑
1b和2中的用户100)周围环境中的说话者。在一些实施例中,助听器系统可以进一步辨识一个说话者正在与另一个说话者或用户100谈话。这种辨识可以通过图像分析、音频分析或两者来实施。助听器系统可以转录说话者之间已辨识的谈话。在一些实施例中,如果说话者是被辨识的个体,则谈话可以与说话者的相应标识符(例如,姓名)相关联。在一些实施例中,助听器系统可以从说话者(例如,当用户100正在开会时)捕获指向用户100的指令或动作项。
467.图38a是示出根据示例性实施例的助听器系统3800的框图。如图38a所示,助听器系统3800包括至少一个可穿戴照相机3801、至少一个麦克风3802、至少一个处理器3803和存储器3804。在一些实施例中,系统3800还可以包括其他组件,诸如如图5a
‑
5c所示的组件。
468.在一些实施例中,可穿戴照相机3801可以从用户100的环境捕获图像。在一些实施例中,可穿戴照相机3801可包括图5a或5c中的图像传感器220。在一些实施例中,可穿戴照相机3801可包括图5b中的图像传感器220a或220b中的至少一个。
469.在一些实施例中,麦克风3802可以捕获来自用户100的环境的声音。在一些实施例中,麦克风3802可以包括定向麦克风。在一些实施例中,麦克风3802可包括多个麦克风(例如,麦克风阵列)。在这种情况下,一个麦克风可以仅捕获背景噪声,而另一个麦克风可以捕获包括背景噪声以及个体语音的组合音频。处理器3803可以通过从组合音频中减去背景噪声来获得语音。在一些其它实施例中,系统3800可包括至少一个麦克风和压力传感器(未示出)。压力传感器可将空气压力差(例如,由声波引起)编码为数字信号。系统3800可以处理由麦克风3802捕获的声音和由压力传感器捕获的数字信号,以分离所需的语音和背景噪声。
470.在一些实施例中,可穿戴照相机3801和麦克风3802可包括在公共外壳(例如,壳)中。例如,可穿戴照相机3801和麦克风3802可以包括在图3a
‑
3b和4a
‑
4b中的装置110的公共外壳中。
471.在一些实施例中,处理器3803可以实施为图5a或5c中的处理器210。在一些实施例中,处理器3803可以实施为图5b中的处理器210a或210b中的至少一个。在一些实施例中,处理器3803可以实施为图5c中的处理器540。在一些实施例中,处理器3803可以包括在包括可穿戴照相机3801和麦克风3802的公共外壳中。例如,处理器3803可以包括在图3a
‑
3b和4a
‑
4b中的装置110的公共外壳中。在一些实施例中,处理器3803可以包括在与公共外壳分离的第二外壳中。在一些实施例中,第二外壳可以与配对的移动设备相关联。例如,移动设备可以是图1a
‑
1d、2或5c中的计算设备120。移动设备可经由例如无线链路(例如链接)与系统300配对。在这种情况下,处理器3803(例如,在图5c中实施为处理器540)可以包括在计算设备120的外壳中。当处理器3803位于第二外壳中时,在一些实施例中,处理器3093可以经由公共外壳中的发射器(例如,图5c中的无线收发器503a)和第二外壳中的接收器(例如,图5c中的无线收发器503b)之间的无线链路来接收数据(例如,可穿戴照相机3801捕获的图像)。例如,无线链路可以是的图像)。例如,无线链路可以是链路、wi
‑
fi链路、近场通信(nfc)链路等。
472.在一些实施例中,存储器3804可以实施为存储器550,如图5a和5b所示。在一些实施例中,存储器3804可以实施为图5c中的存储器550a和550b中的至少一个。
473.装置110可以被配置为从用户100的环境中的个体推断指令。图38b是示出用于使用与本公开一致的具有指令推导能力的助听器的示例性环境的示意图。
474.如图所示,装置110可被配置为辨识与用户100的环境中的个体3807相关联的面部3805或语音3806。例如,装置110可以被配置为使用可穿戴照相机3801捕获用户100的周围环境的一个或多个图像。捕获的图像可以包括被辨识的个体3807的表示,该个体3807可以是用户100的朋友、同事、亲戚或先前的熟人。处理器3803(例如,处理器210a和/或210b)可被配置为使用各种面部辨识技术来分析所捕获的图像并检测被辨识的用户。因此,装置110或具体地存储器550可以包括一个或多个面部或语音辨识组件。
475.处理器3803还可以配置为基于与个体3807的语音相关联的声音的一个或多个检测到的声音特性来确定个体3807是否被用户100辨识。处理器3803可以确定声音3808对应于用户3807的语音3806。处理器3803可以分析代表麦克风3802捕获的声音3808的音频信号,以确定个体3807是否被用户100辨识。这可以使用一个或多个语音辨识算法来执行,诸如隐马尔可夫模型、动态时间扭曲、神经网络或其他技术。语音辨识组件和/或处理器3803
可以访问数据库(未示出),数据库还可以包括一个或多个个体的声纹。处理器3803可以执行语音辨识,以分析代表声音3808的音频信号,以确定语音3806是否与数据库中的个体的声纹相匹配。因此,数据库可以包含与多个个体相关联的声纹数据。在确定匹配后,可以确定个体3807是用户100的被辨识的个体。该过程可以单独使用,也可以与面部辨识技术结合使用。例如,可以使用面部辨识辨识个体3807,并且可以使用语音辨识来验证,反之亦然。
476.在确定个体3807是装置110的被辨识的个体后,处理器3803可引起与被辨识的个体相关联的音频的选择性调节。调节后的音频信号可以发送到听力接口设备(例如扬声器或耳机),因此可以向用户100提供基于被辨识的个体的音频调节。例如,调节可以包括相对于其他音频信号放大被确定为与声音3808相对应的音频信号(该声音3808可以对应于用户3807的语音3806)。在一些实施例中,放大可以通过数字方式实现,例如,通过相对于其他信号处理与声音3808相关联的音频信号。额外地,或可替代地,放大可以通过改变麦克风3802的一个或多个参数以聚焦于与个体3807相关的音频声音来实现。例如,麦克风3802可以是定向麦克风,处理器3803可以执行将麦克风3802聚焦到声音3808上的操作。可以使用用于放大声音3808的各种其他技术,诸如使用波束形成麦克风阵列、声学望远镜技术等。
477.在一些实施例中,选择性调节可包括衰减或抑制从与个体3807不相关联的方向接收的一个或多个音频信号。例如,处理器3803可以衰减声音3809和3810。与声音3808的放大类似,声音的衰减可以通过处理音频信号来发生,或者通过改变与麦克风3802相关的一个或多个参数来定向焦点远离与个体3807无关的声音。
478.选择性调节还可以包括确定个体3807是否在讲话。例如,处理器3803可以配置为分析包含个体3807的表示的图像或视频,以确定个体3807何时正在讲话,例如,基于检测到的被辨识的个体的嘴唇的移动。也可以通过分析麦克风3802接收的音频信号来确定,例如通过检测个体3807的语音3806来确定。在一些实施例中,基于被辨识的个体是否在讲话,选择性调节可以动态地发生(启动和/或终止)。
479.在一些实施例中,调节还可以包括改变与声音3808相对应的一个或多个音频信号的音调,以使声音对于用户100更加可感知。例如,用户100对特定范围内的音调具有较小的敏感性,并且音频信号的调节可以调整声音3808的音高。在一些实施例中,处理器3803可以被配置为改变与一个或多个音频信号相关联的讲话速率。例如,声音3808可被确定为对应于个体3807的语音3806。处理器3803可配置为改变个体3807的讲话速率,以使检测到的讲话对于用户100更加可感知。可以执行各种其他处理,诸如调整声音3808的音调以保持与原始音频信号相同的音高,或减少音频信号内的噪声。
480.在一些实施例中,处理器3803可以确定与个体3807相关联的区域3811。区域3811可与个体3807相对于装置110或用户100的方向相关联。个体3807的方向可以使用可穿戴照相机3801和/或麦克风3802使用上述方法来确定。如图38b所示,区域3811可以由基于个体3807的确定方向的方向的圆锥体或方向范围来定义。角度范围可以由一个角度定义θ确定如图38b所示。角度θ示。可以是用于定义用于在用户100的环境中调节声音的范围的任何合适的角度(例如,10度、20度、45度)。当个体3807的位置相对于装置110改变时,可以动态地计算区域3811。例如,当用户100转动时,或者如果个体3807在环境中移动,则处理器3803可被配置为跟踪环境中的个体3807并动态地更新区域3811。区域3811可用于选择性调节,例如通过放大与区域3811相关联的声音和/或衰减确定为从区域3811外部发出的声音。
481.然后可将调节后的音频信号发送到听力接口设备并为用户100产生。因此,在调节后的音频信号中,声音3808(具体地说,语音3806)可以比声音3809和3810更大和/或更容易辨别,声音3809和3810可以表示环境中的背景噪声。
482.在一些实施例中,处理器3803可以基于图像确定被辨识的个体相对于用户的方向。在一些实施例中,处理器3803可被配置为确定图像中个体的注视方向。在一些实施例中,当被辨识的个体正在对用户讲话时,选择性调节可以包括相对于从与被辨识的个体相关联的区域之外的方向接收的其他音频信号放大与被辨识的个体相关联的音频信号。如果被辨识的个体正对着用户讲话(例如,图38b中的个体3807对着用户100讲话),则处理器3803可以转录与被辨识的个体的语音相关联的讲话对应的文本。
483.图38c示出了穿戴示例性助听器系统的用户。用户100可以穿戴系统3800(例如,作为可穿戴设备)。可穿戴照相机3801可以捕获用户100的环境的图像。如图38c所示,第一个体3812可以站在用户100的前面并且朝用户100的方向看。另外,第二个体3813也可以站在用户100的前面,但是朝远离用户100的方向看。系统3800的图像传感器可以捕获包括第一个体3812和第二个体3813的一个或多个图像。处理器3803可以分析由可穿戴照相机3801捕获的图像。处理器3803还可以基于图像分析或面部辨识来识别包括在图像中的一个或多个个体。例如,处理器3803可以识别图像中包括的第一个体3812和第二个体3813。基于该分析,处理器3803可以检测到第一个体3812正朝着用户100的方向看,而第二个体3813正朝着远离用户100的方向看。麦克风3804可以从用户100的环境接收一个或多个音频信号。例如,麦克风3804可被配置为接收(或检测)与第一个体3812的语音相关联的第一音频信号和与第二个体3813的语音相关联的第二音频信号。在如图38c所示的示例中,基于第一个体3812和第二个体3813的注视方向,处理器3803可以转录对应于与第一个体3812的语音相关联的讲话的文本,但是不转录对应于与第二个体3813的语音相关联的讲话的文本。
484.在一些实施例中,处理器3803可被编程为执行用于为用户100推导指令的方法。图39a是示出用于推导根据实施例的助听器系统的指令的过程3900a的流程图。处理器3803可执行过程3900a以在系统300捕获个体的语音或图像之后辨识用户100的周围环境中的个体。
485.步骤3902,处理器3803可以接收由可穿戴照相机3801捕获的图像。在一些实施例中,图像可以包括人类。在一些实施例中,可穿戴照相机3801可捕获基本上与用户100的视线一致的图像,使得与之交谈的单个用户100可能在图像的中心或附近。
486.在步骤3904,处理器3803接收代表由麦克风3802捕获的声音的音频信号。在一些实施例中,音频信号可以包括由用户100附近的一个或多个体发出的讲话或非讲话声音、环境声音(例如,音乐、音调或环境噪声)等。在一些实施例中,声音可以是音频流。音频流可以由音频信号分量的组合构成。每个音频信号分量可以被分离以提供唯一的音频信号。处理器3803随后可接收多个这样的独特音频信号。
487.在步骤3906,处理器3803可以识别在至少一个图像中表示的第一个体。在一些实施例中,处理器3803可以接收多个图像。在一些实施例中,步骤3906可以是可选的。第一个体可以出现在多个图像中的一些或全部中。在一些实施例中,处理器3803可实施图像处理技术(例如,算法或软件模块)以辨识图像中的个体。这样的图像处理技术可以基于几何体。例如,处理器3803可以将图像中心的个体识别为第一个体。例如,处理器3803可以在图像中
识别用户的下巴,然后识别与该用户相对的另一个体。
488.在一些实施例中,处理器3803可以放大第一音频信号。例如,处理器3803可以通过改变音调或应用噪声消除技术(例如,算法或软件模块)来放大第一音频信号。在一些实施例中,处理器3803可以使得放大的第一音频信号传输(例如,使用图5a
‑
5c中的无线收发器530或530a)到被配置为向用户100的耳朵提供声音的听力接口设备。通过提供经放大的第一音频信号的声音,用户100可以能够在更少的其他语音或声音的干扰下聚焦于第一个体。例如,听力接口设备可以包括与耳机相关联的扬声器。例如,听力接口设备可以包括骨传导麦克风。
489.在一些实施例中,只要第一个体保持讲话,处理器3803可以发送放大的第一音频信号。即使麦克风3802捕获到其他语音或声音(无论是否被辨识),处理器3803可以发送放大的第一音频,以便让用户100连续地收听第一个体。在一些实施例中,当第一个体停顿达预定长度时,处理器3803可将其确定为第一个体的讲话结束,并尝试检测其他个体的讲话。在一些实施例中,处理器3803可以将其他个体的音频信号放大到与第一音频信号不同的程度。
490.回到图39a,在步骤3908,处理器3803可以识别第一音频信号。第一音频信号可以代表来自接收到的音频信号中的第一个体的语音。然而,第一音频信号也可以与另一个或未知的说话者相关联。在一些实施例中,可以对第一音频信号进行预处理以与麦克风3802捕获的背景噪声分离。
491.在步骤3910,处理器3803可以转录与讲话相对应的文本并将其存储在存储器3804中,如果个体已经与讲话相关联,该文本可以与第一个体的语音相关联。在一些实施例中,语音可以包括讲话(例如,谈话或口头指令)。声音还可以包括非讲话声音(例如,笑、哭或噪声)。处理器3803可以实现文本到语音技术(例如,文本到语音算法或软件模块),以从语音中辨识讲话并将与该语音相关联的讲话转录到文本中。
492.在步骤3912,处理器3803可以确定说话者是否是第一个体,以及第一个体是否是被辨识的个体。在一些实施例中,处理器3803可以通过分析相关联的第一音频信号来辨识第一个体。例如,第一个体的语音可能已经被先前辨识(例如,在不同的谈话中或在同一谈话的较早部分中),并且第一个体的被辨识的语音的特征(例如,声纹)可以被存储在存储器3804中(例如,在数据库中)。当处理器3804分析第一音频信号时,它可以确定第一音频信号的特征(例如,通过提取声纹)并搜索存储器3804(例如,在数据库中)以寻求匹配。如果发现这样的匹配,则处理器3803可以确定说话者和第一个体之间的匹配,并且第一个体是被辨识的个体。
493.在一些实施例中,处理器3803可以基于从步骤3803中识别的至少一个图像中提取的成像面部特征来辨识第一个体。例如,第一个体的图像可能已经被先前辨识(例如,使用面部辨识算法),并且第一个体的面部特征可以存储在存储器3804中(例如,在数据库中)。当处理器3804分析所识别的图像时,它可以确定第一个体的面部特征并搜索存储器3804(例如,在数据库中)以寻求匹配。如果找到这样的匹配,则处理器3803可以确定第一个体是被辨识的个体。
494.在一些实施例中,处理器3803可以基于第一音频信号和识别的图像两者来辨识第一个体。应当注意,处理器3803还可以使用其它方法、过程、算法或手段来辨识第一个体,而
不限于本文所描述的示例。
495.返回参考图39a,在步骤3914,如果第一个体是被辨识的个体,则处理器3803可以将第一被辨识的个体的标识符与对应于与第一个体的语音相关联的讲话的存储文本相关联。在一些实施例中,例如,如果文本存储在存储器3804中的数据库(例如,关系数据库)中,则处理器3803可以添加或更改关系数据库中的记录,以将标识符存储为文本的键,其中文本存储为值。在一些实施例中,如果第一个体不是被辨识的个体,则处理器3803可提示用户100识别与第一个体有关的信息。例如,处理器3803可提示用户100说出第一个体的标识符(例如,姓名、标签或标牌)。例如,处理器3803可在用户界面(例如,在图5c中的显示器260上)中提示用户100输入字段,以供用户100输入第一个体的标识符。
496.图39b是示出用于推导根据实施例的助听器系统的指令的过程3900b的流程图。过程3900b可以遵循过程3900a的步骤3910。处理器3803可执行过程3900b以辨识个体是否正对着用户100说话。
497.在步骤3916,处理器3803可以确定与第一个体的语音相关联的讲话是否指向用户100。在一些实施例中,处理器3803可基于检测到的用户100的注视方向或检测到的第一个体的注视方向中的至少一个来确定与第一个体的语音相关联的讲话是否朝向用户100。例如,处理器3803可以基于对在图像中的至少一个中的用户100的下巴的检测来确定用户100的注视方向。又例如,处理器3803可以基于对在图像中的至少一个中的第一个体的一只或多只眼睛的检测并且基于对一只或多只眼睛的至少一个特征的检测来确定第一个体的注视方向。又例如,处理器3803可基于从图像中的至少一个中检测到的第一个体的手势、步态或身体运动特征来确定第一个体的注视方向。又例如,处理器3803可以基于包括在第一个体的讲话中的用户名来确定第一个体的注视方向。
498.在步骤3918,如果第一个体的讲话指向用户100,处理器3803可以在存储器3804中存储第一个体的讲话指向用户100的指示。例如,处理器3803可以将指示存储在步骤3914中描述的关系数据库中。
499.图40a是示出根据实施例的用于推导助听器系统的指令的过程4000a的流程图。在一些实施例中,过程4000a可以遵循过程3900a或3900b的任何步骤。处理器3803可以实施过程4000a,以辨识用户100周围环境中的多个个体,并且如果系统300捕获了个体的语音或图像,则转录他们的讲话。
500.在步骤4002,处理器3803可以识别在至少一个图像中表示的第二个体。步骤4002可以类似于步骤3906的方式来实施。例如,处理器3803可使用图像处理算法基于个体的特征或身体形状、运动或面部表情中的至少一个的特性来识别图像中的个体。如果被辨识的个体具有不同的特征或特性,则处理器3803可确定在图像中识别第二个体。
501.在步骤4004,处理器3803可以从接收到的音频信号中识别代表第二个体的语音的第二音频信号。步骤4004可以类似于步骤3908的方式来实施。例如,处理器3803可以从音频信号中提取特征(例如,声纹)。如果提取的特征不相同,则处理器3803可以确定在接收的音频信号中识别第二信号。
502.在步骤4006,处理器3803可以在存储器3804中转录和存储对应于与第二个体的语音相关联的讲话的文本。步骤4006可以类似于步骤3910的方式来实施。
503.图40b是示出根据实施例的用于推导助听器系统的指令的过程4000b的流程图。在
一些实施例中,过程4000b可遵循过程4000a的步骤4006。处理器3803可以实施过程4000b以辨识第二个体是否是被辨识的个体。处理器3803可实施过程4000b以进一步辨识第二个体是否正对着用户100讲话、第二个体是否正对着第一个体讲话或第一个体是否正对着第二个体讲话。
504.在步骤4008,处理器3803可以确定第二个体是否是被辨识的个体。步骤4008可以类似于步骤3912的方式来实施。
505.在步骤4010,如果第二个体是被辨识的个体,则处理器3803可将第二被辨识的个体的标识符与对应于与第二个体的语音相关联的讲话的存储文本相关联。步骤4010可以类似于步骤3914的方式来实施。
506.在步骤4012,处理器3803可以确定与第二个体的语音相关联的讲话是否指向用户100。步骤4012可以类似于步骤3916的方式实施。
507.在步骤4014,如果第二个体的讲话指向用户100,处理器3803可以在存储器3804中存储第二个体的讲话指向用户100的指示。步骤4014可以以类似于步骤3918的方式实施。
508.在步骤4016,处理器3803可确定与第二个体的语音相关的讲话是否指向第一个体。步骤4016可以以类似于步骤3916或4012的方式实施。在一些实施例中,处理器3803可以基于基于对图像中的至少一个的分析而检测到的第二个体的外观方向来确定与第二个体的语音相关联的讲话是否指向第一个体。在一些实施例中,处理器3803可以基于对第二个体的讲话中的与第一个体相关联的姓名的检测来确定与第二个体的语音相关联的讲话是否指向第一个体。
509.在步骤4018,如果第二个体的讲话指向第一个体,处理器3803可以在存储器3804中存储第二个体的讲话指向第一个体的指示。步骤4018可以以类似于步骤3918或4014的方式实施。
510.在步骤4020,处理器3803可确定与第一个体的语音相关联的讲话是否指向第二个体。步骤4016可以以类似于步骤3916、4012或4016的方式实施。
511.在步骤4022,如果第一个体的讲话指向第二个体,处理器3803可以在存储器3804中存储第一个体的讲话指向第二个体指示。步骤4022可以以类似于步骤3918、4014或4018的方式实施。
512.在一些实施例中,处理39a
‑
39b或40a
‑
40b可包括附加步骤。例如,处理器3803可以在39a
‑
39b或40a
‑
40b的任何步骤之后执行这些附加步骤。
513.在一些实施例中,处理器3803可使存储的文本(例如,在步骤3910或4006)显示在显示器上。在一些实施例中,显示器(图38a中未示出)可以包括在包括可穿戴照相机3801和麦克风3802的公共外壳中。在一些实施例中,显示器可以与配对的移动设备相关联,该设备与系统300配对。例如,移动设备可以是图1a
‑
1d,2或5c中的计算设备120。例如,显示器可以是图5c中的显示260。
514.在一些实施例中,处理器3803可以基于与第一个体的语音相关联的讲话的分析生成任务项。在一些实施例中,处理器3803可以实施任务上下文匹配技术(例如,算法或软件模块),以确定上下文(例如,被辨识的个体的讲话的存储文本)是否适合任何任务(例如,未定日期任务或日期已定的任务)。例如,处理器3803可以实施任务上下文匹配技术,以辨识被辨识的个体和用户100之间的讲话的上下文是会议。基于该上下文,处理器3803可以进一
步确定上下文适合接收任务。基于存储的文本和讲话方向(例如,如在过程400b中辨识的),处理器3803可以确定任务的内容。在一些实施例中,处理器3803可以实施建议技术(例如,算法或软件模块),以向用户100建议该任务。在一些实施例中,建议技术可以包括自然语言处理技术。例如,处理器3803可导致建议执行任务或设置任务的日期。在一些实施例中,处理器3803可以通过讲话中的特定单词来识别任务,例如“请”、“准备”、“给我发电子邮件”、“发送”等。在一些实施例中,处理器3803可以基于讲话中的识别时间或日期,诸如,例如“到星期三中午”、“下星期”等,将到期日附加到任务。
515.在一些实施例中,处理器3803可以基于讲话、图像或转录文本中的至少一个来推断或识别指令。例如,处理器3803可以使用自然语言处理技术来分析第一个体的讲话的上下文,以确定是否包括指令。又例如,处理器3803可分析所捕获的图像并分析手势、步态、面部表情、身体运动以确定是否包括指令,诸如点头、摇头、举手等。例如,处理器3803可分析转录文本以确定是否包括指令,诸如如先前所述生成任务项。在一些实施例中,处理器3803可以使用任何讲话、图像或转录文本的组合来确定是否存在来自第一个体的指令。在一些实施例中,处理器3803可以基于第一个体正在与谁讲话来确定所辨识的指令是指向用户还是指向第二个体。在一些实施例中,处理器3803可以进一步检查上下文信息以进一步确定是否包括指令。例如,当处理器3803辨识出与向用户的日程表或日历添加项目有关的候选指令时,处理器3803可以检查日程表或日历是否存在冲突,以确定该项目是重述的还是新添加的。
516.在一些实施例中,处理器3803可以更新与用户100相关联的数据库以包括生成的任务项。例如,数据库可以是如步骤3912、3914或3918所述的存储器3802中的数据库。例如,处理器3803可以将生成的任务项存储或更新为数据库中的数据记录。
517.在一些实施例中,处理器3803可全天收集任务,并应请求将其提供给用户。
518.基于对象的音频指纹选择性地调节音频信号。
519.人类有区别的和不同的语音。虽然有些人有很好的语音记忆,并且可以很容易地认出他们的第一个小学老师,其他人可能难以仅从其语音辨识他们最亲密的朋友。如今,计算机算法在辨识说话者方面已经超过了大多数人,因为它们能够识别和区分人声。这些机器学习算法辨识说话者的方法是基于使用音频指纹的数学解决方案。术语“音频指纹”,也称为“声学指纹”和“语音签名”,是指从参考音频信号确定地生成的发声对象(例如,个体和也包括无生命对象)的特定声学特征的压缩数字摘要。从记录的音频信号中确定音频指纹的一种常用技术是使用称为频谱图的时频图。例如,所公开的助听器系统可以在频谱图中识别多个点(例如,峰值强度点),这些点与由与用户100交谈的个体创建的不同单词或人声有关。所公开的助听器系统可以访问与存储在本地或基于云的数据库中的不同发声对象相关联的多个参考音频指纹。使用参考音频指纹,所公开的助听器系统可以从记录的音频信号确定音频指纹,并识别负责产生音频信号的发声对象。与本公开一致,助听器系统可检索与所识别的发声对象有关的信息,并基于检索到的信息引起对与所识别的发声对象相关联的至少一个音频信号的选择性调节。例如,当用户100和他的孩子在公园时,所公开的系统可以相对于附近其他孩子的语音放大他的孩子的语音。
520.图41a示出了包含与本公开一致的软件模块的存储器4100的示例性实施例。具体地,如图所示,存储器4100可以包括音频分析模块4102、音频指纹确定模块4104、数据库访
问模块4106、选择性调节模块4108、传输模块4110和数据库4112。模块4102、4104、4106、4108和4110可以包含用于由至少一个处理设备(例如,处理器210,包括在建议的助听器系统中)执行的软件指令。音频分析模块4102、音频指纹确定模块4104、数据库访问模块4106、选择调节模块4108、传输模块4110和数据库4112可以协作来执行多个操作。
521.例如,助听器系统可用于基于发声对象的确定的音频指纹选择性地调节音频信号。例如,音频分析模块4102可以接收代表从用户100的环境中的对象发出的声音的音频信号,并分析接收到的音频信号以获得与一个发声对象相关联的隔离音频流。音频指纹确定模块4104可以确定从隔离音频流发声对象的音频指纹。在一个实施方式中,音频指纹确定模块4104可以使用深度学习算法或神经嵌入模型来确定发声对象的音频指纹。数据库访问模块4106可与数据库4112交互,数据库4112可存储关于与用户100相关联的发声对象的信息以及与模块4102
‑
4110的功能相关联的任何其它信息。例如,数据库访问模块4106可以使用确定的音频指纹从数据库4112检索与检测到的发声对象有关的信息。检索到的信息可以包括用户100和检测到的发声对象之间的关系级别指示符,或者与所识别的发声对象相关联的特定音频调节规则。选择性调节模块4108可引起对与所识别的发声对象相关联的至少一个音频信号的选择性调节。例如,选择性调节模块4108可以放大来自用户的智能电话的声音并且避免放大来自其他电话的声音。传输模块4110可以使得至少一个调节后的音频信号传输到被配置为向用户100的耳朵提供声音的听力接口设备(例如,听力接口设备1710)。
522.在另一示例中,助听器系统可以基于用户100的环境中对象的确定的音频指纹来衰减背景噪声。例如,音频分析模块4102可以从用户100的环境接收代表声音的音频信号,并分析接收到的音频信号以隔离与用户100的环境中相应的多个发声对象相关联的多个音频流。用户100的环境中的每个发声对象可以与唯一的音频指纹相关联。音频指纹确定模块4104可以确定与多个隔离音频流相关联的多个音频指纹。数据库访问模块4106可以使用所确定的音频指纹来获得与多个发声对象中的每一个相关联的类型的至少一个指示符。至少一个指示符可以指示用户100对与多个发声对象中的每一个相关联的类型的感兴趣程度。选择性调节模块4108可基于所确定的与多个发声对象中的每一个相关联的类型的至少一个指示符,引起对多个隔离音频流的选择性调节。例如,选择性调节模块4108可以相对于被确定为不与背景噪声相关联的第二音频流选择性地衰减被确定为与背景噪声相关联的第一音频流。传输模块4110可以使得调节后的音频信号(和非调节后的音频信号)传输到被配置为向用户100的耳朵提供声音的听力接口设备。下面参考图44a
‑
44c提供关于该示例操作的附加细节。
523.与本公开的实施例一致,存储器4100还可以包括对象识别模块(未示出)。对象识别模块可以基于由音频指纹确定模块4104确定的音频指纹来识别用户100的环境中的至少一个发声对象。此外,在一个实施例中,对象识别模块可以使用图像分析来识别用户100的环境中的至少一个发声对象。例如,对象识别模块可以接收描绘一个或多个发声对象的多个图像。多个图像可由位于包括可穿戴麦克风(例如,装置110)的相同外壳中的可穿戴照相机捕获。根据本实施例,对象识别模块可以基于对多个图像的分析来确定发声对象的视觉特性。此后,对象识别模块可以使用所确定的视觉特性和所确定的音频指纹来识别发声对象。例如,发声对象的视觉特性可以包括与用户100谈话的个体的面部特征。数据库访问模块4106可以从数据库4112检索与发声对象的身份相关联的预定设置。此后,选择性调节模
块4108可以基于发声对象的身份来调节至少一个音频信号。例如,由特定发声对象产生的声音可以被静音(例如,与ac相关联的调节后音频信号的强度可以是0%),并且由其他特定发声对象生成的声音可以被放大(例如,与家庭成员相关联的调节后音频信号的强度可以是110%)。
524.在对象识别模块识别发声对象(例如,使用音频分析、使用图像分析或两者的组合)之后,数据库访问模块4106可以检索与所识别的发声对象相关的预定设置。在一个实施例中,预定的设置可以与对由发声对象生成的音频信号的调整相关联。例如,根据一个预定的设置,来自特定发声对象的音频信号可以在遇到时被静音。在另一实施例中,预定设置可以由用户100定义或特定于用户100。例如,爱丽丝可能想放大婴儿生成的声音,鲍勃可能想使婴儿生成的声音静音。在另一实施例中,预定的设置可以是上下文相关的。换句话说,单个发声对象可以与对应于不同情况的不同设置相关联。因此,助听器系统可以识别用户100所处的情况,并相应地应用与发声对象相关联的设置。如另一个示例,当爱丽丝在家时,她可能想放大婴儿生成的声音;但是当爱丽丝在工作的时候,她可能想使婴儿生成的声音静音。助听器系统可以确定爱丽丝是在家还是在工作(例如,通过捕获的爱丽丝周围的图像的分析,通过访问与日历或日程表相关联的信息,和/或经由访问gps或其他位置信息),并相应地调整与婴儿相关联的音频信号。
525.与本公开的其他实施例一致,图41a所示的软件模块可以存储在单独的存储设备中。在一个示例实施例中,选择性调节模块4108可以存储在位于听力接口设备(例如,听力接口设备1710)中的存储器设备中。本公开中的听力接口设备可以包括电声换能器,其被配置为向用户100的耳朵提供来自至少一个音频信号的声音。电声换能器可包括扬声器或骨传导麦克风。在该示例实施例中,传输模块4110可以将隔离的音频信号发送到听力接口设备,并且音频信号的调节可以由听力接口设备执行。在另一示例实施例中,听力接口设备可包括被配置为接收至少一个音频信号的接收器,其中至少一个音频信号由可穿戴麦克风获取并且由至少一个处理器选择性地调节(例如,位于装置110中的处理器210),处理器被配置为使用多个参考音频指纹来识别至少一个发声对象的音频指纹,从数据库检索关于至少一个发声对象的信息,并基于检索到的信息引起调节。
526.图41b是示出用于使用与本公开一致的助听器系统4160的示例性环境4150的示意图。助听器系统4160可包括装置110并使用可穿戴麦克风1720和听力接口设备1710识别环境4150内的一个或多个个体,以向用户100的耳朵提供选择性地调节的音频信号。在所示的场景中,装置110可以使用从记录的音频信号确定的音频指纹来识别第一个体4152和第二个体4154。例如,可穿戴麦克风1720可以记录由环境4150中的发声对象生成的音频信号。在一些实施例中,音频信号可以表示各种个体的语音。例如,如图41b所示,第一音频信号4156可以表示第一个体4152的语音,第二音频信号4158可以表示第二个体4154的语音。助听器系统4160的至少一个处理设备可以分析第一音频信号4156和第二音频信号4158以分离它们并确定与语音相关联的音频指纹。例如,至少一个处理设备可以使用一个或多个语音或语音活动检测(vad)算法和/或语音分离技术来隔离与每个语音相关联的音频信号。在一些实施例中,至少一个处理设备可以对与检测到的语音活动相关联的音频信号执行进一步分析,以确定与每个语音相关联的音频指纹。例如,至少一个处理设备可以使用一个或多个语音辨识算法(例如,隐马尔可夫模型、动态时间扭曲、神经网络或其他技术)来确定与每个语
音相关联的音频指纹。在一些实施例中,如图43b所示,至少一个处理设备可以使用捕获的图像和一个或多个图像辨识算法来识别对象,并且此后可以使用对象的身份来确定音频指纹。
527.图42a
‑
42f是在图41b所示的场景期间记录的并且由使用图41a所示的软件模块的至少一个处理设备处理的音频信号的示意图。根据本公开,音频分析模块4102可以接收由可穿戴麦克风1720获取的音频信号,该音频信号反映由第一个体4152和第二个体4154生成的声音。图42a示出了由可穿戴麦克风1720获取的音频流4200。音频分析模块4102还可分析音频流4200以识别与第一个体4152相关联的第一音频信号4156和与第二个体4154相关联的第二音频信号4158。图42b描绘了浅灰色的第一音频信号4156和深灰色的第二音频信号4158。音频分析模块4102可进一步隔离与第一个体4152相关联的第一音频信号4156和与第二个体4154相关联的第二音频信号4158。图42c描绘了两个隔离的音频信号。在至少一个处理设备确定音频信号4156和4158的音频指纹、识别个体4152和4154并从数据库4112检索与个体4152和4154相关的信息之后,选择性调节模块4108可引起对第一音频信号4156和第二音频信号4158的选择性调节。在图42d所示的示例中,检索到的信息可以指示第二个体4154对于用户100比第一个体4152更重要。因此,选择性调节模块4108可以衰减第一音频信号4156并放大第二音频信号4158。第一调节音频信号4202从第一音频信号4156生成,第二调节音频信号4204从第二音频信号4158生成。传输模块4110可以从选择调节模块4108接收第一调节音频信号4202和第二调节音频信号4204,并且可以将它们组合到调节音频流4206,如图42e所示。此后,传输模块4110可使调节后的音频流4206传输到被配置为向用户100的耳朵提供声音的听力接口设备1710。图42f描绘由听力接口设备1710接收的调节后音频流4206。与本公开一致,至少一个处理设备可以使得在可穿戴麦克风获取音频流4200之后不到100msec内将调节后的音频流4206传输到听力接口设备1710。例如,在可穿戴麦克风获取音频流4200之后,可在小于50ms、小于30msec、小于20msec或小于10msec的时间内将调节后音频流4206发送到听力接口设备。
528.图43a是示出与所公开的实施例一致的用于选择性地调节与所辨识的对象相关联的音频信号的示例性过程4300的流程图。过程4300可以由与装置110相关联的一个或多个处理器(诸如处理器210)执行。在一些实施例中,过程4300的一些或全部可由装置110外部的设备来执行,例如听力接口设备1710或计算设备120。换言之,执行过程4300的处理设备可以包括位于包括可穿戴照相机和可穿戴麦克风的单个外壳中的至少一个处理器,或者位于单独外壳中的多个处理器。
529.在步骤4302中,处理设备可以接收由可穿戴麦克风获取的音频信号。音频信号可以代表从用户100的环境中的对象发出的声音。与本公开一致,接收到的音频信号可以包括用户100的环境中响应于在10到30000赫兹(例如,20到20000赫兹之间)范围内的声音而生成的任何形式的数据。例如,音频信号可以表示由多个发声对象生成的声音。与本公开一致,可穿戴麦克风可包括一个或多个定向麦克风、麦克风阵列、多端口麦克风或各种其他类型的麦克风。处理设备可以被配置为确定用户100的环境中声音的方向性。因此,音频信号可以指示与生成由音频信号表示的声音的发声对象相关联的用户100的环境区域。
530.在步骤4304中,处理设备可以分析接收到的音频信号以获得与用户100的环境中的发声对象相关联的隔离音频流。在一个实施例中,处理设备可以通过使用音频样本卷积
来分析接收到的音频信号。具体地说,本公开中描述的说话者分离和其他音频分析算法可以使用音频样本卷积。例如,通过在计算当前样本的值时卷积过去的样本,并且避免等待将来的样本,可以显著地减少提供分析结果的延迟。例如,为每个发声对象生成隔离音频流(或任何其他处理音频流)的延迟可以小于50msec(例如,小于10msec、小于5msec或小于1msec)。在图41b所示的场景中,处理设备可以为用户100前面的两个说话者中的每一个生成隔离的音频流。每个隔离的音频流可以包括与诸如背景噪声或其他语音的任何其他声音隔离的说话者的语音。
531.在步骤4306中,处理设备可以从隔离的音频流确定音频指纹。在一个实施例中,所确定的音频指纹可以是与个体相关联的声纹。在另一实施例中,所确定的音频指纹可与非人类的发声对象(诸如,ac、汽车、动物等)相关联。音频指纹的确定可通过从所隔离的音频流中提取频谱特征(也称为频谱属性、频谱包络或频谱图)来执行。在一个实施例中,隔离的音频流可以输入到基于计算机的模型中,诸如预先训练的神经网络,该神经网络基于提取的特征输出音频指纹。所确定的音频指纹可用于识别发声对象以引起对其相关音频信号的选择性调节。与本公开一致,处理设备可以访问至少一个标识数据库,该标识数据库存储用于不同发声对象的参考音频指纹集。参考音频指纹集可以预先由处理设备确定,或者由不同的处理设备确定。参考音频指纹集可用于确定发声对象的音频指纹。例如,处理设备可以从参考音频指纹集合中选择最相似的音频指纹作为发声对象的确定音频指纹。在另一实施例中,参考音频指纹集可用于识别发声对象。例如,处理设备可以触发所确定的音频指纹和参考音频指纹集之间的比较,以确定发声对象的身份。
532.在某些情况下,当确定的音频指纹与参考音频指纹集中的一个匹配时,处理设备可以基于与发声对象的身份相关联的预定设置引起至少一个音频信号的调节。在其他情况下,当确定的音频指纹未能匹配参考音频指纹集合中的任何一个时,处理设备可以确定特定参考音频指纹和确定的音频指纹之间的相似度水平的至少一个指示符。基于相似度水平的至少一个指示符与预定阈值的比较,处理设备可以基于与特定参考音频指纹相关联的预定设置引起至少一个音频信号的调节。此外,当所确定的音频指纹未能匹配参考音频指纹集合中的任何一个时,处理设备可以确定特定参考音频指纹和所确定的音频指纹之间的相似度水平的至少一个指示符。基于相似度水平的至少一个指示符与预定阈值的比较,处理设备可以基于所确定的音频指纹更新参考音频指纹集。在一些实施例中,参考音频指纹集可以包括与单个发声对象相关联的多个参考音频指纹。例如,参考音频指纹集可以包括基于特定个体站在用户100旁边的实例确定的特定个体的第一参考音频指纹,以及基于从通信设备投射特定个体语音声音的实例确定的特定个体的第二参考音频指纹。
533.在步骤4308中,处理设备可以使用音频指纹从与发声对象相关的数据库信息中检索。在一个实施例中,检索到的信息可以指示用户100与发声对象之间的预先存在关系。因此,处理设备基于预先存在的关系,引起至少一个音频信号的选择性调节。例如,处理设备可以将放大层次结构应用于与具有不同级别的预先存在关系的多个发声对象相关联的音频信号。与本公开一致,检索到的信息可包括至少一个预定的应用于与发声对象相关联的音频流的音频调节参数值。至少一个预定的音频调节参数可以包括音高、响度、节奏、平滑度、语调等。在一个实施例中,包含在检索信息中的至少一个预定音频调节参数值可以依赖于音频层次结构和发声对象在音频层次结构中的位置(例如,火灾警报的排名可高于办公
室交谈)。在第一示例中,检索到的至少一个预定音频调节参数的值可以以高于在音频层次结构上低于特定发声对象的另一发声对象的电平引起与特定发声对象相关联的音频信号的放大。在第二示例中,检索到的至少一个预定音频调节参数的值可以以低于在音频层次结构上高于特定发声对象的另一发声对象的电平引起与特定发声对象相关联的音频信号的衰减。在第三示例中,检索到的至少一个预定音频调节参数的值可以引起与和特定发声对象相关联的音频信号相关联的音调改变。在本例中,层次结构中较高的对象可能会接收音调调整,而排名较低的对象可能不会收到音调更改。
534.在步骤4310中,处理设备可以引起可穿戴麦克风从与至少一个发声对象相关联的区域接收到的至少一个音频信号的选择性调节。与本公开一致,处理设备可以基于所确定的音频指纹与参考音频指纹集的比较来确定与发声对象相关联的类型。与发声对象相关的类型可以包括机械机器、扬声器、人类、动物、无生命对象、与天气有关的对象等。在确定与发声对象相关联的类型之后,处理设备可基于所确定的类型,引起至少一个音频信号的选择性调节。此外,处理设备可以分析接收到的音频信号,以隔离确定与用户100环境中的多个发声对象相关联的音频分组。例如,多个发声对象可以包括第一个体和第二个体。因此,处理设备可基于与第一个体相关联的检索信息,引起与第一个体相关联的音频信号的第一选择性调节,并基于与第二个体相关联的检索信息引起与第二个体相关联的不同于音频信号的第一选择性调节的第二选择性调节。例如,将与第一个体相关联的音频信号和音高增强放大到与第二个体相关联的音频信号。图42d示出处理设备如何引起与第一个体相关联的音频信号的第一选择性调节,以及与第二个体相关联的音频信号的第二选择性调节。
535.在步骤4312中,处理设备可以使得至少一个调节后的音频信号传输到被配置为向用户100的耳朵提供声音的听力接口设备。与本公开一致,处理设备可使发射器(例如,无线收发器530a)经由无线网络(例如,蜂窝、wi
‑
fi,等)、或经由近场电容耦合、其它短距离无线技术、或经由有线连接将调节后的音频信号发送到听力接口设备。此外,处理设备可使得未处理的音频信号与调节后的音频信号一起传输到听力接口设备。
536.图43b是示出与所公开的实施例一致的用于选择性地调节与所辨识的对象相关联的音频信号的另一示例性过程4350的流程图。与过程4300类似,过程4350可以由与装置110相关联的一个或多个处理器或者由装置110外部的设备来执行。换言之,执行过程4350的处理设备可以包括位于包括可穿戴照相机和可穿戴麦克风的单个外壳中的至少一个处理器,或者位于单独外壳中的多个处理器。
537.在步骤4352中,处理设备可以从可穿戴照相机捕获的用户100的环境接收多个图像。例如,所建议的系统可以包括处理器(例如,处理器210),处理器被配置为接收由图像传感器(例如,图像传感器220)捕获的用户100的环境的多个图像。与本公开一致,多个图像可以包括由可穿戴照相机捕获的视频流的帧。
538.在步骤4354中,处理设备可以处理多个图像,以在多个图像中至少一个中检测发声对象,并且在步骤4356中,处理设备可以使用多个图像中的至少一个来识别发声对象。如本文所使用的,“检测发声对象”一词可广泛地指确定发声对象的存在。例如,系统可以确定多个不同的发声对象的存在。通过检测多个发声对象,系统可以获取与多个发声对象相关的不同细节(例如,用户100的环境中存在多少个发声对象),但不一定获得对象类型的知识。相反,“识别发声对象”一词可指确定与特定发声对象相关联的唯一标识符,该特定发声
对象允许系统唯一地访问数据库中与发声对象相关联的记录(例如,数据库4112)。在一些实施例中,至少可以基于从可穿戴照相机捕获的图像中获得的发声对象的视觉特性进行部分识别。例如,发声对象可以是与用户100讲话的个体,并且发声对象的视觉特性可以包括个体的面部特征。唯一标识符可以包括数字、字母和符号的任何组合。与本公开一致,本公开中还可参考术语“识别发声对象”与术语术确定发声对象的类型”互换使用。
539.在步骤4358中,处理设备可以使用发声对象的确定身份从与发声对象相关的数据库信息中检索。在一个实施例中,检索到的信息可以包括与辨识的发声对象相关联的参考音频指纹或声纹。在另一实施例中,检索到的信息可以指示用户100与辨识的发声对象之间的预先存在关系。因此,处理设备可基于预先存在的关系,引起至少一个音频信号的选择性调节。上文参考步骤4308描述了如何使用检索到的信息来引起至少一个音频信号的选择性调节的附加细节。
540.在步骤4360中,处理设备可以接收由可穿戴麦克风获取的至少一个音频信号,其中至少一个音频信号代表从发声对象发出的声音。与本公开的一些实施例一致,可以基于可穿戴照相机接收的图像和可穿戴麦克风获取的至少一个音频信号来确定一个或多个发声对象的身份。例如,当对应于表示在捕获的图像中的发声对象与数据库中的一个或多个对象相对应的确定程度的置信得分低于某一阈值时,可将至少一个音频信号与接收到的图像一起使用,以识别一个或多个发声对象。
541.在步骤4361中,处理设备可以使用检索到的信息(例如,在步骤4358中检索到的信息)来处理至少一个音频信号(例如,在步骤4360中接收到的至少一个音频信号)。在一个实施例中,当发声对象是个体时,检索到的信息可以包括关于个体的至少一个细节(例如,性别、年龄、种族等)。处理设备可以使用关于个体的至少一个细节来将与个体相关联的声音与从其他发声对象发射的声音分离。在另一个实施例中,检索到的信息可以包括与被辨识的发声对象相关联的参考音频指纹,并且处理设备可以使用参考音频指纹来识别与被辨识的发声对象相关联的声音,并将其与从其他发声对象发出的声音分离。与本公开一致,当检索到的信息包括被辨识的个体的参考音频指纹时,音频分离可能更有效,但是对于系统的一些实施方式,关于个体的至少一个细节可能就足够了。
542.在步骤4362中,处理设备可引起可穿戴麦克风从与在步骤4361中分离的至少一个发声对象相关联的区域接收的音频信号的选择性调节。因此,在该示例中,可以仅调节从特定对象(例如,与用户讲话的人)发出的音频。例如,音频可以被放大。
543.在步骤4364中,处理设备可使得至少一个调节后的音频信号传输到被配置成向用户100的耳朵提供声音的听力接口设备。以上参考步骤4310和4312描述的细节也与步骤4362和4364相关。
544.背景噪声的选择性调整
545.当放大不相关背景噪声时,助听器系统的用户通常会感到烦扰。一些现有助听器系统过滤低频声音,以减少背景噪声。该解决方案消除了一些背景噪声,但它提供了部分解决方案,因为它可以消除用户100环境中的讲话或其他声音的重要部分。其他现有助听器系统使用定向话筒来减少用户旁边和后面的声音。该方案在特定场景下提供了更好的信噪比,但也提供了部分解决方案,因为一些背景噪声是重要的,不应消除。公开的助听器系统可包括可穿戴设备(例如,装置110),该设备可引起由用户的环境中的发声对象生成的音频
信号的选择性调节,以及向用户100的耳朵提供选择性调整后的声音的听力接口设备(例如,听力接口设备1710)。本公开的助听器系统可以使用图像数据来确定背景噪声是否重要,并相应地引起选择性调节。例如,助听器系统可以放大确定为重要的背景噪声,并衰减确定为不重要的背景噪声。
546.图44a示出了用户100在其办公桌上工作的场景。用户100穿戴助听器系统4400,该助听器系统4400可包括可穿戴照相机4402、可穿戴麦克风4404和听力接口设备4406。在所示场景中,用户100的环境的第一部分与可穿戴照相机4402的视野4408相关联,并且可以包括至少一个发声对象,并且用户100的环境的第二部分还可以包括可穿戴照相机4402的视野4408外的至少一个发声对象。例如,用户100的环境的第一部分可以包括第一发声对象4410a(例如,带扬声器的计算机),用户100的环境的第二部分可以包括第二发声对象4412a(例如,女性)和第三发声对象4414a(例如,电视)。
547.图44b示出了可穿戴麦克风4404在时间段t期间获取的音频信号4416。如图所示,获取的音频信号4416包括来自第一发声对象4410a的第一音频信号4410b、来自第二发声对象4412a的第二音频信号4412b和来自第三发声对象4414a的第三音频信号4414b。在上述场景中,助听器系统4400可以确定来自第二发声对象4412a的声音比来自第三发声对象4414a的声音更重要,并且衰减由第三发声对象4414a产生的第三音频信号4414b。图44c示出了发送到听力接口设备4406的调节后的音频信号4418。调节后的音频信号4418包括第一音频信号4410c、第二音频信号4412c和第三音频信号4414c。在所示的示例中,仅对第三音频信号4414c进行调节;具体地,第三音频信号4414c被衰减,因为助听器系统4400确定来自第二发声对象4412a的声音比来自第三发声对象4414a的声音更重要。
548.在一个实施例中,助听器系统4400可以使用可穿戴照相机4402在时间段t期间捕获的图像数据来确定音频信号的重要性。例如,助听器系统4400可根据图像数据确定用户100正坐在其办公室中,并使用该信息基于女性的语音将其识别为他的主管。助听器系统4400可基于女性的身份来确定来自该女性的声音的重要性。在另一实施例中,可穿戴照相机4402可在时间段t之前捕获图像数据。例如,当用户100走向他的办公桌或坐在他的办公桌旁转过身时,可穿戴照相机4402捕获到参与活动的女性的至少一个图像。助听器系统4400可基于女性参与的活动来确定来自该女性的声音的重要性。
549.图45是示出根据示例性实施例的配置为与装置110和计算设备120通信的听力接口设备4406的组件的框图。如图45所示,听力接口设备4406可以包括接收器4500、电声换能器4502、处理器4504、存储器4506和移动电源4508。接收器4500可用于从装置110和/或从计算设备120接收数据(例如,音频信号、关于发声对象的数据等)。电声换能器4502可用于基于所接收的数据产生声音。所产生的声音可以提供给用户100的耳朵。在一个实施例中,电声换能器4502可包括扬声器。在另一实施例中,电声换能器4502可包括骨传导麦克风。处理器4504、存储器4506和移动电源4508可以类似于上述处理器210、存储器550和移动电源520的方式操作。如本领域技术人员将认识到的,受益于本公开,可以对听力接口设备4406进行许多改变和/或修改。并非听力接口设备4406的图示配置中包括的所有组件对于助听器系统4400的操作都是必需的。任何组件可以位于任何适当的装置中,并且组件可以被重新排列成各种配置,同时提供所公开的实施例的功能。例如,在一种配置中,听力接口设备4406可以包括用于接收到的音频信号的选择性调节的处理器。在另一配置中,听力接口设备
4406可以接收由位于单独设备(例如,装置110或计算设备120)中的处理器选择性地调节的音频信号。
550.在一个实施例中,接收器4500可接收至少一个音频信号。至少一个音频信号可由可穿戴麦克风(例如,可穿戴麦克风4404)获取。至少一个音频信号可能已经被至少一个处理器(例如,处理器210或处理器540)选择性地调节。至少一个处理器可以接收由可穿戴照相机(例如,可穿戴照相机4402)捕获的多个图像,并且基于对多个图像的分析来确定至少一个声音是由可穿戴照相机的视野之外的远程发声对象产生的。此后,至少一个处理器可以基于从至少一个存储器(例如,存储器550a、存储器550b或存储器4506)检索到的关于远程发声对象的信息来调节音频信号。与本公开的实施例一致,听力接口设备4406的处理器4504可以具有以下能力中的至少一些:选择性调节音频信号、处理图像数据以识别对象以及处理音频数据以辨识声音。因此,本公开中描述的关于位于装置110中的处理设备的功能也可以由处理器4504执行。例如,接收器4500可以接收由可穿戴麦克风4404获取的非调节音后的频信号,并且此后,处理器4504可以确定至少一个音频信号的重要性,并且引起基于从至少一个存储器检索的信息的至少一个音频信号的选择性调节。
551.图46a是基于所确定的重要性等级引起背景噪声的选择性调整的说明性过程4600。分配给与背景噪声相关联的音频信号的重要性等级可以表示用户100可能对听到所述背景噪声感兴趣的可能性。与本公开一致,可基于背景噪声的内容、产生背景噪声的发声对象的身份、背景噪声的上下文等来确定分配给与背景噪声相关联的音频信号的重要性等级。例如,可以将背景噪声的重要性等级划分为多个等级,例如“烦扰”、“相关”和“严重”。或者,重要性等级可以表示为1到10之间的数值,其中1根本不重要,10非常重要。
552.在步骤4602,助听器系统(例如助听器系统4400)可以接收包括背景噪声的音频信号。背景噪声可以包括来自用户100的环境中但在视野4408之外的一个或多个发声对象的声音,例如,来自第二发声对象4412a的声音和来自第三发声对象4414a的声音。音频信号可以单独接收,例如通过定向麦克风。额外地,或可替代地,可以使用例如特定人类的已知音频指纹、已知模式(例如a/c上的声音)等将音频信号一起接收并且随后分离。
553.在步骤4604,助听器系统可以识别负责背景噪声中的至少一些的一个或多个发声对象。与本公开一致,助听器系统可以使用来自可穿戴照相机4402捕获的一个或多个图像的信息来识别发声对象。例如,助听器系统可根据捕获的图像数据确定用户100在其家中,并使用该信息来确定负责背景噪声中的至少一些的发声对象的身份。
554.在步骤4606,助听器系统可确定与来自发声对象的声音相关联的重要性等级。在一个实施例中,重要性等级的确定可以基于检测到的发声对象的声纹。在另一个实施例中,重要性等级的确定可以基于对可穿戴照相机4402捕获的多个图像的分析。例如,当可穿戴麦克风4404在用户100沿街行走时检测到与汽车喇叭相关联的音频信号时,助听器系统可将这些音频信号的重要性等级排序为7.5。可替代地,当用户100坐在餐厅中时,当可穿戴麦克风4404检测到与汽车喇叭相关联的音频信号时,助听器系统可将这些音频信号的重要性等级排序为2.8。此外,重要性级别的确定可以基于从在接收背景噪声之前由可穿戴照相机4402捕获的至少一个图像的分析中导出的上下文。例如,助听器系统可以基于图像分析确定用户100可以将婴儿放在床上,并且在五分钟之后,可穿戴麦克风4404可以检测到婴儿哭泣。在这种情况下,助听器系统可将与婴儿哭泣相关联的音频信号分类为“严重”。在另一实
施例中,可基于从代表在接收来自发声对象的声音之前获取的声音的音频信号中导出的上下文来确定重要性等级。例如,与用户100相关的人可能已经请求用户100照顾婴儿,并且在五分钟之后,可穿戴麦克风4404可能检测到婴儿哭泣。在这种情况下,助听器系统可将与婴儿哭泣相关联的音频信号分类为“严重”。在另一种情况下,助听器系统可确定用户100在飞机上并且在背景中哭泣的婴儿与用户100无关。在这种情况下,助听器系统可能会将与婴儿哭泣相关的音频信号分类为“烦扰”。
555.在步骤4608,助听器系统可基于检索到的信息来确定重要性等级是否大于阈值。术语“阈值”在此用于表示参考值、水平、点或值的范围,使得当重要性等级高于它时,助听器系统可以遵循第一个动作,并且当重要性等级低于它时,助听器系统遵循第二个动作。阈值的值可以针对每个发声对象预先确定,或者基于基于图像数据确定的上下文动态地选择。
556.如果重要性等级被确定为小于阈值,助听器系统可引起第一选择性调节以减弱与发声对象相关联的音频信号(步骤4610)。在一个实施例中,当助听器系统确定发声对象的重要性等级低于阈值时,第一选择性调节可包括衰减与发声对象相关联的音频信号。例如,来自ac的背景噪声可以被认为是不重要的,因此相对于来自其他发声对象的声音,它们可以被静音。可替代地,第一选择性调节可包括放大与其它发声对象相关联的音频信号。与本公开一致,助听器系统可以基于对来自可穿戴照相机4402的多个图像的分析来确定至少一个声音的重要性等级低于阈值。
557.如果确定重要性等级大于阈值,助听器系统可引起第二选择性调节以增强与发声对象相关的音频信号(步骤4612)。在一个实施例中,当助听器系统确定发声对象的重要性等级大于阈值时,第二选择性调节可包括放大与发声对象相关联的音频信号。例如,来自某些同事的背景噪声可能被认为是重要的,因此它们可以相对于来自其他发声对象的声音被放大。可替代地,第二选择性调节可包括衰减与其它发声对象相关联的音频信号。
558.在一个实施例中,助听器系统可确定背景噪声是由可穿戴照相机视野外的多个发声对象产生的。与本实施例一致,助听器系统可以识别多个发声对象,并基于其相应的重要性等级对多个远程发声对象进行排序。此后,助听器系统可基于与多个远程发声对象相关联的多个声音的相应重要性等级,引起与多个远程发声对象相关联的多个声音的选择性调节。例如,参考图44a,助听器系统可以将来自第三发声对象4414a的声音以低于来自第三发声对象4414的声音的重要性等级进行排序。因此,可以放大来自第二发声对象4412a的音频信号,并且可以衰减来自第三发声对象4414a的音频信号。
559.在与发声对象相关的音频信号的选择性调节后,助听器系统可向用户100提供调节后的音频信号(步骤4614)。可以使用听力接口设备4406的电声换能器4502向用户100提供调节后的音频信号。在一个实施例中,助听器系统可以将在调节后的音频信号中基本消除的背景噪声通知用户100。例如,助听器系统可以向计算设备120发送关于音频信号被衰减的至少一个发声对象的指示。在从用户100接收到关于至少一个发声对象的反馈后,助听器系统可以避免在将来衰减至少一个发声对象的音频信号。
560.图46b是示出与公开实施例一致的用于选择性调整不同类型背景噪声的示例性处理4650的流程图。处理4650可以由与装置110相关联的一个或多个处理器执行,例如处理器210。在一些实施例中,处理4650的部分或全部可以由装置110外部的处理器执行,例如,在
听力接口设备4406中的处理器4504或计算设备120中的处理器540。换句话说,执行过程4650的至少一个处理器可以包括在与可穿戴照相机4402和可穿戴麦克风4404相同的公共外壳中,或者可以包括在单独的外壳中。
561.在步骤4652中,处理设备(例如处理器210)可以从用户100的环境接收由可穿戴照相机4402在一段时间期间内捕获的图像数据。与本公开一致,接收到的图像数据可以包括从近红外、红外、可见、紫外光谱或多光谱中的光信号中检索到的任何形式的数据。图像数据可以包括视频剪辑、一个或多个图像或从处理一个或多个图像得到的信息。例如,图像数据可以包括关于在可穿戴照相机4402捕获的图像中识别的对象(例如,发声对象和非发声对象)的详细信息。
562.在步骤4654中,处理设备可接收代表在该时间段期间内由可穿戴麦克风4404获取的声音的至少一个音频信号。与本公开一致,可穿戴麦克风4404可包括麦克风阵列和/或至少一个定向麦克风,用于捕获用户100的环境中至少一个发声对象的声音。如本文所使用的,“发声对象”一词可指能够在10至30000赫兹(例如,20至20000赫兹)范围内生成声音的任何对象。发声对象的示例可以包括不同的无生命物(例如风扇、扬声器、交通、风、雨等)和有生命的生物(例如,人、动物)。在一个实施例中,至少一个音频信号可以包括来自多个发声对象的多个音频信号,每个音频信号具有不同的音调、不同的节奏、不同的响度或音调、节奏和响度的不同组合。
563.在步骤4656中,处理设备可以确定声音中的至少一个是由在用户的环境中但在可穿戴照相机4402的视野之外的发声对象产生的。当发声对象产生声音和/或当调节后的音频信号被发送到听力接口设备4406时,该发声对象可以在可穿戴照相机4402的视野之外。处理设备可以通过识别可穿戴照相机4402的视野中的对象并确定声音中的至少一个不是由任何所识别的对象产生的,来确定声音中的至少一个是由可穿戴照相机4402的视野之外的发声对象生成的。处理设备还可以使用从数据库检索到的关于可穿戴照相机4402的视野中的对象(例如,声纹、关系等)的信息来确定声音中的至少一个是由可穿戴照相机4402的视野之外的发声对象或不在视野中但之前已经在视野中被辨识的对象生成的。
564.与本公开一致,处理设备可以分析至少一个音频信号,以确定可穿戴照相机4402视野之外的发声对象生成的声音的重要性等级。在一个实施例中,至少一个声音可以与口语单词相关联,并且处理设备可以识别口语单词中的至少一个,并且基于口语单词中的至少一个的身份来确定至少一个声音的重要性等级。例如,口语单词“帮助”、“小心”和用户姓名可能与比其他单词更高的重要性等级相关联。在另一个实施例中,由发声对象生成的至少一个声音可以与频率范围相关联,并且处理设备可以基于检测到的频率范围来确定至少一个声音的重要性等级。例如,烟雾报警器具有特定频率,并且具有该特定频率的音频信号可以与比其他音频信号更高的重要性等级相关联。例如,处理设备可以基于上下文确定警报器的重要性等级,例如,当用户100在街上行走时,特定警报器可能比当用户100在室内时更重要。
565.在步骤4658中,处理设备可以从数据库检索与至少一个声音相关联的信息。数据库可以是能够存储关于一个或多个发声对象的信息的任何设备,并且可以包括硬盘驱动器、固态驱动器、web存储平台、远程服务器等。数据库可位于装置110内(例如,存储器550a内)或装置110外部(例如,存储器550b内或存储器4506内)。在一些实施例中,装置110可以
通过先前的音频分析来编译数据库。例如,处理设备可以在数据库中存储与可穿戴麦克风4404捕获的音频信号中辨识的语音和声音相关联的信息。例如,每当在音频信号中检测到的声音被辨识为符合存储的声纹时,处理设备存储与检测到的发声对象相关联的信息,例如更新的声纹。处理设备可以通过分析音频信号和识别发声对象的声纹来检索信息。检索到的信息可以包括与发声对象的身份相关联的细节。具体地,在一个实施例中,检索到的信息可以指示用户100与发声对象的预先存在的关系,并且至少一个处理器可以进一步编程以基于预先存在的关系来确定至少一个声音的重要性等级。例如,图44a中请求帮助的妇女可以是用户的主管。在另一实施例中,处理设备可以基于对声音中的至少一个的分析来确定声音中的至少一个与公告相关。例如,对声音中的至少一个的分析包括识别与公告相关联的被辨识的单词或短语。此外,处理设备可以基于与用户100相关联的日历数据的自动检查来确定公告与用户100的相关性。公告与用户100的相关性可以影响重要性等级的确定。例如,处理设备可以访问日历数据以确定用户在某一天和某个时间在飞往x目的地的航班641上,并且有选择地放大该航班的通告。
566.在步骤4660中,处理设备可基于检索到的信息,引起可穿戴麦克风4404在时间段期间内获取的音频信号的选择性调节。与本公开一致,调节可包括相对于其它音频信号放大被确定为对应于可穿戴照相机4402视野外的发声对象的音频信号和/或可选地衰减或抑制与可穿戴照相机4402视野内的发声对象相关联的一个或多个音频信号。额外地,或可替代地,选择性调节可包括相对于其他音频信号衰减确定为对应于可穿戴照相机4402视野外的发声对象的音频信号和/或可选地放大与可穿戴照相机4402视野内的发声对象相关联的一个或多个音频信号。额外地,或可替代地,选择性调节可以包括相对于其他音频信号改变与被确定为对应于可穿戴照相机4402视野之外的发声对象的音频信号相关联的讲话的音调或速率,以使得声音对于用户100更加可感知(例如,增加单词之间的间距、措辞改进、口音改进等等)。可以执行各种其它处理,诸如数字地降低音频信号内的噪声。与本公开一致,处理设备可以区分三种类型的背景噪声。例如,第一类型可以是随时间基本恒定的静止噪声,诸如冰箱。第二类型可以是相对瞬态的非平稳噪声,诸如坠落对象的声音。第三种类型可以是比第二种类型的时间长而比第一种类型的时间短的临时噪声。第三种背景噪音的示例可以包括路过的汽车、观众中的嗡嗡声等等。处理设备可引起基于所识别的背景噪声类型的音频信号的选择性调节。
567.如上所述,处理设备可基于检索到的信息来确定至少一个声音的重要性等级大于阈值。在本实施例中,音频信号的选择性调节可以包括基于重要性等级的确定放大至少一个声音。例如,检索到的信息可以将一些音频信号识别为火警,并将这些音频信号排序为重要。当用户100对与火警相关联的范围内的音调具有较低的灵敏度时,音频信号的选择性调节可包括改变音频信号的音调以使得火警对于用户100更加可感知。在另一个实施例中,选择性调节还包括衰减由其他发声对象生成的声音。其他发声对象可以在照相机视野的内部或外部。
568.在步骤4662中,处理设备可引起调节后的音频信号传输到被配置为向用户100的耳朵提供声音的听力接口设备4406。与本公开一致,处理设备可使发射器(例如,无线收发器530a)经由无线网络(例如,蜂窝、wi
‑
fi、fi、等)或经由近场电容耦合、其他短距离无线技术或经由有线连接将调节后的音频信号发送到听力接口设备4406。此外,处理设备可
以使未处理的音频信号与调节后的音频信号一起传输到听力接口设备4406。在一个实施例中,在可穿戴麦克风4404获取至少一个音频信号之后,可在不到100msec内将调节后的音频信号发送到听力接口设备4406。例如,在可穿戴麦克风4404获取至少一个音频信号之后,可在小于50msec、小于30msec、小于20msec或小于10msec内将调节后的音频信号发送到听力接口设备4406。
569.使用语音和视觉签名识别对象
570.与公开的实施例一致,助听器系统可以使用语音和视觉签名来识别用户的环境中的对象。助听器系统可以分析捕获到的用户的环境图像,以识别发声对象并确定对象的视觉特性。当识别不确定时(例如,置信水平低于预定水平),或者基于任何其他标准,系统可以使用从获取的音频信号确定的声纹来识别对象。助听器系统可以重复该过程的一个或多个部分,直到确定性超过阈值,然后基于确定的对象身份采取动作。视觉和音频识别之间的这种关联提供更快的音频分析动作(诸如说话者分离)的开始。
571.图47a是示出根据示例性实施例的助听器系统4700的框图。助听器系统4700可以包括至少一个可穿戴照相机4701、至少一个麦克风4702、至少一个处理器4703和至少一个存储器4704。助听器系统4700还可以包括除图47a中所示的组件之外的附加组件。例如,助听器系统4700可以包括一个或多个以上参考图5a
‑
5c所述的部件。此外,图47a所示的组件可以封装在单个设备中,或者可以包含在一个或多个不同的设备中。
572.可穿戴照相机4701可配置为从用户100的环境捕获一个或多个图像。在一些实施例中,可穿戴照相机4701可包括在可穿戴照相机设备中,例如装置110。例如,可穿戴照相机4701可为照相机1730,如上所述,其也可对应于图像传感器220。
573.麦克风4702可以配置为从用户100的环境中捕获声音。在一些实施例中,照相机4701和麦克风4702可以包括在同一设备中。类似于可穿戴照相机4701,麦克风4702可以包括在可穿戴照相机设备中,例如装置110。例如,装置110可以包括麦克风1720,如关于图17b所述,麦克风1720可以被配置为确定用户100的环境中声音的方向性。如上所述,装置110可以由用户100以各种配置穿戴,包括物理连接到衬衫、项链、腰带、眼镜、腕带、按钮或与用户100相关联的其他物品。在一些实施例中,还可以包括一个或多个附加设备,诸如计算设备120。因此,本文中描述的关于装置110或处理器210的一个或多个过程或功能可以由计算设备120和/或处理器540执行。装置110还可以与用户100穿戴的听力接口设备(例如听力接口设备1710)通信。这种通信可以通过有线连接,或者可以无线地进行(例如,使用蓝牙
tm
、nfc或无线通信的形式)。
574.处理器4703可配置为接收和处理可穿戴照相机4701和麦克风4702捕获的图像和音频信号。在一些实施例中,处理器3803可与装置110相关联,因此可包括在与可穿戴照相机4701和麦克风4702相同的外壳中。例如,处理器4703可对应于处理器210、210a或210b,如上文关于图5a和5b所述。在其他实施例中,处理器4703可以包括在一个或多个其他设备中,诸如计算设备120、服务器250(图2)或各种其他设备。在这样的实施例中,处理器4703可以被配置为远程接收数据,诸如可穿戴照相机4701捕获的图像和麦克风4702捕获的音频信号。
575.存储器4704可以配置成存储与用户100的环境中发声对象相关的信息。存储器4704可以是能够存储关于一个或多个对象的信息的任何设备,并且可以包括硬盘驱动器、
固态驱动器、web存储平台、远程服务器等。存储器4704可位于装置110内(例如,存储器550内)或装置110外部。
576.图47b是示出与本公开一致的使用语音和视觉签名来识别对象的示例性环境的示意图。用户100的环境可以包括一个或多个发声对象。发声对象可以包括能够发出用户100或装置110可感知的声音的任何对象。例如,发声对象可以是发声对象4710和4711,如图47所示。在某些情况下,发声对象4710或4711可以是个体,如图47所示。在其他实施例中,发声对象4710或4711可以是设备,诸如收音机、扬声器、电视、移动设备(例如,移动电话、平板等)、计算设备(例如,个人计算机、桌上型计算机、膝上型计算机、游戏机等)、车辆、警报器,或任何其他能发出声音的设备。发声对象4710或4711还可包括其它对象,诸如宠物、动物、昆虫、自然特征(例如,溪流、树木等)或可发出声音的任何其它对象。
577.助听器系统4700可配置为接收与发声对象4710和/或4711相关的图像和/或音频信号。例如,可穿戴照相机4701可包括在装置110中,由用户100穿戴。可穿戴照相机4701可以捕获包括用户100的环境中的发声对象4710的表示的图像。该图像可以包含用户100的环境中的其他对象或特征的表示。处理器4703可以接收由可穿戴照相机4701和4703捕获的多个图像并分析图像以确定发声对象4710的视觉特性。这种视觉特性可以包括在图像中表示的对象的任何特征。例如,视觉特性可以包括颜色、形状、大小等。在一些实施例中,视觉特性可以指示发声对象的类型。例如,视觉特性可以识别发声对象4710是个体还是无生命对象、对象的分类(例如,电视、车辆、动物、人等)、个体的身份、对象的身份或其他类似对象类型分类。因此,处理器4703可以使用一个或多个图像辨识技术或算法来检测发声对象4710的特征。例如,处理器4703可以识别对象的一个或多个点、边、顶点或其他特征。例如,在发声对象4710是个体的情况下,处理器4703可以基于对个体的图像的面部分析来进一步确定视觉特性。因此,处理器4703可以识别个体面部上的面部特征,诸如眼睛、鼻子、颧骨、下巴或其他特征。处理器4703可以使用一个或多个算法来分析检测到的特征,诸如主成分分析(例如,使用特征脸)、线性判别分析、弹性束图匹配(例如,使用fisherface)、局部二元模式直方图(lbph)、尺度不变特征变换(sift)、加速鲁棒特征(surf)等。类似的特征识别技术也可用于检测无生命对象的特征。
578.处理器4703还可配置为接收与用户100环境中的发声对象相关联的音频信号。音频信号可代表从发声对象发出的一个或多个声音。例如,发声对象4710可以发出声音4720,如图47b所示。麦克风4702可以被配置为捕获声音4720并将其转换为要由处理器4703处理的音频信号。声音4720可以是由发声对象4710产生的任何声音或噪声。例如,声音4720可以是电视、移动电话或其他设备的输出,或者是车辆产生的声音。在发声对象4710是个体的情况下,声音4720可以是个体的语音。处理器4703可被配置为分析接收到的音频信号以确定发声对象的声纹。处理器4703可被配置为基于对个体的记录的音频分析来确定声纹。这可以使用语音辨识组件(诸如,语音辨识组件2041)来执行,如图20b中所述。处理器4703可以使用一个或多个语音辨识算法(例如,隐马尔可夫模型、动态时间扭曲、神经网络或其他技术)来识别个体的语音。所确定的声纹可包括与个体相关联的各种特性,诸如个体的口音、个体的年龄、个体的性别等。虽然声纹可以表示个体的语音模式,但是术语声纹应当被广泛地解释为包括可用于识别发声对象4710的任何声音模式或特征。
579.存储器4704可以包括一个或多个数据库4705,其中包含与多个对象相对应的参考
视觉特性和参考声纹。例如,数据库4705可以存储多个视觉特性,并且可以将一个或多个对象与视觉特性相关联。例如,数据库4705可以将大小、颜色、形状或其他视觉特性与特定类型的对象(诸如电视或移动电话)相关联。数据库4705还可以将视觉特性与特定对象而不是对象类型相关联。例如,视觉特性可用于识别属于用户100或用户100已知的另一个体的移动电话或其他对象。在一些实施例中,数据库4705可包括用户100已知的联系人列表。视觉特性可包括用于识别特定个体的面部特征。在一些实施例中,数据库4705可与社交网络平台(例如脸书
tm
、领英
tm
tm
等)相关联。处理器4703可被配置为访问数据库4705以识别发声对象4710。例如,处理器4703可以将从捕获的图像确定的视觉特性与存储在数据库4705中的视觉特性进行比较。处理器4703可以基于视觉特性匹配的程度来确定图像中表示的发声对象与数据库4705中的对象之间的匹配。在一些实施例中,处理器4703还可以被配置为确定与匹配相关联的置信得分。例如,置信得分可以基于在图像中检测到的与给定对象的数据库中的视觉特性相匹配的视觉特性的数目。置信得分也可以基于视觉特性与数据库4705中的视觉特性的匹配程度。例如,如果视觉特性是一种颜色,置信得分可以基于在图像中检测到的颜色与数据库4705中表示的颜色的匹配程度。置信得分可以以比例(例如,范围从1
‑
10、1
‑
100等)表示为百分比或任何其他合适的格式。在一些实施例中,识别对象可包括将置信得分与特定阈值进行比较,或确定多个潜在对象的置信得分并选择具有最高得分的对象。
580.数据库4705可以类似地将声纹数据与多个对象相关联。例如,数据库4705可以包含与多个个体相关联的声纹数据,类似于上述存储的视觉特性数据。例如,处理器4703可以将从接收到的音频信号确定的声纹数据与数据库4705中的声纹数据进行比较。处理器4703可以基于声纹数据匹配的程度来确定在音频信号中表示的发声对象与数据库4705中的对象之间的匹配。该过程可单独使用,或与上述视觉特性识别技术结合使用。例如,发声对象可以使用视觉特性识别,并且可以使用声纹数据进行确认,反之亦然。在一些实施例中,使用确定的视觉特性识别至少一个发声对象可以导致一组候选对象,并且至少一个发声对象的识别可以包括基于声纹选择候选一组对象中的一个候选对象。
581.类似于视觉特性,处理器4703还可以被配置为确定与声纹匹配相关联的置信得分。例如,置信得分可以基于在音频信号中检测到的声纹与给定对象的存储在数据库4705中的声纹数据匹配的程度。在一些实施例中,声纹数据的置信得分可以与上述基于视觉特性的置信得分相结合。例如,单个置信得分可以表示基于对视觉特性和声纹的组合分析的发声对象4710与数据库4705中的对象相对应的置信度。在一些实施例中,处理器4703可以基于视觉特性确定置信得分,并且,如果置信得分不超过某一阈值,则使用声纹数据进一步识别发声对象4710并细化置信得分。
582.与本公开一致,数据库4703可至少部分地通过机器学习过程构建。例如,数据库4703可以通过将训练数据集输入训练算法中来将各种视觉特性或声纹与已知对象相关联来编译。因此,识别发声对象可以基于与数据库4705相关联的经训练的神经网络的输出。随着助听器系统4700继续识别对象,经训练的神经网络可以不断改进。例如,用户100可以确认或手动编辑通过处理器4703识别的对象的身份,并且可以根据用户100的反馈调整或进一步研发神经网络。这种反馈可以通过与用户100相关联的设备(诸如装置110、计算设备120或任何其他能够与助听器系统4700交互的设备(例如,通过网络连接等))接收。
583.在一些实施例中,处理器4703可配置为基于与另一发声对象相关联的视觉特性或声纹数据来确定发声对象的身份。例如,至少一个发声对象可以包括第一发声对象(例如,发声对象4710)和第二发声对象(例如,发声对象4711)。助听器系统4700可以使用所确定的第一发声对象的视觉特性来识别第二发声对象。类似地,助听器系统4700可以使用所确定的第一发声对象的声纹来识别第二发声对象。来自第一发声对象4710的视觉特性或声纹数据可以指示第二发声对象4711的身份。例如,在发声对象是个体的情况下,第一个体可能经常与第二个体一起遇到。作为另一示例,个体可能经常与诸如移动电话、宠物等的对象相关联。处理器4703可基于与个体相关联的视觉特性(例如,面部辨识)和声纹数据来确定对象的身份。因此,数据库4705(或存储器4704)可被配置为存储数据库内的各种对象之间的关联。
584.处理器4703可被配置为基于是否基于第一发声对象4710的视觉特性和/或声纹数据来识别第二发声对象4711来调整置信得分。例如,在仅基于第一发声对象4710的视觉特性和/或声纹数据来识别第二发声对象4711的情况下,处理器4703可以分配较低的置信得分。另一方面,其中基于与第二发声对象4711相关联的视觉特性和/或声纹数据来识别第二发声对象4711,并且使用与第一发声对象4710相关联的视觉特性和/或声纹数据来确认第二发声对象4711,处理器4703可以分配比如果仅基于第二发声对象4711自身的视觉特性和/或声纹来识别第二发声对象4711更高的置信得分。
585.在一些实施例中,助听器系统4700可配置为基于识别发声对象4710来执行各种动作。在一些实施例中,处理器4703可存储与识别4710有关的信息。例如,处理器4703可在存储器4704中存储与发声对象4710的相遇有关的信息。这可包括存储诸如上面确定的对象的身份(或个体的身份)的信息。该信息还可以包括与识别相关联的时间、与被捕获的图像或音频信号相关联的时间、位置(例如,用户100的位置或发声对象4710的位置)、与发声对象相关联的数据(例如,捕获的图像或音频信号等)、相遇中提到的关键字,或其他各种信息。在一些实施例中,处理器4703可以保持与装置110相关联的已识别对象或其他事件的时间线,并且处理器4703可以将所识别的发声对象添加到时间线。在一些实施例中,存储信息可以包括更新数据库4705。例如,信息可用于更新发声对象4710的视觉特性,或可用于更新发声对象4710的声纹。所存储的信息可改进存储在数据库4705中的关联的准确性,从而提高助听器系统4700在未来对象中识别的准确性。
586.在一些实施例中,助听器系统4700可配置为调节从发声对象接收的声音。在一些实施例中,助听器系统4700执行的动作可以包括引起与至少一个发声对象相关联的至少一个音频信号的选择性调节,并且使得至少一个调节后的音频信号传输到被配置成向用户的耳朵提供声音的听力接口设备。例如,处理器4703可从发声对象4710接收与声音4720相关联的音频信号。基于对发声对象4710的识别,处理器4703可选择性地调节与声音4720相关联的音频信号。例如,发声对象4710可以是电视,并且处理器4703可以选择性地调节电视的音频。在发声对象4710是个体的情况下,处理器4703可确定从个体发出的声音4720应被选择性地调节。
587.在一些实施例中,调节可包括改变与声音4720对应的一个或多个音频信号的音调,以使得声音对于用户100更加可感知。例如,用户100对特定范围内的音调的敏感度较低,并且对音频信号的调节可调整声音4720的音高。例如,用户100可在高于10khz的频率中
经历听力损失,并且处理器210可将更高频率(例如,在15khz处)重新映射到10khz。在一些实施例中,处理器210可被配置为改变与一个或多个音频信号相关联的讲话速率。处理器210可被配置为改变发出声音对象4710的讲话速率,以使检测到的讲话对用户100更加可感知。选择性调节的类型和程度可取决于所识别的特定对象或个体和/或取决于用户的偏好。例如,存储器4704(例如,数据库4705)可以存储与特定对象相关联的选择性调节功能。
588.在一些实施例中,选择性调节可包括衰减或抑制一个或多个与发声对象4710无关的音频信号,诸如声音4721和4722,这些声音可能来自环境中的其他对象(例如,发声对象4711),或可能是背景噪声。类似于声音4720的放大,声音的衰减可以通过处理音频信号,或者通过改变与麦克风4702相关联的一个或多个参数以定向焦点远离与发声对象4710不相关联的声音来发生。
589.当检测到一个以上的发声对象时,助听器系统4700可以相对于彼此选择性地调节与发声对象相互关联的声音。例如,至少一个发声对象可以包括第一发声对象(例如,发声对象4710)和第二发声对象(例如,发声对象4711)。选择性调节可包括衰减与第一发声对象相关联的第一音频信号;以及放大与第二发声对象相关联的第二音频信号。类似地,选择性调节可包括改变与第一发声对象相关联的第一音频信号的音调;以及避免改变与第二发声对象相关联的第二音频信号的音调。因此,与第一发声对象相关联的音频信号对于用户100可以更加可感知。在发声对象是个体的情况下,选择性调节可以包括改变与第一个体相关联的讲话速率,并且避免改变与第二个体相关联的讲话速率。例如,处理器4703可在与第一个体相关联的词之间添加短暂停顿,以使音频更加可理解。还可以执行各种其它形式的选择性调节以改进对用户100的音频信号的呈现。
590.助听器系统4700可执行其他动作,诸如向用户100呈现发声对象4710的确定身份。该身份可以以各种方式呈现。在一些实施例中,助听器系统4700可以通过听力接口设备1710、计算设备120或各种其他设备,听觉地向用户呈现对象的身份。助听器系统4700可向用户读取检测到的对象的名称。因此,助听器系统可以访问在数据库4705中的用于呈现对象名称的一个或多个语音到文本算法或软件组件。在其他实施例中,可以将对象的预先记录的名称存储在存储器4704中。如果发声对象是个体,助听器系统4700可向用户提供个体的名称和/或与个体有关的其他信息(例如,与个体的关系、个体年龄、与个体有关的其他个体的名称、个体的头衔等)。
591.助听器系统4700还可以视觉地向用户100呈现发声对象4710的确定身份。图48是示出与本公开一致的显示发声对象的名称的示例性设备的图。如图48所示,助听器系统4700可以在设备4801的显示器上显示关于发声对象4710的信息。在一些实施例中,设备4801可以是配对的可穿戴设备,例如移动电话、平板、个人计算机、智能手表、抬头显示(hud)等。在发声设备4710是个体的实施例中,助听器系统4700执行的至少一个动作可包括使得个体的名称4810显示在显示器上。显示器上也可以呈现各种其他信息。例如,设备4801可以显示如图48所示的对象或个体的图像4811。在发声对象是个体的情况下,助听器系统4700可以显示与该个体相关的各种其他识别信息(诸如电话号码、地址、标题、公司、关系、年龄等)。显示器还可以包括与个体相关联的其他功能,诸如联系个体(例如通过电话、电子邮件、短信等)、访问与个体相关联的帐户(例如社交媒体页面、文件共享帐户或位置等)。在某些情况下,显示器还可以包括用于确认或编辑发声对象4710的识别的功能,例如,如上文
所述改进经训练的神经网络或其他机器学习系统。
592.图49是示出与本公开的实施例一致的用于使用语音和视觉签名来识别对象的示例性过程4900的流程图。过程4900可以由助听器系统4700执行,例如由处理器4703执行。如上所述,处理器4703可以对应于上面详细描述的一个或多个其他处理器,包括处理器210、210a和/或210b。因此,过程4900可由与诸如装置110的可穿戴照相机设备相关联的处理器执行。过程4900的部分或全部可由与诸如计算机设备120、服务器250或其它设备的其它组件相关联的处理器执行。如上所述,助听器系统4900可以包括存储器4704,存储器4704被配置为存储与多个对象相对应的参考视觉特性和参考声纹的数据库(例如,数据库4705)。处理器4703或执行过程4900的各种步骤的处理器可以访问存储器4704。
593.在步骤4910中,过程4900可包括接收与至少一个发声对象相关联的图像数据和音频信号。例如,步骤4910可以包括接收由可穿戴照相机捕获的多个图像,其中多个图像中的至少一个描绘了用户的环境中的至少一个发声对象。图像可以例如由可穿戴照相机4701捕获,并且可以包括发声对象4710的表示。图像可以由处理器4703接收。步骤4910还可以包括接收由可穿戴麦克风获取的音频信号,其中,音频信号代表从至少一个发声对象发出的一个或多个声音。例如,处理器4703可以从麦克风4702接收音频信号,该音频信号可以表示从发声对象4710发出的声音4720。音频信号可以与捕获的图像同时接收,或者可以在稍后的过程4900期间接收,例如,在基于所捕获的图像对发声对象4710进行了识别之后。
594.在步骤4920中,过程4900可包括分析所接收的多个图像中的至少一个,以确定与至少一个发声对象相关联的一个或多个视觉特性。例如,处理器4703可以使用一个或多个图像辨识技术从图像中提取与发声对象4710相关联的特征。所提取的特征可以被分析以确定视觉特性,视觉特性可以包括对象的颜色、形状、排列、大小或其他特性。视觉特性可以指示对象的类型,诸如对象是个体还是无生命对象、对象的分类等。在一些情况下,发声对象4710可以是个体。因此,步骤4920可以包括基于对个体的图像的面部分析来确定视觉特性。因此,处理器4703可以识别个体面部上的面部特征,诸如眼睛、鼻子、颧骨、下巴或其他特征。处理器4703可以使用一个或多个算法来分析检测到的特征,诸如主成分分析(例如,使用特征脸)、线性判别分析、弹性束图匹配(例如,使用fisherface)、局部二元模式直方图(lbph)、尺度不变特征变换(sift)、加速鲁棒特征(surf)等。
595.在步骤4930中,过程4900可包括鉴于一个或多个视觉特性,识别(或试图识别)数据库中的至少一个发声对象,并确定识别的确定程度。因此,过程4900还可以包括访问与多个对象相对应的参考视觉签名和参考语音签名的数据库。如上所述,处理器4703可以访问数据库4705,数据库4705可以存储多个视觉特性、多个对象以及视觉特性与对象之间的关联。处理器4703可以尝试将步骤4920中确定的视觉特性与数据库4705中的视觉特性相匹配。在如上所述的一些实施例中,至少一个发声对象可以包括第一发声对象和第二发声对象,步骤4930还可包括使用第一发声对象的确定视觉特性来识别第二发声对象。处理器4703可以确定与捕获的图像中表示的发声对象对应于数据库4705中的一个或多个对象的确定程度相对应的置信得分。在一些实施例中,步骤4730可包括为数据库4705中的多个对象生成置信得分,并将发声对象4710识别为数据库4710中与最高置信得分相对应的对象。
596.在某些情况下,仅根据视觉特性就可以识别至少一个发声对象。然而,在某些情况下,过程4900还可以包括基于与发声对象相关联的音频信号来识别至少一个发声对象。因
此,过程4900可包括确定基于视觉特性的识别是否足够的步骤4935。例如,步骤4935可包括将步骤4930中确定的置信得分与特定阈值进行比较。在置信得分以百分比表示(100%代表最大置信度)的情况下,例如,阈值可以是中间值(例如40%、50%、60%、70%等)。阈值可以更高或更低,具体取决于系统的使用。在一些实施例中,阈值可以根据各种其他因素或设置而改变,例如,基于识别对象的类型、图像质量、与正确识别对象相关联的重要性值、一天的时间、用户设置的阈值、管理员设置的阈值等。如果置信得分超过阈值,则过程4900可以继续到图49所示的步骤4960。然而如果置信得分低于阈值,则过程4900可继续到步骤4940。步骤4935的结果可由除置信得分之外的其他因素确定。例如,用户或管理员可以将设置更改为始终继续到步骤4960或4940。在其他实施例中,确定可以基于其他因素,诸如发声对象的类型(例如,对象是否是个体等)或重要值(例如,如果助听器系统正在识别迎面而来的车辆等)。
597.在步骤4940中,过程4900可包括分析接收到的音频信号,以确定至少一个发声对象的声纹。如上所述,关于步骤4910,步骤4940可以包括在尚未接收到音频信号的情况下接收由可穿戴麦克风获取的音频信号的步骤。音频信号可以代表从至少一个发声对象发出的一个或多个声音。处理器4703可以分析接收到的音频信号,以识别发声对象的声纹。在至少一个发声对象是个体的情况下,步骤4940可包括基于对个体的记录的音频分析来确定声纹。例如,处理器4703可以使用一个或多个语音辨识算法,诸如隐马尔可夫模型、动态时间扭曲、神经网络或其他技术来辨识个体的语音。确定的声纹可以包括个体的特性,诸如口音、年龄、性别、词汇等。
598.在步骤4950中,过程4900可包括基于视觉特性和确定的声纹识别至少一个发声对象。例如,处理器4703可以访问数据库4705,数据库4705可以存储与多个对象相关联的声纹数据。处理器4703可被配置为确定步骤4940中确定的声纹与存储在数据库4705中的声纹数据之间的匹配。在一些实施例中,使用确定的视觉特性(例如,在步骤4930中)识别至少一个发声对象导致一组候选对象,并且,至少一个发声对象的识别包括基于声纹选择一组候选对象中的一个。在其他实施例中,声纹数据可用于独立地识别候选对象,并将候选对象与步骤4930中确定的对象进行比较。在一些实施例中,如上所述,至少一个发声对象可以包括第一发声对象和第二发声对象,步骤4930还可包括使用第一发声对象的确定视觉特性来识别第二发声对象。步骤4950还可以包括基于声纹确定与识别相关的置信得分。在一些实施例中,置信得分可以是累积的,表示基于步骤4930中的视觉特性识别和步骤4950中的声纹识别的置信度。在其他实施例中,可以单独确定声纹置信得分。
599.在步骤4955中,过程4950可包括重新评估至少一个发声对象的识别。与步骤4935类似,步骤4955可包括将来自步骤4950的置信得分与预定阈值进行比较。阈值可以是上文参考步骤4935描述的相同阈值,或者可以是不同的阈值。例如,与单独基于步骤4930相比,基于步骤4930和4950下的组合分析的置信得分可以服从更高的置信得分阈值。阈值和步骤4955下的确定通常可基于上文关于步骤4935所述的其它因素。如果置信得分超过阈值,则过程4900可进入步骤4960。然而,如果置信得分不满足阈值,过程4900可以返回到步骤4910。例如,助听器系统4700可以基于接收到的图像和音频信号确定不能识别对象,并且可以获得额外的图像和/或音频信号以完成识别。过程4900可包括其它步骤,例如向用户发送指示识别失败的通知等。
600.在步骤4960中,过程4900可包括基于至少一个发声对象的身份发起至少一个动作。如上所述,至少一个动作可以包括对与至少一个发声对象相关联的至少一个音频信号的选择性调节。至少一个动作还可包括使至少一个调节的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备,诸如听力接口设备1710。例如,选择性调节可包括改变音频信号的音调、音量或讲话速率,正如上面更详细地讨论的。在一些实例中,至少一个发声对象包括第一发声对象和第二发声对象,以及引起至少一个音频信号的选择性调节可以包括衰减与第一发声对象相关联的第一音频信号和放大与第二发声对象相关联的第二音频信号。选择性调节还可以包括改变与第一发声对象相关联的第一音频信号的音调,并避免挂起与第二发声对象相关联的第二音频信号的音调。在一些实例中,至少一个发声对象可包括第一个体和第二个体,并且引起对至少一个音频信号的选择性调节可包括改变与第一个体相关联的讲话速率和避免改变与第二个体相关联的讲话速率。
601.在一些实施例中,如上文更详细地描述的,至少一个动作可以包括存储在和与至少一个发声对象的相遇有关的至少一个存储器设备信息中。存储的信息可用于更新数据库4705中至少一个发声对象的视觉特性和/或声纹。例如,可以使用存储的信息来确保数据库4705准确和/或最新,如上文更详细地讨论的那样。
602.在一些实施例中,在至少一个发声对象(例如,发声对象4710)是个体的情况下,至少一个动作可包括如上文参考图48所述的使得个体的名称显示在显示器上。显示器可与配对的可穿戴设备(例如,设备4801)相关联,例如手机、智能手表或其他移动设备。如上详细讨论,还可以为用户100显示其他信息或功能。
603.基于图像数据的助听器选择性输入
604.与公开实施例一致,助听器系统可以选择性调节来自用户的环境中的发声对象的音频信号。助听器系统可以访问存储关于各种发声对象的信息的数据库,并且可以基于存储在数据库中的信息选择性地调节对来自发声对象的音频。作为一个示例,助听器系统可以基于相对秩或重要性来确定各种发声对象的相对秩或重要性,并选择性地调节与发声对象相关的音频信号。助听器系统还可以基于上下文选择性地调节来自发声对象的音频信号,例如基于用户的位置。
605.本公开的助听器系统可对应于上文关于图47a所述的助听器系统4700。例如,助听器系统可包括至少一个可穿戴照相机4701、至少一个麦克风4702、至少一个处理器4703,以及至少一个存储器4704。尽管在本公开的整个公开中,参考助听器系统4700描述用于选择性地调节来自发声对象的音频信号的助听器系统,但理解助听器系统可以与助听器系统4700分离和/或不同。例如,助听器系统可以包括比图47a所示的部件更多或更少的部件。此外,如上所述,图47a所示的组件可以被安置在单个设备中,或者可以包含在一个或多个不同的设备中。
606.如上所述,可穿戴照相机4701可配置为从用户100的环境捕获一个或多个图像。在一些实施例中,可穿戴照相机4701可包括在可穿戴照相机设备中,例如,如上文所述,可穿戴照相机4701可以是照相机1730,也可以对应于图像传感器220。麦克风4702可配置为捕获来自用户100的环境的声音。在一些实施例中,照相机4701和麦克风4702可以包括在同一设备中。麦克风4702可包括在可穿戴照相机设备中诸如装置110。例如,装置110可以包括如关于图17b所述的麦克风1720,其可配置为确定用户100环境中声音的方向性。装置110可由用
户100在各种配置中穿戴,包括物理连接到衬衫、项链、腰带、眼镜、腕带、按钮或与用户100相关联的其他物品。在一些实施例中,还可以包括一个或多个附加设备,例如计算设备120。因此,本文中描述的与助听器系统4700或处理器4703相关的一个或多个处理或功能可以由计算设备120和/或处理器540执行。
607.处理器4703可配置为接收和处理可穿戴照相机4701和麦克风4702捕获的图像和音频信号。如上所述,处理器4703可与装置110相关联,因此可包括在可穿戴照相机4701和麦克风4702的同一外壳中。例如,处理器4703可对应于处理器210、210a或210b,如上文关于图5a和5b所述。在其他实施例中,处理器4703可以包括在一个或多个其他设备中,例如计算设备120、服务器250(图2)或各种其他设备。在这样的实施例中,处理器4703可以被配置为远程接收数据,例如可穿戴照相机4701捕获的图像和麦克风4702捕获的音频信号。
608.存储器4704可配置为在用户100的环境中存储与发声对象相关联的信息。存储器4704可以是能够存储关于一个或多个对象的信息的任何设备,并且可以包括硬盘驱动器、固态驱动器、web存储平台、远程服务器等。存储器4704可以位于装置110(例如,存储器550内)或装置110外部。在一些实施例中,存储器4704还可以包括诸如数据库5020这样的数据库,具体描述如下。
609.装置110还可以与用户100所穿戴的听力接口设备通信。例如,助听器设备可以是听力接口设备1710,如图17a所示。如上所述,听力接口设备1710可以是配置成向用户100提供听觉反馈的任何设备。听力接口设备1710可以放置在用户100的一个或两个耳朵中,类似于传统的听力接口设备。听力接口设备1710可以是各种类型的,包括在耳道中、完全在耳道中、在耳中、在耳后、在耳上、耳道中接收器、开放适配或各种其他样式。听力接口设备1710可包括用于向用户100提供听觉反馈的一个或多个扬声器、用于接收来自另一系统的信号的通信单元(诸如装置110)、用于检测用户100环境中的声音的麦克风、内部电子、处理器、存储器,等等。听力接口设备1710可对应于反馈输出单元230,或者可以与反馈输出单元230分离,并且可以被配置为从反馈输出单元230接收信号。
610.在一些实施例中,如图17a所示,听力接口设备1710可包括骨传导耳机1711。骨传导耳机1711可通过手术植入,并且可以通过将声音振动骨传导到内耳向用户100提供听觉反馈。听力接口设备1710还可包括一个或多个耳机(例如,无线耳机、耳上耳机等)或由用户100携带或穿戴的便携式扬声器。在一些实施例中,听力接口设备1710可以集成到其他设备中,诸如蓝牙
tm
,使用者的耳机、眼镜、头盔(如摩托车头盔、自行车头盔等)、帽子等。听力接口设备1710可以被配置为与诸如装置110的照相机设备通信。这种通信可以通过有线连接,或者可以无线地(例如,使用蓝牙
tm
、nfc或无线通信的形式)进行。因此,听力接口设备1710可包括配置为接收至少一个音频信号的接收器和电声换能器,电声换能器配置为向用户的耳朵提供来自至少一个音频信号的声音。
611.图50a是示出与本公开一致的用户的环境5000中可以识别的发声对象的示例的示意图。如上所述,发声对象可以包括能够发出用户100或装置110可感知的声音的任何对象。在某些情况下,发声对象可以是个体,诸如图50a所示的个体5010和5011。在其他实施例中,发声对象可以是图50a所示的设备,诸如电视5012。发声对象可以包括其他设备,诸如收音机、扬声器、电视、移动设备(例如移动电话、平板等)、计算设备(例如个人计算机、桌上型计算机、笔记本、游戏控制台等)、车辆、警报或任何其他能够发出声音的设备。声音发出的对
象也可以包括其他对象,诸如宠物、动物、昆虫、自然特征(例如溪流、树木等)、无生命对象、与天气有关的对象或任何其他的对象或可能发声的对象的部分。
612.图50b是与本公开一致的存储与发声对象相关联的信息的示例数据库5020的图示。数据库5020可以维护在与助听器系统4700相关联的任何存储器上,诸如存储器4704。数据库4705可对应于上述数据库4705,或者可以是单独的数据库。在一些实施例中,数据库5020可以与助听器系统4700分开定位,例如在远程设备或服务器上,并且可以通过助听器系统4700访问。如图50b所示,数据库5020可以存储一个或多个发声对象的视觉特性。视觉特性可以包括可由助听器系统4700检测到的发声对象的特征或属性。例如,视觉特性可以包括相关联的发声对象的大小、颜色、形状、图案或其他视觉特征。视觉特性可以包括用于识别特定个体的面部特征。
613.数据库5020可以包括关于发声对象的其他信息,诸如名称、类型、关系、重要性等级、声纹数据和/或音频调节规则。如果发声对象是个体,则发声对象的名称可以与个体的姓名相关联。存储在数据库5020中的关系可以定义个体和用户100之间的关系,诸如个体是朋友、同事、家庭亲戚、熟人还是可以定义的任何其他形式的关系。例如,如图50b所示,个体辛迪摩尔可以是用户100的同事,其中个体拉吉宝拉可以是用户100的朋友。在一些实施例中,可以定义更具体的关系,诸如将同事识别为用户的经理,将家庭成员识别为用户的父亲,将朋友识别为亲密朋友等。在一些实施例中,数据库5020可与用户100的联系人列表、社交网络平台(例如,脸书
tm
、领英
tm
tm
等),或者各种其他相关联的列表或数据库相关联,并且可以被配置为基于从列表或数据库接收的数据来确定关系。
614.如上所述,发声对象也可以是设备或其他对象。在一些实例中,发声对象的名称可以是设备的通用名称(例如,膝上型计算机、电视、电话等)。在一些实施例中,助听器系统4700可以识别特定设备,而不仅仅是一般设备类型。因此,存储在数据库5020中的发声对象的名称可以特定于被检测的设备。例如,名称可以识别设备的所有者(例如,“我的手机”、“特里的膝上型计算机”等)。在一些实施例中,名称还可以包括设备的序列号或其他唯一标识符。类似地,发声对象的关系可以指示发声对象是否以某种方式与用户100相关联。
615.数据库5020可进一步存储与发声对象的选择性音频调节有关的信息。例如,重要性等级可以将数据库5020中发声对象彼此相对地排列。在一些实施例中,每个设备可以相对于数据库中的其他发声对象中的每一个唯一地排列。在其他实施例中,可以基于预定的排名级别(例如,“高重要性”、“低重要性”等)或任何其他合适的排名方法,以百分比的形式在比例(例如,1
‑
5、1
‑
10、1
‑
100等)上对发声对象进行排名。在一些实施例中,排名可以基于与用户的关系。例如,用户100的家庭成员可被赋予比用户100的熟人更高的重要性等级。类似地,用户100的经理或老板可被赋予比用户100的熟人更高的重要性等级。数据库5020还可存储与发声对象相关联的特定音频调节规则。例如,如图50b所示,规则可以包括要应用于与发声对象相关联的音频信号的预定调节参数,诸如改变音频信号的音高或音量。调节参数可以是绝对的(例如,设定音量水平,+10%音量等),或者可以相对于环境中的其他声音来定义(例如,相对于其他声音增大音量)。在一些实施例中,规则可以与一个或多个其他参数相关联,诸如与用户的关系。例如,该规则可以应用于用户100的所有家庭成员,或者可以应用于具有某种重要性等级的个体。在一些实施例中,规则还可以包括基于上下文的调节,例如,基于用户100的当前或先前动作、用户100的环境或任何其他基于上下文的规则。
参考图50b所示的示例,助听器系统4700可以被配置为当用户100不看电视时使其静音,或者当个体在外面开会时增大其音量。因此,助听器系统4700可以被配置为例如基于分析捕获图像中的其他对象、分析捕获音频、使用全球定位系统(gps)数据等来确定用户的环境。下面更详细地描述其它音频调节方法。
616.在一些实施例中,数据库5020还可以存储与发声对象相关联的声纹数据。声纹数据可以是与之相关联的特定发声对象所特有的(类似于上面描述的数据库4705中的声纹数据)。因此,声纹可适于识别发声对象。例如,处理器4703可以通过上述视觉特性识别发声对象,诸如个体,并且可以从数据库5020检索与发声对象相关联的信息。在一些实施例中,信息可以包括声纹,可用于进一步识别发声对象等。在一些实例中,特定发声对象的声纹信息可包括一组参考声纹。例如,特定个体的第一声纹可以与特定个体站在用户旁边的场景相关联,并且特定个体的第二声纹可以与特定个体通过通信设备说话的场景相关联。
617.在一些实施例中,存储在数据库5020中的信息可以由用户100或其他个体(例如,看守人、管理员等)指定和/或修改。例如,用户100可以手动添加或编辑数据库5020中的发声对象,例如通过诸如计算设备120的用户界面。用户100可以定义发声对象的名称、分类类型、关系、重要性等级和/或音频调节规则。在一些实施例中,可以通过自动化过程构建和/或修改数据库5020。例如,助听器系统4700可配置为基于用户100与发声对象的交互来学习与发声对象相关联的一个或多个属性或值。如果用户100在与特定的发声对象交互时不断增加听力接口设备1710的音量,助听器系统4700可自动包括增加与该发声对象相关联的音频信号的音量的规则。作为另一示例,用户100可以更频繁地查看相对于其他发声对象的特定发声对象,并且助听器系统4700可以基于用户100的行为来分配重要性等级、关系、音频调节规则或其他属性。
618.图51a是示出与本公开一致的用于选择性地调节音频信号的示例环境5100的示意图。如上文所述,用户100的环境5100可包括一个或多个发声对象。例如,环境5100可包括可以是个体的发声对象5110和5111以及可以是设备的发声对象5512。
619.助听器系统4700可配置为接收与发声对象5110、5111和5112相关联的图像和/或音频信号。例如,可穿戴照相机4701可包括在装置110中,用户100穿戴的可穿戴照相机4701可捕获包括用户100环境中的发声对象5110的表示的图像。处理器4703可接收由可穿戴照相机4701捕获的多个图像,并分析图像以确定发声对象5110的视觉特性。这种视觉特性可以包括图像中表示的对象的任何特征。例如,视觉特性可以包括颜色、形状、大小、类型等,其可对应于存储在数据库5020中的视觉特性类型。因此,处理器4703可以使用一种或多个图像辨识技术或算法来检测发声对象5110的特征。例如,处理器4703可以识别对象的一个或多个点、边、顶点或其他特征。在发声对象5110是个体的情况下,处理器4703可以基于个体的图像的面部分析或面部辨识进一步确定视觉特性。因此,处理器4703可以使用一个或多个算法来分析检测到的特征,诸如主成分分析(例如,使用特征脸)、线性判别分析、弹性束图匹配(例如,使用fisherface)、局部二元模式直方图(lbph)、尺度不变特征变换(sift),加速鲁棒特征(surf)等。类似的特征识别技术也可用于检测无生命对象的特征,诸如发声对象5112。
620.除了识别发声对象外,助听器系统4700还可以确定发声对象的上下文。因此,处理器4703可被配置为分析捕获图像内的其它特征或对象。例如,诸如树、花、草、建筑物等的对
象可以指示用户100在外面。其他对象,诸如椅子、桌子、计算机屏幕、打印机等,可以指示用户100处于办公室环境中。在一些实施例中,处理器4703可将特定对象或对象组与用户100的特定环境相关联。例如,处理器4703可辨识一个或多个对象以确定用户100位于特定房间,诸如用户100的起居室、特定办公室或会议室等。该上下文信息可用于选择性地调节与发声对象相关联的音频信号,如下面进一步详细描述的。
621.处理器4703还可配置为接收与用户100环境中的发声对象相关联的音频信号。音频信号可代表从发声对象发出的一个或多个声音。例如,发声对象5110、5111和5112可以分别发出声音5120、5121和5122,如图51a所示。助听器系统4700可被配置为捕获声音5120、5121和5122(例如,通过麦克风4702)并将其转换为将由处理器4703处理的音频信号。在发声对象是个体的情况下,诸如发声对象5110,声音5120可以是个体的语音。在发声对象是设备或其它对象(例如发声对象5112)的情况下,声音5122可以是设备的输出,诸如来自电视、移动电话或其它设备的声音、车辆产生的声音等。
622.在一些实施例中,处理器4703可配置为确定发声对象的声纹。可以根据上面关于图47b讨论的任何方法来确定声纹。例如,处理器4703可以使用一个或多个语音辨识算法(例如,隐马尔可夫模型、动态时间扭曲、神经网络或其他技术)来识别个体的语音。所确定的声纹可包括与个体相关联的各种特性,诸如个体的口音、个体的年龄、个体的性别等。虽然声纹可以表示个体的声音模式,但是术语声纹应该被广泛地解释为包括可用于识别发声对象的任何声音模式或特征。
623.助听器系统4700可配置为选择性地调节从一个或多个发声对象接收的声音。在一些实施例中,调节可包括改变与声音5120相对应的一个或多个音频信号的音调,以使声音对于用户100更加可感知。用户100可对特定范围内的音调具有较低的灵敏度,并且音频信号的调节可调整声音5120的音高。例如,用户100可在高于10khz的频率中经历听力损失,并且处理器4703可将更高频率(例如,在15khz处)重新映射到10khz。在一些实施例中,处理器4703可被配置为接收关于用户的听力能力的信息,并基于用户的听力能力引起至少一个音频信号的调节。
624.在一些实施例中,处理器4703可配置为改变与一个或多个音频信号相关联的讲话速率。处理器4703可被配置为改变发声对象5110的讲话速率,以使检测到的语音对于用户100更加可感知。选择性调节还可包括在音频信号内添加一个或多个间隔或停顿。例如,发声对象可以包括说句子的个体,并且使至少一个音频信号的调节包括在句子中的单词之间添加至少一个间隔以使句子更加可理解。因此,用户100可以以更高的速度(例如,1.1x、1.5x、2.0x、2.5x等)听到句子,而不是以1x的速度听到口语句子,并且每个单词之间的间隔可以相应地增加。类似地,可以增加句子之间的间隔,从而给用户100更多的时间来解释或消化每个句子。
625.在一些实施例中,助听器系统4700可以基于从数据库5020检索到的关于所识别的发声对象的信息来选择性地调节音频信号。例如,处理器4703可从发声对象5110接收与声音5120相关联的音频信号。基于发声对象5110的识别,处理器4703可从数据库5020检索关于发声对象的信息。例如,识别发声对象可以包括确定发声对象的类型,并且处理器4700还可以被编程为基于所确定的至少一个发声对象的类型引起对音频信号的选择性调节。在另一个实施例中,检索到的信息可以与用户100与发声对象的预先存在的关系相关联,并且至
少一个处理器可以进一步编程以基于预先存在的关系引起对至少一个音频信号的选择性调节。在一些实施例中,还可以基于与用户100相关联的上下文情况来执行选择性调节。上下文情况可以通过分析从照相机设备捕获的一个或多个图像来确定,诸如可穿戴照相机4701。基于上下文,通过数据库5020确定的发声对象的调节可能不同。作为说明性示例,如果发声对象是哭泣的婴儿,则选择性调节可以包括放大与婴儿相关联的音频信号的音量(如果用户100在家)。相反,如果助听器系统4700确定用户100在飞机上,则选择性调节可包括使与哭泣的婴儿相关联的音频信号静音。
626.当检测到多于一个的发声对象时,助听器系统4700可以相对于彼此选择性地调节与发声对象相互关联的声音。在图51a所示的示例场景中,发声对象5110和5111可以包括两个个体。处理器4703可经编程以基于检索到的与第一个体相关联的信息,引起对与第一个体相关联的音频信号(例如,发声对象5110)的第一选择性调节,以及基于检索到的与第二个体相关联的信息,引起对与第二个体相关联的音频信号(例如,发声对象5111)的不同于第一选择性调节的第二选择性调节。例如,第一个体可能难以理解,并且处理器4703可以增加与第一个体相关联的音频信号的音量或改变其音高。处理器4703可以确定与第二个体相关联的音频信号的重要性较低(例如,基于关系、重要性等级等),并且可以减小与第二个体相关联的音量。作为另一示例,处理器4703可分析多个图像以识别正在讲话的个体(例如,发声对象5110)和生成背景噪声的发声对象(例如,发声对象5112)。处理器4703可被配置为将个体生成的声音与背景噪声分离。因此,引起音频信号的选择性调节可包括相对于与个体相关联的音频信号衰减与发声对象相关联的音频信号。例如,如果发声对象是电视,例如发声对象5012,则音频信号的选择性调节可包括减小电视的音量或将其完全静音。
627.图51b是示出与本公开一致的用于选择性调节音频信号的另一示例环境5101的示意图。在该场景中,用户100可以穿戴装置110并且可以存在发声对象5110和5111,其可以是个体,如上所述。环境5101可以包括第三发声对象5113,其也可以是个体。处理器4703可以被配置为基于发声对象5110、5111和5113和/或用户100之间的交互来选择性地调节与发声对象5110、5111和5113相关联的音频信号。在图51b所示的场景中,处理器4703可以识别与用户100谈话的第一个体(例如,发声对象5110)和与第三个体(例如,发声对象5113)谈话的第二个体(例如,发声对象5111)。因此,处理器4703可放大与第一个体相关联的音频信号并衰减与第二个体相关联的音频信号。在另一个场景中,处理器4703可以识别收听特定个体的一组个体,并且可以被编程来放大来自特定个体的音频信号。
628.如上所述,数据库5020可包括一个或多个与特定发声对象相关联的声纹。处理器4703可包括用于接收与已基于视觉特性识别的发声对象相关联的参考声纹的指令。因此,处理器4703可以被配置为使用多个图像和参考声纹来识别至少一个发声对象,并基于与至少一个发声对象的身份相关联的预定设置来引起至少一个音频信号的调节。预定的设置可以对应于存储在数据库5020中的信息,包括用于选择性调节音频的规则、重要性等级、与用户100的关系,或者各种其他参数,这些参数可以在图50b中示出,也可以不在图50b中示出。例如,基于声纹数据,处理器4703可确定应该听到某些声音(例如,警报器、婴儿哭泣等),但可以减小背景噪声(例如,空调单元、交通、办公室伙伴噪声等)的音量。在一些实施例中,处理器4703可以进一步使用声纹来分离与各种发声对象相关联的音频信号。例如,每个发声对象与唯一的声纹相关联,并且处理器4703可以使用发声对象的声纹来分离由第一发声对
象生成的声音和由第二发声对象生成的声音。引起至少一个音频信号的调节可以包括相对于与第一发声对象相关联的音频信号衰减与第二发声对象相关联的音频信号。
629.图52是示出与所公开实施例一致的的用于调整从用户的环境中的对象发出的声音的示例性处理5200的流程图。过程5200可由助听器系统(例如助听器系统4700)执行,该系统可包括至少一个处理器(例如处理器4703),该处理器可编程以执行下文所述的步骤。处理器4703可对应于上述详细描述的一个或多个其他处理器,包括处理器210、210a和/或210b。因此,处理5200可以由与可穿戴照相机设备(例如装置110)相关联的处理器执行。处理5200的部分或全部可以由与其他组件相关联的处理器执行,例如计算设备120、服务器250和/或其他设备。如上所述,助听器系统4700可以访问数据库(例如数据库5020),数据库可以包含用于选择性地为一个或多个发声对象调节音频的信息。数据库可以是助听器系统的内部(例如,存储在存储器4704中)的或可以是外部的(例如,经由网络连接、短程无线连接等访问)。助听器系统还可包括至少一个可穿戴照相机(例如,可穿戴照相机4701)和至少一个可穿戴麦克风(例如麦克风4702)。在一些实施例中,可穿戴照相机、可穿戴麦克风和至少一个处理器可以包括在公共外壳中(例如,在装置110中)。在其他实施例中,可穿戴照相机、可穿戴麦克风和至少一个处理器可以分布在多个外壳之间。例如,可穿戴照相机和可穿戴麦克风包括在第一外壳中,并且至少一个处理器包括在与第一外壳分离的第二外壳中。
630.在步骤5210中,过程5200可包括接收由可穿戴照相机捕获的多个图像。例如,步骤5210可以包括接收由可穿戴照相机从用户(例如,用户100)的环境捕获的多个图像。因此,多个图像可以描绘用户的环境中的对象。多个图像可以包括发声对象的表示,诸如发声对象5110。在步骤5220中,过程5200可以包括接收由可穿戴麦克风获取的音频信号。音频信号可以代表在步骤5210中接收的多个图像中描绘的对象发出的声音。例如,处理器4703可以从麦克风4702接收音频信号,麦克风4702可以代表从发声对象5110发出的声音5120。
631.在步骤5230中,过程5200可包括分析多个图像以识别用户的环境中的至少一个发声对象。例如,处理器4703可以使用一个或多个图像辨识技术来从图像中提取与发声对象5110相关联的特征。在一些实例中,至少一个发声对象可以包括个体,并且相应地,步骤5230可包括对个体的图像执行面部分析或面部辨识。在一些实施例中,识别至少一个发声对象可以包括确定至少一个发声对象的类型。例如,处理器4703可确定发声对象5510是否是机械机器或设备、扬声器、个体、动物、无生命对象、天气相关对象等。
632.在步骤5240中,过程5200可包括从数据库检索关于至少一个发声对象的信息。例如,处理器4703可以访问存储关于一个或多个发声对象的信息的数据库5020。所存储的信息可以指一类发声对象(例如,电视机),或者可以指特定发声对象(例如,特定的人、用户的电话等)。如上参考图50b所述,数据库5020可以存储包括对象的视觉特性、对象的名称、对象的类型、对象与用户的关系、对象的重要性等级、与对象相关联的声纹数据、对象的音频调节规则的信息,或其他信息。
633.在步骤5250中,过程5200可包括基于检索到的信息,引起对可穿戴麦克风从与至少一个发声对象相关联的区域接收到的至少一个音频信号的选择性调节。可以使用上述各种方法来确定区域(例如,如图20a所示)。例如,可以基于基于对多个图像或音频信号中的一个或多个的分析而确定的发声对象的方向来确定区域。该范围可与关于发声对象的方向的角宽度相关联(例如,10度、20度、45度等)。
634.如上所述,可以对音频信号执行各种形式的调节。在一些实施例中,调节可包括改变音频信号的音调或回放速度。例如,调节可以包括改变与音频信号相关联的讲话速率。如上所述,至少一个发声对象可以包括说句子的个体,并且引起至少一个音频信号的调节可以包括在句子中的单词之间添加至少一个间隔以使句子更加可理解。在一些实施例中,调节可包括相对于从与被辨识的个体相关联的区域外部接收的其他音频信号放大音频信号。可以通过各种方式来执行放大,诸如操作配置成聚焦于从该区域发出的音频声音的定向麦克风,改变与可穿戴麦克风相关联的一个或多个参数以使麦克风聚焦于从该区域发出的音频声音,调整音频信号的一个或多个属性等。放大可包括衰减或抑制由麦克风从区域外的方向接收的一个或多个音频信号。如上所述,选择性调节可取决于用户的偏好或听力能力。例如,检索到的信息(例如,在步骤5240中接收到的信息)可以包括指示用户的听力能力的信息,并且可以基于用户的听力能力引起至少一个音频信号的调节。
635.在一些实施例中,识别至少一个发声对象(例如,在步骤5230中)可包括确定至少一个发声对象的类型,并且至少一个处理器可被进一步编程以基于所确定的至少一个发声对象的类型引起对至少一个音频信号的选择性调节。例如,个体的语音可以被放大,而来自电视的声音可以被减弱或静音。在其他实施例中,检索到的信息可以与用户和至少一个发声对象的预先存在的关系相关联,并且至少一个处理器还可以被编程为基于预先存在的关系引起对至少一个音频信号的选择性调节。例如,处理器4703可以识别发声对象是属于用户100的电话,并且可以放大与属于用户100的电话相关联的音频信号,但是可以不放大(或者可以静音或衰减)与其他电话相关联的音频信号。在至少一个发声对象包括多个对象的情况下,处理器4703可以对与这些对象相关联的音频信号应用放大层次结构。在这样的实施例中,放大的层次结构可以基于预先存在的关系。
636.与本公开一致,处理器4703可以相对于其他发声对象选择性地调节与一个发声对象相关联的音频。例如,至少一个发声对象可以包括多个发声对象,并且过程5200还可以包括使用多个图像来识别不同类型的发声对象,并且对由从与不同类型的发声对象相关联的不同区域接收的音频信号应用不同的调节。类似地,过程5200还可包括分析多个图像以识别说话的个体和产生背景噪声的发声对象,并将个体产生的声音与背景噪声分离。引起至少一个音频信号的调节可以包括相对于与个体相关联的音频信号衰减与发声对象相关联的音频信号,该发声对象产生背景噪声。例如,发声对象可以是电视或类似设备,并且衰减音频信号可以包括静音或减小与电视相关联的音频信号的音量。
637.在一些实施例中,处理器4703可配置为在用户100的环境中选择性地调节与多个个体相关联的音频信号。如上所述,处理器4703可配置为基于数据库5020中的信息对不同个体应用不同的调节。例如,至少一个发声对象可以包括多个个体,并且至少一个处理器还可以被编程为基于检索到的与第一个体相关联的信息来引起与第一个体相关联的音频信号的第一选择性调节,并且基于检索到的与第二个体相关联的信息引起与第二个体相关联的音频信号的不同于第一选择性调节的第二选择性调节。
638.处理器4703还可以基于个体的动作选择性地调节音频信号。例如,所述至少一个发声对象可以包括多个个体,并且所述至少一个处理器还可以被编程为在所述多个图像中识别与用户交谈的第一个体和与第三个体交谈的第二个体。所述至少一个处理器可放大来自所述第一个体的音频信号并衰减来自所述第二个体的音频信号。因此,与正在与用户交
谈的第一个体相关联的音频可以比与第二个体相关联的音频更容易感知。作为另一示例,所述至少一个发声对象可以包括多个个体,并且所述至少一个处理器还可以被编程为在所述多个图像中识别收听特定个体的一组个体并放大来自所述特定个体的音频信号。
639.在一些实施例中,处理器4703可以基于检测到的说话者选择性地调节音频信号。处理器4703可以基于另一个体开始讲话在说话者之间自动切换。例如,多个发声对象可以包括多个个体,并且过程5200可以包括使用多个图像来确定第一个体正在讲话;放大从与第一个体相关联的区域接收的音频信号;使用多个图像来确定第二个体将要讲话并放大从与第二个体相关联的区域接收的音频信号,而不是从与第一个体相关联的区域接收的音频信号。例如,处理器4703可以被配置为检测第二个体的面部特征,并且可以在他们张开他们的嘴时自动切换以调节与第二个体相关联的音频信号等。
640.在一些实施例中,处理器4703还可以确定和/或检索与发声对象相关联的声纹数据,以便选择性地调节与发声对象相关联的音频。例如,检索到的信息(例如,在步骤5240中从数据库5020检索到的信息)可以包括与至少一个发声对象相关联的参考声纹。在一些实施例中,过程5200还可以包括使用多个图像和参考声纹来识别至少一个发声对象,分离与参考声纹相关联的音频信号,以及基于与至少一个发声对象的身份相关联的预定设置引起音频信号的调节。例如,处理器4703可放大与用户100的亲密家庭成员相关联的音频信号,但可衰减或静音与诸如嘈杂的办公室伙伴的其他个体相关联的音频。数据库5020可以为每个发声对象存储多于一个的声纹。例如,至少一个发声对象可以包括多个个体,并且检索到的信息可以包括每个个体的一组参考声纹。特定个体的第一声纹可以与特定个体正站在用户旁边的场景相关联,并且特定个体的第二声纹可以与特定个体通过通信设备讲话的场景相关联。因此,处理器4703可以选择性地调节个体的语音,而不管他们是正站在用户旁边还是正在扬声器电话上讲话。
641.声纹数据也可用于改进音频信号的选择性调节。例如,过程5200还可以包括分析多个图像以识别用户的环境中的多个发声对象,其中每个发声对象与唯一的声纹相关联。过程5200可包括使用多个发声对象的声纹来分离由第一发声对象产生的声音和由第二发声对象产生的声音,以及引起至少一个音频信号的调节可包括相对于与第一发声对象相关联的音频信号衰减与第二发声对象相关联的音频信号。
642.如上所述,选择性调节还可以基于与用户100或至少一个发声对象相关联的上下文信息。例如,过程5200还可以包括基于对多个图像的分析来识别与多个图像中的一个或多个相关联的上下文情况;从数据库中检索与上下文情况有关的信息;以及响应于第一检测到的上下文情况引起来自特定对象的音频信号的第一选择性调节,并且响应于第二检测到的上下文情况引起来自特定对象的音频信号的与第一选择性调节不同的第二选择性调节。
643.在步骤5260中,过程5200可以包括使至少一个调节后的音频信号传输到被配置为向用户的耳朵提供声音的听力接口设备。例如,调节后的音频信号可以被发送到听力接口设备1710,听力接口设备1710可以向用户100提供与音频信号相对应的声音。处理器4703可以被配置为实时(或在非常短的延迟之后)发送调节后的音频信号。例如,至少一个处理器可被编程为使得在可穿戴麦克风获取至少一个音频信号之后在不到100msec(例如,10msec、20msec、30msec、50msec等)内将至少一个调节后的音频信号传输到听力接口设备。
执行过程1900的处理器还可以被配置为使得向听力接口设备传输一个或多个代表其他发声对象的音频信号,这些音频信号也可以是调节后的。因此,听力接口设备可以包括被配置为接收至少一个音频信号的接收器。如上所述,至少一个音频信号可以已经由可穿戴麦克风获取,并且可以由至少一个处理器选择性地调节,处理器被配置为接收由可穿戴照相机捕获的多个图像,在多个图像中识别至少一个发声对象,以及基于检索到的关于至少一个发声对象的信息引起调节。听力接口设备还可以包括电声换能器,其被配置为向用户的耳朵提供来自至少一个音频信号的声音。助听器设备还可包括其它元件,例如上文关于听力接口设备1710所述的元件。在一些实施例中,听力接口设备可包括骨传导麦克风,其被配置为通过用户头部的骨骼的振动向用户提供音频信号。这种设备可以与用户皮肤外部接触放置,或者可以通过外科手术植入并附着在用户的骨骼上。
644.上述描述仅用于说明。本公开并不详尽,且不限于所公开的精确形式或实施例。从所公开的实施例的规范和实践的考虑,对本领域技术人员来说,修改和适应将是显而易见的。另外,尽管所公开的实施例的方面被描述为存储在存储器中,但是本领域技术人员将理解,这些方面也可以存储在其他类型的计算机可读介质上,诸如,辅助存储设备,例如,硬盘或cd
‑
rom,或其他形式的ram或rom、usb介质、dvd、蓝光、超高清蓝光或其他光驱介质。
645.基于书面描述和公开的方法的计算机程序在有经验的开发人员的技能范围内。各种程序或程序模块可以使用本领域技术人员已知的任何技术来创建,或者可以结合现有软件来设计。例如,程序段或程序模块可以以或通过.net框架、.net紧凑框架(以及相关语言,诸如visual basic、c等)、java、c++、objective
‑
c、html、html/ajax组合、xml或包括在java applets中的html等方式设计。
646.此外,虽然本文已经描述了示例性实施例,但是任何和所有实施例的范围具有本领域技术人员基于本公开将理解的等效元素、修改、省略、组合(例如,跨各种实施例的方面的)、适应和/或改变。权利要求书中的限制将基于权利要求书中使用的语言进行广泛解释,而不限于本说明书中描述的示例或在申请过程中描述的示例。这些示例将被解释为非排他性的。此外,所公开的方法的步骤可以任何方式修改,包括通过对步骤重新排序和/或插入或删除步骤。因此,在以下权利要求及其等效物的全部范围所指示的真实的范围和精神中,本说明书和示例意图于仅被认为是说明性的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1